大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
Stream基础概念
Stream流是 Java8 API 新增的一个处理集合的关键抽象概念,是一个来自数据源的元素队列并支持聚合操作。以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
| 相关名词 | 描述 |
|---|---|
| 元素 | 对象形成的一个队列。 Java中的Stream并不会存储元素,而是按需计算。 |
| 数据源 | 是流Stream的来源。 可以是集合、数组、I/O channel、 产生器generator 等 |
| 聚合操作 | 类似SQL语句一样的操作,比如filter, map, reduce, find, match, sorted等。 |
| 内部迭代 | 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。 |
| Pipelining | 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。 |
Stream的特点:
- Stream不是什么数据结构,它不会保存数据,只是将操作的数据结果保存到另一个对象中。
- Stream是惰性求值的(延迟执行),在中间处理的过程中,只对操作进行记录,并不会立即执行,只有等到执行终止操作的时候才会进行实际的计算,这时候中间操作才会执行。
- 可以把Stream当成一个高级版本的Iterator来使用。(原始版本的Iterator,只能一个个的遍历操作)
1. 分类
| Stream操作分类 | 作用描述 | 常用方法 |
|---|---|---|
| 无状态 | 中间操作, 该操作不受之前元素的影响 | unordered、filter、map、mapToInt、mapToLong、mapToDouble、flatMap、flatMapToInt、flatMapToLongg、flatMapToDouble、peek |
| 有状态 | 中间操作,该操作只有拿到所有元素之后才能继续执行 | distinct、sorted、limit、skip |
| 非短路操作 | 结束操作 , 必须处理所有元素才能得到最终结果 | forEach、forEachOrdered、toArray、collect、max、min、count、reduce |
| 短路操作 | 结束操作 , 遇到某些符合条件的元素就可以得到最终结果 | anyMatch、allMatch、noneMatch、findFirsh、findAny |
2. 常用方法
初始化一个String类型的List集合
List<String> stringList = Arrays.asList("a","b", "", "", "c", "", "a", "d","e","a");
System.out.println("字符串集合:" + stringList);
运行结果:
字符串集合:[a, b, , , c, , a, d, e, a]
创建JavaBean对象User,初始化一个User列表
@Data
class User{
String name;
String description;
}
List<User> userList = new ArrayList<>(
Arrays.asList(
new User("strive", "努力"),
new User("fighter", "奋斗"),
new User("lucky", "幸运"),
new User("lucky", "幸运222")
)
);
运行结果:
[User{name=‘strive’, description=‘努力’}, User{name=‘fighter’, description=‘奋斗’}, User{name=‘lucky’, description=‘幸运’}, User{name=‘lucky’, description=‘幸运222’}]
2.1 forEach
forEach方法用于迭代遍历每个数据
//迭代遍历输出
stringList.forEach(str ->{
System.out.print(str + " ");
});
运行结果:
a b c a d e a
2.2 filter
使用 filter 按照设置的条件过滤元素,得到满足条件的元素。
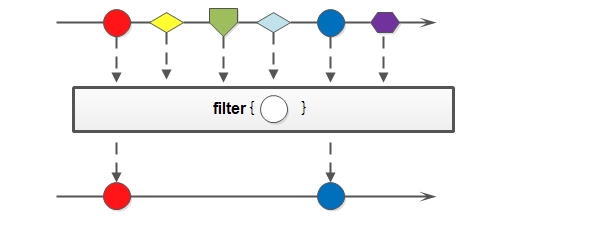

//获取stringList中非空字符串的集合
List<String> collect = stringList.stream().filter(str -> !str.isEmpty())
.collect(Collectors.toList());
System.out.println("非空字符串集合:" + collect);
运行结果:
非空字符串集合:[a, b, c, a, d, e, a]
count() 方法,用来统计数量
long emptyStrNum = stringList.stream().filter(str -> str.isEmpty()).count();
System.out.println("空字符串数量 = " + emptyStrNum);
运行结果:
空字符串数量 = 3
2.3 distinct
distinct() 方法用于去重
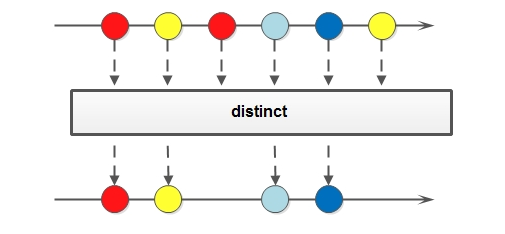
//获取stringList中非空字符串的集合 去重后 转化为list集合
List<String> collect3 = stringList.stream().filter(str -> !str.isEmpty()).distinct()
.collect(Collectors.toList());
System.out.println("去重后字符串集合:" + collect3);
//提取出userList对象中的属性name并去重
List<String> nameList = userList.stream().map(User::getName).distinct().collect(Collectors.toList());
System.out.println("nameList = " + nameList);
运行结果:
去重后字符串集合:[a, b, c, d, e]
nameList = [strive, fighter, lucky]
2.4 Collectors – (Collector工具库)
Collectors 类中实现了很多的规约操作(可用于返回列表或字符串)
最常用的是将流转换为 集合或聚合元素对象
2.4.1 Collectors.toList()方法将Stream转化为List对象
//查找非空、去重后通过 Collectors.toList() 转化为List列表
List<String> strList = stringList.stream().filter(str -> !str.isEmpty())
.distinct().collect(Collectors.toList());
System.out.println("strList = " + strList);
运行结果:
strList = [a, b, c, d, e]
2.4.2 Collectors.toSet()方法将Stream转化为Set对象
//通过 Collectors.toSet() 方法转化为set列表
//set集合,不去重也输出相同的结果(set中不会有重复的元素)
Set<String> strSet = stringList.stream().filter(str -> !str.isEmpty())
.collect(Collectors.toSet());
System.out.println("strSet = " + strList);
运行结果:
strSet = [a, b, c, d, e]
2.4.3 Collectors.toMap()方法将Stream转化为Map对象
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,BinaryOperator mergeFunction,Supplier mapSupplier)参数1: keyMapper 用来生成key值的。
参数2: valueMapper 用来生成value值的。
参数3: mergeFunction 用在key值冲突的情况下使用(可省略),如果新元素产生的key在Map中已经出现过了,第三个参数就会定义解决的办法。
参数4:mapSupplier 默认返回的map类型为hashMap,可以按自己的需要自己返回不同的map实现。( 可省略 )
主要举个3个参数的案例来说明:
Collectors.toMap(keyMapper, valueMapper, mergeFunction)该toMap()方法有三个参数.
比如
collect Collectors.toMap(User::getName, i -> i, (v1, v2) -> v1)第一个参数
User::getName表示选择User对象的的getName方法获取的值作为map的key值;第二个参数
i -> i表示选择将原来的对象作为map的value值(这里的i只是对遍历对象取的别名)第三个参数
(v1, v2) -> v1,当出现key值相同时(也就是如果v1与v2的key值相同),选择前面的 也就是v1 作为那个key所对应的值,**就是出现相同key时,谁覆盖谁的问题 **
案例:
创建一个Javabean对象User
@Data
class User{
String name;
String description;
}
A. 使用Collectors.toMap(keyMapper, valueMapper)两个参数来将List转化为Map
//初始化一个User的List列表
List<User> list = new ArrayList<>(
Arrays.asList(
new User("strive", "努力"),
new User("fighter", "奋斗"),
new User("lucky", "幸运"),
)
);
//Collectors.toMap()方法,将List转化为Map集合
//Map<String, String> map = list.stream().collect(Collectors.toMap(item -> item.getName(), item -> item.getDescription()));
//简写为下面这种方式
Map<String, User> map = list.stream().collect(Collectors.toMap(User::getName, i -> i));
System.out.println(map);
运行结果:
{lucky=User{name=‘lucky’, description=‘幸运’}, strive=User{name=‘strive’, description=‘努力’}, fighter=User{name=‘fighter’, description=‘奋斗’}}
B. 如果出现key相同,但是没有设置第三个参数对其进行处理,就会报错 IllegalStateException:
//初始化一个User的List列表,里面有两个lucky
List<User> list = new ArrayList<>(
Arrays.asList(
new User("strive", "努力"),
new User("fighter", "奋斗"),
new User("lucky", "幸运"),
new User("lucky", "幸运222")
)
);
Map<String, User> map = list.stream().collect(Collectors.toMap(User::getName, i -> i));
System.out.println(map);
运行结果:
报错:java.lang.IllegalStateException: Duplicate key User{name=‘lucky’, description=‘幸运’}
因为按照User的name转换有两个相同的key值lucky,没有选择处理方式报错:
IllegalStateException
C. 设置第三个参数,解决出现相同key时,谁覆盖谁的问题
List<User> list = new ArrayList<>(
Arrays.asList(
new User("strive", "努力"),
new User("fighter", "奋斗"),
new User("lucky", "幸运"),
new User("lucky", "幸运222")
)
);
//设置当key相同的时候,保留前面的 【如果为 (v1,v2)->v2 就是用新的覆盖旧的】
Map<String, User> map = list.stream().collect(Collectors.toMap(User::getName, i -> i, (v1,v2) -> v1));
System.out.println(map);
运行结果:
{lucky=User{name=‘lucky’, description=‘幸运’}, strive=User{name=‘strive’, description=‘努力’}, fighter=User{name=‘fighter’, description=‘奋斗’}}
2.4.4 统计
count获取集合数量
List<String> stringList = Arrays.asList("a","b", "", "", "c", "", "a", "d","e","a");
//获取集合StringList的元素数量
//Collectors.counting()
stringList.stream().collect(Collectors.counting());
//简写为count()
stringList.stream().count();
//等价于集合的size方法
(long) stringList.size();
运行结果:
三种结果最终的效果相同
10
10
10
求平均值:averagingInt、averagingLong、averagingDouble
求最大/最小值:maxBy、minBy
统计求和:summingInt、summingLong、summingDouble
统计所有(包括计数、求和、最小、最大、平均):summarizingInt、summarizingLong、summarizingDouble
List<Integer> intList = Arrays.asList(2, 3, 10, 6, 8, 5, 2, 9);
// maxBy 求最大值 -- 等价于max
Optional<Integer> maxBy = intList.stream().collect(Collectors.maxBy(Integer::compareTo));
// minBy 求最大值 -- 等价于min
Optional<Integer> minBy = intList.stream().collect(Collectors.minBy(Integer::compareTo));
// averagingInt 求平均值
Double averagingInt = intList.stream().collect(Collectors.averagingInt(i -> i));
// 求和summingInt(需要求和的参数) -- 等价于 mapToInt
Integer summingInt = intList.stream().collect(Collectors.summingInt(i -> i));
//summarizingInt 统计数目、求和、最小值、平均值、最大值
IntSummaryStatistics summarizingInt = intList.stream().collect(Collectors.summarizingInt(i -> i));
System.out.println("maxBy = " + maxBy);
System.out.println("minBy = " + minBy);
System.out.println("averagingInt = " + averagingInt);
System.out.println("summingInt = " + summingInt);
System.out.println("summarizingInt = " + summarizingInt);
运行结果:
maxBy = Optional[10]
minBy = Optional[2]
averagingInt = 5.625
summingInt = 45
summarizingInt = IntSummaryStatistics{count=8, sum=45, min=2, average=5.625000, max=10}
2.4.5 分组
partitioningBy(分区):按照条件分为两个Map<Boolean, List>,一个是满足条件的Map和一个不满足条件的Map。
groupingBy(分组):类似于分区,但是是将集合按照条件分为多个Map,可以对进行分组之后的结果再分组
List<Integer> intList = Arrays.asList(2, 3, 10, 6, 8, 5, 2, 9);
//按 >5 分为两个区间
Map<Boolean, List<Integer>> partitioningBy = intList.stream().collect(Collectors.partitioningBy(i -> i > 5));
//按 >5 分为两组
Map<Boolean, List<Integer>> groupingBy = intList.stream().collect(Collectors.groupingBy(i -> i > 5));
//先按 >5 分为两组,然后再在前面分组满足条件的基础上对(满足条件的集合)再对 >8 进行分组
Map<Boolean, Map<Boolean, List<Integer>>> groupingBy2 = intList.stream().collect(Collectors.groupingBy(i -> i > 5, Collectors.groupingBy(i -> i > 8)));
System.out.println("分区partitioningBy = " + partitioningBy);
System.out.println("分组groupingBy = " + groupingBy);
System.out.println("两次分组groupingBy2 = " + groupingBy2);
运行结果:
分区partitioningBy = {false=[2, 3, 5, 2], true=[10, 6, 8, 9]}
分组groupingBy = {false=[2, 3, 5, 2], true=[10, 6, 8, 9]}
两次分组groupingBy2 = {false={false=[2, 3, 5, 2]}, true={false=[6, 8], true=[10, 9]}}
2.4.6 joining(连接)
joining(条件):可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个新的字符串。
List<String> stringList2 = Arrays.asList("a","b", " ", " ", "c", " ", "a", "d","e","a");
String joining = stringList2.stream().collect(Collectors.joining("-"));
System.out.println("joining = " + joining);
运行结果:
joining = a-b- – -c- -a-d-e-a
2.4.7 reducing (规约)
reducing(U identity, Function<? super T, ? extends U> mapper, BinaryOperator<U> op)
reducing:Collectors类提供的reducing方法,类似于stream本身的reduce方法,但是增加了对自定义归约的支持。
参数 BinaryOperator<T>: 这是一个函数式接口,是给两个相同类型的量,返回一个跟这两个量相同类型的一个结果,伪表达式为 (T,T) -> T。默认给了两个实现 maxBy 和 minBy ,根据比较器来比较大小并分别返回最大值或者最小值。当然你也可以灵活定制。然后 reducing 就很好理解了,元素两两之间进行比较根据策略淘汰一个,随着轮次的进行元素个数就是 reduce 的。
List<Integer> intList2 = Arrays.asList(1, 2, 3);
Integer reducing = intList2.stream().collect(Collectors.reducing(100, i -> i, (v1, v2) -> (v1 + v2 - 1)));
System.out.println("reducing = " + reducing);
运行结果:
reducing = 103
Stream提供的reduce方法也有类似的作用
// stream的reduce -- T reduce(T identity, BinaryOperator<T> accumulator);
//参1:(identity):求出结果之后再加该值
Optional<Integer> reduce = Optional.ofNullable(intList2.stream().reduce(100, Integer::sum));
System.out.println("reduce = " + reduce.get());
运行结果:
reduce = 106
Optional<Integer> reduce = Optional.ofNullable(intList2.stream().reduce(100, Integer::sum, (v1, v2) -> (v1 + v2 - 1)));
System.out.println("reduce = " + reduce.get());
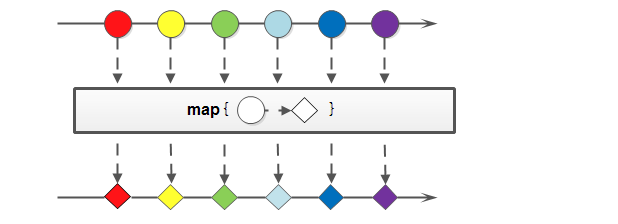
2.5 map、flatMap
map方法用于 映射每个元素到对应的结果,该函数会被应用到每个元素上,并将其映射成一个新的元素。
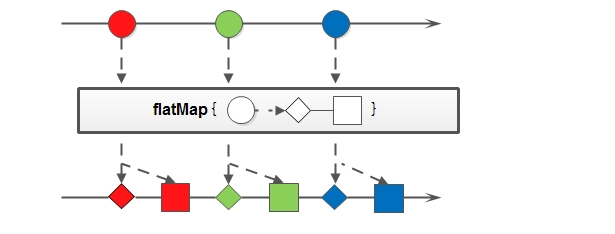
flatMap方法用于 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
//使用 map 输出stringList中元素对应的两倍并去重
List<String> doubleStr = stringList.stream().map(str -> str += str).distinct()
.collect(Collectors.toList());
System.out.print(doubleStr + " ");
运行结果:
[aa, bb, , cc, dd, ee]
//通过map获取userList列表中的User对象的name属性组成一个list列表
List<String> nameList = list.stream().map(user -> user.getName()).distinct()
.collect(Collectors.toList());
System.out.println(nameList);
运行结果:
[strive, fighter, lucky]
//flagMap转换为流后再转化为list列表输出
List<String> s = stringList.stream().flatMap(s -> {
//将每个元素按照分隔符,转换成一个stream
String[] split = s.split(",");
return Arrays.stream(split);
}).collect(Collectors.toList());
System.out.println(s);
运行结果:
[a, b, , , c, , a, d, e, a]
2.6 peek
peek 方法(消费),类似于map,能得到流中的每一个元素。但map接收的是一个Function表达式,有返回值;而peek接收的是Consumer表达式,是没有返回值的。
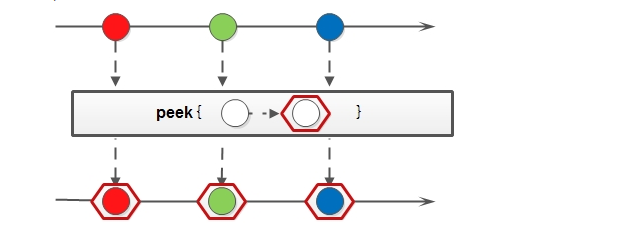
//peek消费,去重输出
stringList.stream().peek(i -> i += i).distinct().forEach(i-> System.out.print(i + " "));
输出结果:
a b c d e
2.7 limit
limit(n) 方法用于获取指定数量 (n个) 的流

Random random = new Random();
// 通过 limit 输出3个随机数
random.ints().limit(3).forEach(r ->{
System.out.print(r + " ");
});
运行结果:
1677393552 -608502510 2060923188
// 三个参数:random.ints(生成数量,最小值,最大值)
//生成10个1-100之间的随机数,再通过limit取出5个输出
random.ints(10,1,100).limit(5).forEach(r ->{
System.out.print(r + " ");
});
运行结果:
7 85 73 60 49
2.8 skip
skip(n) 方法用于跳过 (n个) 元素,配合 limit(n) 可实现分页
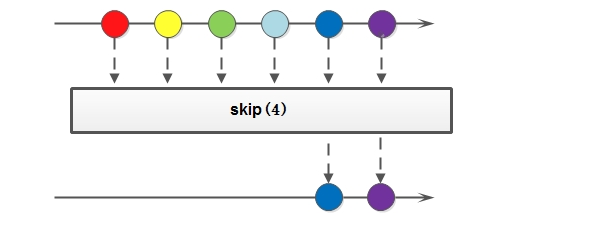
List<Integer> numbers = Arrays.asList(0, 9 ,6 , 5, 6, 3, 2, 1, 12, 5, 8, 3, 9, 3);
//过滤得到集合中>1的元素,然后去重,跳过前2个,然后取出5个
List<Integer> collect = numbers.stream().filter(i -> i > 1)
.distinct()
.skip(2)
.limit(5).collect(Collectors.toList());
System.out.println(collect);
运行结果:
[5, 3, 2, 12, 8]
2.9 sorted
sorted() 方法用于对流进行排序,这是自然排序,流中元素需实现Comparable接口。
sorted(Comparator com) : 带参数是定制排序,使用自定义的Comparator排序器进行排序
Random random = new Random();
//两个参数:random.ints(最小值,最大值)
//随机生成0-1000的随机数,通过limit取8个,然后排序输出
random.ints(0,1000)
.limit(8).sorted().forEach(i ->{
System.out.print(i + " ");
});
运行结果:
86 192 232 552 560 776 928 929
2.10 统计结果收集器
比如:getCount、getMax、getMin、getSum、getAverage等等用于统计结果的收集器,主要用于int、double、long等基本类型上
//定义一个int类型的集合
List<Integer> numbers = Arrays.asList(6, 2, 1, 2, 5, 8, 3, 9);
//通过mapToInt转化
IntSummaryStatistics intStatus = numbers.stream().mapToInt((i) -> i).summaryStatistics();
System.out.println("列表中元素数量:" + intStatus.getCount());
System.out.println("列表中最大数 : " + intStatus.getMax());
System.out.println("列表中最小数 : " + intStatus.getMin());
System.out.println("所有数之和 : " + intStatus.getSum());
System.out.println("平均值 : " + intStatus.getAverage());
运行结果:
列表中元素数量:8
列表中最大数 : 9
列表中最小数 : 1
所有数之和 : 36
平均值 : 4.5
2.11 流的终止操作
| 方法名称 | 描述 |
|---|---|
| count | 返回流中元素的总个数 |
| max | 返回流中元素最大值 |
| min | 返回流中元素最小值 |
| findFirst | 返回流中第一个元素 |
| findAny | 返回流中第一个元素(随机) |
| allMatch | 接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false |
| noneMatch | 接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false |
| anyMatch | 接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false |
List<Integer> intList = Arrays.asList(2, 3, 10, 6, 8, 5, 2, 9);
long count = intList.stream().count();// 等价于intList.size()
Integer max = intList.stream().max(Integer::compareTo).get();
Integer min = intList.stream().min(Integer::compareTo).get();
Integer findFirst = intList.stream().findFirst().get();
Integer findAny = intList.stream().findAny().get();
boolean allMatch = intList.stream().allMatch(i -> i > 1);
boolean noneMatch = intList.stream().noneMatch(i -> i > 1);
boolean anyMatch = intList.stream().anyMatch(i -> i > 5);
运行结果:
count = 8
max = 10
min = 2
findFirst = 2
findAny = 2
allMatch = true
noneMatch = false
anyMatch = true
3. 创建流的两种方式
| 创建流的方式 | 描述 |
|---|---|
| stream | 为集合创建串行流 |
| parallelStream | 为集合创建并行流 |
parallelStream里面的执行是异步的,并且使用的线程池是 ForkJoinPool.common,可以通过设置 -Djava.util.concurrent.ForkJoinPool.common.parallelism = N 来调整线程池的大小。可能提高你的多线程任务的速度。
List<Integer> intList = Arrays.asList(1, 2, 3, 4, 5, 6);
System.out.print("stream串行:");
intList.stream().forEach(System.out::print);
System.out.print("\nparallelStream并行:");
intList.parallelStream().forEach(System.out::print);
三次运行结果:
第一次运行:
stream串行:123456
parallelStream并行:456321第二次运行:
stream串行:123456
parallelStream并行:451623第三次运行:
stream串行:123456
parallelStream并行:465321
可以发现,Stream每次运行都是相同的结果,且是顺序输出的,但是parallelStream每次运行结果可能不同,顺序也是错乱的。
打印执行线程信息,查看是否是并行的
List<Integer> intList = Arrays.asList(1, 2, 3, 4, 5, 6);
intList.parallelStream().forEach(i -> System.out.println("线程 = " + Thread.currentThread().getName() +" : 输出 = " + i));
运行结果:
线程 = main : 输出 = 4
线程 = ForkJoinPool.commonPool-worker-2 : 输出 = 1
线程 = ForkJoinPool.commonPool-worker-2 : 输出 = 3
线程 = ForkJoinPool.commonPool-worker-2 : 输出 = 5
线程 = main : 输出 = 6
线程 = ForkJoinPool.commonPool-worker-9 : 输出 = 2
所以 parallelStream 是利用多线程并行执行的,通过 parallelStream 可以很大程度简化我们使用并发操作。
使用 parallelStream 是平行处理的,所以顺序每次都不一定一致,如果想要顺序是按照原来Stream的数据一样顺序输出,可以通过 forEachOrdered 方法实现。
List<Integer> intList = Arrays.asList(1, 2, 3, 4, 5, 6);
System.out.println("parallelStream并行使用forEachOrdered顺序输出:");
intList.parallelStream().forEachOrdered(System.out::print);
System.out.println();
intList.parallelStream().forEachOrdered(i -> System.out.println("线程 = " + Thread.currentThread().getName() +" : 输出 = " + i));
运行结果:
parallelStream并行使用forEachOrdered顺序输出:123456
线程 = ForkJoinPool.commonPool-worker-6 : 输出 = 1
线程 = ForkJoinPool.commonPool-worker-6 : 输出 = 2
线程 = ForkJoinPool.commonPool-worker-6 : 输出 = 3
线程 = ForkJoinPool.commonPool-worker-6 : 输出 = 4
线程 = ForkJoinPool.commonPool-worker-6 : 输出 = 5
线程 = ForkJoinPool.commonPool-worker-6 : 输出 = 6
所以调用 forEachOrdered 方法顺序执行的话,就不是多线程并行处理了,是一个线程进行处理。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189532.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
