大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
本篇文章是基于台大李宏毅老师的课程写的,如有疏漏,请看原课程。https://www.youtube.com/watch?v=rl_ozvqQUU8
 1. 什么是模仿学习?
1. 什么是模仿学习?
模仿学习(Imitation Learning)也被称为基于演示的学习(Learning By Demonstration)或者学徒学习(Apprenticeship Learning)。
机器是可以与环境进行交互的,但是大部分情况下,机器却不能从这个过程中显示的获得奖励(例外是类似于马里奥之类的游戏,显然获得的分数就是奖励)。奖励函数是难以确定的,人工制定的奖励函数往往会导致不可控制的结果(比如,我想通过强化学习让机器人学会自动抓握物体,如果我设计的奖励函数是机器手与目标物体的距离,机器人可能会通过掀桌子等手段让目标物体靠近机器手,而不是像人类一样抓握)。因此我们考虑让机器学习人类的做法,来使得机器可以去做人类才能完成的事。
模仿学习主要有两种方式:行为克隆(Behavior Cloning)和逆向强化学习(Inverse Reinforcement Learning),接下来我们一一介绍。
2. 行为克隆(Behavior Cloning)
行为克隆是一种十分简单,十分直接的想法。假设我们有许多专家的示例数据,它们以这样的形式出现:<s1,a1>,<s2,a2>,…,<sn,an>,si代表当前的环境,ai代表当前环境下专家采取的动作。
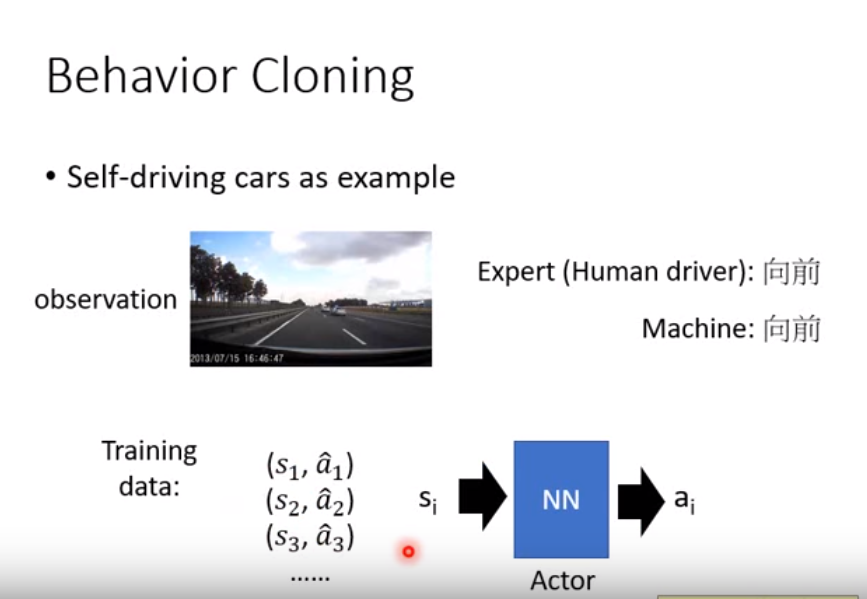
如上图所示,我们得到了这一串专家动作之后,直接丢到一个神经网络中,s是输入,a是输出,直接训练出一个结果。
这种想法显然存在很多问题,机器的输出太依赖专家的数据了,一旦出现了训练数据中没有的场景,机器的输出就会失去了参考,变得极其不靠谱。如下图所示,汽车正常行驶在路上,没有问题,机器可以把车开的很好,但是一旦车偏理了预定轨道,因为专家没遇到过这种情况,机器马上就不知道怎么开车了。另外,我们在此类问题中处理的都是一系列相关的环境和动作,如果我们处理的是独立同分布的数据,那错一个也就罢了,不影响,但是在此类问题中,极易出现一步错步步错的情况。
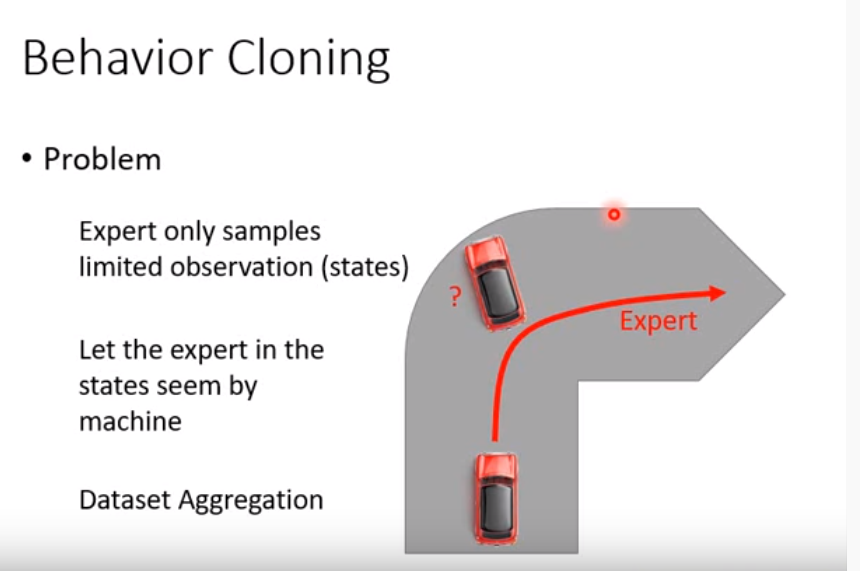
针对这种问题,我们有数据增强(Data Aggregation)的手段,数据增强的手段有一些,大家可以通过查阅其他文献得到。在这个课程中,作者举的例子是我们假设车里面坐了一个专家,专家在每个不同的环境下都会给一个策略,但是机器仍然是按照原本的模型输出的策略行进的,这样子当汽车偏离的时候,虽然车可能依然会撞墙,但是此时专家就会把这个模型缺失的一部分数据补充上。
另外,行为克隆还有一个非常严重的问题,机器会学习到专家所有的行为,甚至是无关紧要的行为。这里作者举了一个很有意思的例子,在《生活大爆炸》中,霍华德在教谢尔顿中文,霍华德在说中文的同时,还不时用手指点,然后我们可爱的谢尔顿就在模仿口音的同时把动作也模仿了出来,以为这些动作是在这个文化中说话必须的。如果机器是原原本本的把这些行为全部学到为还好,至少没有什么坏处,但是更多的时候,机器是学习不全,学不到为的。比如,一个机器去学习一位企业家是如何成功的,他发现,企业家有如下几个特质:勤奋,智慧,领导力,“996福报论”。然后他觉得前面三个太难学习到了,因此只学会了最后一个,那广大劳动人民可要遭殃了。总结来说,机器只是机械的不完整的学习了人类的行为,没有抓住事务的本质。
总的来说,行为克隆本质上是一种有监督的学习,在现实应用中,很不靠谱。
3. 逆向强化学习(Inverse Reinforcement Learning)
上面我们提到,奖励函数十分难以确定,那么有没有一种方法可以去学习奖励函数呢?逆向强化学习算法应运而生。
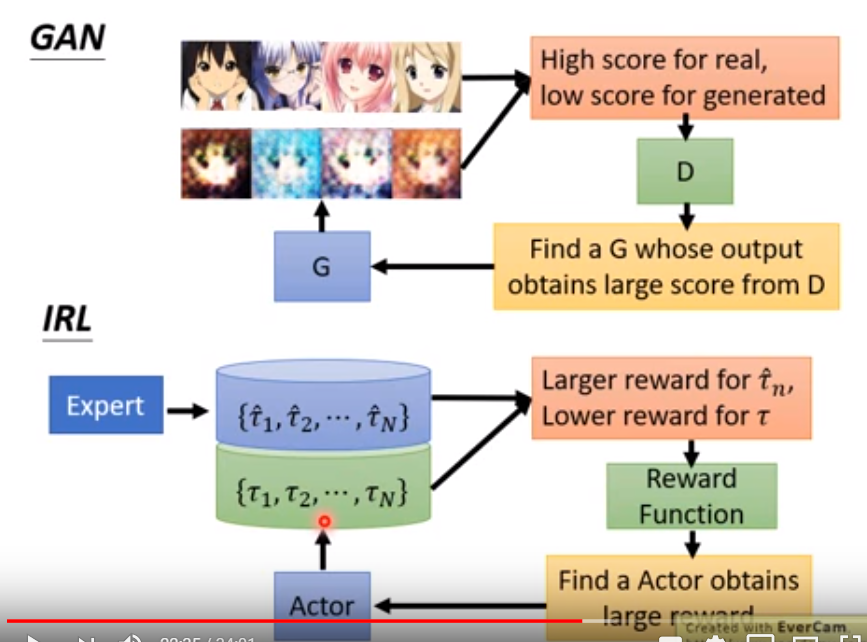
如下图所示,传统的强化学习下方的箭头应该是从左到右的,基于奖励函数与环境交互,做出最大奖励的行为,但是在逆向强化学习算法中,这个过程却是从右向左进行,通过专家数据学习到奖励函数(注意,在逆向强化学习算法中从左到右也要走,后面会讲到)。
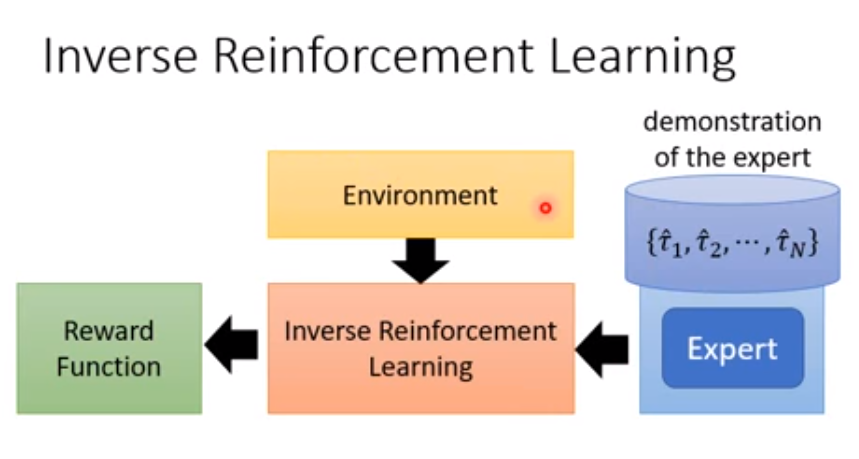
逆强化学习的算法框架如下:
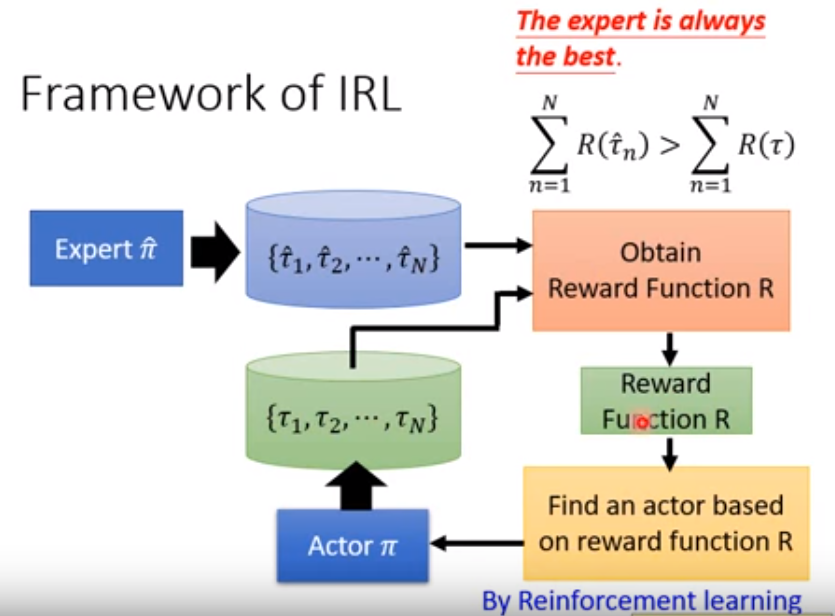
我们通过专家数据,去学习一个奖励函数,再通过这个奖励函数去生成模型的轨迹。至于如何去学习这个奖励函数,我们给的指导就是要保证专家数据获得的奖励一定要比模型生成的数据的奖励要多。
我们仔细去研究这个过程,就会发现这个过程和GAN好像。上图右下角生成Actor和Actor轨迹的行为就像是GAN中的Generator,而右上角的奖励函数,起到的就是Discriminator的作用,用来去区分这个网络是不是专家生成的。Generator尽可能去寻找奖励最大的行为,而Discriminator则不断优化奖励函数,让专家的行为和模型的行为区分开来。关于GAN和逆向强化学习,我们在下篇文章中继续分析。
注意,在逆强化学习中,我们也要执行强化学习的步骤,因此逆强化学习的运算量是不小的。
4. 应用
停车场导航:我们发现,因为在逆向强化学习中,数据只是作为一种演示,因此往往只需要很少的数据就能得到不错的结果。
机器人:这里作者举了两个例子,一个是First Person的,就是人类直接拿着机器人的手,手把手教着机器人去做事,另一种是Third Person的,就是通过观察人类的行为做事。
句子生成和对话机器人:其实,我们也可以把这两个任务看成是一个模仿学习的过程。环境是目前给你的语句,比如I’m,后面要生成一个action,比如fine。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191651.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
