大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
JDBC
简介
JDBC 是Java应用程序用来连接关系型数据库的标准API,为多种关系型数据库提供一个统一的访问接口。Sun公司一共定义4种 JDBC 驱动类型,一般使用第4种,该类型的Driver完全由Java代码实现,通过使用socket与数据库进行通信。
- JDBC-ODBC Bridge driver (bridge driver),JDBC-ODBC桥驱动程序;
- Native-API/partly Java driver (native driver),JDBC本地API;
- All Java/Net-protocol driver (middleware driver),JDBC-Net纯Java;
- All Java/Native-protocol driver (Pure java driver),100%纯Java。
常规数据库连接一般由以下六个步骤构成:
- 装载数据库驱动程序;
- 建立数据库连接;
- 创建数据库操作对象;
- 访问数据库,执行sql语句;
- 处理返回结果集;
- 断开数据库连接。
此处省略常规 JDBC 获取连接、执行SQL、获取结果集代码,一般严格遵守上面的流程,网上一大堆;
连接角度看 JDBC
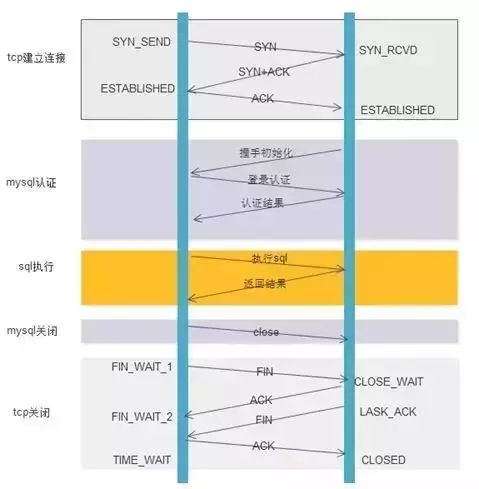

上图大致画出以访问MySQL为例,执行一条 SQL 命令,不使用连接池的情况下,需要经过哪些流程。
- TCP建立连接的三次握手;
- MySQL认证的三次握手;
- 真正的SQL执行;
- MySQL的关闭;
- TCP的四次握手关闭;
为了执行一条SQL,有很多网络交互。
优点:实现简单。
缺点:
- 网络IO较多;
- 数据库的负载较高;
- 响应时间较长及QPS较低;
- 应用频繁的创建连接和关闭连接,导致临时对象较多,GC频繁;
- 在关闭连接后,会出现大量TIME_WAIT 的TCP状态(在2个MSL之后关闭)。
JDBC技巧
- 使用PrearedStatement,可以通过预编译的方式避免在拼接SQL时造成SQL注入。
- 使用ConnectionPool
- 禁用自动提交
这个最佳实践在我们使用JDBC的批量提交的时候显得非常有用,将自动提交禁用后,你可以将一组数据库操作放在一个事务中,而自动提交模式每次执行SQL语句都将执行自己的事务,并且在执行结束提交。 - 使用Batch Update:批量更新/删除,比单个更新/删除,能显著减少数据传输的往返次数,提高性能。
- 使用列名获取ResultSet中的数据,从而避免invalidColumIndexError
JDBC中的查询结果封装在ResultSet中,我们可以通过列名和列序号两种方式获取查询的数据,当我们传入的列序号不正确的时候,就会抛出invalidColumIndexException,例如你传入了0,就会出错,因为ResultSet中的列序号是从1开始的。另外,如果你更改了数据表中列的顺序,你也不必更改JDBC代码,保持了程序的健壮性。有一些Java程序员可能会说通过序号访问列要比列名访问快一些,确实是这样,但是为了程序的健壮性、可读性,我还是更推荐你使用列名来访问。 - 使用变量绑定而不是字符串拼接
使用PreparedStatment可以防止注入,而使用?或者其他占位符也会提升性能,因为这样数据库就可以使用不同的参数执行相同的查询,提示性能,也防止SQL注入。 - 关闭Connection 等资源,确保资源被释放;
- 选择合适的JDBC驱动,参考前文,选择第四种;
- 尽量使用标准的SQL语句,从而在某种程度上避免数据库对SQL支持的差异
不同的数据库厂商的数据库产品支持的SQL的语法会有一定的出入,为了方便移植,推荐使用标准的ANSI SQL标准写SQL语句。 - 使用正确的getXXX()方法
当从ResultSet中读取数据的时候,虽然JDBC允许你使用getString()和getObject()方法获取任何数据类型,推荐使用正确的getter方法,这样可以避免数据类型转换。
连接池
先看看连接的简介。
连接
当数据库服务器和客户端位于不同的主机时,就需要建立网络连接来进行通信。客户端必须使用数据库连接来发送命令和接收应答、数据。通过提供给客户端数据库的驱动指定连接字符串后,客户端就可以和数据库建立连接。查阅程序语言手册来获知通过何种方式使用短连接、长连接。
- 短连接
短连接是指程序和数据库通信时需要建立连接,执行操作后,连接关闭。短连接简单来说就是每一次操作数据库,都要打开和关闭数据库连接,基本步骤是:连接 -> 数据传输 -> 关闭连接
在慢速网络下使用短连接,连接的开销会很大;在生产繁忙的系统中,连接也可能会受到系统端口数的限制,如果要每秒建立几千个连接,那么连接断开后,端口不会被马上回收利用,必须经历一个FIN阶段等待,直到可被回收利用为止,这样就可能会导致端口资源不够用。在Linux上,可以通过调整/proc/sys/net/ipv4/ip_local_port_range来扩大端口的使用范围;调整/proc/sys/net/ipv4/tcp_fin_timeout来减少回收延期(如果想在应用服务器上调整这个参数,一定要慎重!)。
另外一个办法是主机使用多个IP地址。端口数的限制其实是基于同一个IP:PORT的,如果主机增加IP,MySQL就可以监听多个IP地址,客户端也可以选择连接某个IP:PORT,这样就增加端口资源。
- 长连接
长连接是指程序之间的连接在建立之后,就一直打开,被后续程序重用。使用长连接的初衷是减少连接的开销。当收到一个永久连接的请求时,检查是否已经存在一个相同的永久连接。存在则复用;不存在则重新建立一个新的连接。所谓相同的连接是指基本连接信息,即用户名、密码、主机及端口都相同。
从客户端的角度来说,使用长连接有一个好处,可以不用每次创建新连接,若客户端对MySQL服务器的连接请求很频繁,永久连接将更加高效。对于高并发业务,如果可能会碰到连接的冲击,推荐使用长连接或连接池。
从服务器的角度来看,它可以节省创建连接的开销,但维持连接也是需要内存的。如果滥用长连接的话,可能会使用过多的MySQL服务器连接。现代的操作系统可以拥有几千个MySQL连接,但很有可能绝大部分都是睡眠状态的,这样的工作方式不够高效,而且连接占据内存,也会导致内存的浪费。
对于扩展性好的站点来说,其实大部分的访问并不需要连接数据库。如果用户需要频繁访问数据库,那么可能会在流量增大的时候产生性能问题,此时长短连接都是无法解决问题的,所以应该进行合理的设计和优化来避免性能问题。
如果客户端和MySQL数据库之间有连接池或Proxy代理,一般在客户端推荐使用短连接。对于长连接的使用一定要慎重,不可滥用。如果没有每秒几百、上千的新连接请求,就不一定需要长连接,也无法从长连接中得到太多好处。在Java语言中,由于有连接池,如果控制得当,则不会对数据库有较大的冲击,但PHP的长连接可能导致数据库的连接数超过限制,或者占用过多的内存。
-
连接池
数据库连接池是一些网络代理服务或应用服务器实现的特性,实现一个持久连接的“池”,允许其他程序、客户端来连接,这个连接池将被所有连接的客户端共享使用,连接池可以加速连接,也可以减少数据库连接,降低数据库服务器的负载。 -
持久连接和连接池的区别
长连接是一些驱动、驱动框架、ORM工具的特性,由驱动来保持连接句柄的打开,以便后续的数据库操作可以重用连接,从而减少数据库的连接开销。而连接池是应用服务器的组件,它可以通过参数来配置连接数、连接检测、连接的生命周期等。
如果连接池或长连接使用的连接数很多,有可能会超过数据库实例的限制,那么就需要留意连接相关的设置,比如连接池的最小、最大连接数设置,以及php-fpm的进程个数等,否则程序将不能申请新的连接。
最小连接数和最大连接数的设置要考虑到以下几个因素:
最小连接数:连接池一直保持的数据库连接,如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费;
最大连接数:连接池能申请的最大连接数,如果数据库连接请求超过次数,后面的数据库连接请求将被加入到等待队列中,这会影响以后的数据库操作;
如果最小连接数与最大连接数相差很大:那么最先连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接。不过这些大于最小连接数的数据库连接在使用完不会马上被释放,将被放到连接池中等待重复使用或是空间超时后被释放。
池化
连接池类似于线程池或者对象池,数据库连接池为系统的运行带来以下优势:
- 昂贵的数据库连接资源得到重用;
- 减少数据库连接建立和释放的时间开销,提高系统响应速度;
- 统一的数据库连接管理,避免连接资源的泄露。
连接池负责:连接建立、连接释放、连接管理、连接分配。
数据库连接池运行机制:
系统初始化时创建连接池,程序操作数据库时从连接池中获取空闲连接,程序使用完毕将连接归还到连接池中,系统退出时,断开所有数据库连接并释放内存资源。
数据库连接池生命周期
数据库每个读写操作需要一个连接。数据库连接调用流如下图:
调用流程为:
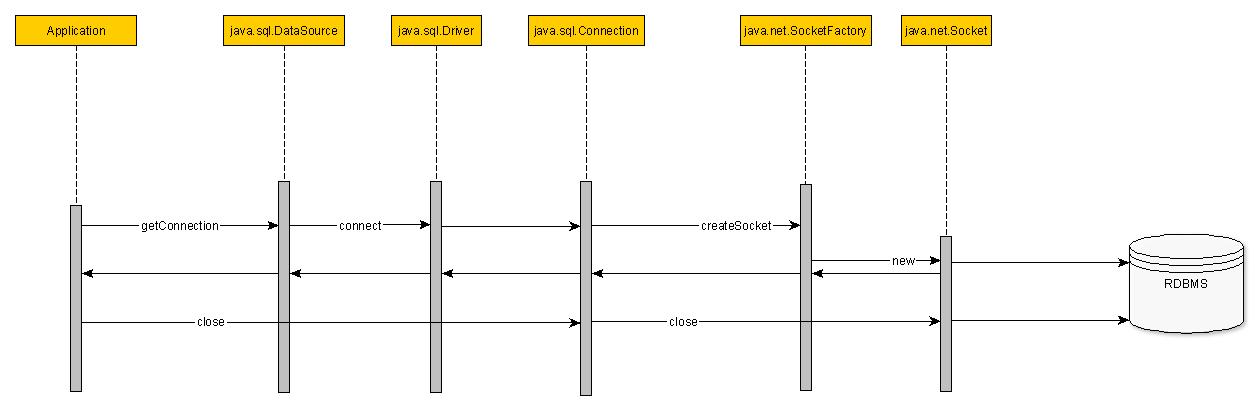
- 应用数据层向DataSource请求数据库连接
- DataSource使用数据库Driver打开数据库连接
- 创建数据库连接,打开TCP socket
- 应用读/写数据库
- 如果该连接不再需要就关闭连接
- 关闭socket
为什么连接池快很多?
分析池连接管理的调用流程:
无论何时请求一个连接,池数据源会从可用的连接池获取新连接。仅当没有可用的连接而且未达到最大的连接数时连接池将创建新的连接。close()方法把连接返回到连接池而不是真正地关闭它。
重用数据库连接最明显的原因:
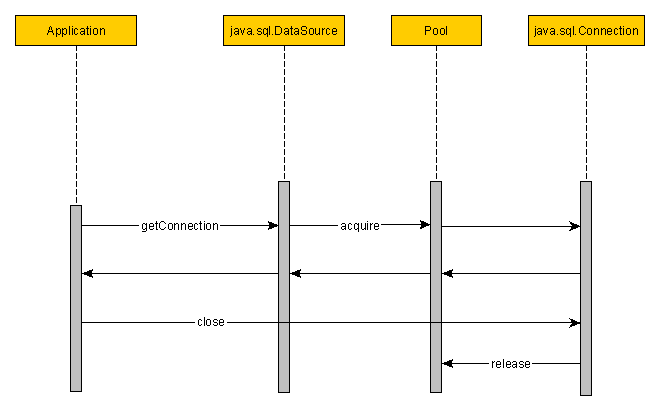
- 减少应用程序和数据库管理系统创建/销毁TCP连接的OS I/O开销
- 减少JVM对象垃圾
- 缓冲安全:连接池是即将到来的连接请求的有界缓冲区。如果出现瞬间流量尖峰,连接池会平缓这一变化,而不是使所有可用数据库资源趋于饱和。
- 等待步骤和超时机制,可有效防止数据库服务器过载。如果一个应用消耗太多数据库流量,为防止它将数据库服务器压垮,连接池将减少它对数据库的使用。
配置
连接池配置大体可以分为基本配置、关键配置、性能配置等主要配置。
基本配置
基本配置是指连接池进行数据库连接的四个基本必需配置:传递给JDBC驱动的用于连接数据库的用户名、密码、URL以及驱动类名。
在Druid连接池的配置中,driverClassName可配可不配,如果不配置会根据url自动识别dbType(数据库类型),然后选择相应的driverClassName。
关键配置
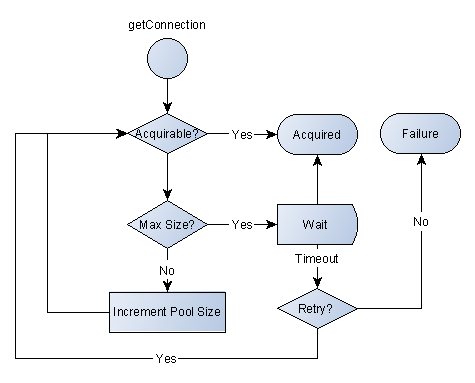
为了发挥数据库连接池的作用,在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
最小连接数:是数据库一直保持的数据库连接数,所以如果应用程序对数据库连接的使用量不大,将有大量的数据库资源被浪费。
初始化连接数:连接池启动时创建的初始化数据库连接数量。
最大连接数:是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求被加入到等待队列中。
最大等待时间:当没有可用连接时,连接池等待连接被归还的最大时间,超过时间则抛出异常,可设置参数为0或者负数使得无限等待(根据不同连接池配置)。
数据库连接池在初始化的时候会创建initialSize个连接,当有数据库操作时,会从池中取出一个连接。如果当前池中正在使用的连接数等于maxActive,则会等待一段时间,等待其他操作释放掉某一个连接,如果这个等待时间超过maxWait,则会报错;如果当前正在使用的连接数没有达到maxActive,则判断当前是否空闲连接,如果有则直接使用空闲连接,如果没有则新建立一个连接。在连接使用完毕后,不是将其物理连接关闭,而是将其放入池中等待其他操作复用。
性能配置
预缓存设置:PSCache,对支持游标的数据库性能提升巨大,比如说oracle。JDBC的标准参数,用以控制数据源内加载的PreparedStatements数量。但由于预缓存的statements属于单个connection而不是整个连接池,所以设置这个参数需要考虑到多方面的因素。
单个连接拥有的最大缓存数:要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
连接有效性检测设置:连接池内部有机制判断,如果当前的总的连接数少于miniIdle,则会建立新的空闲连接,以保证连接数得到miniIdle。如果当前连接池中某个连接在空闲timeBetweenEvictionRunsMillis时间后任然没有使用,则被物理性的关闭掉。有些数据库连接的时候有超时限制(mysql连接在8小时后断开),或者由于网络中断等原因,连接池的连接会出现失效的情况,这时候设置一个testWhileIdle参数为true,可以保证连接池内部定时检测连接的可用性,不可用的连接会被抛弃或者重建,最大情况的保证从连接池中得到的Connection对象是可用的。当然,为了保证绝对的可用性,你也可以使用testOnBorrow为true(即在获取Connection对象时检测其可用性),不过这样会影响性能。
超时连接关闭设置:removeAbandoned参数,用来检测当前使用的连接是否发生连接泄露,所以在代码内部就假定如果建立连接的时间很长,则将其认定为泄露,继而强制将其关闭掉。
工具
- C3P0:开源JDBC连接池,实现数据源和JNDI绑定,包括实现jdbc3和jdbc2扩展规范说明的Connection 和Statement 池的DataSources 对象。单线程,性能较差,适用于小型系统,代码600KB左右。
- BoneCP:开源的快速的 JDBC 连接池。只有四十几K(运行时需要log4j和Google Collections的支持)。另外个人觉得 BoneCP 有个缺点是,JDBC驱动的加载是在连接池之外的,这样在一些应用服务器的配置上就不够灵活。官方说法BoneCP是一个高效、免费、开源的Java数据库连接池实现库。设计初衷就是为了提高数据库连接池性能,完美集成到一些持久化产品如Hibernate和DataNucleus中。特色:高度可扩展,快速;连接状态切换的回调机制;允许直接访问连接;自动化重置能力;JMX支持;懒加载能力;支持XML和属性文件配置方式;较好的Java代码组织。
- DBCP:Database Connection Pool,一个依赖Jakarta commons-pool对象池机制的数据库连接池,单独使用dbcp需要3个包:
common-dbcp.jar,common-pool.jar,common-collections.jar,预先将数据库连接放在内存中,应用程序需要建立数据库连接时直接到连接池中申请一个就行,用完再放回。单线程,并发量低,性能不好,适用于小型系统。 - Tomcat Jdbc Pool:Tomcat在7.0以前都是使用common-dbcp做为连接池组件,但是dbcp是单线程,为保证线程安全会锁整个连接池,性能较差,dbcp有超过60个类,也相对复杂。Tomcat从7.0开始引入新增连接池模块叫做Tomcat jdbc pool,基于Tomcat JULI,使用Tomcat日志框架,完全兼容dbcp,通过异步方式获取连接,支持高并发应用环境,超简单,核心文件只有8个,支持JMX,支持XA Connection。
- Druid:下面详细讲解;
- HikariCP:下面详细讲解;
本文不会详细介绍前面几种连接池工具,基本上过时;
Druid
简介
阿里出品,淘宝和支付宝专用数据库连接池,但它不仅仅是一个数据库连接池,它还包含一个ProxyDriver,一系列内置的JDBC组件库,一个SQL Parser。支持所有JDBC兼容的数据库。Druid针对Oracle和MySQL特别优化,比如Oracle的PS Cache内存占用优化,MySQL的ping检测优化。Druid提供SQL-92的SQL的完整支持,这是一个手写的高性能SQL Parser,支持Visitor模式,使得分析SQL的抽象语法树很方便。Druid能够提供强大的监控和扩展功能,是一个可用于大数据实时查询和分析的高容错、高性能的开源分布式系统,尤其是当发生代码部署、机器故障以及其他产品系统遇到宕机等情况时,Druid仍能够保持100%正常运行。主要特色:为分析监控设计;快速的交互式查询;高可用;可扩展;
简单SQL语句用时10微秒以内,复杂SQL用时30微秒。
通过Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。Druid防御SQL注入攻击的WallFilter就是通过Druid的SQL Parser分析语义实现的。
- Proxool:一个Java SQL Driver驱动程序,完全可配置。
todo
spring boot with druid
以目前也是以后的 Java EE 发展方向的spring boot 为例,说明如何集成druid。其他传统 SSH & SSM应用架构大致类似,但是配置会复杂一些;
HikariCP
简介
新一代数据库连接池,性能相当优异,spring boot 2 默认使用的 dbcp 从之前的 tomcat-pool 换成HikariCP 。
在 druid 以及 HikariCP 出现之前,BoneCP 可以说是性能最好的 dbcp 之一,https://jolbox.com/index.html?page=https://jolbox.com/benchmarks.html
官网:http://www.jolbox.com/
可是现在,BoneCP 的GitHub 的截图。
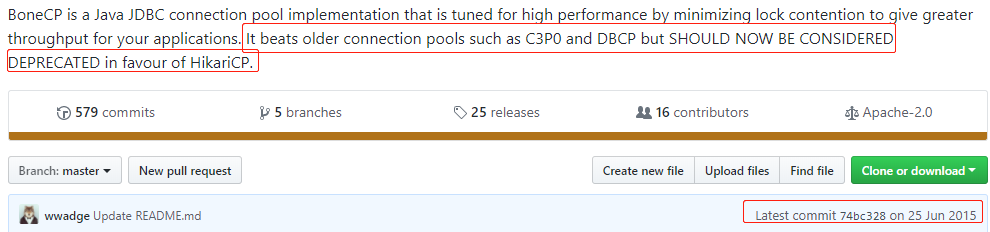
GitHub
优势
Springboot 2.0 默认使用的连接池换成HikariCP,因为其性能格外优异。而其性能来源于HikariCP的在以下几个方面的优化:
- 字节码精简 :优化代码,直到编译后的字节码最少,这样CPU缓存可以加载更多的程序代码;
- 优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
- 自定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
- 自定义集合类型,使用ConcurrentBag提高并发读写的效率;
- 其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究。
JDBC连接池的实现,主要是对JDBC中几个核心对象Connection、Statement、PreparedStatement、CallableStatement以及ResultSet的封装与动态代理。
常用配置项
- dataSourceClassName
接收字符串值,默认为空。JDBC driver 提供的 DataSource 类名。不同的 JDBC driver 会有其相对应的类名(不支持 XA data sources)。如果使用了 jdbcUrl 配置项则不需要配置此项。 - jdbcUrl
接收字符串值,默认为空。此属性将使 HikariCP 使用“基于驱动管理器”(DriverManager-based)的配置。由于多种原因,我们认为基于数据源(DataSource-based)的配置是更好的选择。但对许多部署实例来讲却也区别不大。当使用此属性来配置“旧”的 JDBC 驱动时,你可能也需要设置 driverClassName 属性,但可以试一试不设置是否能行得通。 - username / password
接收字符串值,默认为空。对 DataSource 来讲,username和password仅会在调用 DataSource.getConnection(username, password) 时用到。但在使用基于驱动(Driver-based)配置时,HikariCP 会使用 username 的值去设置调用 DriverManager.getConnection(jdbcUrl, props) 方法时传入的 Properties 中的 user 属性。如果并不是你想要的,你需要避免执行这个方法。 - autoCommit
布尔值,默认为 true。控制从连接池中返回的连接的 auto-commit 行为。通常情况下会设置为 false。比如使用Spring 统一管理数据库事务,这时就需要禁用 auot-commit。 - connectionTimeout
接收数值,默认为30000(30秒),最小可接收值为250ms。设置客户端获取连接前等待的最大毫秒数,即超时时间。如果超过了这个时间后仍然没有可用的数据库连接返回,SqlException 则会被抛出。 - idleTimeout
接收数值,默认为600000(10分),最小可接收值为10000(10秒)。此属性控制一个连接保持空闲状态的最大超时时间。只有当 minimumIdle 小于 maximumPoolSize 时此属性才会生效。一个数据库连接是否退化为空闲状态需要平均15秒+,最多30秒+。设置0表示空闲的连接永远不会从连接池中销毁。 - maxLifetime
接收数值,默认为1800000(30分)。此属性为单个连接在连接池中的最长生命周期时间。连接只有在被关闭后才会被移除。强烈建议设置此属性,并且至少应该比任何数据库或组件强制要求的连接时间少30秒。此属性设置为0表示没有最长生命周期时间。 - connectionTestQuery
接收字符串值,默认为空。如果数据库驱动支持 JDBC4,则强烈建议不要设置此属性。此属性是为那些不支持 JDBC4 Connection.isValid() API 的老旧数据库准备的。这条查询语句会在连接从连接池返回给客户端之前执行,用以验证返回的数据库连接仍然可用。再次重申,在不设置此属性时尝试启动数据库连接池,如果你的数据库驱动不支持 JDBC4,HikariCP 会记录下错误信息。
在 c3p0 中,这个属性的名称是 preferredTestQuery;在 tmocat-jdbc 中,这个属性的名称叫做 validationQuery。属性值一般设置为 “Select 1”。 - minimumIdle
接收数值,默认和 maximumPoolSize 相同。设置 HikariCP 在连接池中保存的最少空闲连接数。如果空闲连接数少于此属性值,HikariCP 会尽力快速高效的增加连接。不过,为了最高性能和峰值弹性需求,我们建议不要设置此属性,而是让 HikariCP 作为一个固定大小的连接池。 - maximumPoolSize
接收数值,默认为10。设置 HikariCP 在连接池中保存的最多连接数,包括空闲的和正在使用的连接。此属性的合理值应该由程序的运行环境决定。当连接池中没有空闲连接,调用 getConnection() 会一直阻塞直到超过 connectionTimeout 设置的超时时间。 - poolName
接收字符串值,默认值为自动生成。此属性为连接池设置用户自定义的名称,并会在日志中显示。设置连接池名称主要是为了配合 JMX 在控制台日志中区分不同的连接池和连接池配置。注意,通过我们实践发现,如果需要配合使用 JMX,最好设置自定义的连接池名称。使用默认的自动生成的连接池名称有可能会出现意想不到的问题。 - prepStmtCacheSize
接收数值,默认为25。此属性设置 MySQL 驱动在每个连接会缓存的 Prepared Statement 数量。推荐设为250到500之间。 - prepStmtCacheSqlLimit
接收数值。此属性为 MySQL 驱动缓存的 Prepared SQL statement 的最大长度。MySQL 默认为256。此默认值远远小于生成的语句长度,推荐将其设置为2048。 - cachePrepStmts
布尔值,默认为 false。打开预处理语句缓存。如果为 false,prepStmtCacheSize 和 prepStmtCacheSqlLimit 都不会起作用。 - useServerPrepStmts
布尔值。新版的 MySQL 支持服务端预处理语句,这可以极大的提高性能。新版MySQL建议设置为 true。
spring boot with HikariCP
initialSize:默认值是 0,连接池创建连接的初始连接数目。
minIdle : 默认是 0,连接数中最小空闲连接数。
maxIdle : 默认是 8,连接池中最大空闲连接数。
maxActive : 默认值是 8, 连接池中同时可以分派的最大活跃连接数。
maxWait : 默认值是无限大,当连接池中连接已经用完,等待建立一个新连接的最大毫秒数 ( 在抛异常之前 )。
validationQuery : 一条 sql 语句,用来验证数据库连接是否正常。这条语句必须是一个查询模式,并至少返回一条数据。一般用“ select 1 ”。
minEvictableIdleTimeMilis : 默认值是 1000 * 60 * 30(30 分钟 ) 单位毫秒,连接池中连接可空闲的时间。
timeBetweenEvictionRunsMilis : 默认值是 -1 ,每隔一段多少毫秒跑一次回收空闲线程的线程。
对于minEvictableIdleTimeMilis、timeBetweenEvictionRunsMilis这两个参数,timeBetweenEvictionRunsMilis必须大于1且小于minEvictableIdleTimeMilis,建议是minEvictableIdleTimeMilis的五分之一或十分之一。
HikariCP v.s. Druid
不具有可比性,HikariCP 追求性能,Druid 偏向监控;druid 默认开启公平锁导致性能下降,有阿里生产环境大数据验证。
参考:issue
其他工具
flexy-pool
FlexyPool adds metrics and fail-over strategies to a given Connection Pool, allowing it to resize on demand.
大意:增加监控,容错,和自适应调整参数功能。
从其GitHub源码组织结构,即可得知,根据不同的连接池工具,引用不同的依赖。
优化
数据库连接池本质上是一种缓存,它是一种抗高并发的手段。数据库连接池优化主要是对参数进行优化,DBCP连接池的具体参数如下(其他各种连接池的配置参数大同小异,需要区别对待):
- initialSize:初始连接数,第一次getConnection的,而不是应用启动时。初始值可以设置为并发量的历史平均值;
- minIdle:最小保留的空闲连接数。DBCP会在后台开启一个回收空闲连接的线程,当该线程进行空闲连接回收的时候,会保留minIdle个连接数。一般设置为5,并发量实在很小可以设置为1.
- maxIdle:最大保留的空闲连接数,按照业务并发高峰设置。比如并发高峰为20,那么当高峰过去后,这些连接不会马上被回收,如果过一小段时间又来一个高峰,那么连接池就可以复用这些空闲连接而不需要频繁创建和关闭连接。
- maxActive:最大活跃连接数,按照可以接受的并发极值设置。比如单机并发量可接受的极值是100,那么这个maxActive设置成100后,就只能同时为100个请求服务,多余的请求会在最大等待时间之后被抛弃。这个值必须设置,可以防止恶意的并发攻击,保护数据库。
- maxWait:获取连接的最大等待时间,建议设置的短一点,比如3s,这样可以让请求快速失败,因为一个请求在等待获取连接的时候,线程是不可以被释放的,而单机的线程并发量是有限的,如果这个时间设置的过长,比如网上建议的60s,那么这个线程在这60s内是无法被释放的,只要这种请求一多,应用的可用线程就少了,服务就变得不可用了。
- minEvictableIdleTimeMillis:连接保持空闲而不被回收的时间,默认30分钟。
- validationQuery:检测连接是否有效的sql语句,建议设置;
- testOnBorrow:申请连接的时候对连接进行检测,不建议开启,严重影响性能;
- testOnReturn:归还连接的时候对连接进行检测,不建议开启,严重影响性能;
- testWhileIdle:开启以后,后台清理连接的线程会没隔一段时间对空闲连接进行validateObject,如果连接失效则会进行清除,不影响性能,建议开启;
- numTestsPerEvictionRun:代表每次检查链接的数量,建议设置和maxActive一样大,这样每次可以有效检查所有的链接;
- 预热连接池:对于连接池,建议在启动应用的时候进行预热,在还未对外提供访问之前进行简单的sql查询,让连接池充满必要的连接数。
参考:
JDBC驱动程序类型
MySQL之长连接、短连接、连接池
the-anatomy-of-connection-pooling
数据库连接池极简教程
高性能数据库连接池的内幕
五大理由分析Springboot 2.0为什么选择HikariCP
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192468.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
