大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
基于一维卷积神经网络对机械振动信号进行分类并加以预测
*使用一维卷积神经网络训练振动信号进行二分类
2020年7月16日,一学期没等到开学,然而又放假了。
总览CSDN中大多数卷积神经网络都是对二维图片进行分类的,而图片也都是常见的猫狗分类,minst手写数字分类。一维卷积神经网络的使用非常少见,有也是IDMB情感分类,和鸢尾花分类的。
作者研究生就读于河北一所双飞,全国排名270多,哈哈哈,不吹不黑。
在网上翻来翻去找不到一篇可以利用的代码去研究我的机械故障诊断,后来在无奈下到某宝搜寻到一段代码,可以利用。这篇代码是改装鸢尾花分类的,直观性较强,对于本人天资愚钝的人来说入手方便。不多说直接上代码:
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import StratifiedShuffleSplit
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten, Convolution1D, Dropout,MaxPooling1D,BatchNormalization
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.models import load_model
train = pd.read_csv('C:/Users/pc/Desktop/100train.csv')#导入训练集
test = pd.read_csv('C:/Users/pc/Desktop/100test.csv')#导入测试集
#这里是代码的精髓之处,编辑数据集中的标签,直接使用即可
def encode(train, test):
label_encoder = LabelEncoder().fit(train.species)
labels = label_encoder.transform(train.species)
classes = list(label_encoder.classes_)
train = train.drop(['species', 'id'], axis=1)
test = test.drop('id', axis=1)
return train, labels, test, classes
train, labels, test, classes = encode(train, test)
scaled_train=train.values
# SSS将每个数据集中的30%用作测试
sss = StratifiedShuffleSplit(test_size=0.3, random_state=23)
for train_index, valid_index in sss.split(scaled_train, labels):
X_train, X_valid = scaled_train[train_index], scaled_train[valid_index]
y_train, y_valid = labels[train_index], labels[valid_index]
nb_features = 64
nb_class = len(classes)
# reshape train data这里的128强调一点,64*2=128,如果数据量大,可以改变nb_feature的大小,同时在这里将128改成nb_feature的2倍,这里为什么这样,将在代码下面详细说明
X_train_r = np.zeros((len(X_train), nb_features, 3))
X_train_r[:, :, 0] = X_train[:, :nb_features]
X_train_r[:, :, 1] = X_train[:, nb_features:128]
X_train_r[:, :, 2] = X_train[:, 128:]
print(X_train_r)
# reshape validation data
X_valid_r = np.zeros((len(X_valid), nb_features, 3))
X_valid_r[:, :, 0] = X_valid[:, :nb_features]
X_valid_r[:, :, 1] = X_valid[:, nb_features:128]
X_valid_r[:, :, 2] = X_valid[:, 128:]
model = Sequential()
model.add(Convolution1D(nb_filter=16, filter_length=64,strides=1, input_shape=(nb_features, 3),padding='same'))
model.add(Activation('tanh'))#在对振动信号,尤其是在对加速度计测得的振动信号时使用tanh是个不错的选择
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Convolution1D(32,3,padding='same'))
model.add(Activation('tanh'))
model.add(MaxPooling1D(2,strides=2,padding='same'))
model.add(BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None))
model.add(Flatten())
model.add(Dropout(0.3))
model.add(Dense(100, activation='tanh'))
model.add(Dense(10, activation='tanh'))
model.add(Dense(nb_class))
model.add(Activation('softmax'))
model.summary()
y_train = np_utils.to_categorical(y_train, nb_class)#这里是将数据集中的标签做成独热码,直接黏贴就好了
y_valid = np_utils.to_categorical(y_valid, nb_class)
sgd = SGD(lr=0.01, nesterov=True, decay=1e-6, momentum=0.9)
model.compile(loss='categorical_crossentropy',optimizer=sgd,metrics=['accuracy'])
nb_epoch = 150
model.fit(X_train_r, y_train, nb_epoch=nb_epoch, validation_data=(X_valid_r, y_valid), batch_size=32)
model.save('fei100_model.h5')#将训练好的模型保存,不想保存的话可以在代码前加上#
前十行没什么可说的,导入乱七八糟的函数,日常不管用不用的到瞎鸡导入,不会影响训练。
这里说明为什么上面将长度为192的代码分成三个长度为64的在重整成一个三维矩阵加载进第一个卷积层:
在鸢尾花分类的时候是有三大个明显特征的,这里用长、宽、高代替,因为原本是什么,本人记不清楚了,懒得去查,也不重要了。那么问题来了,这是在训练振动信号不用将192长的信号再分成三段了,于是本人将代码进行改变,将原本reshape部分删除,将第一个卷积层的输入改成1维,中间过程不堪入目,终于两天后我放弃了,总是维度有问题,就是无法将(175,192)的数据输入到(1,192)的卷积层中,然后又将(175,192)的信号曾了个维度还是不行,在此希望成功的小伙伴在下面评论一下,或者把代码发本人邮箱983401858@qq.com哈哈哈哈。
关于振动信号采用激活函数tanh是因为,本人尝试了relu,和sigmod但发现,效果并没有tanh好,为什么不好,同样好在哪里,就不一一赘述了。
下面,用训练好的模型去预测新收集到的振动信号,当然了,并没有真的做实验去获得新数据,是从原有数据中摘取出一部分。预测用的代码如下:
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from keras.models import load_model,Sequential
from keras.layers import Dense, Activation, Flatten, Convolution1D, Dropout,MaxPooling1D,BatchNormalization
c = pd.read_csv('C:/Users/pc/Desktop/10000.csv')
a=np.array(c)
b=a.reshape(-1,64,3)
model=Sequential()
model = load_model("fei100_model.h5")
predict=model.predict(b)
呐,这就基本上完成了。
本人简单的贴一下预测结果
0 1
0 0.99957 0.000430316
1 0.00109235 0.998908
2 0.999585 0.000414541
3 0.0143072 0.985693
4 0.999522 0.000478374
5 0.999482 0.000517729
6 0.00236826 0.997632
7 0.154483 0.845517
8 0.999583 0.000417115
9 0.999579 0.000420685
10 0.0249035 0.975097
11 0.999566 0.000434191
12 0.00106062 0.998939
13 0.999545 0.000454852
14 0.999595 0.000404937
15 0.63731 0.36269
16 0.00356141 0.996439
17 0.00621646 0.993783
18 0.999571 0.000429145
19 0.99954 0.00045966
其中0代表信号中的bad,1代表信号中的good
数据在没测试前的标签如下图
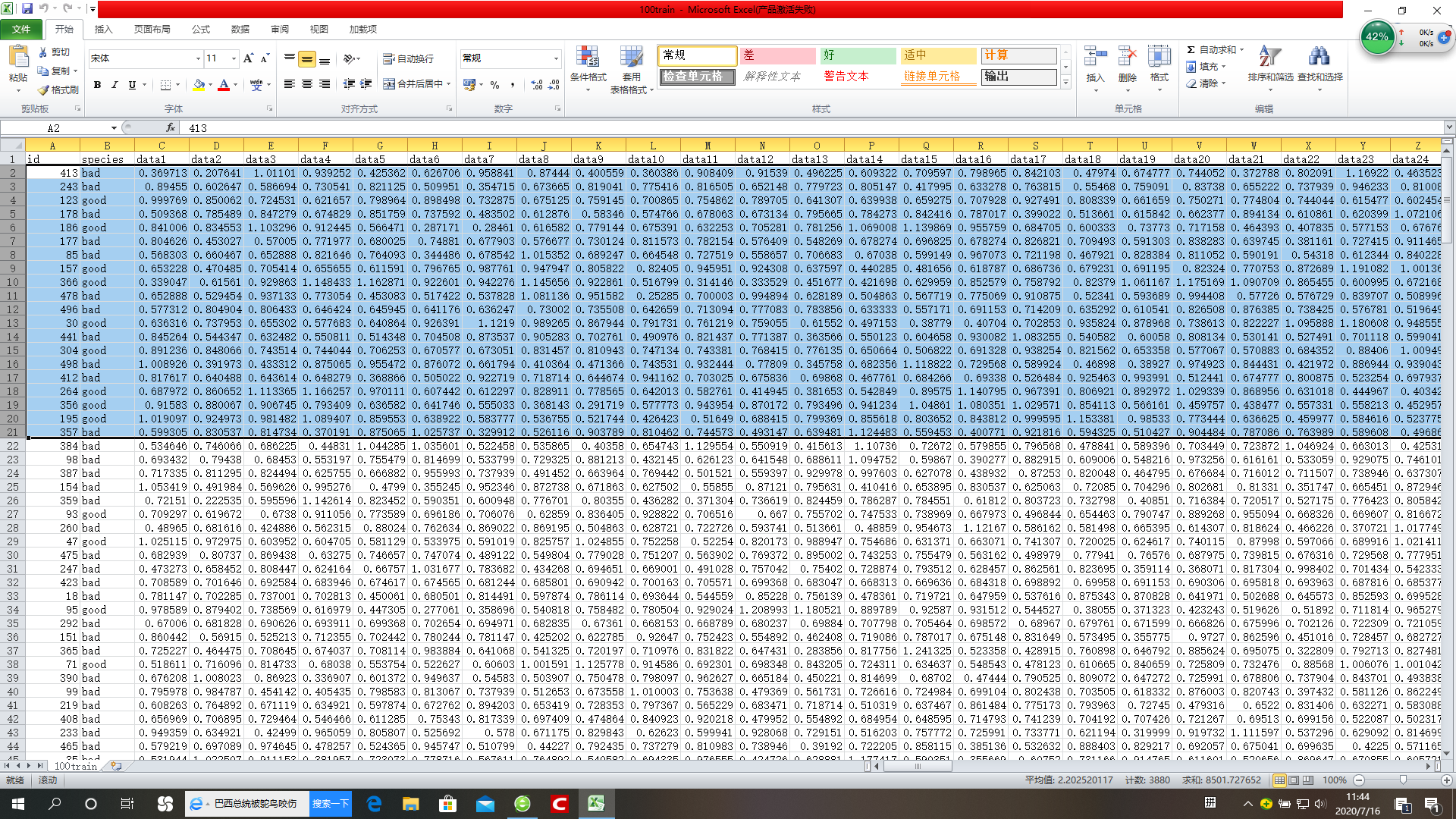

选择的是2-21行,这样就是20个样本进行验证。可以看出预测的和原本的不太一致,预测过程中将第一行直接转移到了最后一行,奇奇怪怪令人不解,其中还有个预测的概率为0.6多。这样就在研究我的课题时变相的迈了一小步。
细心的朋友可能早就发现,本人将代码里的归一化,标准化删除了,哈哈哈,卖个乖,本人的研究中发现了一种标准化方法,还在测试阶段,不一定理想。所以将数据直接用matlab归一化和标准化好了。图片中的数据使用的用每个值减去最小值除以最大值得来的。虽然做起来麻烦,但是这样做的好处倒也是有的,那就是在测试的程序中不用再添加训练时的归一化标准化程序。往往在训练的程序中进行归一化处理,再到预测程序中进行归一化,往往得到一些奇奇怪怪的预测结果。
数据集的连接:
https://pan.baidu.com/s/18rkiU9gROfSMQhZ5nDzEsg
提取码sbun
永久有效
第一次写博客分享研究生一年来,做出的丁点成果。希望看过这篇帖子的同志在下面评论,共同学习,共同进步。我导师带研究生在3届,然而研三师兄半年没见到就毕业了。研二师兄做老师的另外一个课题。老师赴美学习被堵到了国外。这学上的稀里糊涂,难受的丫批。
有问题评论区指出,共同讨论,本人虚心受教
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190777.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
