大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
系列博客是博主学习神经网络中相关的笔记和一些个人理解,仅为作者记录笔记之用,不免有很多细节不对之处。博主用Numpy实现了一个小巧的深度学习框架kitorch,可以方便实现CNN: MNIST例子。请不要再私信我要matlab的代码了。
卷积神经网络回顾
上一节,我们简单探讨了卷积神经网络的反向传播算法,本节我们着手实现了一个简单的卷积神经网,在此之前先以最基本的批量随机梯度下降法+L2正则化对对卷积神经网络的反向传播算法做一个很简单回顾。
需要确定参数有:
- 小批量数据的大小 m m m
- CNN模型的层数 L L L 和所有隐藏层的类型
- 对于卷积层,要定义卷积核的大小 k k k,卷积核子矩阵的维度 d d d,填充大小 p p p,步幅 s s s
- 对于池化层,要定义池化区域大小 h h h 和池化标准(max 或者 mean)
- 对于全连接层,要定义全连接层的激活函数和各层的神经元个数
- 对于输出层,要定义输出函数和代价函数,多分类任务一般采用 softmax 函数和交叉熵代价函数 C = y ln ( a ) C = y\texttt{ln}(a) C=yln(a)
- 超参数:学习速率 η \eta η, 惩罚系数 λ \lambda λ,最大迭代次数 max_iter, 和停止条件 ϵ \epsilon ϵ
计算步骤
- 初始化每个隐含层的 W , b W,b W,b 的值为随机数。一般可以采用标准正态分布进行初始化(选用 1 ( n i n ) \dfrac{ 1}{\sqrt{(n_{in})}} (nin)1 进行来缩放优化初始值),也可以采用 ( − ξ , ξ ) (-\xi, \xi) (−ξ,ξ) 的均匀分布( ξ \xi ξ 取小值)
2.正向传播
2.1).将输入数据 x x x 赋值于输入神经元 a 1 , a 1 = x a^1, a^1 = x a1,a1=x
2.2).从第二层开始,根据下面3种情况进行前向传播计算:- 如果当前是全连接层:则有 a l = σ ( z l ) = σ ( W l a l − 1 + b l ) a^{l} = \sigma(z^{l}) = \sigma(W^la^{l-1} + b^{l}) al=σ(zl)=σ(Wlal−1+bl)
- 如果当前是卷积层:则有 a l = σ ( z l ) = σ ( W l ∗ a l − 1 + b l ) a^{l} = \sigma(z^{l}) = \sigma(W^l*a^{l-1} + b^{l}) al=σ(zl)=σ(Wl∗al−1+bl)
- 如果当前是池化层:则有 a l = pool ( a l − 1 ) a^{l}= \texttt{pool}(a^{l-1}) al=pool(al−1)
2.3).对于输出层第 L L L 层,计算输出 a L = softmax ( z l ) = softmax ( W l a l − 1 + b l ) a^{L}= \texttt{softmax}(z^{l}) = \texttt{softmax}(W^la^{l-1} + b^{l}) aL=softmax(zl)=softmax(Wlal−1+bl)
3. 反向传播
3.1).通过损失函数计算输出层的 δ L \delta^L δL
3.2).从倒数第二层开始,根据下面3种情况逐层进行反向传播计算:
- 如果当前是全连接层:则有 δ l = ( W l + 1 ) T δ l + 1 ⊙ σ ′ ( z l ) \delta^{l} = (W^{l+1})^T\delta^{l+1}\odot \sigma^{‘}(z^{l}) δl=(Wl+1)Tδl+1⊙σ′(zl)
- 如果上层是卷积层:则有 δ l = δ l + 1 ∗ rot180 ( W l + 1 ) ⊙ σ ′ ( z l ) \delta^{l} = \delta^{l+1}*\texttt{rot180}(W^{l+1}) \odot \sigma^{‘}(z^{l}) δl=δl+1∗rot180(Wl+1)⊙σ′(zl)
- 如果上层是池化层:则有 δ l = upsample ( δ l + 1 ) ⊙ σ ′ ( z l ) \delta^{l} = \texttt{upsample}(\delta^{l+1})\odot \sigma^{‘}(z^{l}) δl=upsample(δl+1)⊙σ′(zl)。
4. 根据以下两种情况进行模型更新:
4.1).如果当前是全连接层:
W l = ( 1 − η λ n ) W l − η m ∑ [ δ l ( a l − 1 ) T ] W^l = \left(1-\frac{\eta\lambda}{n}\right)W^l -\frac{\eta}{m} \sum \left[ \delta^{l}(a^{ l-1})^T\right] Wl=(1−nηλ)Wl−mη∑[δl(al−1)T]
b l = b l − η m ∑ ( δ l ) b^l = b^l -\frac{\eta}{m} \sum \left( \delta^{l} \right) bl=bl−mη∑(δl)4.2).如果当前是卷积层,对于每一个卷积核有:
W l = ( 1 − η λ n ) W l − η m ∑ [ δ l ∗ rot90 ( a l − 1 , 2 ) ] W^l = \left(1-\frac{\eta\lambda}{n}\right)W^l – \frac{\eta}{m} \sum \left[ \delta^{l}*\texttt{rot90}(a^{ l-1},2)\right] Wl=(1−nηλ)Wl−mη∑[δl∗rot90(al−1,2)]
b l = b l − η m ∑ [ mean ( δ l ) ] b^l = b^l – \frac{\eta}{m} \sum \left[ \texttt{mean}(\delta^{l})\right] bl=bl−mη∑[mean(δl)]
MATLAB实现
限于个人能力,我们目前先实现一个简单的 1+N 结构的卷积神经网络,即 1 个卷积层(包括池化层)和 N个全连接层。下面是这个简单网络的结构
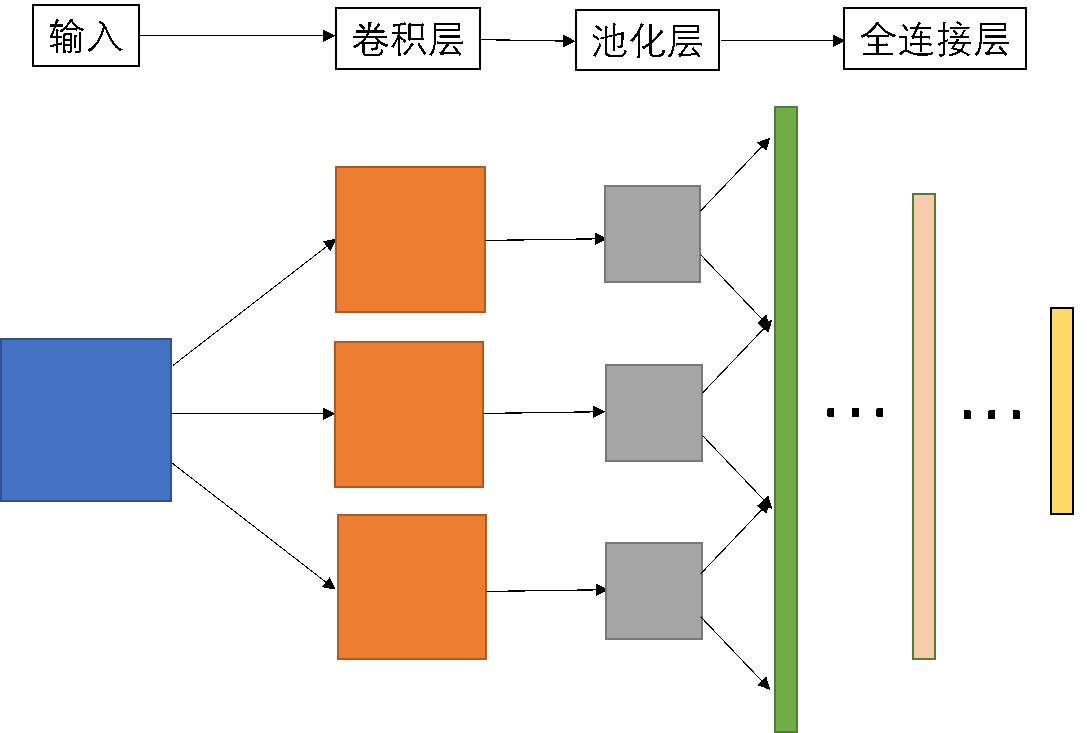

下面对各层做简要的说明:
1、 卷积层:无padding,步幅 stride 设置为 1,激活函数选择ReLU函数
2、 池化层:无padding,池化类型只实现 ‘average’ 方法
3、 展铺层:为方便计算设计的层,属于预先分配的内存空间,作为全连接层的输入
4、 全连接层:激活函数为Sigmoid函数
5、 输出层:分类函数选择Softmax函数,代价函数选择交叉熵代价函数+L2正则化
网络定义的MATLAB代码如下:
loadMnistDataScript; %加载数据
ntrain = size(training_data_label,2);
mini_batch_size = 100;
cnn.ntrain = ntrain;
cnn.eta = 1; %学习速率
cnn.lambda = 5; %正则化惩罚系数
cnn.layer = {
% input layer: 'input', mini_size, [height,width] of image
{'input',mini_batch_size,[28,28]};
% convlution layer: 'conv', kernel_number, [height,width] of kernel
{'conv',20,[9,9]};
% pooling layer: 'pool', pooling_type, [height,width] of pooling area
{'pool','average',[2,2]};
% flatten layer: 'flat', a layer for pre-allocated memory
{'flat'};
% full connect layer: 'full', neuron number
{'full',100};
{'full',100};
% output layer: 'output', neuron number
{'output',10};
};
由于变量过多,将cnn设计为一个结构体,包含的成员变量有
1、cnn.layer:网络结构的定义,元胞数组;
2、cnn.z:每一层的带权输入,元胞数组;
3、cnn.a:每一层的输出,元胞数组;
4、cnn.delta::每一层的误差敏感项,元胞数组;
5、cnn.weights:每一层的权重。元胞数组;
6、cnn.biases:每一层的偏置,元胞数组;
7、cnn.nabla_w:权重的梯度,元胞数组;
8、cnn.nabla_b:偏置的梯度,元胞数组;
9、其他一些超参数
这样每一层包含7个量:带权输入( z z z),输出( a a a),误差( δ \delta δ),权重( W W W),偏置( b b b),权重梯度( ∇ W \nabla W ∇W),偏置梯度( ∇ b \nabla b ∇b)。并不是每一层都实际需要这7个量,不需要的层将其设置为空数组即可,下面是网络初始化的过程,假如第 n n n层为:
1、输入层:
a{n} = zeros([ImageHeight, ImageWidth, mini_batch_size])
2、卷积层:
ImageHeight = ImageHeight – KernelHeight+1
ImageWidth = ImageWidth– KernelWidth+1
z{n} = zeros([ImageHeight, ImageWidth, mini_batch_size, kernel_number])
a{n} = zeros([ImageHeight, ImageWidth, mini_batch_size, kernel_number])
delta{n} = zeros([ImageHeight, ImageWidth, mini_batch_size, kernel_number])
weights{n} = rand([KernelHeight, KernelWidth, kernel_number])-0.5
nabla_w =zeros( [KernelHeight, KernelWidth, kernel_number])
biases{n} = rand([1, kernel_number])-0.5
nabla_b{n} =zeros( [1, kernel_number])
3、池化层
ImageHeight = ImageHeight / KernelHeight
mageWidth = ImageWidth / KernelWidth
a{n} = zeros([ImageHeight, ImageWidth, mini_batch_size, kernel_number])
delta{n} = zeros([ImageHeight, ImageWidth, mini_batch_size, kernel_number])
4、展铺层
a{n} = zeros([ImageHeight*ImageWidth* kernel_number, mini_batch_size])
delta{n} = zeros([ImageHeight*ImageWidth* kernel_number, mini_batch_size])
5、全连接层和输出层
z{n} = zeros([neuron_number, mini_batch_size])
a{n} = zeros([neuron_number, mini_batch_size])
delta{n} = zeros([neuron_number, mini_batch_size])
weights{n} = rand([neuron_number,prev_layer_neuron_number])-0.5
nabla_w{n} = zeros([neuron_number,prev_layer_neuron_number])
biases{n} = rand([neuron_number,1])-0.5
nabla_b{n} = zeros([neuron_number,1])
下面是详细代码
function cnn = cnn_initialize(cnn)
%CNN_INIT initialize the weights and biases, and other parameters
%
index = 0;
num_layer = numel(cnn.layer);
for in = 1:num_layer
switch cnn.layer{in}{1}
case 'input'
index = index + 1;
height = cnn.layer{in}{3}(1);
width = cnn.layer{in}{3}(2);
mini_size = cnn.layer{in}{2};
cnn.weights{index} = [];
cnn.biases{index} = [];
cnn.nabla_w{index} = [];
cnn.nabla_b{index} = [];
%n*n*m
cnn.a{index} = [];
cnn.z{index} = [];
cnn.delta{index} = [];
cnn.mini_size = mini_size;
case 'conv'
index = index + 1;
%kernel height, width, number
ker_height = cnn.layer{in}{3}(1);
ker_width = cnn.layer{in}{3}(2);
ker_num = cnn.layer{in}{2};
cnn.weights{index} = grand(ker_height,ker_width,ker_num) - 0.5;
cnn.biases{index} = grand(1,ker_num) - 0.5;
cnn.nabla_w{index} = zeros(ker_height,ker_width,ker_num);
cnn.nabla_b{index} = zeros(1,ker_num);
height = height - ker_height + 1;
width = width - ker_width + 1;
cnn.a{index} = zeros(height,width,mini_size,ker_num);
cnn.z{index} = zeros(height,width,mini_size,ker_num);
cnn.delta{index} = zeros(height,width,mini_size,ker_num);
case 'pool'
index = index + 1;
%kernel height, width, number
ker_height = cnn.layer{in}{3}(1);
ker_width = cnn.layer{in}{3}(2);
cnn.weights{index} = [];
cnn.biases{index} = [];
cnn.nabla_w{index} = [];
cnn.nabla_b{index} = [];
height = height / ker_height;
width = width / ker_width;
cnn.a{index} = zeros(height,width,mini_size,ker_num);
cnn.z{index} = [];
cnn.delta{index} = zeros(height,width,mini_size,ker_num);
case 'flat'
index = index + 1;
cnn.weights{index} = [];
cnn.biases{index} = [];
cnn.nabla_w{index} = [];
cnn.nabla_b{index} = [];
cnn.a{index} = zeros(height*width*ker_num,mini_size);
cnn.z{index} = [];
cnn.delta{index} = zeros(height*width*ker_num,mini_size);
case 'full'
index = index + 1;
%kernel height, width, number
neuron_num = cnn.layer{in}{2};
neuron_num0 = size(cnn.a{in-1},1);
cnn.weights{index} = grand(neuron_num,neuron_num0) - 0.5;
cnn.biases{index} = grand(neuron_num,1) - 0.5;
cnn.nabla_w{index} = zeros(neuron_num,neuron_num0);
cnn.nabla_b{index} = zeros(neuron_num,1);
cnn.a{index} = zeros(neuron_num,mini_size);
cnn.z{index} = zeros(neuron_num,mini_size);
cnn.delta{index} = zeros(neuron_num,mini_size);
case 'output'
index = index + 1;
%kernel height, width, number
neuron_num = cnn.layer{in}{2};
neuron_num0 = size(cnn.a{in-1},1);
cnn.weights{index} = grand(neuron_num,neuron_num0) - 0.5;
cnn.biases{index} = grand(neuron_num,1);
cnn.nabla_w{index} = zeros(neuron_num,neuron_num0);
cnn.nabla_b{index} = zeros(neuron_num,1);
cnn.a{index} = zeros(neuron_num,mini_size);
cnn.z{index} = zeros(neuron_num,mini_size);
cnn.delta{index} = zeros(neuron_num,mini_size);
otherwise
end
end
end
下面是正向计算过程(伪代码),假设第 n n n层为
1、输入层:
a{n} = x
2、卷积层:
z{n} = conv(weights{n}*a{n-1})+biases{n}
a{n} = relu(z{n})
3、池化层
a{n}=pool(a{n-1}) %程序中同样使用卷积实现的
4、展铺层
a{n} = reshape(a{n-1})
5、全连接层
z{n} = weights{n}*a{n-1}+biases{n}
a{n} = sigmoid(z{n})
6、输出层
z{n} = weights{n}*a{n-1}+biases{n}
a{n} = softmax(z{n})
具体代码如下:
function cnn = cnn_feedforward(cnn,x)
%CNN_FEEDFORWARD CNN feedforward
%
num = numel(cnn.layer);
for in = 1:num
switch cnn.layer{in}{1}
case 'input'
cnn.a{in} = x;
case 'conv'
kernel_num = cnn.layer{in}{2};
for ik = 1:kernel_num
cnn.z{in}(:,:,:,ik) = convn(cnn.a{in-1},...
cnn.weights{in}(:,:,ik),'valid')+cnn.biases{in}(ik);
end
cnn.a{in} = relu(cnn.z{in});
case 'pool'
ker_h = cnn.layer{in}{3}(1);
ker_w = cnn.layer{in}{3}(2);
kernel = ones(ker_h,ker_w)/ker_h/ker_w;
tmp = convn(cnn.a{in-1},kernel,'valid');
cnn.a{in} = tmp(1:ker_h:end,1:ker_w:end,:,:);
case 'flat'
[height,width,mini_size,kernel_num] = size(cnn.a{in-1});
for ik = 1:mini_size
cnn.a{in}(:,ik) = reshape(cnn.a{in-1}(:,:,ik,:),[height*width*kernel_num,1]);
end
case 'full'
cnn.z{in}= bsxfun(@plus,cnn.weights{in}*cnn.a{in-1},cnn.biases{in});
cnn.a{in} = sigmoid(cnn.z{in});
case 'output'
cnn.z{in}= bsxfun(@plus,cnn.weights{in}*cnn.a{in-1},cnn.biases{in});
cnn.a{in} = softmax(cnn.z{in});
end
end
end
下面是反向计算过程(伪代码),假设第 n n n层为
1、卷积层:
delta{n} = upsample(delta{n+1}).*relu_prime(z{n})
nabla_w{n} = conv2(delta{n},rot90(a{n-1},2),'valid')/mini_batch_size
nabla_b{n} = mean(delta{n})
2、池化层
delta{n} = reshape(delta{n+1})
3、展铺层
delta{n} = weights{n+1}'*delta{n+1}
4、全连接层
delta{n} = weights{n+1}'*delta{n+1}.*sigmoid_prime(a{n})
nabla_w{n} = delta{n}*a{n-1}'/mini_batch_size
nabla_b{n} = mean(delta{n})
5、输出层
delta{n} = a{n}-y
nabla_w{n} = delta{n}*a{n-1}'/mini_batch_size
nabla_b{n} = mean(delta{n})
下面是反向传播和模型更新部分的 MATLAB 代码
function cnn = cnn_backpropagation(cnn,y)
%CNN_BP CNN backpropagation
num = numel(cnn.layer);
for in = num:-1:2
switch cnn.layer{in}{1}
case 'conv'
ker_h = cnn.layer{in+1}{3}(1);
ker_w = cnn.layer{in+1}{3}(2);
kernel = ones(ker_h,ker_w)/ker_h/ker_w;
[~,~,mini_size,kernel_num] = size(cnn.delta{in+1});
cnn.nabla_w{in}(:) = 0;
cnn.nabla_b{in}(:) = 0;
for ik = 1:kernel_num
for im = 1:mini_size
cnn.delta{in}(:,:,im,ik) = kron(cnn.delta{in+1}(:,:,im,ik),kernel).*relu_prime(cnn.z{in}(:,:,im,ik));
cnn.nabla_w{in}(:,:,ik) = cnn.nabla_w{in}(:,:,ik) +...
conv2(rot90(cnn.a{in-1}(:,:,im),2),cnn.delta{in}(:,:,im,ik),'valid');
cnn.nabla_b{in}(ik) = cnn.nabla_b{in}(ik) + mean(mean(cnn.delta{in}(:,:,im,ik)));
end
cnn.nabla_w{in}(:,:,ik) = cnn.nabla_w{in}(:,:,ik)/mini_size;
cnn.nabla_b{in}(ik) = cnn.nabla_b{in}(ik)/mini_size;
end
case 'pool'
[height,width,mini_size,kernel_num] = size(cnn.a{in});
for ik = 1:mini_size
cnn.delta{in}(:,:,ik,:) = reshape(cnn.delta{in+1}(:,ik),[height,width,kernel_num]);
end
case 'flat'
cnn.delta{in} = cnn.weights{in+1}'*cnn.delta{in+1};
case 'full'
cnn.delta{in}= cnn.weights{in+1}'*cnn.delta{in+1}.*sigmoid_prime(cnn.z{in});
cnn.nabla_w{in} = cnn.delta{in}*(cnn.a{in-1})'/cnn.mini_size;
cnn.nabla_b{in} = mean(cnn.delta{in},2);
case 'output'
cnn.delta{in}= (cnn.a{in} - y);
cnn.nabla_w{in} = cnn.delta{in}*(cnn.a{in-1})'/cnn.mini_size;
cnn.nabla_b{in} = mean(cnn.delta{in},2);
otherwise
end
end
eta = cnn.eta;
lambda = cnn.lambda;
ntrain = cnn.ntrain;
% update models
for in = 1:num
cnn.weights{in} = (1-eta*lambda/ntrain)*cnn.weights{in} - eta*cnn.nabla_w{in};
cnn.biases{in} = (1-eta*lambda/ntrain)*cnn.biases{in} - eta*cnn.nabla_b{in};
end
end
下面是主程序部分
cnn = cnn_initialize(cnn);
max_iter = 50000;
for in = 1:max_iter
pos = randi(ntrain-mini_batch_size);
x = training_data(:,:,pos+1:pos+mini_batch_size);
y = training_data_label(:,pos+1:pos+mini_batch_size);
cnn = cnn_feedforward(cnn,x);
cnn = cnn_backpropagation(cnn,y);
if mod(in,100) == 0
disp(in);
end
if mod(in,5000) == 0
disp(['validtion accuracy: ',num2str(...
cnn_evaluate(cnn,validation_data,validation_data_label)*100), '%']);
end
end
运行结果为
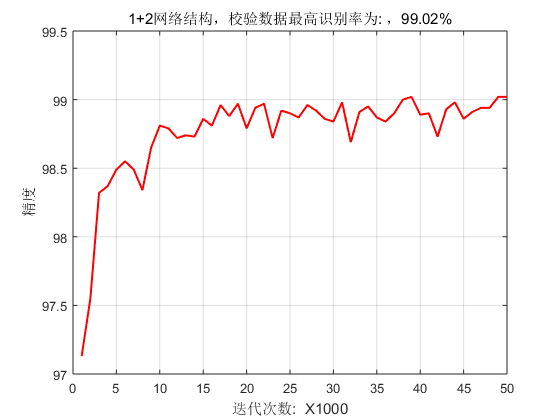
迭代次数为50000次,mini_batch_size = 100,如果按照无放回的随机梯度计算,迭代次数为100个epoch。在校验数据(validation_data)上的识别率最高为 99.02%, 在测试数据(test_data)上的识别率为 99.13%。CNN的效率比较低,单线程迭代50000次,共耗时3个多小时。-_-||。
本节代码可在这里下载到(没有积分的同学可私信我)。
免费代码在这里呀,由于MATLAB版本的问题,可能会出错哦,自己调整下吧
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190840.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
