大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
TiDB存储引擎TiKV是基于RocksDB存储引擎,通过Raft分布式算法保证数据一致性。本文详细介绍了TiKV存储引擎的实现机制和原理,加深对TiDB底层存储架构的理解。
1、TiDB存储引擎TiKV
TiDB存储引擎TiKV是分布式的key-value存储引擎,它是一种高度分层的架构,通过Raft协议保证数据一致性,不依赖于分布式文件系统。

1.1 存储引擎RocksDB
RocksDB是由Facebook基于LevelDB开发的一款提供key-value存储与读写功能的LSM-tree架构引擎。RocksDB适用于多CPU场景、高效利用fast storage比如SSD、弹性扩展架构、支持IO-bound/in-memory/write-once等功能。
RocksDB不是一个分布式的DB,而是一个高效、高性能、单点的数据库引擎。RocksDB持久化存储key-value键值对数据,keys 和values可以是任意的字节流,且按照keys以log-structured merge tree的形式有序存储。
来源:https://www.cnblogs.com/cobbliu/articles/9553271.html
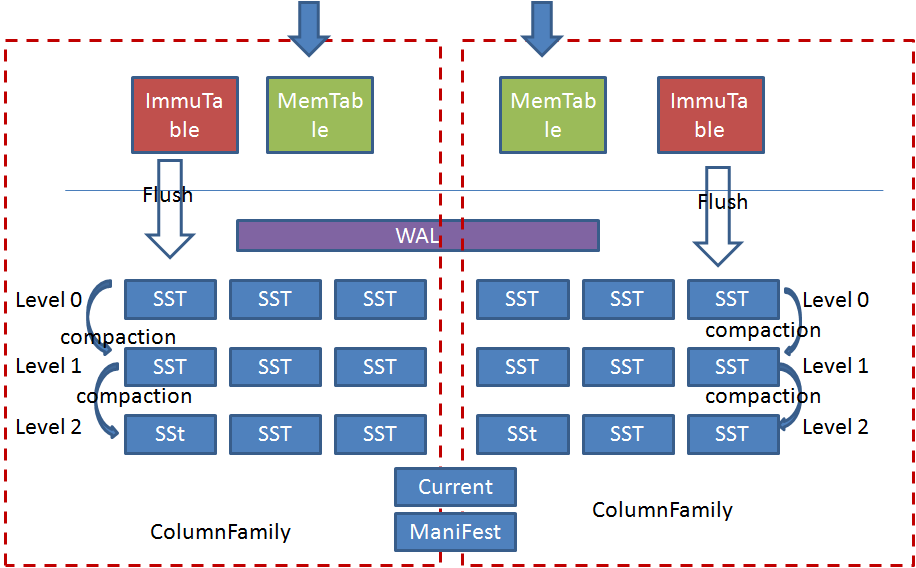
上图就是Rocksdb的基础架构,主要完成以下功能:
- Rocksdb中引入了ColumnFamily(列族, CF)的概念,所谓列族也就是一系列kv组成的数据集。所有的读写操作都需要先指定列族。
- 写操作先写WAL,再写memtable,memtable达到一定阈值后切换为Immutable Memtable,只能读不能写。
- 后台Flush线程负责按照时间顺序将Immu Memtable刷盘,生成level0层的有序文件(SST)。
- SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是上一层的 10 倍(因此 90% 的数据存储在最后一层)。
- Manifest负责记录系统某个时刻SST文件的视图,Current文件记录当前最新的Manifest文件名。
- 每个ColumnFamily有自己的Memtable, SST文件,所有ColumnFamily共享WAL、Current、Manifest文件。
RocksDB作为TiKV的核心存储引擎,用于存储Raft日志以及用户数据。每个TiKV实例中有两个RocksDB实例,一个用于存储Raft日志(通常被称为raftdb),另一个用于存储用户数据以及MVCC信息(通常被称为kvdb)。kvdb中有四个ColumnFamily:raft、lock、default和write:
- raft列:用于存储各个Region的元信息,仅占极少量空间
- lock列:用于存储悲观事务的悲观锁以及分布式事务的一阶段Prewrite锁。当用户的事务提交之后, lock cf中对应的数据会很快删除掉,因此大部分情况下lock cf中的数据也很少(少于1GB)。如果lock cf中的数据大量增加,说明有大量事务等待提交,系统出现了bug或者故障。
- write列:用于存储用户真实的写入数据以及MVCC信息(该数据所属事务的开始时间以及提交时间)。当用户写入了一行数据时,如果该行数据长度小于255字节,那么会被存储write列中,否则的话该行数据会被存入到default列中。由于TiDB的非unique 索引存储的value为空,unique索引存储的value为主键索引,因此二级索引只会占用writecf的空间。
- default列:用于存储超过255字节长度的数据
1.2 LSM-tree
LSM-Tree全称是Log Structured Merge Tree,是一种分层、有序、面向磁盘的数据结构,其核心思想是充分了利用了磁盘批量的顺序写要远比随机写性能高出很多。这种结构的写入,全部都是以Append的模式追加,不存在删除和修改,但是是以牺牲部分读取性能为代价尤其是随机读,通常适合于写多读少的场景。
1.2.1 LSM-tree和SST-table
在LSM-Tree里面,核心的数据结构就是SSTable,全称是Sorted String Table。SSTable是一种拥有持久化,有序且不可变的的键值存储结构,它的key和value都是任意的字节数组,并且了提供了按指定key查找和指定范围的key区间迭代遍历的功能。SSTable内部包含了一系列可配置大小的Block块,典型的大小是64KB,关于这些Block块的index存储在SSTable的尾部,用于帮助快速查找特定的Block。当一个SSTable被打开的时候,index会被加载到内存,然后根据key在内存index里面进行一个二分查找,查到该key对应的磁盘的offset之后,然后去磁盘把响应的块数据读取出来。当然如果内存足够大的话,可以直接把SSTable直接通过MMap的技术映射到内存中,从而提供更快的查找。

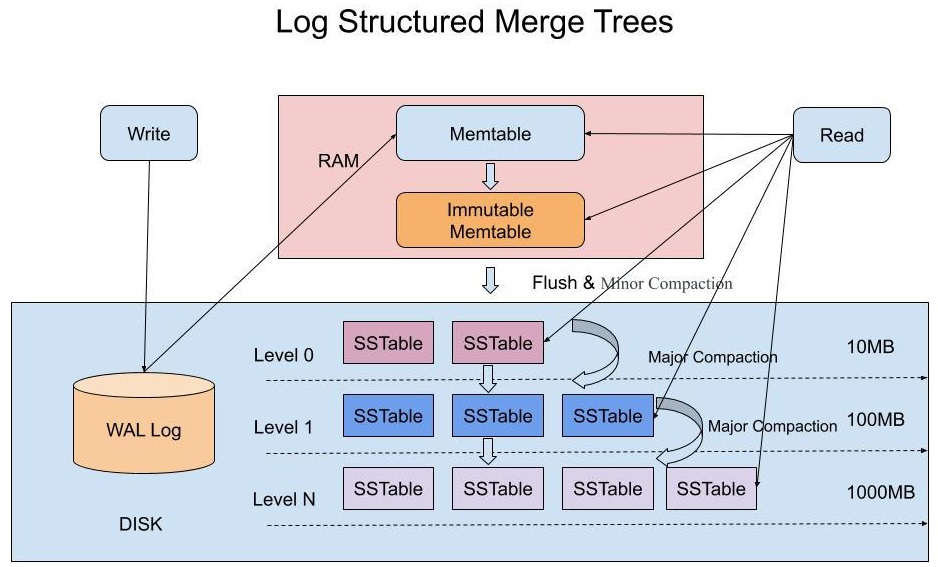
在LSM-Tree里,SSTable有一份在内存里面,其他的多级在磁盘上,如下图所示:
来源:https://blog.csdn.net/u010454030/article/details/90414063
- LSM-tree中写数据流程
- 当收到一个写请求时,会先把该条数据记录在WAL Log里面,用作故障恢复。
- 当写完WAL Log后,会把该条数据写入内存的SSTable里面(删除是标记,更新是新记录一条的数据),也称Memtable。注意为了维持有序性在内存里面可以采用红黑树或者跳跃表相关的数据结构。
- 当Memtable超过一定的大小后,会在内存里面冻结,变成不可变的Memtable,同时为了不阻塞写操作需要新生成一个Memtable继续提供服务。
- 把内存里面不可变的Memtable给dump到到硬盘上的SSTable层中,此步骤也称为Minor Compaction,这里需要注意在L0层的SSTable是没有进行合并的,所以这里的key range在多个SSTable中可能会出现重叠,在层数大于0层之后的SSTable,不存在重叠key。
- 当每层的磁盘上的SSTable的体积超过一定的大小或者个数,也会周期的进行合并。此步骤也称为Major Compaction,这个阶段会真正的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间,注意由于SSTable都是有序的,我们可以直接采用merge sort进行高效合并。
- LSM-tree中读数据流程
- 当收到一个读请求的时候,会直接先在内存里面查询,如果查询到就返回。
- 如果没有查询到就会依次下沉,知道把所有的Level层查询一遍得到最终结果。
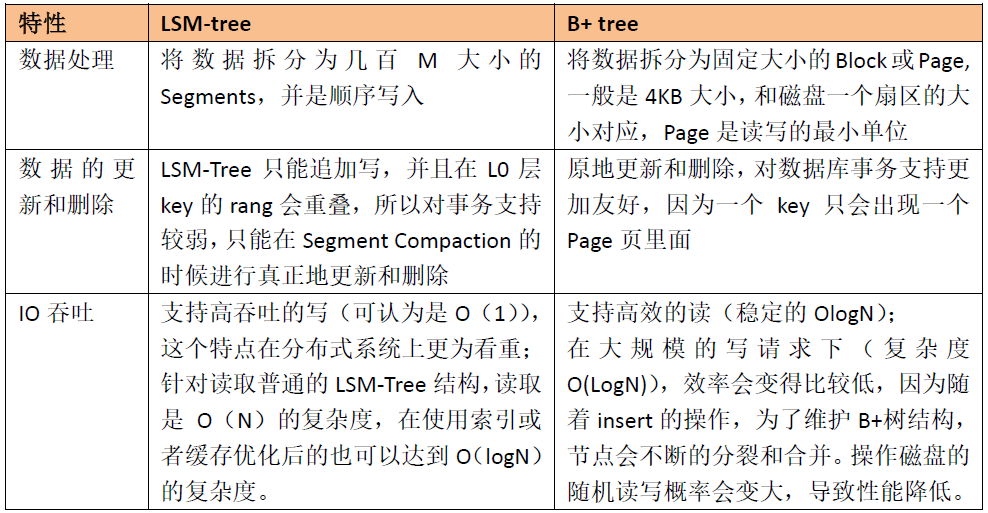
1.2.2 LSM-tree和B+ tree
LSM-tree和B+ tree的特性如下所示:
来源:In Search of an Understandable Consensus Algorithm
还有一点是基于LSM-Tree分层存储能够做到写的高吞吐,带来的副作用是整个系统必须频繁的进行compaction,写入量越大,Compaction的过程越频繁。而compaction是一个compare & merge的过程,非常消耗CPU和存储IO,在高吞吐的写入情形下,大量的compaction操作占用大量系统资源,必然带来整个系统性能断崖式下跌,对应用系统产生巨大影响,当然我们可以禁用自动Major Compaction,在每天系统低峰期定期触发合并,来避免这个问题。
1.3 Raft算法
Raft是一个共识算法,所谓共识就是多个节点多某个事情达成一致。Raft算法提供几个重要的功能:leader选举、成员变更以及日志复制。
1.3.1 Leader选举
在raft协议中,一个节点任一时刻处于以下三个状态之一:leader、follower和candidate。
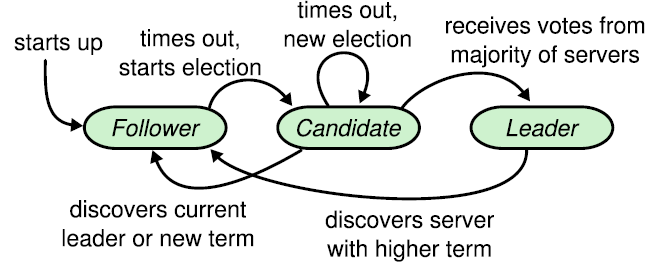
- 所有节点启动时都是follower状态;
- 在一段时间内如果没有收到来自leader的心跳,从follower切换到candidate,发起选举;
- 如果收到majority的造成票(含自己的一票)则切换到leader状态;
- 如果发现其他节点比自己更新,则主动切换到follower。
总之,系统中最多只有一个leader,如果在一段时间里发现没有leader,则大家通过选举-投票选出leader。leader会不停的给follower发心跳消息,表明自己的存活状态。如果leader故障,那么follower会转换成candidate,重新选出leader。
- 选举详细过程
如果follower在election timeout内没有收到来自leader的心跳,则会主动发起选举。步骤如下:
- 增加节点本地的 current term ,切换到candidate状态
- 投自己一票
- 并行给其他节点发送 RequestVote RPCs
- 等待其他节点的回复
在这个过程中,根据来自其他节点的消息,可能出现三种结果:
- 收到多数的投票(含自己的一票),则赢得选举,成为leader
- 被告知别人已当选,那么自行切换到follower
- 一段时间内没有收到majority投票,则保持candidate状态,重新发出选举
第一种情况,赢得了选举之后,新的leader会立刻给所有节点发消息,广而告之,避免其余节点触发新的选举。在这里,先回到投票者的视角,投票者如何决定是否给一个选举请求投票呢,有以下约束:
- 在任一任期内,单个节点最多只能投一票
- 候选人知道的信息不能比自己的少(这一部分,后面介绍log replication和safety的时候会详细介绍)
- first-come-first-served 先来先得
第二种情况,比如有三个节点A B C。A B同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的第一个约束,即C不会给B投票,而A和B显然都不会给对方投票。A胜出之后,会给B,C发心跳消息,节点B发现节点A的term不低于自己的term,知道有已经有Leader了,于是转换成follower。
第三种情况,没有任何节点获得majority投票。假如有四个节点,Node C、Node D同时成为了candidate,进入了term 4,但Node A投了NodeD一票,NodeB投了Node C一票,这就出现了平票 split vote的情况。这个时候大家都在等啊等,直到超时后重新发起选举。如果出现平票的情况,那么就延长了系统不可用的时间(没有leader是不能处理客户端写请求的),因此raft引入了randomized election timeouts来尽量避免平票情况。同时,leader-based 共识算法中,节点的数目都是奇数个,尽量保证majority的出现。
1.3.2 日志复制
选举leader以后,系统可以对外进行工作。客户端的请求发送到leader,leader来调度这些并发请求的顺序,并保证leader和follower状态的一致性。在Raft算法中,将这些请求以及执行顺序告知followers,leader和followers以相同的顺序来执行这些请求,保证状态一致。
共识算法一般是通过复制状态机来实现的,复制状态机简单来说就是:相同的初识状态 + 相同的输入=相同的结束状态。 如何保证所有节点按照相同的顺序执行相同的输入,replicated log可以实现,log具有持久化、有序的特点,是大多数分布式系统的基石。因此,在raft算法中,leader将客户端请求封装到一个个log entry,然后将这些log entries复制到所有follower节点,然后大家按相同顺序应用log entry中的command,来保证状态一致性。
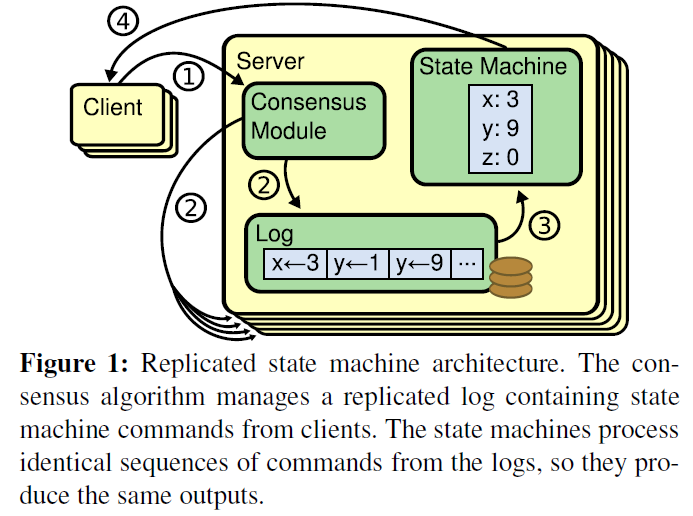
当系统(leader)收到一个来自客户端的写请求,到返回给客户端,整个过程从leader的视角来看会经历以下步骤:
- leader以append方式写log entry
- leader 并行发送AppendEntries RPC
- leader等待majority回应
- leader将log entry应用到state machine
- leader回复消息到client
- leader通知follower应用log
可以看到日志的提交过程有点类似两阶段提交(2PC),不过与2PC的区别在于,leader只需要大多数(majority)节点的回复即可,这样只要超过一半节点处于工作状态则系统就是可用的。每个节点的日志并不完全一致,raft算法为了保证高可用,并不是强一致性,而是最终一致性,leader会不断尝试给follower发log entries,直到所有节点的log entries都相同。
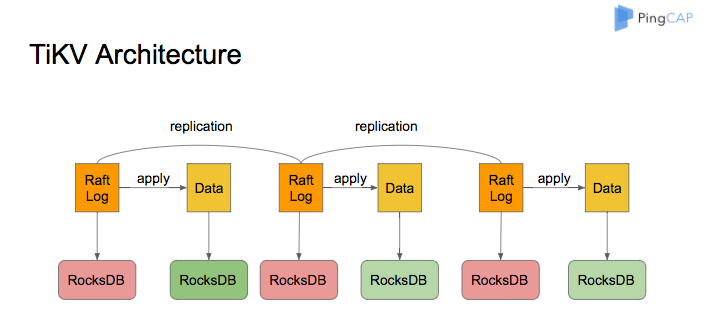
1.3.3 TiKV中的Raft
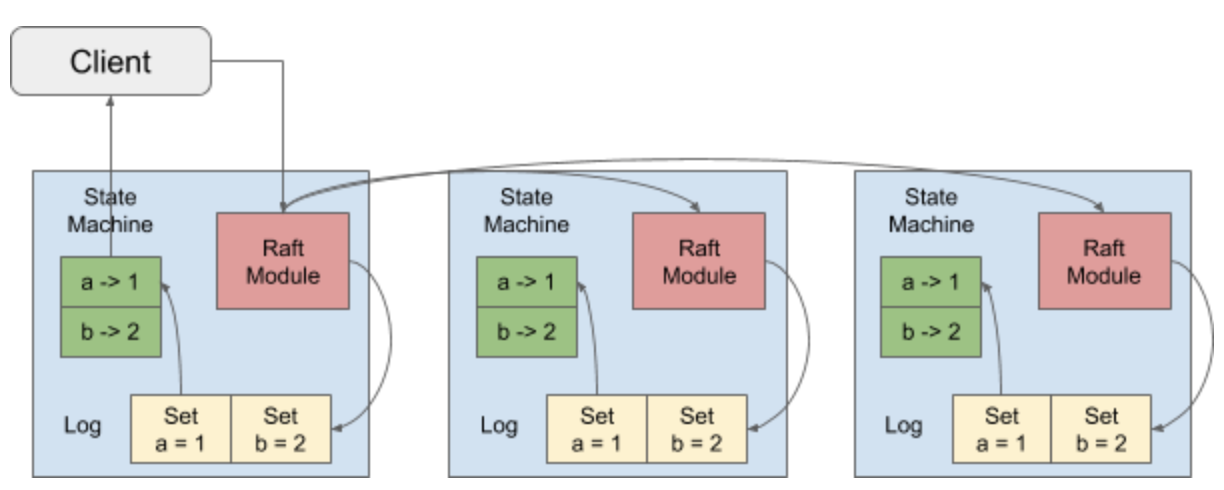
来源:https://en.pingcap.com/blog/how-tikv-reads-and-writes
TiKV使用Raft算法来保证数据的一致性,默认情况下使用3副本组成一个raft group,过Raft的日志复制功能,将数据安全可靠地同步到raft group的每一个节点中。
- 当client端需要写数据的时候,它会发送请求给Raft Leader,Leader会将操作解码为log entry并以append方式写入自己的Raft log中
- Leader会根据Raft算法将log entry复制到Follower,Follower也会将这些entry追加到log entry中,并且通知Leader已经完成
- 当Leader发现log entry追加到多数majority节点中,它会认为这个log entry已经committed。之后Leader会解码entry中的操作,执行它们并应用到状态机中,这个过程称之为apply
另外,TiKV支持lease Read功能:对于读请求,可以直接发送给Leader,如果leader判断基于时间的lease没有过期,则可以直接提供读请求的客户端,不需要经过Raft算法过程;如果过期了,则leader需要强制通过Raft算法来更新lease内容提供该客户端。
1.4 TiKV中的分区Region
TiKV可以看做是一个巨大的有序的KV Map,那么为了实现存储的水平扩展,数据将被分散在多台机器上。 对于一个KV系统,将数据分散在多台机器上有两种比较典型的方案:
- Hash:按照Key做Hash,根据Hash值选择对应的存储节点
- Range:按照Key分Range,某一段连续的Key都保存在一个存储节点上
因为使用RocksDB存储引擎,出于性能考量TiKV使用range做分区,将整个Key-Value空间分成很多段,每一段是一系列连续的Key,这些段叫做一个Region,目前在TiKV中Region默认的大小是96MB。每一个Region都可以用[StartKey,EndKey)这样一个左闭右开区间来描述。将数据划分成Region后,TiKV将完成两件事情:
- 以Region为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的Region数量差不多
- 以Region为单位做Raft的复制和成员管理
1)以Region为单位分散数据
数据按照Key切分成很多Region,每个Region的数据只会保存在一个节点上面。TiDB系统通过PD来负责将Region尽可能均匀的散布在集群中所有的节点上,这样一方面实现了存储容量的水平扩展(增加新的节点后,会自动将其他节点上的Region调度过来),另一方面也实现了负载均衡(不会出现某个节点有很多数据,其他节点上没什么数据的情况)。同时为了保证上层客户端能够访问所需要的数据,系统中也会使用PD记录Region在节点上面的分布情况,也就是通过任意一个Key就能查询到这个Key在哪个Region中,以及这个Region目前在哪个节点上(即Key的位置路由信息)。
2)以Region为单位做Raft的复制和成员管理
TiKV是以Region为单位做数据的复制,也就是一个Region的数据会保存多个副本,TiKV将每一个副本叫做一个Replica。Replica之间是通过Raft来保持数据的一致,一个Region的多个Replica会保存在不同的节点上,构成一个Raft Group。其中一个Replica会作为这个 Group的Leader,其他的Replica作为Follower。默认情况下,所有的读和写都是通过Leader进行,读操作在Leader上即可完成,而写操作再由 Leader 复制给 Follower。
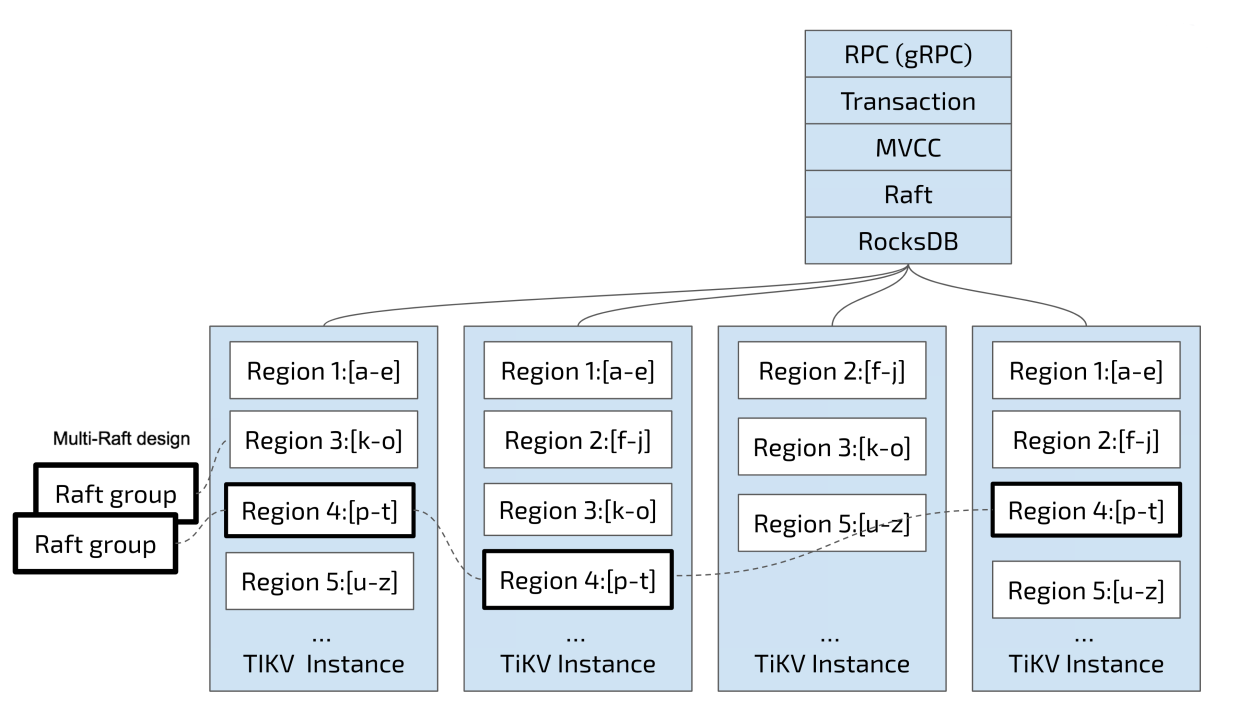
以Region为单位做数据的分散和复制,TiKV就成为了一个分布式的具备一定容灾能力的KeyValue系统,不用再担心数据存不下,或者是磁盘故障丢失数据的问题。
1.5 事务模型Percolator
Percolator是基于Bigtable,利用了Bigtable的单行事务特性,实现了跨行跨表的事务特性(ACID)。Percolator实现的事务具有如下特点:
- 利用了Bigtable的单行事务。因为Bigtable基于GFS提供了可靠的存储和原子写特性,Bigtable被选作用于实现锁服务。
- Percolator利用了Bigtable的timestamp来提供快照隔离(snapshot isolation),快照隔离为每一个事务提供了一个一致的快照视图。如果两个事务同时修改同一个行,那么事务冲突,其中一个事务必须回滚然后重试。
1.5.1 Percolator两阶段提交的实现
Precolator通过访问Bigtable获取数据,但是Bigtable中数据不是直接由Bigtable的节点来控制的,而是存储在GFS上面的,因此Precolator需要显式的维护锁。在所有启用了Percolator事务的表中,每一个列族都会预先增加两个列,分别是:
- lock:存储事务过程中的锁信息;
- write:存储当前行可见(最近一次提交)的版本号
Percolator事务分为两个阶段:预写(Pre-write)和提交(Commit),本质上相当于一个加强的2PC。
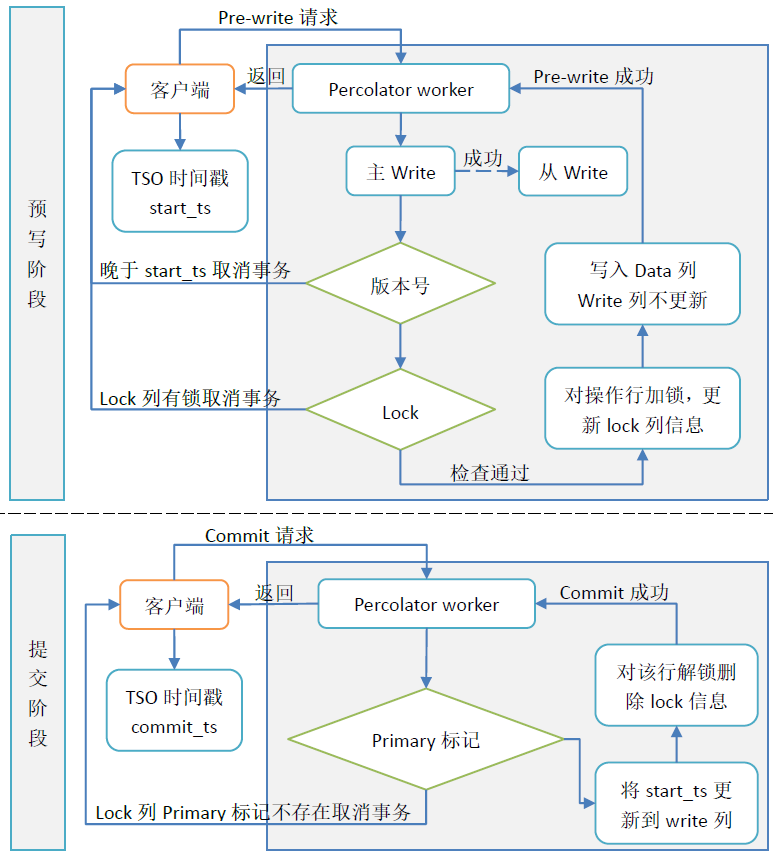
- 预写阶段
- 客户端启动事务,从TSO获取时间戳,记为start_ts,并向Percolator Worker发起Pre-write请求。
- 在该事务包含的所有写操作中选取一个作为主(primary)操作,其余的作为次(secondary)操作。主操作将作为整个事务的互斥点,标记事务的状态。
- 先预写主操作,成功后再预写次操作。在预写过程中,对每一个写操作都要执行检查:
- 检查写入的行对应的write列版本号是否晚于start_ts,如果是,说明有版本冲突,直接取消整个事务;
- 检查写入的行对应的lock列是否有锁,如果有,说明其他事务正在写,直接取消整个事务。
- 检查通过后,以start_ts作为版本号将数据写入data列,但不更新write列,亦即此时写入的数据仍然不可见。
- 对操作行加锁,即更新lock列的锁信息:主操作行的lock直接标为primary,次操作行的lock则标为主操作行的行键和列名。
注意:处理每一行时,上述步骤3、4、5每次都会在同一个Bigtable单行事务中进行,保证原子性。
- 提交阶段
- 客户端从TSO获取时间戳,记为commit_ts,并向Percolator Worker发起Commit请求。
- 检查主操作行对应的lock列所在的primary标记是否存在,如果不存在(可能已经被清理,见后文所述)则失败,取消事务;如果存在则继续。
- 以commit_ts作为版本号,将start_ts更新到write列中。也就是说在本阶段完成后,预写阶段写入的数据将会可见。
- 对该行解锁,即删除lock列的锁信息。
- 若步骤1~4均成功,说明主操作行成功,代表整个事务实际上已经提交。接下来只需异步地提交每个次操作即可,即重复步骤3、4的更新write列和清除lock列操作。
注意:上述步骤2、3、4会在同一个Bigtable单行事务中进行,保证原子性。另外,如果次操作的提交失败,则仍然要回滚事务。
1.5.2 TiKV中事务写操作
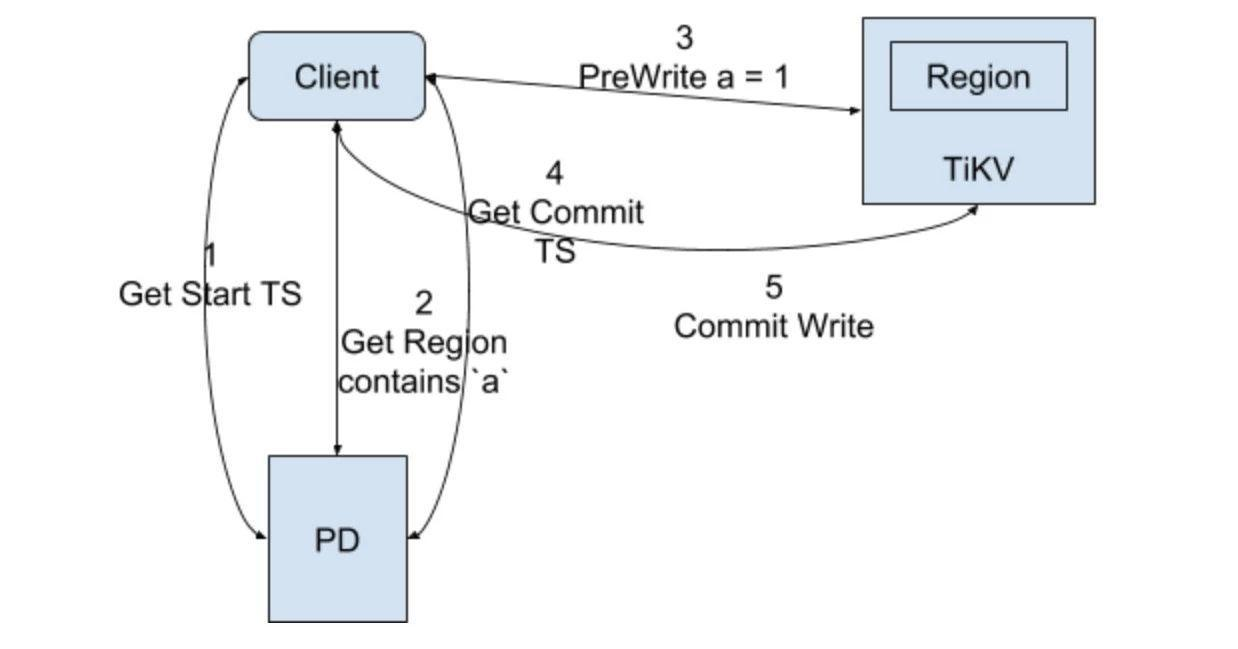
事务提交前,在客户端 buffer 所有的 update/delete 操作。
- Prewrite阶段
- 首先在所有行的写操作中选出一个作为primary,其他的为secondaries。
- Prewrite Primary: 对 primaryRow 写入 L 列(上锁),L 列中记录本次事务的开始时间戳。写入 L 列前会检查:
- 是否已经有别的客户端已经上锁 (Locking)。
- 是否在本次事务开始时间之后,检查 W 列,是否有更新 [startTs, +Inf) 的写操作已经提交 (Conflict)。
- 在这两种种情况下会返回事务冲突。否则,就成功上锁。将行的内容写入row中,时间戳设置为startTs。
- 将primaryRow的锁上好了以后,进行secondaries的prewrite流程。类似primaryRow的上锁流程,只不过锁的内容为事务开始时间及primaryRow的Lock的信息。检查的事项同 primaryRow 的一致。
- 当锁成功写入后,写入row,时间戳设置为startTs
注:以上Prewrite流程任何一步发生错误,都会进行回滚:删除Lock,删除版本为startTs的数据。
- Commit阶段
当Prewrite完成以后,进入Commit阶段,当前时间戳为commitTs,且commitTs> startTs :
- commit primary:写入W列新数据,时间戳为commitTs,内容为startTs,表明数据的最新版本是startTs对应的数据。
- 删除L列
如果primary row提交失败的话,全事务回滚,回滚逻辑同prewrite。如果commit primary成功,则可以异步的commit secondaries, 流程和commit primary一致, 失败了也无所谓。
1.5.3 TiKV中事务的读操作
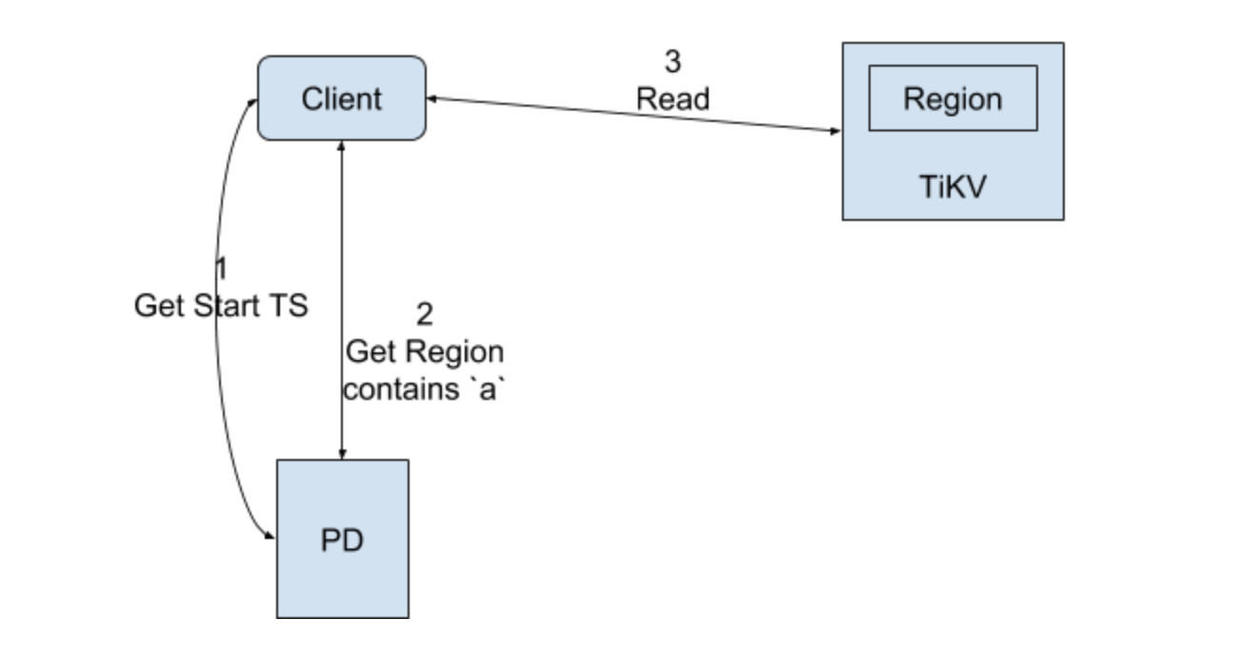
- 检查该行是否有L列,时间戳为[0, startTs],如果有,表示目前有其他事务正占用此行,如果这个锁已经超时则尝试清除,否则等待超时或者其他事务主动解锁。注意此时不能直接返回老版本的数据,否则会发生幻读的问题。
- 读取至startTs时该行最新的数据,方法是:读取W列,时间戳为[0, startTs], 获取这一列的值,转化成时间戳t, 然后读取此列于t版本的数据内容。
由于锁是分两级的,primary和seconary,只要primary的行锁去掉,就表示该事务已经成功提交,这样的好处是secondary的commit是可以异步进行的,只是在异步提交进行的过程中 ,如果此时有读请求,可能会需要做一下锁的清理工作。
参考资料:
- https://docs.pingcap.com/zh/tidb/stable/tidb-storage
- https://www.cnblogs.com/cobbliu/articles/9553271.html
- https://www.jianshu.com/p/3302be5542c7
- https://blog.csdn.net/u010454030/article/details/90414063
- https://www.cnblogs.com/xybaby/p/10124083.html
- https://www.jianshu.com/p/c39e64d6c5da
- https://pingcap.com/blog-cn/percolator-and-txn/
- https://www.jianshu.com/p/05194f4b29dd
- https://en.pingcap.com/blog/how-tikv-reads-and-writes
转载请注明原文地址:https://blog.csdn.net/solihawk/article/details/118926380
文章会同步在公众号“牧羊人的方向”更新,感兴趣的可以关注公众号,谢谢!

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190430.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
