大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
0. 前言
- 一些常用的数据增强方法
- Cutout:随即删除一个矩形区域,通过0填充
- Random Erasing:随即删除一个矩形区域,通过均值填充
- Mixup:两张图像每个位置的像素根据一定比例进行叠加,label根据像素叠加比例进行分配
- Cutmix:随机删除一个矩形区域,并通过另一张图像的同一位置像素值填充,label根据像素所占比例进行分配
1. Cutout
1.1. 要解决什么问题
- 深度学习训练非常容易造成过拟合,需要大量数据以及各类正则化方法。
- 数据增强可以看做是一种正则化方法。
1.2. 用了什么方法
- Cutout本身非常容易,就是随机将若干个矩形区域删除(像素值改成0)
class Cutout(object):
"""Randomly mask out one or more patches from an image. Args: n_holes (int): Number of patches to cut out of each image. length (int): The length (in pixels) of each square patch. """
def __init__(self, n_holes, length):
self.n_holes = n_holes
self.length = length
def __call__(self, img):
""" Args: img (Tensor): Tensor image of size (C, H, W). Returns: Tensor: Image with n_holes of dimension length x length cut out of it. """
h = img.size(1)
w = img.size(2)
mask = np.ones((h, w), np.float32)
for n in range(self.n_holes):
y = np.random.randint(h)
x = np.random.randint(w)
y1 = np.clip(y - self.length // 2, 0, h)
y2 = np.clip(y + self.length // 2, 0, h)
x1 = np.clip(x - self.length // 2, 0, w)
x2 = np.clip(x + self.length // 2, 0, w)
mask[y1: y2, x1: x2] = 0.
mask = torch.from_numpy(mask)
mask = mask.expand_as(img)
img = img * mask
return img
- 看本文前我就非常好奇,这到底能说出什么花来。
- 还真能讲个故事……
- 将Cutout和Dropout比较,认为Cutout就是Dropout的一种特殊形式。
- 只是dropout的对象变成了输入图像,而不是特征图。
- 忽略的是一个连续的区域,而不是随机选择的。
- 没有进行rescale。
- Cutout的motivation是“遮挡”,即删除的矩形区域可以看成是被遮挡的位置。
- 最初设计Cutout的时候其实很复杂:
- 去除的区域不是随机的矩形区域,而是去掉输入图像中重要的特征。
- 方法类似于maxdrop,目标删除重要区域,从而通过其他信息来获取分类结果,达到更好的模型泛化能力。
- 实现方法就是:每一轮都记录每张图片的maximally activated feature map,然后下一轮根据阈值删除指定区域。
- 但后来发现,随机删除区域的效果与这个复杂的方法差不多。
- 举例如下图


1.3. 效果如何
- 结果发现,删除区域面积的重要性远远大于删除区域的形状。
- 使用了Cutout后,普遍提点了
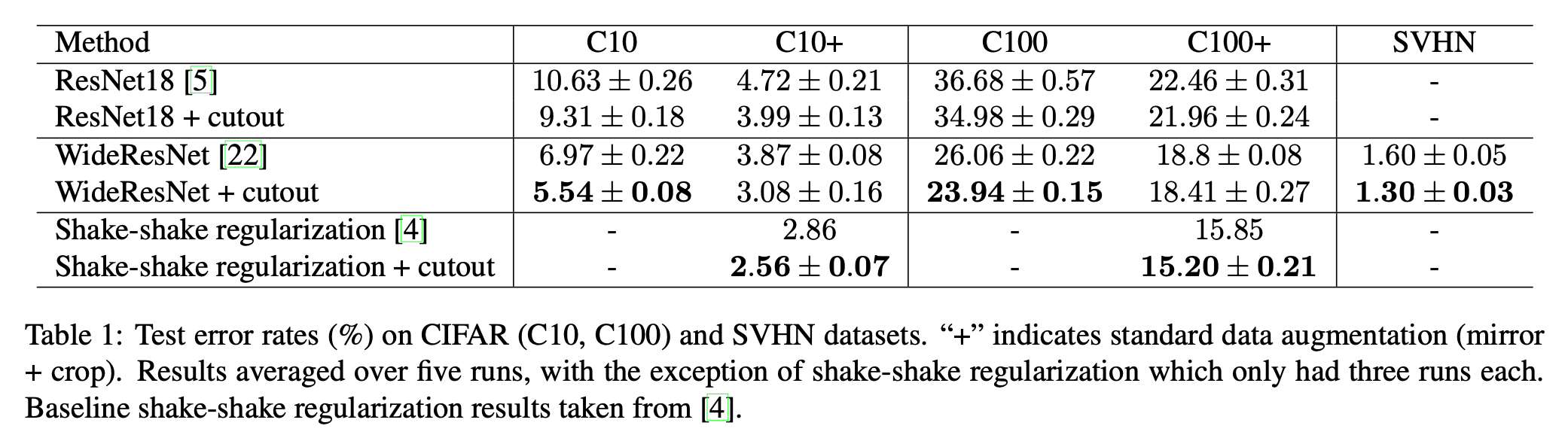
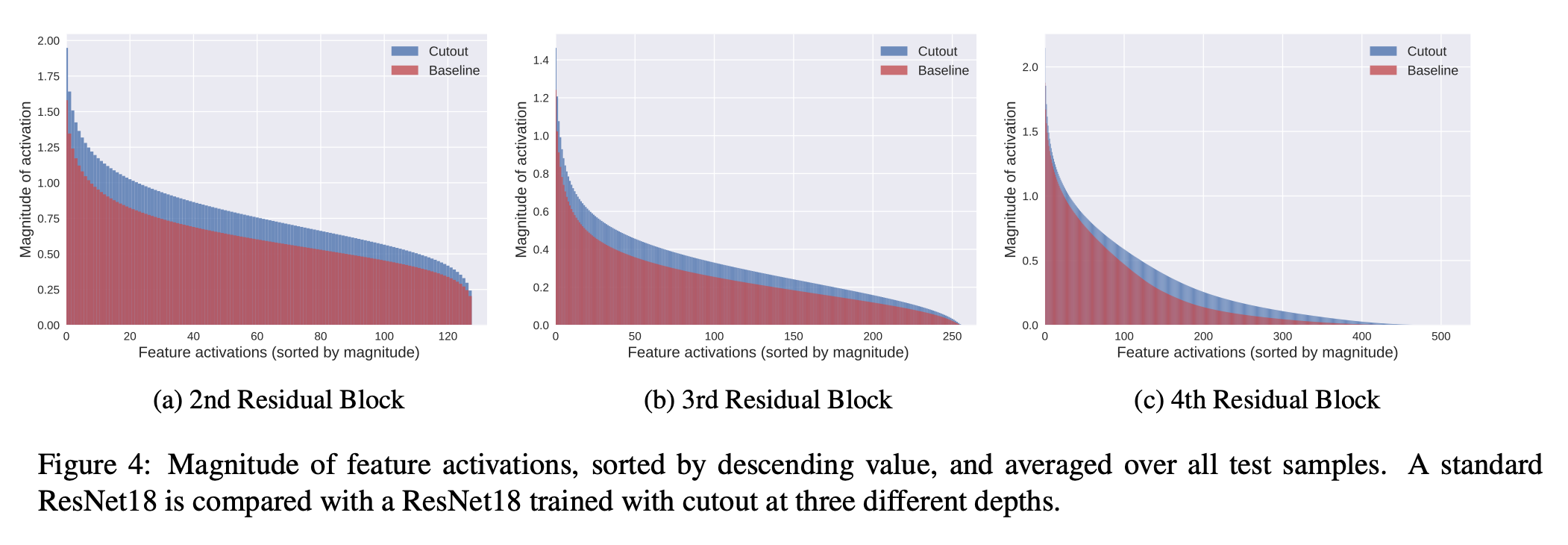
- 使用了Cutout后,到底造成了什么样的效果?
- 红色区域是没有cutout时的结果,蓝色是加上cotout后变化的结果。
- 浅层特征图(如图a)的activate strength(特征图数值大小)增加了
- 深层特征图(如图c)的分布范围更广(see more activatetions in tail end of the distribution)
1.4. 还存在什么问题&可借鉴之处
- 第一反应:这也能作为论文?
- 感觉更像是实验报告、项目总结。
2. Rand Erasing
2.1. 要解决什么问题
- 卷积神经网络容易过拟合,需要大量数据来提高模型的泛化能力。
- 遮挡问题在提高模型泛化能力方面非常重要。
2.2. 用了什么方法
- Random Erasing 效果

- 代码
class RandomErasing(object):
def __init__(self, EPSILON = 0.5, sl = 0.02, sh = 0.4, r1 = 0.3, mean=[0.4914, 0.4822, 0.4465]):
self.EPSILON = EPSILON
self.mean = mean
self.sl = sl
self.sh = sh
self.r1 = r1
def __call__(self, img):
if random.uniform(0, 1) > self.EPSILON:
return img
for attempt in range(100):
area = img.size()[1] * img.size()[2]
target_area = random.uniform(self.sl, self.sh) * area
aspect_ratio = random.uniform(self.r1, 1/self.r1)
h = int(round(math.sqrt(target_area * aspect_ratio)))
w = int(round(math.sqrt(target_area / aspect_ratio)))
if w < img.size()[2] and h < img.size()[1]:
x1 = random.randint(0, img.size()[1] - h)
y1 = random.randint(0, img.size()[2] - w)
if img.size()[0] == 3:
#img[0, x1:x1+h, y1:y1+w] = random.uniform(0, 1)
#img[1, x1:x1+h, y1:y1+w] = random.uniform(0, 1)
#img[2, x1:x1+h, y1:y1+w] = random.uniform(0, 1)
img[0, x1:x1+h, y1:y1+w] = self.mean[0]
img[1, x1:x1+h, y1:y1+w] = self.mean[1]
img[2, x1:x1+h, y1:y1+w] = self.mean[2]
#img[:, x1:x1+h, y1:y1+w] = torch.from_numpy(np.random.rand(3, h, w))
else:
img[0, x1:x1+h, y1:y1+w] = self.mean[1]
# img[0, x1:x1+h, y1:y1+w] = torch.from_numpy(np.random.rand(1, h, w))
return img
return img
- 内容跟cutout差不多
- 都说实现简单、达到较好效果
- 都说借鉴了dropout,但有一点点不同
2.3. 效果如何
- 除了对图像分类任务进行对比,对检测、ReID进行对比。
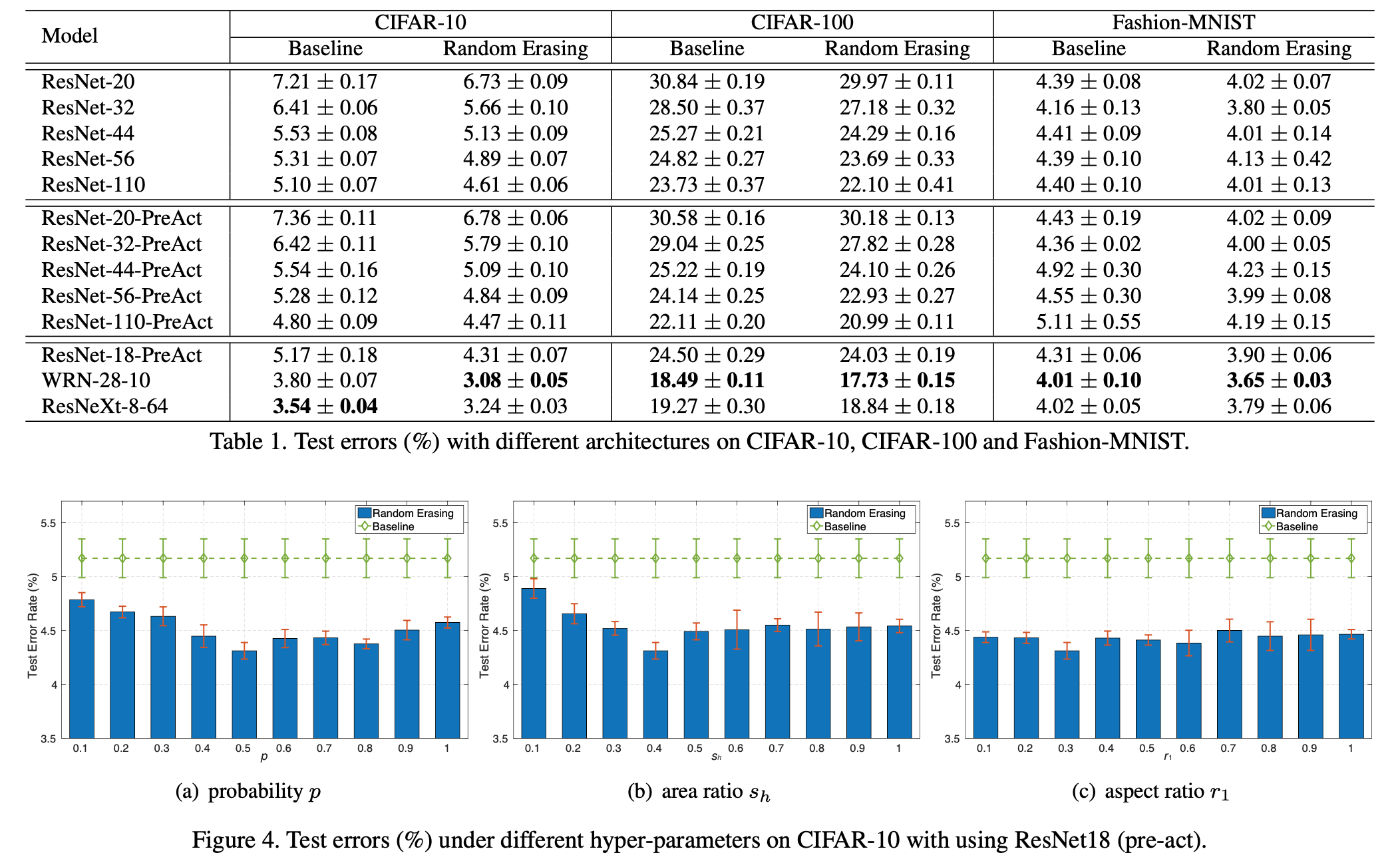
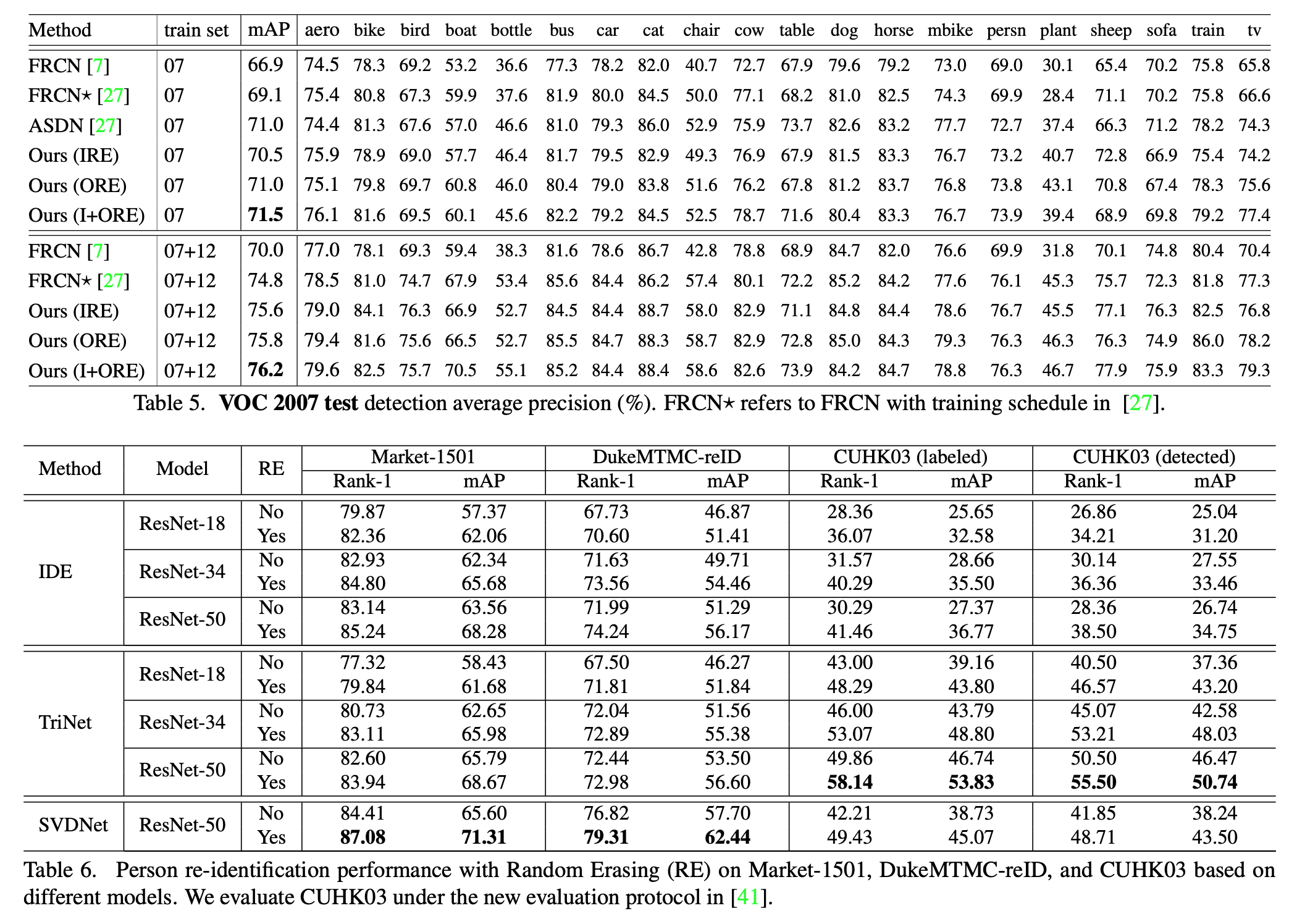
- 本文还对比了对于不同填充数值的结果(随机数填充效果最好),与dropout的对比,以及与其他增强方法的对比

2.4. 还存在什么问题&可借鉴之处
- 跟Cutout是一回事,两篇论文的发表时间非常接近
- 总感觉用于检测、ReID任务有点不对,小目标一档不就啥都没了
3. Mixup
3.1. 要解决什么问题
- 成功的神经网络示例都有两个共同特点
- 使用了ERM(经验风险最小化)原则训练模型。
- 数据越多,效果越好。
- ERM存在一个矛盾的情况
- 一方面,ERM令大型神经网络记住了训练数据。
- 另一方面,ERM存在对抗样本问题(有一点点不同就可能导致结果偏差很大),如果数据不在训练分布中就容易出现问题。
- 有什么取代ERM的方法呢?
3.2. 用了什么方法
- Mixup的定义非常简单
- 输入图像每个像素按比例融合,输出结果按比例融合(one-hot形式)

- Mixup官方代码如下,就是在一个batch里进行shuffle然后累加。
def mixup_data(x, y, alpha=1.0, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
- 数学角度分析Mixup
- 论文介绍了如何从数据角度理解,从ERM进化为Mixup
- 大概就是从 expected risk -> empirical distribution -> approximate the expected risk by the empirical risk -> VRM -> generic vicinal distribution
- 我也不是特别懂,就不贴公式了,论文中自己看吧
- 对于Mixup的一些理解
- A \Alpha A 趋向于0时,Mixup就退化为ERM
- 试验发现,>2个样本Mixup的效果也没有啥提升。
- 实现Mixup使用了同一mini-batch中的shuffle
- 鼓励模型behave linearly in-between training samples,不知道该怎么翻译,不同样本间线性转换时,label也线性转换?
- 论文认为linear behaviours减少了预测其他样本时的oscillation(扰动、彷徨,该怎么翻译?)
- linearity也是奥卡姆剃刀的一种体现
- 下图b中也显示,mixup令不同类别之间的边界(desicion boundaries)线性变换。

3.3. 效果如何
- 图像分类效果更好了,对于speech data(语音?)效果也更好了(图没放)
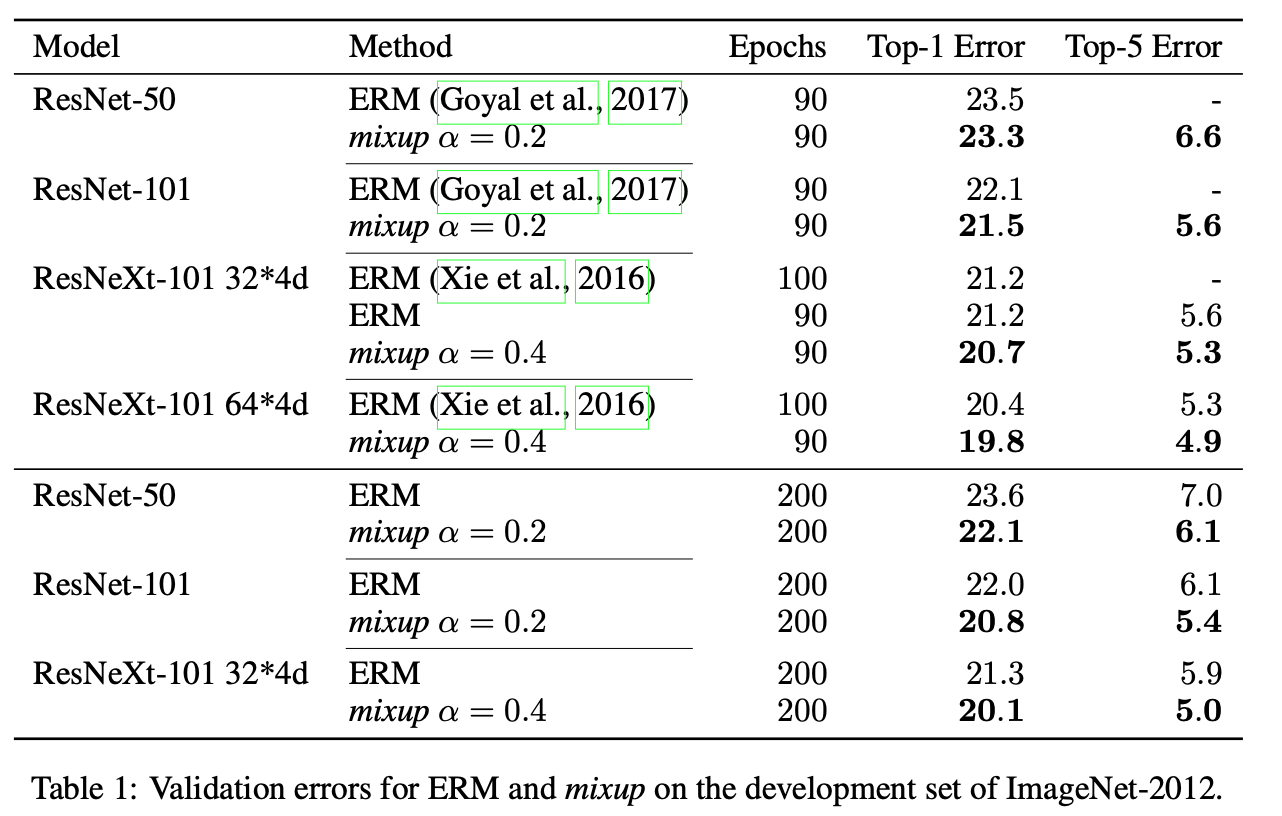
- 对于corrept labels(错误标签)以及对抗样本的效果都变好了
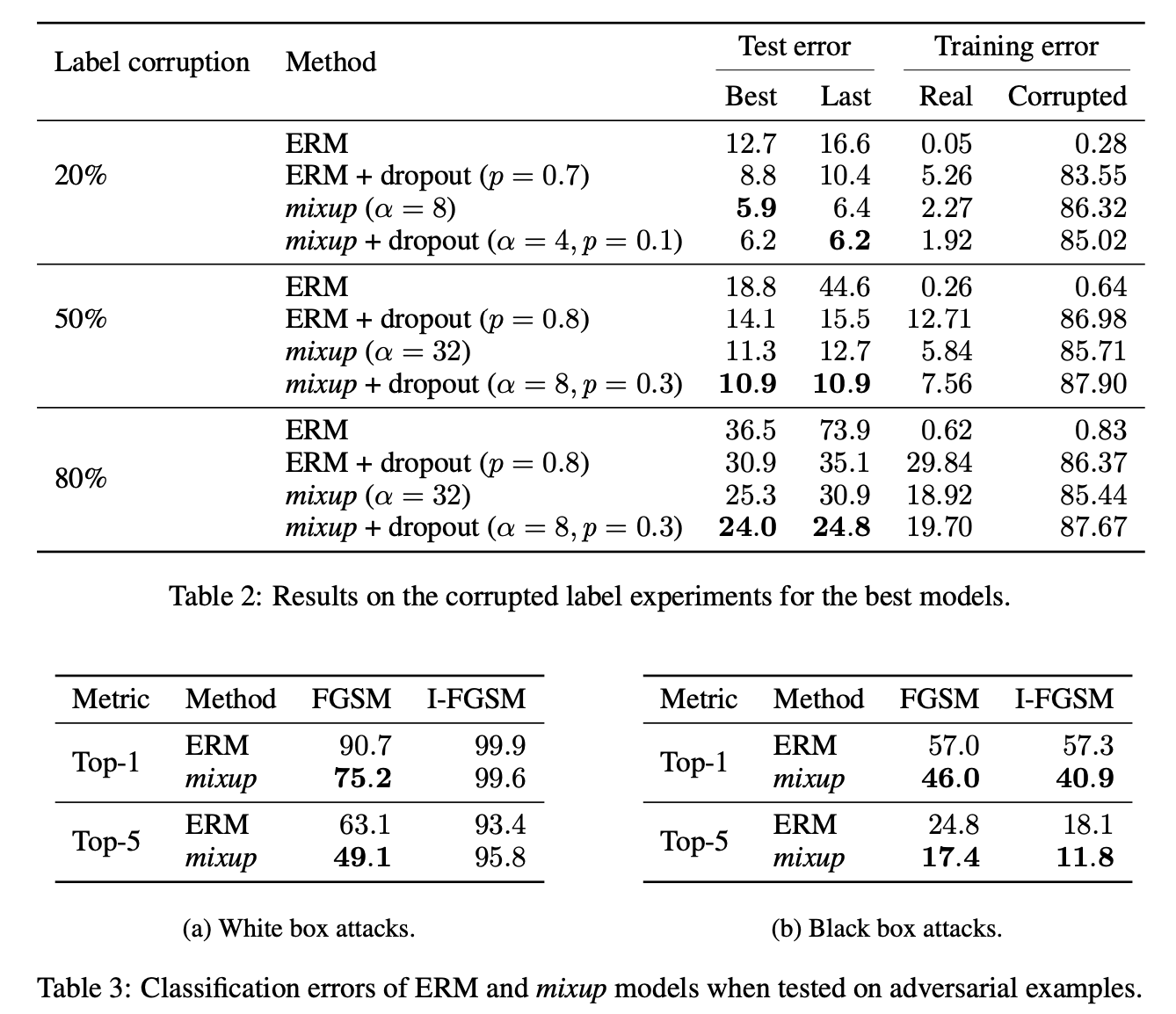
- 还做了很多消融试验,我关注的就是同一类样本之间的mixup效果并不好,还是要多类样本之间进行。
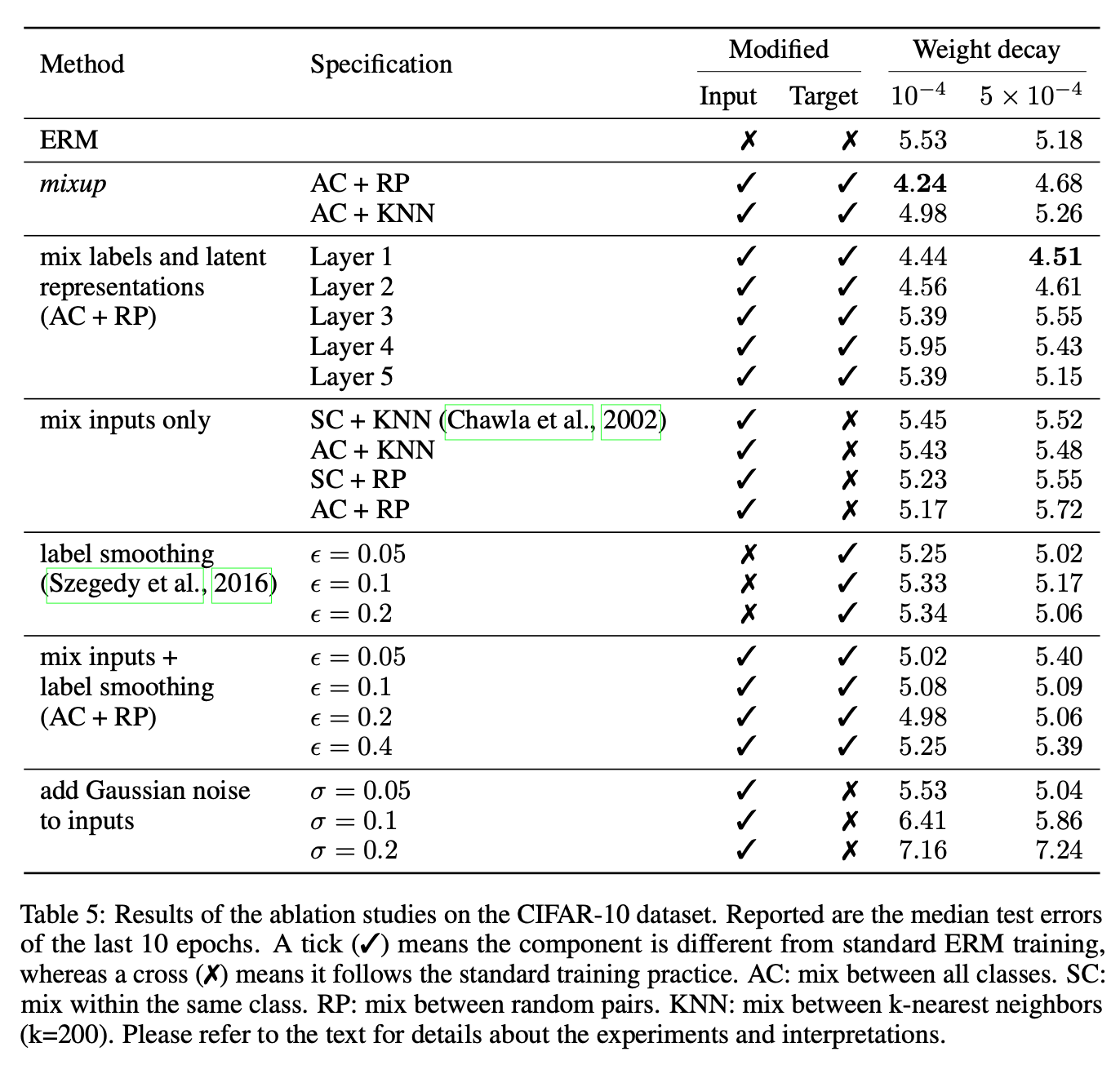
3.4. 还存在什么问题&可借鉴之处
- Mixup的主要问题我觉得是与我们人类视觉习惯不符。
- 一直以来CV给我的感觉都是模仿人类视觉,如果能做到人能做到的事情就很厉害了。
- 但Mixup跟我之前的感觉不一样,Mixup之后的训练数据对于我们人来说还是比较费劲的。
- 在行为识别里也能用,计划复现一个。
4. Cutmix
- 相关资料:
- 论文基本信息
- 领域:数据增强
- 作者单位:NAVER Crop(韩国搜索引擎) & LINE Plus Crop(韩国版微信?不太清楚) & 韩国延世大学
- 发表时间:ICCV 2019
- 一句话总结:随机删除一个矩形区域,并通过另一张图像的同一位置像素值填充删除了的区域,label根据像素所占比例进行分配
4.1. 要解决什么问题
- Regional Dropout Strategies比较有效(令模型不会只关注一个小区域),比如前文说的Cutout和Random Erasing,但也存在问题
- 会损失一些信息,且inefficient during training(不知道该怎么理解)
- 如何更好的利用cutout中删除的区域?
4.2. 用了什么方法
- 什么是CutMix,下图很清晰了
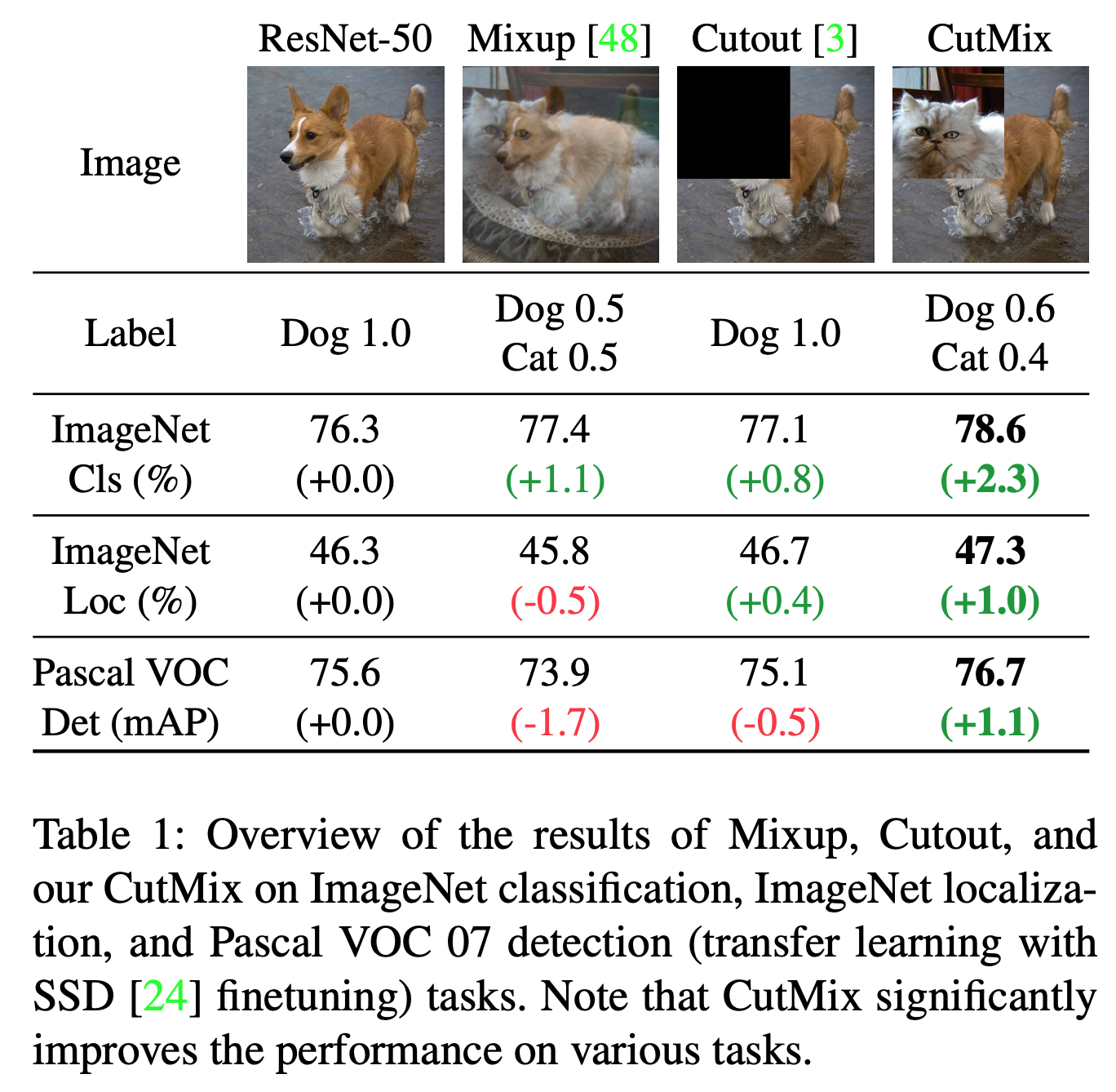
- Cutmix公式定义如下
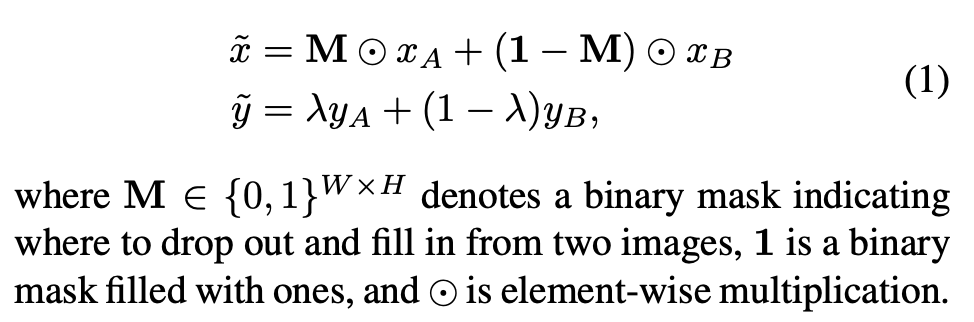
- 问题的关键在于 λ \lambda λ怎么获取,删除的区域如何获取

4.3. 效果如何
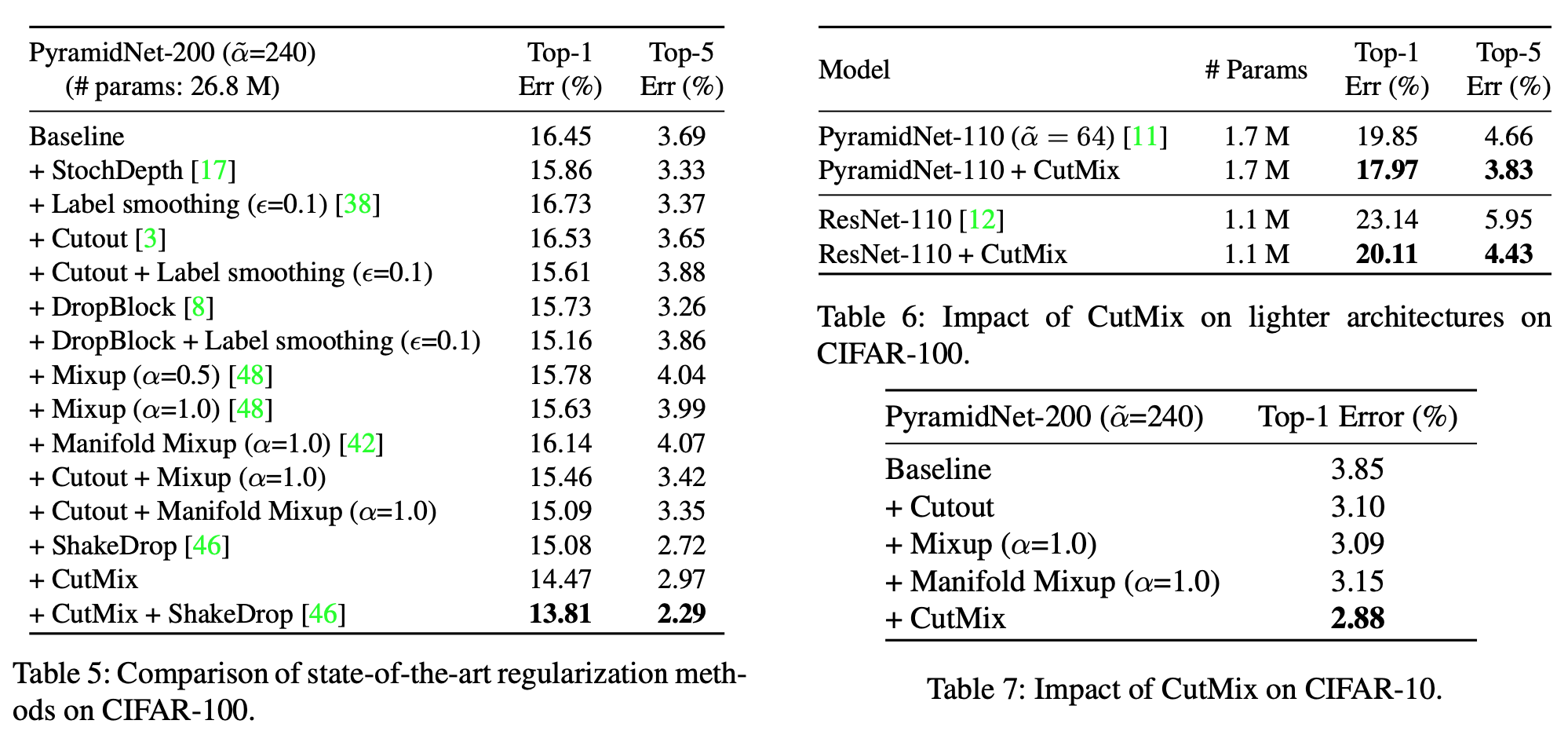
- 对于分类任务效果较好

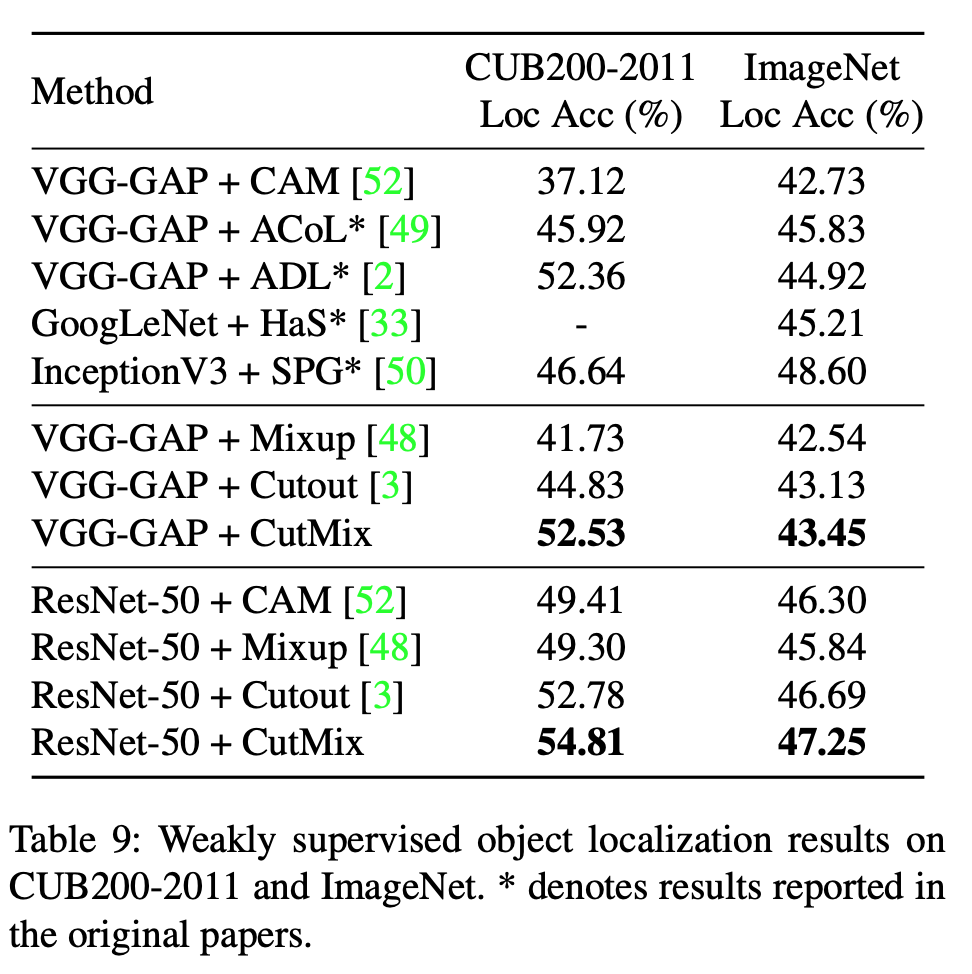
- 对于弱监督学习定位任务效果较好
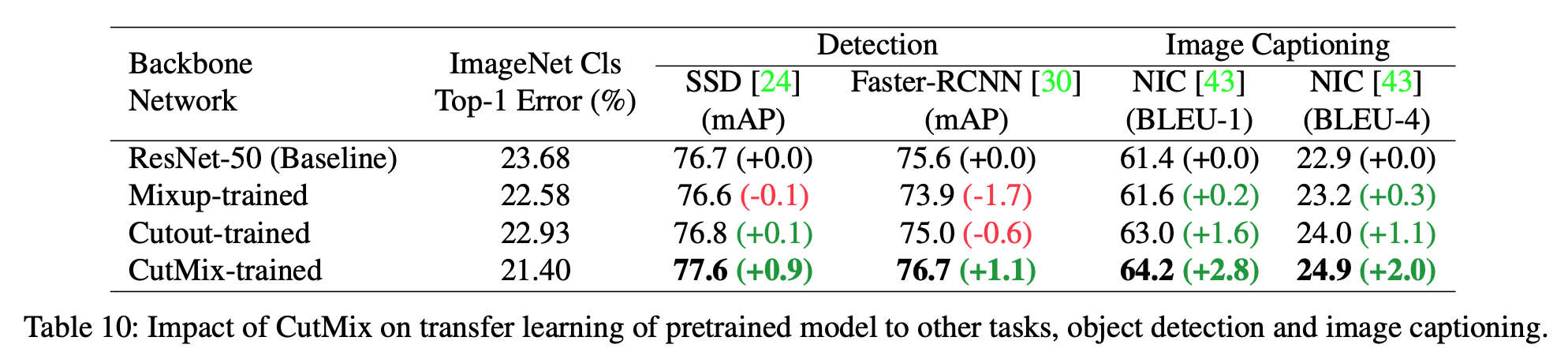
- 用于迁移学习时效果也更好
4.4. 还存在什么问题&可借鉴之处
- 对于这些增强方法都有一个问题,随机删除了区域如果没有什么重要信息只有背景信息,那应该会影响结果吧?
- 换句话说,这些方法应该对输入数据都有较大要求吧。。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189690.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
