大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
目录
Introduction & Behavioral Cloning
DAGGER algorithm to improve BC【就是在BC中引入了online iteration,2011】
(1)最简单直接的结合:预训练和调整 Pretrain and Finetune【应用十分广泛】
(2)IL 结合 Off-Policy RL:算是对 Pretrain and Finetune 的改进
一个有趣的 Case Study—— motion imitation
课程大纲
模仿学习介绍
行为克隆 BC 和 DAGGER 算法
逆强化学习 IRL 和 生成对抗模仿学习GAIL
改进模仿学习的性能
把模仿学习和强化学习结合
Introduction & Behavioral Cloning
从最简单的行为克隆方法开始介绍:比较简单的思想就是把策略的学习当做有监督的学习来进行,例如学习出来策略网络
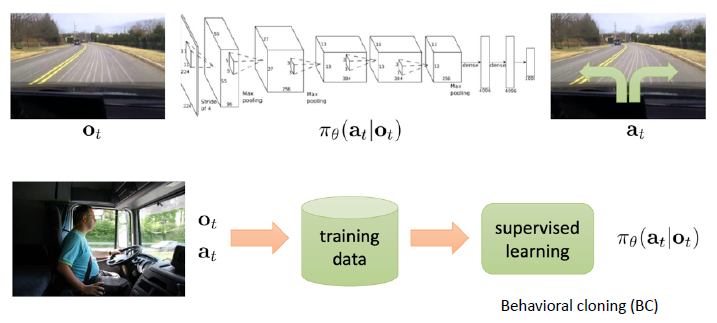

这样直接把它当做一个有监督的问题来解决的话其实是有问题的:数据的分布假设相矛盾 —— 有监督学习假设数据是 IID 的,但是一个时序的决策过程采集到的数据是有关联的;而且如果模型进入到 off-course 状态(训练时没见到过的状态)时不知道怎么回来
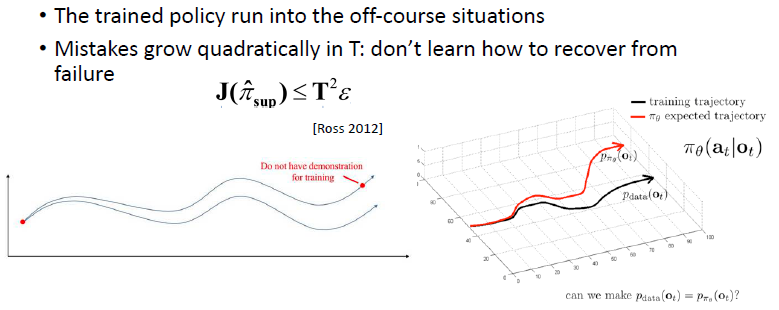
一个可能的解决方案就是:不断添加数据,变成 online 的过程
DAGGER algorithm to improve BC【就是在BC中引入了online iteration,2011】


DAGGER 的缺点在于第三步实在是太耗费时间了,可以改进 DAGGER 吗?第三步是不是可以用其他的算法来打标签呢?
改进DAGGER:

Inverse RL & GAIL
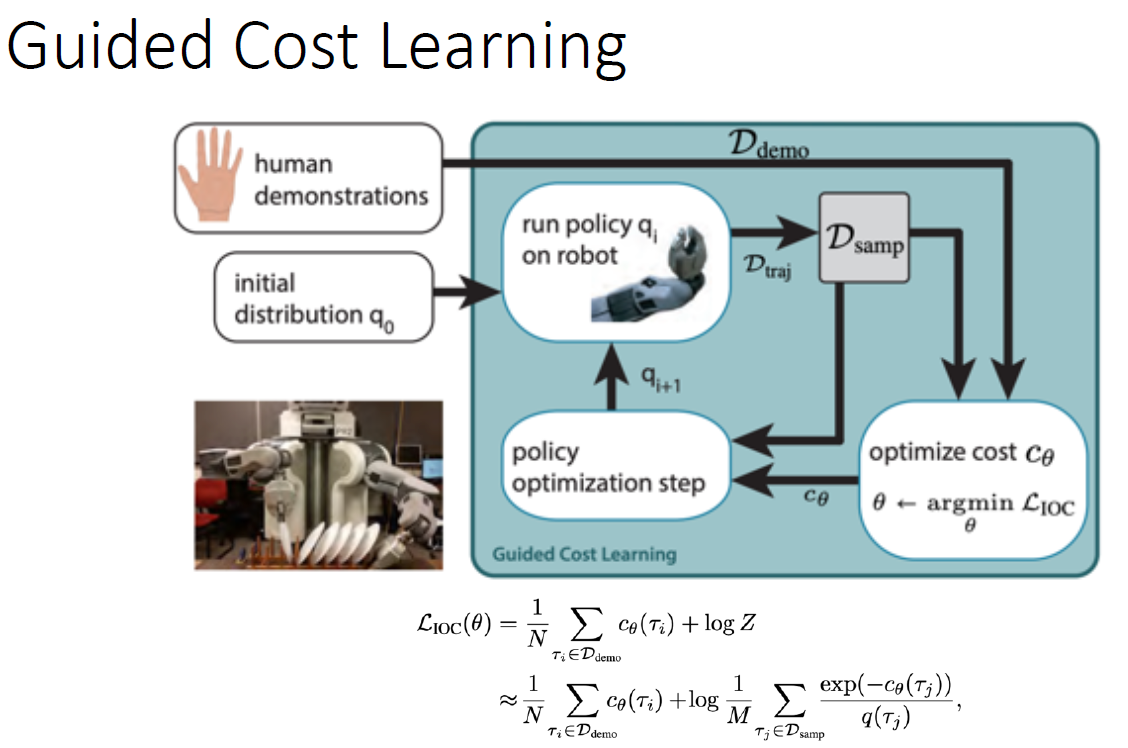
Inverse RL
IRL 与 RL 的对比:

IRL的举例:
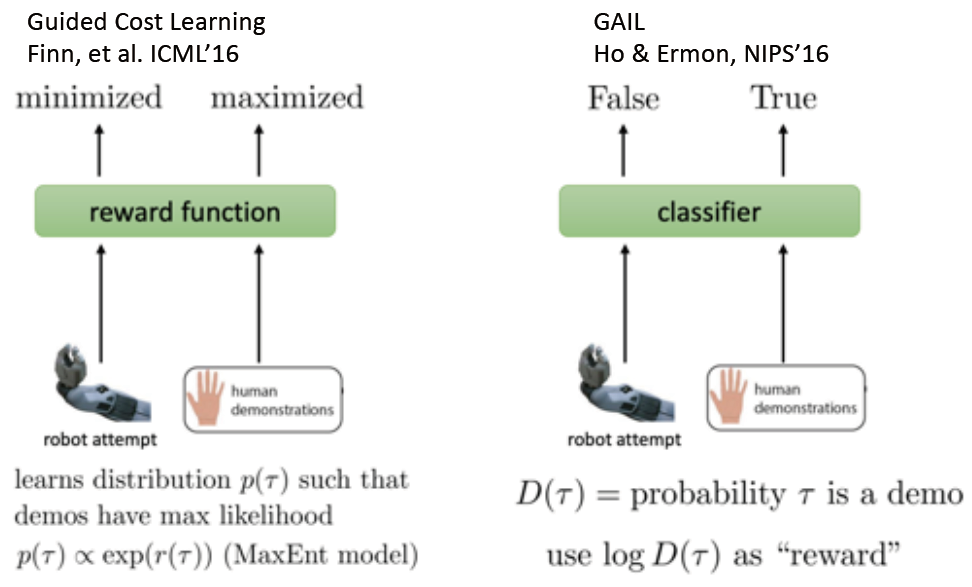
GAIL
类似于 IRL,GAN 学习了一个目标函数用于生成模型,GAIL 模仿了 GAN 的思想

Connection between IRL & GAIL
改进模仿学习的性能
怎样提升我们的策略模型?
问题一:Multimodal behavior

解决方案:
①输出一个多高斯模型,也就是多峰的叠加的形式
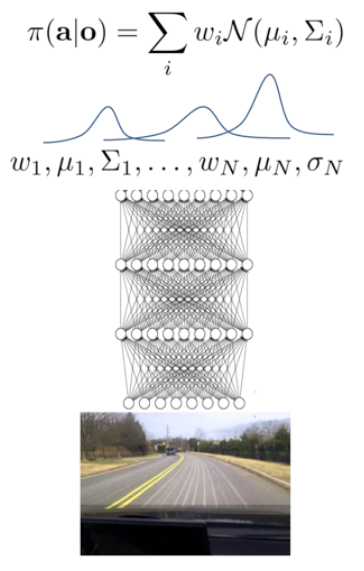
②隐变量模型
③自回归离散
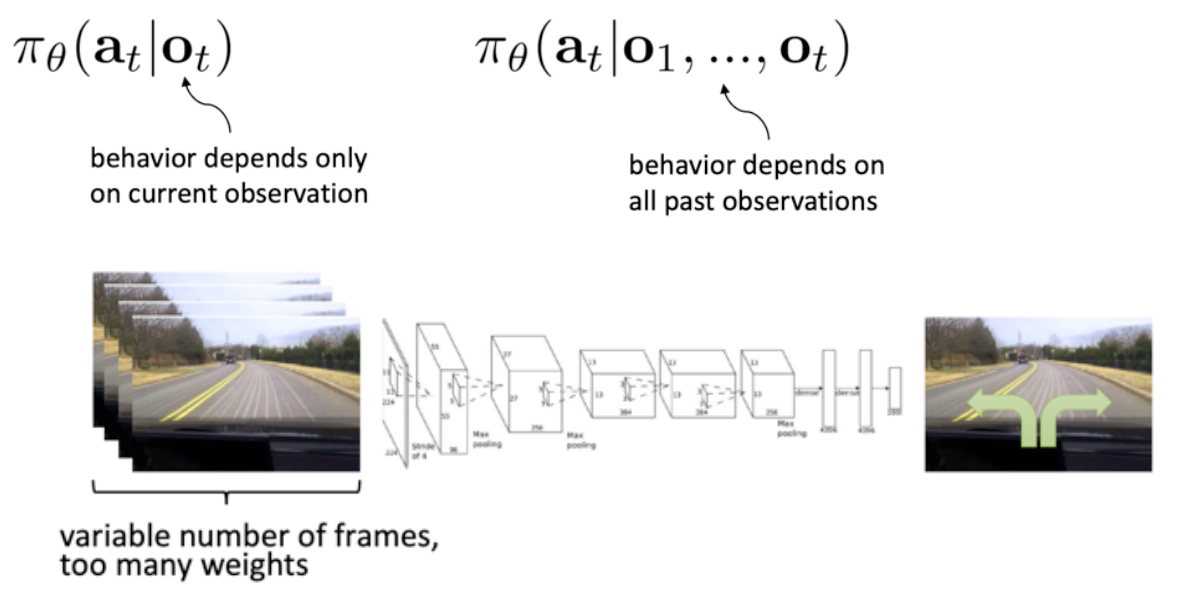
问题二:Non-Markovian behavior

解决方案:
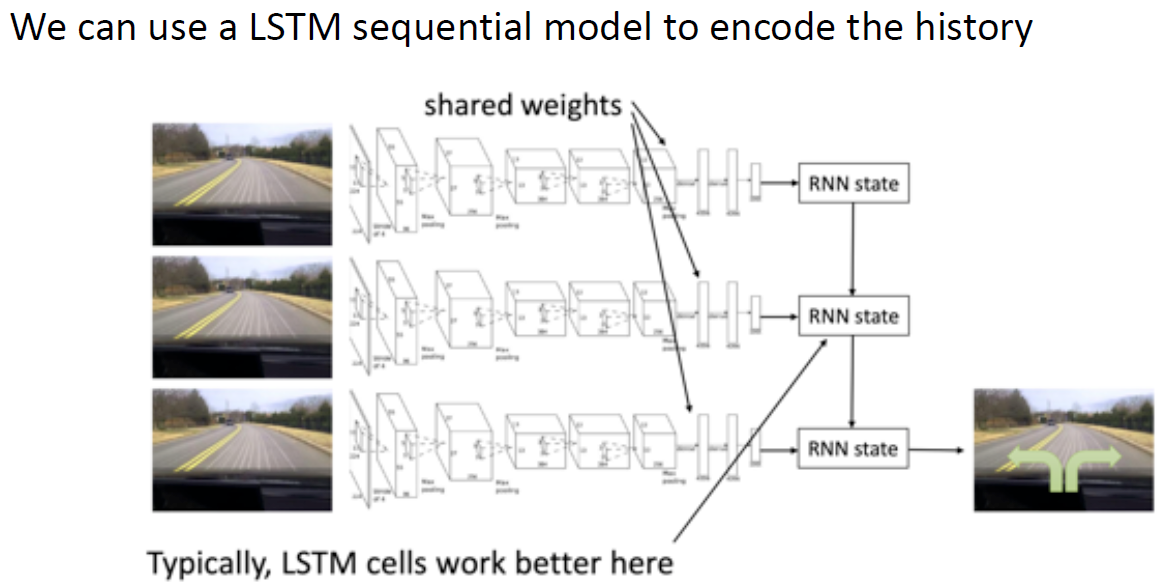
①建模整个观测历史,比如说 LSTM
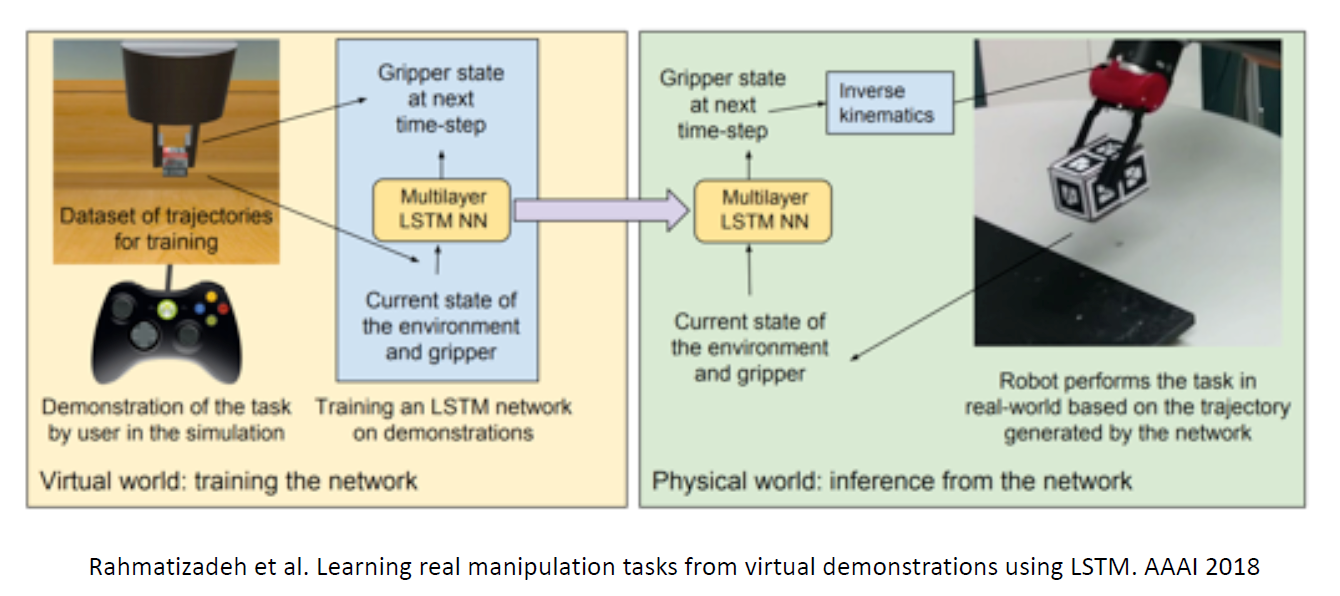
用 LSTM 和 示教数据 完成机械臂抓取的例子【AAAI 2018】
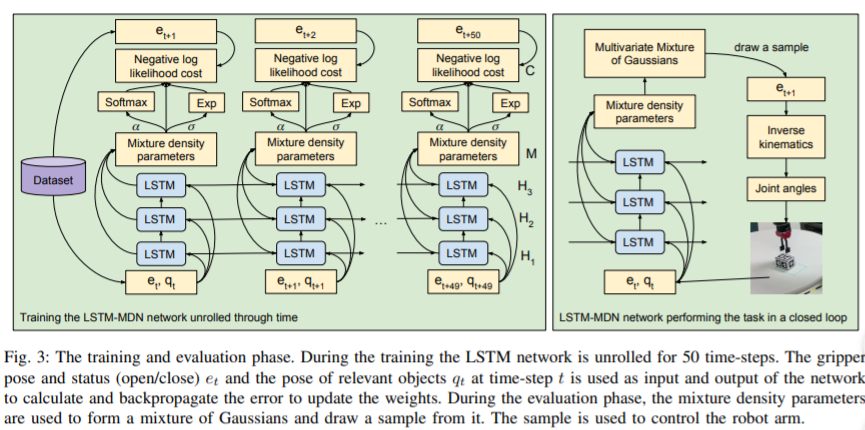
那么其实在机器人领域,如何 scale up 数据一直是一个很大的问题

斯坦福的李飞飞组提出的 crowdsourcing 的方法来采集很多很多很多人的示教数据,RoboTurk项目出了一种解决方案
模仿学习其实还有一些问题
①人为提供数据,这个数据本身就有限
②人有时候不能很好提供数据,例如对无人机示教、对复杂机器人的示教
③人本身是可以在环境中自由探索的,是否可以借鉴这一点呢?
所以下面我们就想把模仿学习与强化学习结合起来
模仿学习与强化学习结合
模仿学习与强化学习的各自的特点对比

怎么把两者结合起来,既有 Demonstration 又有 Rewards?
(1)最简单直接的结合:预训练和调整 Pretrain and Finetune【应用十分广泛】
也就是说用 Demonstration 预训练一个 Policy(解决 exploration 的问题),然后用 RL 去 improve policy 和解决那些 off-policy 的状态,最终达到超过示教者表现的过程
Pretrain and Finetune 的流程如下:

这里是之前的 DAGGER 算法,可以和 Pretrain and Finetune 进行对比:

Pretrain and Finetune 的应用:
①应用于 AlphaGo【Nature 2016 Silver】
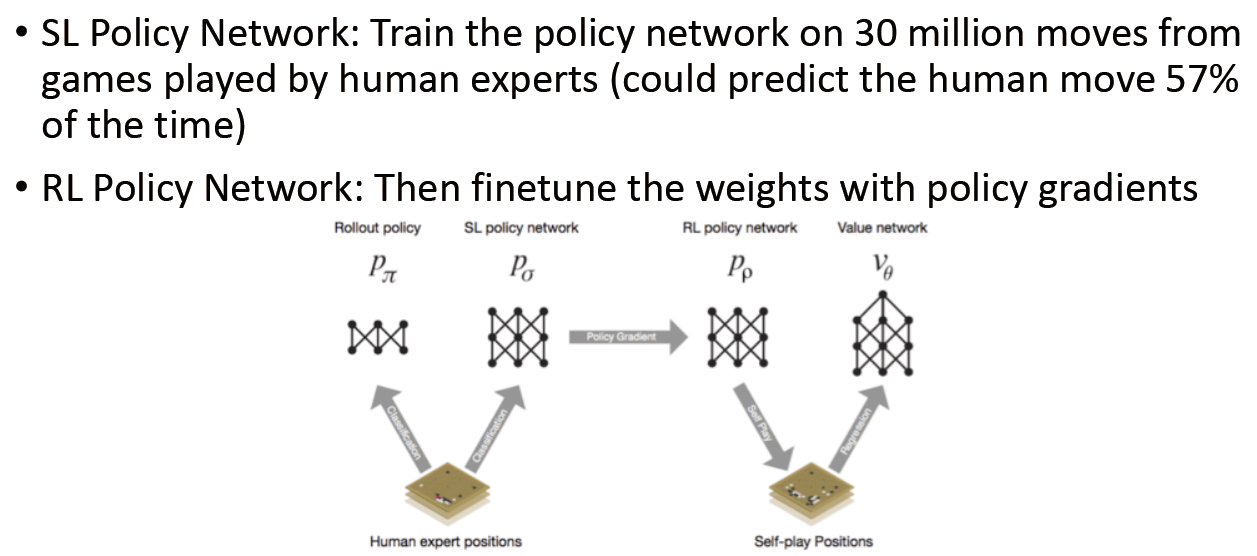
②应用于 Starcraft2【DeepMind工作】

Pretrain and Finetune 的问题:

①在第三步的时候我们之前获得的比较好的 Policy 用强化学习来训练的时候,可能会面临分布不一致的问题
②最开始的 experience 可能是很糟糕的,这样在进行训练时会摧毁 policy network
解决Pretrain and Finetune 问题的方案:考虑怎样把 Demonstration 一直保留下来 —— Off-Policy RL
(2)IL 结合 Off-Policy RL:算是对 Pretrain and Finetune 的改进
off-policy RL 可以用任意的 experience data ,例如对Q-Learning来说,只要把它们放到 replay buffer 里面就可以一直用

①形式一:Policy Gradient with Demonstration

应用举例:
②形式二:Q-Learning with Demonstration

(3)另一种结合方式:把 IL 作为一项辅助的损失函数

优化 RL的期望回报 + IL的极大似然
应用举例:【2017年】


一个有趣的 Case Study—— motion imitation
可以在实际的人的关节贴传感器采数据,甚至还可以从视频里通过姿态估计来采数据训练agent
详细内容去听周老师的课吧~
IL 本身存在的问题
(1)怎样去收集 Demonstration
① Crowdsourcing
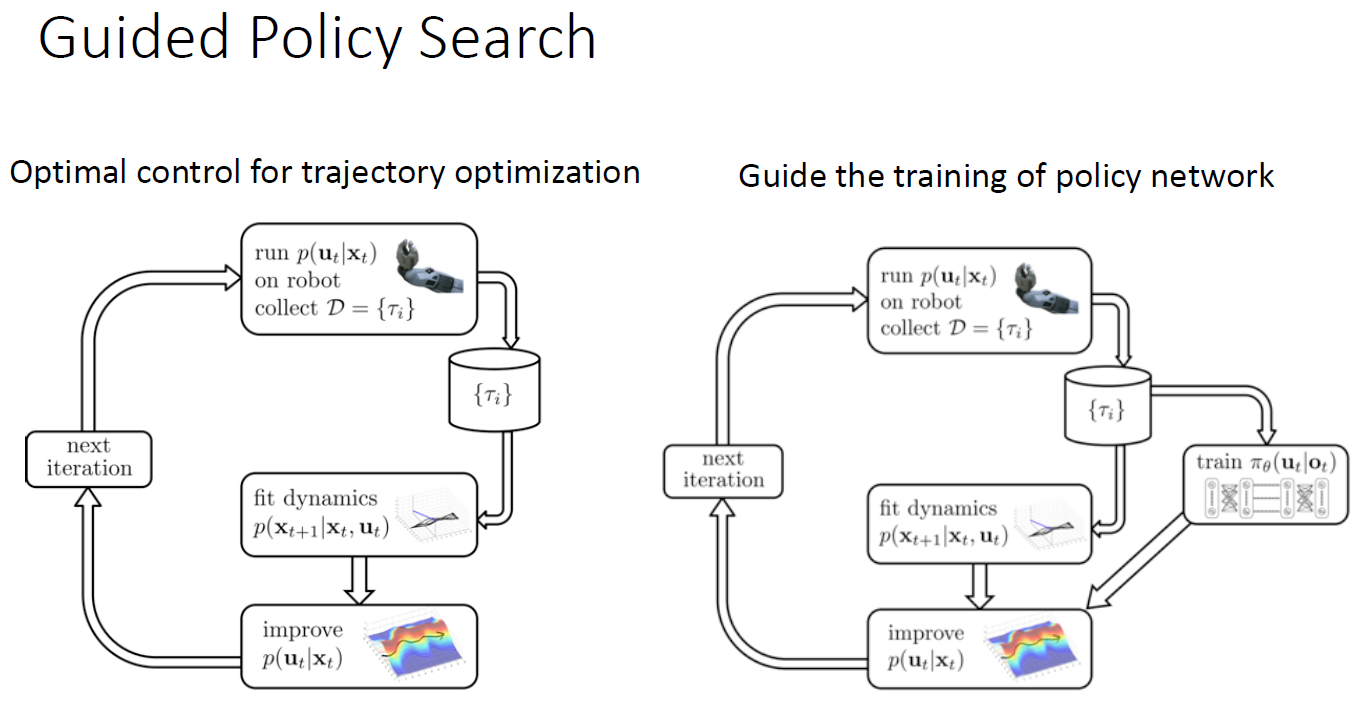
② Guided policy search or optimal control for trajectory optimization
(2)怎样优化 Policy 使得 Agent 能处理 off-course 的状况
① 把这些 off-course 的状况也建模进来,打好标签
② Use off-policy learning with the already collected samples
③ 结合 IL 和 RL
总结


注:本文所有内容源自于B站周博磊老师更新完成的强化学习纲要课程,听完之后获益很多,本文也是分享我的听课笔记。周老师Bilibili视频个人主页:https://space.bilibili.com/511221970?spm_id_from=333.788.b_765f7570696e666f.2
感谢周老师 :)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/192003.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
