大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
1. 综述
简介
全卷积网络(Fully Convolutional Networks,FCN)是Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation一文中提出的用于图像语义分割的一种框架,是深度学习用于语义分割领域的开山之作。FCN将传统CNN后面的全连接层换成了卷积层,这样网络的输出将是热力图而非类别;同时,为解决卷积和池化导致图像尺寸的变小,使用上采样方式对图像尺寸进行恢复。
核心思想
- 不含全连接层的全卷积网络,可适应任意尺寸输入;
- 反卷积层增大图像尺寸,输出精细结果;
- 结合不同深度层结果的跳级结构,确保鲁棒性和精确性。

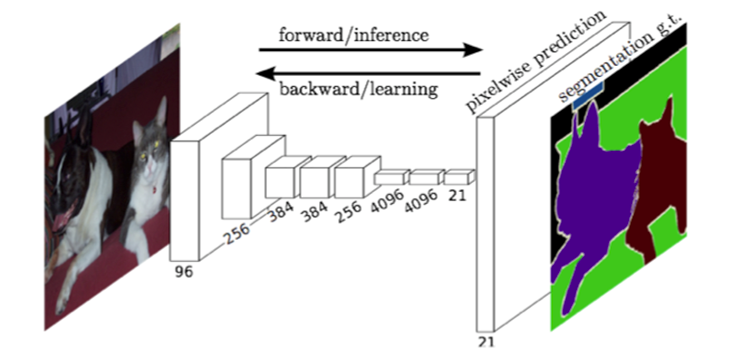
2. FCN网络
2.1 网络结构
FCN网络结构主要分为两个部分:全卷积部分和反卷积部分。其中全卷积部分为一些经典的CNN网络(如VGG,ResNet等),用于提取特征;反卷积部分则是通过上采样得到原尺寸的语义分割图像。FCN的输入可以为任意尺寸的彩色图像,输出与输入尺寸相同,通道数为n(目标类别数)+1(背景)。FCN网络结构如下:

2.2 上采样 Upsampling
在卷积过程的卷积操作和池化操作会使得特征图的尺寸变小,为得到原图像大小的稠密像素预测,需要对得到的特征图进行上采样操作。可通过双线性插值(Bilinear)实现上采样,且双线性插值易于通过固定卷积核的转置卷积(transposed convolution)实现,转置卷积即为反卷积(deconvolution)。在论文中,作者并没有固定卷积核,而是让卷积核变成可学习的参数。转置卷积操作过程如下:

2.3 跳级结构
如果仅对最后一层的特征图进行上采样得到原图大小的分割,最终的分割效果往往并不理想。因为最后一层的特征图太小,这意味着过多细节的丢失。因此,通过跳级结构将最后一层的预测(富有全局信息)和更浅层(富有局部信息)的预测结合起来,在遵守全局预测的同时进行局部预测。
将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到原尺寸的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。图示如下:

3 FCN训练
- 阶段1:以经典的分类网络为初始化,最后两级为全连接(红色),参数弃去不用。

- 阶段2:FCN-32s 网络—从特征小图预测分割小图,之后直接升采样为大图。

- 阶段3:FCN-16s 网络—上采样分为两次完成。在第二次升采样前,把第4个pooling层的预测结果融合进来,使用跳级结构提升精确性。

- 阶段4:FCN-8s 网络—升采样分为三次完成。 进一步融合了第3个pooling层的预测结果。

4. 其它
4.1 FCN与CNN
CNN的强大之处在于它的多层结构能自动学习特征,可学习到多个层次的特征:
- 较浅的卷积层感知域较小,学习到一些局部区域的特征;
- 较深的卷积层感知域较大,学习到更加抽象一些的特征;
抽象特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。但抽象特征对物体的大小、位置和方向等敏感性低,因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此难以做到精确的分割。而FCN是从抽象的特征中恢复出每个像素所属的类别,即从图像级别的分类进一步延伸到像素级别的分类。
4.2 FCN的不足
- 得到的结果还不够精细,对细节不够敏感;
- 未考虑像素与像素之间的关系,缺乏空间一致性等。
4.3 答疑
- 为什么说如果一个神经网络里面只有卷积层,那么输入的图像大小是可以任意的。但是如果神经网络里不仅仅只有卷积层,还有全连接层,那么输入的图像的大小必须是固定的?
- 卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系。图像进行卷积时,因为每一个卷积核中的权值都是共享的,因此无论输入图像的尺寸多大,都可以按步长滑动做卷积,不同之处在于经过卷积运算,不同大小的输入图片所提取出的卷积特征的大小是不同的。
- 全连接层的参数与输入图像大小有关,因为它要把输入图像的所有像素点连接起来。在含有全连接层的神经网络中,假设输入的图像大小一样,那经过卷积得到特征的尺寸也都是相同的。如输入特征尺寸为 a × b a×b a×b,之后连接一个 1 × c 1×c 1×c 的全连接层,那么卷积层的输出与全连接层间的权值矩阵大小为 ( a × b ) × c (a×b)×c (a×b)×c。但如果输入与原图像大小不同,得到新的卷积输出为 a ′ × b ′ a’×b’ a′×b′。与之对应,卷积层的输出与全连接层间的权值矩阵大小应为 ( a ′ × b ′ ) × c (a’×b’)×c (a′×b′)×c。很明显,权值矩阵大小发生了变化,故而也就无法使用和训练了。
【参考】
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189458.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
