维度建模方法论[通俗易懂]维度建模方法一、前言本人学习《数仓工具箱》的学习总结,纯学习分享,供大家参考。二、经典数仓架构理论围绕着维度建模,那就不得不了解,早期的数据仓库构架方法。这里介绍一下两个经典的数仓架构理论。2.1、Kimball模式Kimball模式从流程上看是是自顶向下的,即从数据集市到数据仓库再到数据源(先有数据集市再有数据仓库)的一种敏捷开发方法。对于Kimball模式,数据源每每是给定的若干个数据库表,数据较为稳定但是数据之间的关联关系比较复杂,须要从这些OLTP中产生的事务型数据结构抽取出分析型
大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
维度建模方法
一、前言
本人学习《数仓工具箱》的学习总结,纯学习分享,供大家参考。
二、经典数仓架构理论
围绕着维度建模,那就不得不了解,早期的数据仓库构架方法。这里介绍一下两个经典的数仓架构理论。
2.1、Kimball模式
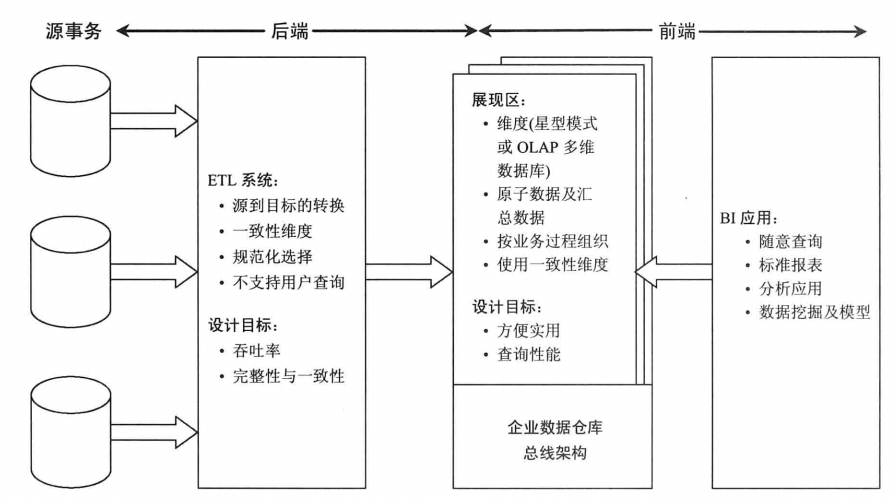

Kimball 模式从流程上看是是自顶向下的,即从数据集市到数据仓库再到数据源(先有数据集市再有数据仓库)的一种敏捷开发方法。对于Kimball模式,数据源每每是给定的若干个数据库表,数据较为稳定但是数据之间的关联关系比较复杂,须要从这些OLTP中产生的事务型数据结构抽取出分析型数据结构,再放入数据集市中方便下一步的BI与决策支持。所以KimBall是根据需求来确定需要开发ETL哪些数据。
2.2、Inmon模式
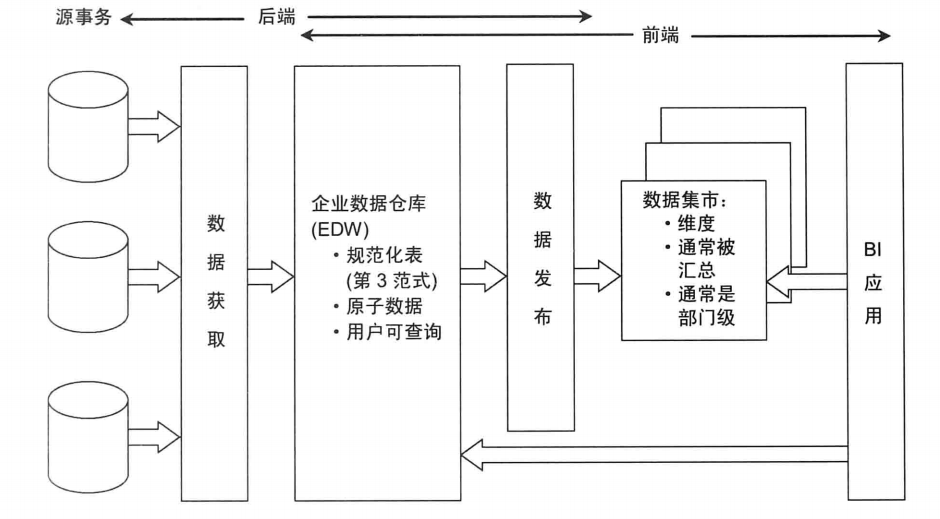
Inmon 模式从流程上看是自底向上的,即从数据源到数据仓库再到数据集市的(先有数据仓库再有数据市场)一种瀑布流开发方法。对于Inmon模式,数据源每每是异构的。这里主要的数据处理工作集中在对异构数据的清洗,包括数据类型检验,数据值范围检验以及其余一些复杂规则。在这种场景下,数据没法从stage层直接输出到dm层,必须先经过ETL将数据的格式清洗后放入dw层,再从dw层选择须要的数据组合输出到dm层。在Inmon模式中,并不强调事实表和维度表的概念,由于数据源变化的可能性较大,须要更增强调数据的清洗工作,从中抽取实体-关系。immon是将整个数据仓库规划好,统一按照范式建模进行开发。
参考:深入对比数据仓库模式:Kimball vs Inmon
三、维度建模步骤
3.1、设计企业服务总线
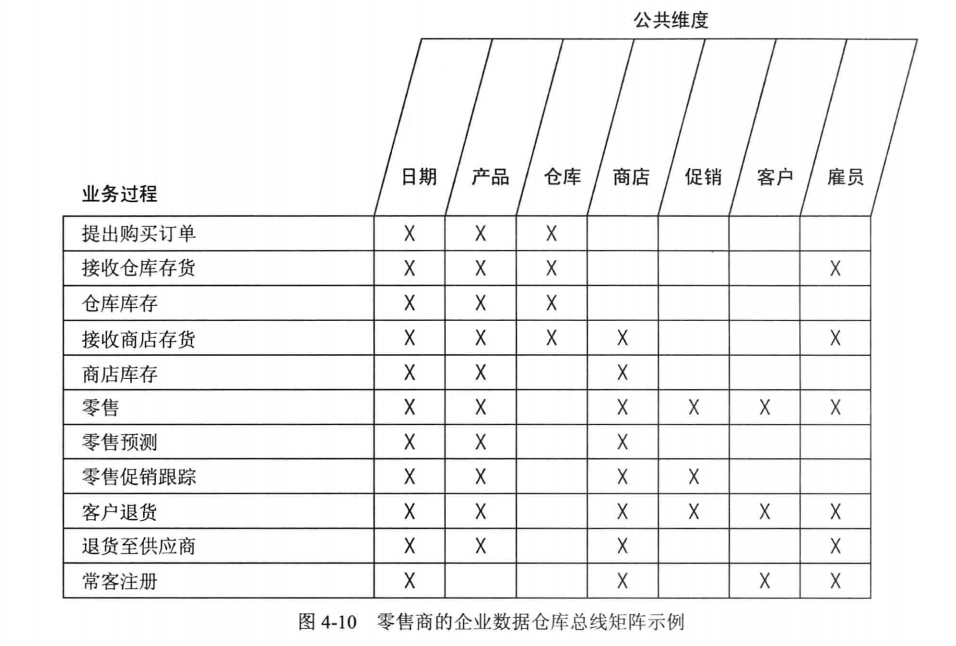
需要调查业务过程以及业务过程所涉及的公共维度。比如零售商从订单到库存到零售这些业务过程中所涉及到的公共维度用一个矩阵进行统计,梳理这些的过程中,也对总体业务流程有概要的了解。
3.2、选择业务过程
业务过程通常用行为动词表示,如:获取订单、开具发票、接收付款,注册账号、处理索赔等。维度建模是紧贴业务的,所以必须以业务为根基进行建模,那么选择业务过程,顾名思义就是在整个业务流程中选取我们需要建模的业务,根据运营提供的需求及日后的易扩展性等进行选择业务。比如商城,整个商城流程分为商家端,用户端,平台端,运营需求是总订单量,订单人数,及用户的购买情况等,我们选择业务过程就选择用户端的数据,商家及平台端暂不考虑。业务选择非常重要,因为后面所有的步骤都是基于此业务数据展开的。
3.3、声明粒度
先举个例子:对于用户来说,一个用户有一个身份证号,一个户籍地址,多个手机号,多张银行卡,那么与用户粒度相同的粒度属性有身份证粒度,户籍地址粒度,比用户粒度更细的粒度有手机号粒度,银行卡粒度,存在一对一的关系就是相同粒度。为什么要提相同粒度呢,因为维度建模中要求我们,在同一事实表中,必须具有相同的粒度,同一事实表中不要混用多种不同的粒度,不同的粒度数据建立不同的事实表。并且从给定的业务过程获取数据时,强烈建议从关注原子粒度开始设计,也就是从最细粒度开始,因为原子粒度能够承受无法预期的用户查询。但是上卷汇总粒度对查询性能的提升很重要的,所以对于有明确需求的数据,我们建立针对需求的上卷汇总粒度,对需求不明朗的数据我们建立原子粒度。
3.4、确认维度
维度表是作为业务分析的入口和描述性标识,所以也被称为数据仓库的“灵魂”。在一堆的数据中怎么确认哪些是维度属性呢,如果该列是对具体值的描述,是一个文本或常量,某一约束和行标识的参与者,此时该属性往往是维度属性,牢牢掌握事实表的粒度,就能将所有可能存在的维度区分开,并且要确保维度表中不能出现重复数据,应使维度主键唯一
3.5、确认事实
可以通过回答“业务过程的度量是什么?”这一问题来确定事实。事实表是用来度量的,基本上都以数量值表示,事实表每行的数据是一个特定级别的细节数据,称为粒度。维度建模的核心原则之一是同一事实表中的所有度量必须具有相同的粒度。这样能确保不会出现重复计算度量的问题。有时候往往不能确定该列数据是事实属性还是维度属性。记住最实用的事实就是数值类型和可加类事实。所以可以通过分析该列是否是一种包含多个值并作为计算的参与者的度量,这种情况下该列往往是事实。
四、维度建模设计技巧
4.1、使用代理键代替自然键作为维度表主键
自然键:就是充当主键的字段本身具有一定的含义,是构成记录的组成部分,比如学生的学号,除了充当主键之外,同时也是学生记录的重要组成部分。
代理键:就是充当主键的字段本身不具有业务意义,只具有主键作用,比如自动增长的ID。
使用代理键的优点:
- 为数据仓库缓冲源系统的变化。例如:账号闲置一年就会重新分配给新用户,如果用账号作为数据主键,则原账号数据就会被覆盖丢失;如果用代理键作为维度主键,那么可以对账号的变化赋予新的代理键以作区分。
- 集成多个源系统。可以通过引用映射表将多个自然键连接成一个公共的代理键。
4.2、缓慢变化维度处理方法
类型0:不做任何处理
案例:用户在使用产品之前是有注册动作的,大部分产品都会让用户填写出生年月之类的属性信息,当然用户有可能是瞎写的,在未来的某个时间点可能想把这个出生信息给重新修改,站在分析的角度上,我们通常是使用第一次注册的数据,或者是使用身份证上的信息为准。那么对于这种持久型的标识符通常是不做任何处理的。
适用场景:这种处理手段适用于我们只关心第一次维度属性值的场景下,后续变化的值都认为是无效的。
类型1:重写覆盖
案例:在实际的业务过程中,用户是会更换手机号或者更改用户名的,那么站在分析的角度上来看,通常是只关心最新的数据,所以针对这种场景,我们可以采取覆盖的方式来解决,比如小明把用户名称改为小小明,那么从数据角度上来看的就变成了如下的方式:
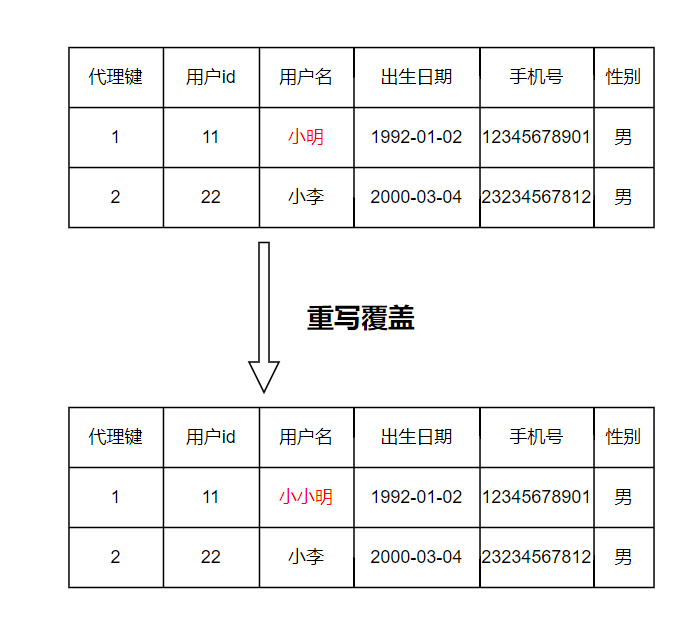
适用场景:这适用于只关心最新数据的场景下,不需要关心属性历史信息变化;不用投入过多的etl成本,维护也比较简单
类型2:增加新行
案例:虽然重写覆盖的手段比较简单,但是其缺点也很明显,那就是我们没有办法分析历史变化的数据了,特别是像手机号这类的数据变更,是完全有必要把每次的变更记录保留下来,特别是对于风控业务,利用手机号通过图谱关系结合欺诈规则来拦截羊毛党、团伙欺诈等黑产。针对这类场景,我们可以采用新增记录的方式来解决。如下图所示,通过增加新行并分配新的代理键来保留维度的历史变化数据。
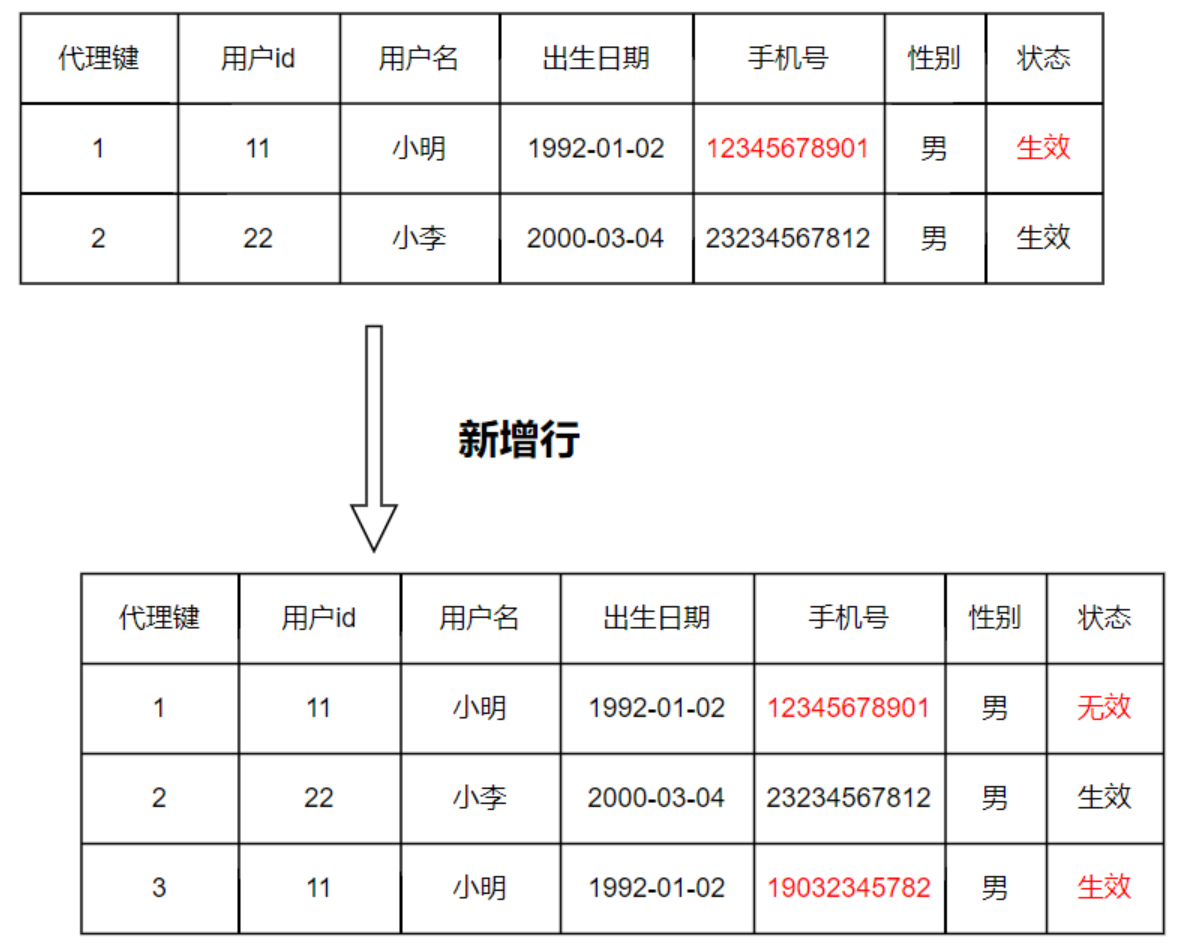
适用场景:该方案也是比较简单的一种处理方式,而且保留了历史信息变化的数据;但是该种方式在每变更一次就会新增一条记录,整个维表就会随着时间推移其数据也会越发膨胀,只要有一个维度发生变化,都会新增一行记录(当然一个维表里可以只对某几个属性变更采用类型2)
类型3:增加新列
案例:维度属性每次发生一次变更,我们通过新增一条记录的方式来保留历史数据,但其缺点也比较明显。对于数据量比较大的维度表来说,采用类型2就有些笨拙了,特别是对于属性指标分组的分析场景下就不太适用新增行记录的方式了。比如按照性别分组来分析活跃占比的时候,如果突然有一天的占比和历史分析结果相差比较大的时候,那么就需要定位判断是否有大量的属性变更的情况存在,针对这种情况可以采用新增列的方式来保留上一个变更版本的记录。如下图所示:
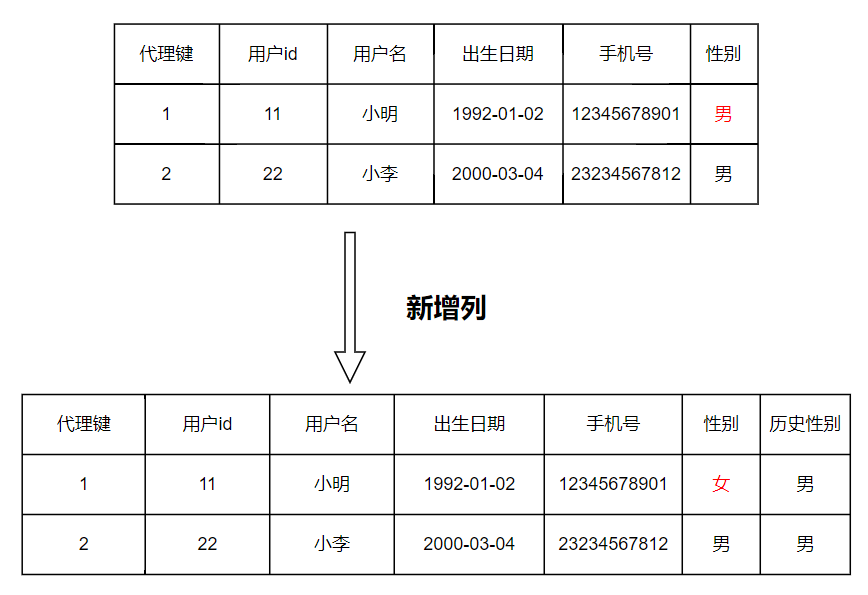
适用场景:避免了因为信息变化而新增记录造成数据膨胀的情况;而且可以允许保留一部分版本的变化,很多书籍中大多是新增一个当前列和上一次变化的列值,当然也可以多搞几个字段来保存多个版本,但不会把所有版本的数据都保留下来,而且如果维度信息比较多的话,那么字段就会变得非常多(比如表里有5个维度属性,需要保留3个版本,那这个表的字段数就会扩充到15个),所以这种处理手段很少用到,只适用于可以预测到变化而且不会分析过多版本的场景下(比如本案例中的男女占比分析)。
类型4:微型维度
案例:微型维度大概意思就是说对于变化比较快的维度(这个时候已经超出了缓慢变化的定义了)抽离出来形成一张单独的维表,那么抽离出来的这个维度表就被称为“微型维度”,说白了其实就是从大维表里把几个变化比较快的维度拿出来形成一个小的维度表(相对于原有维度来说确实是一个小维表)。比如在画像的场景中,我们通常会基于用户的收入属性运用一些规则定一个收入级别,并对用户打上一些标签,比如用户是属于高收入,高消费,还是属于低收入,高消费人群。通常收入属性可以说是变化比较频繁的(不要抬扛,特别是像拿提成的岗位收入本身就不是固定的),如果直接放在基维表(基础维度表,可以理解成主维表)的话就会不太合适了。所以采用微型维度,将收入级别这类变化比较快的维度抽离出来单独搞一个小型维。这样一搞的话,就解决了基维表数据一旦变化就会新增记录的问题了。因为微型维度是框定了范围,在范围内的变化,都对应的同一个范围值,比如小明的年龄从20岁变化到22岁对应的微型维度代理键还是03。而且将维度维度代理键代替年龄范围、收入水平、消费水平三个快速变化的维度,在原有维表上减属性。
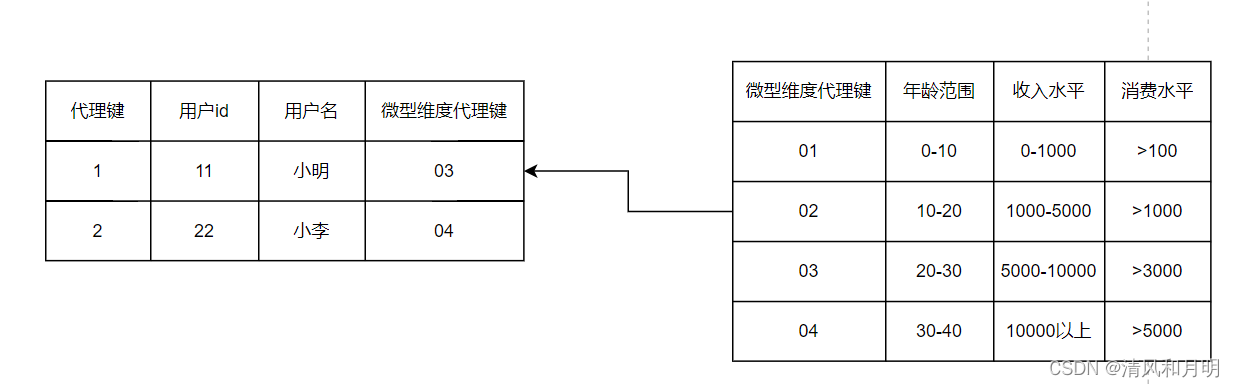
适用场景:维度快速变化的情况,需要维护主表中对应的微型维度代理键
参考:建模之旅:你以为的SCD
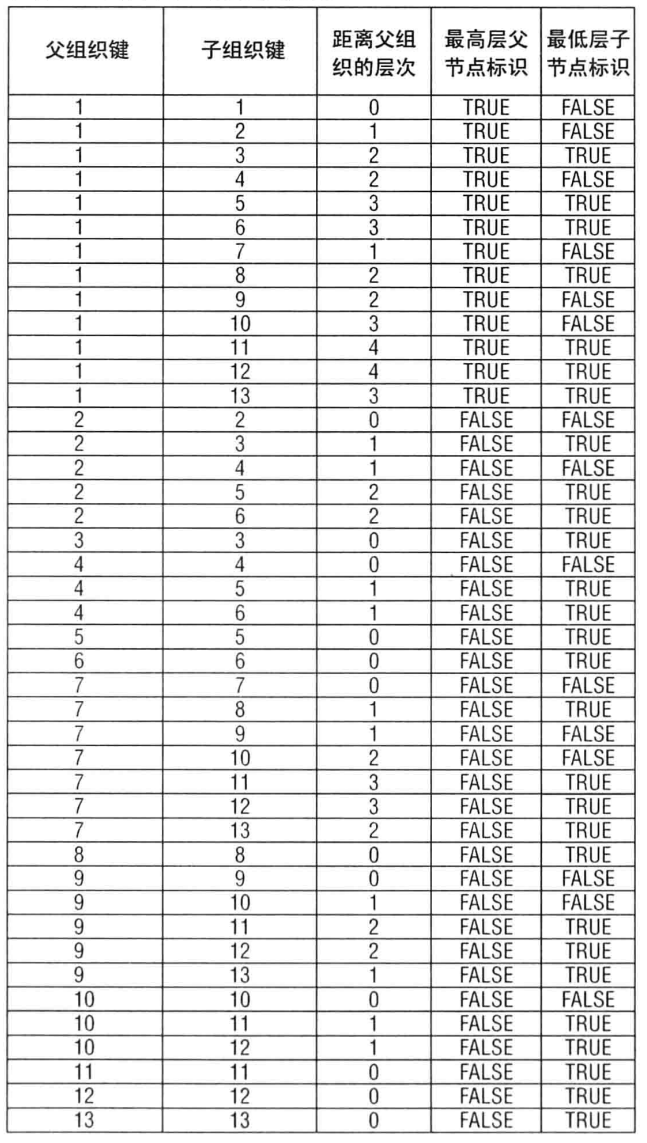
4.3、树状结构数据处理
有些涉及多层级数据处理,比如对财务各级组织的相关指标计算。这就需对多层级数据处理。如下图,模拟的是集团中的组织架构,举例:怎么计算7和7所有的下属机构对应的月营收收入?
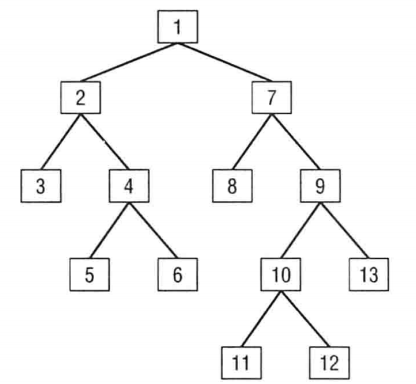
这里可以建立多层级组织关系桥接表,如下图。通过这个桥接表来筛选出7的所有下属机构。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/190208.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】:
Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】:
官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
