大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
文章目录
参考资料
1. 模仿学习概述
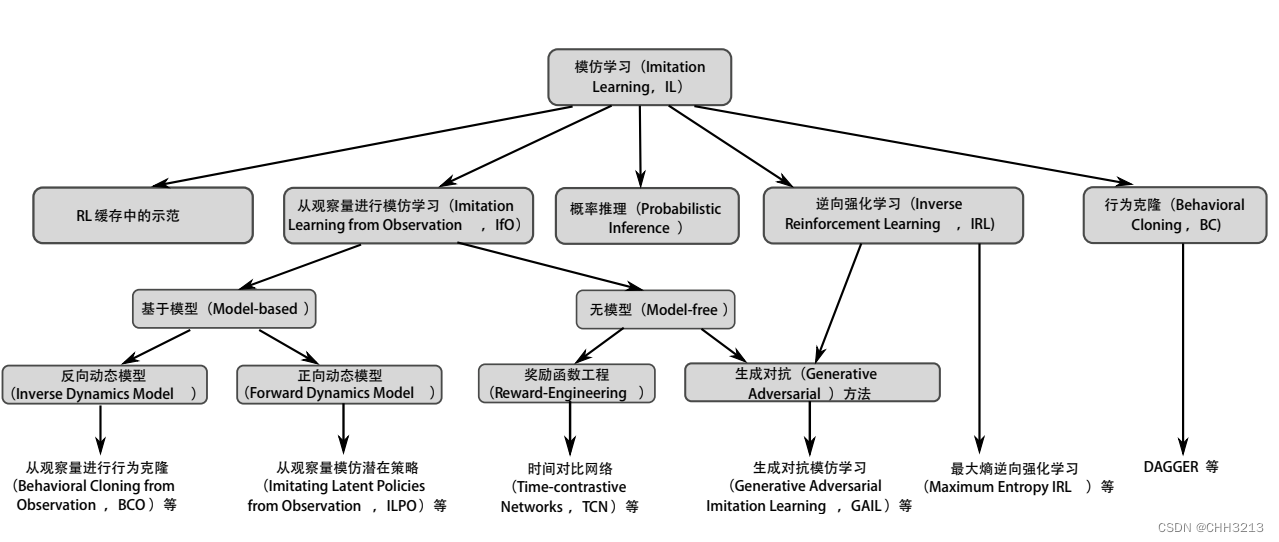

模仿学习(imitation learning,IL)又叫做示范学习(learning from demonstration),学徒学习(apprenticeship learning),观察学习(learning by watching)。
模仿学习的概念可以用学徒学习的形式来定义:按照一个未知的奖励函 数 r ( s , a ) r(s, a) r(s,a), 学习者找到一个策略 π \pi π 能够表现得和专家策略 π E \pi_{\mathrm{E}} πE 相当。我们定义一个策略 π ∈ Π \pi \in \Pi π∈Π 的占 用率 (Occupancy) 的度量 ρ π ∈ D : S × A → R \rho_{\pi} \in \mathcal{D}: \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R} ρπ∈D:S×A→R 为: ρ π ( s , a ) = π ( a ∣ s ) ∑ t = 0 ∞ γ t p ( S t = s ∣ π ) \rho_{\pi}(s, a)=\pi(a \mid s) \sum_{t=0}^{\infty} \gamma^{t} p\left(S_{t}=s \mid \pi\right) ρπ(s,a)=π(a∣s)∑t=0∞γtp(St=s∣π), 这是一个用当前策略估计的状态和动作的联合分布。由于 Π \Pi Π 和 D \mathcal{D} D 的一一对应关系, 模仿 学习的问题等价于 ρ π ( s , a ) \rho_{\pi}(s, a) ρπ(s,a) 和 ρ π E ( s , a ) \rho_{\pi_{\mathrm{E}}}(s, a) ρπE(s,a) 之间的一个匹配问题。模仿学习的一个普遍目标是学习这 样一个策略:
π ^ = arg min π ∈ Π ψ ∗ ( ρ π − ρ π E ) − λ H ( π ) \hat{\pi}=\arg \min _{\pi \in \Pi} \psi^{*}\left(\rho_{\pi}-\rho_{\pi_{\mathrm{E}}}\right)-\lambda H(\pi) π^=argπ∈Πminψ∗(ρπ−ρπE)−λH(π)
其中 ψ ∗ \psi^{*} ψ∗ 是一个 ρ π \rho_{\pi} ρπ 和 ρ π E \rho_{\pi_{\mathrm{E}}} ρπE 之间的距离度量, 而 λ H ( π ) \lambda H(\pi) λH(π) 是一个有权衡因子 λ \lambda λ 的正则化项。举例来说, 这个正则化项可以定义为策略 π \pi π 的 γ \gamma γ-折扣因果熵 (Causal Entropy): H ( π ) = def E π [ − log π ( s , a ) ] H(\pi) \stackrel{\text { def }}{=} \mathbb{E}_{\pi}[-\log \pi(s, a)] H(π)= def Eπ[−logπ(s,a)] 。模 仿学习的整体目标就是增加从当前策略采样得到的 { ( s , a ) } \{(s, a)\} {(s,a)} 分布和示范数据中分布的相似度, 同 时考虑到策略参数上的一些限制。
2. 行为克隆
如果示范数据有相应标签的话(比如, 对于给定状态的一个好的动作可以被看作一个标签), 利用示范的模仿学习可以自然地被看作是一个监督学习任务。
在强化学习的情况下, 有标签的示范数据 D \mathcal{D} D 通常包含配对的状态和动作: D = { ( s i , a i ) ∣ i = 1 , ⋯ , N } \mathcal{D}=\left\{\left(s_{i}, a_{i}\right) \mid i=1, \cdots, N\right\} D={
(si,ai)∣i=1,⋯,N}, 其中 N N N 是示范数据集的大小而指标 i i i 表示 s i s_{i} si 和 a i a_{i} ai 是在同一个时间步的。在满足 MDP 假设的情况下(即最优动作只依赖 于当前状态), 状态-动作对的顺序在训练中可以被打乱。考虑强化学习设定下, 有一个以 θ \theta θ 参数 化和 s s s 为输入状态的初始策略 π θ \pi_{\theta} πθ, 其输出的确定性动作为 π θ ( s ) \pi_{\theta}(s) πθ(s), 我们有专家生成的示范数据集 D = { ( s i , a i ) ∣ i = 1 , ⋯ , N } \mathcal{D}=\left\{\left(s_{i}, a_{i}\right) \mid i=1, \cdots, N\right\} D={
(si,ai)∣i=1,⋯,N}, 可以用来训练这个策略, 其目标如下:
min θ ∑ ( s i , a i ) ∼ D ∥ a i − π θ ( s i ) ∥ 2 2 \min _{\theta} \sum_{\left(s_{i}, a_{i}\right) \sim \mathcal{D}}\left\|a_{i}-\pi_{\theta}\left(s_{i}\right)\right\|_{2}^{2} θmin(si,ai)∼D∑∥ai−πθ(si)∥22
一些随机性策略 π θ ( a ~ ∣ s ) \pi_{\theta}(\tilde{a} \mid s) πθ(a~∣s) 的具体形式, 比如高斯策略等, 可以用再参数化技巧来处理:
min θ ∑ a ~ i ∼ π ( ⋅ ∣ s i ) , ( s i , a i ) ∼ D ∥ a i − a ~ i ∥ 2 2 \min _{\theta} \sum_{\tilde{a}_{i} \sim \pi\left(\cdot \mid s_{i}\right),\left(s_{i}, a_{i}\right) \sim \mathcal{D}}\left\|a_{i}-\tilde{a}_{i}\right\|_{2}^{2} θmina~i∼π(⋅∣si),(si,ai)∼D∑∥ai−a~i∥22
这个使用监督学习直接模仿专家示范的方法称为行为克隆 (Behavioral Cloning, BC)。
2.1 行为克隆缺点
缺点1:观测非常有限
行为克隆虽然非常简单,但它的问题是如果你只收集专家的资料,观测会是非常有限的。也就是说,行为克隆对于专家数据中没有出现的情况根本不知道如何处理。
所以光是做行为克隆是不够的,只观察专家的行为是不够的,需要一个招数,这个招数叫作数据集聚合(dataset aggregation,DAgger)。
缺点2:机器会完全模仿专家的行为
行为克隆还有一个问题:机器会完全模仿专家的行为,不管专家的行为是否有道理。如果机器确实可以记住所有专家的行为,也许还好,假设机器的行为可以完全仿造专家行为,它就是跟专家一样得好,只是做一些多余的事。但问题是机器是一个网络,网络的容量是有限的。就算给网络训练数据,它在训练数据上得到的正确率往往也不是 100%,它有些事情是学不起来的。这个时候,什么该学,什么不该学就变得很重要。
缺点3:训练数据跟测试数据不匹配
尽管模仿学习可以对与示范数据集(用于训练策略)相似的样本有较好的表现,对它在训练过程中未见过的样本可能会有较差的泛化表现,因为示范数据集中只能包含有限的样本。
2.2 数据集聚合
数据集聚合( Dataset Aggregation, DAgger) 是一种更先进的基于 BC 方法的从示范中模仿学习的算法,它是一种无悔的( No-Regret)迭代算法。根据先前的训练迭代过程,它主动选择策略,在随后过程中有更大几率遇到示范样本,这使得 DAgger 成为一种更有用且高效的在线模仿学习方法, 可以应用于像强化学习中的连续预测问题。示范数据集 D \mathcal{D} D 会在每个时间步 i i i 连续地聚合新的数据集 D i \mathcal{D}_{i} Di, 这些数据集包含当前策略在整个模仿学习过程中遇到的状态 和相应的专家动作。因此, DAgger 同样有一个缺陷, 即它需要不断地与专家交互, 而这在现实应 用中通常是一种苛求。
DAgger 的伪代码如算法 8.29 8.29 8.29 所示, 其中 π ∗ \pi^{*} π∗ 是专家策略, 而 β i \beta_{i} βi 是在迭代 i i i 时对策略软更新(Soft-Update)的参数。
![【学习强化学习】十三、模仿学习介绍[通俗易懂]](https://img-blog.csdnimg.cn/03909f7146eb46e390b8331c9b8e770b.png)
2.3 Variational Dropout
一种缓解模仿学习中泛化问题的方法是预训练并使用 Variational Dropout ,来替代 BC 方法中完全克隆专家示范的行为。在这个方法中,使用示范数据集预训练(模仿学习)得到的权重被参数化为高斯分布,并用一个确定的方差阈值来进行高斯 Dropout,然后用来初始化强化学习策略。对于模仿学习的 Variational Dropout 方法可以被看作一种相比于在预训练的权重中加入噪声来说更高级的泛化方法,它可以减少对噪声大小选择的敏感性,因而是一种使用模仿学习来初始化强化学习的有用技巧。
3. 逆强化学习
3.1 概述
另一种主要的模仿学习方法基于逆向强化学习(Inverse Reinforcement Learning, IRL) )。IRL 可以归结为解决从观察到的最优行为中提取奖励函数(Reward Function)的问题, 这些最优行为也可以表示为专家策略 π E \pi_{\mathrm{E}} πE 。
基于 IRL 的方法反复地在两个过程中交替: 一个是使用示范来推断一个隐藏的奖励或代价(Cost)函数, 另一个是使用强化学习基 于推断的奖励函数来学习一个模仿策略。
IRL 选择奖励函数 R R R 来最优化策略, 并且使得任何脱离 于 π E \pi_{\mathrm{E}} πE 的单步选择尽可能产生更大损失。对于所有满足 ∣ R ( s ) ∣ ⩽ R max , ∀ s |R(s)| \leqslant R_{\max }, \forall s ∣R(s)∣⩽Rmax,∀s 的奖励函数 R R R, IRL 用 以下方式选择 R ∗ R^{*} R∗ :
R ∗ = arg max R ∑ s ∈ S ( Q π ( s , a E ) − max a ∈ A \ a E Q π ( s , a ) ) (1) \tag{1} R^{*}=\arg \max _{R} \sum_{s \in \mathcal{S}}\left(Q^{\pi}\left(s, a_{\mathrm{E}}\right)-\max _{a \in A \backslash a_{\mathrm{E}}} Q^{\pi}(s, a)\right) R∗=argRmaxs∈S∑(Qπ(s,aE)−a∈A\aEmaxQπ(s,a))(1)
其中 a E = π E ( s ) a_{\mathrm{E}}=\pi_{\mathrm{E}}(s) aE=πE(s) 或 a E ∼ π ( ⋅ ∣ s ) a_{\mathrm{E}} \sim \pi(\cdot \mid s) aE∼π(⋅∣s) 是专家(最优的)动作。
IRL 中一个典型的方法是使用最大因果熵 (Maximum Causal Entropy)正则化, 即最大熵(Maximum Entropy, MaxEnt)IRL 方法。MaxEnt IRL 可以表示为以下两个步骤:
IRL ( π E ) = arg max R E π E [ R ( s , a ) ] − RL ( R ) RL ( R ) = max π H ( π ( ⋅ ∣ s ) ) + E π [ R ( s , a ) ] (2) \tag{2} \begin{aligned} \operatorname{IRL}\left(\pi_{\mathrm{E}}\right) &=\arg \max _{R} \mathbb{E}_{\pi_{\mathrm{E}}}[R(s, a)]-\operatorname{RL}(R) \\ \operatorname{RL}(R) &=\max _{\pi} H(\pi(\cdot \mid s))+\mathbb{E}_{\pi}[R(s, a)] \end{aligned} IRL(πE)RL(R)=argRmaxEπE[R(s,a)]−RL(R)=πmaxH(π(⋅∣s))+Eπ[R(s,a)](2)
这构成了 R L ∘ IRL ( π E ) R L \circ \operatorname{IRL}\left(\pi_{\mathrm{E}}\right) RL∘IRL(πE) 策略学习架构。第一个式子 IRL ( π E ) \operatorname{IRL}\left(\pi_{\mathrm{E}}\right) IRL(πE) 学习一个奖励函数来最大化专家策略 和强化学习策略间的奖励值差异, 并且由于 Q Q Q 值是对奖励的估计, 它可以被式 (1) 替代。第二 个式子 RL ( R ) \operatorname{RL}(R) RL(R) 是熵正则化(Entropy-Regularized)正向强化学习, 而其奖励函数 R R R 是第一个式子 学到的。这里的熵 H ( π ( ⋅ ∣ s ) ) H(\pi(\cdot \mid s)) H(π(⋅∣s)) 是给定状态下的策略分布的熵函数。
关于随机变量 X X X 的分布 p ( X ) p(X) p(X) 的香农信息熵度量了这个概率分布的不确定性。
定义: 一个满足 p p p 分布的离散随机变量 X X X 的信息熵为
H p ( X ) = E p ( X ) [ − log p ( X ) ] = − ∑ X ∈ X p ( X ) log p ( X ) H_{p}(X)=\mathbb{E}_{p(X)}[-\log p(X)]=-\sum_{X \in \mathcal{X}} p(X) \log p(X) Hp(X)=Ep(X)[−logp(X)]=−X∈X∑p(X)logp(X)
对于强化学习中随机策略的情况, 表示动作分布的随机变量通常排列成一个与动作空间维数相同的矢量。常用的分布有对角高斯分布和类别分布, 导出它们的熵是很简单的。
代价函数 c ( s , a ) = − R ( s , a ) c(s, a)=-R(s, a) c(s,a)=−R(s,a) 也很常见, 它在强化学习的过程中被最小化:
R L ( c ) = arg min π − H ( π ) + E π [ c ( s , a ) ] \mathrm{RL}(c)=\arg \min _{\pi}-H(\pi)+\mathbb{E}_{\pi}[c(s, a)] RL(c)=argπmin−H(π)+Eπ[c(s,a)]
其中 H ( π ) = E π [ − log π ( a ∣ s ) ] H(\pi)=\mathbb{E}_{\pi}[-\log \pi(a \mid s)] H(π)=Eπ[−logπ(a∣s)] 是策略 π \pi π 的熵。代价函数 c ( s , a ) c(s, a) c(s,a) 常用作当前策略 π \pi π 的分布和示范 数据间相似度的度量。熵 H ( π ) H(\pi) H(π) 可以被视作实现最优解的唯一性的正则化项。
把上式代入 IRL 公式 (2) 中, 我们可以将 IRL 的目标表示成 max-min 的形式, 它企图在最 大化熵正则化奖励值的目标下学习一个状态 s s s 和动作 a a a 的代价函数 c ( s , a ) c(s, a) c(s,a), 以及进行策略 π \pi π 的 学习。
max c ( min π − E π [ − log π ( a ∣ s ) ] + E π [ c ( s , a ) ] ) − E π E [ c ( s , a ) ] \max _{c}\left(\min _{\pi}-\mathbb{E}_{\pi}[-\log \pi(a \mid s)]+\mathbb{E}_{\pi}[c(s, a)]\right)-\mathbb{E}_{\pi_{\mathrm{E}}}[c(s, a)] cmax(πmin−Eπ[−logπ(a∣s)]+Eπ[c(s,a)])−EπE[c(s,a)]
其中 π E \pi_{\mathrm{E}} πE 表示生成专家示范的专家策略, 而 π \pi π 是强化学习过程训练的策略。所学的代价函数将给 专家策略分配较高的熵而给其他策略较低的熵。
3.2 逆向强化学习方法的挑战
-
奖励函数的非唯一性或奖励歧义 (Reward Ambiguity): IRL 的函数搜索是病态的, 因为示范行为可以由多个奖励或代价函数导致。它始于奖励塑形 (Reward Shaping) 的概念, 这个概念描述了一类能保持最优策略的奖励函数变换。主要的结果是, 在以 下奖励变换之下:
r ^ ( s , a , s ′ ) = r ( s , a , s ′ ) + γ ϕ ( s ′ ) − ϕ ( s ) , \hat{r}\left(s, a, s^{\prime}\right)=r\left(s, a, s^{\prime}\right)+\gamma \phi\left(s^{\prime}\right)-\phi(s), r^(s,a,s′)=r(s,a,s′)+γϕ(s′)−ϕ(s),
最优策略对任何函数 ϕ : S → R \phi: \mathcal{S} \rightarrow \mathbb{R} ϕ:S→R 保持不变。只用示范数据通过 IRL 方法学到的奖励函数, 是不能消除上面一类变换下奖励函数之间分歧的。
因此, 我们需要对奖励或者策略施加限制来保证示范行为最优解的唯一性。举例来说, 奖 励函数通常被定义为一个状态特征的线性组合 或凸的组合 (Convex Combination)。所学的策略也假设其满足最大熵 或者最大因果熵 规则。然而, 这些显式的限制对所提出方法 的通用性有一定潜在限制。 -
较大的计算代价: IRL 可以在一般强化学习过程中通过示范和交互学到一个更好的策略。然 而, 在推断出的奖励函数下, 使用强化学习来优化策略要求智能体与它的环境交互, 这从 时间和安全性的角度考虑都可能是要付出较大代价的。此外, IRL 的步骤主要要求智能体 在迭代优化奖励函数的内循环中解决一个 MDP 问题,而这从计算的角度也可能是有极大消耗的。然而,近来有一些方法被提出,以减轻这个要求。其中一种方法称为生成对抗模仿学习
4. 第三人称视角模仿学习
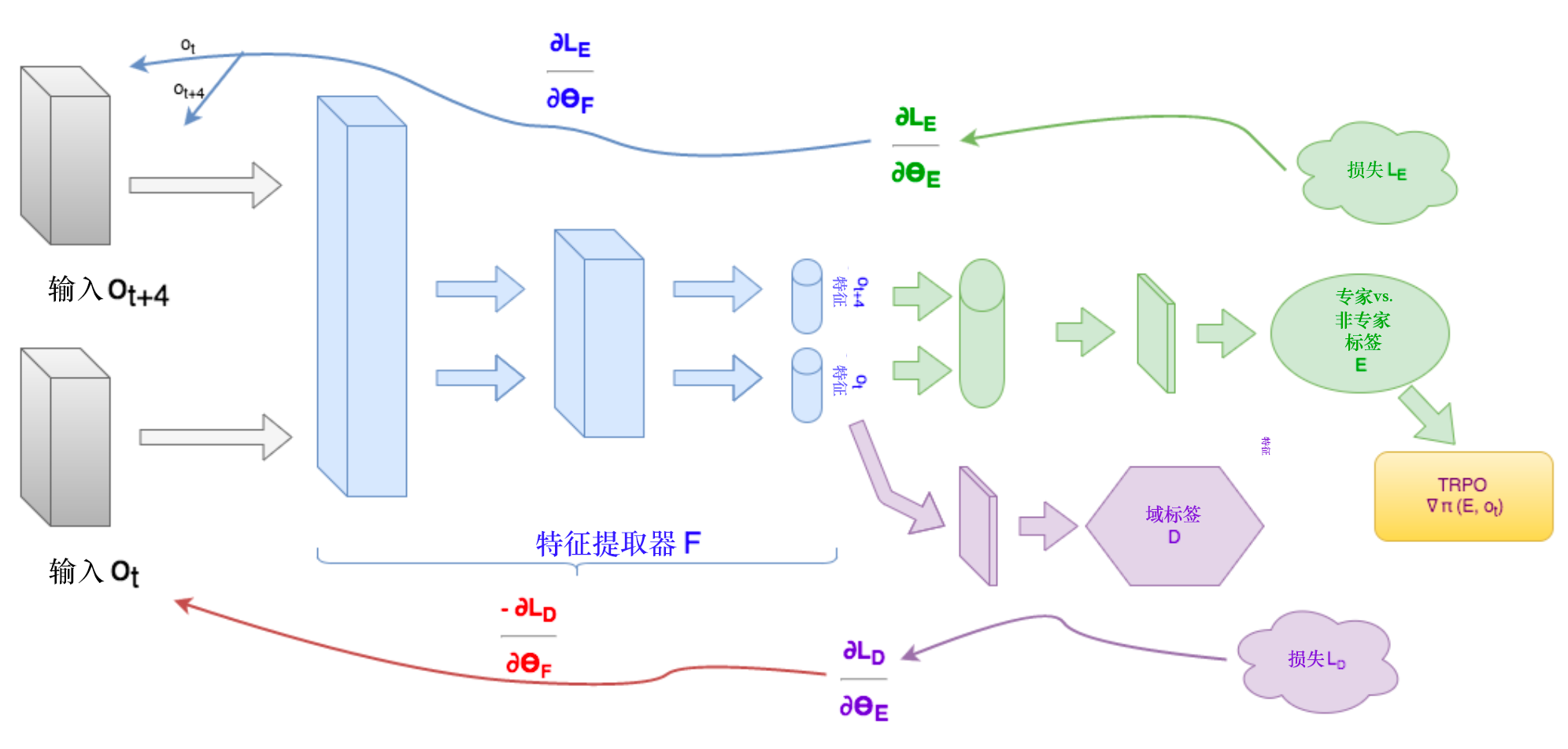
其实还有很多相关的研究,如下图所示,举例来说,你在教机械手臂的时候,要注意就是也许机器看到的视野跟人看到的视野是不太一样的。在刚才那个例子里面,人跟机器的动作是一样的。但是在未来的世界里面,也许机器是看着人的行为学的。刚才是人拉着,假设你要让机器学会打高尔夫球,有没有可能机器就是看着人打高尔夫球,它自己就学会打高尔夫球了呢?这个时候,要注意的事情是机器的视野跟它真正去采取这个行为的时候的视野是不一样的。机器必须了解到当它是第三人的视角的时候,看到另外一个人在打高尔夫球,跟它实际上自己去打高尔夫球的时候,看到的视野显然是不一样的。但它怎么把它是第三人称视角所观察到的经验把它泛化到它是第一人称视角的时候所采取的行为,这就需要用到第三人称视角模仿学习(third person imitation learning)的技术。
这个怎么做呢?它的技术其实也是不只是用到模仿学习,它用到了领域对抗训练(domain-adversarial Training)。这也是一个 GAN 的技术。如下图 所示,我们希望有一个提取器,有两个不同领域(domain)的图像,通过特征提取器以后,没有办法分辨出它来自哪一个领域。其实第一人称视角和第三人称视角,模仿学习用的技术其实也是一样的,希望学习一个特征提取器,机器在第三人称的时候跟它在第一人称的时候看到的视野其实是一样的,就是把最重要的东西抽出来就好了。
5. 练习
5.1 keywords
Imitation learning: 其讨论我们没有reward或者无法定义reward但是有与environment进行交互时怎么进行agent的学习。这与我们平时处理的问题中的情况有些类似,因为通常我们无法从环境中得到明确的reward。Imitation learning 又被称为 learning from demonstration (示范学习) ,apprenticeship learning (学徒学习),learning by watching (观察学习)等。Behavior Cloning: 类似于ML中的监督学习,通过收集expert的state与action的对应信息,训练我们的network(actor)。在使用时input state时,得到对应的outpur action。Dataset Aggregation: 用来应对在Behavior Cloning中expert提供不到的data,其希望收集expert在各种极端state下expert的action。Inverse Reinforcement learning(IRL): Inverse Reinforcement Learning 是先找出 reward function,再去用 Reinforcement Learning 找出 optimal actor。这么做是因为我们没有环境中reward,但是我们有expert 的demonstration,使用IRL,我们可以推断expert 是因为什么样的 reward function 才会采取这些action。有了reward function 以后,接下来,就可以套用一般的 reinforcement learning 的方法去找出 optimal actor。Third Person Imitation Learning: 一种把第三人称视角所观察到的经验 generalize 到第一人称视角的经验的技术。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191810.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
