大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
MySQL为何不选择平衡二叉树
既然平衡二叉树解决了普通二叉树的问题,那么mysql为何不选择平衡二叉树作为索引呢?
索引需要存储什么
让我们想一想,如果我们要把索引存起来,那么应该存哪些信息呢,它应该存储三块信息:
-
索引的值:就是表里面索引列对应的值。
-
数据的磁盘地址(通过磁盘地址找到当前数据)或者直接存储整条数据。
-
子节点的引用:我们需要从根节点往下走,所以需要知道左右子节点的地址。 根据这三点,可以有如下大致的一个简单的结构图:
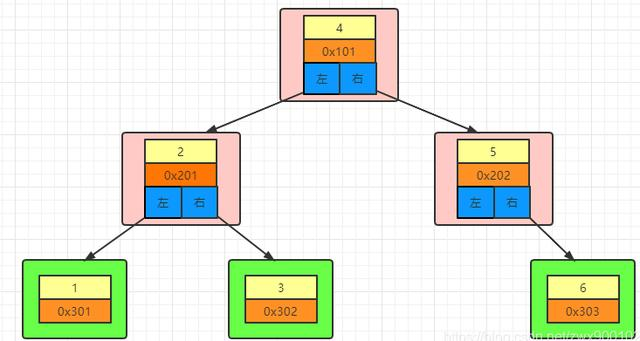

上图中数字表示的是索引的值,0x开头的表示磁盘地址,根节点中存了左右节点的引用。
AVL树用来存储索引存在什么问题
我们知道,页(Page)是 Innodb 存储引擎用于管理数据的最小磁盘单位,页的默认大小为16KB。页也就是上图中的节点,每查询一次节点就需要进行一次IO操作,IO操作是一种非常耗时的操作,很多业务系统的瓶颈都是卡在IO操作上,所以如果我们需要提高查询效率的办法之一就是减少IO次数,那么问题就来了,AVL树一个节点上只存了一个关键字(索引值)+一个磁盘地址+左右节点的引用,这是远远达不到16KB的,会浪费了大量的空间。
上图中如果我们要找到6这条数据,需要进行3次IO(获取一个节点就是一个IO操作),如果这棵树很高的话,就会进行大量的IO操作,所以说AVL树存在的最大问题就是空间利用不足,浪费了大量空间,数据量大的时候就会成为一颗瘦高的树,那么我们可以怎么改进呢?答案很明显了,那就是每个磁盘块多存一点东西,也就是说每个磁盘多存几个关键字,因为关键字越多,路数越多;路数越多,树也就越矮越胖,相应的操作IO次数就会越少。
多路平衡树(Balanced Tree)
多路平衡树简称B树,又称B-树,和AVL树一样,B树在枝节点和叶子节点存储键值、磁盘地址、左右节点引用。请看下图的一个多路平衡树的示例:
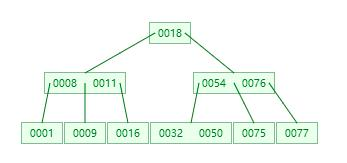
B树的特点
相比较AVL树,B树一个磁盘上可以存多个关键字(值),而且有一个特点就是:
- 分叉数(路数)永远比关键字数多1。 我们可以画出如下简图(下图中只画了3路,即两个关键字,实际取决于一页能存储多少个关键字):
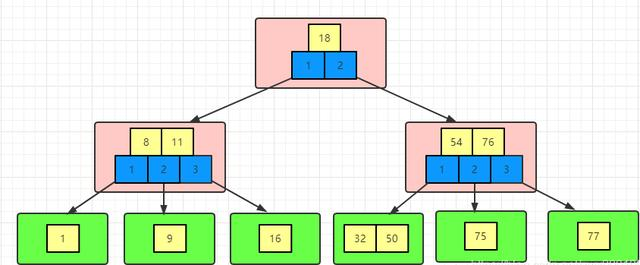
从上图可以很明显的看出,同样高度的树,B树能存的数据远远大于平衡二叉树。
B树是如何查找数据的
以上图为例,假如我们要找key=32这个数字,首先获取到根节点,发现18小于key,所以往右边走,获取到右边的数据,54和76,这时候遵循以下原则:
-
key<54,命中最左边分叉;
-
key=54,直接命中,返回数据;
-
54<key<76,走中间的一个分叉;
-
key=76,直接命中,返回数据;
-
key>76,命中右边分支; 这里因为key=32,所以走得是第1条,命中左边分支,这时候再去获取左边分支,获取到32和50,比较发现key=32,命中,返回数据。
从上面我们可以看出B树效率相对于AVL树,在数据量大的情况效率已经提高了很多,那么为什么MySQL还是不选择B树作为索引呢? 那么接下来让我们先看看改良版的B+树,然后再下结论吧!
B+树
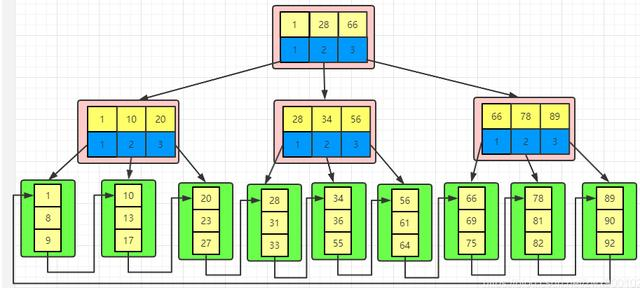
B+树由B树改良而来,属于改良版的多路平衡查找树。 首先让我们来看看B+树到底长什么样呢:
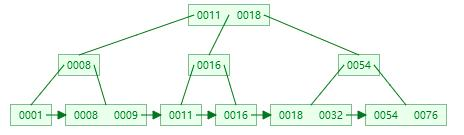
对比B+树,我们可以发现一个很明显的区别就是叶子节点有一个箭头指引而且从左到右是有序的。
InnoDB中使用的B+树相比较于传统B+树,改进之后的B+树具有以下特点
InnoDB中B+树的特点
-
它的关键字的数量是跟路数相等的。
-
B+树的根节点和枝节点中都不会存储数据,只有叶子节点才存储数据。而搜索到关键字不会直接返回,会到最后一层的叶子节点。
-
B+树的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,形成了一个有序链表的结构。
-
它是根据左闭右开的区间来检索数据的 按照B+树的特点,我们可以画出一个存储数据的简图,如下:
线程、数据库、算法、JVM、分布式、微服务、框架、Spring相关知识
一线互联网P7面试集锦+各种大厂面试集锦

学习笔记以及面试真题解析
08626)]
学习笔记以及面试真题解析
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189522.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
