大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
刚刚接触到深度学习,前2个月的时间里,我用一维的卷积神经网络实现了对于一维数据集的分类和回归。由于在做这次课题之前,我对深度学习基本上没有过接触,所以期间走了很多弯路。
在刚刚收到题目的要求时,我选择使用TensorFlow来直接编写函数,结果由于没有什么基础,写了一个周我就放弃了,改用keras来完成我的任务。
用keras来搭建神经网络其实很简单。我把自己的网络模型和数据集分享给大家,一起交流一起进步。
我们要完成的任务是对一些给定的湿度特征数据进行分类,多分类就是最简单最入门的深度学习案例。
我们要完成分类任务的数据集,247*900大小的一个矩阵,其中包含900条湿度信息,每条湿度信息由246位比特构成,最后一位表示湿度的类别,数值1-9,也就是每种湿度有100条。大家可以点击下边的链接自取。
或者百度网盘:
链接:https://pan.baidu.com/s/1R0Ok5lB_RaI2cVHychZuxQ
提取码:9nwi
复制这段内容后打开百度网盘手机App,操作更方便哦
首先是数据的导入:
# 载入数据
df = pd.read_csv(r"数据集-用做分类.csv")
X = np.expand_dims(df.values[:, 0:246].astype(float), axis=2)
Y = df.values[:, 246]X是900条数据的特征信息,Y表示真实类别。特别注意:这里的X在读取的时候矩阵增加了一维。使用一维卷积神经网络Conv1D的时候必须要事先这样对数据集进行处理,而只使用深度网络Dense时不需要额外的增加一维。
具体细节大家可以看我之前写过的一篇博客,比较细的区分了这两种情况:
没有接触过的读者可以查一下只使用深度层和使用卷积层的区别。CNN眼里只有局部小特征,而DNN只有全局大特征。
最普通的深层神经网络包含多层神经元,从输入信号中提取信息。每个神经元接受来自前一层神经元的输入,并通过权重和非线性将它们组合起来。与普通神经网络中每个神经元与前一层的所有神经元连接不同,CNN中的每个神经元只与前一层的少数神经元局部连接。而且,CNN同一层的所有神经元都有相同的权重。CNN层中神经元的值通常被称为特征映射(features maps),因为它们可以被看作是对应于输入的不同部分的特征。卷积神经网络可以很好地捕获出原数据中的局部简单特征,随着层数的增加,产生的特征映射会捕获输入信号越来越多的全局和更复杂的属性。它可以在一条数据中较短的片段中获得感兴趣的特征,并且该特征在该数据片段中的位置不具有高度相关性
紧接着是对湿度类别的编码:
# 湿度分类编码为数字
encoder = LabelEncoder()
Y_encoded = encoder.fit_transform(Y)
Y_onehot = np_utils.to_categorical(Y_encoded)Y_onehot编码是为了让程序自己来区分每一条特征信息而添加的编码。一个简单的例子解释一下:
这一步转化工作我们可以利用keras中的np_utils.to_categorical函数来进行。
“one-hot编码。one-hot编码的定义是用N位状态寄存器来对N个状态进行编码。比如[0,…,0],[1,…,1],[2,…,2]有3个分类值,因此N为3,对应的one-hot编码可以表示为100,010,001。”
我们将原始的数据集划分为训练集和测试集:
# 划分训练集,测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y_onehot, test_size=0.3, random_state=0)我这里把原始数据集以7:3的比例划分为训练集和测试集。训练集用来逼近真实类别,测试集来测试效果。
接着的是网络模型的搭建:
# 定义神经网络
def baseline_model():
model = Sequential()
model.add(Conv1D(16, 3, input_shape=(246, 1)))
model.add(Conv1D(16, 3, activation='tanh'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(MaxPooling1D(3))
model.add(Flatten())
model.add(Dense(9, activation='softmax'))
plot_model(model, to_file='./model_classifier.png', show_shapes=True) # 保存网络结构为图片,这一步可以直接去掉
print(model.summary()) # 显示网络结构
model.compile(loss='categorical_crossentropy',optimizer='adam', metrics=['accuracy'])
return model这一步往往是最核心的一步,网络模型通过卷积层来提取特征,在分类任务中,网络的最后一层为每个类。分类算法得到的是一个决策面,通过对比湿度信息属于每一类湿度的概率,进而对号入座。
经过多次调参尝试,最后我使用7层Conv1D来提取特征值,每两层Conv1D后添加一层MaxPooling1D来保留主要特征,减少计算量。每层卷积层使用双曲正切函数tanh(hyperbolic tangent function)来提高神经网络对模型的表达能力。tanh经常被运用到多分类任务中用做激活函数。
神经网络本就具有不可解释性,一般卷积核和全连接的结点数按照2的指数次幂来取。
Flatten()层作为中间层来链接卷积神经网络和全连接层。
神经网络被训练来最小化一个损失函数(Softmax loss),该函数捕捉到网络的特征输出与给定的期望输出之间的差异。9个输出结点对应九个类别的湿度,Softmax将每个特征数据匹配到概率最大的特征类别。
交叉熵损失函数(categorical crossentropy)作为模型训练的损失函数,它刻画的是当前学习到的概率分布与实际概率分布的距离,也就是损失函数越小,两个概率分布越相似,此时损失函数接近于0。
我将网络模型绘制成了AlexNet风格的示意图:
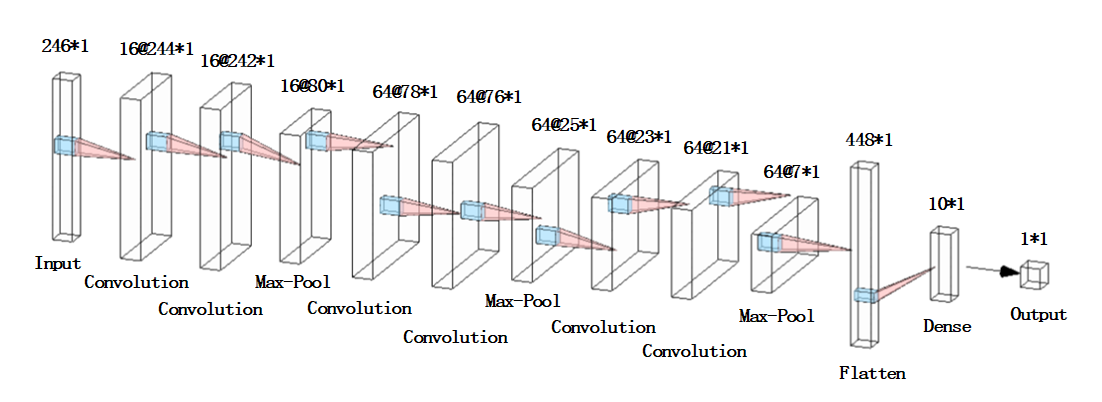

这里也给大家安利下这个很好用的绘制神经网络的工具:
http://alexlenail.me/NN-SVG/AlexNet.html
搭建好网络之后就可以开始训练了。
# 训练分类器
estimator = KerasClassifier(build_fn=baseline_model, epochs=40, batch_size=1, verbose=1)
estimator.fit(X_train, Y_train)batch_size设为1,然后一共训练40期。
这些数据大家都可以根据自己的实际情况做出调整和优化。
到这一步已经是搭建和训练的部分全部结束了。
紧接着是测试集来验证训练的准确性。
为了每次测试前不重复训练,我们将训练的模型保存下来:
# 将其模型转换为json
model_json = estimator.model.to_json()
with open(r"C:\Users\Desktop\model.json",'w')as json_file:
json_file.write(model_json)# 权重不在json中,只保存网络结构
estimator.model.save_weights('model.h5')下面是读取模型的部分,这一部分完全可以写到另一个函数里:
# 加载模型用做预测
json_file = open(r"C:\Users\Desktop\model.json", "r")
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
loaded_model.load_weights("model.h5")
print("loaded model from disk")
loaded_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 分类准确率
print("The accuracy of the classification model:")
scores = loaded_model.evaluate(X_test, Y_test, verbose=0)
print('%s: %.2f%%' % (loaded_model.metrics_names[1], scores[1] * 100))
# 输出预测类别
predicted = loaded_model.predict(X)
predicted_label = loaded_model.predict_classes(X)
print("predicted label:\n " + str(predicted_label))当然我们也希望可以直观的显示出模型的分类精度,和训练的过程。
混淆矩阵经常用来表示分类的效果。
#显示混淆矩阵
plot_confuse(estimator.model, X_test, Y_test)当然也需要我们自己写出来:
# 混淆矩阵定义
def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt.cm.jet):
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks,('0%','3%','5%','8%','10%','12%','15%','18%','20%','25%'))
plt.yticks(tick_marks,('0%','3%','5%','8%','10%','12%','15%','18%','20%','25%'))
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, '{:.2f}'.format(cm[i, j]), horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('真实类别')
plt.xlabel('预测类别')
plt.savefig('test_xx.png', dpi=200, bbox_inches='tight', transparent=False)
plt.show()
# 显示混淆矩阵
def plot_confuse(model, x_val, y_val):
predictions = model.predict_classes(x_val)
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
conf_mat = confusion_matrix(y_true=truelabel, y_pred=predictions)
plt.figure()
plot_confusion_matrix(conf_mat, range(np.max(truelabel)+1))
如果好奇的话你也可以看看每层卷积层到底学到了什么:
# 可视化卷积层
visual(estimator.model, X_train, 1)但是我觉得看一维卷积层的特征没啥意义,毕竟都是一些点,看起来有点非人类。
# 卷积网络可视化
def visual(model, data, num_layer=1):
# data:图像array数据
# layer:第n层的输出
layer = keras.backend.function([model.layers[0].input], [model.layers[num_layer].output])
f1 = layer([data])[0]
print(f1.shape)
num = f1.shape[-1]
print(num)
plt.figure(figsize=(8, 8))
for i in range(num):
plt.subplot(np.ceil(np.sqrt(num)), np.ceil(np.sqrt(num)), i+1)
plt.imshow(f1[:, :, i] * 255, cmap='gray')
plt.axis('off')
plt.show()最后运行的所有结果如下:

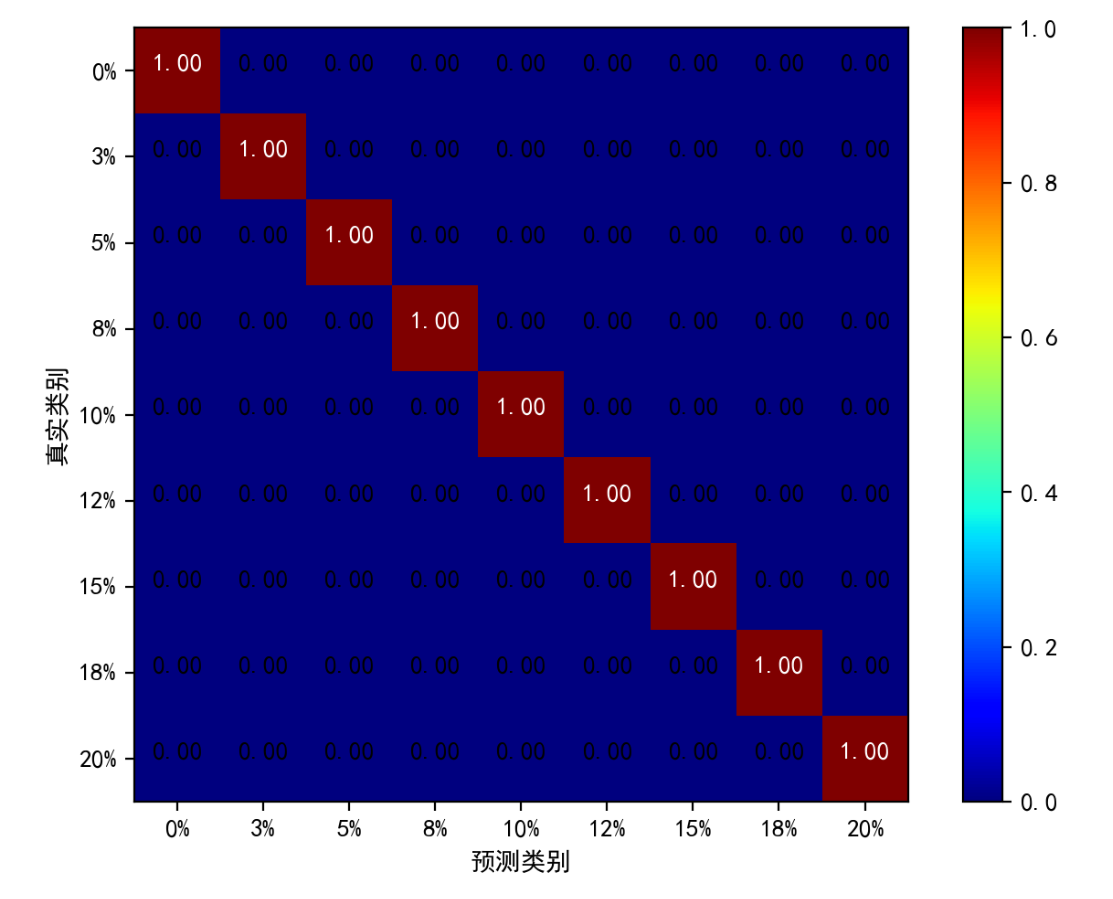
这个结果这么好纯粹是因为数据比较好,分类的准确率很大程度都是依赖你数据集本身的区分度的。
下面是数据集的特征图,从图上就可以看出数据的层次性很直观。
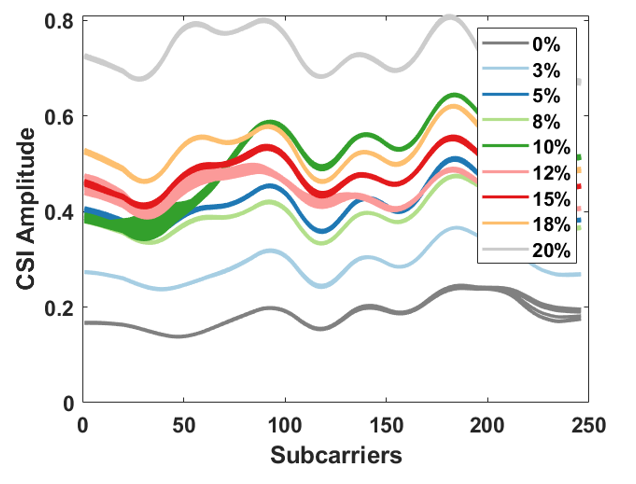
当然我给大家上传的这部分数据是我这边结果最好的一批,其他数据集准确度达不到这么高。
下面贴出整个分类过程的完整代码:
# -*- coding: utf8 -*-
import numpy as np
import pandas as pd
import keras
from keras.models import Sequential
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils,plot_model
from sklearn.model_selection import cross_val_score,train_test_split,KFold
from sklearn.preprocessing import LabelEncoder
from keras.layers import Dense,Dropout,Flatten,Conv1D,MaxPooling1D
from keras.models import model_from_json
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import itertools
# 载入数据
df = pd.read_csv(r"C:\Users\Desktop\数据集-用做分类.csv")
X = np.expand_dims(df.values[:, 0:246].astype(float), axis=2)
Y = df.values[:, 246]
# 湿度分类编码为数字
encoder = LabelEncoder()
Y_encoded = encoder.fit_transform(Y)
Y_onehot = np_utils.to_categorical(Y_encoded)
# 划分训练集,测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y_onehot, test_size=0.3, random_state=0)
# 定义神经网络
def baseline_model():
model = Sequential()
model.add(Conv1D(16, 3, input_shape=(246, 1)))
model.add(Conv1D(16, 3, activation='tanh'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(MaxPooling1D(3))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(Conv1D(64, 3, activation='tanh'))
model.add(MaxPooling1D(3))
model.add(Flatten())
model.add(Dense(9, activation='softmax'))
plot_model(model, to_file='./model_classifier.png', show_shapes=True)
print(model.summary())
model.compile(loss='categorical_crossentropy',optimizer='adam', metrics=['accuracy'])
return model
# 训练分类器
estimator = KerasClassifier(build_fn=baseline_model, epochs=40, batch_size=1, verbose=1)
estimator.fit(X_train, Y_train)
# 卷积网络可视化
# def visual(model, data, num_layer=1):
# # data:图像array数据
# # layer:第n层的输出
# layer = keras.backend.function([model.layers[0].input], [model.layers[num_layer].output])
# f1 = layer([data])[0]
# print(f1.shape)
# num = f1.shape[-1]
# print(num)
# plt.figure(figsize=(8, 8))
# for i in range(num):
# plt.subplot(np.ceil(np.sqrt(num)), np.ceil(np.sqrt(num)), i+1)
# plt.imshow(f1[:, :, i] * 255, cmap='gray')
# plt.axis('off')
# plt.show()
# 混淆矩阵定义
def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt.cm.jet):
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks,('0%','3%','5%','8%','10%','12%','15%','18%','20%','25%'))
plt.yticks(tick_marks,('0%','3%','5%','8%','10%','12%','15%','18%','20%','25%'))
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, '{:.2f}'.format(cm[i, j]), horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('真实类别')
plt.xlabel('预测类别')
plt.savefig('test_xx.png', dpi=200, bbox_inches='tight', transparent=False)
plt.show()
# seed = 42
# np.random.seed(seed)
# kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
# result = cross_val_score(estimator, X, Y_onehot, cv=kfold)
# print("Accuracy of cross validation, mean %.2f, std %.2f\n" % (result.mean(), result.std()))
# 显示混淆矩阵
def plot_confuse(model, x_val, y_val):
predictions = model.predict_classes(x_val)
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
conf_mat = confusion_matrix(y_true=truelabel, y_pred=predictions)
plt.figure()
plot_confusion_matrix(conf_mat, range(np.max(truelabel)+1))
# 将其模型转换为json
model_json = estimator.model.to_json()
with open(r"C:\Users\316CJW\Desktop\毕设代码\model.json",'w')as json_file:
json_file.write(model_json)# 权重不在json中,只保存网络结构
estimator.model.save_weights('model.h5')
# 加载模型用做预测
json_file = open(r"C:\Users\Desktop\model.json", "r")
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
loaded_model.load_weights("model.h5")
print("loaded model from disk")
loaded_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 分类准确率
print("The accuracy of the classification model:")
scores = loaded_model.evaluate(X_test, Y_test, verbose=0)
print('%s: %.2f%%' % (loaded_model.metrics_names[1], scores[1] * 100))
# 输出预测类别
predicted = loaded_model.predict(X)
predicted_label = loaded_model.predict_classes(X)
print("predicted label:\n " + str(predicted_label))
#显示混淆矩阵
plot_confuse(estimator.model, X_test, Y_test)
# 可视化卷积层
# visual(estimator.model, X_train, 1)但是,湿度值到底是连续的数值,分类任务验证了我们数据集特征的可分辨性。
下一篇博客中,我将对数据集稍作修改,将湿度类别改为真实湿度值。
利用卷积神经网络来提取特征,实现线性回归,二者同出一脉。
比起其他科普的博客,我这篇文章更像是在学习如何利用工具做深度学习。
希望大家多多支持,不足之处互相交流(●ˇ∀ˇ●)!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190492.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
