大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
简介
模仿学习是强化学习的好伙伴,使用模仿学习可以让智能体在比强化学习短得多的时间内得到与人类操作相近的结果,但是这种做法并不能超越人类,而强化学习能够得到远超人类的智能体,但训练时间往往非常漫长。因此我们希望让智能体并不是从零开始学,我们给予智能体人类的演示,在学习人类演示的基础上,再进行强化学习。这样往往能大大减少强化学习的训练时间。在金字塔环境中,只需要四轮人类的游戏数据,就能使训练步数减少四分之三以上。因此,模仿学习和强化学习往往是一起使用的。好处是既能大大加快训练速度,又能得到超越人类的超高水准。
模仿学习是一种Supervised Learning(监督学习)的方法,也就是根据我们给定人类演示中的状态和对应的动作,就能训练智能体的策略网络去逼近我们的这个演示。光用模仿学习的缺点是,人类没有办法给出环境中所有的状态对应的做法,往往人类的演示中只包含了所有状态中的一小部分的应对方式,因此只进行模仿学习后,智能体没有办法应对人类演示数据中没有遇到过的情况,因此才需要用强化学习进行弥补。
ML-Agents提供了关于模仿学习的两种算法,一种是Generative Adversarial Imitation Learning(生成对抗模仿学习),简称GAIL,还有一种是Behavior Cloning(行为克隆),简称BC,在大多数情况下,两者可以一起使用。
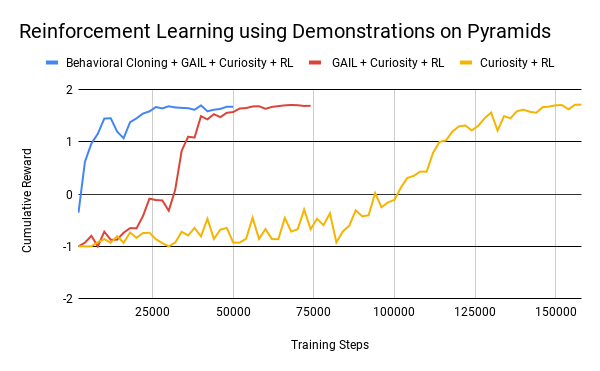
如下图,在金字塔环境中,同时使用生成对抗模仿学习,行为克隆,好奇心奖励,普通强化学习四种方法的情况下,得到相同结果的时长大大减少。

下面来讲解一下对应的算法。
注意:这里需要对ML-Agents有一定的了解,详情请见:Unity强化学习之ML-Agents的使用、ML-Agents命令及配置大全。
Behavioral Cloning
Behavior Cloning(行为克隆),简称BC。它的思想较为简单,就是把智能体的策略网络训练得和人类的演示数据的行为模式越接近越好,也就是说,输入相同的状态s,应当有相近的输出a。这单纯就是一个Supervised Learning,每一个状态相当于输入的特征,专家输出的动作相当于Label(标签),我们只需要让模型的输出接近我们的Label即可。
在这里,BC通常用作预训练,因此我们需要先进行BC,再进行强化学习。
现在我们看看配置文件中的参数是怎么设定的。
behavioral_cloning:
demo_path: Project/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
steps: 50000
strength: 1.0
samples_per_update: 0
在使用BC之前,应当确保自己已经录制了演示文件(后面会讲怎么录制演示),其中的参数含义如下:
demo_path:演示文件的路径。
strength:默认为1。表示模仿学习相对于PPO算法的学习率,表示了BC改变策略的强度。
steps:通常BC应当在模仿学习进行到智能体能够获取奖励时停止,从而正式进入强化学习。当运行的步数大于steps的时候,模仿学习的学习率将为0,也就是不再起作用。如果设为0,那么将会在整个过程中持续进行BC。
batch_size:默认为强化学习使用的batch_size。表示一次性使用多少条数据进行梯度递减。推荐:512-5120
num_epoch:默认为PPO设定。梯度下降期间需要从经验池中抽取多少次。推荐:512-5120
samples_per_update:默认为0。每次更新期间使用的最大样本数,0表示每次拿所有演示数据进行训练。如果演示数据非常大,应当降低此值防止过拟合。
Generative Adversarial Imitation Learning
Generative Adversarial Imitation Learning(生成对抗模仿学习),简称GAIL,这是受到了生成对抗网络(简称GAN)的启发,对应有一个生成模型和一个判别模型 ,生成模型的目标是生成与真人操作相类似的数据欺骗判别模型,判别模型的任务是尽可能区分哪些是真实数据,哪些是生成的假数据,即是一个输出reward的网络,我们要尽量保持真实的数据拥有比生成数据更高的累计reward。在彼此对抗中,两个网络能成长为能够生成超接近于人类数据的生成模型,以及能够判别非常解决人类数据的生成数据的判别模型。
GAIL属于Inverse RL的范畴,即逆强化学习,原本的强化学习是环境给定Reward和下一个状态 s t + 1 s_{t+1} st+1,我们用来学习最优的策略。现在,我们需要自己学习出一个输出Reward网络,即给定 s t s_t st和 a t a_t at的情况下,输出Reward。然后我们在通过这个自己训练出来的Reward函数来训练我们的策略模型。这种做法的好处是策略不是直接监督学习的,因此使得学习到的策略更加通用。
策略模型可以通过各种的算法来训练,这部分属于强化学习的领域,论文中使用了TRPO算法。
GAIL相当于另外的一个内在奖励,是可以和强化学习的外部奖励加在一起进行训练的。专家奖励设得越高,智能体在环境中就越趋向于模仿专家的行为。合理设置其奖励上限,智能体就会在一定程度上模仿专家行为的同时,更多地去探索环境,寻找更好的策略,金字塔案例中设为了环境奖励的0.01。

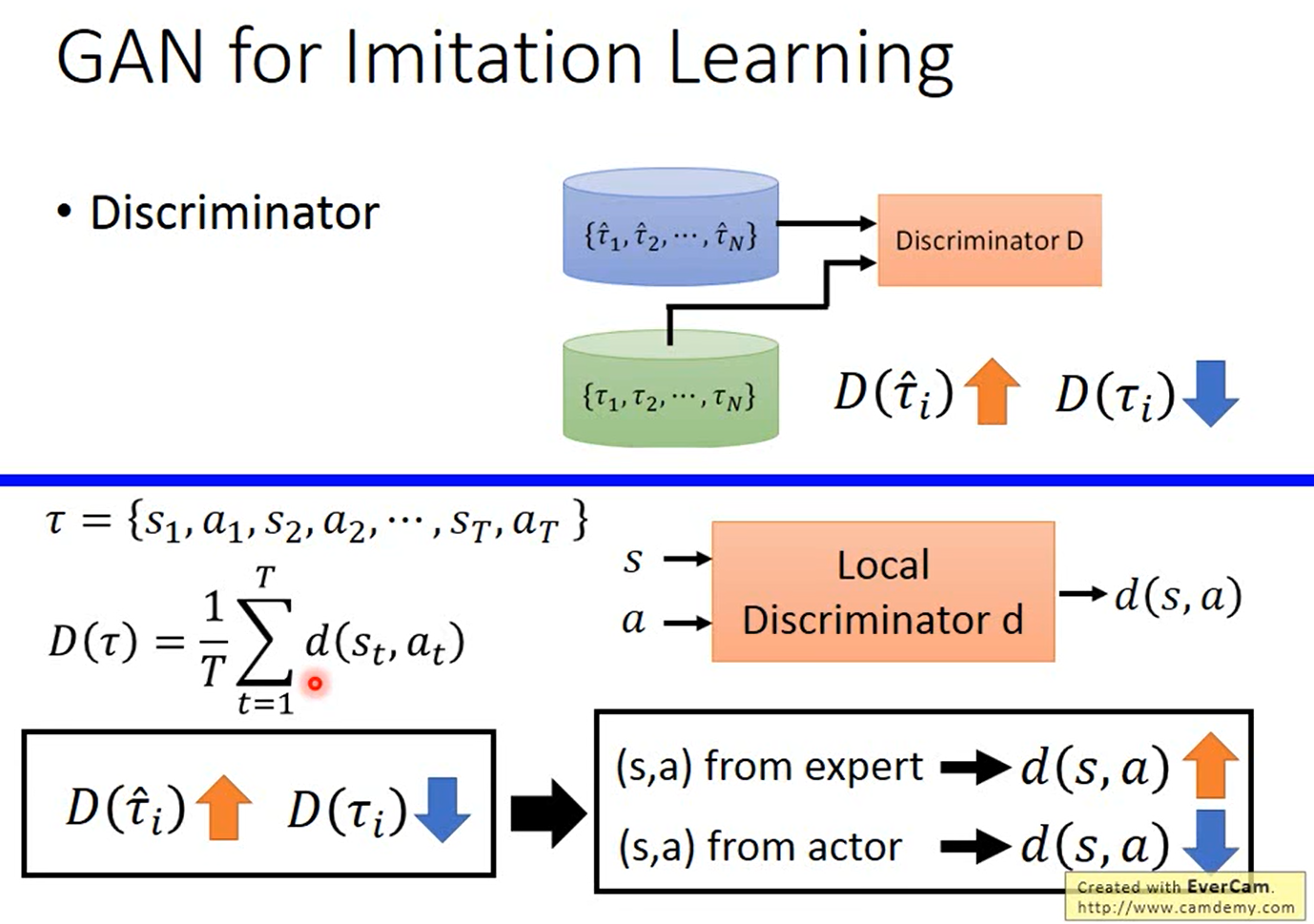
论文原文:
Generative Adversarial Imitation Learning
参考资料:https://proceedings.neurips.cc/paper/2016/file/cc7e2b878868cbae992d1fb743995d8f-Paper.pdf
【强化学习】GAIL生成对抗模仿学习详解《Generative adversarial imitation learning》
现在我们看看配置文件中的参数是怎么设定的。
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
gail:
gamma: 0.99
strength: 0.01
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
可以看到GAIL是属于额外的奖励信号的一部分。在使用GAIL之前,应当确保自己已经录制了演示文件(后面会讲怎么录制演示),其中的参数含义如下:
strength:原始的GAIL奖励乘以strength就是实际的GAIL奖励,如果演示数据并不是非常完美应当设得较低(0.01 – 0.1),使得智能体能够专注于外部奖励而不是完全复制演示数据。推荐范围:0.01 – 1
gamma:GAIL奖励的折扣因子。
demo_path:演示文件的路径。
learning_rate:更新判别器的学习率,如果GAIL训练不稳定,应当减少。
network_settings:判别器的网络规范。
normalize:是否对输入进行标准化。
hidden_units:隐藏层中节点的个数。推荐范围:32 – 512
num_layers:神经网络中隐藏层的层数。推荐范围:1 – 3
vis_encode_type:对应于可视化观测进行编码的编码器类型,选项包含:simple(默认):两个卷积层组成的简单编码器,nature_cnn:三个卷积层组成,详见https://www.nature.com/articles/nature14236。resnet:由三个堆叠的层构成,是比其他两个更大的网络,详见https://arxiv.org/abs/1802.01561。
use_actions:判别器是获取状态和动作进行输入,还是只获取状态作为输入,如果希望智能体模仿演示中的动作,应当设为true,如果只是希望能够到达相同的状态但保留动作的多样性,应当设为false。设为false会比较稳定,但学习较慢。
use_vail:对判别器的性能进行额外的约束,迫使判别器学习一种更一般的表示,降低了其在辨别方面的过拟合,使学习更加稳定,但也会增加训练时间,如果模仿学习不成功,可以启用这个功能。详情参见论文:https://arxiv.org/abs/1810.00821,我也对此做过相应的讲解:论文阅读:Variational Discriminator Bottleneck
录制演示
首先需要将Demonstration Recorder这个组件添加到智能体身上:

其中参数的含义如下:
Record表示是否开启录制,Num Steps To Record表示录制到多少步自动停止(如果设为0那么只有自己点击停止运行才能停止)。Demostration Name表示生成的文件名是什么,Demostration Directory表示生成文件放在什么目录。
点击开始游戏之前,如果自己手动操作,那就不要给智能体挂上策略模型,然后在智能体代码中添加上Heuristic方法用以控制模型的输出:
public override void Heuristic(in ActionBuffers actionsOut)
{
var discreteActionsOut = actionsOut.DiscreteActions;
if (Input.GetKey(KeyCode.D))
{
discreteActionsOut[0] = 3;
}
else if (Input.GetKey(KeyCode.W))
{
discreteActionsOut[0] = 1;
}
else if (Input.GetKey(KeyCode.A))
{
discreteActionsOut[0] = 4;
}
else if (Input.GetKey(KeyCode.S))
{
discreteActionsOut[0] = 2;
}
}
同时我们也可以自己写一个硬编码的控制智能体的脚本,或者之前有训练较好的策略网络拖进智能体中,我们就可以让智能体自己进行操作。
演示完成后,ML-Agents会在对应的位置生成一个.demo文件,在Unity中会显示如下数据:

其中显示出录制的输入,输出,录制了多少步数,平均奖励是多少,运行了多少个episode等数据。
实战分析
推箱子案例
相应环境说明参见之前的文章:ML-Agents案例之推箱子游戏
之前的文章采用了强化学习算法PPO和SAC以及MA-POCA来训练智能体,训练步数超过几十万个step达到比较满意的效果,现在我们采用强化学习 + BC + GAIL来训练智能体。首先我们需要录制好对应的演示文件,并修改配置文件如下:
behaviors:
PushBlock:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
gail:
gamma: 0.99
strength: 0.01
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project-new/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
keep_checkpoints: 5
max_steps: 100000
time_horizon: 64
summary_freq: 2500
behavioral_cloning:
demo_path: Project-new/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPushBlock.demo
steps: 50000
strength: 1.0
samples_per_update: 0
可以看到相比于平常的PPO强化学习算法,配置文件中加入了behavioral_cloning和gail两个部分,配置了对应的参数,现在开启训练,训练效果如下:
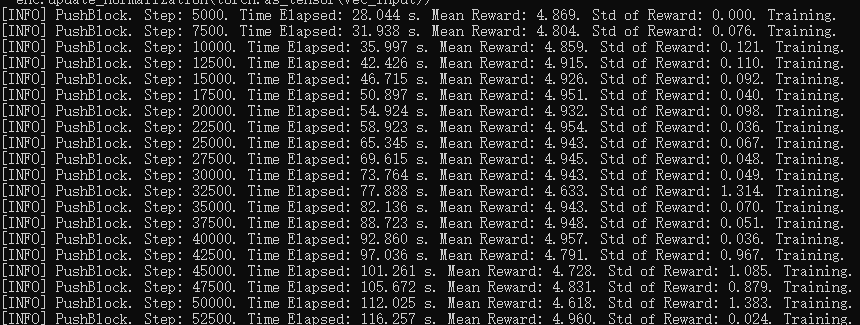
可以看到仅仅经过5000个step,就能达到满意的效果,训练时间是直接使用强化学习的几十分之一。
演示操作得越完美,那么训练时间就能缩短越多。
爬虫案例
相应环境说明参见之前的文章:ML-Agents案例之Crawler
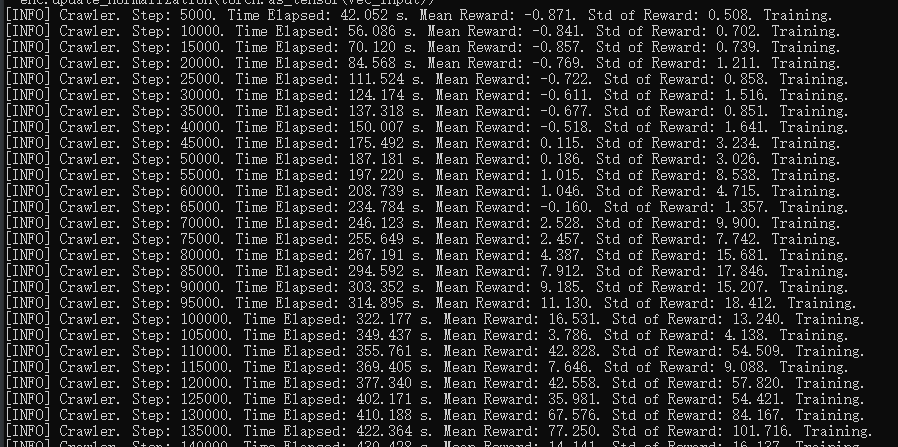
这里甚至不用采用外部奖励,只用了GAIL + BC就能进行训练,训练时长甚至比纯强化学习更短。
behaviors:
Crawler:
trainer_type: ppo
hyperparameters:
batch_size: 2024
buffer_size: 20240
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
gail:
gamma: 0.99
strength: 1.0
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project/Assets/ML-Agents/Examples/Crawler/Demos/ExpertCrawler.demo
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 1000
summary_freq: 5000
behavioral_cloning:
demo_path: Project/Assets/ML-Agents/Examples/Crawler/Demos/ExpertCrawler.demo
steps: 50000
strength: 0.5
samples_per_update: 0
金字塔案例
相应环境说明参见之前的文章:ML-Agents案例之金字塔
配置文件如下:
behaviors:
Pyramids:
trainer_type: ppo
time_horizon: 128
max_steps: 1.0e7
hyperparameters:
batch_size: 128
beta: 0.01
buffer_size: 2048
epsilon: 0.2
lambd: 0.95
learning_rate: 0.0003
num_epoch: 3
network_settings:
num_layers: 2
normalize: false
hidden_units: 512
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
curiosity:
strength: 0.02
gamma: 0.99
network_settings:
hidden_units: 256
gail:
strength: 0.01
gamma: 0.99
demo_path: Project/Assets/ML-Agents/Examples/Pyramids/Demos/ExpertPyramid.demo
behavioral_cloning:
demo_path: Project/Assets/ML-Agents/Examples/Pyramids/Demos/ExpertPyramid.demo
strength: 0.5
steps: 150000
可以看到,这里采用了 RL + Curosity + GAIL + BC,四大元素齐聚,每一样都为我们训练提供了很大的帮助,效果如下:
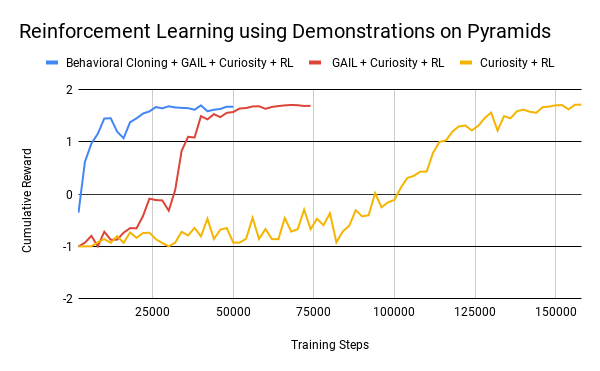
在最初我们训练成功时,需要至少150000个step才能勉强达到效果,加入GAIL后,只需要50000个step,再加入BC,更是缩短到了25000个step,可见模仿学习和强化学习的能够产生奇妙的反应,达到1 + 1大于2的效果。
在训练智能体解决相对困难的任务时,我们往往就需要用这种模仿学习+强化学习的方法解决问题。
看图配对案例
相应环境说明参见之前的文章:[ML-Agents案例之看图配对](https://blog.csdn.net/tianjuewudi/article/details/121692539)
配置文件如下:
behaviors:
Hallway:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 1024
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory:
sequence_length: 64
memory_size: 256
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
gail:
gamma: 0.99
strength: 0.01
learning_rate: 0.0003
use_actions: false
use_vail: false
demo_path: Project/Assets/ML-Agents/Examples/Hallway/Demos/ExpertHallway.demo
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 64
summary_freq: 10000
可以看到,我们这里只增加了一个GAIL,但对训练速度的提升仍然十分显著,在这种需要记忆的环境下,仅仅十万个step就使Loss迅速减少:
总结
Behavioral Cloning和Generative Adversarial Imitation Learning相当于强化学习上的两个挂件,能够十分显著得增强强化学习的效果。其中Behavioral Cloning相当于一个预训练,只在前期使用;而Generative Adversarial Imitation Learning则可以贯穿整个强化学习的始终,相当于又增加了一个内部奖励,和专家演示的策略越接近,这个奖励越大,但这个奖励不能盖过外部奖励,以便智能体能探索更多的最优解。
相关文章:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191760.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
