大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
eBPF 介绍
Tcpdump 是Linux 平台常用的网络数据包抓取及分析工具,tcpdump 主要通过libpcap 实现,而libpcap 就是基于eBPF。
先介绍BPF(Berkeley Packet Filter),BPF 是基于寄存器虚拟机实现的,支持 JIT(Just-In-Time),比基于栈实现的性能高很多。它能载入用户态代码并且在内核环境下运行,内核提供 BPF 相关的接口,用户可以将代码编译成字节码,通过 BPF 接口加载到 BPF 虚拟机中,当然用户代码跑在内核环境中是有风险的,如有处理不当,可能会导致内核崩溃。因此在用户代码跑在内核环境之前,内核会先做一层严格的检验,确保没问题才会被成功加载到内核环境中。
eBPF(extended Berkeley Packet Filter)起源于BPF,它提供了内核的数据包过滤机制。其扩充了 BPF 的功能,丰富了指令集。
最初,eBPF 仅在内核内部使用,并且 cBPF 程序在幕后无缝转换。但是随着2014 年的 daedfb22451d提交,eBPF 虚拟机直接暴露给用户空间。
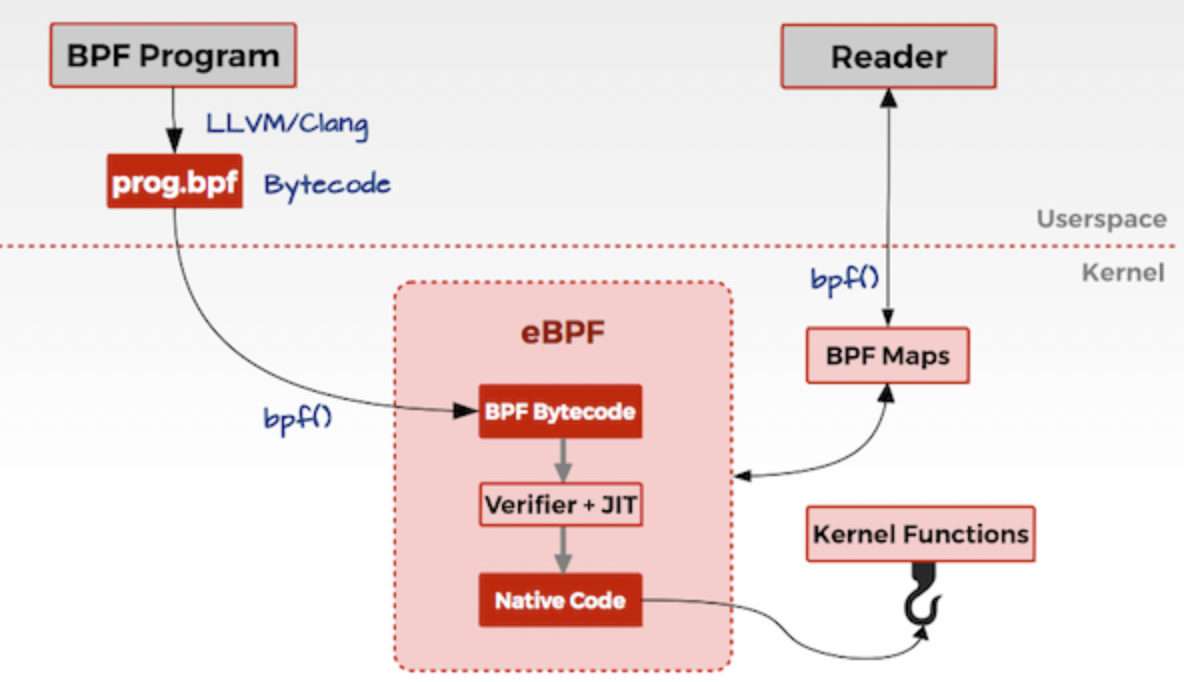

eBPF分用户空间和内核空间,用户空间和内核空间的交互有2种方式:
- BPF map:统计摘要数据
- perf-event:用户空间获取实时监测数据
如上,一般eBPF 的工作逻辑是:
- BPF Program 通过LLVM/Clang 编译成eBPF定义的字节码prog.bpf。
- 通过系统调用bpf() 将bpf 字节码指令传入内核中。
- 经过verifier 检验字节码的安全性、合规性。
- 在确认字节码安全后将其加载对应的内核模块执行,通过Helper/hook机制,eBPF与内核可以交换数据/逻辑。BPF 观测技术相关的程序程序类型可能是 kprobes/uprobes/tracepoint/perf_events 中的一个或多个,其中:
-
-
- kprobes:实现内核中动态跟踪。 kprobes 可以跟踪到 Linux 内核中的函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。理论上可以跟踪到所有导出的符号 /proc/kallsyms。
-
-
-
- uprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪的函数为用户程序中的函数。
-
-
-
-
tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。
-
-
-
-
- perf_events:定时采样和 PMC。
-
5. 用户空间通过BPF map 与内核通信。
eBPF 可以做什么
eBPF 主要功能列表
|
特性 |
引入版本 |
功能介绍 |
应用场景 |
|---|---|---|---|
| Tc-bpf | 4.1 | eBPF重构内核流分类 | 网络 |
| XDP | 4.8 | 网络数据面编程技术(主要面向L2/L3层业务) | 网络 |
| Cgroup socket | 4.10 | Cgroup内socket支持eBPF扩展逻辑 | 容器 |
| AF_XDP | 4.18 | 网络原始报文直送用户态(类似DPDK) | 网络 |
| Sockmap | 4.20 | 支持socket短接 | 容器 |
| Device JIT | 4.20 | JIT/ISA解耦,host可以编译指定device形态的ISA指令 | 异构编程 |
| Cgroup sysctl | 5.2 | Cgroup内支持控制系统调用权限 | 容器 |
| Struct ops Prog ext | 5.3 | 内核逻辑可动态替换 eBPF Prog可动态替换 | 框架基础 |
| Bpf trampoline | 5.5 | 三种用途: 1.内核中代替K(ret)probe,性能更优 2.eBPF Prog中使用,解决eBPF Prog调试问题 3.实现eBPF Prog动态链接功能(未来功能) | 性能跟踪 |
| KRSI(lsm + eBPF) | 5.7 | 内核运行时安全策略可定制 | 安全 |
| Ring buffer | 5.8 | 提供CPU间共享的环形buffer,并能实现跨CPU的事件保序记录。用以代替perf/ftrace等buffer。 | 跟踪/性能分析 |
eBPF 在 Linux 3.18 版本以后引入,并不代表只能在内核 3.18+ 版本上运行,低版本的内核升级到最新也可以使用 eBPF 能力,只是可能部分功能受限,比如我就是在 Linux 发行版本 CentOS Linux release 7.7.1908 内核版本 3.10.0-1062.9.1.el7.x86_64 上运行 eBPF 在生产环境上搜集和排查网络问题。
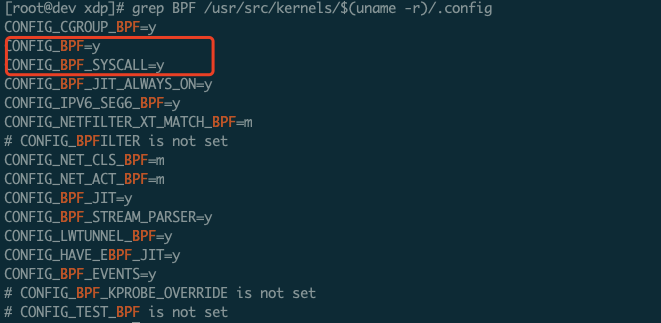
查看kernel 对BPF 的支持情况,确保CONFIG_BPF、CONFIG_BPFSYSCALL 是yes的。
[root@dev ~]# grep BPF /usr/src/kernels/$(uname -r)/.config
和内核模块对比
|
维度 |
Linux 内核模块 |
eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
eBPF 的使用场景
**网络场景**
在网络加速场景中,DPDK技术大行其道,在某些场景DPDK成了唯一选择。XDP的出现为厂商提供了一种新的选择,借助于kernel eBPF社区的蓬勃发展,为网络加速场景注入了一股清流。下面我们总结下两种差异:
- DPDK优势/价值:优势(性能、生态)、价值(带动硬件销售)
- 性能:总体上XDP性能全面弱于DPDK(但是差距不大),注意:只是比较DPDK/XDP自身性能
- 生态:DPDK历经多年发展,生态体现在:驱动支持丰富、基础库丰富(无锁队列、大页内存、多核调度、性能分析工具等)、协议支持丰富(社区强大,例如VPP,支持众多协议ARP/VLAN/IP/MPLS等)
- 价值:将网络类专有硬件的工作转嫁给软件实现,进而拓展硬件厂商市场范围。
- XDP优势:可编程、内核协同工作
- 可编程:在网络硬件智能化趋势下,可编程可以适用多种场景。
- 内核协同:XDP并不是完全bypass kernel,所以在必要的时候可以与内核协同工作,利于网络统一管理、部署。
- DPDK一些固有缺陷:
- 独占Device:设备利用率低。
- 部署复杂:由于独占Device,网络部署需要与OS协议栈协同部署。
- 开发困难:DPDK定位就是网络数据面开发包,所以它对使用者要求具备专业网络知识、专业硬件知识,所以入门门槛高。
- 端到端性能不高:DPDK只是提供数据包从NIC到用户态软件的零拷贝,但是用户态传输协议依然需要CPU参与。所以端到端性能不高。
进阶阅读Polycube 项目。
容器场景
背景:云原生场景中容器比虚拟化技术有着更好的低底噪、轻便、易管理等优点,基本已经成为云原生应用的事实标准。容器场景对网络需求实际是应用对网络的需求,即面向应用的网络服务。
- 云原生应用特点以及对网络的诉求:
- 生命周期短:要求提供基于PoD静态身份信息实施的网络安全策略。
- (不能基于IP/Port) 租户间隔离:要求提供API级别的网络隔离策略。
- ServiceMesh拓扑管理:要求提供side-car加速。
- 服务入口位置透明:要求提供跨集群Ingress服务能力。
- 安全策略跨集群:要求网络安全策略能够在集群间共享、继承。
- 服务实例冗余保证高可用性:要求提供L3/4层LB能力。
进阶阅读Cilium项目。
安全场景
背景:Linux系统的运行安全始终是在动态平衡中,系统安全性通常要评估两方面的契合度:signals(系统中一些异常活动迹象)、mitigation(针对signals的一些补救措施)。
内核中的signal/mitigation设置散布在多个地方,配置时费时费力。
解决方案:引入eBPF,提供一些eBPF Helper实现“unified policy API”,由API来统一配置signal和mitigation。
eBPF 的使用
eBPF 提供多种使用方式:BCC、BPFTrace、libbpf C/C++ Library、eBPF GO library等
更早期的工具使用 C 语言来编写 BPF 程序,使用 LLVM clang 编译成 BPF 代码,这对于普通使用者上手有不少门槛当前仅限于对于 eBPF 技术更加深入的学习场景。
对于大多数开发者而言,更多的是基于 BPF 技术之上编写解决我们日常遇到的各种问题。
BCC 和 BPFTrace 作为BPF的两个前端,当前这两个项目在观测和性能分析上已经有了诸多灵活且功能强大的工具箱,完全可以满足我们日常使用。
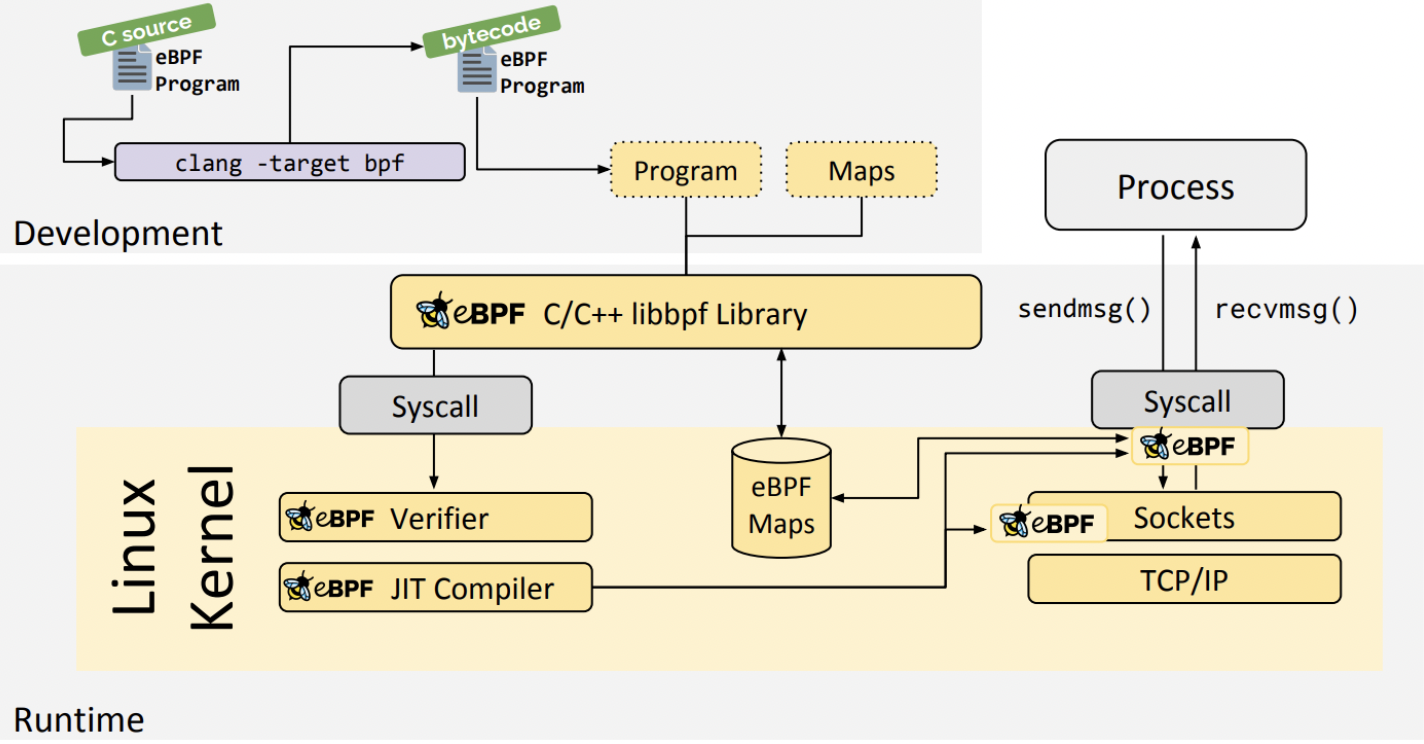
libbpf C/C++ Library
基于libbpf C/C++ library 的开发架构如下:
获取libbpf:
1) git clone https://github.com/libbpf/libbpf
2) cd libbpf/src
3) make -j8 && make install
原生C Hello world
参考:https://github.com/bpftools/linux-observability-with-bpf/tree/master/code/chapter-2/hello_world
[root@dev ~]# git clone https://github.com/bpftools/linux-observability-with-bpf
[root@dev ~]# cd linux-observability-with-bpf/code/chapter-2/hello_world
获取内核源码,将Makefile 中kenel-src 路径替换为实际内核源码路径
[root@dev ~]# make
make 后会创建BPF ELF bpf-program.o 及 Loader monitor-exec
这时执行
[root@dev ~]# ./monitor-exec
将bpf 指令加载至内核。
之后,执行任意的execve 系统调用都会打印:Hello, BPF World!
如执行ls:

此时可以看到BPF 程序打印出Hello, BPF World!
注意:
- centos 默认yum 安装的clang 版本是3.4,不支持tagert bpf,需要升级clang 至3.9
BCC 的安装及使用
bcc 即BPF Compiler Collection,bcc 是一个关于BPF 技术的工具集。
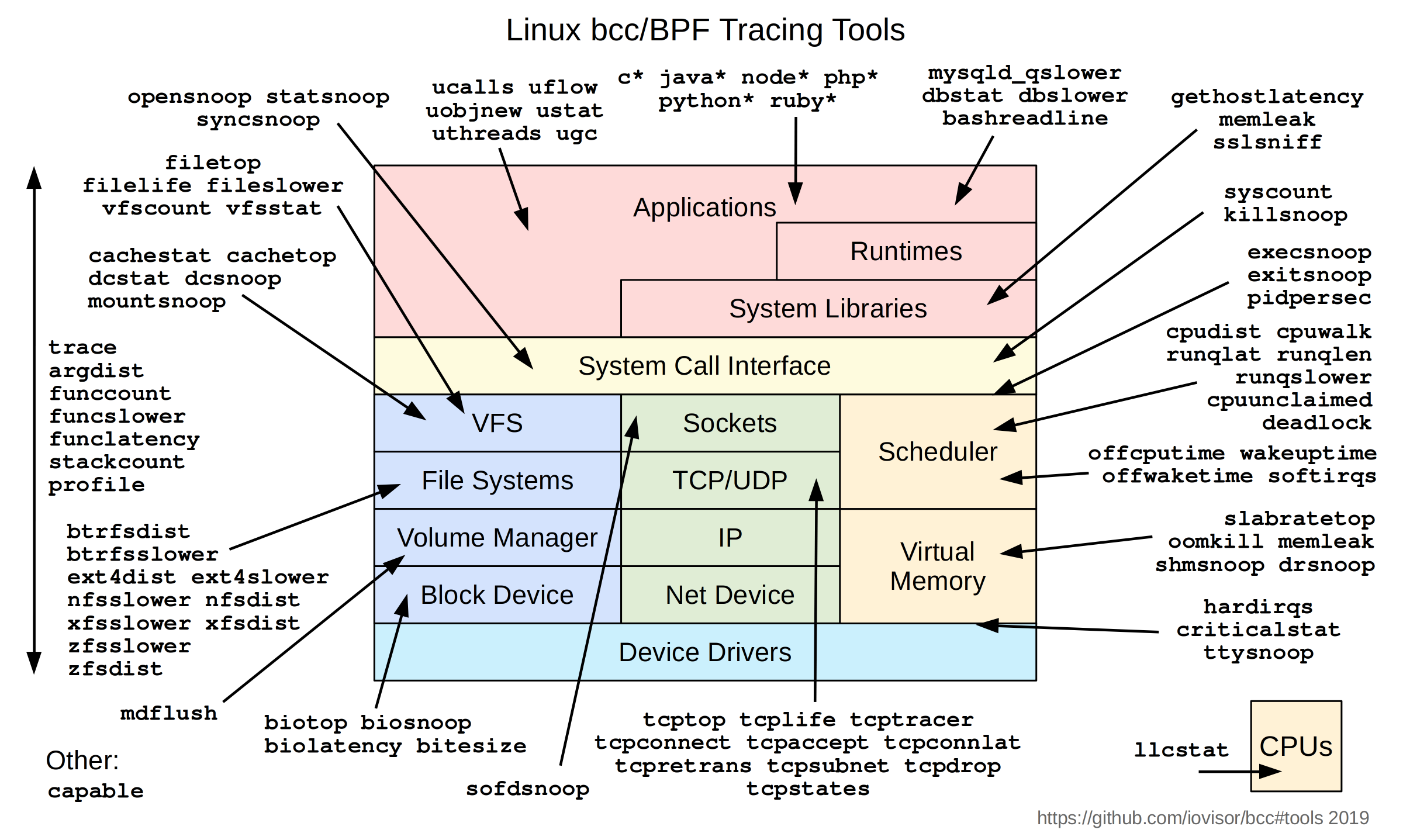
以CentOS 7 为例
安装
Linux 3.15 开始引入 eBPF,而又因为bcc 在5以上的内核版本中存在bug(https://github.com/iovisor/bcc/issues/2329),建议将内核升级至4+,如lt 版本4.19.
升级Linux 内核
因为多数elrepo 中的kernel 版本默认是最新的5.4 或5.12 等,可以直接下载4.19 的kernel rpm 包本地安装;
rpm 包参考:Index of /c7-kernels.x86_64/kernel/20190918210642/4.19.72-300.el7.x86_64
下载rpm 包至本地:
|
kernel-4.19.72-300.el7.x86_64.rpm kernel-core-4.19.72-300.el7.x86_64.rpm |
本地安装:
# yum localinstall kernel-core-4.19.72-300.el7.x86_64.rpm kernel-4.19.72-300.el7.x86_64.rpm kernel-modules-4.19.72-300.el7.x86_64.rpm kernel-headers-4.19.72-300.el7.x86_64.rpm
更新 Grub 后重启:
[root@dev ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
[root@dev ~]# awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
0 : CentOS Linux (5.2.8-1.el7.elrepo.x86_64) 7 (Core)
1 : CentOS Linux (3.10.0-862.14.4.el7.x86_64) 7 (Core)
[root@dev ~]# grub2-set-default 0
[root@dev ~]# reboot
重新登录后确认当前内核版本
[root@dev ~]# grub2-editenv list uname -r
安装bcc-tools
[root@dev ~]# yum install -y bcc-tools
[root@dev ~]# export PATH=$PATH:/usr/share/bcc/tools
使用bcc-tools
如对于一些生命周期很短的进程很难通过top 工具去监测,这是可以通过execsnoop 去监测:
[root@dev ~]# /usr/share/bcc/tools/execsnoop

BCC 的程序一般情况下都需要 root 用户或sudo 来运行。
BCC hello world
BCC 前端绑定语言Python

1 #!/usr/bin/python3
2
3 from bcc import BPF
4
5 # This may not work for 4.17 on x64, you need replace kprobe__sys_clone with kprobe____x64_sys_clone
6 prog = """
7 int kprobe__sys_clone(void *ctx) {
8 bpf_trace_printk("Hello, World!\\n");
9 return 0;
10 }
11 """
12
13 b = BPF(text=prog, debug=0x04)
14 b.trace_print()

其中,
-
text='...':自定义的C 代码BPF 程序。 -
kprobe__sys_clone():通过kprobes 执行内核动态追踪的捷径。以kprobe__为前缀的C函数,被当作内核函数名使用,本文是sys_clone()。 -
void *ctx: ctx 传递参数,当前不传递参数则使用void *。 -
bpf_trace_printk():一个简单的内核工具,用于printf 输出至trace_pipe (/sys/kernel/debug/tracing/trace_pipe)。对于一些简单的用法是没问题的,不过有三个限制:最多3个参数、只有1%s、trace_pipe 全局共享,所以当前程序的输出会有不清晰的情况。更好的接口是利用BPF_PERF_OUTPUT(),而后覆盖。 -
return 0;: 必要的步骤 (参考 #139)。 -
.trace_print(): 常规的bcc 代码,读取 trace_pipe 并打印输出。
输出:bash-21720 是ls,11789 是执行C BPF 程序 ./monitor-exec
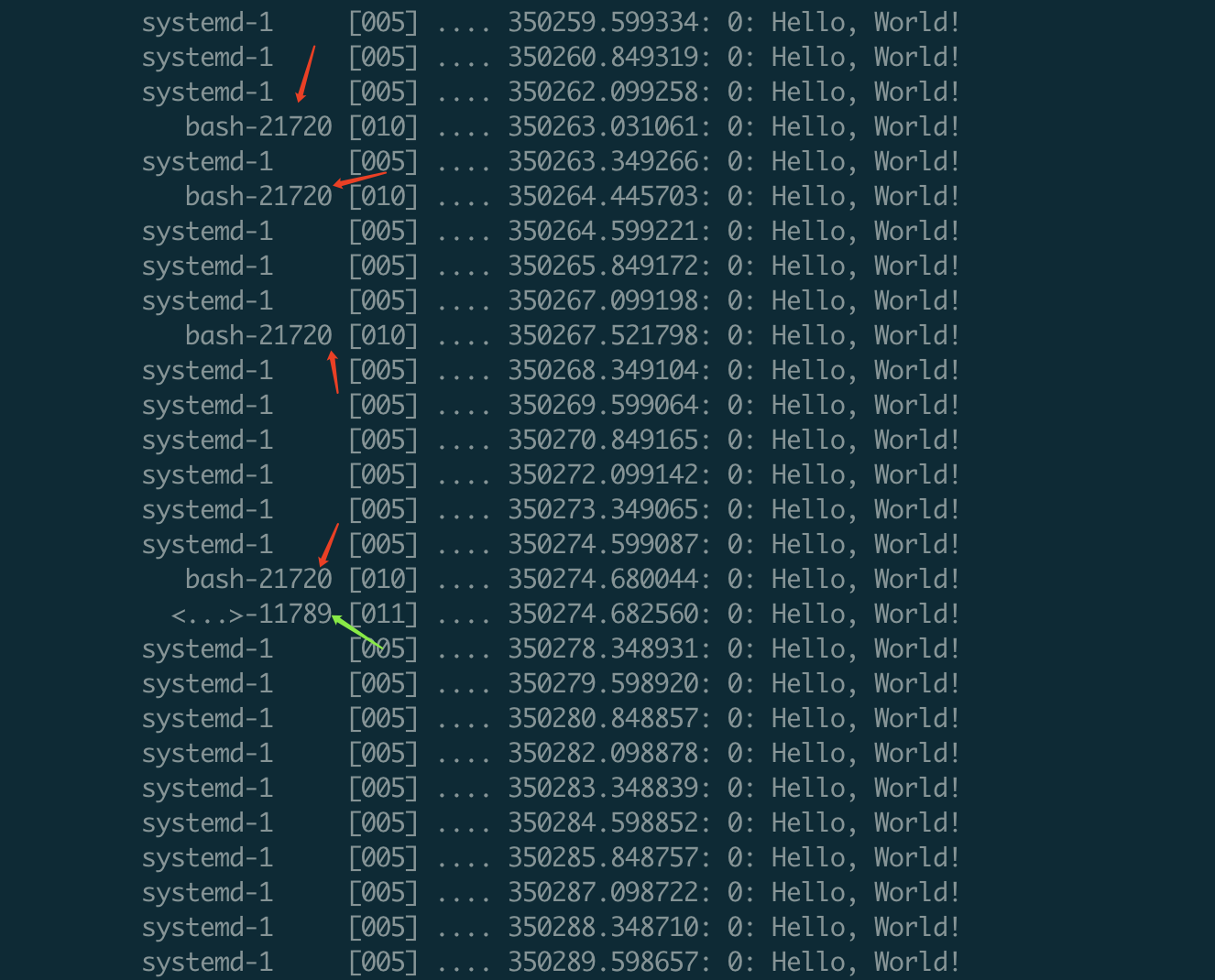
BPFTrace
BPFTrace 使用 LLVM 将脚本编译成 BPF 二进制码,后续使用 BCC 与 Linux 内核进行交互。
从功能层面上讲,BPFTrace 的定制性和灵活性不如 BCC,但是比 BCC 工具更加易于理解和使用,降低了 BPF 技术的使用门槛。
- 获取bpftrace 源码:git clone https://github.com/iovisor/bpftrace
- cd bpftrace
-
mkdir build; cd build; cmake -DCMAKE_BUILD_TYPE=Release .. -
make -j8 && make install
# 统计内核中函数堆栈的次数
# bpftrace -e 'profile:hz:99 { @[kstack] = count(); }'参考
- eBPF – Introduction, Tutorials & Community Resources
- eBPF 技术简介 | 云原生社区
- https://github.com/iovisor/bcc
- openEuler
Further Reading
- BPF and XDP Reference Guide — Cilium 1.11.0 documentation
- https://github.com/xdp-project/xdp-tutorial
eBPF 发展历程
- 1992年:BPF全称Berkeley Packet Filter,诞生初衷提供一种内核中自定义报文过滤的手段(类汇编),提升抓包效率。(tcpdump)
- 2011年:linux kernel 3.2版本对BPF进行重大改进,引入BPF JIT,使其性能得到大幅提升。
- 2014年: linux kernel 3.15版本,BPF扩展成eBPF,其功能范畴扩展至:内核跟踪、性能调优、协议栈QoS等方面。与之配套改进包括:扩展BPF ISA指令集、提供高级语言(C)编程手段、提供MAP机制、提供Help机制、引入Verifier机制等。
- 2016年:linux kernel 4.8版本,eBPF支持XDP,进一步拓展该技术在网络领域的应用。随后Netronome公司提出eBPF硬件卸载方案。
- 2018年:linux kernel 4.18版本,引入BTF,将内核中BPF对象(Prog/Map)由字节码转换成统一结构对象,这有利于eBPF对象与Kernel版本的配套管理,为eBPF的发展奠定基础。
- 2018年:从kernel 4.20版本开始,eBPF成为内核最活跃的项目之一,新增特性包括:sysctrl hook、flow dissector、struct_ops、lsm hook、ring buffer等。场景范围覆盖容器、安全、网络、跟踪等。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/191005.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
