大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Saga模式是一种分布式异步事务,一种最终一致性事务,是一种柔性事务。
Saga事务模型又叫做长时间运行的事务(Long-running-transaction), 它是由普林斯顿大学的H.Garcia-Molina等人提出,它描述的是另外一种在没有两阶段提交的的情况下解决分布式系统中复杂的业务事务问题。
Saga的组成
每个Saga由一系列sub-transaction Ti 组成
每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果
可以看到,和TCC相比,Saga没有“预留”动作,它的Ti就是直接提交到库。
Saga的执行顺序有两种:
T1, T2, T3, …, Tn
T1, T2, …, Tj, Cj,…, C2, C1,其中0 < j < n
Saga定义了两种恢复策略:
backward recovery,向后恢复,即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。
forward recovery,向前恢复,适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, …, Tj(失败), Tj(重试),…, Tn,其中j是发生错误的sub-transaction。该情况下不需要Ci。
和TCC对比
Saga相比TCC的缺点是缺少预留动作,导致补偿动作的实现比较麻烦:Ti就是commit,比如一个业务是发送邮件,在TCC模式下,先保存草稿(Try)再发送(Confirm),撤销的话直接删除草稿(Cancel)就行了。而Saga则就直接发送邮件了(Ti),如果要撤销则得再发送一份邮件说明撤销(Ci),实现起来有一些麻烦。
如果把上面的发邮件的例子换成:A服务在完成Ti后立即发送Event到ESB(企业服务总线,可以认为是一个消息中间件),下游服务监听到这个Event做自己的一些工作然后再发送Event到ESB,如果A服务执行补偿动作Ci,那么整个补偿动作的层级就很深。
不过没有预留动作也可以认为是优点:
有些业务很简单,套用TCC需要修改原来的业务逻辑,而Saga只需要添加一个补偿动作就行了。
TCC最少通信次数为2n,而Saga为n(n=sub-transaction的数量)。
有些第三方服务没有Try接口,TCC模式实现起来就比较棘手了,而Saga则很简单。
没有预留动作就意味着不必担心资源释放的问题,异常处理起来也更简单(请对比Saga的恢复策略和TCC的异常处理)。
实现Saga的注意事项
对于服务来说,实现Saga有以下这些要求:
Ti和Ci是幂等的。
Ci必须是能够成功的,如果无法成功则需要人工介入。
Ti – Ci和Ci – Ti的执行结果必须是一样的:sub-transaction被撤销了。
第一点要求Ti和Ci是幂等的,举个例子,假设在执行Ti的时候超时了,此时我们是不知道执行结果的,如果采用forward recovery策略就会再次发送Ti,那么就有可能出现Ti被执行了两次,所以要求Ti幂等。如果采用backward recovery策略就会发送Ci,而如果Ci也超时了,就会尝试再次发送Ci,那么就有可能出现Ci被执行两次,所以要求Ci幂等。
第二点要求Ci必须能够成功,这个很好理解,因为,如果Ci不能执行成功就意味着整个Saga无法完全撤销,这个是不允许的。但总会出现一些特殊情况比如Ci的代码有bug、服务长时间崩溃等,这个时候就需要人工介入了。
第三点乍看起来比较奇怪,举例说明,还是考虑Ti执行超时的场景,我们采用了backward recovery,发送一个Ci,那么就会有三种情况:
Ti的请求丢失了,服务之前没有、之后也不会执行Ti
Ti在Ci之前执行
Ci在Ti之前执行
对于第1种情况,容易处理。对于第2、3种情况,则要求Ti和Ci是可交换的(commutative),并且其最终结果都是sub-transaction被撤销。
举例
电子商务示例,用户下单涉及到订单,支付,库存,发货等服务。非常高层次级的Saga设计实现如下所示:
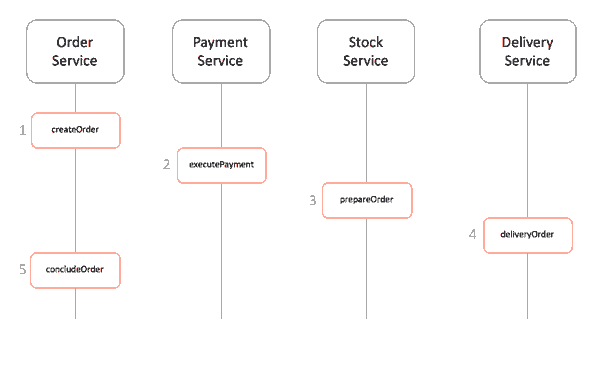

实现方式一:事件/编排Choreography
在Events/Choreography方法中,第一个服务执行一个事务,然后发布一个事件。该事件被一个或多个服务进行监听,这些服务再执行本地事务并发布(或不发布)新的事件。当最后一个服务执行本地事务并且不发布任何事件时,意味着分布式事务结束,或者它发布的事件没有被任何Saga参与者听到都意味着事务结束。
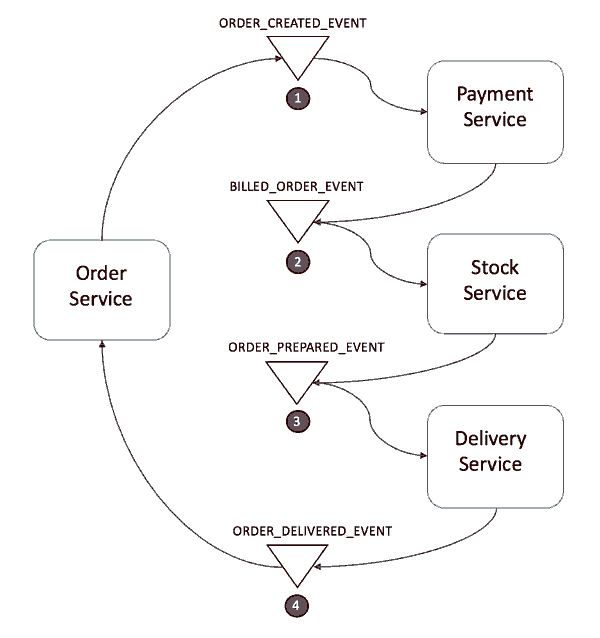

步骤如下:
1.订单服务保存新订单,将状态设置为pengding挂起状态,并发布名为ORDER_CREATED_EVENT的事件。
2.支付服务监听ORDER_CREATED_EVENT,并公布事件BILLED_ORDER_EVENT。
3.库存服务监听BILLED_ORDER_EVENT,更新库存,并发布ORDER_PREPARED_EVENT。
4.货运服务监听ORDER_PREPARED_EVENT,然后交付产品。最后,它发布ORDER_DELIVERED_EVENT
5.最后,订单服务侦听ORDER_DELIVERED_EVENT并设置订单的状态为concluded完成。
在上面的情况下,如果需要跟踪订单的状态,订单服务可以简单地监听所有事件并更新其状态。 在这个案例中,除了订单服务以外的其他服务都是订单服务的子服务,也就是说,为完成一个订单服务,需要经过这些步骤,订单服务与这些服务是包含与被包含关系,因此,订单服务在业务上天然是一个协调器。回滚分布式事务并不是免费的。通常情况下,您必须实施额外操作才能弥补以前所做的工作。
假设库存服务在事务过程中失败了。让我们看看回滚是什么样子的:
1.库存服务产生PRODUCT_OUT_OF_STOCK_EVENT ;
2.订购服务和支付服务会监听到上面库存服务的这一事件:
1. 支付服务会退款给客户。
2. 订单服务将订单状态设置为失败。
请注意,为每个事务定义一个公共共享ID非常重要,因此每当您抛出一个事件时,所有侦听器都可以立即知道它引用的是哪个事务。
saga事件/编排设计的优点和缺点
事件/编排是实现Saga模式的自然方式; 它很简单,容易理解,不需要太多的努力来构建,所有参与者都是松散耦合的,因为他们彼此之间没有直接的耦合。如果您的事务涉及2至4个步骤,则可能是非常合适的。
但是,如果您在事务中不断添加额外步骤,则此方法可能会很快变得混乱,因为很难跟踪哪些服务监听哪些事件。此外,它还可能在服务之间添加循环依赖,因为它们必须订阅彼此的事件。
最后,使用这种设计来实现测试将会非常棘手。为了模拟交易行为,您应该运行所有服务。
实现方式二:命令/协调orchestrator
这里我们定义了一项新服务,全权负责告诉每个参与者该做什么以及什么时候该做什么。saga协调器orchestrator以命令/回复的方式与每项服务进行通信,告诉他们应该执行哪些操作。
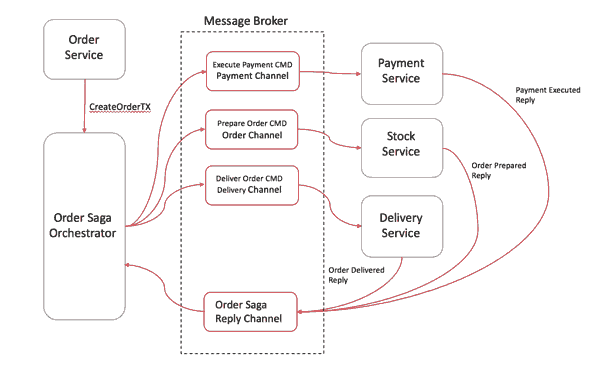
1.订单服务保存pending状态,并要求订单Saga协调器(简称OSO)开始启动订单事务。
2.OSO向收款服务发送执行收款命令,收款服务回复Payment Executed消息
3.OSO向库存服务发送准备订单命令,库存服务将回复OrderPrepared消息
4.OSO向货运服务发送订单发货命令,货运服务将回复Order Delivered消息。
OSO订单Saga协调器必须事先知道执行“创建订单”事务所需的流程(通过读取BPM业务流程XML配置获得)。如果有任何失败,它还负责通过向每个参与者发送命令来撤销之前的操作来协调分布式的回滚。当你有一个中央协调器协调一切时,回滚要容易得多,因为协调器默认是执行正向流程,回滚时只要执行反向流程即可。类似saga协调器的标准模式是状态机,其中每个转换对应于命令或消息。状态机是构建定义明确的行为的极好模式,因为它们易于实现,特别适用于测试。
命令/协调器设计的优点和缺点
基于协调器的Saga有很多好处:
1.避免服务之间的循环依赖关系,因为saga协调器会调用saga参与者,但参与者不会调用协调器
2.集中分布式事务的编排
3.只需要执行命令/回复(其实回复消息也是一种事件消息),降低参与者的复杂性。
4.更容易实施和测试
5. 在添加新步骤时,事务复杂性保持线性,回滚更容易管理
6.如果在第一笔交易还没有执行完,想改变有第二笔事务的目标对象,则可以轻松地将其暂停在协调器上,直到第一笔交易结束。
缺点:
1.有在协调器中集中太多逻辑的风险,并最终导致智能协调器会告诉愚蠢的服务该做什么的架构,这不符合Martinfowler定义微服务应该是聪明的服务+哑巴或愚蠢的管道。
2.是它会稍微增加基础设施的复杂性,因为您需要管理额外的服务。同时增加单点风险,协调器一旦出问题,全局影响。
注意点
1.为每个事务创建一个唯一的ID
为每项事务设置一个唯一的标识符是追踪后续处理步骤的常用技术,但它也有助于参与者以标准方式向对方请求数据。例如,通过使用事务ID,送货服务可以要求库存服务在哪里提取产品,如果订单已付款,请与支付服务进行双重检查。
2.在命令Command中添加回复地址
可以考虑像在消息中发送回复地址,而不是让参与者回复固定地址,这样您可以让参与者回复多个协调人。
3.幂等操作
如果您使用队列进行服务之间的通信(如SQS,Kafka,RabbitMQ等),我个人建议您将您的操作设置为幂等。这些队列中的大多数可能会传递相同的消息两次。(Kafak 0.10以后已经支持正好一次消息传递,消除了重复消息传递)
4.它也可能会增加服务的容错能力。通常,客户端中的错误可能会触发/重放不需要的消息,并与数据库混淆。
5.避免同步通信
随着事务的进行,不要忘记在消息中添加每个要执行的操作所需的所有数据。整个目标是避免服务之间再进行同步调用,以请求更多的数据。它将使您的服务能够在其他服务脱机时执行其本地事务。很多人错误地使用消息系统,先使用消息系统发送一个提醒通知,然后再让消息接受者通过服务接口过来取数据,这等同于没有使用消息系统,因为同步操作会堵塞,而消息系统是非堵塞的,大数据读取时同步经常会堵塞,这是无法通过事前评估数据量大小来主观以为这么小数据量不会造成堵塞的。
参考:
https://www.upyun.com/opentalk/310.html
https://segmentfault.com/a/1190000013889443
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191787.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...