大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
免责声明:本文所记录的技术手段及实现过程,仅作为爬虫技术学习使用,不对任何人完全或部分地依据本文的全部或部分内容从事的任何事情和因其任何作为或不作为造成的后果承担任何责任。
Scrapy爬虫框架用Python编写的功能强大,应用范围最广,最流行的爬虫框架,框架提供了大量的爬虫相关的组件,能够方便快捷的完成各网站的爬取。
01
Scrapy安装
打开scrapy官方网站【scrapy.org】,目前最新版本为2.5:


按照官方提供的脚本,在命令行执行安装:pip install scrapy
之后会自动下载依赖的包,并完成安装:
02
创建scrapy工程
打开windows命令行,跳转到需要爬虫工程的目录,运行scrapy创建工程脚本:
scrapy startproject test001

Scrapy框架自动生成test001工程代码,通过Pycharm打开:
03
创建scrapy爬虫
进入工程的根目录,cd test001
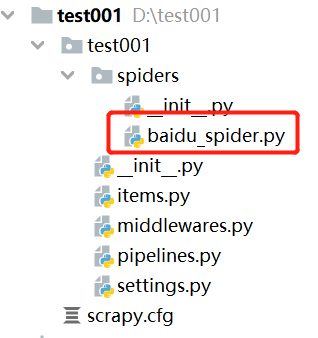
运行生成爬虫的命令:scrapy genspider baidu_spider baidu.com

爬虫生成成功
04
运行scrapy爬虫
进入工程的根目录,cd test001
运行生成爬虫的命令:scrapy crawl baidu_spider
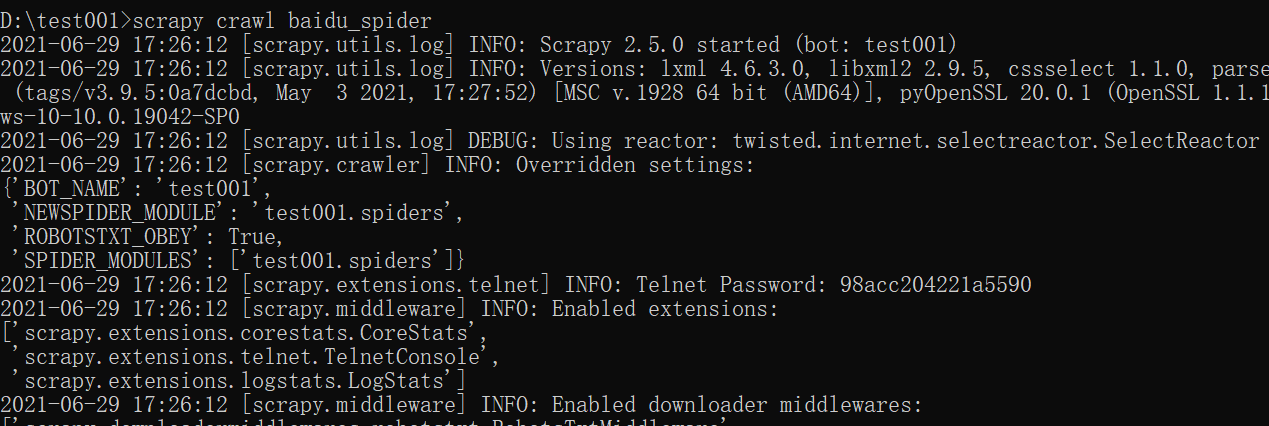
爬虫运行成功,由于没有编写爬虫代码,所以没有任何结果。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192163.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
