大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
TiKV 简介
TiKV 是一个分布式事务型的键值数据库,提供了满足 ACID 约束的分布式事务接口,并且通过 Raft 协议 保证了多副本数据一致性以及高可用。TiKV 作为 TiDB 的存储层,为用户写入 TiDB 的数据提供了持久化以及读写服务,同时还存储了 TiDB 的统计信息数据。
整体架构
与传统的整节点备份方式不同,TiKV 参考 Spanner 设计了 multi raft-group 的副本机制。将数据按照 key 的范围划分成大致相等的切片(下文统称为 Region),每一个切片会有多个副本(通常是 3 个),其中一个副本是 leader,提供读写服务。TiKV 通过 PD 对这些 Region 以及副本进行调度,以保证数据和读写负载都均匀地分散在各个 TiKV 上,这样的设计保证了整个集群资源的充分利用并且可以随着机器数量的增加水平扩展。
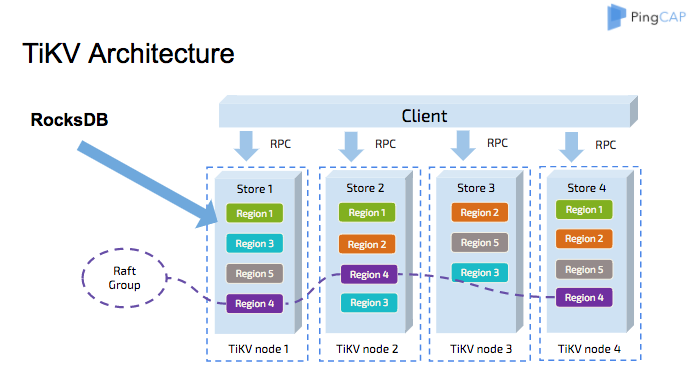

Region 与 RocksDB
虽然 TiKV 将数据按照范围切割成了多个 Region,但是同一个节点的所有 Region 数据仍然是不加区分地存储于同一个 RocksDB 实例上,而用于 Raft 协议复制所需要的日志则存储于另一个 RocksDB 实例。这样设计的原因是因为随机 I/O 的性能远低于顺序 I/O,所以 TiKV 使用同一个 RocksDB 实例来存储这些数据,以便不同 Region 的写入可以合并在一次 I/O 中。
Region 与 Raft 协议
Region 与副本之间通过 Raft 协议来维持数据一致性,任何写请求都只能在 leader 上写入,并且需要写入多数副本后(默认配置为 3 副本,即所有请求必须至少写入两个副本成功)才会返回客户端写入成功。
当某个 Region 的大小超过一定限制(默认是 144MB)后,TiKV 会将它分裂为两个或者更多个 Region,以保证各个 Region 的大小是大致接近的,这样更有利于 PD 进行调度决策。同样的,当某个 Region 因为大量的删除请求导致 Region 的大小变得更小时,TiKV 会将比较小的两个相邻 Region 合并为一个。
当 PD 需要把某个 Region 的一个副本从一个 TiKV 节点调度到另一个上面时,PD 会先为这个 Raft Group 在目标节点上增加一个 Learner 副本(虽然会复制 leader 的数据,但是不会计入写请求的多数副本中)。当这个 Learner 副本的进度大致追上 Leader 副本时,Leader 会将他变更为 Follower,之后再移除操作节点的 Follower 副本,这样就完成了 Region 副本的一次调度。
Leader 副本的调度原理也类似,不过需要在目标节点的 Learner 副本变为 Follower 副本后,再执行一次 Leader Transfer,让该 Follower 主动发起一次选举成为新 Leader,之后新 Leader 负责删除旧 Leader 这个副本。
分布式事务
TiKV 支持分布式事务,用户(或者 TiDB)可以一次性写入多个 key-value 而不必关心这些 key-value 是否处于同一个数据切片 (Region) 上,TiKV 通过两阶段提交保证了这些读写请求的 ACID 约束,详见 TiDB 乐观事务模型。
计算加速
TiKV 通过协处理器 (Coprocessor) 可以为 TiDB 分担一部分计算:TiDB 会将可以由存储层分担的计算下推。能否下推取决于 TiKV 是否可以支持相关下推。计算单元仍然是以 Region 为单位,即 TiKV 的一个 Coprocessor 计算请求中不会计算超过一个 Region 的数据。
RocksDB 简介
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(SkipList,这部分结构又被称作 MemTable)。LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件 (Sorted String Table),SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是上一层的 10 倍(因此 90% 的数据存储在最后一层)。
RocksDB 允许用户创建多个 ColumnFamily ,这些 ColumnFamily 各自拥有独立的内存跳表以及 SST 文件,但是共享同一个 WAL 文件,这样的好处是可以根据应用特点为不同的 ColumnFamily 选择不同的配置,但是又没有增加对 WAL 的写次数。
TiKV 架构
TiKV 的系统架构如下图所示:
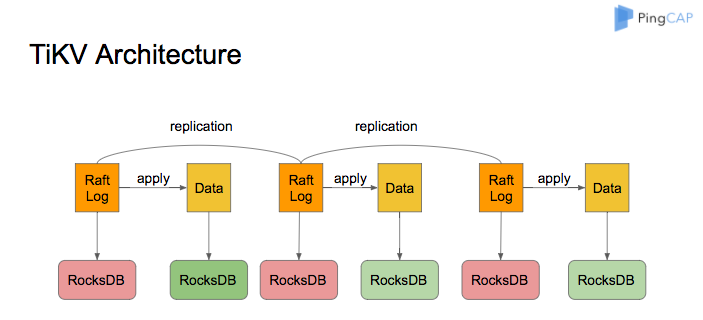
RocksDB 作为 TiKV 的核心存储引擎,用于存储 Raft 日志以及用户数据。每个 TiKV 实例中有两个 RocksDB 实例,一个用于存储 Raft 日志(通常被称为 raftdb),另一个用于存储用户数据以及 MVCC 信息(通常被称为 kvdb)。kvdb 中有四个 ColumnFamily:raft、lock、default 和 write:
-
raft 列:用于存储各个 Region 的元信息。仅占极少量空间,用户可以不必关注。
-
lock 列:用于存储悲观事务的悲观锁以及分布式事务的一阶段 Prewrite 锁。当用户的事务提交之后, lock cf 中对应的数据会很快删除掉,因此大部分情况下 lock cf 中的数据也很少(少于 1GB)。如果 lock cf 中的数据大量增加,说明有大量事务等待提交,系统出现了 bug 或者故障。
-
write 列:用于存储用户真实的写入数据以及 MVCC 信息(该数据所属事务的开始时间以及提交时间)。当用户写入了一行数据时,如果该行数据长度小于 255 字节,那么会被存储 write 列中,否则的话该行数据会被存入到 default 列中。由于 TiDB 的非 unique 索引存储的 value 为空,unique 索引存储的 value 为主键索引,因此二级索引只会占用 writecf 的空间。
-
default 列:用于存储超过 255 字节长度的数据。
RocksDB 的内存占用
为了提高读取性能以及减少对磁盘的读取,RocksDB 将存储在磁盘上的文件都按照一定大小切分成 block(默认是 64KB),读取 block 时先去内存中的 BlockCache 中查看该块数据是否存在,存在的话则可以直接从内存中读取而不必访问磁盘。
BlockCache 按照 LRU 算法淘汰低频访问的数据,TiKV 默认将系统总内存大小的 45% 用于 BlockCache,用户也可以自行修改 storage.block-cache.capacity 配置设置为合适的值,但是不建议超过系统总内存的 60%。
写入 RocksDB 中的数据会写入 MemTable,当一个 MemTable 的大小超过 128MB 时,会切换到一个新的 MemTable 来提供写入。TiKV 中一共有 2 个 RocksDB 实例,合计 4 个 ColumnFamily,每个 ColumnFamily 的单个 MemTable 大小限制是 128MB,最多允许 5 个 MemTable 存在,否则会阻塞前台写入,因此这部分占用的内存最多为 4 x 5 x 128MB = 2.5GB。这部分占用内存较少,不建议用户自行更改。
RocksDB 的空间占用
-
多版本:RocksDB 作为一个 LSM-tree 结构的键值存储引擎,MemTable 中的数据会首先被刷到 L0。L0 层的 SST 之间的范围可能存在重叠(因为文件顺序是按照生成的顺序排列),因此同一个 key 在 L0 中可能存在多个版本。当文件从 L0 合并到 L1 的时候,会按照一定大小(默认是 8MB)切割为多个文件,同一层的文件的范围互不重叠,所以 L1 及其以后的层每一层的 key 都只有一个版本。
-
空间放大:RocksDB 的每一层文件总大小都是上一层的 x 倍,在 TiKV 中这个配置默认是 10,因此 90% 的数据存储在最后一层,这也意味着 RocksDB 的空间放大不超过 1.11 (L0 层的数据较少,可以忽略不计)
-
TiKV 的空间放大:TiKV 在 RocksDB 之上还有一层自己的 MVCC,当用户写入一个 key 的时候,实际上写入到 RocksDB 的是 key + commit_ts,也就是说,用户的更新和删除都是会写入新的 key 到 RocksDB。TiKV 每隔一段时间会删除旧版本的数据(通过 RocksDB 的 Delete 接口),因此可以认为用户存储在 TiKV 上的数据的实际空间放大为,1.11 加最近 10 分钟内写入的数据(假设 TiKV 回收旧版本数据足够及时)。详情见《TiDB in Action》。
RocksDB 后台线程与 Compact
RocksDB 中,将内存中的 MemTable 转化为磁盘上的 SST 文件,以及合并各个层级的 SST 文件等操作都是在后台线程池中执行的。后台线程池的默认大小是 8,当机器 CPU 数量小于等于 8 时,则后台线程池默认大小为 CPU 数量减一。通常来说,用户不需要更改这个配置。如果用户在一个机器上部署了多个 TiKV 实例,或者机器的读负载比较高而写负载比较低,那么可以适当调低 rocksdb/max-background-jobs 至 3 或者 4。
WriteStall
RocksDB 的 L0 与其他层不同,L0 的各个 SST 是按照生成顺序排列,各个 SST 之间的 key 范围存在重叠,因此查询的时候必须依次查询 L0 中的每一个 SST。为了不影响查询性能,当 L0 中的文件数量过多时,会触发 WriteStall 阻塞写入。
如果用户遇到了写延迟突然大幅度上涨,可以先查看 Grafana RocksDB KV 面板 WriteStall Reason 指标,如果是 L0 文件数量过多引起的 WriteStall,可以调整下面几个配置到 64,详细见 《TiDB in Action》。
rocksdb.defaultcf.level0-slowdown-writes-trigger
rocksdb.writecf.level0-slowdown-writes-trigger
rocksdb.lockcf.level0-slowdown-writes-trigger
rocksdb.defaultcf.level0-stop-writes-trigger
rocksdb.writecf.level0-stop-writes-trigger
rocksdb.lockcf.level0-stop-writes-trigger
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190277.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
