大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
https://tech.meituan.com/2018/01/19/mybatis-cache.html
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
二、mybatis二级缓存:
出现的原因:
1、就是为了解决一级缓存中sql相同,而不同的session会查询两次数据库,不仅浪费时间,也给数据库增加压力。
2、spring与mybatis整合时,每次查询都要进行关闭sqlssion(缓存的数据被清空),即spring与mybatis整合后一级缓存没有意义。
二级缓存介绍:
开启二级缓存关闭sqlssion,会把该sqlssion中的一级缓存中数据添加到mapper.namespace中的二级缓存中,这样之后,即使缓存在sqlssion关闭之后依然存在。(二级缓存是application级别的,它可将整个应用划分的分细,即每个mapper都可以拥有一个cache对象)开启二级缓存后,会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询,工作流程如下:
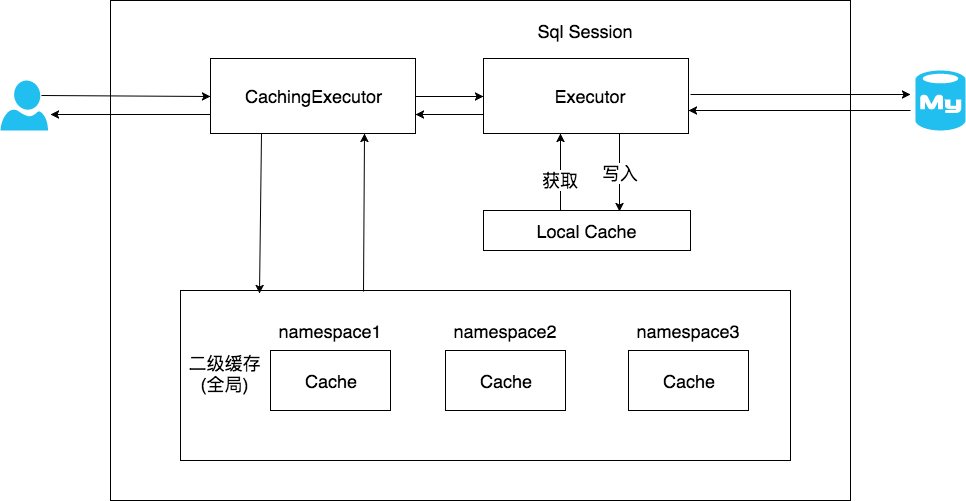

二级缓存开启后,同一个namespace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享,是一个全局的变量。
开启二级缓存后,数据的查询执行的流程是:二级缓存->一级缓存->数据库。
配置二级缓存:
1、在Mybatis的配置文件中开启。
<setting name="cacheEnabled" value="true" />
2、在MyBatis的映射XML文件中配置cache或者cache-ref。
cache标签用于声明这个namespace使用二级缓存,并且可以自定义配置。
<cache/>
- type :cache使用的类型,默认是PerpetualCache。
- eviction :定义回收的策略,常见的有FIFO,LRU。
- flushInterval :配置一定时间自动刷新缓存,单位毫秒。
- size:最多缓存对象的个数。
- readOnly :是否只读,若配置可读写,需要对应的实体类能够序列化。
- blocking :若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
cache-ref 代表引用别的命名空间的Cache配置,两个命名空间的操作使用的是同一个Cache。
<cache-ref namespace ="mapper.xxxMapper"/>
二级缓存特点:
1、当sqlsession查询完数据没有提交事务,二级缓存不会起作用。
2、当update操作提交事务后,sqlsession的xxxMapper下的查询走的是数据库,不是Cache。
3、如果多个namespace没有引用同一个命名空间的缓存,那么多表查询语句所在的namespace无法感应到其他的namespace中的语句对多表查询中涉及的表进行的修改,容易引发脏数据问题。
源码分析:
Mybatis二级缓存的工作流程和上文讲解的一级缓存比较类似,在一级缓存处理前,用CachingExecutor装饰了BaseExecutor的子类,在委托具体职责给delegate之前,实现了二级缓存的查询与写入功能。具体类关系图如下:
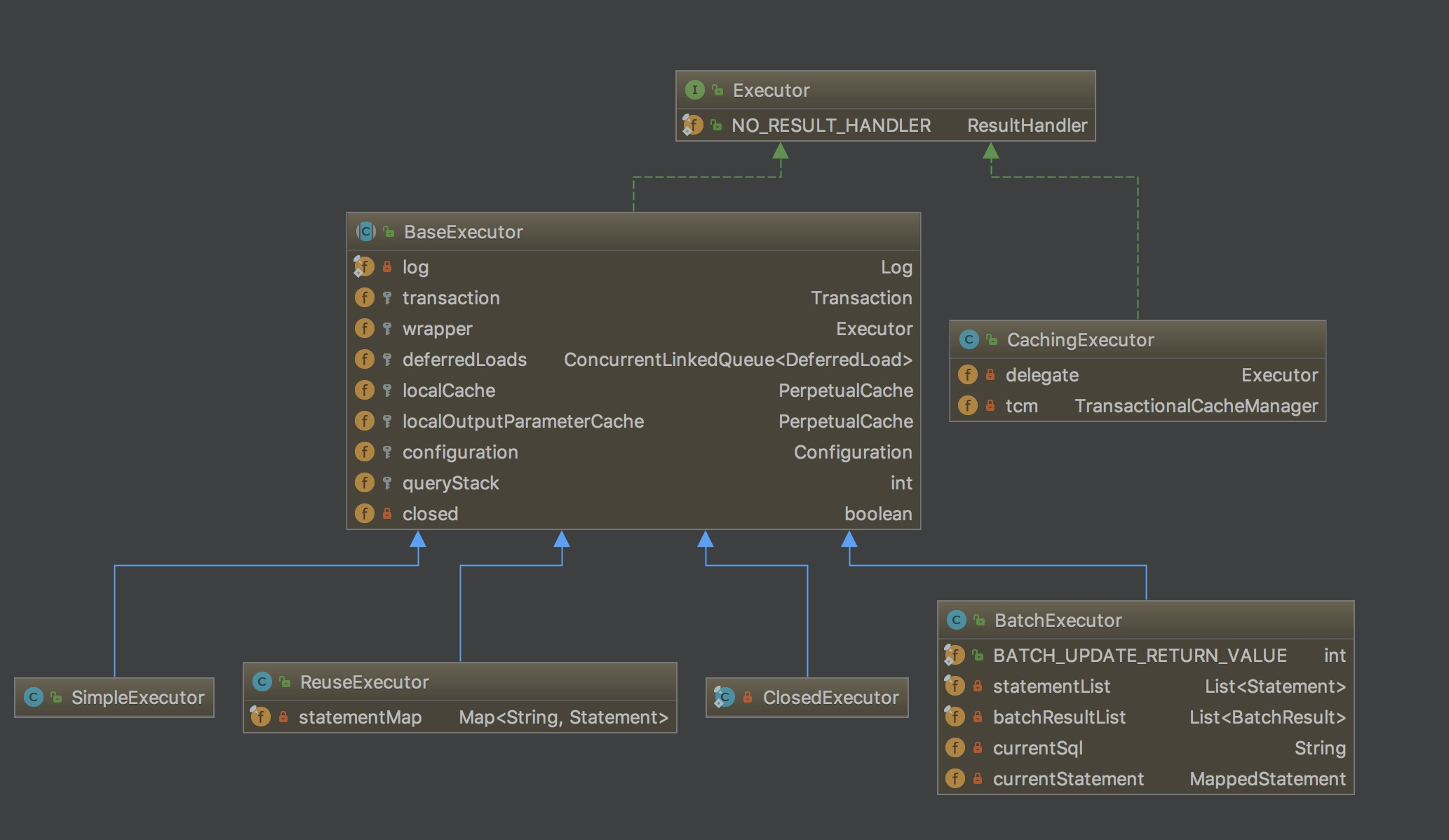
我们从CachingExecutor的query方法展开,源代码走读涉及的知识点会比较多,有省略。
CachingExecutor的query方法,首先会从MappedStatement中获得在配置初始化时赋予的Cache。
Cache cache = ms.getCache();
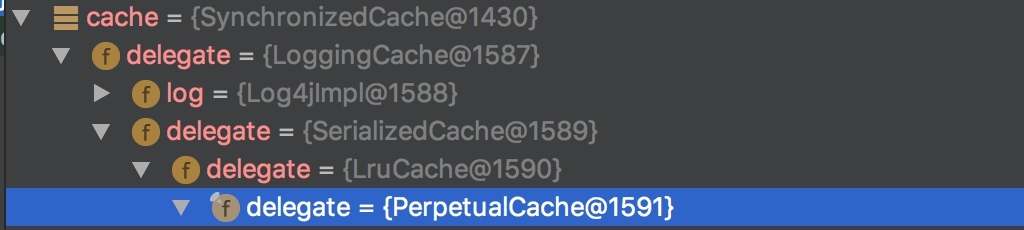
本质上时装饰器模式的使用,具体的装饰链是:
SynchronizedCache->LoggingCache->SerializedCache->LruCache->PerpetualCache
-
SynchronizedCache:同步Cache,实现比较简单,直接使用synchronized修饰方法。
LoggingCache:日志功能,装饰类,用于记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志。 -
SerializedCache:序列化功能,将值序列化后存到缓存中,该功能用于缓存返回一份示例的Copy,用于保存线程安全。
-
LruCache:采用了Lru算法的Cache实现,移除最近最少使用的Key/Value。
-
PerpetualCache:作为为最基础的缓存类,底层实现比较简单,直接使用的是HashMap。
然后判断是否需要刷新缓存:
flushCacheIfRequired(ms);
在默认的设置中SELECT 语句不会刷新缓存,insert/update/delete会刷新缓存。进入该方法,代码如下:
private void flushCacheIfRequired(MappedStatement ms){
Cache cache = ms.getCache();
if(cahce !=null && ms.isFlushCacheRequired()){
tcm.clear(cache);
}
}
MyBatis的CachingExecutor持有了TransactionalCacheManager,即上述代码中的tcm。
TransactionalCacheManager中持有了一个Map,代码如下:
private Map<Cache,TransactionalCache> transactionalCaches = new HashMap<Cache,TransactionalCache>();
这个Map保存了Cache和用
TransactionalCache包装后的Cache的映射关系。
TransactionalCache实现了Cache接口,CachingExecutor会默认使用它包装初始生成的Cache,作用是如果事务提交,对缓存的操作才会生效,如果事务回滚或者不提交事务,则不对缓存产生影响。
在TransactionalCache的clear,有以下两句。清空了需要在提交时加入缓存的列表,同事设定提交时清空缓存,代码如下:
@Override
public void clear(){
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
CachingExecutor继续往下走,ensureNoOutParams主要是用来处理存储过程的,暂时不用考虑。
if(ms.isUseCache()&&ResultHandler ==null){
ensureNoOutParams(ms,parameterObject,boundSql);
之后会尝试从tcm中获取缓存的列表。
List<E> list = (List<E>)tcm.getObject(cache,key);
在getObject方法中,会把获取值的职责一路传递,最终到PerpetualCache,如果没有查到,会把key加入到Miss集合,这个主要是为了统计命中率。
Object object = delegate.getObject(key);
if(object==null){
entriesMissedInCache.add(key)
}
CachingExecutor继续往下走,如果查询到数据,则调用tcm.putObject方法,往缓存中放入值。
if(list ==null){
list=delegate.<E> query(ms.parameterObject,rowBounds,resultHander,key,boundSql);
tcm.putObject(cache,ley,list);
}
tcm的put方法也不是直接操作缓存,只是在把这次的数据和key放入待提交的Map中。
@Override
public void putObject(Object key,Object object){
entriesToAddOnCommit.put(key,object);
}
从以上的代码分析中,我们可以明白,如果不调用commit方法的话,由于TranscationalCache的作用,并不会对二级缓存造成直接的影响。所以我们看看Sqlsession的commit方法中做了什么,代码如下:
@Override
public void commit(boolean force){
try{
executor.commit(isCommitOrRollbackRequired(force));
}
因为我们使用了CachingExecutor,首先会进入CachingExecutor实现的commit方法。
@Override
public void commit(boolean required) throws SQLException{
delegate.commit(required);
tcm.commit();
}
会把具体commit的职责委托给包装的Executor。主要是看下tcm.commit(),tcm最终又会调用到TrancationalCache。
public void commit(){
if(clearOnCommit){
delegate.clear();
}
flushPendingEntries();
reset();
}
看到这里的clearOnCommit就想起刚才TrancationalCache的clear方法设置的标志位,真正的清理Cache是放到这里来进行的。具体清理的职责委托给了包装的Cache类,之后进入flushPendingEntries方法。代码如下:
private void flushPendingEntries(){
for(Map.Entry<Object,Object> entry: entriesToAddOnCommit.entrySet()){
delegate.putObject(entry.getKey(),entry.getValue());
}
................
}
在flushPending Entries中,将待提交的Map进行循环处理,委托给包装的Cache类,进行putObject的操作。
后续的查询操作会重复执行这套流程,如果是insert|update|delete的话,会统一进入CachingExecutor的update方法,其中调用了这个函数,代码如下:
private void flushCacheIfRequired(MappedStatement ms)
在二级缓存执行流程后就会进入一级缓存的执行流程,请看上篇文章。
二级缓存清除策略:
LRU – 最近最少使用(也是mybatis默认清除策略)
FIFO – 先进先出
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象
WEAK – 弱引用:更积极的基于垃圾收集器状态和弱引用规则来移除对象
事务管理策略:
1、使用JDBC的事务管理机制,这种就是利用java.sql.Connection对象完成对事务的提交。
2、使用MANAGED的食物管理机制,这种机制mybatis自身不会去实现事务管理,而是让程序的web容器或者spring容器来实现对事务的管理。
总结
1、Mybatis的二级缓存相对于一级缓存来说,实现了SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强。
2、Mybatis在多表查询时,极大可能会出现脏数据,有涉及上的缺陷,安全使用二级缓存的条件比较苛刻。
3、在分布式环境下,由于默认的MyBatis Cache 实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis 的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存成本可更低,而且更安全。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191514.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
