大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
ebpf起源于bpf(Berkeley Packet Filter),bpf是一种网络过滤框架,为了向后兼容,现在也称为cbpf。
bpf和ebpf主要有以下不同。
bpf仅限于网络性能监控,ebpf已经扩展到内核追踪、性能监控和traffice control多个领域。向下,已经涵盖kprobe、tracepoinut、uprobe、profile和watchpoint等调试接口,向上又在接口设计和易用性上做了较大改进,目前主流使用工具为bcc和bpftrace。
同时,ebpf指令和寄存器的更接近于64位处理器,内核JIT编译的效率更高。数据通信方面,ebpf抛弃了bpf的socket通信机制,采用了map机制,更加丰富高效。
ebpf属于一种驻留在内核的虚拟机,本质是代码注入技术,通过注入控制逻辑实现用户的监控和调试目的,map机制用来实现用户和内核的数据交换和管理。本文主要通过简单bpftrace和bcc例子分析ebpf的prog注入流程和map机制。
prog注入流程:
- c代码控制逻辑通过llvm和clang编译成ebpf汇编程序
- 通过bpf系统调用加载ebpf的prog到内核,对ebpf程序进行verfify,通过之后再JIT在线编译成本机可执行指令
- 将JIT编译出的可执行程序关联到kprobe、tracepoint的hook上
看一个内核中标示prog的结构体:
struct bpf_prog {
u16 pages; /* 分配page数 */
u16 jited:1, /* prog是否已经jit过*/
jit_requested:1,/* 是否需要jit */
undo_set_mem:1, /* Passed set_memory_ro() checkpoint */
gpl_compatible:1, /* Is filter GPL compatible? */
cb_access:1, /* Is control block accessed? */
dst_needed:1, /* Do we need dst entry? */
blinded:1, /* 常量致盲 */
is_func:1, /* ebpf func? 大多数情况是 */
kprobe_override:1, /* 是否是overrided kprobe */
has_callchain_buf:1; /* callchain buffer allocated? */
enum bpf_prog_type type; /* prog类型,eg kprobe 、tracepoint*/
enum bpf_attach_type expected_attach_type; /* For some prog types */
u32 len; /* ebpf指令个数 */
u32 jited_len; /* ebpf汇编指令代码总长度 */
u8 tag[BPF_TAG_SIZE];
struct bpf_prog_aux *aux; /* Auxiliary fields */
struct sock_fprog_kern *orig_prog; /* Original BPF program */
unsigned int (*bpf_func)(const void *ctx,
const struct bpf_insn *insn);/* 存放jit后的可执行汇编 */
/* 不支持jit,需要模拟,x64支持jit,不需要模拟 */
union {
struct sock_filter insns[0]; /* 从用户态拷贝来的ebpf原程序 */
struct bpf_insn insnsi[0];
};
};
struct bpf_prog作为ebpf注入程序的载体,比较重要的是bpf_func成员,这个是ebpf程序jit后的本机可执行程序,是用户控制逻辑在内核中的体现,jited_len是其长度。insns存放从用户拷贝来的原ebpf汇编程序。
在看ebpf prog load流程之前先看下ebpf寄存器和x64的对应关系
ebpf从bpf的两个32位寄存器扩展到10个64位寄存器R0~R9和一个只读栈帧寄存器,并支持call指令,更加贴近现代64位处理器硬件
- R0对应rax, 函数返回值
- R1对应rdi, 函数参数1
- R2对应rsi, 函数参数2
- R3对应rdx, 函数参数3
- R4对应rcx, 函数参数4
- R5对应r8, 函数参数5
- R6对应rbx, callee保存
- R7对应r13, callee保存
- R8对应r14, callee保存
- R9对应r15, callee保存
- R10对应rbp,只读栈帧寄存器
可以看到x64的r9寄存器没有ebpf寄存器对应,所以ebpf函数最多支持5个参数。
看下ebpf prog的load流程:
bpf系统调用调用bpf_prog_load来加载ebpf程序。
bpf_prog_load大致有以下几步:
- 1.调用bpf_prog_alloc为prog申请内存,大小为struct bpf_prog大小+ebpf指令总长度
- 2.将ebpf指令复制到prog->insns
- 3.调用bpf_check对ebpf程序合法性进行检查,这是ebpf的安全性的关键所在,不符ebpf规则的load失败
- 4.调用bpf_prog_select_runtime在线jit,编译ebpf指令成x64指令
- 5.调用bpf_prog_alloc_id为prog生成id,作为prog的唯一标识的id被很多工具如bpftool用来查找prog
其中第4步的bpf_check函数会对ebpf程序进行各种检查,确保安全性,主要包括:
- 1.调用replace_map_fd_with_map_ptr将ebpf汇编中的fd替换为对应的map结构体地址。在需要map通信的之后,llvm和clang会使用map的fd来标识map机构体地址,并把fd作为参数给map helper输出函数使用,所以这里需要进行转换。这里需要构造个load 64-bit immediate nsn,就是两个指令,原指令和后面一个空白指令,把map结构体的地址分成前后32位分别存入这两条指令的imm域。可见在编译成ebpf指令的时候,load map fd的指令下一个指令是无效指令,供填充
- 2.check_subprogs检查所有条件跳转指令都位于相应subprog内(本ebpf函数内)。首先遍历prog中所有的指令,根据函数首地址,生成subprog(一个bebpf可能有多个函数),并对subprog以函数首地址以顺序的方式插入到subprog_info数组里去。最后遍历所有指令,确保所有的条件跳转指令必须位于本函数体地址之内。第一个subprog是bpf的main函数。bpf指令支持两种call调用,一种bpf函数对bpf函数的调用,一种是bpf中对内核helper func的调用。前者是指令class为BPF_JMP,指令opcode位BPF_CALL,并且src寄存器为BPF_PSEUDO_CALL,指令imm为callee函数到本指令的距离。另外一种是对对内核helper func的调用,指令class为特征是BPF_JMP,指令opcode为BPF_CALL,并且src_reg=0,指令imm在jit之前位内核helper func id,jit之后为对应的func到本指令的距离。
- 3.check_cfg采用深度优先算法确保函数分支不存在循环和存在执行不到的指令。
- 4.do_check函数检查寄存器和参数的合法性。在检查的过程中,以函数为维度会记录ebpf的10个寄存器和每个栈数据的访问权限状态,对于没有被读写过的寄存器,访问不被允许。写R10寄存器是非法的,R10寄存器对应x64的bp寄存器,但ebpf的是只读的。每个指令经过检查之后,更新寄存器和栈内存的权限状态。
- 5.check_max_stack_depth函数确保函数调用深度不超过8(MAX_CALL_FRAMES)。该函数遍历ebpf所有指令,并在遇到opcode是BPF_CALL指令并且src_reg是BPF_PSEUDO_CALL的指令(也就是ebpf函数对ebpf函数的调用)时候进行函数模拟调用,并记录调用深度和返回地址,函数执行完,返回上一层subprog,在这期间如果调用深度超过8或者最大栈消耗超过512字节,返回失败。
- 6.fixup_bpf_calls函数用于修正BPF_CALL指令(helper func调用)。
- 7.调用fix_call_args函数对多bpf函数的prog进行jit。这里注意,如果prog是包含多个ebpf函数,调用jit_subprogs函数进行jit。如果是单bpf函数的prog,函数返回。单bpf函数的prog的jit放到bpf_prog_select_runtime函数进行。
先看下第2步的check_subprogs函数:
static int check_subprogs(struct bpf_verifier_env *env)
{
int i, ret, subprog_start, subprog_end, off, cur_subprog = 0;
struct bpf_subprog_info *subprog = env->subprog_info;
struct bpf_insn *insn = env->prog->insnsi;
int insn_cnt = env->prog->len;
/* 添加main函数到env->subprog_info数组 */
ret = add_subprog(env, 0);
if (ret < 0)
return ret;
/* 遍历所有prog指令,只关注bpf到bpf函数调用,把所有的bpf函数以函数首地址为key升序加入env->subprog_info数组*/
for (i = 0; i < insn_cnt; i++) {
if (insn[i].code != (BPF_JMP | BPF_CALL))
continue;
if (insn[i].src_reg != BPF_PSEUDO_CALL)
continue;
if (!env->allow_ptr_leaks) {
verbose(env, "function calls to other bpf functions are allowed for root only\n");
return -EPERM;
}
/* 走到这里的都是bpf到bpf函数调用的call指令,i+insn[i].imm+1为调用子函数的首地址 */
ret = add_subprog(env, i + insn[i].imm + 1);
if (ret < 0)
return ret;
}
subprog[env->subprog_cnt].start = insn_cnt;
if (env->log.level > 1)
for (i = 0; i < env->subprog_cnt; i++)
verbose(env, "func#%d @%d\n", i, subprog[i].start);
/* 遍历prog所有指令,这次只关注跳转指令*/
/* 由于env->subprog_info数组里是以函数首地址升序排序, 那么,suprog_info[i].start和subprog_info[i+1].start就是第i个函数的其实地址*/
subprog_start = subprog[cur_subprog].start;
subprog_end = subprog[cur_subprog + 1].start;
for (i = 0; i < insn_cnt; i++) {
u8 code = insn[i].code;
if (BPF_CLASS(code) != BPF_JMP)
goto next;
if (BPF_OP(code) == BPF_EXIT || BPF_OP(code) == BPF_CALL)
goto next;
//走到这里的都是ebpf跳转指令,i+insn[i].off+1为跳转目的区
off = i + insn[i].off + 1;
//如果跳转范围超过本跳转指令所在函数的地址范围,verify失败
if (off < subprog_start || off >= subprog_end) {
e
verbose(env, "jump out of range from insn %d to %d\n", i, off);
return -EINVAL;
}
next:
//到达函数末尾,进行下一个函数
if (i == subprog_end - 1) {
/* to avoid fall-through from one subprog into another * the last insn of the subprog should be either exit * or unconditional jump back */
if (code != (BPF_JMP | BPF_EXIT) &&
code != (BPF_JMP | BPF_JA)) {
verbose(env, "last insn is not an exit or jmp\n");
return -EINVAL;
}
subprog_start = subprog_end;
cur_subprog++;
if (cur_subprog < env->subprog_cnt)
subprog_end = subprog[cur_subprog + 1].start;
}
}
return 0;
}
check_subprogs函数的逻辑比较简单,两轮循环,首先找出所有ebpf函数的首地址(不包括内核helper func的调用),然后把每个函数的首地址,按照升序插入到env->subprog_info数组。第二轮循环,遍历prog所有指令,确保所有的跳转指令的跳转范围位于本函数地址范围之内,否则失败。
再看第3步的check_cfg检查bpf 主函数是否存在循环。
这里采用非递归深度优先算法探测程序是否是DAG(Directed acyclic graph 有向无环图),即检测程序不存在循环。
借用网上的一张图来看下。
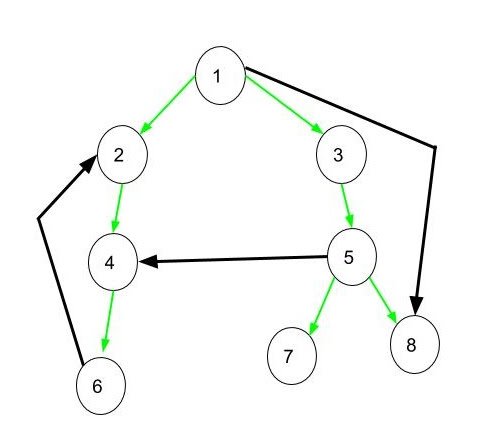

首先根据深度有优先算法将程序执行流转换成一个tree,这个tree可能存在四种tree edge:
tree edge:图中所有的绿色箭头都是正常的tree edge
forward edge:1->8的黑色箭头为forward edge
cross edge:5->4的黑色箭头属于cross edge
back edge : 6->2的黑色箭头为back edge,检测到back edge说明程序存在loop
static int check_cfg(struct bpf_verifier_env *env)
{
struct bpf_insn *insns = env->prog->insnsi;
int insn_cnt = env->prog->len;
int ret = 0;
int i, t;
//申请insn_stat跟踪指令的状态
insn_state = kcalloc(insn_cnt, sizeof(int), GFP_KERNEL);
if (!insn_state)
return -ENOMEM;
//保存当前执行流的指令,供push和pop用
insn_stack = kcalloc(insn_cnt, sizeof(int), GFP_KERNEL);
if (!insn_stack) {
kfree(insn_state);
return -ENOMEM;
}
insn_state[0] = DISCOVERED; /* mark 1st insn as discovered */
insn_stack[0] = 0; /* 0 is the first instruction */
cur_stack = 1;
//主循环,包含指令入栈和指令退栈
peek_stack:
if (cur_stack == 0)
goto check_state;
t = insn_stack[cur_stack - 1];//取的上次入栈的指令
//函数调用和跳转指令的class都是BPF_JMP
if (BPF_CLASS(insns[t].code) == BPF_JMP) {
u8 opcode = BPF_OP(insns[t].code);
if (opcode == BPF_EXIT) {
goto mark_explored;//遇到函数末尾,对执行过的指令进行explored标记,并退栈操作
} else if (opcode == BPF_CALL) {
//函数调用
//push_insn对函数调用的下一条指令入栈,如果入栈成功,标记函数调用指令的insn_state
//标记为DISCOVERED和FALLTHROGH,下一条指令为DISCOVERED,并返回1。
ret = push_insn(t, t + 1, FALLTHROUGH, env);
if (ret == 1)
goto peek_stack; //返回1,代表入入栈成功。跳转到peek_stack,获取本次入栈的指令,
//并对下一条指令继续入栈。
else if (ret < 0)
goto err_free;
if (t + 1 < insn_cnt)
env->explored_states[t + 1] = STATE_LIST_MARK;
if (insns[t].src_reg == BPF_PSEUDO_CALL) {
env->explored_states[t] = STATE_LIST_MARK;//对于bpf到bpf函数的调用,对callee函数
//也需要进行push_insn来进行入栈,对于kernel helper的函数调用这一步不需要
ret = push_insn(t, t + insns[t].imm + 1, BRANCH, env);
if (ret == 1)
goto peek_stack;
else if (ret < 0)
goto err_free;
}
} else if (opcode == BPF_JA) {
//无条件跳转,类似goto
if (BPF_SRC(insns[t].code) != BPF_K) {
//合法性检查
ret = -EINVAL;
goto err_free;
}
/* unconditional jump with single edge */
//无条件跳转指令只需要建立到跳转的分支的入栈操作
//因为永远不会执行到下一条指令,没必要模拟
ret = push_insn(t, t + insns[t].off + 1,
FALLTHROUGH, env);
if (ret == 1)
goto peek_stack;
else if (ret < 0)
goto err_free;
/* tell verifier to check for equivalent states * after every call and jump */
if (t + 1 < insn_cnt)
env->explored_states[t + 1] = STATE_LIST_MARK;
} else {
/* conditional jump with two edges */
//条件跳转两个分支都需要入栈模拟执行,因为两个分支
//都有可能执行到。这里深度优先算法先搜索false分支
env->explored_states[t] = STATE_LIST_MARK;
//false分支
ret = push_insn(t, t + 1, FALLTHROUGH, env);
if (ret == 1)
goto peek_stack;
else if (ret < 0)
goto err_free;
//true分支
ret = push_insn(t, t + insns[t].off + 1, BRANCH, env);
if (ret == 1)
goto peek_stack;
else if (ret < 0)
goto err_free;
}
} else {
/* all other non-branch instructions with single * fall-through edge */
//正常指令的入栈
ret = push_insn(t, t + 1, FALLTHROUGH, env);
if (ret == 1)
goto peek_stack;
else if (ret < 0)
goto err_free;
}
//遇到BPF_EXIT指令后,会触发一些列的退栈操作,会把每个
//退栈的指令标记为explored
mark_explored:
insn_state[t] = EXPLORED;
if (cur_stack-- <= 0) {
//退栈
verbose(env, "pop stack internal bug\n");
ret = -EFAULT;
goto err_free;
}
goto peek_stack;
//入栈之后在退栈,退栈完毕之后,才会执行到这里,也就是
//整个深度优先搜索完成
check_state:
//检查所有指令是否被执行过,如果没有,返回-EINVAL
//进而会导致整个bpf verify流程失败
for (i = 0; i < insn_cnt; i++) {
if (insn_state[i] != EXPLORED) {
verbose(env, "unreachable insn %d\n", i);
ret = -EINVAL;
goto err_free;
}
}
ret = 0; /* cfg looks good */
err_free:
kfree(insn_state);
kfree(insn_stack);
return ret;
}
push_insn函数负责指令入栈。t为当前指令index,w为下一条指令,也就是要入栈的指令。e可能是FALLTHROUGH代表当前指令到下一条指令是顺序执行,e为BRANCH代表w指令为条件跳转指令。
函数返回1,代表w成功入栈,当前为入栈过程。函数返回0,w不会入栈,当前为退栈流程。返回-EINVAl,代表跳转超出整个prog程序或者检测到loop。
static int push_insn(int t, int w, int e, struct bpf_verifier_env *env)
{
//退栈时候遇到tree edge的指令
if (e == FALLTHROUGH && insn_state[t] >= (DISCOVERED | FALLTHROUGH))
return 0;
//退栈时候遇到分支跳转指令
if (e == BRANCH && insn_state[t] >= (DISCOVERED | BRANCH))
return 0;
//跳转超出prog程序的范围
if (w < 0 || w >= env->prog->len) {
verbose_linfo(env, t, "%d: ", t);
verbose(env, "jump out of range from insn %d to %d\n", t, w);
return -EINVAL;
}
if (e == BRANCH)
/* mark branch target for state pruning */
env->explored_states[w] = STATE_LIST_MARK;
//入栈操作
if (insn_state[w] == 0) {
/* tree-edge */
insn_state[t] = DISCOVERED | e;
insn_state[w] = DISCOVERED;
if (cur_stack >= env->prog->len)
return -E2BIG;
insn_stack[cur_stack++] = w; //下条指令入栈
return 1;
//如果将要入栈的指令已经在栈中,出现loop
} else if ((insn_state[w] & 0xF0) == DISCOVERED) {
verbose_linfo(env, t, "%d: ", t);
verbose_linfo(env, w, "%d: ", w);
verbose(env, "back-edge from insn %d to %d\n", t, w);
return -EINVAL;
//将要执行的指令被执行过,但不在栈中,出现那么就是forward-edge或者cross-edge,
//这种情况不构成loop。需要注意的是,这种代表下一条指令已经被执行过。不必在对这条指令压栈
//因为之前的检查已经模拟执行过,没有问题。遇到这种情况相当于BPF_EXIT,可以触发退栈操作。
} else if (insn_state[w] == EXPLORED) {
/* forward- or cross-edge */
insn_state[t] = DISCOVERED | e;
} else {
verbose(env, "insn state internal bug\n");
return -EFAULT;
}
return 0;
}
check_cfg从prog第一条指令开始进行模拟执行,遇到函数调用先执行函数后的程序,再执行函数体,遇到条件跳转,先false分支,在true分支。因为是深度优先,每个分支的指令都会进行入栈,并执行到底,直到遇到BPF_EXIT指令。遇到BPF_EXIT开始退栈操作,遇到分支,在深度搜索相邻分支。
每次退栈操作会调用push_insn函数尝试把退栈指令下一条指令入栈,对于非分支或者非调用指令,因为指令已经执行过,push_insn指令会返回0,会继续退栈。如果遇到分支处理指令,对于已经处理分支,push_insn返回0,会继续把另一分支指令入栈,push_insn返回1,入栈成功,这时候会进入另外分支的深度遍历操作。push_insn还会检测到超过prog程序范围跳转,会返回-EINVAL。
入栈指令会标记为DISCOVERD,代表指令在栈中,每次退栈之后,指令被标记位EXPLORED,代表该指令被执行过,但不在栈中。如果当前执行的指令的下一条指令是正在栈中(DISCOVERED状态),检测到loop。
在函数最后,深度优先搜索完毕,如果有指令不是EXPLORED,说明没有被执行到过,verify失败。
最后,check_cfq函数同样可以检测函数递归的情况,递归调用是种特殊的back-edge。
看第3步的do_check函数,这个函数比较长,不在贴代码,只是根据自己理解,说下流程。
do_check函数遍历所有prog的指令,主要用于检测指令的访问权限的合法性。
do_check函数的框架,主要是将每个跳转分支为一级维度进行遍历,遇到分支,先处理本分支本分支,other分支入栈,同时在分支处理过程中,如果遇到函数调用,在以函数调用为二级维度对函数返回地址进行压栈。函数执行完也就是遇到BPF_EXIT指令,执行函数返回处理,如果本分支的所有函数都已出栈,那么遇到BPF_EXIT指令,会出栈本分支的other分支,继续处理。
do_check以函数调用维度来维护10寄存和本函数所有栈内存器的访问权限和状态。记录到strut bpf_func_state:
struct bpf_func_state {
struct bpf_reg_state regs[MAX_BPF_REG]; //10个寄存器的访问权限和liveness
int callsite; //当前流程调用本函数的调用指令index
u32 frameno; //当前函数调用深度
u32 subprogno; //本函数在env->subprog_info中的index
int acquired_refs;
struct bpf_reference_state *refs;
int allocated_stack; //当前函数的栈的最大消耗
struct bpf_stack_state *stack; //本函数所有栈的访问权限和状态
};
对于bpf_reg_state的type有以下状态:
enum bpf_reg_type {
NOT_INIT = 0, /* 寄存器包含无效值,不允许read*/
SCALAR_VALUE, /* 寄存器包含有效值,但不是有效指针*/
PTR_TO_CTX, /* 指向struct bpf_context */
CONST_PTR_TO_MAP, /* 指向struct bpf_map */
PTR_TO_MAP_VALUE, /* 指向 map element value */
PTR_TO_MAP_VALUE_OR_NULL,/* 指向map elem value 或者null */
PTR_TO_STACK, /* 指向bpf栈数据 */
PTR_TO_PACKET_META, /* 指向skb->data - meta_len */
PTR_TO_PACKET, /* 指向to skb->data */
PTR_TO_PACKET_END, /* 指向skb->data + headlen */
PTR_TO_FLOW_KEYS, /* 指向bpf_flow_keys */
PTR_TO_SOCKET, /* 指向struct bpf_sock */
PTR_TO_SOCKET_OR_NULL, /* 指向struct bpf_sock*/
};
对于bpf_stack_state有以下几种类型:
enum bpf_stack_slot_type {
STACK_INVALID, /* 栈slot无有效数据*/
STACK_SPILL, /* spill类型指针 */
STACK_MISC, /* 包含有效数据,但不是合法指针类型*/
STACK_ZERO, /* 为常数0*/
};
其中STACK_SPILL类型的是栈slot保存了如下类型的合法指针:
- CONST_PTR_TO_MAP, /* 指向struct bpf_map */
- PTR_TO_MAP_VALUE, /* 指向 map element value */
- PTR_TO_MAP_VALUE_OR_NULL,/* 指向map elem value 或者null */
- PTR_TO_STACK, /* 指向bpf栈数据 */
- PTR_TO_PACKET_META, /* 指向skb->data – meta_len */
- PTR_TO_PACKET, /* 指向to skb->data */
- PTR_TO_PACKET_END, /* 指向skb->data + headlen */
- PTR_TO_FLOW_KEYS, /* 指向bpf_flow_keys */
- PTR_TO_SOCKET, /* 指向struct bpf_sock */
以PTR_TO_STACK类型的数据,也就是栈数据的访问类型权限检查为例看下BPF_LDX和BPF_STX两类指令,分别是读写栈内存的指令。
BPF_LDX是bpf的64位读内存指令,假设读的是栈内存。此时insn->src_reg为BPF_REG_10,insn->src_reg->off是指源寄存器内容相对栈帧寄存器的偏移,insn->off代表本次load要从insn->src_reg指向的区域的多大偏移开始读。do_check开始会调用init_reg_state函数对所有寄存器类型最初始化。看下这个函数:
static void init_reg_state(struct bpf_verifier_env *env,
struct bpf_func_state *state)
{
struct bpf_reg_state *regs = state->regs;
int i;
for (i = 0; i < MAX_BPF_REG; i++) {
mark_reg_not_init(env, regs, i); //设置10个寄存器的类型位NOT_INIT,全部不可读
regs[i].live = REG_LIVE_NONE;
regs[i].parent = NULL;
}
/*设置栈帧寄存器类型为PTR_TO_STACK*/
regs[BPF_REG_FP].type = PTR_TO_STACK;
mark_reg_known_zero(env, regs, BPF_REG_FP);
regs[BPF_REG_FP].frameno = state->frameno;
/* 设置prog第一个参数R1寄存器类型为PTR_TO_CTX,也就是pt_regs结构体 */
regs[BPF_REG_1].type = PTR_TO_CTX;
mark_reg_known_zero(env, regs, BPF_REG_1);
}
可见,在刚开始,只有栈帧寄存器和prog第一个入参R1是可读的。
do_check函数遍历到BPF_LDX指令的时候,首先调用 check_reg_arg(env, insn->src_reg, SRC_OP)检查R10寄存器是否可读,看它是否是NOT_INIT状态,是的话代表不可读,返回失败,这里R10寄存器为PTR_TO_STACK,check_reg_arg返回成功。
然后调用check_mem_access函数检查,具体要读的栈数据是否可读。看下这个函数,只看PTR_TO_STACK检查相关的:
static int check_mem_access(struct bpf_verifier_env *env, int insn_idx, u32 regno,
int off, int bpf_size, enum bpf_access_type t,
int value_regno, bool strict_alignment_once)
{
struct bpf_reg_state *regs = cur_regs(env);
struct bpf_reg_state *reg = regs + regno;
struct bpf_func_state *state;
int size, err = 0;
size = bpf_size_to_bytes(bpf_size);
if (size < 0)
return size;
/* alignment checks will add in reg->off themselves */
err = check_ptr_alignment(env, reg, off, size, strict_alignment_once);
if (err)
return err;
......
if (reg->type == PTR_TO_STACK) {
off += reg->var_off.value;
err = check_stack_access(env, reg, off, size);
if (err)
return err;
state = func(env, reg);
err = update_stack_depth(env, state, off);
if (err)
return err;
if (t == BPF_WRITE)
err = check_stack_write(env, state, off, size,
value_regno, insn_idx);
else
err = check_stack_read(env, state, off, size,
}
......
}
首先调用check_ptr_alignment函数检查指针的对齐访问,不对齐不被允许。
分别看下,check_stack_access函数、check_stack_depth函数和check_stack_read函数:
static int check_stack_access(struct bpf_verifier_env *env,
const struct bpf_reg_state *reg,
int off, int size)
{
//对栈的访问,偏移必须是常量固定的,不能是指针
if (!tnum_is_const(reg->var_off)) {
char tn_buf[48];
tnum_strn(tn_buf, sizeof(tn_buf), reg->var_off);
verbose(env, "variable stack access var_off=%s off=%d size=%d",
tn_buf, off, size);
return -EACCES;
}
//栈是递减栈,off必须小于等于零,并且绝对值偏移需小于512字节(prog最大栈允许)
if (off >= 0 || off < -MAX_BPF_STACK) {
verbose(env, "invalid stack off=%d size=%d\n", off, size);
return -EACCES;
}
return 0;
}
check_stack_access函数主要检查偏移是否为固定偏移,并看栈偏移否超过最大栈大小(512字节)。
static int update_stack_depth(struct bpf_verifier_env *env,
const struct bpf_func_state *func,
int off)
{
u16 stack = env->subprog_info[func->subprogno].stack_depth;
if (stack >= -off)
return 0;
/* 如果这次对栈的访问地址超出本函数目前的栈消耗,那么扩充之*/
env->subprog_info[func->subprogno].stack_depth = -off;
return 0;
}
这个函数维护了每个函数对栈的最大消耗,并记录到subprog_info数组里相应函数的stack_depth里,这个值在check_max_stack_depth函数模拟函数调用里会用来判断栈的当前所有栈消耗是否超标。
看下check_stack_read函数:
static int check_stack_read(struct bpf_verifier_env *env,
struct bpf_func_state *reg_state /* func where register points to */,
int off, int size, int value_regno)
{
struct bpf_verifier_state *vstate = env->cur_state;
struct bpf_func_state *state = vstate->frame[vstate->curframe];
int i, slot = -off - 1, spi = slot / BPF_REG_SIZE;
u8 *stype;
//这里的off是insn->off和insn->src_reg->off的和,如果栈访问地址超过本次函数的栈最大用度,非法
if (reg_state->allocated_stack <= slot) {
verbose(env, "invalid read from stack off %d+0 size %d\n",
off, size);
return -EACCES;
}
stype = reg_state->stack[spi].slot_type;
if (stype[0] == STACK_SPILL) {
//如果STACK_SPILL是指的是栈里保存的是bpf几种类型的合法指针,如果部分读取,失败
if (size != BPF_REG_SIZE) {
verbose(env, "invalid size of register spill\n");
return -EACCES;
}
//对于STACK_SPILL类型的,8个slot所有类型必须都是STACK_SPILL
for (i = 1; i < BPF_REG_SIZE; i++) {
if (stype[(slot - i) % BPF_REG_SIZE] != STACK_SPILL) {
verbose(env, "corrupted spill memory\n");
return -EACCES;
}
}
if (value_regno >= 0) {
//检查成功后,更新src_dest的reg state到dst reg
state->regs[value_regno] = reg_state->stack[spi].spilled_ptr;
state->regs[value_regno].live |= REG_LIVE_WRITTEN;
}
mark_reg_read(env, ®_state->stack[spi].spilled_ptr,
reg_state->stack[spi].spilled_ptr.parent);
return 0;
} else {
int zeros = 0;
//对于非STACK_SPILL类型的,以次检测每个要读取的字节对应的slot,
//size要读取的字节数,可以小于8,要求每个要读取的字节要么STACK_MISC,要么是0,
//如果是STACK_INVALID,不可读,失败
for (i = 0; i < size; i++) {
if (stype[(slot - i) % BPF_REG_SIZE] == STACK_MISC)
continue;
if (stype[(slot - i) % BPF_REG_SIZE] == STACK_ZERO) {
zeros++;
continue;
}
verbose(env, "invalid read from stack off %d+%d size %d\n",
off, i, size);
return -EACCES;
}
mark_reg_read(env, ®_state->stack[spi].spilled_ptr,
reg_state->stack[spi].spilled_ptr.parent);
if (value_regno >= 0) {
if (zeros == size) {
//如果所有读取的字节均是0,标记dst寄存器值为0,类型为SCALAR_VALUE
__mark_reg_const_zero(&state->regs[value_regno]);
} else {
//如果读取的数据不全为0,标记dst寄存器类型为SCALAR_VALUE。
mark_reg_unknown(env, state->regs, value_regno);
}
state->regs[value_regno].live |= REG_LIVE_WRITTEN;
}
return 0;
}
}
check_stack_read函数从以下几个方面进行读权限检查:
- 栈偏移不能超过当前函数最大栈消耗
- 如果栈内存类型位STACK_SPILL类型,那么不支持非对齐当问和部分读取,并且栈内存所在的8个字节全部应该是STACK_SPILLl类型。
- 如果是非STACK_SPILL类型,需要确保要读取的栈数据必须要么是TACK_MISC类型或者STACK_ZERO类型,或者兼有二者。非STACK_SPILL类型的栈支持部分读取。最后设置dst寄存器为SCALER_VALUE类型。
最后需要注意,bpf_stack_state中slot_type数组低地址保存的实际栈数据高地址栈数据的访问类型
对于BPF_STX指令,如果目的寄存器为BPF_REG_10,那么需要调用check_stack_write函数类检查栈内存的可写权限:
static int check_stack_write(struct bpf_verifier_env *env,
struct bpf_func_state *state, /* func where register points to */
int off, int size, int value_regno, int insn_idx)
{
struct bpf_func_state *cur; /* state of the current function */
int i, slot = -off - 1, spi = slot / BPF_REG_SIZE, err;
enum bpf_reg_type type;
//如果这次对栈内存的写导致栈扩展,那么需要重新申请bpf_stack_state内存,
//因为栈变大,用于跟踪栈数据状态的内存不够了
err = realloc_func_state(state, round_up(slot + 1, BPF_REG_SIZE),
state->acquired_refs, true);
if (err)
return err;
//如果栈数据保存的合法的指针类型,但这次写是部分写,这会写坏指针,不允许非特权用户这么做
if (!env->allow_ptr_leaks &&
state->stack[spi].slot_type[0] == STACK_SPILL &&
size != BPF_REG_SIZE) {
verbose(env, "attempt to corrupt spilled pointer on stack\n");
return -EACCES;
}
cur = env->cur_state->frame[env->cur_state->curframe];
if (value_regno >= 0 &&
is_spillable_regtype((type = cur->regs[value_regno].type))) {
//对于源寄存器是STACK_SPILL的情况,部分写不允许
if (size != BPF_REG_SIZE) {
verbose(env, "invalid size of register spill\n");
return -EACCES;
}
if (state != cur && type == PTR_TO_STACK) {
verbose(env, "cannot spill pointers to stack into stack frame of the caller\n");
return -EINVAL;
}
/* save register state */
state->stack[spi].spilled_ptr = cur->regs[value_regno];
state->stack[spi].spilled_ptr.live |= REG_LIVE_WRITTEN;
for (i = 0; i < BPF_REG_SIZE; i++) {
if (state->stack[spi].slot_type[i] == STACK_MISC &&
!env->allow_ptr_leaks) {
int *poff = &env->insn_aux_data[insn_idx].sanitize_stack_off;
int soff = (-spi - 1) * BPF_REG_SIZE;
if (*poff && *poff != soff) {
/* disallow programs where single insn stores * into two different stack slots, since verifier * cannot sanitize them */
verbose(env,
"insn %d cannot access two stack slots fp%d and fp%d",
insn_idx, *poff, soff);
return -EINVAL;
}
*poff = soff;
}
//源寄存包含是合法的bpf指针类型,设置栈数据类型为STACK_SPILL类型
state->stack[spi].slot_type[i] = STACK_SPILL;
}
} else {
//源寄存器包含是非有效指针的情况
u8 type = STACK_MISC;
state->stack[spi].spilled_ptr.type = NOT_INIT;
//如果栈内存是是STACK_SPILL类型,因为写入不是指针,所以需要设置为STACK_MISC
//代表栈包含非指针、非零变量,这前面不矛盾,走到这里是特权用户
if (state->stack[spi].slot_type[0] == STACK_SPILL)
for (i = 0; i < BPF_REG_SIZE; i++)
state->stack[spi].slot_type[i] = STACK_MISC;
/* only mark the slot as written if all 8 bytes were written * otherwise read propagation may incorrectly stop too soon * when stack slots are partially written. * This heuristic means that read propagation will be * conservative, since it will add reg_live_read marks * to stack slots all the way to first state when programs * writes+reads less than 8 bytes */
if (size == BPF_REG_SIZE)
state->stack[spi].spilled_ptr.live |= REG_LIVE_WRITTEN;
if (value_regno >= 0 &&
register_is_null(&cur->regs[value_regno]))
type = STACK_ZERO;
//如果源寄存器为0,标记所写栈slot的类型位STACK_ZERO,否则STACK_MISC
for (i = 0; i < size; i++)
state->stack[spi].slot_type[(slot - i) % BPF_REG_SIZE] =
type;
}
return 0;
}
check_stack_write函数对栈内存进行以下检查:
- 如果此次写超过本函数的目前最大用度(allocated_stack),需要重新申请bpf_stack_state内存,bpf_stack_state需要记录每个栈数据的访问权限,内存不够了
- 对于非特权用户,不允许部分写STACK_SPILL类型的栈数据
- 对于源寄存器是STACK_SPILL的情况,并且是部分写栈数据,不被允许。8字节全写的话,最后需要标记栈数据8个字节全部为STACK_SPILL类型
- 对于源寄存器是非STACK_SPILL的情况,根据源寄存器和写入字节的情况设置栈数据相应的slot类型为STACK_ZERO或者STACK_MISC,非STACK_SPILL的情况支持部分写的
最后需要注意的是,bpf_stack_state中slot_type数组低地址保存的实际栈数据高地址栈数据的访问类型
看下第5步的check_max_stack_depth函数:
static int check_max_stack_depth(struct bpf_verifier_env *env)
{
int depth = 0, frame = 0, idx = 0, i = 0, subprog_end;
struct bpf_subprog_info *subprog = env->subprog_info;
struct bpf_insn *insn = env->prog->insnsi;
int ret_insn[MAX_CALL_FRAMES]; //函数返回地址
int ret_prog[MAX_CALL_FRAMES]; //保存返回函数的idx
process_func:
/* round up to 32-bytes, since this is granularity * of interpreter stack size */
depth += round_up(max_t(u32, subprog[idx].stack_depth, 1), 32); //stack_depth是本层函数对栈最大的消耗
if (depth > MAX_BPF_STACK) {
//超过MAX_BPF_STACK(512),verify失败
verbose(env, "combined stack size of %d calls is %d. Too large\n",
frame + 1, depth);
return -EACCES;
}
//取下一个函数。subprog[0]是主函数
continue_func:
subprog_end = subprog[idx + 1].start;
for (; i < subprog_end; i++) {
if (insn[i].code != (BPF_JMP | BPF_CALL))
continue;
if (insn[i].src_reg != BPF_PSEUDO_CALL)
continue;
//只有BPF之间函数调用指令才会走到这里
/* remember insn and function to return to */
ret_insn[frame] = i + 1; //函数调用返回地址
ret_prog[frame] = idx; //当前函数idx
/* find the callee */
i = i + insn[i].imm + 1; //调用函数callee的地址
idx = find_subprog(env, i); //根据callee地址查找callee的idx
if (idx < 0) {
WARN_ONCE(1, "verifier bug. No program starts at insn %d\n",
i);
return -EFAULT;
}
frame++;
if (frame >= MAX_CALL_FRAMES) {
//函数调用深度大于8,verify失败
WARN_ONCE(1, "verifier bug. Call stack is too deep\n");
return -EFAULT;
}
goto process_func;
}
/* end of for() loop means the last insn of the 'subprog' * was reached. Doesn't matter whether it was JA or EXIT */
走到这里,当前函数已经执行完了,函数需要返回上一层
if (frame == 0)
return 0;
depth -= round_up(max_t(u32, subprog[idx].stack_depth, 1), 32);
frame--;
i = ret_insn[frame]; //弹出函数返回地址
idx = ret_prog[frame]; //弹出上层函数的idx
goto continue_func; //返回上层函数
}
函数里已经注释,该函数遍历prog的指令,只关注函数调用,模拟所有函数调用,检查函数调用深度是否超过 MAX_CALL_FRAMES(8),并检查栈的消耗是否超过MAX_BPF_STACK(512)。
看下第6步的fixup_bpf_calls函数:
static int fixup_bpf_calls(struct bpf_verifier_env *env)
{
struct bpf_prog *prog = env->prog;
struct bpf_insn *insn = prog->insnsi;
const struct bpf_func_proto *fn;
const int insn_cnt = prog->len;
const struct bpf_map_ops *ops;
struct bpf_insn_aux_data *aux;
struct bpf_insn insn_buf[16];
struct bpf_prog *new_prog;
struct bpf_map *map_ptr;
int i, cnt, delta = 0;
for (i = 0; i < insn_cnt; i++, insn++) {
if (insn->code == (BPF_ALU64 | BPF_MOD | BPF_X) ||
insn->code == (BPF_ALU64 | BPF_DIV | BPF_X) ||
insn->code == (BPF_ALU | BPF_MOD | BPF_X) ||
insn->code == (BPF_ALU | BPF_DIV | BPF_X)) {
bool is64 = BPF_CLASS(insn->code) == BPF_ALU64;
struct bpf_insn mask_and_div[] = {
BPF_MOV32_REG(insn->src_reg, insn->src_reg),
/* Rx div 0 -> 0 */
BPF_JMP_IMM(BPF_JNE, insn->src_reg, 0, 2),
BPF_ALU32_REG(BPF_XOR, insn->dst_reg, insn->dst_reg),
BPF_JMP_IMM(BPF_JA, 0, 0, 1),
*insn,
};
struct bpf_insn mask_and_mod[] = {
BPF_MOV32_REG(insn->src_reg, insn->src_reg),
/* Rx mod 0 -> Rx */
BPF_JMP_IMM(BPF_JEQ, insn->src_reg, 0, 1),
*insn,
};
struct bpf_insn *patchlet;
if (insn->code == (BPF_ALU64 | BPF_DIV | BPF_X) ||
insn->code == (BPF_ALU | BPF_DIV | BPF_X)) {
patchlet = mask_and_div + (is64 ? 1 : 0);
cnt = ARRAY_SIZE(mask_and_div) - (is64 ? 1 : 0);
} else {
patchlet = mask_and_mod + (is64 ? 1 : 0);
cnt = ARRAY_SIZE(mask_and_mod) - (is64 ? 1 : 0);
}
new_prog = bpf_patch_insn_data(env, i + delta, patchlet, cnt);
if (!new_prog)
return -ENOMEM;
delta += cnt - 1;
env->prog = prog = new_prog;
insn = new_prog->insnsi + i + delta;
continue;
}
.....................................................................................................
switch (insn->imm) {
case BPF_FUNC_map_lookup_elem:
insn->imm = BPF_CAST_CALL(ops->map_lookup_elem) -
__bpf_call_base;
continue;
case BPF_FUNC_map_update_elem:
insn->imm = BPF_CAST_CALL(ops->map_update_elem) -
__bpf_call_base;
continue;
case BPF_FUNC_map_delete_elem:
insn->imm = BPF_CAST_CALL(ops->map_delete_elem) -
__bpf_call_base;
continue;
case BPF_FUNC_map_push_elem:
insn->imm = BPF_CAST_CALL(ops->map_push_elem) -
__bpf_call_base;
continue;
case BPF_FUNC_map_pop_elem:
insn->imm = BPF_CAST_CALL(ops->map_pop_elem) -
__bpf_call_base;
continue;
case BPF_FUNC_map_peek_elem:
insn->imm = BPF_CAST_CALL(ops->map_peek_elem) -
__bpf_call_base;
continue;
}
goto patch_call_imm;
}
patch_call_imm:
fn = env->ops->get_func_proto(insn->imm, env->prog);
/* all functions that have prototype and verifier allowed * programs to call them, must be real in-kernel functions */
if (!fn->func) {
verbose(env,
"kernel subsystem misconfigured func %s#%d\n",
func_id_name(insn->imm), insn->imm);
return -EFAULT;
}
insn->imm = fn->func - __bpf_call_base;
}
6845,21-24 94%
这个函数主要处理两个问题,一个BPF_MOD和BPF_DIV的除0问题,一个是修正BPF_CALL指令的跳转距离的问题。
20-26 行,将一个BPF_DIV指令扩展为4个指令,如果源操作位0,dst置0,调到本指令的下一行执行,否则执行原指令。
28-32行,将一个BPF_MOD指令扩展为两个指令,如果源操作数为零,目的操作数保持不变,调到原指令下一行执行,否则执行原指令。
45-52行,将扩展的指令替换原指令,如果有必要需要重新申请prog空间。
55-100行,用来修正BPF_CALL指令的跳转距离。ebpf访问内核数据结构是受限的,需要通过调用相应的helper func来完成。ebpf指令格式如下:
struct bpf_insn {
__u8 code; /* opcode */
__u8 dst_reg:4; /* dest register */
__u8 src_reg:4; /* source register */
__s16 off; /* signed offset */
__s32 imm; /* signed immediate constant */
};
ebpf指令类似RISC,除了BPF_LD_IMM64指令是16字节之外,其余每个指令8个字节,对于BPF_CALL指令来说imm就是调用函数到本指令的距离。
根据imm中的func id找到内核中对应的BPF_FUNC开头的helper func函数,然后把该函数地址减去内核符号__bpf_call_base的地址得出新的offset,结果在写到bpf_insn的imm里,完成BPF_CALL指令的修正。这个明显不是正确的offset,正确的offset应该是目标函数和本条指令地址的距离,真正的修正是在JIT里。
通过一个bpftrace例子来看下。
#include <linux/fs.h>
#include <linux/path.h>
#include <linux/blk_types.h>
#include <linux/sched.h>
BEGIN
{
printf("Tracing dcache lookups... Hit Ctrl-C to end.\n");
printf("%-8s %-6s %-16s %1s %s\n", "TIME", "PID", "COMM", "T", "FILE");
}
// comment out this block to avoid showing hits:
kprobe:vfs_write
{
$file = (struct file *)arg0;
printf("ino %ld!\n",$file->f_inode->i_ino);
}
通过kprobe探测通过vfs_write函数,打印文件的ino。运行一下。执行,
[root@111-11-11-11 my_examples]# bpftool perf
pid 27290 fd 4: prog_id 19 uprobe filename /proc/self/exe offset 1935000
pid 27290 fd 63: prog_id 20 kprobe func vfs_write offset 0
bpftool查看下ebpf的prog的汇编
[root@11-11-11-11 my_examples]# bpftool prog dump xlate id 20
0: (bf) r6 = r1 //r1为pt_regs机构体
1: (79) r3 = *(u64 *)(r6 +112) // r3 = regs->di,strut file地址
2: (b7) r1 = 2
3: (7b) *(u64 *)(r10 -24) = r1
4: (07) r3 += 32 // r3 = file->inode,参数3
5: (bf) r1 = r10
6: (07) r1 += -8 //栈局部变量 (r10-8) 参数1
7: (b7) r2 = 8 //拷贝字节 参数2
8: (85) call bpf_probe_read#-46816
9: (79) r3 = *(u64 *)(r10 -8) //(r10-8)存放bpf_probe_read读取的file->inode副本结果,r3=inode
10: (07) r3 += 64 //r3=inode->i_ino地址
11: (bf) r1 = r10
12: (07) r1 += -8 //(r10-8)栈局部变量
13: (b7) r2 = 8 //拷贝字节 参数2
14: (85) call bpf_probe_read#-46816
15: (79) r1 = *(u64 *)(r10 -8) //r1为读取的inode->ino
16: (7b) *(u64 *)(r10 -16) = r1
17: (18) r7 = map[id:6]
19: (85) call bpf_get_smp_processor_id#76416 //这是一个无效指令,供上条指令扩展填充,扩展后imm存map地址低32位
20: (bf) r4 = r10
21: (07) r4 += -24 //参数4
22: (bf) r1 = r6 // 参数1 r1=struct ptr_reg
23: (bf) r2 = r7 // 参数2 r2 = map地址
24: (bf) r3 = r0 //参数3 flag
25: (b7) r5 = 16 // 参数4 输出拷贝字节,ino是8字节,这里多拷贝前8个字节
26: (85) call bpf_perf_event_output#-45376
27: (b7) r0 = 0
28: (95) exit
第8、14和26行,为ebpf调用内核helper 函数,#后面的数字经验证等于helper func的地址减去__bpf_call_base的差值。在llvm和clang编译好之后,这的imm应该是helper func id ,在fixup_bpf_call里然后根据func id找真正的helper func,最后把函数地址和__bpf_call_base的差值给imm。这个是在运行的bpf prog,可见是转换过的。
看下第7步的的fixup_call_args函数,该函数调用了jit_subprogs函数,直接看这个函数:
static int jit_subprogs(struct bpf_verifier_env *env)
{
struct bpf_prog *prog = env->prog, **func, *tmp;
int i, j, subprog_start, subprog_end = 0, len, subprog;
struct bpf_insn *insn;
void *old_bpf_func;
int err;
//prog只有一个bpf函数,不做处理
if (env->subprog_cnt <= 1)
return 0;
//遍历prog的指令,只处理bpf到bpf的调用情况
for (i = 0, insn = prog->insnsi; i < prog->len; i++, insn++) {
if (insn->code != (BPF_JMP | BPF_CALL) ||
insn->src_reg != BPF_PSEUDO_CALL)
continue;
//根据调用地址找到被调用子程序的所在的subinfo数组的内的索引subprog,保存subprog到指令的insn->off里
subprog = find_subprog(env, i + insn->imm + 1);
if (subprog < 0) {
WARN_ONCE(1, "verifier bug. No program starts at insn %d\n",
i + insn->imm + 1);
return -EFAULT;
}
insn->off = subprog;
env->insn_aux_data[i].call_imm = insn->imm;
insn->imm = 1;
}
err = bpf_prog_alloc_jited_linfo(prog);
if (err)
goto out_undo_insn;
err = -ENOMEM;
func = kcalloc(env->subprog_cnt, sizeof(prog), GFP_KERNEL);
if (!func)
goto out_undo_insn;
//为每个subprog申请内存并根据父prog对其进行初始化
for (i = 0; i < env->subprog_cnt; i++) {
subprog_start = subprog_end; //subprog开始指令index
subprog_end = env->subprog_info[i + 1].start; //subprog结束指令index
len = subprog_end - subprog_start; //subprog指令长度
func[i] = bpf_prog_alloc(bpf_prog_size(len), GFP_USER); //申请struct bpf_prog结构体
if (!func[i])
goto out_free; memcpy(func[i]->insnsi, &prog->insnsi[subprog_start],
len * sizeof(struct bpf_insn));
func[i]->type = prog->type;
func[i]->len = len;
if (bpf_prog_calc_tag(func[i]))
goto out_free;
func[i]->is_func = 1;
func[i]->aux->func_idx = i;
func[i]->aux->btf = prog->aux->btf;
func[i]->aux->func_info = prog->aux->func_info;
func[i]->aux->name[0] = 'F';
func[i]->aux->stack_depth = env->subprog_info[i].stack_depth; //栈消耗
func[i]->jit_requested = 1; //需要jit
func[i]->aux->linfo = prog->aux->linfo;
func[i]->aux->nr_linfo = prog->aux->nr_linfo;
func[i]->aux->jited_linfo = prog->aux->jited_linfo;
func[i]->aux->linfo_idx = env->subprog_info[i].linfo_idx;
func[i] = bpf_int_jit_compile(func[i]); //对该subprog进行jit,后面在看这个函数
if (!func[i]->jited) {
err = -ENOTSUPP;
goto out_free;
}
cond_resched();
}
//修正bpf到bpf函数调用距离
for (i = 0; i < env->subprog_cnt; i++) {
for (i = 0; i < env->subprog_cnt; i++) {
insn = func[i]->insnsi;
for (j = 0; j < func[i]->len; j++, insn++) {
if (insn->code != (BPF_JMP | BPF_CALL) ||
insn->src_reg != BPF_PSEUDO_CALL)
continue;
//调用距离为调用子函数到__bpf_call_base地址的距离,这个和调用内核helper func的统一。
//这个距离明显不是正确的,正确的调用距离位为调用函数子函数到本指令的距离,这个会在bpf_int_jit_compile函数里处理
//因为后面还会进入bpf_int_jit_compile函数
subprog = insn->off;
insn->imm = (u64 (*)(u64, u64, u64, u64, u64))
func[subprog]->bpf_func -
__bpf_call_base;
}
func[i]->aux->func = func;
func[i]->aux->func_cnt = env->subprog_cnt;
}
for (i = 0; i < env->subprog_cnt; i++) {
old_bpf_func = func[i]->bpf_func;
tmp = bpf_int_jit_compile(func[i]); //这次调用主要是处理bpf到bpf函数调用的调用距离
if (tmp != func[i] || func[i]->bpf_func != old_bpf_func) {
verbose(env, "JIT doesn't support bpf-to-bpf calls\n");
err = -ENOTSUPP;
goto out_free;
}
cond_resched();
}
/* finally lock prog and jit images for all functions and * populate kallsysm */
for (i = 0; i < env->subprog_cnt; i++) {
bpf_prog_lock_ro(func[i]); //设置jit之后的每个子函数所在内存只读
bpf_prog_kallsyms_add(func[i]); //添加每个subprog->bpf_func到kallsyms
}
for (i = 0, insn = prog->insnsi; i < prog->len; i++, insn++) {
if (insn->code != (BPF_JMP | BPF_CALL) ||
insn->src_reg != BPF_PSEUDO_CALL)
continue;
insn->off = env->insn_aux_data[i].call_imm;
subprog = find_subprog(env, i + insn->off + 1);
insn->imm = subprog;
}
prog->jited = 1; //jit完成,后面进入bpf_int_jit_compile函数会直接返回。
prog->bpf_func = func[0]->bpf_func; //prog在在内核里的可执行函数的地址
prog->aux->func = func;
prog->aux->func_cnt = env->subprog_cnt;
bpf_prog_free_unused_jited_linfo(prog);
return 0;
out_free:
for (i = 0; i < env->subprog_cnt; i++)
if (func[i])
bpf_jit_free(func[i]);
kfree(func);
out_undo_insn:
/* cleanup main prog to be interpreted */
prog->jit_requested = 0;
for (i = 0, insn = prog->insnsi; i < prog->len; i++, insn++) {
if (insn->code != (BPF_JMP | BPF_CALL) ||
insn->src_reg != BPF_PSEUDO_CALL)
continue;
insn->off = 0;
insn->imm = env->insn_aux_data[i].call_imm;
}
bpf_prog_free_jited_linfo(prog);
return err;
}
jit_subprogs函数用作多bpf函数prog的jit。主要有三步:
- .函数首先对prog的每个函数生成一个subprog,并初始化,然后调用bpf_int_jit_compile函数对每个subprog进行单独jit。
- .修正bpf到bpf调用指令的调用距离问题,修改为callee函数地址到__bpf_call_base的差值,并把这个值放入insn->imm。
- .最后在对每个subprog调用bpf_int_jit_compile函数进行jit,这次jit主要是最终修正bpf到bpf的跳转距离,修正为callee函数到本调用指令的距离。
为何要进行两轮jit。我的理解是第一次jit的时候,如果后面的subprog的jit还没有进行,虽然ebpf的和x64指令基本可以做到一对一翻译,但ebpf指令定长,但x64指令不定长,那么就不可能知道bpf函数调用的调用距离,也不知道每个call指令的确切地址,只有对每个函数体都要进行过Jit之后,这个时候每个subprog在内核中函数地址已经确定,每个bpf call指令的地址也已经确定,这里在进行一轮jit完成对bpf到bpf函数调用指令的修正
内核里有两个jit的路径,一个上面这个,bpf_prog_load->bpf_check->fixup_bpf_args->jit_suprogs->bpf_int_jit_compile。另外一个路径bpf_prog_load->bpf_prog_select_runtime->bpf_int_jit_compile。
前者是多bpf函数的jit路径,后者是单bpf函数prog的jit路径。第一个路径执行完prog->jited设置为1,等进入进入第二个路径在do_jit函数里看到jited=1函数直接返回。
看下关键的JIT的流程,bpf_prog_load中,bpf_check对prog验证通过之后,执行bpf_prog_select_runtime函数执行jit,最后是在do_jit函数里。
static int do_jit(struct bpf_prog *bpf_prog, int *addrs, u8 *image,
int oldproglen, struct jit_context *ctx)
{
struct bpf_insn *insn = bpf_prog->insnsi;
int insn_cnt = bpf_prog->len;
bool seen_exit = false;
u8 temp[BPF_MAX_INSN_SIZE + BPF_INSN_SAFETY];
int i, cnt = 0;
int proglen = 0;
u8 *prog = temp;
emit_prologue(&prog, bpf_prog->aux->stack_depth,
bpf_prog_was_classic(bpf_prog));
for (i = 0; i < insn_cnt; i++, insn++) {
const s32 imm32 = insn->imm;
u32 dst_reg = insn->dst_reg;
u32 src_reg = insn->src_reg;
u8 b2 = 0, b3 = 0;
s64 jmp_offset;
u8 jmp_cond;
int ilen;
u8 *func;
switch (insn->code) {
/* ALU */
case BPF_ALU | BPF_ADD | BPF_X:
case BPF_ALU | BPF_SUB | BPF_X:
case BPF_ALU | BPF_AND | BPF_X:
case BPF_ALU | BPF_OR | BPF_X:
case BPF_ALU | BPF_XOR | BPF_X:
case BPF_ALU64 | BPF_ADD | BPF_X:
case BPF_ALU64 | BPF_SUB | BPF_X:
case BPF_ALU64 | BPF_AND | BPF_X:
case BPF_ALU64 | BPF_OR | BPF_X:
case BPF_ALU64 | BPF_XOR | BPF_X:
switch (BPF_OP(insn->code)) {
case BPF_ADD: b2 = 0x01; break;
case BPF_SUB: b2 = 0x29; break;
case BPF_AND: b2 = 0x21; break;
case BPF_OR: b2 = 0x09; break;
case BPF_XOR: b2 = 0x31; break;
}
if (BPF_CLASS(insn->code) == BPF_ALU64)
EMIT1(add_2mod(0x48, dst_reg, src_reg));
else if (is_ereg(dst_reg) || is_ereg(src_reg))
EMIT1(add_2mod(0x40, dst_reg, src_reg));
EMIT2(b2, add_2reg(0xC0, dst_reg, src_reg));
break;
case BPF_ALU64 | BPF_MOV | BPF_X:
case BPF_ALU | BPF_MOV | BPF_X:
emit_mov_reg(&prog,
BPF_CLASS(insn->code) == BPF_ALU64,
dst_reg, src_reg);
break;
/* neg dst */
case BPF_ALU | BPF_NEG:
case BPF_ALU64 | BPF_NEG:
if (BPF_CLASS(insn->code) == BPF_ALU64)
EMIT1(add_1mod(0x48, dst_reg));
else if (is_ereg(dst_reg))
EMIT1(add_1mod(0x40, dst_reg));
EMIT2(0xF7, add_1reg(0xD8, dst_reg));
break;
case BPF_ALU | BPF_ADD | BPF_K:
case BPF_ALU | BPF_SUB | BPF_K:
case BPF_ALU | BPF_AND | BPF_K:
case BPF_ALU | BPF_OR | BPF_K:
case BPF_ALU | BPF_XOR | BPF_K:
case BPF_ALU64 | BPF_ADD | BPF_K:
case BPF_ALU64 | BPF_SUB | BPF_K:
case BPF_ALU64 | BPF_AND | BPF_K:
case BPF_ALU64 | BPF_OR | BPF_K:
case BPF_ALU64 | BPF_XOR | BPF_K:
if (BPF_CLASS(insn->code) == BPF_ALU64)
EMIT1(add_1mod(0x48, dst_reg));
else if (is_ereg(dst_reg))
EMIT1(add_1mod(0x40, dst_reg));
/* * b3 holds 'normal' opcode, b2 short form only valid * in case dst is eax/rax. */
switch (BPF_OP(insn->code)) {
case BPF_ADD:
.......................................................................................................
/* call */
case BPF_JMP | BPF_CALL:
func = (u8 *) __bpf_call_base + imm32;
jmp_offset = func - (image + addrs[i]);
if (!imm32 || !is_simm32(jmp_offset)) {
pr_err("unsupported BPF func %d addr %p image %p\n",
imm32, func, image);
return -EINVAL;
}
EMIT1_off32(0xE8, jmp_offset);
break;
case BPF_JMP | BPF_TAIL_CALL:
emit_bpf_tail_call(&prog);
break;
/* cond jump */
case BPF_JMP | BPF_JEQ | BPF_X:
case BPF_JMP | BPF_JNE | BPF_X:
case BPF_JMP | BPF_JGT | BPF_X:
case BPF_JMP | BPF_JLT | BPF_X:
case BPF_JMP | BPF_JGE | BPF_X:
case BPF_JMP | BPF_JLE | BPF_X:
case BPF_JMP | BPF_JSGT | BPF_X:
case BPF_JMP | BPF_JSLT | BPF_X:
case BPF_JMP | BPF_JSGE | BPF_X:
case BPF_JMP | BPF_JSLE | BPF_X:
/* cmp dst_reg, src_reg */
EMIT3(add_2mod(0x48, dst_reg, src_reg), 0x39,
add_2reg(0xC0, dst_reg, src_reg));
goto emit_cond_jmp;
case BPF_JMP | BPF_JSET | BPF_X:
/* test dst_reg, src_reg */
EMIT3(add_2mod(0x48, dst_reg, src_reg), 0x85,
add_2reg(0xC0, dst_reg, src_reg));
goto emit_cond_jmp;
case BPF_JMP | BPF_JSET | BPF_K:
/* test dst_reg, imm32 */
EMIT1(add_1mod(0x48, dst_reg));
............................................................................................
if (image) {
if (unlikely(proglen + ilen > oldproglen)) {
pr_err("bpf_jit: fatal error\n");
return -EFAULT;
}
memcpy(image + proglen, temp, ilen);
}
proglen += ilen;
addrs[i] = proglen;
prog = temp;
}
return proglen;
}
do_jit主要完成以下工作:
- 1.调用emit_prologue函数,由于ebpf指令没有栈操作指令,需要构造函数执行开始的栈初始化环境,使之完全符合x64的abi规则。包括,bp push,bp初始化,以及保存需要被调用者需要保存的寄存器(r15、r14、r13和rbx)。
- 2.对于普通指令,基本能根据opcode和ebpf和x64的寄存器映射一对一的进行指令翻译。
- 3.修正BPF_CALL的函数调用。BPF_CALL主要用于helper func的调用和bpf到bpf函数的调用,现在BPF_CALL的imm是func地址减去__bpf_call_base,加上__bpf_call_base 得到func的地址,然后用func地址减去当前指令的地址作为新的imm。
- 4.函数收场工作。遇到BPF_EXIT指令,代表bpf函数结束。从栈里弹出先前保存的r15、r14、r13和rbx寄存器,添加leave指令平栈,添加ret返回指令。
- 5.emit_bpf_tail_call处理是prog调用另外一个prog的函数的问题,ebpf的prog是可以复用的。在调用深度允许的情况下,直接跳转到被调用用者的prog->bpf_func + prologue_size地址执行。
- 6.do_jit执行完毕,prog->bpf_func存放编译后的可执行代码。
do_jit函数只被bpf_int_jit_compile调用。看下bpf_init_jit_compile主要执行流程:
- 1.首先申请addr[prog->len]数组,用于存储相应的ebpf指令对应的x64指令的地址。初始化假设每个ebpf指令对应64字节长的x64指令。
- 2.循环调用do_jit函数。对一个函数体进行jit一般需要多轮pass。这主要因为跳转指令,在进行jit的时候,如果是向后跳转,无法知道确切的距离,因为后面的指令还没有生成,这里只能按照第一步的假设,假设每个ebpf指令对应的x86指令占64个字节长,这个明显偏大,会导致生成x86的jmp指令的长度比实际的长。所以几轮调用do_jit函数,并没有保存指令编译结果,只是把每个ebpf指令对应的x84指令的偏移地址记录到addr数组里,第一轮pass过后,每个指令的位置信息都会记录到addr里,但这个位置信息只是大致的,不是准确的,因为jmp指令的跳转是不对的,而且生成的jmp指令本身长度也可能不对(本来是短跳转,现在可能是长跳转),所以需要第二轮pass,每一轮pass,要生成的总的x86指令长度不断收敛,位置信息越来越准确,直到最后x86总的长度不再收敛,addr位置信息就完全正确
- 3.x86指令总长度不在收敛后,根据这个长度申请内存,给do_jit,进行最后一轮pass,保存所有翻译后的x64指令。
举个简单的例子,如果一个函数就包含一个跳转指令。
第一轮pass之后,在addr[]里非跳转指令的长度从假设的64字节收敛为真实的x64指令长度,如果是向后跳转,那么跳转指令的跳转距离是不对,偏大,并且可能导致跳转指令本身长度偏大。
第二轮pass,由于所有非跳转指令在第一轮的长度都收敛为正确的长度,所以do_jit遇到跳转指令的时候,此时生成的跳转指令无论是跳转距离和指令长度都正确。
第三轮pass。如果第二轮pass对跳转指令的修正导致jmp指令变短(例如从长跳转变为短跳),此时,需要进行第三轮pass。第三轮pass中,所有指令长度都不再变了。
第四次调用do_jit函数。第三轮pass中,所有指令布局不会在收敛。add[]记录的所有指令占位全部正确。bpf_int_jit_compile函数会为do_jit申请内存,在do_jit里会把每个翻译的指令保存起来,完成最后的jit。
看下前面bpftrce程序prog的jit后的汇编代码:
[root@11-11-11-11 ~]# bpftool prog dump jit id 20
0xffffffffc03eb692:
0: push %rbp
1: mov %rsp,%rbp
4: sub $0x40,%rsp
b: sub $0x28,%rbp
f: mov %rbx,0x0(%rbp)
13: mov %r13,0x8(%rbp)
17: mov %r14,0x10(%rbp)
1b: mov %r15,0x18(%rbp)
1f: xor %eax,%eax
21: mov %rax,0x20(%rbp)
25: mov %rdi,%rbx
28: mov 0x70(%rbx),%rdx
2c: mov $0x2,%edi
31: mov %rdi,-0x18(%rbp)
35: add $0x20,%rdx
39: mov %rbp,%rdi
3c: add $0xfffffffffffffff8,%rdi
40: mov $0x8,%esi
45: callq 0xfffffffff65d906e
4a: mov -0x8(%rbp),%rdx
4e: add $0x40,%rdx
52: mov %rbp,%rdi
55: add $0xfffffffffffffff8,%rdi
59: mov $0x8,%esi
5e: callq 0xfffffffff65d906e
63: mov -0x8(%rbp),%rdi
67: mov %rdi,-0x10(%rbp)
6b: movabs $0xffff9860ed0ba000,%r13
75: callq 0xfffffffff65f71ce
7a: mov %rbp,%rcx
7d: add $0xffffffffffffffe8,%rcx
81: mov %rbx,%rdi
84: mov %r13,%rsi
87: mov %rax,%rdx
8a: mov $0x10,%r8d
90: callq 0xfffffffff65d960e
95: xor %eax,%eax
97: mov 0x0(%rbp),%rbx
9b: mov 0x8(%rbp),%r13
9f: mov 0x10(%rbp),%r14
a3: mov 0x18(%rbp),%r15
a7: add $0x28,%rbp
ab: leaveq
ac: retq
0xffffffffc03eb692为prog->bpf_func的地址,其中的调用函数的地址是错误的,怀疑是工具的问题。
以基于kprobe的ebpf为例看下bpf_func的执行流程。
create_local_trace_kprobe首先函数调用alloc_trace_kprobe分配trace_kprobe,并初始化kprobe的pre_handler为kprobe_dispatcher。然后调用__register_trace_kprobe注册kprobe。
kprobe探测函数执行的之后,执行其pre_handler也就是kprobe_dispatcher。
static int kprobe_dispatcher(struct kprobe *kp, struct pt_regs *regs)
{
struct trace_kprobe *tk = container_of(kp, struct trace_kprobe, rp.kp);
int ret = 0;
raw_cpu_inc(*tk->nhit);
if (tk->tp.flags & TP_FLAG_TRACE)
kprobe_trace_func(tk, regs);
#ifdef CONFIG_PERF_EVENTS
if (tk->tp.flags & TP_FLAG_PROFILE)
ret = kprobe_perf_func(tk, regs);
#endif
return ret;
}
走kprobe_perf_func分支。kprobe_perf_func函数调用trace_call_bpf()。
unsigned int trace_call_bpf(struct trace_event_call *call, void *ctx)
{
unsigned int ret;
if (in_nmi()) /* not supported yet */
return 1;
preempt_disable();
if (unlikely(__this_cpu_inc_return(bpf_prog_active) != 1)) {
/* * since some bpf program is already running on this cpu, * don't call into another bpf program (same or different) * and don't send kprobe event into ring-buffer, * so return zero here */
ret = 0;
goto out;
}
/* * Instead of moving rcu_read_lock/rcu_dereference/rcu_read_unlock * to all call sites, we did a bpf_prog_array_valid() there to check * whether call->prog_array is empty or not, which is * a heurisitc to speed up execution. * * If bpf_prog_array_valid() fetched prog_array was * non-NULL, we go into trace_call_bpf() and do the actual * proper rcu_dereference() under RCU lock. * If it turns out that prog_array is NULL then, we bail out. * For the opposite, if the bpf_prog_array_valid() fetched pointer * was NULL, you'll skip the prog_array with the risk of missing * out of events when it was updated in between this and the * rcu_dereference() which is accepted risk. */
ret = BPF_PROG_RUN_ARRAY_CHECK(call->prog_array, ctx, BPF_PROG_RUN);
out:
__this_cpu_dec(bpf_prog_active);
preempt_enable();
return ret;
}
BPF_PROG_RUN_ARRAY_CHECK宏调用prog_array中所有prog的bpf_func函数。
看看bpf_probe_read函数,bpf_probe_read 被ebpf用于拷贝内核内存达到间接访问的目的,
BPF_CALL_3(bpf_probe_read, void *, dst, u32, size, const void *, unsafe_ptr)
{
int ret;
ret = probe_kernel_read(dst, unsafe_ptr, size);
if (unlikely(ret < 0))
memset(dst, 0, size);
return ret;
}
probe_kernel_read调用copy_user_enhanced_fast_string函数:
ENTRY(copy_user_enhanced_fast_string)
ASM_STAC
cmpl $64,%edx
jb .L_copy_short_string /* less then 64 bytes, avoid the costly 'rep' */
movl %edx,%ecx
1: rep
movsb
xorl %eax,%eax
ASM_CLAC
ret
.section .fixup,"ax"
12: movl %ecx,%edx /* ecx is zerorest also */
jmp copy_user_handle_tail
.previous
_ASM_EXTABLE(1b,12b)
ENDPROC(copy_user_enhanced_fast_string)
三个参数,rdi是目的地址,rsi是要可拷贝的内核地址,rdx是拷贝长度。
6,7行,循环内存拷贝rsi地址的内容到rdi,直到ecx长度为止
13行,定义一个名为fixup的段,之后的指令加入该段,ax段属性,可分配可执行
17行,向异常向量表添加异常处理项。1b是异常发生地址,12b是异常处理跳转地址。
如果内核地址src非法,在do_page_fault里,fix_exception里查找异常向量表,将reg->ip设置12b的地址,do_page_fault执行完从异常返回后,回到12b处执行。
12b处会调用copy_user_handle_tail拷贝剩下的字节。这个函数也是同样的机制,不在说明。
可见bpf_probe_read函数可以处理内核地址非法的情况,最后只会给用户返回实际拷贝成功的长度。
最后,ebpf的安全性:
- ebpf prog load的严格的verify机制
- ebpf访问内核资源需借助各种ebpf 的helper func,helper func函数能在最坏的情况下保证安全
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190982.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
