大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
从之前的讨论看,都是有奖励的。哪怕是上一章的稀疏奖励,其实也有奖励。==假如任何奖励都没有怎么办?==本章介绍的就是这种情况的解决办法。
什么时候任何奖励都没有。其实还挺常见的,以聊天机器人为例,聊的好不好很难定义奖励。解决这种情况的方法就是模仿学习
模仿学习(imitation learning),有时也叫示范学习或者学徒学习。指有一些专家的示范,通过模仿这些专家来达到目的。专家的示范含义很广,比如在自动驾驶中,一个司机的行为就可以被称为专家的示范。
模仿学习中主要有两个方法:行为克隆和逆强化学习
1.行为克隆
其实行为克隆和监督学习一样的。它的思路就是完全复制专家的行为(克隆),专家怎么干它就怎么干。
这种方法大多数情况下没有问题,但行为克隆会有问题。
问题一:特殊情况
但专家的观测也是有限的。举个例子就是司机不会在能拐弯的时候去撞墙,所以对于撞墙下面的状态就没有示范了。但有的时候机器学习的时候会随机进入这种状态,无法处理。所以只观察专家行为是不够的,需要招数处理这种特殊情况。这个招数就叫做数据集聚合。
希望收集更多样化的数据,并且包含最极端的情况。数据集聚合的思想很野蛮,就是让专家也处于这种极端的情况(我感觉说了和没说一样),有了这样的数据就能够进行处理了。
问题二:会跑偏
除了上面的问题,行为克隆还有一个问题就是可能学不到点子上。比如专家有多种形式的知识,本来想学习知识1,但实际学了知识2,而且内存空间有限,学完了知识2满了。这就彻底跑偏了。
问题三:有误差
在学习过程中,很难和专家一摸一样。但RL中是前面状态会影响到后面状态的。监督学习中独立分布没有问题,但这个里面可能就会越走越偏。
所以行为克隆并不能完全解决模仿学习的事情,就需要下面的方法
2.逆强化学习
之前介绍过需要模仿学习的原因就是因为获得不了奖励。而常规RL是从奖励函数出发去推导动作。逆强化学习的思路是先推导出一个奖励函数,再接着常规RL学习。
最大的问题就是:怎么利用专家行为推导奖励函数呢?
首先专家和环境互动,会得到很多轨迹。从这些轨迹中推导奖励函数。要定一个奖励函数,这个奖励函数的原则就是专家得到的分数比演员分高。然后再修改奖励函数,最后使专家和智能体的得分一致,这个时候就认为是最佳的奖励函数。一个直观的问题是:怎么让专家得到奖励大过演员呢?
实现手段是把奖励函数作为一个神经网络。训练的时候希望专家的输出的奖励越大越好,希望智能体输出的奖励越小越好。逆强化学习的框架如下:
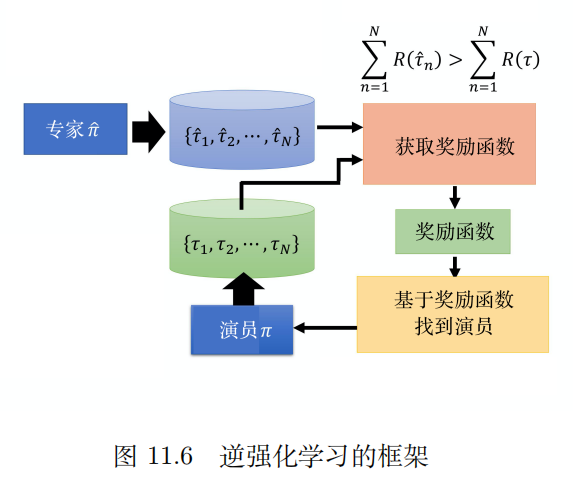

还有一种第三人称视角模仿学习,在这里简单提一下。之前介绍的都是第一人称,机器人是参与主体。我们希望它在旁边看人类做就能自己学会做,这对它来说是第三人称。把第三人称变成第一人称然后再学习的技术就叫做第三人称视角模仿学习。它的框架图如下: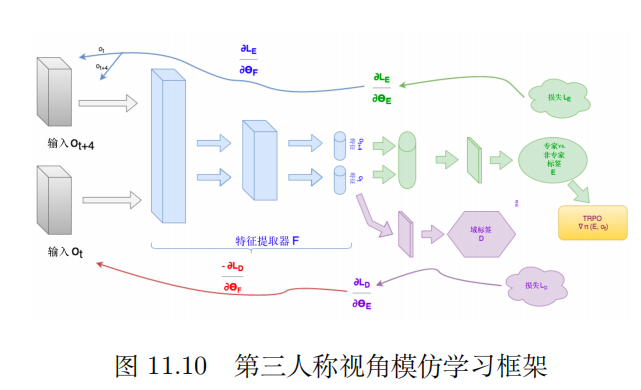
模仿学习over!
课后题如下:
因作者水平有限,如有错误之处,请在下方评论区指正,谢谢!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191716.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
