大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
BPF和eBPF是什么?
BPF是Berkeley Packet Filter(伯克利数据包过滤器)得缩写,诞生于1992年,其作用是提升网络包过滤工具得性能,并于2014年正式并入Linux内核主线。
BPF提供一种在各种内核事件和应用程序事件发生时允许运行一小段程序的机制,使得内核完全可编程,允许用户定制和控制他们的系统以解决相应的问题。
BPF是一项灵活而高效的技术,由指令集、存储对象和辅助函数等几部分组成。其采用了虚拟指令集规范,运行时BPF模块提供两个执行机制:解释器和即时编译器(JIT)。在实际执行前,BPF指令必须通过验证器(verifer)的安全性检查以确保BPF程序自身不会崩溃或者损坏内核。
扩展后的BPF通常缩写为eBPF,但是官方的说法仍然是BPF,并且内核中也只有一个执行引擎即BPF(扩展后的BPF)。
相关概念
- 跟踪(tracing):基于事件的记录-BPF工具所使用的监测方式。
- 采样(sampilng):通过获取全部观测的子集来绘制目标的大致图像。也被称为profiling即性能刨析样本,它是基于计时器来对运行中的代码进行定时采样。
- 可观测性(observability):通过全面观测来理解一个系统,包括跟踪工具、采样工具和基于固定计数器的工具。
- BCC(BPF编译器集合,BPF Compiler Collection):最早用来开发BPF跟踪程序的高级框架。它提供了一个编写内核BPF程序的C语言环境,还提供Python、Lua和C++环境来实现用户接口。
- bpftrace:创建BPF工具的高级语言支持。
- 动态跟踪技术(动态插装技术):在生产环境中对正在运行的软件插入观测点的能力。
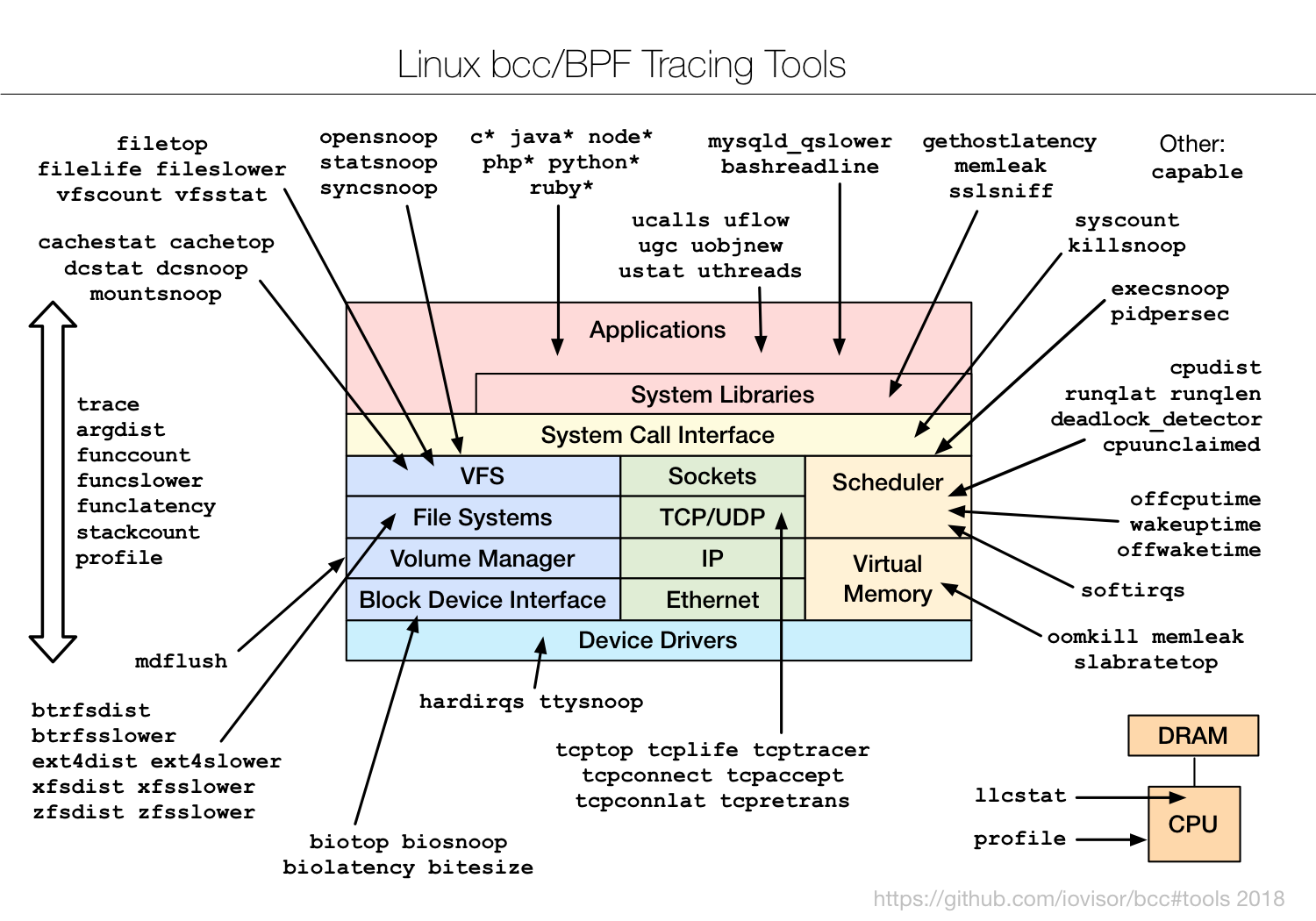
BCC工具图一览

快速入门
环境搭建
这里我们使用vagrant搭建虚拟机来快速搭建一个环境关于vagrant的使用请参考:https://blog.csdn.net/msdnchina/article/details/118461544
vagrant box add ubuntu/impish64
# 创建和启动Ubuntu 21.10虚拟机
vagrant init ubuntu/impish64
vagrant up
# 登录到虚拟机
vagrant ssh
然后我们再安装一些必备的组件
apt-get update
apt-get install -y make clang llvm libelf-dev git libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)
apt-get install build-essential -y gdb libtool pkg-config automake autoconf wget
sudo apt install strace tar gcc-multilib
Hello ebpf
在开始前我们先来看下eBPF的开发步骤:
开发eBPF步骤
- 使用C开发一个eBPF程序
- 借助LLVM将eBPF程序编译成字节码
- 通过bpf系统调用将BPF程序提交给内核
- 内核验证并运行BPF字节码,并把相应得状态映射到BPF映射中
- 用户程序通过BPF映射查询BPF字节码的运行状态

开始开发一个eBPF程序
我们这里使用eBPF的高级封装BCC来开发一个eBPF程序
- 首先我们使用C开发一个eBPF程序
hello.c
int hello_world(void *ctx)
{
bpf_trace_printk("Hello, World!");
return 0;
}
- 然后使用python编写用户态代码
hello.py
#!/usr/bin/env python3
# 1. 导入BCC库
from bcc import BPF
# 2. 加载BPF程序
b = BPF(src_file="hello.c")
# 3. 将 BPF 程序挂载到内核探针(简称 kprobe)
b.attach_kprobe(event="do_sys_openat", fn_name="hello_world")
# 4. 读取内核调试文件 /sys/kernel/debug/tracing/trace_pipe 的内容,并打印到标准输出中
b.trace_print()
- 执行
hellp.py
# python3 hello.py
b' ps-2098 [002] d... 307.515292: bpf_trace_printk: Hello, World!'
b' sh-2099 [001] d... 307.529035: bpf_trace_printk: Hello, World!'
b' sh-2099 [001] d... 307.529155: bpf_trace_printk: Hello, World!'
b' cpuUsage.sh-2100 [002] d... 307.531789: bpf_trace_printk: Hello, World!'
b' cpuUsage.sh-2100 [002] d... 307.531938: bpf_trace_printk: Hello, World!'
trace_print输出的格式可由 /sys/kernel/debug/tracing/trace_options 来修改。比如前面这个默认的输出中,每个字段的含义如下所示:
- ps-2098:表示进程名字和PID
- [002]:表示CPU编号
- [d…]:表示一系列选项
- 307.515292:表示时间戳
- bpf_trace_printk:表示函数名
- Hello, World!:
bpf_trace_printk传入的字符串
使用BPF映射来获取文件信息
BPF 程序可以利用 BPF 映射(map)进行数据存储,而用户程序也需要通过 BPF 映射,同运行在内核中的 BPF 程序进行交互。BCC 定义了一系列的库函数和辅助宏定义。比如,你可以使用 BPF_PERF_OUTPUT 来定义一个 Perf 事件类型的 BPF 映射。
我们可以通过这些辅助函数将我们需要的数据映射到用户态程序中
- 使用bpf辅助函数映射数据
// 包含头文件
#include <uapi/linux/openat2.h>
#include <linux/sched.h>
// 定义数据结构
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
// 定义性能事件映射
BPF_PERF_OUTPUT(events);
// 定义kprobe处理函数
int hello_world(struct pt_regs *ctx, int dfd, const char __user * filename, struct open_how *how)
{
struct data_t data = {
};
// 获取进程的 TGID 和 PID,这儿定义的 data.pid 数据类型为 u32,所以高 32 位舍弃掉后就是进程的 PID
data.pid = bpf_get_current_pid_tgid();
// 获取系统自启动以来的时间,单位是纳秒
data.ts = bpf_ktime_get_ns();
// 获取进程名
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0)
{
//从中指针处读取固定大小的数据
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
// 提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
- 在用户态中读取内核提交的性能事件信息
from bcc import BPF
# 加载
b = BPF(src_file="hello.c")
b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world")
# 打印头 TIME(s) COMM PID FILE
print("%-18s %-16s %-6s %-16s" % ("TIME(s)", "COMM", "PID", "FILE"))
# 定义性能事件回调函数
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))
# 注册性能事件回调函数
b["events"].open_perf_buffer(print_event)
# 循环等待性能事件回调
while 1:
try:
#读取映射内容,并执行回调函数
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
- 执行程序
# python3 hello.py
<command line>:3:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP16__ 1
^
3 warnings generated.
TIME(s) COMM PID FILE
0.000000000 b'node' 1429 b'/root/.vscode-server/data/User/workspaceStorage/f610d604c637ea4c98b5ca477b61ef94/vscode.lock'
0.013446614 b'node' 1265 b'/proc/6209/cmdline'
0.191411986 b'node' 1421 b'/proc/meminfo'
eBPF工作原理
eBPF是一个运行在内核的虚拟机,为了确保在内核中安全地执行,eBPF 只提供了非常有限的指令集。这些指令集可用于完成一部分内核的功能,但却远不足以模拟完整的计算机。为了更高效地与内核进行交互,eBPF 指令还有意采用了 C 调用约定,其提供的辅助函数可以在 C 语言中直接调用,极大地方便了 eBPF 程序的开发。eBPF运行时内部结构如图,主要由5大模块组成
- 第一个模块是eBPF 辅助函数。它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。
- 第二个模块是 eBPF 验证器。它用于确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令。
- 第三个模块是由 11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块。这个模块用于控制 eBPF 程序的执行。其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;而 R10 则是一个只读寄存器,用于从栈中读取数据。
- 第四个模块是即时编译器,它将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行。
- 第五个模块是 BPF 映射(map),它用于提供大块的存储。这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。

bpftool
Linux内核在4.15之后添加了bpftool这个工具可以用来查看和操作BPF对象,包括BPF程序和对应的映射表。它的源码位于Linux源代码的tools/bpf/bpftool中
命令简述
bpftool由对象和命令组成,在内核5.13中bpftool的对象包括 prog | map | link | cgroup | perf | net | feature | btf | gen | struct_ops | iter
选项支持:
- -j、–json
- -p、–pretty
- -f、–bpffs
- -m、–mapcompat
- -n、-nomount
bpftool [OPTIONS] OBJECT {
COMMAND | help}
对于每一类对象都有一个帮助文档,比如
# bpftool prog help
Usage: /usr/lib/linux-tools/5.13.0-39-generic/bpftool prog {
show | list } [PROG]
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog dump xlated PROG [{
file FILE | opcodes | visual | linum }]
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog dump jited PROG [{
file FILE | opcodes | linum }]
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog pin PROG FILE
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog {
load | loadall } OBJ PATH \
[type TYPE] [dev NAME] \
[map {
idx IDX | name NAME } MAP]\
[pinmaps MAP_DIR]
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog attach PROG ATTACH_TYPE [MAP]
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog detach PROG ATTACH_TYPE [MAP]
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog run PROG \
data_in FILE \
[data_out FILE [data_size_out L]] \
[ctx_in FILE [ctx_out FILE [ctx_size_out M]]] \
[repeat N]
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog profile PROG [duration DURATION] METRICs
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog tracelog
/usr/lib/linux-tools/5.13.0-39-generic/bpftool prog help
MAP := {
id MAP_ID | pinned FILE | name MAP_NAME }
PROG := {
id PROG_ID | pinned FILE | tag PROG_TAG | name PROG_NAME }
TYPE := {
socket | kprobe | kretprobe | classifier | action |
tracepoint | raw_tracepoint | xdp | perf_event | cgroup/skb |
cgroup/sock | cgroup/dev | lwt_in | lwt_out | lwt_xmit |
lwt_seg6local | sockops | sk_skb | sk_msg | lirc_mode2 |
sk_reuseport | flow_dissector | cgroup/sysctl |
cgroup/bind4 | cgroup/bind6 | cgroup/post_bind4 |
cgroup/post_bind6 | cgroup/connect4 | cgroup/connect6 |
cgroup/getpeername4 | cgroup/getpeername6 |
cgroup/getsockname4 | cgroup/getsockname6 | cgroup/sendmsg4 |
cgroup/sendmsg6 | cgroup/recvmsg4 | cgroup/recvmsg6 |
cgroup/getsockopt | cgroup/setsockopt | cgroup/sock_release |
struct_ops | fentry | fexit | freplace | sk_lookup }
ATTACH_TYPE := {
msg_verdict | stream_verdict | stream_parser |
flow_dissector }
METRIC := {
cycles | instructions | l1d_loads | llc_misses | itlb_misses | dtlb_misses }
OPTIONS := {
{
-j|--json} [{
-p|--pretty}] | {
-f|--bpffs} |
{
-m|--mapcompat} | {
-n|--nomount} }
bpftool perf
perf子命令用来显示哪些BPF程序正在通过perf_event_open进行挂载。
# bpftool perf
pid 16377 fd 5: prog_id 32 kprobe func do_sys_openat2 offset 0
bpftool prog show
bpftool prog show会列出所有的程序
# bpftool prog show
3: cgroup_device tag e3dbd137be8d6168 gpl
loaded_at 2022-04-17T08:33:56+0000 uid 0
xlated 504B jited 309B memlock 4096B
4: cgroup_skb tag 6deef7357e7b4530 gpl
loaded_at 2022-04-17T08:33:56+0000 uid 0
xlated 64B jited 54B memlock 4096B
5: cgroup_skb tag 6deef7357e7b4530 gpl
loaded_at 2022-04-17T08:33:56+0000 uid 0
xlated 64B jited 54B memlock 4096B
6: cgroup_device tag 0ecd07b7b633809f gpl
loaded_at 2022-04-17T08:34:00+0000 uid 0
xlated 496B jited 307B memlock 4096B
7: cgroup_skb tag 6deef7357e7b4530 gpl
loaded_at 2022-04-17T08:34:00+0000 uid 0
xlated 64B jited 54B memlock 4096B
8: cgroup_skb tag 6deef7357e7b4530 gpl
loaded_at 2022-04-17T08:34:00+0000 uid 0
xlated 64B jited 54B memlock 4096B
9: cgroup_device tag ee0e253c78993a24 gpl
loaded_at 2022-04-17T08:34:04+0000 uid 0
xlated 416B jited 255B memlock 4096B
10: cgroup_device tag e3dbd137be8d6168 gpl
loaded_at 2022-04-17T08:34:06+0000 uid 0
xlated 504B jited 309B memlock 4096B
11: cgroup_device tag c8b47a902f1cc68b gpl
loaded_at 2022-04-17T08:34:06+0000 uid 0
xlated 464B jited 288B memlock 4096B
12: cgroup_device tag 8b9c33f36f812014 gpl
loaded_at 2022-04-17T08:34:08+0000 uid 0
xlated 744B jited 447B memlock 4096B
13: cgroup_skb tag 6deef7357e7b4530 gpl
loaded_at 2022-04-17T08:34:08+0000 uid 0
xlated 64B jited 54B memlock 4096B
14: cgroup_skb tag 6deef7357e7b4530 gpl
loaded_at 2022-04-17T08:34:08+0000 uid 0
xlated 64B jited 54B memlock 4096B
32: kprobe name hello_world tag 38dd440716c4900f gpl
loaded_at 2022-04-17T11:09:18+0000 uid 0
xlated 104B jited 70B memlock 4096B
btf_id 66
bpftool prog dump xlated
xlated将BPF指令翻译为汇编指令打印出来。
# bpftool prog dump xlated id 32
int hello_world(void * ctx):
; int hello_world(void *ctx)
0: (b7) r1 = 33
; ({
char _fmt[] = "Hello, World!"; bpf_trace_printk_(_fmt, sizeof(_fmt)); });
1: (6b) *(u16 *)(r10 -4) = r1
2: (b7) r1 = 1684828783
3: (63) *(u32 *)(r10 -8) = r1
4: (18) r1 = 0x57202c6f6c6c6548
6: (7b) *(u64 *)(r10 -16) = r1
7: (bf) r1 = r10
;
8: (07) r1 += -16
; ({
char _fmt[] = "Hello, World!"; bpf_trace_printk_(_fmt, sizeof(_fmt)); });
9: (b7) r2 = 14
10: (85) call bpf_trace_printk#-61904
; return 0;
11: (b7) r0 = 0
12: (95) exit
正是我们前面写的 C 代码,而其他行则是具体的 BPF 指令。具体每一行的 BPF 指令又分为三部分:
- 第一部分,冒号前面的数字 0-12 ,代表 BPF 指令行数;
- 第二部分,括号中的 16 进制数值,表示 BPF 指令码。它的具体含义你可以参考 IOVisor BPF 文档,比如第 0 行的 0xb7 表示为 64 位寄存器赋值。
- 第三部分,括号后面的部分,就是 BPF 指令的伪代码。
BPF系统调用
在用户态与内核进行交互必须要使用系统调用来完成,在eBPF程序中使用的系统调用
// cmd代表操作命令,比如BPF_PROG_LOAD是加载eBPF程序
// attr代表bpf_attr类型的eBPF属性指针,不同类型的操作命令需要传入不同的属性参数
// size代表属性的大小
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
在内核5.13中已经支持了以下命令
enum bpf_cmd {
BPF_MAP_CREATE,
BPF_MAP_LOOKUP_ELEM,
BPF_MAP_UPDATE_ELEM,
BPF_MAP_DELETE_ELEM,
BPF_MAP_GET_NEXT_KEY,
BPF_PROG_LOAD,
BPF_OBJ_PIN,
BPF_OBJ_GET,
BPF_PROG_ATTACH,
BPF_PROG_DETACH,
BPF_PROG_TEST_RUN,
BPF_PROG_GET_NEXT_ID,
BPF_MAP_GET_NEXT_ID,
BPF_PROG_GET_FD_BY_ID,
BPF_MAP_GET_FD_BY_ID,
BPF_OBJ_GET_INFO_BY_FD,
BPF_PROG_QUERY,
BPF_RAW_TRACEPOINT_OPEN,
BPF_BTF_LOAD,
BPF_BTF_GET_FD_BY_ID,
BPF_TASK_FD_QUERY,
BPF_MAP_LOOKUP_AND_DELETE_ELEM,
BPF_MAP_FREEZE,
BPF_BTF_GET_NEXT_ID,
BPF_MAP_LOOKUP_BATCH,
BPF_MAP_LOOKUP_AND_DELETE_BATCH,
BPF_MAP_UPDATE_BATCH,
BPF_MAP_DELETE_BATCH,
BPF_LINK_CREATE,
BPF_LINK_UPDATE,
BPF_LINK_GET_FD_BY_ID,
BPF_LINK_GET_NEXT_ID,
BPF_ENABLE_STATS,
BPF_ITER_CREATE,
BPF_LINK_DETACH,
BPF_PROG_BIND_MAP,
};
其常用的命令如下:
| 命令 | 说明 |
|---|---|
| BPF_MAP_CREATE | 创建一个BPF映射 |
| BPF_MAP_LOOKUP_ELEM |
BPF_MAP_UPDATE_ELEM
BPF_MAP_DELETE_ELEM
F_MAP_LOOKUP_AND_DELETE_ELEM
BPF_MAP_GET_NEXT_KEY | BPF映射相关的操作命令 |
| BPF_PROG_LOAD | 验证并加载BPF程序 |
| BPF_PROG_ATTACH
BPF_PROG_DETACH | 挂载/协助BPF程序 |
| BPF_OBJ_PIN | 把BPF程序或映射挂载到sysfs中的/sys/fs/bpf目录中 |
| BPF_OBJ_GET | 从/sys/fs/bpf目录中从查找BPF程序 |
| BPF_BTF_LOAD | 验证并加载BTF信息 |
BPF辅助函数
eBPF 程序并不能随意调用内核函数,因此,内核定义了一系列的辅助函数,用于 eBPF 程序与内核其他模块进行交互。比如 bpf_trace_printk() 就是最常用的一个辅助函数,用于向调试文件系统(/sys/kernel/debug/tracing/trace_pipe)写入调试信息。
eBPF 内部的内存空间只有寄存器和栈。所以,要访问其他的内核空间或用户空间地址,就需要借助 bpf_probe_read 这一系列的辅助函数。这些函数会进行安全性检查,并禁止缺页中断的发生。
而在 eBPF 程序需要大块存储时,就不能像常规的内核代码那样去直接分配内存了,而是必须通过 BPF 映射(BPF Map)来完成。
并不是所有的辅助函数都可以在 eBPF 程序中随意使用,不同类型的 eBPF 程序所支持的辅助函数是不同的。比如,对于 Hello World 示例这类内核探针(kprobe)类型的 eBPF 程序,你可以在命令行中执行 bpftool feature probe ,来查询当前系统支持的辅助函数列表:
# bpftool feature probe
Scanning system configuration...
bpf() syscall restriction has unknown value 2
JIT compiler is enabled
JIT compiler hardening is disabled
JIT compiler kallsyms exports are enabled for root
Global memory limit for JIT compiler for unprivileged users is 264241152 bytes
CONFIG_BPF is set to y
CONFIG_BPF_SYSCALL is set to y
CONFIG_HAVE_EBPF_JIT is set to y
CONFIG_BPF_JIT is set to y
CONFIG_BPF_JIT_ALWAYS_ON is set to y
CONFIG_DEBUG_INFO_BTF is set to y
CONFIG_DEBUG_INFO_BTF_MODULES is set to y
CONFIG_CGROUPS is set to y
CONFIG_CGROUP_BPF is set to y
CONFIG_CGROUP_NET_CLASSID is set to y
CONFIG_SOCK_CGROUP_DATA is set to y
CONFIG_BPF_EVENTS is set to y
CONFIG_KPROBE_EVENTS is set to y
CONFIG_UPROBE_EVENTS is set to y
CONFIG_TRACING is set to y
CONFIG_FTRACE_SYSCALLS is set to y
CONFIG_FUNCTION_ERROR_INJECTION is set to y
CONFIG_BPF_KPROBE_OVERRIDE is set to y
CONFIG_NET is set to y
CONFIG_XDP_SOCKETS is set to y
CONFIG_LWTUNNEL_BPF is set to y
CONFIG_NET_ACT_BPF is set to m
CONFIG_NET_CLS_BPF is set to m
CONFIG_NET_CLS_ACT is set to y
CONFIG_NET_SCH_INGRESS is set to m
CONFIG_XFRM is set to y
CONFIG_IP_ROUTE_CLASSID is set to y
CONFIG_IPV6_SEG6_BPF is set to y
CONFIG_BPF_LIRC_MODE2 is not set
CONFIG_BPF_STREAM_PARSER is set to y
CONFIG_NETFILTER_XT_MATCH_BPF is set to m
CONFIG_BPFILTER is set to y
CONFIG_BPFILTER_UMH is set to m
CONFIG_TEST_BPF is set to m
CONFIG_HZ is set to 250
Scanning system call availability...
bpf() syscall is available
Scanning eBPF program types...
eBPF program_type socket_filter is available
eBPF program_type kprobe is available
eBPF program_type sched_cls is available
eBPF program_type sched_act is available
eBPF program_type tracepoint is available
eBPF program_type xdp is available
eBPF program_type perf_event is available
eBPF program_type cgroup_skb is available
eBPF program_type cgroup_sock is available
eBPF program_type lwt_in is available
eBPF program_type lwt_out is available
eBPF program_type lwt_xmit is available
eBPF program_type sock_ops is available
eBPF program_type sk_skb is available
eBPF program_type cgroup_device is available
eBPF program_type sk_msg is available
eBPF program_type raw_tracepoint is available
eBPF program_type cgroup_sock_addr is available
eBPF program_type lwt_seg6local is available
eBPF program_type lirc_mode2 is NOT available
eBPF program_type sk_reuseport is available
eBPF program_type flow_dissector is available
eBPF program_type cgroup_sysctl is available
eBPF program_type raw_tracepoint_writable is available
eBPF program_type cgroup_sockopt is available
eBPF program_type tracing is NOT available
eBPF program_type struct_ops is available
eBPF program_type ext is NOT available
eBPF program_type lsm is NOT available
eBPF program_type sk_lookup is available
Scanning eBPF map types...
...
BPF映射
BPF 映射用于提供大块的键值存储,这些存储可被用户空间程序访问,进而获取 eBPF 程序的运行状态。eBPF 程序最多可以访问 64 个不同的 BPF 映射,并且不同的 eBPF 程序也可以通过相同的 BPF 映射来共享它们的状态。
创建BPF映射的最直接方法是使用bpf系统调用。如果该系统调用的第一个参数设置为BPF_MAP_CREATE,则表示创建一个新的映射。该调用将返回与创建映射相关的文件描述符。bpf系统调用的第二个参数是BPF映射的设置,如下所示:
union bpf_attr {
struct {
__u32 map_type;
__u32 key_size;
__u32 value_size;
__u32 max_entries;
__u32 map_flags;
};
}
其中最关键的是映射的类型,在内核头文件 include/uapi/linux/bpf.h 中的 bpf_map_type 定义了所有支持的映射类型,你可以使用如下的 bpftool 命令,来查询当前系统支持哪些映射类型:
# bpftool feature probe | grep map_type
eBPF map_type hash is available
eBPF map_type array is available
eBPF map_type prog_array is available
eBPF map_type perf_event_array is available
eBPF map_type percpu_hash is available
eBPF map_type percpu_array is available
eBPF map_type stack_trace is available
eBPF map_type cgroup_array is available
eBPF map_type lru_hash is available
eBPF map_type lru_percpu_hash is available
eBPF map_type lpm_trie is available
eBPF map_type array_of_maps is available
eBPF map_type hash_of_maps is available
eBPF map_type devmap is available
eBPF map_type sockmap is available
eBPF map_type cpumap is available
eBPF map_type xskmap is available
eBPF map_type sockhash is available
eBPF map_type cgroup_storage is available
eBPF map_type reuseport_sockarray is available
eBPF map_type percpu_cgroup_storage is available
eBPF map_type queue is available
eBPF map_type stack is available
eBPF map_type sk_storage is available
eBPF map_type devmap_hash is available
eBPF map_type struct_ops is NOT available
eBPF map_type ringbuf is available
eBPF map_type inode_storage is available
eBPF map_type task_storage is available
下表列出了一些常用的BPF映射:
| 映射类型 | 说明 |
|---|---|
| BPF_MAP_TYPE_HASH | 哈希表映射,用于保存key/value对 |
| BPF_MAP_TYPE_LRU_HASH | 在表满时会按LRU算法删除的哈希表映射 |
| BPF_MAP_TYPE_ARRAY | 数组映射,用于保存固定大小的数组 |
| BPF_MAP_TYPE_PROG_ARRAY | 程序数组映射,用于保存BPF程序的引用,适合调用其他eBPF程序 |
| BPF_MAP_TYPE_PERF_EVENT_ARRAY | 性能事件数组映射,用于保存性能事件跟踪记录 |
| BPF_MAP_TYPE_PERCPU_HASH | |
| BPF_MAP_TYPE_PERCPU_ARRAY | 每个CPU单独维护的哈希表和数组映射 |
| BPF_MAP_TYPE_STACK_TRACE | 调用栈跟踪映射,用于存储调用栈信息 |
| BPF_MAP_TYPE_ARRAY_OF_MAPS | |
| BPF_MAP_TYPE_HASH_OF_MAPS | 映射数组和哈希,保存其他映射的引用 |
| BPF_MAP_TYPE_CGROUP_ARRAY | CGROUP数组映射,用于存储cgroups引用 |
| BPF_MAP_TYPE_SOCKMAP | 套接字映射,用于存储套接字引用,适合套接字重定向 |
参考资料
BCC:https://github.com/iovisor/bcc
bpf手册页:https://man7.org/linux/man-pages/man2/bpf.2.html
libbpf-tool:https://github.com/iovisor/bcc/tree/master/libbpf-tools
专栏:https://time.geekbang.org/column/article/479350
官网:https://ebpf.io/
libbpf:https://github.com/libbpf/libbpf
内核BPF新特性:https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md#main-features
《Linux内核观测技术》
《BPF之巅》
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:
Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190892.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
