大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
大家好,我是脚丫先生 (o^^o)
最近一直忙于实时流任务的开发。
糟点无处不在,好在成功克服。
时常想做技术的乐趣,在于每当解决一个疑难问题时候的那种喜悦难以言表。
甚是带劲。
时隔多日,我们正式迈入大数据平台之采集篇。
希望能带给小伙伴们劲味十足的喜悦。


文章目录
一、大数据采集之预热
在之前「从 0 到 1 搭建大数据平台之开篇」,我们详细分析了大数据平台框架。
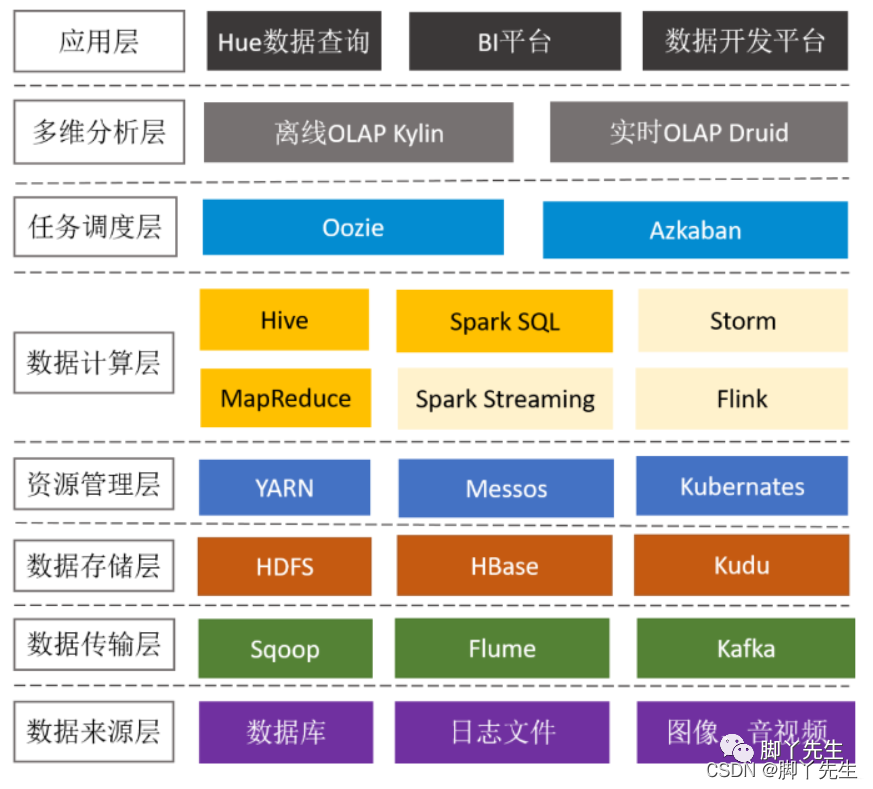
一步一个脚印向前迈进,一层到八层,贼高贼高。
似乎有点恐高。

小伙伴们选择大数据平台,想必是传统的关系型数据库无法满足业务的存储计算要求,面临着海量数据的存储和计算问题。
那么要使用大数据平台的计算能力,首先要做的就是进行数据的集成。
简言之,把需要处理的数据导入大数据平台,利用大数据平台计算能力,对数据进行处理。
二、大数据采集之来源
「从 0 到 1 搭建大数据平台之开篇」中,我们知道了大数据的特性。
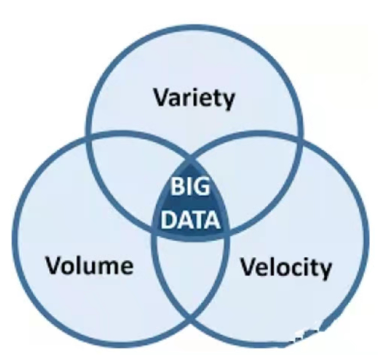
海量的数据: 大而复杂的数据集。
复杂的数据:数据类型的多样性,包括文本,图片,视频,音频。
高速的数据:数据的产生呈指数式爆炸式增长,要求处理数据的速度越来越高。
数据种类大致分为结构化数据、半结构化数据、非结构化数据。
| 数据类型 | 区别 |
|---|---|
| 结构化数据 | 用二维数据库表来抽象表示。以数据库数据和文本数据为结构化数据。 |
| 半结构化数据 | 介于结构化和非结构化之间,主要指 XML、HTML、JSON 文档、Email 等等,也可称非结构化 |
| 非结构化数据 | 数据没有以一个预先定义的方式来组织,不可用二维表抽象,比如图片,图像,音频,视频等 。 |
数据采集,就是根据海量数据的种类不同,选择合适的采集工具,实施数据集成到大数据平台的过程。
一般而言,数据来源主要是两类。
1、各个业务系统的关系数据库,可以称之为业务的交互数据。主要是在业务交互过程中产生的数据。比如,你去大保健要用支付宝付费,淘宝剁手购物等这些过程产生的相关数据。一般存储在 DB 中,包括 Mysql,Oracle。
2、各种埋点日志,可以称之为埋点用户行为数据。主要是用户在使用产品过程中,与客户端进行交互过程产生的数据。比如,页面浏览、点击、停留、评论、点赞、收藏等。简而言之,夜深人静的时候,你躲在被子里,用快播神器看不知名的大片这些行为,都会产生数据被捕获。
其实,还有一种数据来源,就是爬虫爬取的数据。有很多外部数据,比如天气、IP 地址等数据,我们通常会爬取相应的网站数据存储。
总结:大数据采集的数据来自于日志、数据库、爬虫。
2.1 日志采集
2.1.1 浏览器页面日志
浏览器页面日志采集,主要分为两大类。
页面浏览(展现)日志采集: 页面浏览日志是指当
一个页面被浏览器加载呈现时采集的日志。此日志主要价值在于两大基本指标:页面浏览量(PV)和访客数(UV)的统计。
页面交互日志采集:也就是用户行为数据的采集,主要是用户在使用产品过程中,与客户端进行交互过程产生的数据。
2.1.2 无线客户端 App 日志采集
众所周知,日志来集多是为了进行后续的数据分析。

移动端的数据采集。
一是为了服务于开发者,协助开发者分析各类设备信息;
二是为了帮助各 APP 更好地了解自己的用户,了解用户在 APP 上的各类行为,帮助各应用不断进行优化,提升用户体验。
一般来说,App 日志采集采用采集 SDK 来完成。
但是,它的采集又与浏览器日志的采集方式有所不同,移动端的日志采集
根据不同的用户行为分成不同的事件,“事件”为无线客户端日志行为
的最小单位。
2.2 多源异构数据的采集
业务系统的数据类型多种多样,有来源于关系型数据库的结构化数据。
如 MySQL、Oracle、DB2, SQL Server 等:也有来源于非关系型
数据库的非结构化数据,如 HBase、 MongoDB 等,这类数据通常存储在数据库表中。

还有一类以文件的形式进行数据的存储,如:文件系统 FTP,阿里云对象存储等。
针对这些不同源的数据进行采集,利用采集工具将数据源的数据读取出来,转换为中间状态,并在目标数据系统中将中间状态的数据转换为对应的数据格式后写入。
三、大数据采集之工具
上文已经说过,对于不同的数据来源,所选取的大数据采集组件是不同。
正所谓,好马配好鞍。
面对,如此多的数据来源,我们如何选取大数据采集技术栈呢?

我们已经知道了大数据采集的数据来自于日志、数据库、爬虫。
接下来,针对每种数据来源使用的工具进行讲解。
3.1 日志采集工具
目前广泛使用的日志收集工具有,Flume、Logstash、Filebeat、Fluentd。
我们知道了针对日志数据进行采集所使用的工具。
那么这么几款日志收集工具,小伙伴一定会说。
自己有选择困难症。
要如何选取,也是一个问题。
Flume: Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,它支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Logstash: 一个开源数据收集引擎,具有实时管道功能。Logstash 可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Filebeat: 一个轻量级的日志传输工具,监视指定的日志文件或位置,收集日志事件,并将它们转发到 Elasticsearch 或 Logstash 进行索引。
Fluentd: 一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
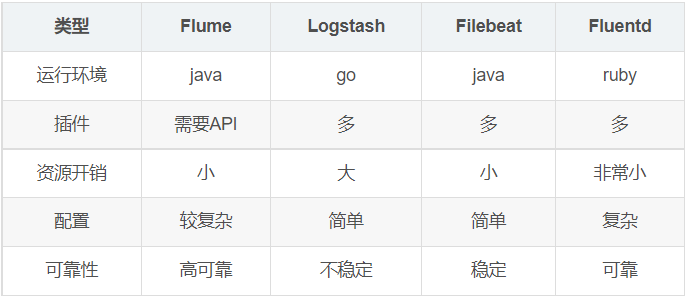
大数据日志采集工具,有很多种,小伙伴们可以根据自己的业务需求,进行合适选择。
3.2 多源异构数据的采集工具
目前公司项目,离线数据的集成与同步,利用大数据采集技术栈进行多源异构数据的导入导出的使用比较多。

多源异构数据采集的大数据技术栈,目前广泛的是 Sqoop、Datax。
1、Sqoop: SQL–to–Hadoop。正如 Sqoop 的名字所示,主要用于在 Hadoop、Hive 与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。

其架构如下所示
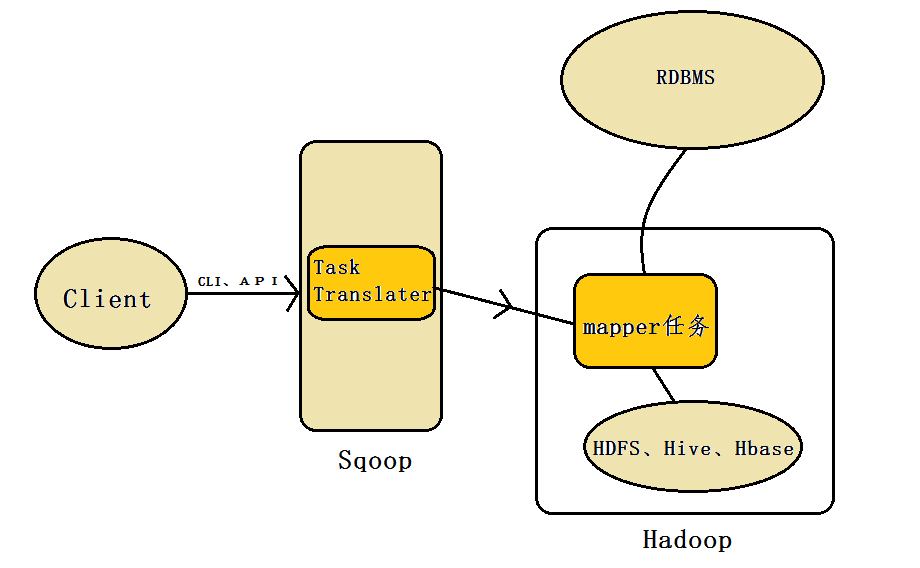
Sqoop 工具接收到客户端的 shell 命令或者 Java api 命令后,通过 Sqoop 中的任务翻译器将命令转换为对应的 MapReduce 任务,而后将关系型数据库和 Hadoop 中的数据进行相互转移,进而完成数据的拷贝。
2、Datax:阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。

DataX 本身作为离线数据同步框架,采用 Framework + plugin 架构构建。将数据源读取和写入抽象成为 Reader/Writer 插件,纳入到整个同步框架中。
其架构如下所示:

DataX 在设计之初就将同步理念抽象成框架+插件的形式.框架负责内部的序列化传输,缓冲,并发,转换等而核心技术问题,数据的采集(Reader)和落地(Writer)完全交给插件执行。
- Read 数据采集模块,负责采集数据源的数据,将数据发送至 FrameWork。
- Writer 数据写入模块,负责不断的向 FrameWork 取数据,并将数据写入目的端。
- FrameWork 用于连接 reader 和 write,作为两者的数据传输通道,处理缓冲,流控,并发,转换等核心技术问题。
以上为最常用的异构数据源采集工具,至于小伙伴们要选择哪个技术栈都是根据自己的业务需求的。
小结:Sqoop依赖于Hadoop生态对HDFS、Hive支持友善,在处理数仓大表的速度相对较快,但不具备统计和校验能力。
DataX无法分布式部署,可以在传输过程中进行过滤,并且可以统计传输数据的信息,因此在业务场景复杂(表结构变更)更适用,同时对于不同的数据源支持更好。
且DataX的开源版本目前只支持单机部署,需要依赖调度系统实现多客户端,同时不支持自动创建表和分区。
3.3 外部数据之爬虫

简单的来说,网络爬虫就是自动从互联网中定向或不定向的采集信息的一种程序。
目前常用的爬虫工具是Scrapy,它是一个爬虫框架,提供给开发人员便利的爬虫API接口。开发人员只需要关心爬虫API接口的实现,不需要关心具体框架怎么爬取数据。
Scrapy框架大大降低了开发人员开发速率,开发人员可以很快的完成一个爬虫系统的开发。
至此,我们就已经通过大数据采集技术栈把不同来源的海量数据采集至大数据平台。
好了,今天就聊到这里,祝各位终有所成,收获满满!
期待老铁的关注!!!
更多精彩内容请关注 微信公众号 ?「脚丫先生」?:
一枚热衷于分享大数据基础原理,技术实战,架构设计与原型实现之外,还喜欢输出一些有趣实用的编程干货内容,与私活案例。
更多精彩福利干货,期待您的关注 ~
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192376.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
