大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
【强化学习纲要】8 模仿学习
周博磊《强化学习纲要》
学习笔记
课程资料参见:
https://github.com/zhoubolei/introRL.
教材:Sutton and Barton
《
Reinforcement Learning: An Introduction》
8.1 模仿学习概要
- 什么是模仿学习?
- 模仿学习可以把它看作是对agent policy network的一种强监督学习,在训练这个agent的时候会告诉他正确的action是什么,每一步agent都会做出一个决策。
- 在正常的强化学习里面,agent并没有及时得到反馈每一步对不对。模仿学习是说在每一步做出行为后就可以直接告诉agent当前这一步正确行为是什么,所以就可以把它看作对行为模型的监督学习。
- 但是这两者也不完全一致,因为这里面也有很多问题,agent是在一个时序决策过程,所以它每一步做出的影响都会影响它后面做出的决策,所以把它当作一个纯粹的监督学习还是不能满足所有的需求的。
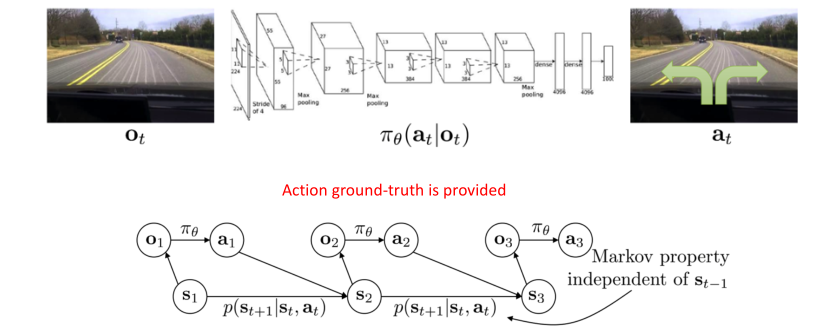

8.2 Behavioral cloning and DAGGER
- 所以对于每一步的决策,很多情况下面可以采集到很多监督信号。比如说需要训练一个自动驾驶的车辆,最容易采集的就是直接在每一个出租车以及人前面装上摄像头,记录司机的行为,这样就会采集到很多的驾驶数据,那么我们可以把它转换成一个监督学习的任务,相当于使得模型每一步都模仿人类世界的行为。
- 这就是模仿学习里面比较常见的一个算法:Behavioral cloning(BC),就是每一步都克隆人的行为。

- 这就是模仿学习里面比较常见的一个算法:Behavioral cloning(BC),就是每一步都克隆人的行为。
Case Study: End to End Learning for Self-Driving Cars
- DAVER-2 System By Nvidia: It works to some degree!
自动驾驶的demo。- 在车上面记录前置摄像头以及司机的转向行为,记录数据。然后车就在无人驾驶的情况下面输入In-vehicle camera,自动针对前置摄像头观测到的数据来进行决策。
- 利用72小时人类开车的数据作为训练

有3个摄像头,把3个摄像头采集到的数据放入CNN网络,这里训练也同时记录了人类对方向盘的操控,用方向盘的操控作为一个训练,这样就可以得到训练强监督的办法,训练开车的agent。然后就可以在真实场景里面开车。
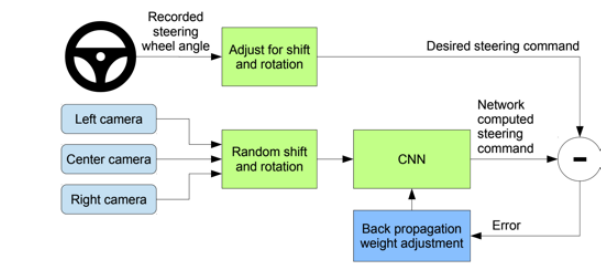
但显而易见这样有很大的缺陷,比如你没法控制让agent左转还是右转,它只会从输入直接给一个输出,所以里面还有很多不足的地方。但是这个工作证明了Behavioral cloning是可以正常运作的。 - Example code of behavior clone: https://github.com/Az4z3l/CarND-Behavioral-Cloning
Case Study: Trail following as a classification轨迹跟踪
- A. Giusti, et al. A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robot. IEEE trans on Robotics and
Automation
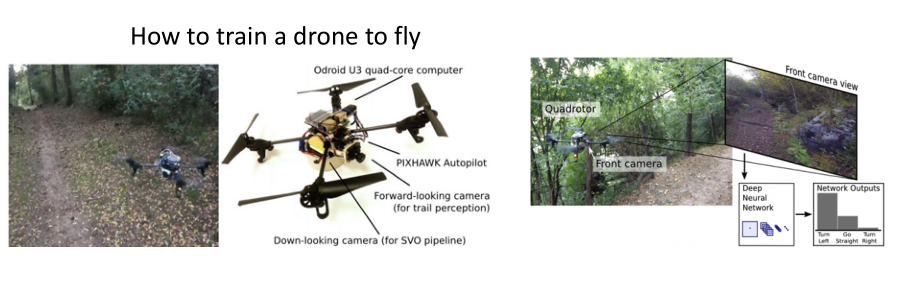

- https://youtu.be/umRdt3zGgpU

监督模仿学习的局限性
- 训练好的policy没法训练off-course situation。也就是说如果进入到之前没有的状态,他就不知道怎么做了。训练这个模型的时候其实用的离线数据,离线数据采集好后就固定下来了。
- agent进入之前并没有见到的状态后,会发生错误,会随着时间 T T T 上面已知累加,会进入一个完全未知的状态。在这种情况下就没法进行一个正常的行为。
- 现在我们的问题是,怎么让agent采集到的数据和实际面临的数据分布尽可能一致?
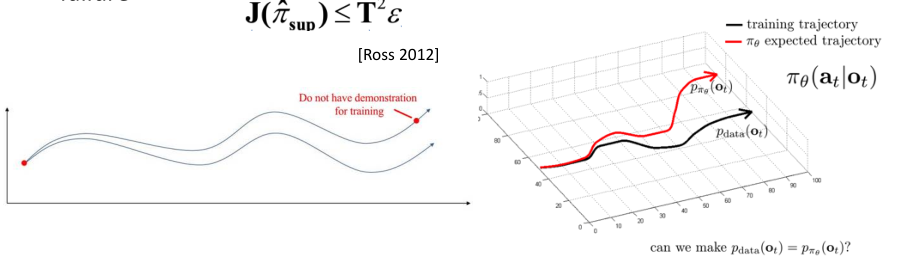
Annotating More On-Policy Data Iteratively
我们可以采取的一个办法是一直保证采取更多的数据。
- 在我们训练好一个agent后,我们可以让这个agent在这个环境里面进行运作;
- 如果进入之前没有的状态,我们就把这个状态收集过来,让人给一个标签,就可以收集到这种状态,放入数据库,就可以重新收集policy网络。
- 就可以在我们deploy(部署)这个数据的时候采集更多的数据,就使得之前的数据库变得越来越完善,训练出来的agent也会越来越好。
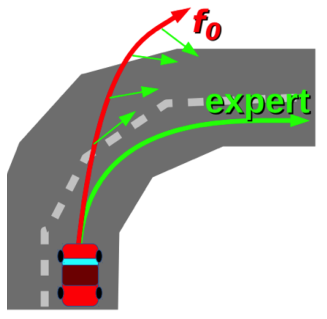
DAgger: Dataset Aggregation数据集集合
这也是DAgger的核心。
- 它希望解决的问题是希望 p d a t a ( o t ) p_{data}(o_t) pdata(ot)的分布和policy 采集到的数据 p π θ ( o t ) p_{
{\pi}_{\theta}}(o_t) pπθ(ot)尽可能一致。 - 它采取的办法是,利用初步的human data训练一个agent;让agent在环境里面进一步采集,和环境交互采集到另外一个数据库;让人给新采集到的数据进行标签;把它组合到原来的数据库里面去。再重新训练policy,这样迭代的过程就可以采集到越来越多更实际的数据,这样就可以让agent在运作的过程中,遇到的数据都是在训练数据中出现过的。

- 局限性是第三步是很耗时的过程。
- 因此这里可以改进的办法是可以在第三步的时候可以用其他的算法。因为有些其他的算法可能是个速度比较慢的算法,因为这里是个离线的过程可以允许比较慢的算法,或者可以用优化的办法来search最佳的结果。因此第三步可以用其他算法来产生标签这样就可以完善它的数据集,来训练policy network。
8.3 Inverse RL and GAIL
Inverse Reinforcement Learning (IRL)
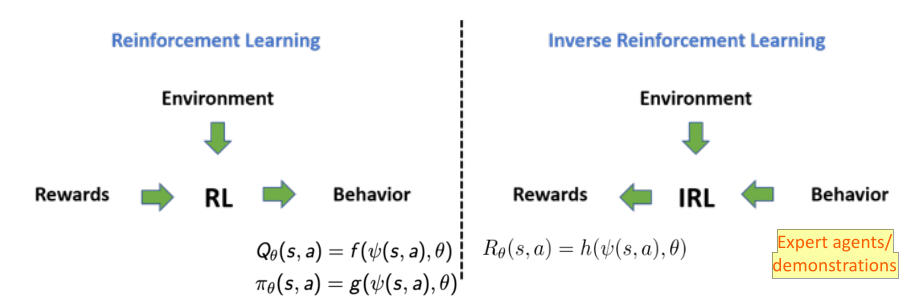
- 左边是普通强化学习的情况。在强化学习里面是给定了环境,也给定了奖励函数,通过强化学习可以对价值函数以及决策函数进行参数化来优化参数。
- 右边是逆强化学习。面临的问题是相反的,给定了环境,行为(可能是policy network也可能是expert的一些示教(数据)),我们希望从这些数据里面去反推reward function。相当于我们可以把reward function进行建模变成需要去优化的一个函数。通过观测到数据去优化reward function,训练出reward function后,我们可以去新训练这个agent,模仿这个Expert agents/demonstrations的行为。
Guided Cost Learning
- Finn, et al, ICML’16. https://arxiv.org/pdf/1603.00448.pdf
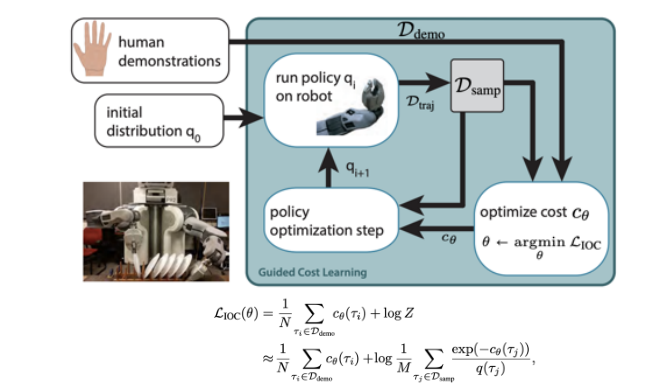
大致思想是由一个human demonstrations,用human demonstrations和机器人得到了行为,训练一个cost function c θ c_{\theta} cθ去优化函数,使得和policy optimization结合起来,可以使得policy network的行为和human network的行为越来越一致。
Generative Adversarial Imitation Learning(GAIL)生成对抗模仿模型
- 仿照的是GAN,GAN是在数据生成里面利用非常广的算法,利用了对抗损失函数的方法,来训练generator G G G。在GAN模型里面由generator G G G生成七 和discriminator D D D辨别器 。generator的目的是产生数据欺骗discriminator,discriminator的目的是区分开generator生成的虚假和真实的数据。通过对抗的原理就可以得到generator和discriminator。

- GAIL是模仿了GAN的思想。可以把demonstration trajectory τ \tau τ看成是sample x x x;把policy π \pi π~ q ( τ ) q(\tau) q(τ)看成generator G G G;把reward function r r r看成discriminator D D D。

- 我们希望训练一个generator可以产生轨迹使得discriminator没法区分出是human产生的轨迹还是生成模型产生的轨迹。
- Ho and Ermon,NIPS’16. https://arxiv.org/pdf/1606.03476.pdf
IRL和GAIL的联系
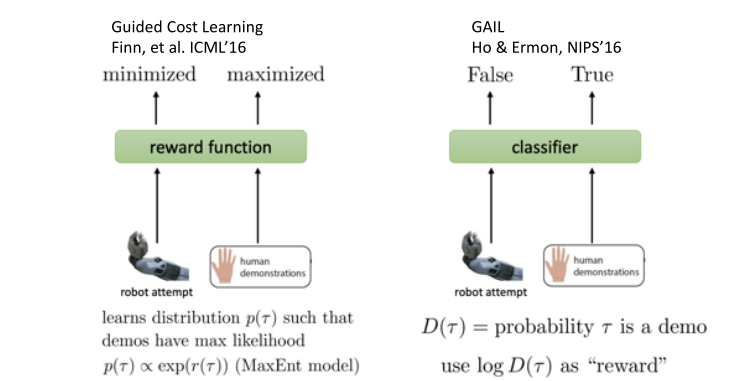
- 在Guided Cost Learning里面是希望训练一个reward function,使得human demonstration可以maximized cost function,robot attempt可以minimized cost function。
- 在GAIL环境下面是训练了一个discriminator,是个binary分类器,使得discriminimator对robot attempt和human domostrations的区分越来越小。
- Finn, Christiano, et al. A connection between GANs, Inverse RL, and Energy-based Models. https://arxiv.org/pdf/1611.03852.pdf
这篇论文揭示了这三者之间的联系。
8.4 进一步改进模仿学习的模型
- 这里比较重要的一点是我们采集到的demonstration很多时候可能是在同一个状态下面有多个可能的解。
比如像绕开这棵树,可以从左边也可以从右边走。
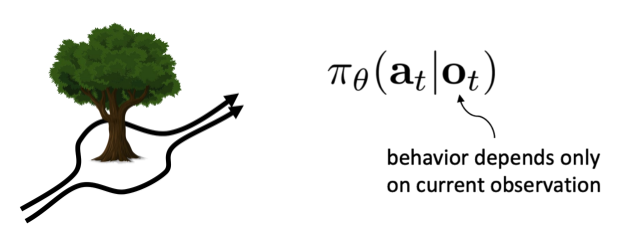
但是在采集的时候只能采集到其中一条数据。 - 因此我们希望改进能够解决:
- Multimodal behavior多模态行为
- Non-Markovian behavior非马尔可夫行为
- 比较直接的改进是可以把policy network建成一个mixture of Gaussians,即多峰的高斯分布的输出。因为这样的多峰的可以由很多个mode,这样就可以输出很多个action的行为。

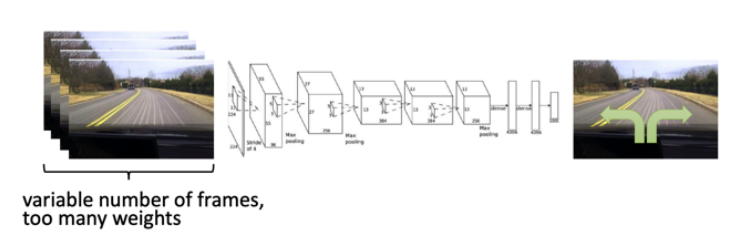
- 另外我们可以把policy network进一步改进,让它实际采集的input behavior 观测把之前的观测都考虑进来,做出下一步的决策行为。

所以我们输入的情况下可以把之前帧尽可能多的放到网络里面,这样这个网络就可以通过之前很多帧做出正确的决策。
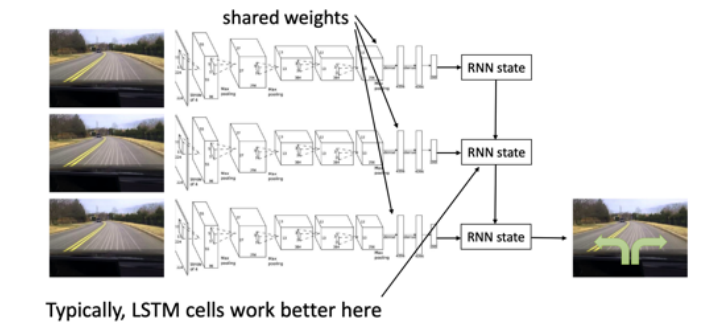
- 更进一步的改进,比如把LSTM加入里面,把之前帧的信息做一个整合,再输出当前应该做出怎么样的行为。这样使得它做出更准确的决策。
Case Study: Learning from demonstration using LSTM
- Rahmatizadeh et al. Learning real manipulation tasks from virtual demonstrations using LSTM. AAAI 2018
- 很多机器人的应用里面imitation learning都是非常重要的,因为机器人的setup下,是非常贵的。如果纯粹通过强化学习trial and error的方法,去尝试的话很难学到好的policy。最好的办法是让人控制手臂,采集到demonstration,然后让机器人结合demonstration来学习就可以极大的提高它的效率。
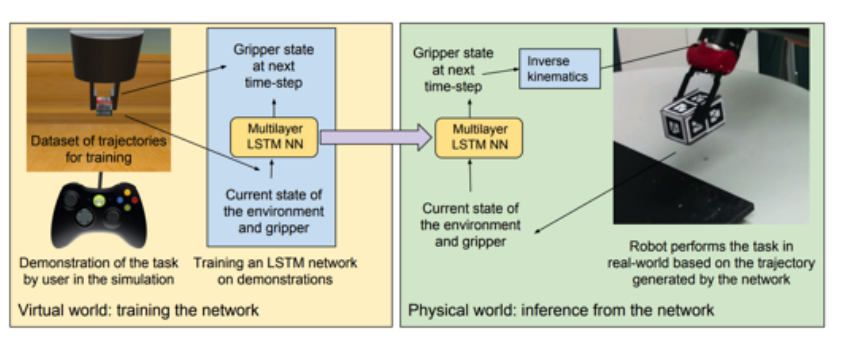
比如说这个工作就是在一个虚拟环境下面,通过控制一个手柄采集到了示教的数据,然后把采集到的示教的数据用到机械臂上。 - 模型中利用LSTM当成监督学习来训练它的模型。这里也用到了Mixture of Gaussians 来处理多峰的模型,因为机器人模型要控制很多jiont model,所以输出是一个连续的输出。
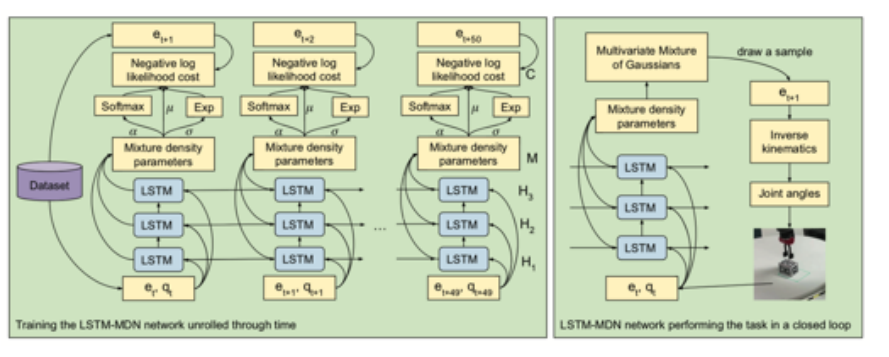
- 但是这样的机械臂控制也有一个问题,怎样scale up(提高)它的 demonstration?因为在控制手臂的时候他都是通过人来控制机器人,去示教它的值。

比如之前的那个是人为的控制了650次demonstrations。 - 因此我们提出可以用==Crowd-sourcing(众包)==的办法来采集数据。
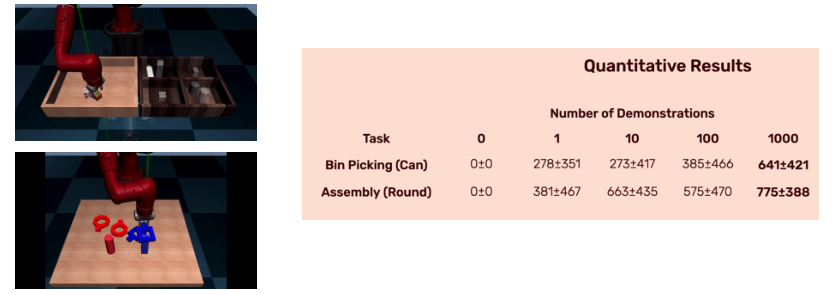
RoboTurk: Crowdsourcing Robotic Demonstrations
- RoboTurk is a crowdsourcing platform that is collecting human demonstrations of tasks such as “picking” and “assembly”;

- 137.5 hours of demonstration for two tasks
- 1071 successful picking demonstrations and 1147 assembly demonstrations
模仿学习的缺点
- 必须人为的收集数据,数据并不是很好的收集到。
- 有些比较复杂的机械情况下面,人并不是很好的提供数据,比如六旋翼的飞行桨很难通过一个遥控来采集数据
- 人的行为有的时候是非监督学习
8.5 模仿学习和强化学习结合
- 模仿学习:
- 优点:
- 简单稳定的监督学习
- 缺点:
- 需要提供demonstration
- distributional shift(分配移位),data分布不一致
- 只能和demo一样好
- 优点:
- 强化学习:
- 优点:
- 可以取得比demo(人)更好的结果
- 缺点:
- 需要定义好reward function
- 需要平衡exploration和exploitation
- Potentially non-convergent
- 优点:
- 怎样结合起来?在训练的过程中既有人的示教demonstration又有reward function?
Simplest Combination: Pretrain预训练 & Finetune微调
- 最简单的一个方法是pretraining预训练的方法。先采集到人为的数据,然后把人为的数据监督学习得到一个初步的策略网络。得到策略网络后,再进一步用强化学习来改进初步得到的策略网络。
- Pretrain预训练 & Finetune微调

先利用demonstration data,通过监督的方法得到网络;
再进一步改进策略。 - == DAgger==

相对于DAgger,是先采集human data,得到data set;
然后把data set里面data都进行标定;
再合成新的数据库,再训练policy。
Pretrain & Finetune for AlphaGo
- SL Policy Network:通过监督学习采集到人类选手下围棋的30million的moves 的数据,通过监督的办法先训练了policy network,
- RL policy network:然后把policy network放到self-play里面,通过强化学习的办法进一步finetune weight,这样就可以得到一个超人的行为。
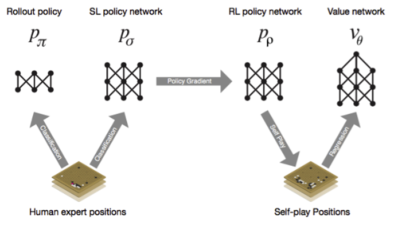
- David Silver, et al. Mastering the ancient game of Go with Machine Learning. Nature 2016
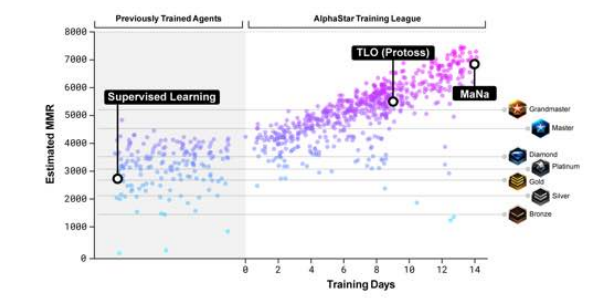
Pretrain & Finetune for Starcraft2
- https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
- 首先采集人类的行为训练出policy

- 采用Population-based and multi-agent reinforcement learning
Problem with the Pretrain & Finetune
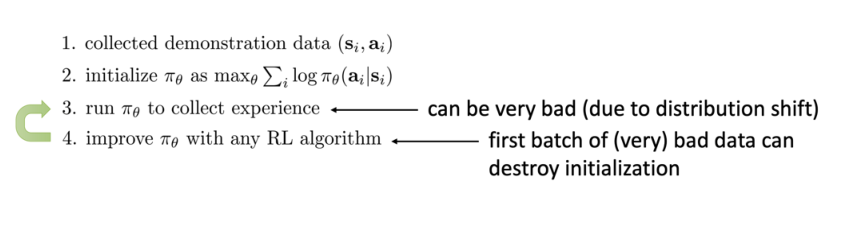
当得到了一个初步的policy network后,用强化学习来训练的时候,强化学习采集到的experience可能本身是非常糟糕的,会直接摧毁policy network。
那么在这个过程中,怎么让它不要忘记demonstrations呢?
Solution: Off-policy Reinforcement Learning
- Off-policy RL是可以用任何experience,是可以把人类施教的experience也放到buffer里面。
- 把demonstration当作data在每一步都提供。
- Off-policy policy gradient (with importance sampling)
- Off-policy Q-learning
Policy gradient with demonstrations

Guided Policy Search
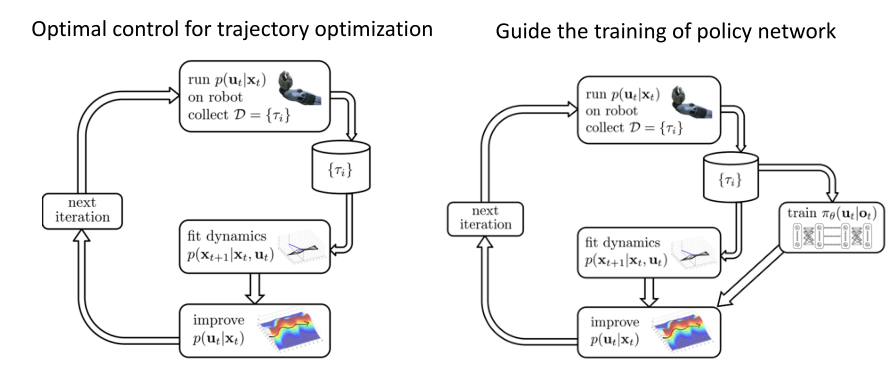
Q-learning with demonstrations

- Vecerik et al., ‘17, “Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Imitation learning as an auxiliary loss function
- Hybrid objective: we can combine RL and imitation learning objective

第一部分是强化学习本身需要优化expectation over reward function,另外一半是直接优化极大似然imitation learning。
面临问题:放KaTeX parse error: Undefined control sequence: \lamda at position 1: \̲l̲a̲m̲d̲a̲
Hybrid policy gradient

- Rajeswaran et al., ‘17, “Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations”
Hybrid Q-Learning
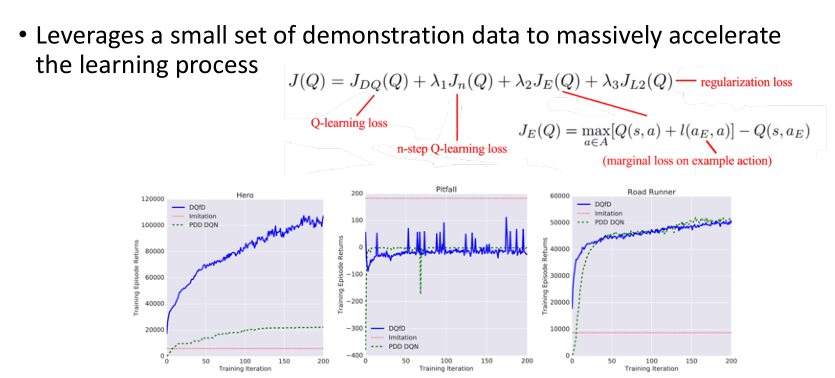
- Hester et al., AAAI’18, “Deep Q-learning from Demonstrations”
8.6 Case studies
Case Study: Motion Imitation

- 把这个reference motion表征成一个sequence of target poses

- 定义一个reward function

- First term is imitation objective (imitate the reference motion),
second term is task dependent - Train with PPO
- Imitation reward is carefully designed
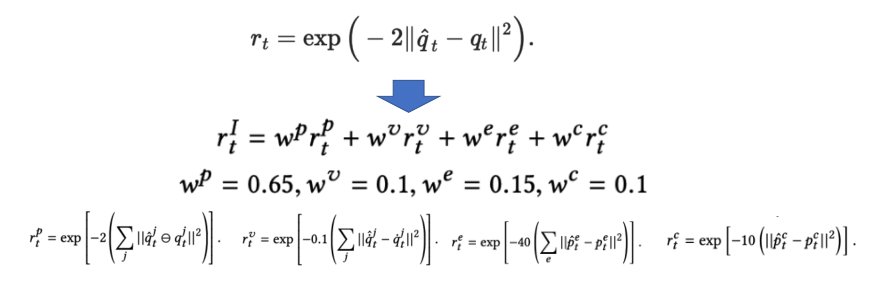
- Peng et al. SIGGRAPH’18. DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
https://xbpeng.github.io/projects/DeepMimic/index.html - Follow-up work: how to get rid of MoCap data(在人身上贴很多标定点)

- Learning dynamics from videos
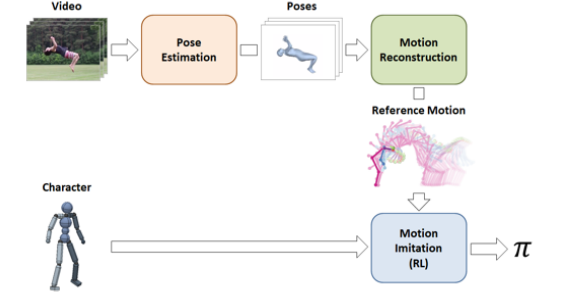
- Vision-based pose estimator

- Peng, et al. SFV: Reinforcement Learning of Physical Skills from Videos Transactions on Graphics (Proc. ACM SIGGRAPH Asia 2018) https://bair.berkeley.edu/blog/2018/10/09/sfv/
Two Major Problems in Imitation Learning
- How to collect expert demonstrations
- Crowdsourcing
- Guided policy search or optimal control for trajectory optimization
- How to optimize the policy for off-course situations
- Simulate those situations to collect new labels
- Use off-policy learning with the already collected samples
- Combine IL and RL
Conclusion
- Imitation learning is an important research topic to bridge machine learning and human demonstration
- Robot learning (learn from few samples)
- Inverse reinforcement learning
- Active learning
- etc
- Recent survey: An Algorithmic Perspective on Imitation Learning: https://arxiv.org/pdf/1811.06711.pdf
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191915.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
