大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
层次分析法
层次分析法(analytic hierarchy process),简称AHP。是建模比赛中比较基础的模型之一,其主要解决评价类的问题。如选择哪种方案最好,哪位员工表现最好等。
它是一个较为 主观 的评价方法,其在赋权得到权重向量的时候,主观因素占比很大。因而在建模比赛中,常常与客观方法得到的权重向量方法进行综合,而得出一个综合的权重向量,进行后续操作。
本文借鉴了数学建模清风老师的课件与思路,如果大家发现文章中有不正确的地方,欢迎大家在评论区留言,也可以点击查看右侧链接查看清风老师视频讲解:清风数学建模:https://www.bilibili.com/video/BV1DW411s7wi
一、建模步骤
层次分析法进行建模,大致分为以下四步:
- 分析系统中各因素之间的关系,建立系统的递阶层次结构。
- 对于同一层次的个元素关于上一层次中某一准则的重要性两两比较,构造两两比较矩阵(判断矩阵)。
- 由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验通过权重才能用)。
- 填充权重矩阵,根据矩阵计算得分,得出结果。
接下来,我们根据例题讲解,并在相应出进行解释。
二、模型实现
例:小明同学想出去旅游。在查阅了网上的攻略后,他初步选择了苏杭、北戴河和桂林三地之一作为目标景点。请你确定评价指标、形成评价体系来为小明同学选择最佳的方案。
1. 分析系统中各因素之间的关系,建立系统的递阶层次结构。
首先,需要明确以下三个问题:
- 我们评价的 目标 是什么? 答:为小明同学选择最佳的旅游景点。
- 评价的 准则 或者说指标是什么?(我们根据什么东西来评价好坏) 答:景色、花费、居住、饮食、交通。
- 我们为了达到这个目标有哪几种可选的 方案 ? 答:三种,分别是去苏杭、去北戴河和去桂林。
根据以上问题,建立层次结构图,旅游地选择层次结构图如下:
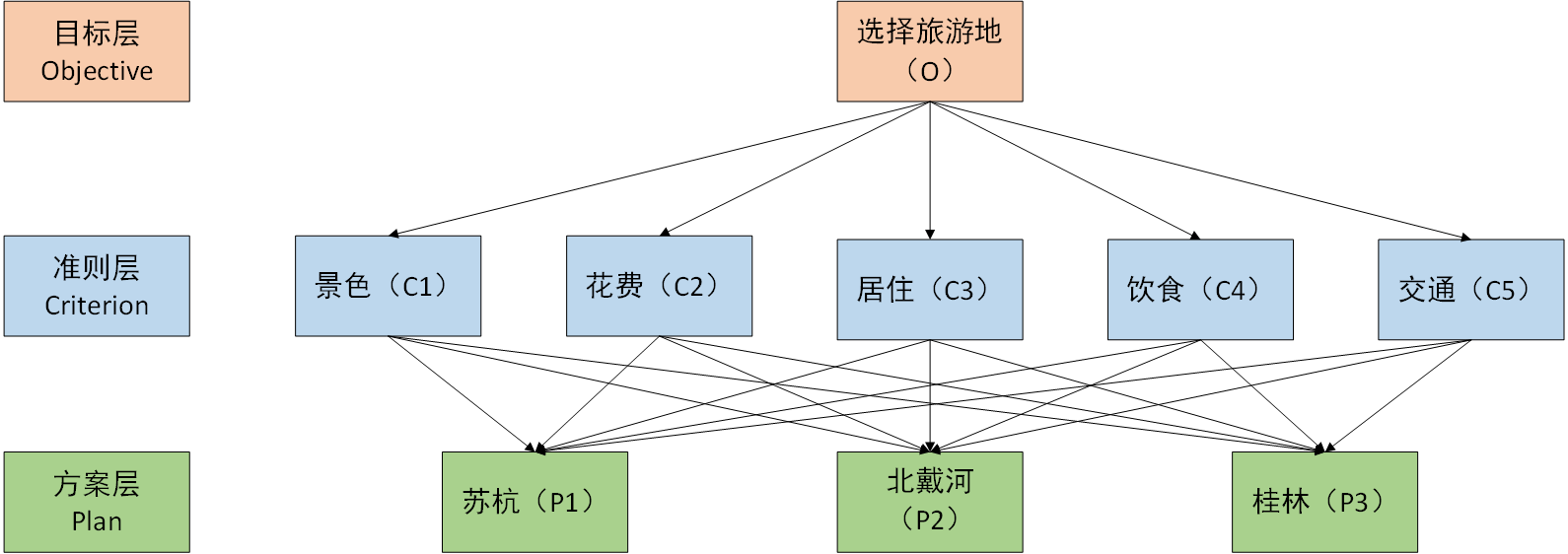

2. 对于同一层次的个元素关于上一层次中某一准则的重要性两两比较,构造两两比较矩阵(判断矩阵)。
那么如何构造这个判断矩阵呢?需要构造几个呢?有什么意义呢?接下来我们一一回答。
首先,我们先来看看层次分析法最终要得出的结果是什么样子的:
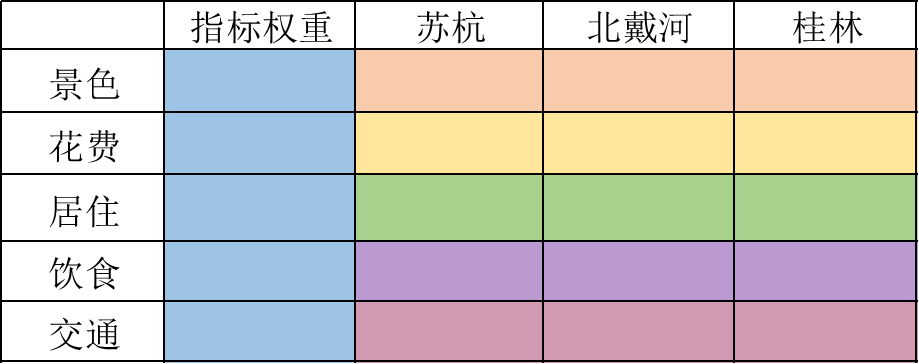
实际上的建模结果就是要填满权重矩阵,即这个表格:
- 其中,蓝色一列代表景色、花费、居住、饮食以及交通的权重,加和为1。(实际上就是准则层关于上一层目标层的重要性)
- 然后同一颜色每一横行,就是三种方案相对于准则层的重要性。如:橙色一行 代表的就是苏杭、北戴河以及桂林关于景色的权重,以此类推。
如何填满这个表格,就需要用判断矩阵得出,这也是构造判断矩阵的意义!
然后,我们看一下如何构造这个判断矩阵,要构造几个?
由上文可知得到这个判断矩阵实际上要分别得出准则层关于目标层的一组权重向量,方案层关于准则层的五组权重向量,实际上我们就需要构造出一个准则层关于目标层的判断矩阵以及五个方案层关于准则层的矩阵,一共六个判断矩阵。(这里采用分治的思想)最终在经过权重计算每组得出一组权重向量,填到相应的表格中。构造的6个判断矩阵如下:
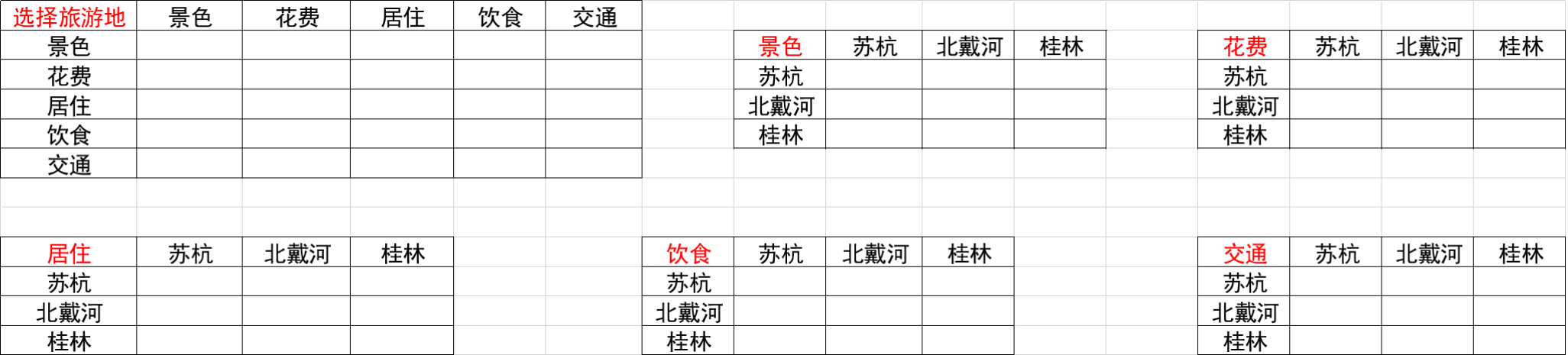
接下来,我们看一下,每个位置应该怎么填。
注意:这个位置不是随便填的,因为影响因子占比很大,有可能第一天我们看重景色,把景色权重写的占比大一些,第二天我们看重饮食了,就把饮食占比大一些,因而常常考虑不周全,而使得不易定量化。所以需要两两比较得出判断矩阵,而两两比较得出重要性填到矩阵中。重要程度如下表:
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有同样重要性 |
| 3 | 表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 | 表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 | 表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 | 表示两个因素相比,一个因素比另一个因素极端重要 |
| 2、4、6、8 | 上述两相邻判断的中值 |
| 倒数 | A和B相比如果标度为3,那么B和A相比就是1/3 |
根据以上这个表格,我们人为的进行填充,得到了下面这个判断矩阵:(实际情况下都是专家填的,但是比赛中大都是我们自己填的,最好有一些理论的依据支撑)
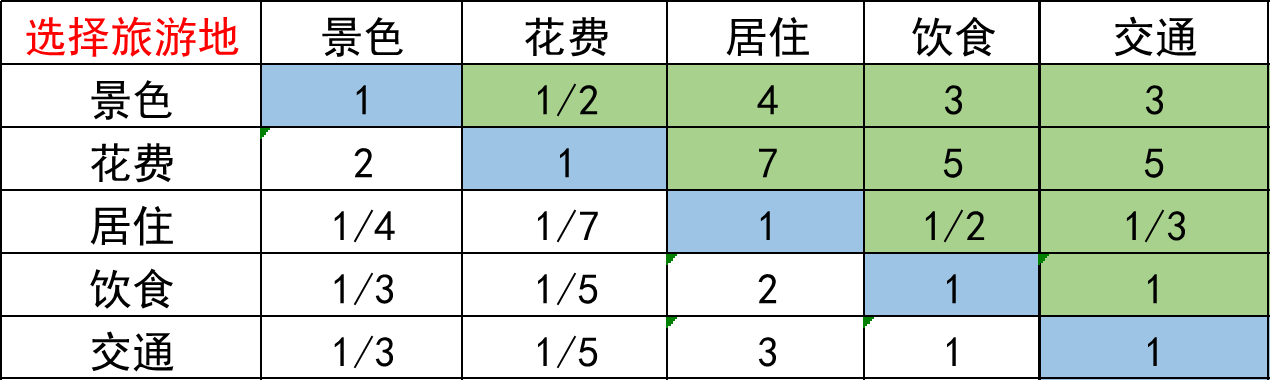
观察一下:上面这个判断矩阵有如下特点:
- aij 表示的意义是,与指标j相比, i的重要程度。
- 当i= j时,两个指标相同,因此同等重要记为1,这就解释了主对角线元素为1
- aj >0 且满足 aij × aji = 1 (我们称满足这一条件的矩阵为正互反矩阵)
其余五个矩阵如下图:


3. 由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验通过权重才能用)。
思考一个问题,拿方案层关于景色的矩阵说明,假设我们填写的判断矩阵是这个样子:
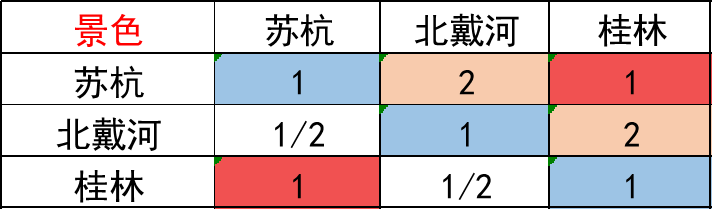
假设:苏杭 = A、北戴河 = B、桂林 = C,
那么由矩阵可以看出,苏杭比北戴河景色好一点 A > B,苏杭和桂林景色一样好 A = C,北戴河比桂林景色好一点 B > C,出现了 矛盾!
这里就不得不提出一个概念叫做 一致矩阵,它在正互反矩阵性质的基础上没有以上的矛盾,可以说:一致矩阵是正互反矩阵的特例。
将上面的矩阵进行改良,得到一致矩阵:
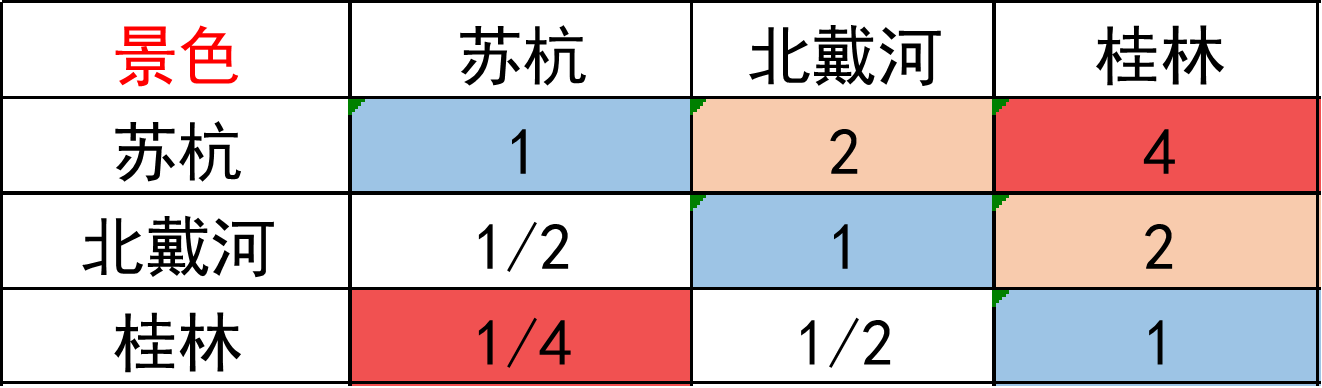
它比正互反矩阵多出两个性质:
- aij = i的重要程度 / j的重要程度,ajk = j的重要程度 / k的重要程度,aik = i的重要程度 / k的重要程度 = aij × ajk。
- 矩阵各行(各列)之间成倍数关系。
我们进行构造矩阵大多是正互反矩阵,难免会出现矛盾,即不容易构造出一致性矩阵,但是我们可以向一致性矩阵靠拢,只要这个差距(CR)不超过一个范围(0.1)那么这个判断矩阵也是可以使用的。这个判断差距的过程叫做 一致性检验。
接下来正式讲解一下一致性检验。
证明过程(只需要了解,可以直接看步骤):
一致性检验原理: 检验我们构造的判断矩阵和一致矩阵是否有太大的差别。
[ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] 为 一 致 矩 阵 的 充 要 条 件 : { a i j > 0 a 11 = a 22 = ⋯ = a n n = 1 [ a i 1 , a i 2 , ⋯ , a i n ] = k i [ a 11 , a 12 , ⋯ , a 1 n ] ( 注 : 也 可 以 定 义 为 列 与 列 ) \begin{bmatrix} a_{11} & a_{12} & \cdots &a_{1n} \\ a_{21}& a_{22} & \cdots &a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1}& a_{n2} & \cdots &a_{nn} \end{bmatrix} 为一致矩阵的充要条件:\begin{cases} & \text a_{ij}>0 \\ & \text a_{11}=a_{22}=\cdots=a_{nn}=1\\ &\text [a_{i1}, a_{i2},\cdots,a_{in} ] = k_i[a_{11}, a_{12},\cdots,a_{1n} ] \\& \text(注:也可以定义为列与列)\end{cases} ⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤为一致矩阵的充要条件:⎩⎪⎪⎪⎨⎪⎪⎪⎧aij>0a11=a22=⋯=ann=1[ai1,ai2,⋯,ain]=ki[a11,a12,⋯,a1n](注:也可以定义为列与列)
引理: A 为 n 阶方阵,且 A 的秩 r(A) = 1,则 A 有一个特征值为 A 的迹 tr(A),其余特征值均为0。因为一致矩阵的各行成比例且不是零矩阵,所以一致矩阵的秩一定为1。
由引理可知: 一致矩阵有一个特征值为 n,其余特征值均为 0。
另外,我们很容易可以得到,特征值为 n 时,对应的特征向量刚好为:
k [ 1 a 11 , 1 a 12 , ⋯ , 1 a 1 n ] T ( k ≠ 0 ) k\left[ \frac {1} {a_{11}},\frac {1} {a_{12}},\cdots,\frac {1} {a_{1n}} \right] ^T(k≠0) k[a111,a121,⋯,a1n1]T(k=0)
此外,n 阶正互反矩阵 A 为一致矩阵时当且仅当最大特征值 λ m a x = n λ_{max} = n λmax=n,且当正互反矩阵 A 非一致时,一定满足 λ m a x > n λ_{max} > n λmax>n。总而言之,判断矩阵越不一致时,最大特征值与 n 相差就越大。
一致性检验的步骤:
第一步:计算一致性指标 CI
C I = λ m a x − n n − 1 CI=\frac{\lambda_{max}-n}{n-1} CI=n−1λmax−n
第二步:查找对应的平均随机一致性指标 RI

注:在实际运用中,n很少超过10,如果指标的个数大于10,则可考虑建立二级指标体系,或使用我们以后要学习的模糊综合评价模型。此外,RI 可以直接查表使用即可。
第三步:计算一致性比例CR
C R = C I R I CR=\frac{CI}{RI} CR=RICI
如果 CR < 0.1, 则可认为判断矩阵的一致性可以接受;否则需要对判断矩阵进行修正。
当然本道例题上面的6个矩阵已经通过了一致性检验,然后接下来要根据判断矩阵计算权重。
4. 填充权重矩阵,根据矩阵计算得分,得出结果。
计算权重的方法有三种:算数平均法求权重、几何平均法求权重以及特征值法求权重。
一般情况下:第三种特征值法求权重是最常用的,但是建议可以综合三种方法来求得一个综合的权重向量。
下面拿下面这个判断矩阵进行说明:
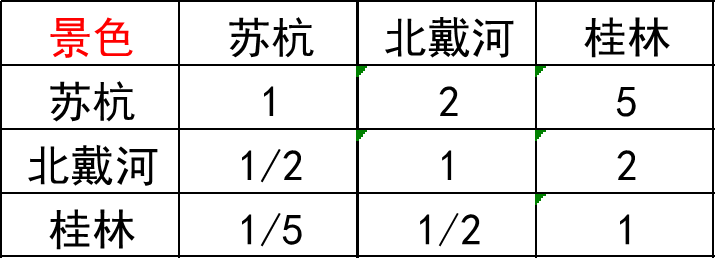
方法1:算术平均法求权重
第一步: 将判断矩阵按照列归一化(每个元素除以其所在列的和,如1/(1+0.5+0.2)=0.5882)
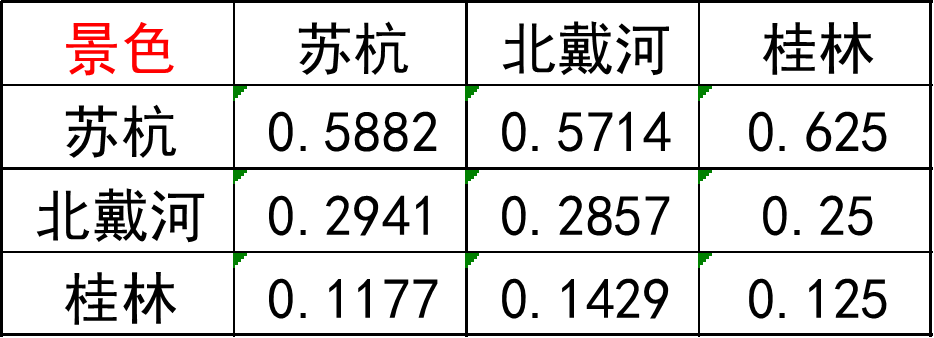
第二步: 将归一化的列相加(按行求和)
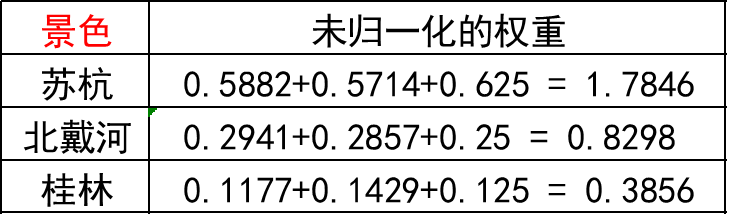
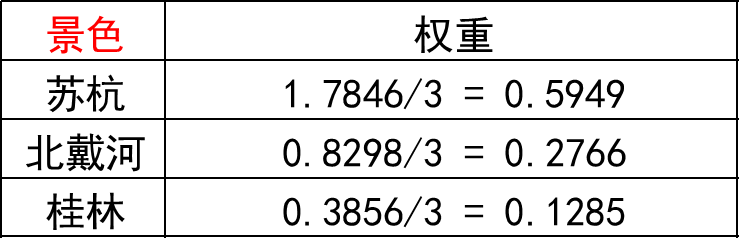
第三步: 将相加后得到的向量中的每个元素除以 n 即可得到权重向量
以表达式进行解释:
假 设 判 断 矩 阵 A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] 假设判断矩阵 A= \begin{bmatrix} a_{11} & a_{12} & \cdots &a_{1n} \\ a_{21}& a_{22} & \cdots &a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1}& a_{n2} & \cdots &a_{nn} \end{bmatrix} 假设判断矩阵A=⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤
那 么 算 术 平 均 法 求 得 的 权 重 向 量 ω i = 1 n ∑ j = 1 n a i j ∑ k = 1 n a k j , ( i = 1 , 2 , ⋯ , n ) 那么算术平均法求得的权重向量\text { }\omega_i=\frac{1}{n}\sum_{j=1}^{n} {\frac{a_{ij}}{\displaystyle \sum_{k=1}^{n} a_{kj}}},\text { }(i=1,2,\cdots,n) 那么算术平均法求得的权重向量 ωi=n1j=1∑nk=1∑nakjaij, (i=1,2,⋯,n)
方法2:几何平均法求权重
第一步: 将A的元素按照行相乘得到一个新的列向量
第二步: 将新的向量的每个分量开n次方
第三步: 对该列向量进行归一化即可得到权重向量
以表达式进行解释:
假 设 判 断 矩 阵 A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] 假设判断矩阵 A= \begin{bmatrix} a_{11} & a_{12} & \cdots &a_{1n} \\ a_{21}& a_{22} & \cdots &a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1}& a_{n2} & \cdots &a_{nn} \end{bmatrix} 假设判断矩阵A=⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤
那 么 几 何 平 均 法 求 得 的 权 重 向 量 ω i = ( ∏ j = 1 n a i j ) 1 n ∑ k = 1 n ( ∏ j = 1 n a k j ) 1 n , ( i = 1 , 2 , ⋯ , n ) 那么几何平均法求得的权重向量\text { }\omega_i=\frac{ (\displaystyle\prod_{j=1}^n a_{ij})^\frac{1}{n}}{\displaystyle\sum_{k=1}^n(\displaystyle\prod_{j=1}^n a_{kj})^\frac{1}{n}},\text { }(i=1,2,\cdots,n) 那么几何平均法求得的权重向量 ωi=k=1∑n(j=1∏nakj)n1(j=1∏naij)n1, (i=1,2,⋯,n)
求得权重结果如图:
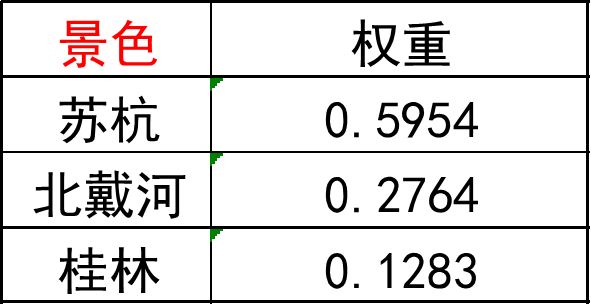
方法3:特征值法求权重
上文在证明一致性检验的时候,提到过如下内容:
由引理可知: 一致矩阵有一个特征值为 n,其余特征值均为 0。
另外,我们很容易可以得到,特征值为 n 时,对应的特征向量刚好为:
k [ 1 a 11 , 1 a 12 , ⋯ , 1 a 1 n ] T ( k ≠ 0 ) k\left[ \frac {1} {a_{11}},\frac {1} {a_{12}},\cdots,\frac {1} {a_{1n}} \right] ^T(k≠0) k[a111,a121,⋯,a1n1]T(k=0)
那么我们我们直接可以将特征向量归一化即可求得特征向量。
求的结果为:
最大特征值为 3.0055,
一致性比例 CR = 0.0053 对应的 特征向量:[-0.8902,-0.4132,-0.1918]
归一化后得到权重向量 : [0.5954,0.2764,0.1283]
我们将三种方法求得的权重向量如下图所示:
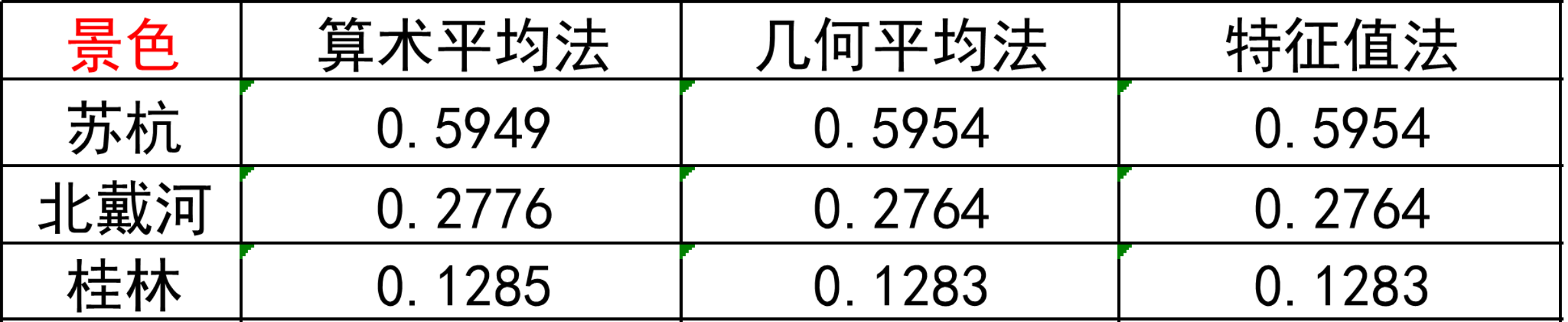
但在实际建模中建议综合三种方法求得的权重得到一个综合的权重向量更具有说服力!
填充权重矩阵
这里只拿第三种的结果填充权重矩阵
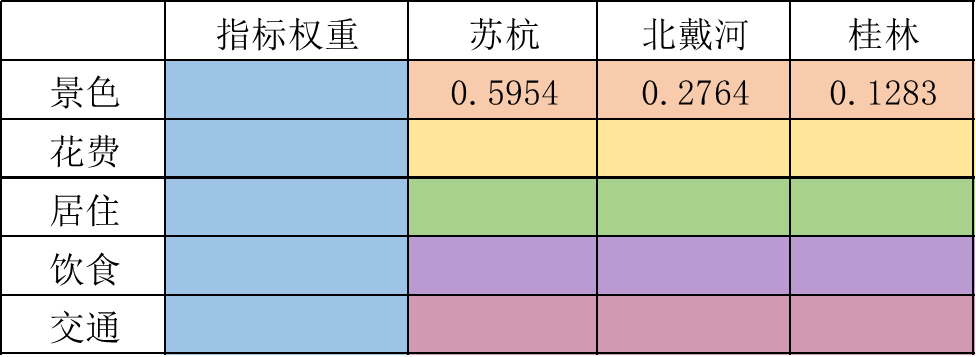
其余的矩阵以此类推,最终得到如下图所示的权重矩阵:
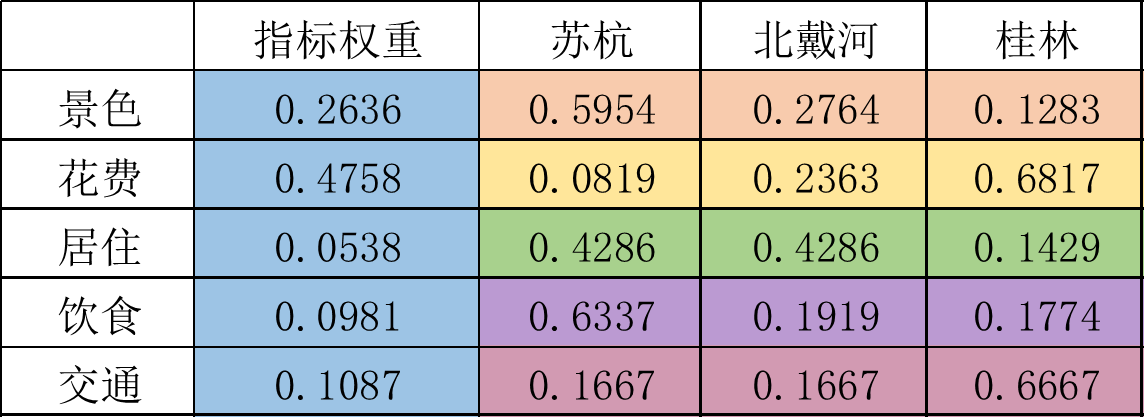
计算得分,得出最终结果
苏杭得分:指标权重×苏杭与其他两种方案中的权重,即前两列相乘:
0.5954×0.2636+0.0819×0.4758+0.4286×0.0538+0.6337×0.0981+0.1667×0.1087=0.299
同理:北戴河得分为0.245,桂林得分为0.455。
因此最佳的旅游景点是桂林。
三、模型扩展(★)
- 评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异可能会很大。因为平均随机一致性指标 RI 的表格中 n 最多是15,因此应该根据实际情况选择是否应用此方法。
- 如果决策层中指标的数据是已知的,那么层次分析法不容易将这些已知数据应用在其中。如拿上面的例题举例:如果已知景色 、花费、居住、饮食以及交通在三个旅游景点的一些数据,那么如何将这些数据转化为构造判断矩阵的依据,只能为其提供一定的文字说明,而不容易将数据应用到其中。
- 在实际建模中,判断矩阵的数值都是人为填的,具有一定的主观性存在,这时应该搜寻相应的数据让人信服,不能空口无凭。
- 如果说只想拿到的决策因素的权重向量,那大可不必这么麻烦,在第一步递阶层次结构的时候,只需要目标层和准则层即可,构造判断矩阵也只需要构造出一个,并进行检验,检验通过了,差不多就拿到了权重向量。
四、模型总结
总结一下步骤:
- 分析系统中各因素之间的关系,建立系统的递阶层次结构。
- 对于同一层次的个元素关于上一层次中某一准则的重要性两两比较,构造两两比较矩阵(判断矩阵)。
- 由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验通过权重才能用)。
- 填充权重矩阵,根据矩阵计算得分,得出结果。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190319.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
