大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
以TiKvConfig struct为起始点,从TiKvConfig内部的字段开始,分析每个模块的作用和配置检查逻辑所做的事情。
TiKV 是一个分布式事务型的键值数据库,是TiDB的存储层,提供了满足 ACID 约束的分布式事务接口,并且通过 Raft 协议保证了多副本数据一致性以及高可用。关于TiDB、TiKV的详细介绍可以从官网查阅,这里就不多赘述了。
知乎上已经有一篇高屋建瓴的文章,由TiKV亲爹Ed写的TiKV代码初探,可以从整体了解TiKV的内部功能,不过作为喜欢阅读代码的攻城狮来说,更喜欢来一个庖丁解牛式的分析。所以我们从代码级别粗略的分析一下TiKV。
我们首先选择了Config这部分代码逻辑来分析,一个是相对其他功能模块来说,这部分代码没有太烧脑的算法逻辑,另一个原因是这部分代码是整个TiKV启动后马上运行的部分,是最先碰到的代码逻辑,再有就是可以通过配置代码大体了解TiKV内部那些重要的功能模块们,从而避免繁杂的细节导致窥测一斑的局限。如果想整体了解配置字段,我们可以从官网上查阅完整的配置说明文档。
文章中所参考的代码是基于Oct 29, 2020 master分支来进行分析的,可能会和最新的代码有出入,读者需要按照实际情况判别。


从配置流程主干流程上可以看到,系统从cmd/bin/tikv-server开始运行,进入cmd/src/setup获取配置文件参数,之后进入src/config.rs执行各个模块的配置逻辑。
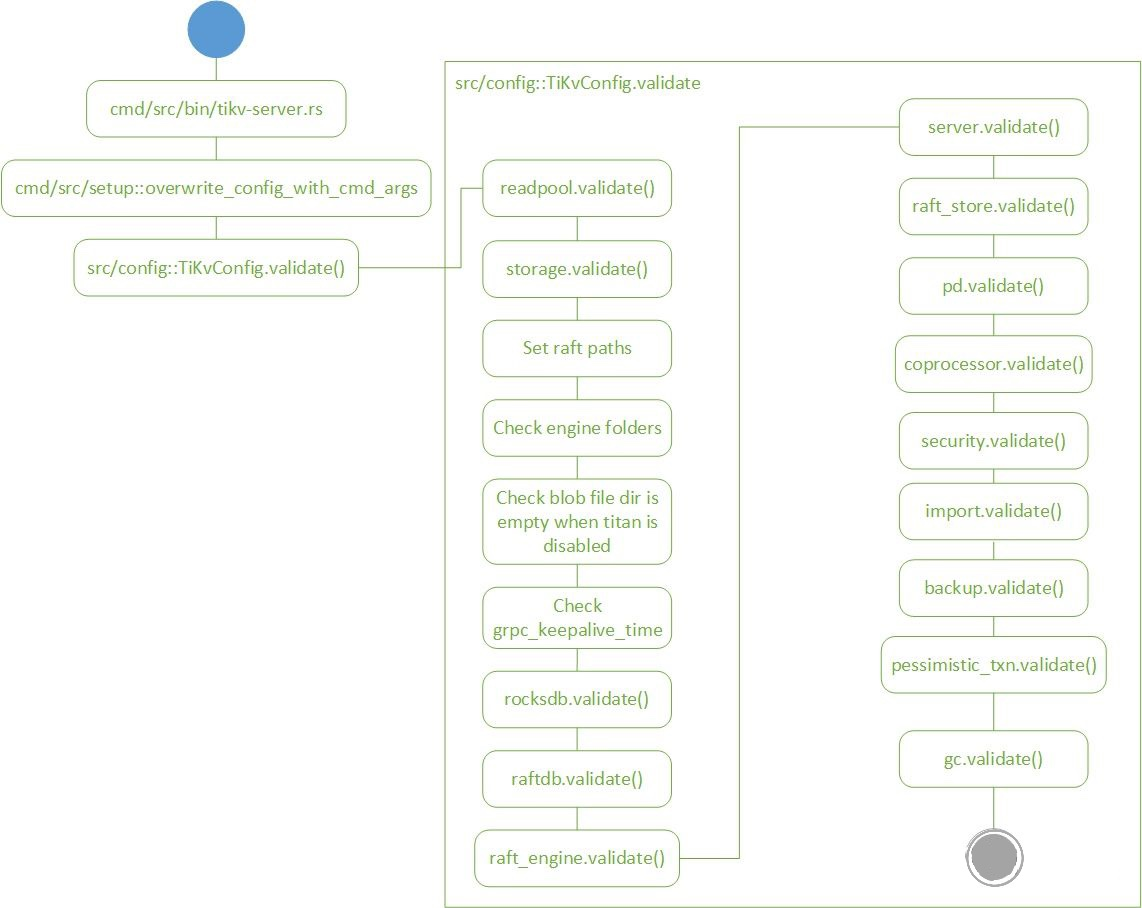
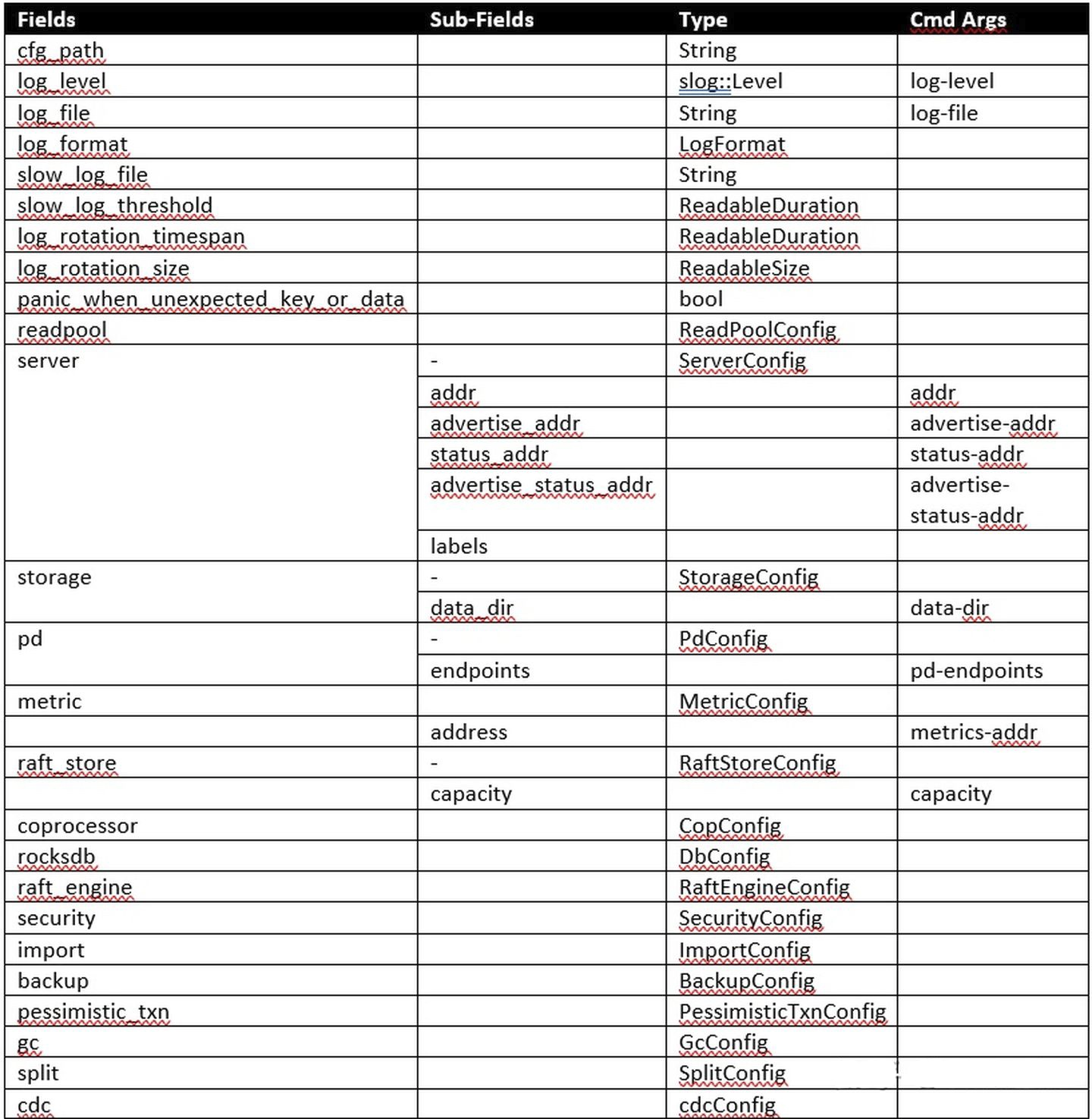
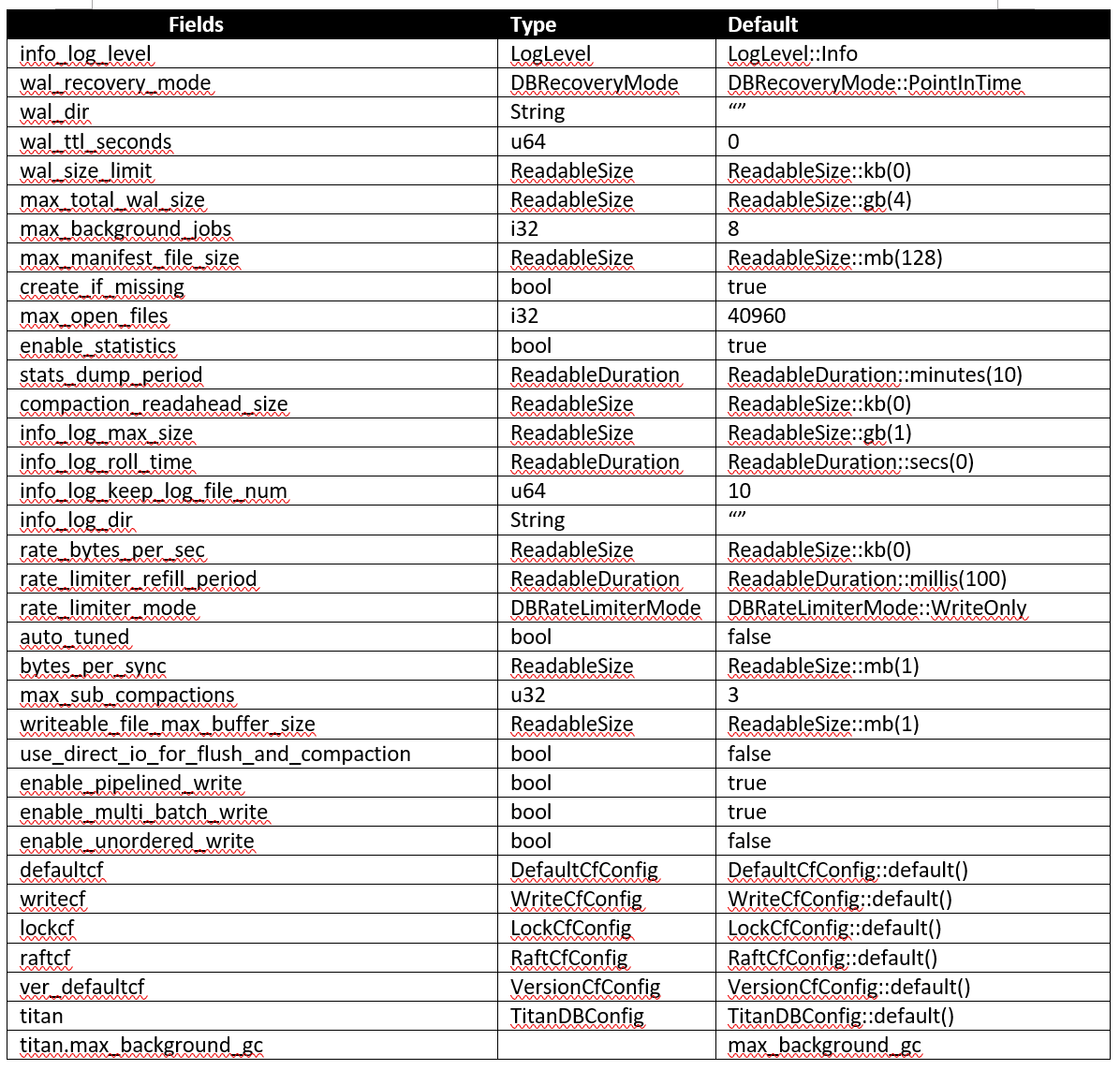
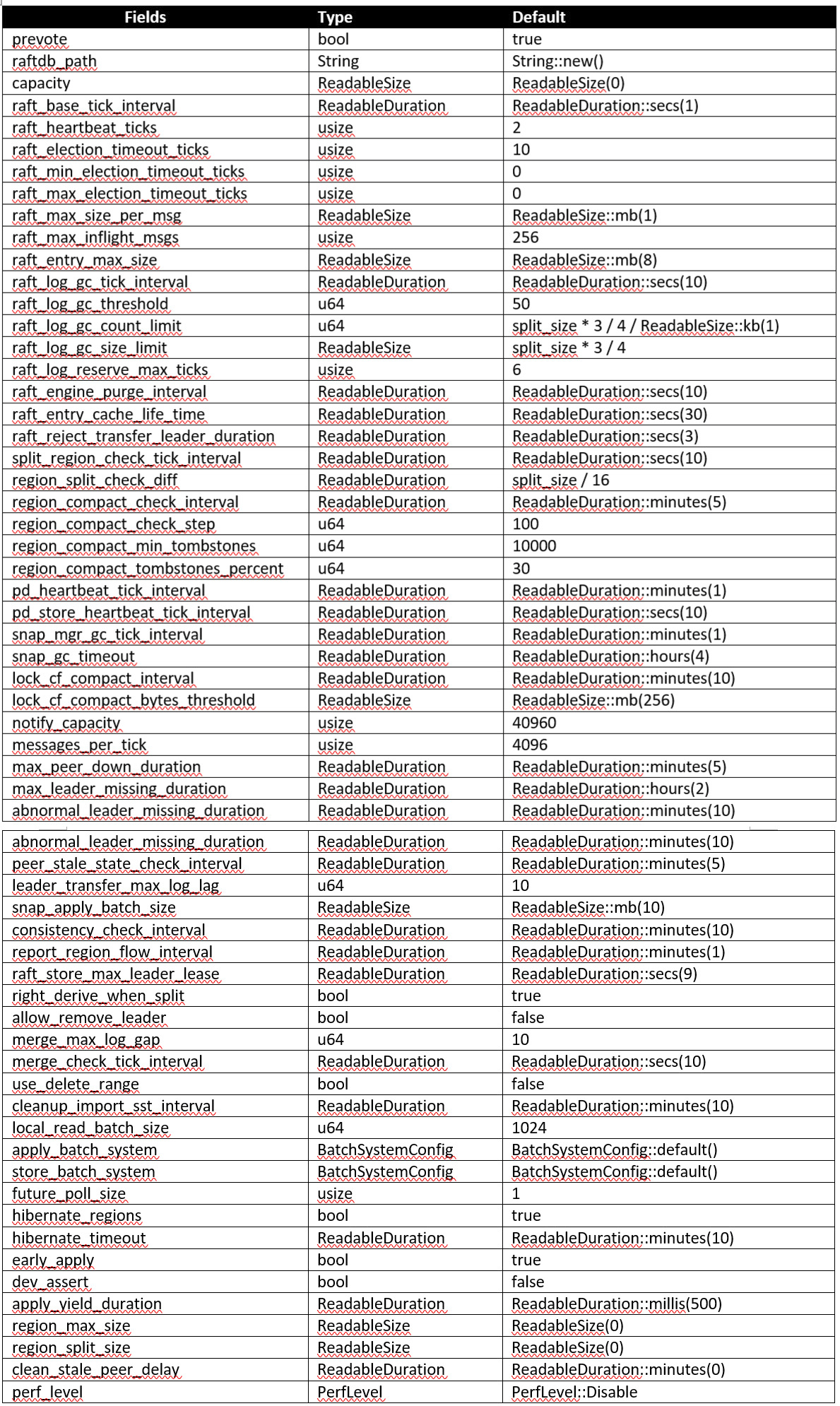
src/config.rs内以TiKvConfig struct为起始点,从外部读取配置信息后完成配置初始化工作,以下是TiKvConfig内部的字段。
所以我们下面按照代码顺序,依次介绍每个模块的作用和配置检查逻辑所做的事情,流程图内镂空的图例是每个流程图的起始点。
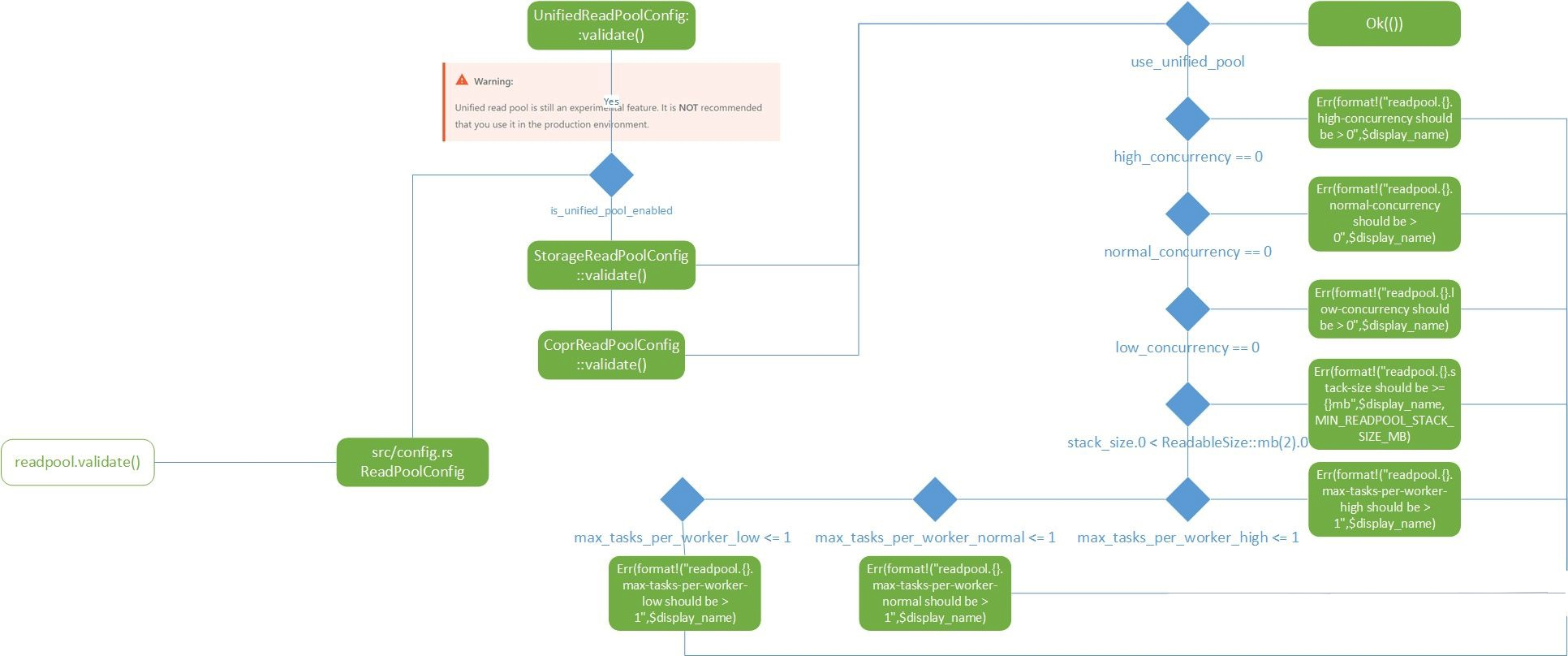
readpool
这是一个独立的用于数据读取的线程池,主要解决单一线程池导致的读写性能阻塞问题,具体的设计细节可以查看Read Pool RFC。
https://github.com/tikv/rfcs/blob/master/text/2017-12-22-read-pool.md
readpool内的unifed read pool还处于试验阶段,其他两个config都是通过readpool_config宏来定义的,所以他们的逻辑都是一样的,针对并发配置做了检查。
storage
从名字上就能看出这块代码主要负责存储相关的内容,打开项目代码,可以看出不光包含kv数据落盘的逻辑,还包括mvcc,txn一系列相关操作。validate部分比较简单,就是对数据存储的目录进行检查和校验,另外对4.0版本之后的优化配置也进行了检测。
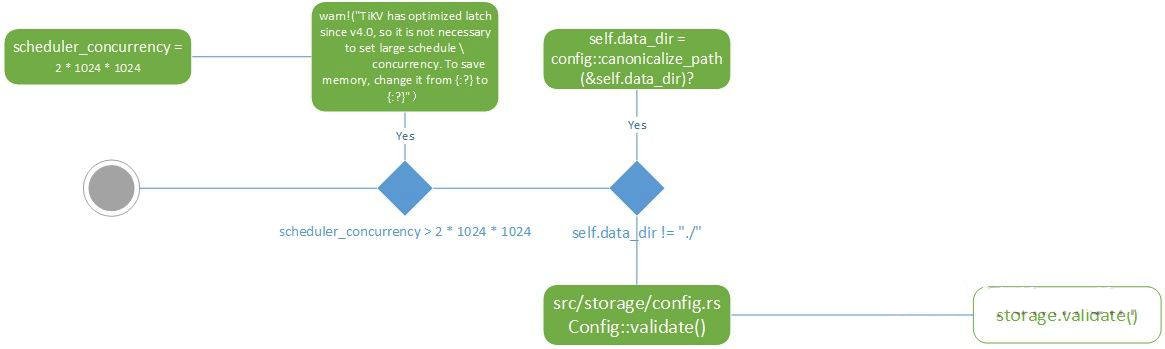
src/storage/config.rs, Config struct
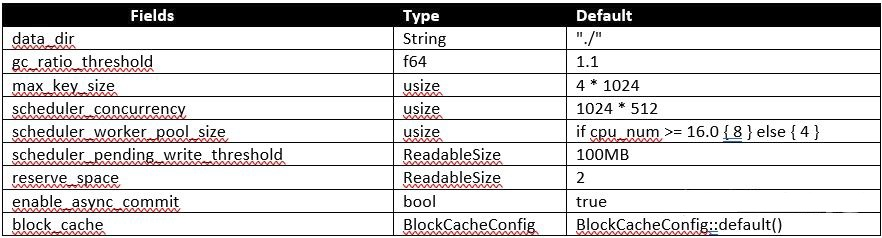
paths and grpc
这部分配置逻辑没有独立成一个validate方法,我们作为一个整体看一下主要做了哪几件事情:
- 设置region拆分检查的大小=6MB
- 配置config目录,当空时配置cfg_path为storage.data_dir,默认配置下为”./”
- 配置raftdb目录,当空时配置为storage.data_dir”/raft”,默认配置下为”./raft”
- 配置raft-engine目录,当空时配置为storage.data_dir”/raft-engine”,默认配置下为”./raft-engine”
- 配置rocksdb目录,默认配置为storage.dat_dir”/db”,也就是”./db”。但是这个路径不能和raftdb放在一起,所以会有一个检查,检查有问题会抛出”raft_store.raftdb_path can not same with storage.data_dir/db”的错误。之后会根据kv_db_path, raft_store.raftdb_path, raft_engine.config.dir对目录内的数据库文件进行检查,判断是否存在对应的数据库。
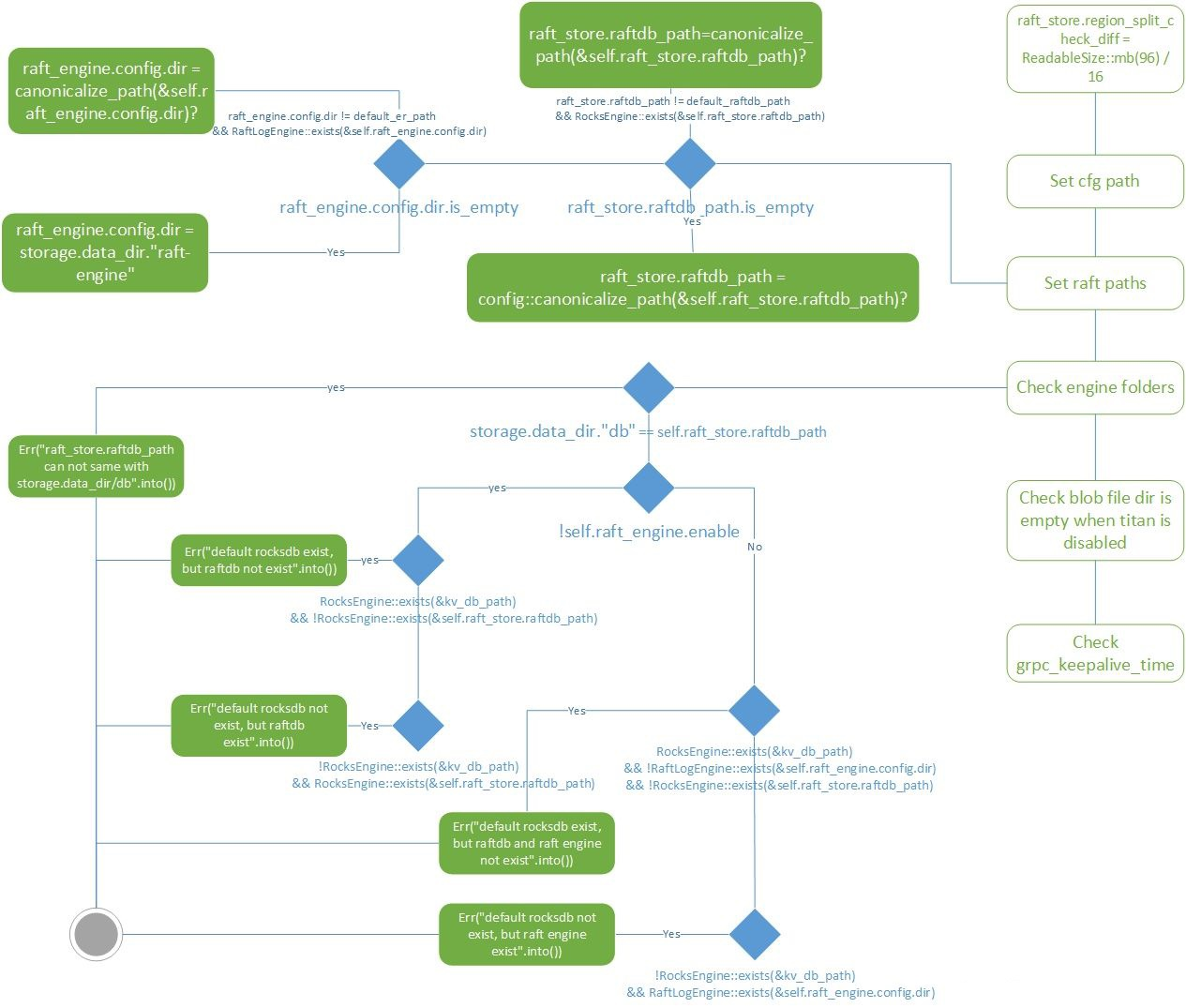
rocksdb
从变量名字上可以知道,这部分的代码逻辑是配置核心数据库的,也就是rocksdb的配置。我们可以看到这里主要是对cf做检测,cf的命名猜测应该是column family的简称,而主要检查内容就是块大小不能大于32MB。另外还有对titan和rocksdb的unordered_write配置检查。titan是pingcap开发的一个用来减少写放大问题的rocksdb插件,titan的理论基础来自于WiscKey。而unorder_write是一个提高rocksdb写性能的配置。这里有几篇文章可以扩展阅读一下。
https://tikv.org/docs/3.0/tasks/configure/titan/
https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
HIgher write throughput with `unordered_write` feature
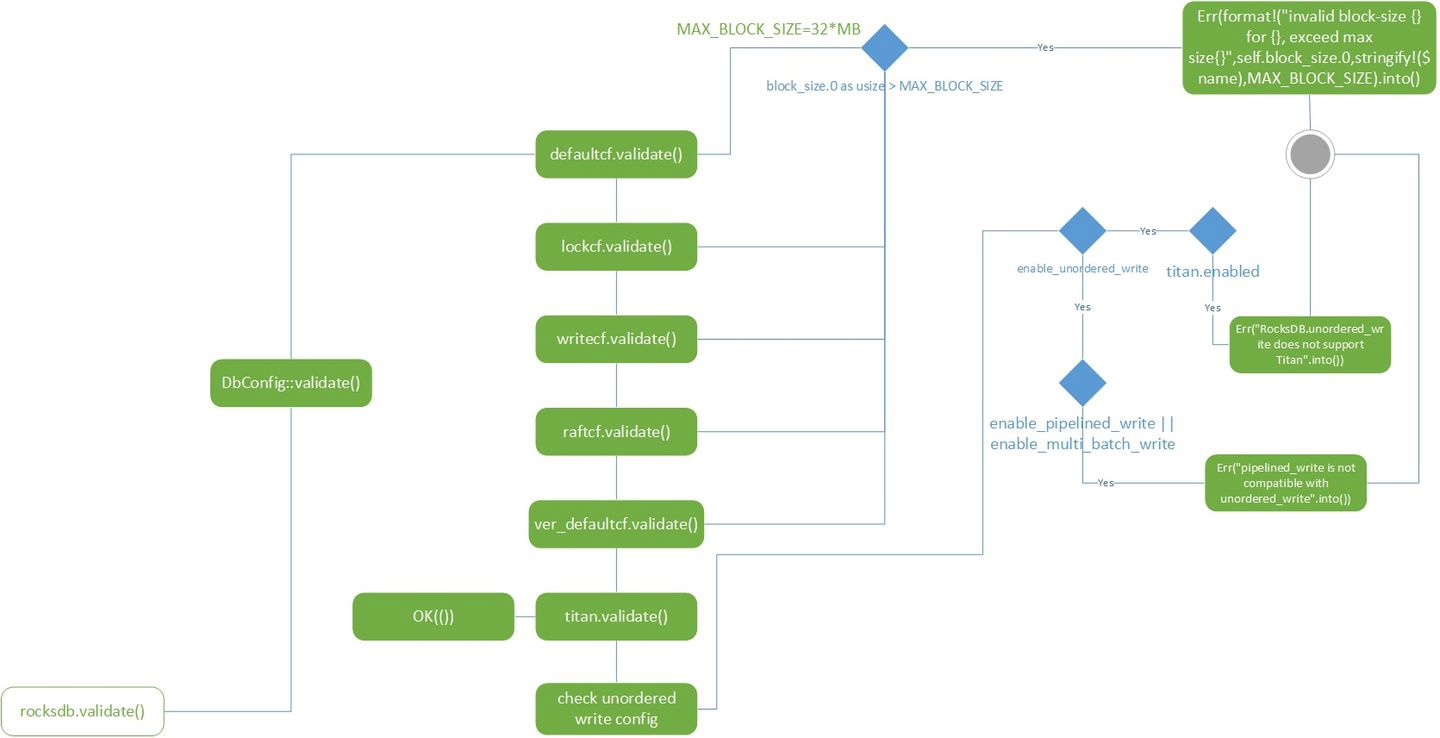
src/config.rs, DbConfig struct
raftdb
每一个TiKV都包含两个rocksdb实例,一个是用来存储真实数据的我们称之为kv rocksdb,就是我们上面介绍的rocksdb变量对应的配置;另一个用来存储raft log,我们称之为raft rocksdb,也就是这个raftdb变量对应的配置,用来存放multi-raft log的数据。可以参考下面的文章进行配置和调优工作。

src/config.rs, RaftDbConfig struct
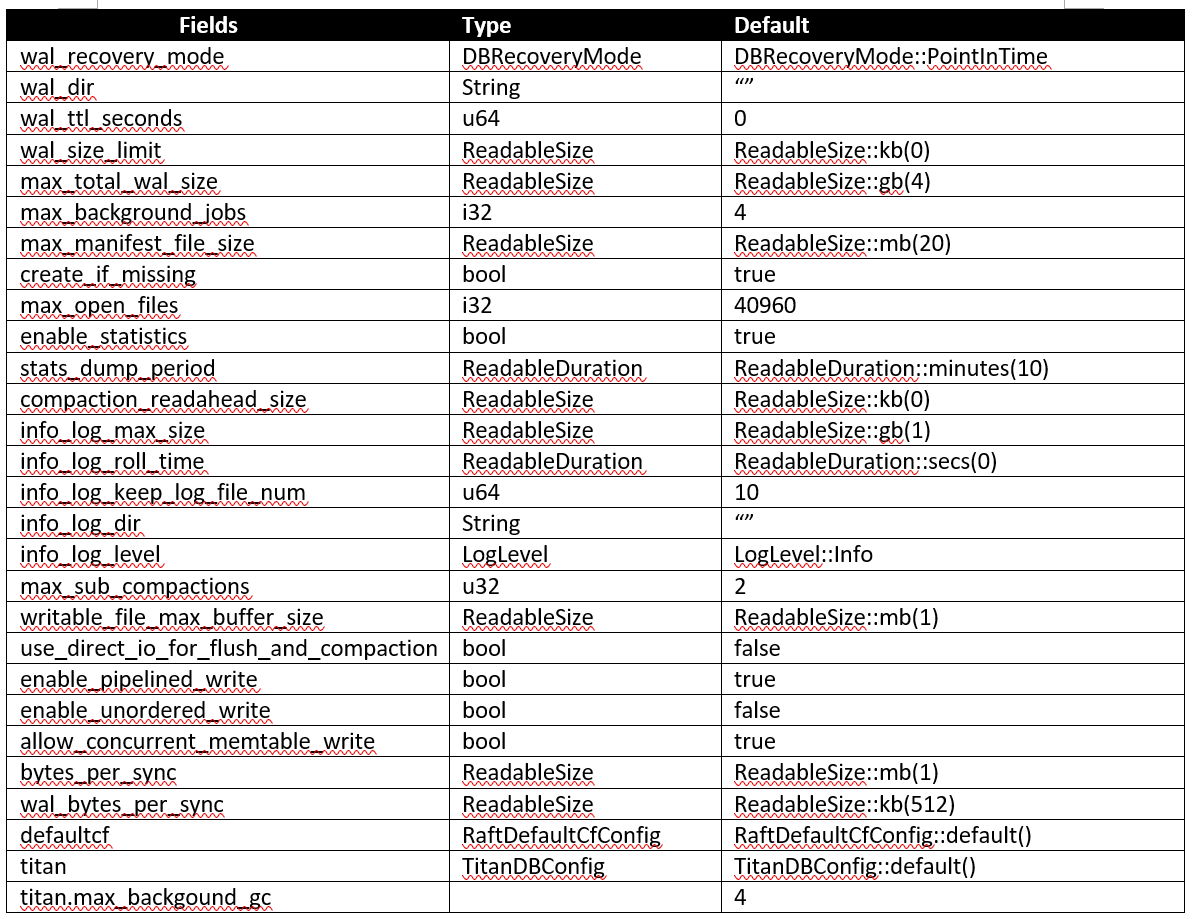
raft_engine
raft engine应用了另一个tikv的git库,所对应的validate逻辑也不复杂,就检验了purge阈值。但从raft engine的readme看,这是一个存放multi-raft log的数据引擎,用来解决raftdb出现的性能问题,最终会替换raftdb。从文中声称的性能测试结果来看,确实有非常大的提升。
https://github.com/tikv/raft-engine
关于multi-raft的设计和实现可以参考这篇文章。
TiKV 源码解析系列 – multi-raft 设计与实现

server
从流程图上也可以看出,服务器配置相对来说是所有配置里面算逻辑复杂的,但大体上分成几个部分:对ip地址/端口的检查,snapshot收发量检查,被调用的递归深度和时长的检查,grpc的配置检查。
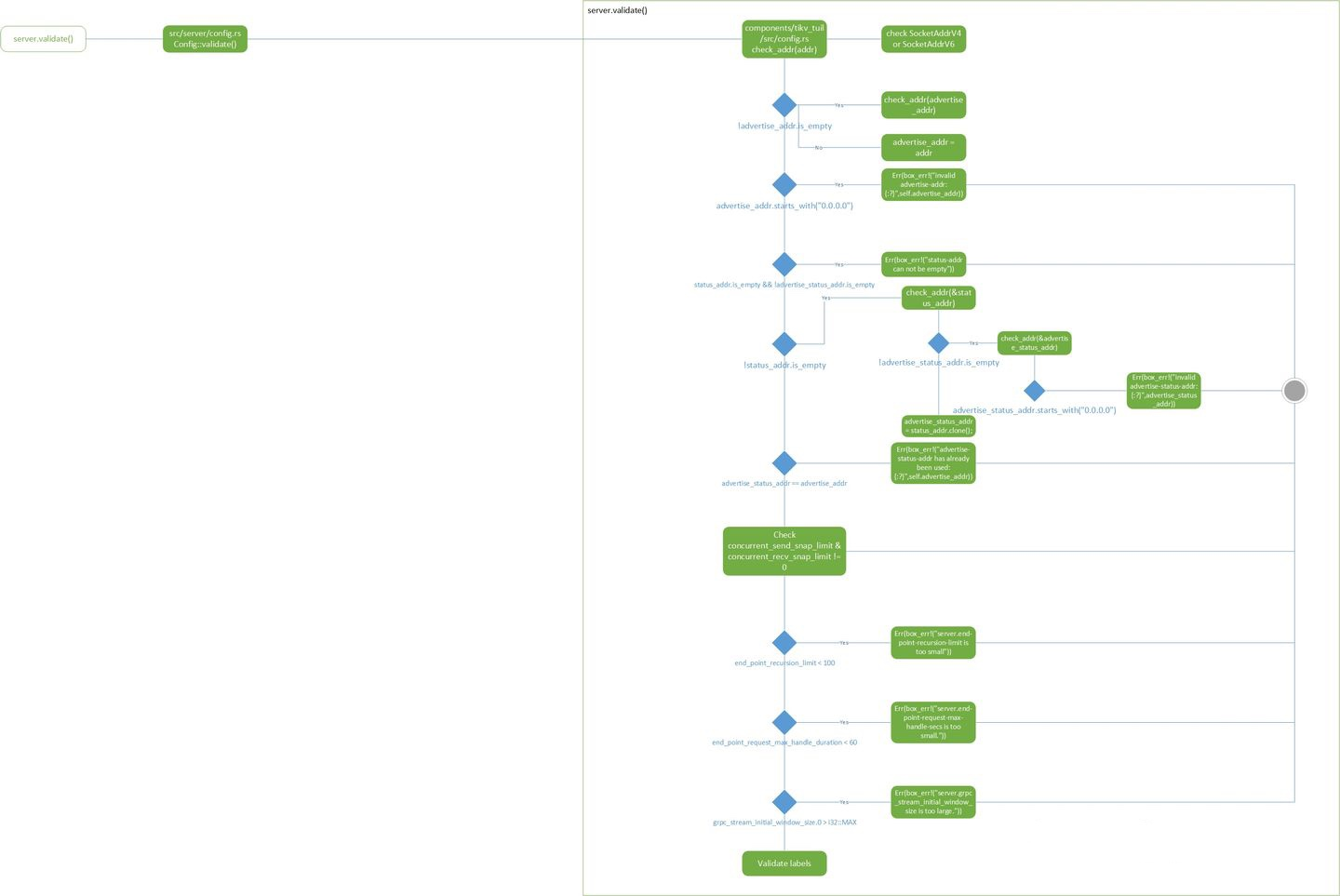
src/server/config.rs, Config struct
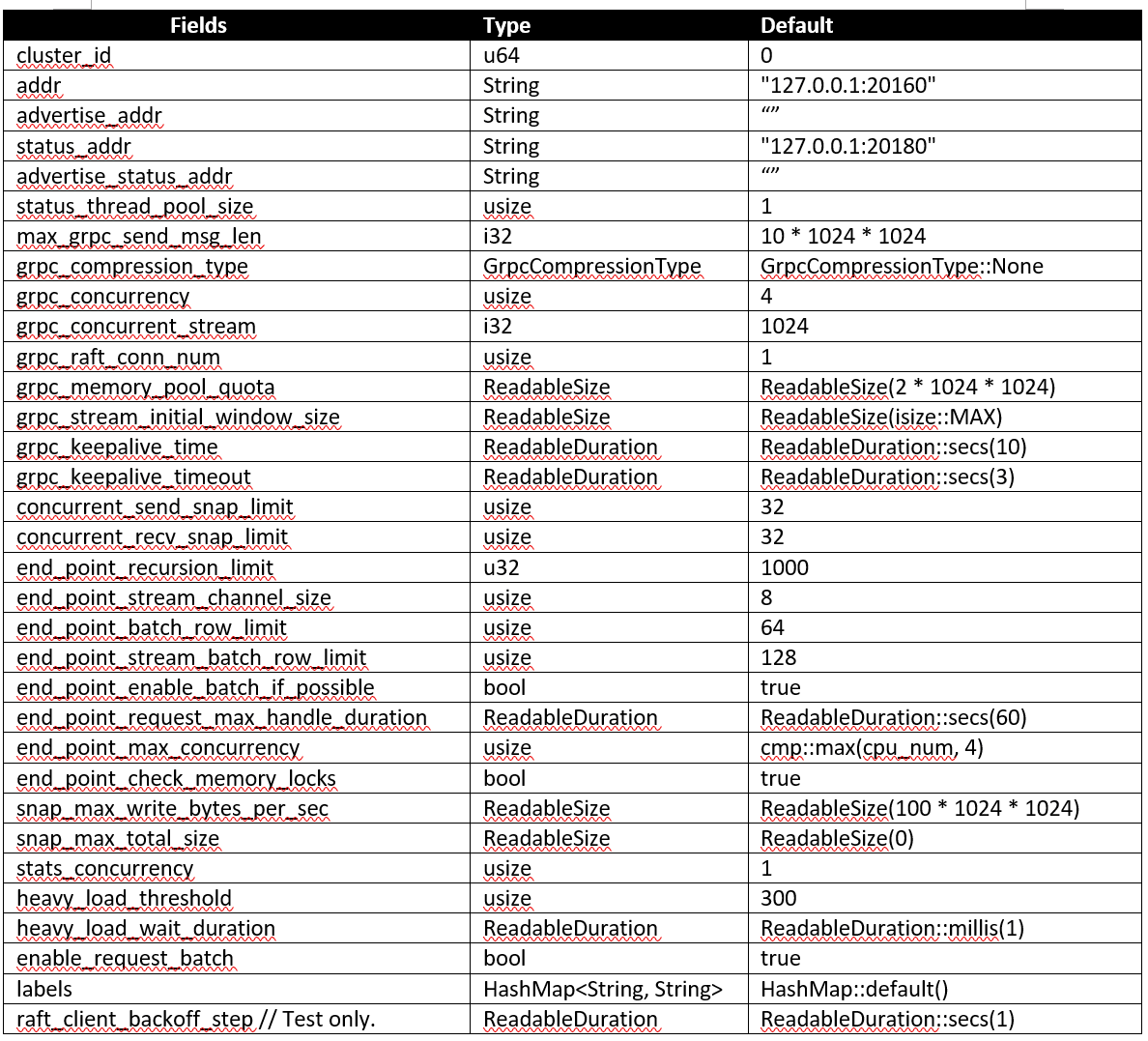
raft_store
这个是所有配置逻辑里面最复杂的部分了,不过主要还是围绕raft算法进行配置,包括:Leader选举(Leader election)、日志同步(Log replication)、安全性(Safety)、日志压缩(Log compaction)、成员变更(Membership change)等。到此我们其实看到有三处地方与raft配置有关系的代码,设置raft存储目录,raftdb配置,raftstore配置,是不是可以把这些代码放在一起来维护?
以下是对于raft store逻辑的扩展阅读:
关于raft算法这里就不详细讲解了,需要深入了解的同学可以参考这篇知乎。
当然pingcap在raft paper的基础上做了很多优化措施,具体细节可以参考这篇文章。
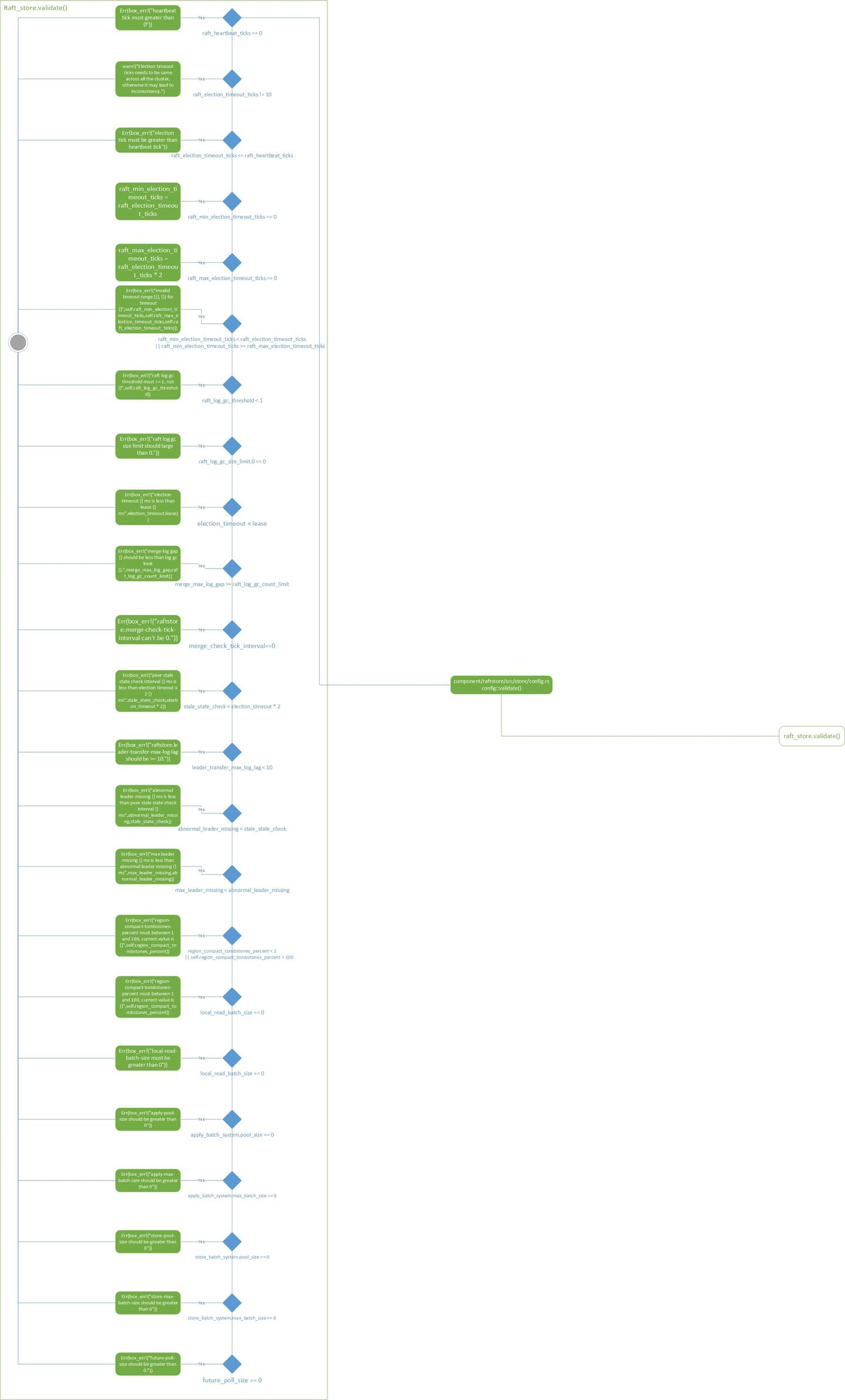
component/raftstore/src/store/config.rs, Config struct
let split_size = ReadableSize::mb(coprocessor::config::SPLIT_SIZE_MB) // SPLIT_SIZE_MB=96
pd
pd是placement driver的缩写,用来管理整个tikv集群,是整个集群的中央控制器,负责整个集群的调度工作。tikv内是pd client的逻辑,所以对配置的检查逻辑相对比较简单。
相关的介绍可以先看看这篇文章,后续的文章也会从代码级别来分析pd。
TiKV 源码解析系列 – multi-raft 设计与实现
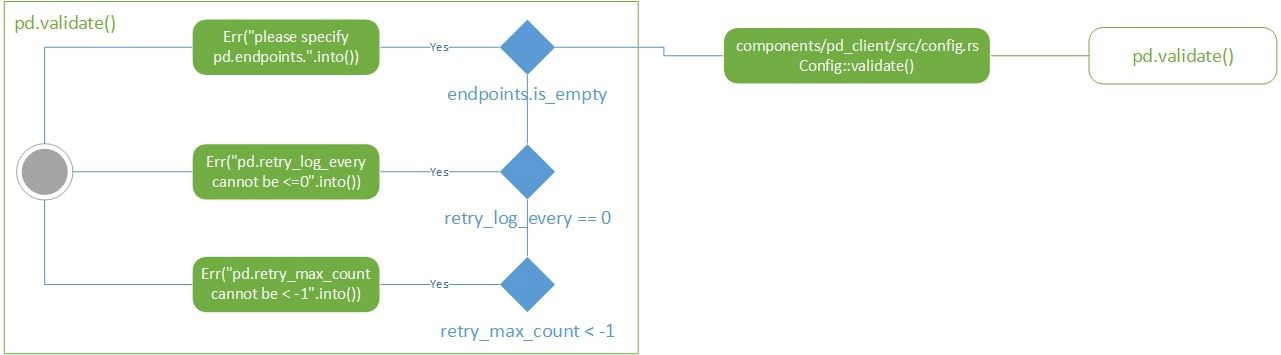
component/pd_client/src/config.rs, Config struct

coprocessor
类似于Hbase,tikv提供了一个协处理器框架来支持分布式计算。主要的功能是,每个节点在接收到分布式请求处理之后把自己负责的数据先做一次处理。这里不仅能提高整体运算效率,还能有效减少网络开销。需要具体了解coprocessor,可以参考这篇文章。
TiKV 源码解析系列文章(十四)Coprocessor 概览
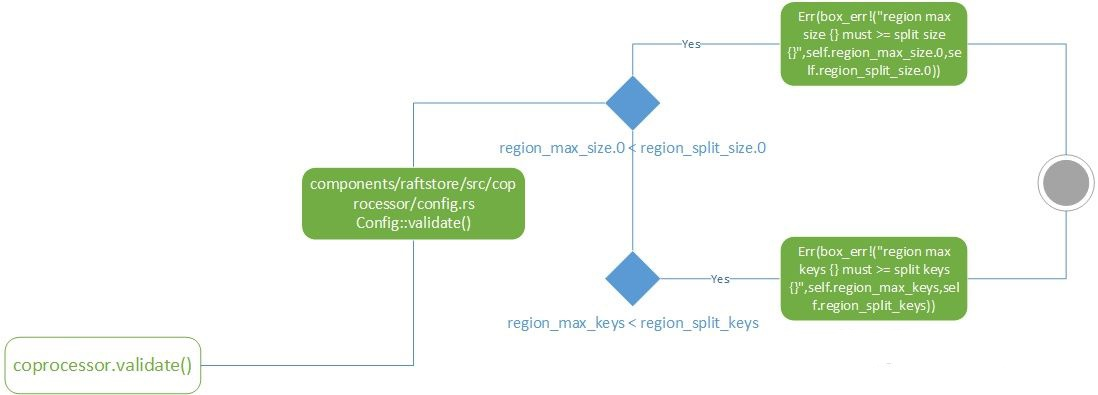
components/raftstore/src/coprocessor/config.rs, Config struct
let split_size = ReadableSize::mb(96);
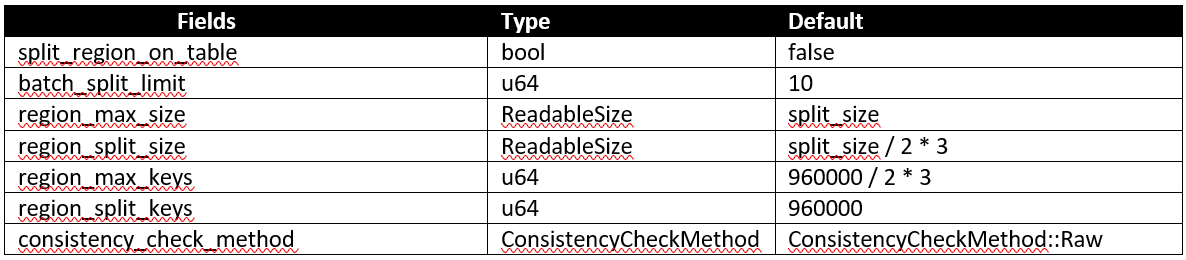
security
security一看就知道是负责安全相关的逻辑,validate代码里主要检查了证书,密钥等一系列配置。security的config struct和其他模块不太一样,居然放在lib.rs里面,是不是可以考虑移出来,跟其他模块保持一致呢?
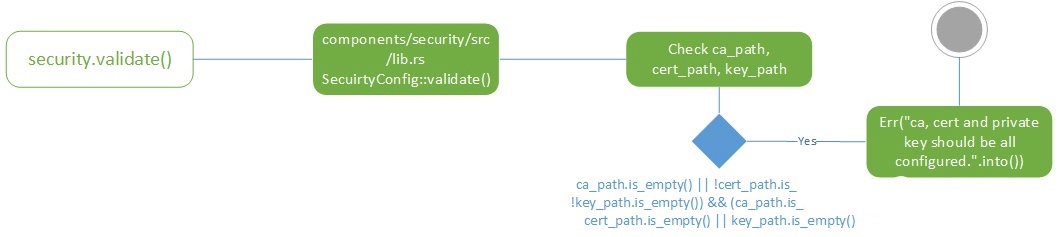
components/security/src/lib.rs, SecurityConfig struct
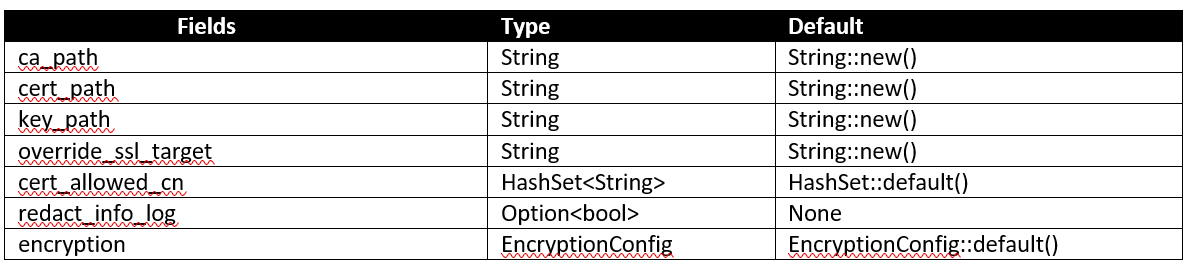 import
import
这里的import老实说没有能从代码引用关系找到对应代码文件,当然在浏览全项目文件之后找到了一个有近似逻辑的文件,所以这部分之后还需要跟tikv团队确认一下。
import的主要功能是磁盘加载rocksdb的文件,在代码中会看到sst这样的缩写,sst其实是rocksdb生成的文件格式名称,但由于不同的应用场景,这种文件格式其实有好几种结构:block-based table, plain table, cuckoo table和index block。
block-based table是sst文件的默认格式结构,这种格式下默认block大小为4kb,所有存储在文件内的key都是被排序过的,所以利用二叉搜索算法能够快速搜索到对应的键值。具体block-based table详解和其他格式结构可以参考一下文章:
| SST File Formats | Links |
|---|---|
| Rocksdb BlockBasedTable Format | https://github.com/facebook/rocksdb/wiki/Rocksdb-BlockBasedTable-Format |
| PlainTable Format | https://github.com/facebook/rocksdb/wiki/PlainTable-Format |
| CuckooTable Format | https://github.com/facebook/rocksdb/wiki/CuckooTable-Format |
| Index Block Format | https://github.com/facebook/rocksdb/wiki/Index-Block-Format |
validate检查的内容也很简单,就是threads和window两个变量。
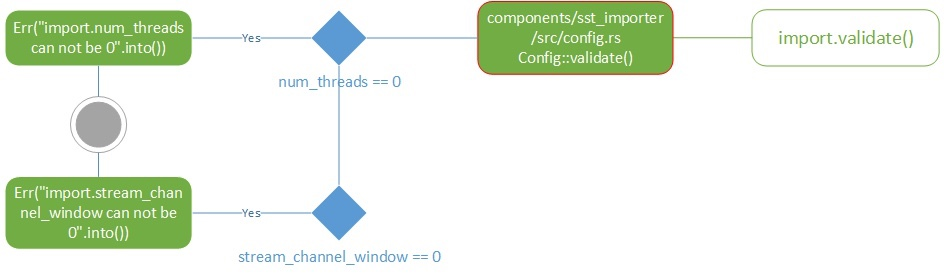
components/sst_importer/src/config.rs, Config struct

backup
这部应该是关于数据备份相关的配置代码,里面其实就一个字段num_threads,默认最多75%cpu来做备份的工作。

pessimistic_txn
从名字上看,这是一个悲观锁事务的配置验证。悲观锁和乐观锁的概念是大学数据库课程的基本概念,这里可以看一下tikv的解释说明,这篇文章也指出tikv主要使用乐观锁,所以这里的配置检查只是保证在使用悲观锁时的锁定时长不能等于0毫秒。
https://tikv.org/deep-dive/distributed-transaction/locking/

src/server/lock_manager/config.rs, Config struct

gc
这部分代码应该是检查垃圾回收配置的逻辑,关于垃圾回收的官方文档目前只有在2.1版本里能找到,不过在用户文档里有相关的内容。
垃圾回收(GC)- GC机制简介 – 《TiDB v4.0用户文档》- 书栈网 BookStack
gc的任务也比较清楚,就是清理不再需要的旧数据。这里检查的batch_keys会在src/server/gc_worker/gc_worker.rs内被用来设定批量扫描的范围,所以这个值肯定不能等于0。
// Scans at most `GcConfig.batch_keys` keys. let (keys, updated_next_key) = reader.scan_keys(next_key, self.cfg.batch_keys)?;

src/server/gc_worker/config.rs, GcConfig struct

封面上都是我们的团队成员,上个月刚刚在集团内部获得技术创新大奖,恭喜他们~~!
最后贴上完整的config流程图,图有点大,只能看个大概 !-P

传送门
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190340.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
