大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
性能调优在整个工程中是非常重要的,也是非常有必要的。但有的时候我们往往都不知道如何对性能进行调优。其实性能调优主要分两个方面:一方面是硬件调优,一方面是软件调优。本章主要是介绍Kettle的性能优化及效率提升。
一、Kettle调优
1、 调整JVM大小进行性能优化
修改Kettle定时任务中的Kitchen或Pan或Spoon脚本:
|
修改脚本代码片段 |
|
set OPT=-Xmx512m -cp %CLASSPATH% -Djava.library.path=libswt\win32\ -DKETTLE_HOME=”%KETTLE_HOME%” -DKETTLE_REPOSITORY=”%KETTLE_REPOSITORY%” -DKETTLE_USER=”%KETTLE_USER%” -DKETTLE_PASSWORD=”%KETTLE_PASSWORD%” -DKETTLE_PLUGIN_PACKAGES=”%KETTLE_PLUGIN_PACKAGES%” -DKETTLE_LOG_SIZE_LIMIT=”%KETTLE_LOG_SIZE_LIMIT%” |
|
参数参考: -Xmx1024m:设置JVM最大可用内存为1024M。 |
|
样例:OPT=-Xmx1024m -Xms512m |
2、 调整提交(Commit)记录数大小进行优化
如修改RotKang_Test01中的“表输出”组件中的“提交记录数量”参数进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000。
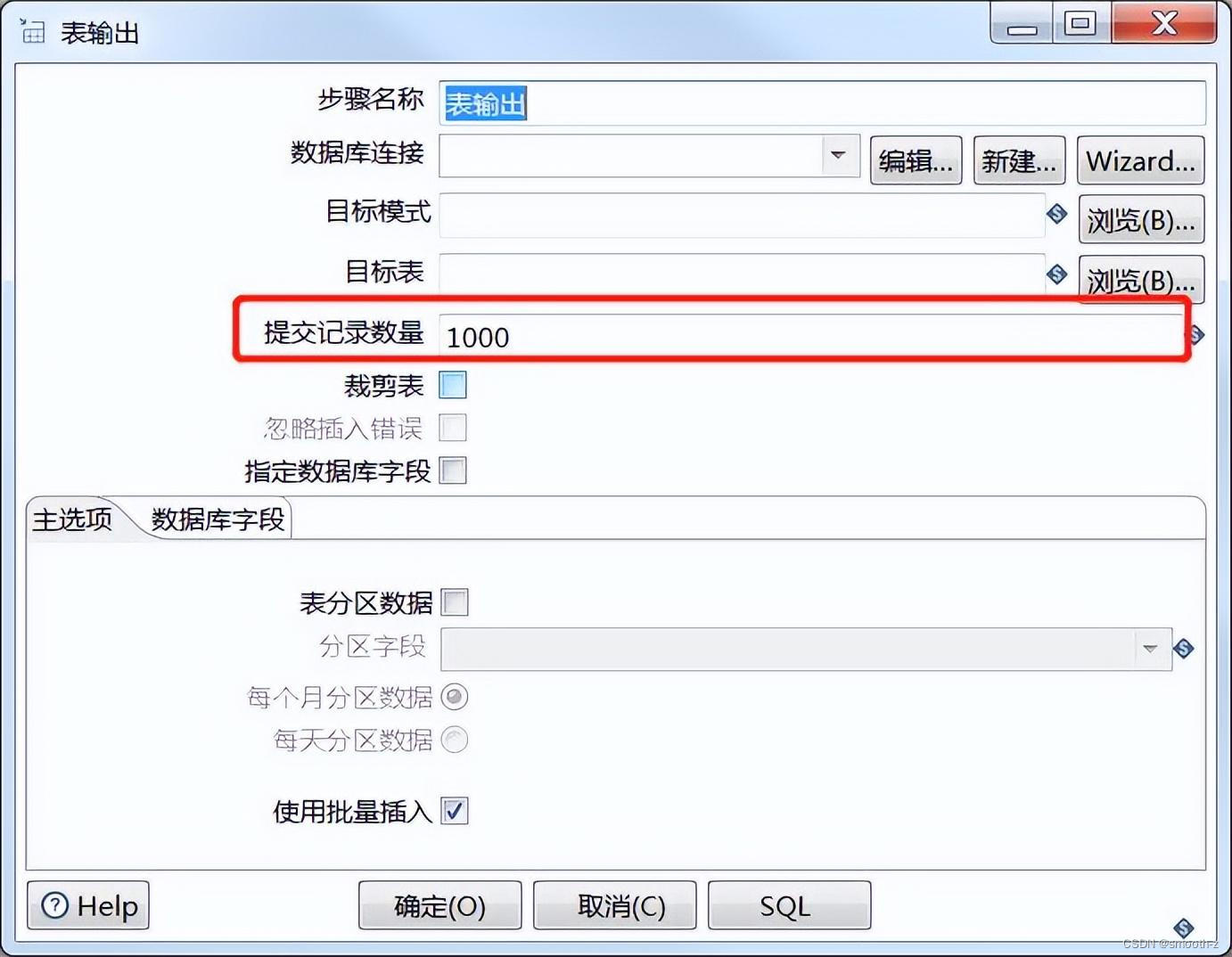

3、 调整记录集合里的记录数
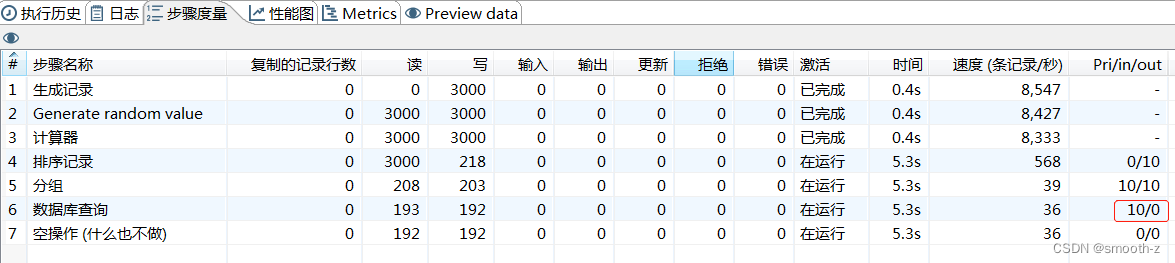
RowSet是两个步骤之间的缓存。
性能调优的关键是如何找到性能瓶颈:一个重要的方法就是观察RowSet。如下图所示,当左边的in大于右边的out的位置时,很可能就是性能瓶颈的位置。(也可以通过单个执行最长的步骤来确定性能瓶颈)
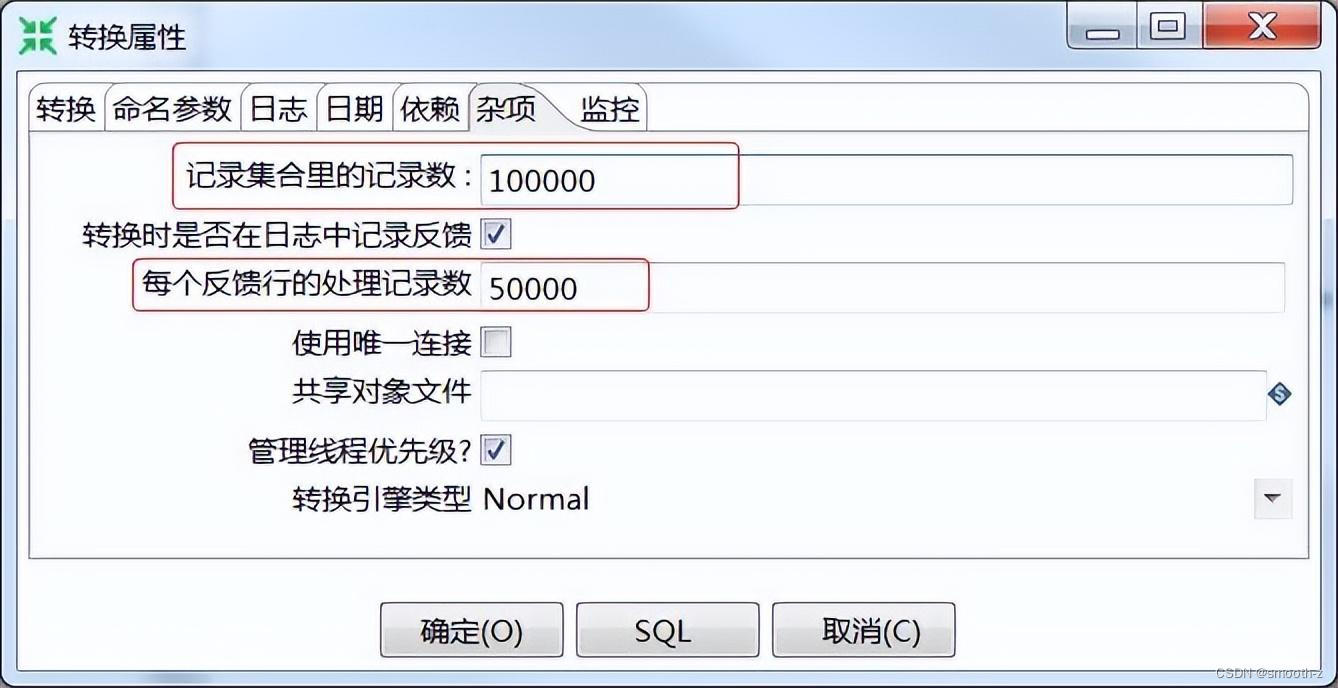
通过点击转换空白处,可以调整RowSet的大小:
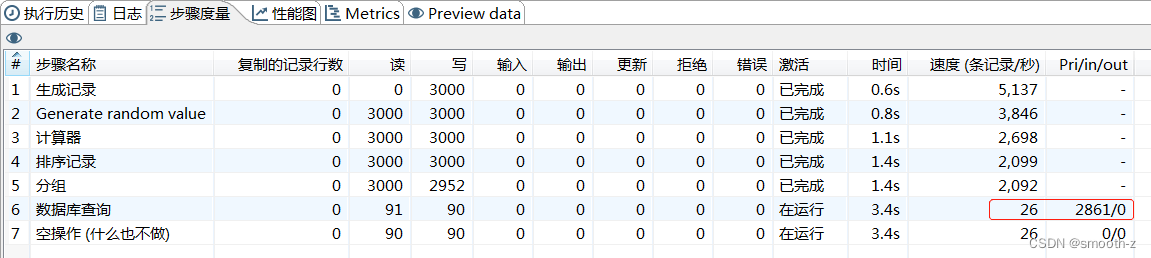
调整之后,执行效果如下:
4、调整转换动作的并发处理数(改变开始复制的数量)
注意:此种方式要用在适合并发操作的场景,比如查询类,要注意死锁问题。
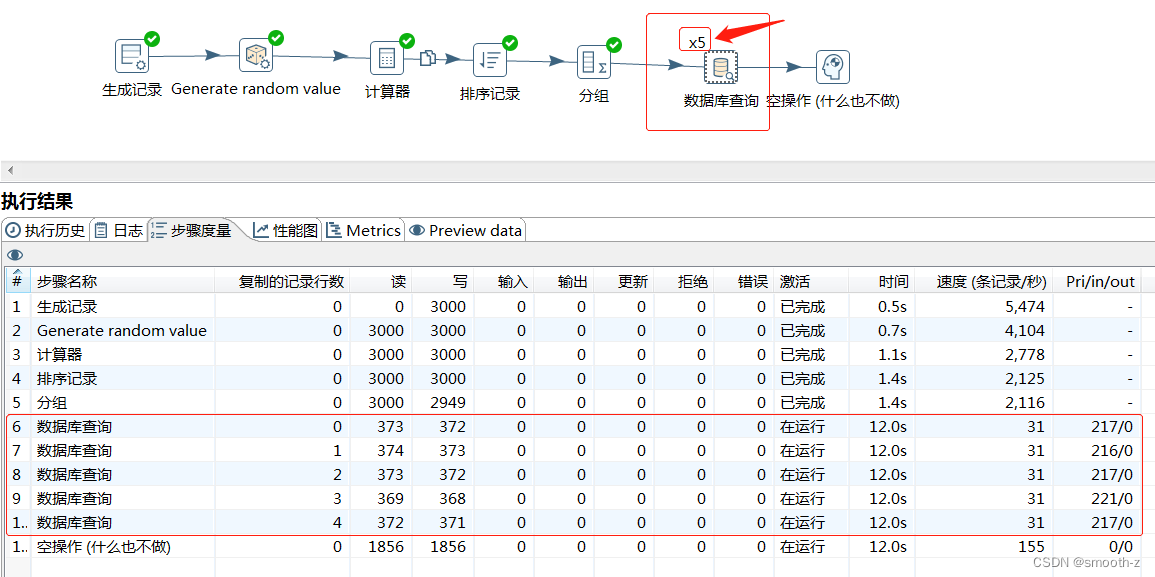
当调整RowSet大小之后,性能效果仍不明显的话,可以尝试调整转换动作的并发处理数,比如以下转换操作在“数据库查询”处出现性能瓶颈。

调整并发处理数(一般设置成2-8个),如下:
执行情况如下图所示,速度明显提高了很多:
5、Insert/Update增加错误处理步骤分离Insert和Update
Kettle的原作者在他的博客中提到过,尽量不要使用Insert/Update组件,因为这个组件慢的他都受不了,正常情况下在几百条每秒(对比TableInsert几万的速度)。如果必须使用这个组件的时候,那么可以在Insert/Update中勾选Don’t perform any updates(不做任何更新操作),然后把错误的数据指向一具数据库更新的操作,这要就把添加和更新分离了开来。根据官网描述,在少量更新大量插入的时候性能可以提高到原来的3倍左右,实测时达不到,可能和数据集有关。
6、数据库分组和排序优于ETL分组和排序
在ETL中减少排序和分组的操作,尽量使用数据库完成排序和分组。在KTR中,数据是使用流的方式在不同的步骤间传递数据,使用排序和分组的操作会在这一步阻塞KTR的执行,直到接收到前面所有步骤传过来的数据为止,导致ETL的运行时间增长,占用的内存增大。
使用Blocking Step也会将流阻塞到这一步,和以上情况类似。
7、延迟转化
很多字段在读入到最后输出,实际上都没有被操作过,开启延迟转化可以让kettle在必要的时候再进行转化。这里的转化是指从二进制到字符串之间的转化,在输入和输出都是文本的时候更为明显。事实上,Select Values在转化的效率上也高于读取时直接转化。
8、尽量减少步骤的数量
步骤的数量会影响ktr的执行效率,包含并行处理时复制的数量。ktr中步骤的数量为机器核心总数的3〜4倍最佳,如果超过这个范围,可以考虑通过减少步骤数量的方式以提高ktr的执行效率。
9、不要在Select Values的步骤删除某个字段
如果在Select Values的步骤删除某个字段,kettle会需要调整现有的存储结构,在可以不删除的时候尽量不要删除字段。
10、其他调优手段
(1). 使用集群,尤其是对于查询类,运算类,排序等;
(2). 更换其他实现方式,如js使用java类或插件;
(3). 注意日志级别(Rowlevel日志的性能会严重下降,是Basic的1/10);
(4). 注意死锁问题:数据库死锁(读写同一张表)和转换本身死锁;
(5). 尽量使用数据库连接池;
使用数据库连接池,可以在一定程度上提高速度。如何查看是否使用了数据库连接池?(这个在详细日志中可以看到,使用了连接池)。
(6). 尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流),比如排序;
(7). 合适的使用数据库索引,尤其对于数据库查询类。具体可以参考 [索引的正确使用];
(8). 可以使用sql来做的一些操作尽量用sql;
Group, merge,stream lookup,split field这些操作都是比较慢的,想办法避免他们,能用sql就用sql;
(9). 插入大量数据的时候尽量把索引删掉;
(10). 尽量避免使用update,delete操作,尤其是update,如果可以把update变成先delete,后insert;
(11). 能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
(12). 尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
(13). 尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤);
(14). 尽量不要用kettle的calculate计算步骤,能用数据库本身的sql就用sql,不能用sql就尽量想办法用procedure,实在不行才是calculate步骤;
(15). 远程数据库用文件+FTP的方式来传数据,文件要压缩。(只要不是局域网都可以认为是远程连接);
(16). 使用Carte管理kjb和ktr减小内存消耗;
(17). 在确保结果输出正确的情况下,能使用并行处理的就不要使用串行处理;
(18). 要知道你的性能瓶颈在哪,可能有时候你使用了不恰当的方式,导致整个操作都变慢,观察kettle log生成的方式来了解你的ETL操作最慢的地方。
二、索引的正确使用
在ETL过程中的索引需要遵循以下使用原则:
1、当插入的数据为数据表中的记录数量10%以上时,首先需要删除该表的索引来提高数据的插入效率,当数据全部插入后再建立索引。
2、避免在索引列上使用函数或计算,在where子句中,如果索引列是函数的一部分,优化器将不使用索引而使用全表扫描。
3、避免在索引列上使用 NOT和 “!=”,索引只能告诉什么存在于表中,而不能告诉什么不存在于表中,当数据库遇到NOT和 “!=”时,就会停止使用索引转而执行全表扫描。
4、索引列上用 >=替代 >
高效:select * from temp where deptno>=4
低效:select * from temp where deptno>3
两者的区别在于,前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录。
三、数据抽取的SQL优化
1、Where子句中的连接顺序:
比如ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。
例如:
(低效,执行时间156.3 秒)
SELECT …
FROM EMP E
WHERE SAL > 50000
AND JOB = 'MANAGER'
AND 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO);(高效,执行时间10.6 秒)
SELECT …
FROM EMP E
WHERE 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO)
AND SAL > 50000
AND JOB = 'MANAGER';2、删除全表是用TRUNCATE替代DELETE:
因为TRUNCATE是DDL语句,它执行时不会产生UNDO信息,因此要更快。尤其是当数据量比较大的时候。但注意的是 TRUNCATE只针对删除全表数据。
delete关键字:delete from 表名
truncate关键字:truncate 表名3、尽量多使用COMMIT:
mysql默认是开启Commit,而对于Oracle也尽量多使用Commit。
只要有可能,在程序中尽量多使用COMMIT,这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少:
COMMIT所释放的资源包括:
a. 回滚段上用于恢复数据的信息;
b. 被程序语句获得的锁;
c. redo log buffer 中的空间;
d. ORACLE为管理上述3种资源中的内部花费。
ETL中同一个过程的数据操作步骤很多,数据仓库采用的是数据抽取后分析模型重算的原理,所以对数据的COMMIT不像业务系统为保证数据的完整和一致性而需要某个操作过程全部完成才能进行,只要有可能就在程序中对每个delete insert和update操作尽量多使用COMMIT,这样系统性能会因为COMMIT所释放的资源而大大提高。
4、建议用EXISTS替代IN:
写sql时,最好用exists来代替in,因为in不走索引,所以用exists的sql性能较好。当然这不是绝对的,毕竟in的可读性好,如果in的访问量比较小或者in的参数为数值列表就比较合适。
总之,建议尽可能使用exists方式,避免使用子查询。
5、用NOT EXISTS替代NOT IN:
在SQL中,我们经常会习惯性的使用not in来实现一张表有而另外一张表没有的数据,在访问量比较小的时候是可以的,但是一旦数据量大了,NOT IN就是最低效的,因为它对子查询中的表执行了一个全表遍历,所以我们推荐使用not exists或者外连接来代替:
select * from table t where t.id not in (select id from table2)
-- 可以替换成以下两种方式
select * from table a where not exists (select 1 from table2 b where a.id = b.id);
select a.* from table1 a left join table2 b on a.id = b.id where b.id is null; 总结:EXISTS与IN的使用效率的问题,通常情况下采用exists要比in效率高,因为IN不走索引,但要看实际情况具体使用:IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
6、优化GROUP BY:
group by使用了临时表和排序:
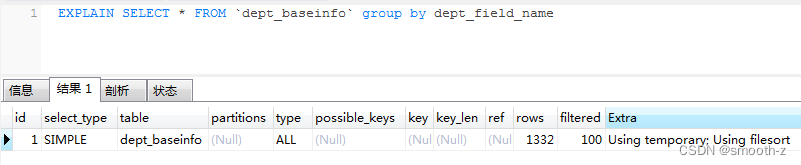
Extra 这个字段的Using temporary表示在执行分组的时候使用了临时表
Extra 这个字段的Using filesort表示使用了排序group by使用不当,很容易就会产生慢SQL 问题。因为它既用到临时表,又默认用到排序,有时候还可能用到磁盘临时表。
如果执行过程中,会发现内存临时表大小到达了上限(控制这个上限的参数就是tmp_table_size),会把内存临时表转成磁盘临时表。如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间和磁盘IO。
主要是这些导致了慢SQL的因素,所以Group By的优化很重要。
从哪些方向去优化呢?
- 方向1: 既然它默认会排序,我们不给它排是不是就行啦。
- 方向2:既然临时表是影响group by性能的X因素,我们是不是可以不用临时表?
我们一起来想下,执行group by语句为什么需要临时表呢?group by的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果啦?所以我们优化的方式主要是以下方面:
- group by 后面的字段加索引
- order by null 不用排序
- 尽量只使用内存临时表
- 使用SQL_BIG_RESULT
提高Gruop By语句的效率,可以通过将不需要的记录在GROUP BY之前过滤掉。
低效:select JOB,AVG(SAL) FROM EMP GROUP BY JOB HAVING JOB='PRESIDENT' OR JOB='MA NAGE'R
高效:select JOB,AVG(SAL) FROM EMP WHERE JOB='PRESIDEN' TOR JOB='MA NAGE'R GROUP BY JOB7、有条件的使用UNION-ALL替换UNION:
ETL过程针对多表连接操作的情况很多,有条件的使用union-ALL替换union的前提是:所连接的各个表中无主关键字相同的记录,因为uniion ALL将重复输出两个结果集全中相同记录。
当SQL语句需要union两个查询结果集合时,这两个结果集合会以uniion-ALL的方式被合并,然后在输出最终结果前进行排序。如果union ALL替代union,这样排序就不是必要的了,效率就会因此提高3-5倍。
8、分离表和索引:
主要针对ORACLE,总是将你的表和索引建立在不同的表空间内(TABLESPACES),决不要将不属于ORACLE内部系统的对象存放到SYSTEM表空间里。同时,确保数据表空间和索引表空间置于不同的硬盘上。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191353.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
