大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在 mybatis 中,使用 RowBounds 进行分页,非常方便,不需要在 sql 语句中写 limit,即可完成分页功能。但是由于它是在 sql 查询出所有结果的基础上截取数据的,所以在数据量大的sql中并不适用,它更适合在返回数据结果较少的查询中使用
最核心的是在 mapper 接口层,传参时传入 RowBounds(int offset, int limit) 对象,即可完成分页
注意:由于 java 允许的最大整数为 2147483647,所以 limit 能使用的最大整数也是 2147483647,一次性取出大量数据可能引起内存溢出,所以在大数据查询场合慎重使用
mapper 接口层代码如下
List<Book> selectBookByName(Map<String, Object> map, RowBounds rowBounds);调用如下
List<Book> list = bookMapper.selectBookByName(map, new RowBounds(0, 5));说明: new RowBounds(0, 5),即第一页,每页取5条数据
测试示例
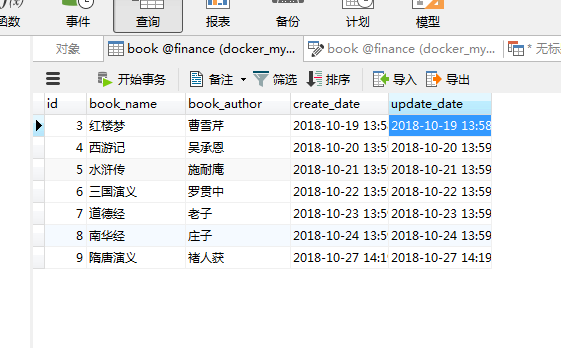
数据库数据

mapper 接口层
package com.demo.mapper;
import java.util.List;
import java.util.Map;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.session.RowBounds;
import com.demo.bean.Book;
@Mapper
public interface BookMapper {
//添加数据
int insert(Book book);
//模糊查询
List<Book> selectBookByName(Map<String, Object> map, RowBounds rowBounds);
}
mapper.xml 文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.demo.mapper.BookMapper">
<resultMap id="BaseResultMap" type="com.demo.bean.Book">
<id column="id" property="id" jdbcType="VARCHAR" />
<result column="book_name" property="bookName" jdbcType="VARCHAR" />
<result column="book_author" property="bookAuthor" jdbcType="VARCHAR" />
<result column="create_date" property="createDate" jdbcType="VARCHAR" />
<result column="update_date" property="updateDate" jdbcType="VARCHAR" />
</resultMap>
<sql id="Base_Column_List">
book_name as bookName, book_author as bookAuthor,
create_date as createDate, update_date as updateDate
</sql>
<insert id="insert" useGeneratedKeys="true" keyProperty="id" parameterType="com.demo.bean.Book">
insert into book(book_name, book_author, create_date, update_date) values(#{bookName}, #{bookAuthor}, #{createDate}, #{updateDate})
</insert>
<select id="selectBookByName" resultMap="BaseResultMap">
<bind name="pattern_bookName" value="'%' + bookName + '%'" />
<bind name="pattern_bookAuthor" value="'%' + bookAuthor + '%'" />
select * from book
where 1 = 1
<if test="bookName != null and bookName !=''">
and book_name LIKE #{pattern_bookName}
</if>
<if test="bookAuthor != null and bookAuthor !=''">
and book_author LIKE #{pattern_bookAuthor}
</if>
</select>
</mapper>测试代码
package com.demo;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.ibatis.session.RowBounds;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import com.demo.bean.Book;
import com.demo.mapper.BookMapper;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringbootJspApplicationTests {
@Autowired
private BookMapper bookMapper;
@Test
public void contextLoads() {
Book book = new Book();
book.setBookName("隋唐演义");
book.setBookAuthor("褚人获");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
book.setCreateDate(sdf.format(new Date()));
book.setUpdateDate(sdf.format(new Date()));
bookMapper.insert(book);
System.out.println("返回的主键: "+book.getId());
}
@Test
public void query() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("bookName", "");
map.put("bookAuthor", "");
List<Book> list = bookMapper.selectBookByName(map, new RowBounds(0, 5));
for(Book b : list) {
System.out.println(b.getBookName());
}
}
}
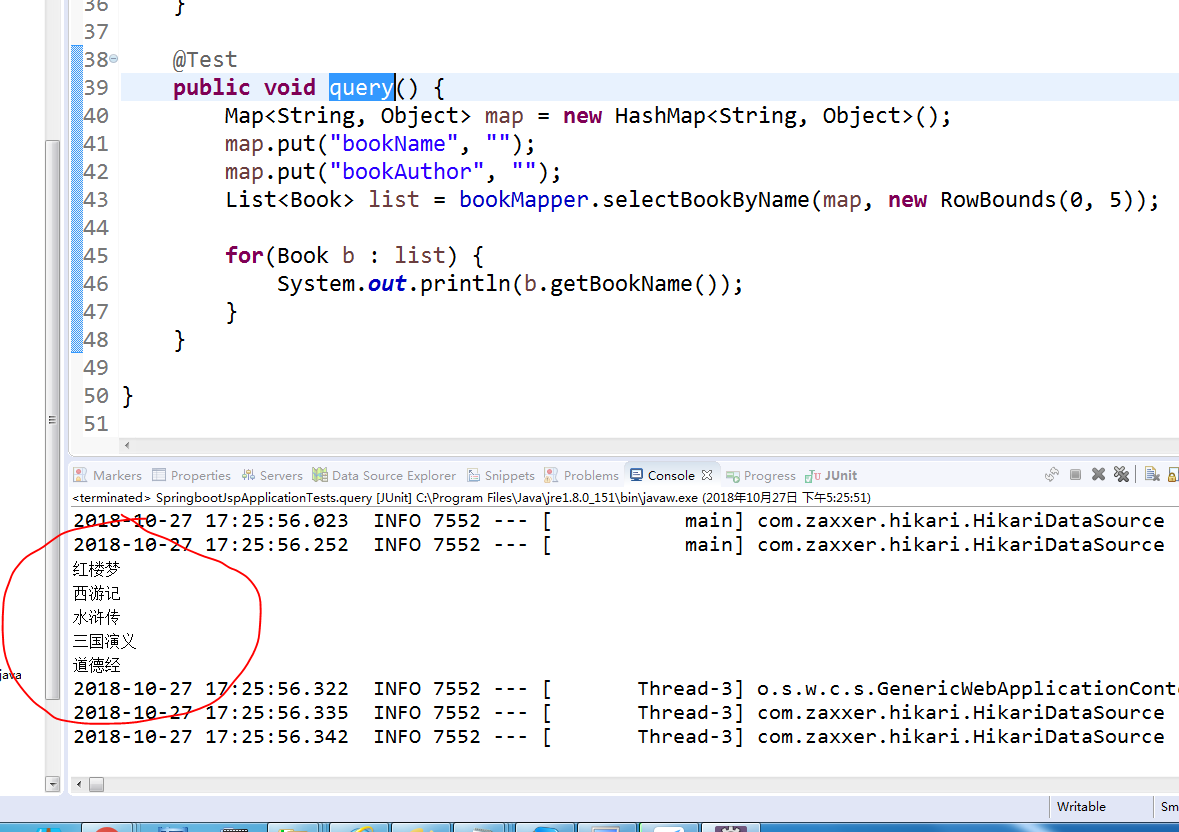
运行 query 查询第一页,5 条数据,效果如下
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190520.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
