大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、前言
Summary:本章介绍为什么要学习源码并分享个人学习感悟,想看干货的朋友可以直奔三四章~


- 框架架构师体验卡!
相信很多朋友和我一样,本身从事开发工作已久,期间也应用Spring全家桶开发了无数优秀的JavaEE项目,却一直对底层原理不甚了解,框架到底帮我们配置了什么?底层如何封装?应用了哪些设计模式?今天,就让我们当一回框架架构师,以SpringBoot框架为例探究框架源码与执行流程!
- 何谓框架的框架?
所谓“框架”就是可被应用开发者定制的应用骨架,是整个或部分系统的可重用设计。(把百度关掉,说人话!)简言之,框架就是底层封装好大量核心代码的程序,使开发者可以在其上继续开发自己所需的业务,避免重复造轮子嘛。为什么要使用框架?因为框架可以有效提升开发效率、程序的健壮性、服务性能、后续功能的可维护、可扩展性等。实际上很多公司都在创建或使用自己的框架,阿里等互联网巨头公司也都有许多开源的框架。
那么什么是“框架的框架”?一个框架往往可以用来开发一种服务,实现一项业务功能,但一个完整的项目是包含多个服务多个业务功能的,实际开发中我们往往需要用到多个框架,从而产生了一个“框架整合”的问题!框架整合其实是一个很折磨的过程…你并不知道整合过程中各个框架之间是否会产生不兼容性或依赖冲突,即便兼容你也要为每个框架都能正常运行做无数的配置工作,就连Spring原生框架之间的SSM整合都需要较多步骤,其他框架整合可想而知。因此,SpringBoot应运而生,它就是“框架的框架”,专门负责解决“框架整合”问题的,通过依赖管理、场景启动器、自动配置等方式实现,其核心思想就是“约定大于配置”,通过约定好的默认配置取代手动配置,简化框架整合流程。
- 封装过深的代价?
原生JavaWeb开发——>Spring横空出世——>SSM整合——>SpringBoot全自动~
技术演进的过程中,开发人员需要写的重复冗余的代码越来越少,配置过程也越来越简化,但是这种便捷是有“代价”的。实现同样的功能,并不是代码总量减少了,而是框架底层帮我们写好了大量的代码,做好了无数的配置。众所周知,“力量是要付出代价的!” “封装过深“也有代价:
① 对业务逻辑的每一个细节不如以前熟悉了
② 难以精通理解底层配置原理
③ 调试与检错难度直线上升
不过不用担心!我们作为框架的使用者、“资深”从业者、互联网时代的建造者!(逐渐离谱….)我们要真正“掌握雷电”,而不是成为“锤子之神”~这些“代价”都是可以优化甚至彻底解决的。我们通过深入学习框架源码,理解其封装过程,就能成为真正掌握框架的开发者,而不是被框架所限制!
- 先验知识
想要完全掌握SpringBoot2的源码需要很扎实的编程基础和深入的设计思想,坦白说着手写这篇博客的我也没有足够深厚的底蕴精通SpringBoot2的源码,只是将自己掌握的部分以流程图和文字详解的方式分享给大家。总体来讲,无论是想通过本文学习SpringBoot源码还是想深入理解设计原理,都应该具备以下基础的先验知识储备:
① 了解原生Web开发流程,熟悉Servlet、HTTP请求响应格式、Session等域对象
② 熟悉Spring基础框架,包括IOC、AOP原理,Bean对象生命周期等
③ 熟悉SpringMVC框架,包括DispatcherServle请求分发原理、ModelAndMap模型、拦截器原理等
④ 理解常见设计模式,如适配器模式、装饰器模式、代理模式、责任链模式等
掌握了以上知识,才能流畅的进行SpringBoot源码学习并避免遇到理解上的障碍,同样在讲解过程中我也会穿插各种设计模式,加深大家对源码中设计思想的理解。
- 感想&交流
“程序员是最乐于分享的团体”。首先声明,本文创作的内容基本源于个人理解,并非照搬其他博客,原理图和执行流程也都是自己分析并创作的,付出了一定的心血~写作过程中当然也借鉴了多方资料,包括视频教程、博客论坛、官方文档,这些资料在文末“参考资料”章节中都有展示,分享给大家一起学习。
这是我第一次提笔写文,目前在读研并有过一些中大型企业项目开发经历,可能还只能算作半个从业者吧(因为没毕业嘛),因此创作过程中心情是非常忐忑不安的,写下的内容都会反复理解检查几遍,生怕误人子弟。不过话说回来,我一届学生,凭借自己的学习理解去解析时下最热门的开发框架底层源码,可能难免会有纰漏与错误,如果各路大神在本文中看到任何理解不当或有误的内容,请及时指正,感谢大家的包容与指导!如果有想与我交流的朋友可以留言或私信,希望与大家共同进步! 早日成为人均架构师(笑)
Summary:本章以时代需求为背景介绍了技术演进过程,时代的需求与技术背景正是SpringBoot2升级的原因,从而让读者更好的理解SpringBoot2在这些新需求和新技术下衍生的新特性
二、SpringBoot2应用背景与技术升级
1.简介&生态

Spring Boot是Pivotal团队在Spring的基础上提供的一套全新的开源框架,其目的是为了简化Spring应用的搭建和开发过程。Spring Boot去除了大量的XML配置文件,简化了复杂的依赖管理,它具有Spring一切优秀特性且使用更简单、功能更丰富,性能更稳定更健壮。此外Spring Boot集成了大量常用的第三方库配置,Spring Boot应用中这些第三方库几乎可以是零配置的开箱即用(out-of-the-box),大部分的 Spring Boot应用都只需要非常少量的配置代码(基于Java的配置),开发者能够更加专注于业务逻辑。 其具体优势可概括为以下几点:
- 独立运行的 Spring 项目
Spring Boot 可以以jar包的形式独立运行,Spring Boot项目只需通过命令“ java–jar xx.jar” 即可运行。- 内嵌 Servlet 容器
Spring Boot 使用嵌入式的 Servlet 容器(例如Tomcat、Jetty 或者Undertow等),应用无需打成WAR包 。- 提供 starter 简化Maven配置
Spring Boot 提供了一系列的“starter”项目对象模型(POMS)来简化 Maven 配置。- 提供了大量的自动配置
Spring Boot 提供了大量的默认自动配置,来简化项目的开发,开发人员也通过配置文件修改默认配置。- 自带应用监控
Spring Boot可以对正在运行的项目提供监控。- 无代码生成和 xml 配置
Spring Boot不需要任何xml配置即可实现Spring的所有配置
虽然我们常使用SpringBoot来做Web开发,但实际上SpringBoot打造的功能生态非常丰富,包括:
- web开发
- 数据访问
- 安全控制
- 分布式
- 消息服务
- 移动开发
- 批处理
这些功能可不是我编的~是Spring官方网站首页上摆着的:

Spring功能图
更多特性与功能请参考:官方文档-OverView
2.时代背景
“时势造英雄”——SpringBoot成为时下最热门框架的背后,实际上是时代背景所驱,其框架设计之初就考虑到了当下开发中的痛点与难点,并提出了解决方案,从而被广泛应用于高性能服务端程序开发。下面让我们看看当下开发所面临的时代背景与解决方案。
2.1 大数据-背景
大数据时代是一个早已泛滥的词,在我的理解里,对于我们开发者或从业者来说大数据包含两个层面的意思:数据量大、并发量高,特点可概括为“5V”+“3高”。数据量大描述的是需要存储的数据内容和特点,并发量高是伴随用户增多而出现的现象,通常人们说的大数据主要指第一层意思即数据量大,其特点是5V。

大数据5V特点
- 数据量大(Volume)
第一个特征是数据量大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。 - 类型繁多(Variety)
第二个特征是数据类型繁多。包括网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。 - 价值密度低(Value)
第三个特征是数据价值密度相对较低。如随着物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何通过强大的机器算法更迅速地完成数据的价值“提纯”,是大数据时代亟待解决的难题。 - 速度快、时效高(Velocity)
第四个特征是处理速度快,时效性要求高。这是大数据区分于传统数据挖掘最显著的特征。 - 真实(Veracity)
大数据中的内容是与真实世界中的发生息息相关的,要保证数据的准确性和可信赖度。研究大数据就是从庞大的网络数据中提取出能够解释和预测现实事件的过程。
原先既有的技术架构和路线,已经无法高效处理如此海量的数据,而对于相关组织来说,如果投入巨大采集的信息无法通过及时处理反馈有效信息,那将是得不偿失的。SpringBoot框架中可以通过原生和集成第三方技术来处理海量数据。
参考: 大数据5V特点-CSDN
2.2 微服务-架构
微服务是一种开发软件的架构和组织方法,其中软件由通过明确定义的 API 进行通信的小型独立服务组成。这些服务由各个小型独立团队负责。
实际上,微服务的产生是为了应对微服务架构使应用程序更易于扩展和更快地开发,也是适应大数据时代的软件开发架构,从而实现加速创新并缩短新功能的上市时间。
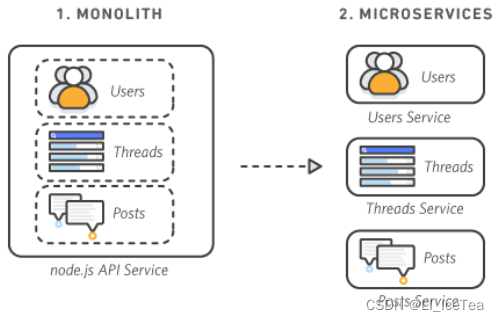
微服务示意图
微服务概念最早是Martin Fowler于2014年的一篇文章《Microservices – the new architectural style》中提出的,其主要特点包括:
- 微服务是一种架构风格
- 一个应用拆分为一组小型服务
- 每个服务运行在自己的进程内,也就是可独立部署和升级
- 服务之间使用轻量级HTTP交互
- 服务围绕业务功能拆分
- 可以由全自动部署机制独立部署
- 去中心化,服务自治。服务可以使用不同的语言、不同的存储技术
原文链接:MartinFowler网站——Microservices Guide
2.3 分布式-系统
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。
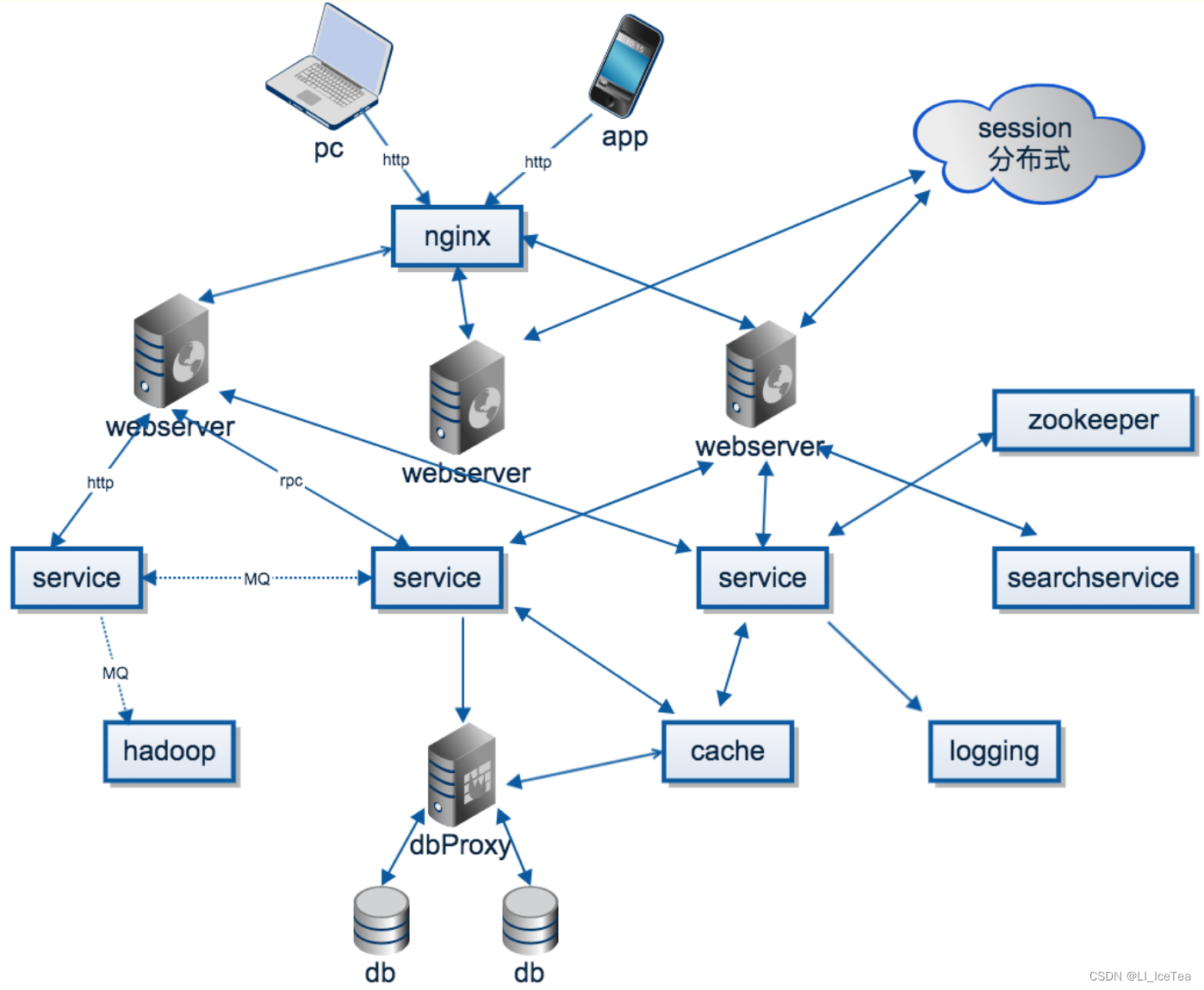
分布式系统示意图
分布式系统本质上有两个目的,一是增强系统实时处理所需的算力,二是扩展系统数据存储的容量。但随之而来的,是系统结构复杂化导致的诸多问题与解决方案,包括以下几点(注解了自己对该问题和解决方案的理解):
● 远程调用:RPC,通过NIO方式处理封装调用方法参数的数据并相应执行结果
● 服务发现:使用一个注册中心来记录分布式系统中的全部服务的信息,以便其他服务能够快速的找到这些已注册的服务
● 负载均衡:通过轮询或Nginx等服务器策略分配请求降低单服务器QPS负载压力
● 服务容错:当发生网络异常或代码异常时,服务的返回结果和逻辑处理机制
● 配置管理:统一管理部署在多台服务器上的某服务的配置
● 服务监控:通过心跳等机制监控服务是否存活(网络及CPU内存等运行状态)
● 链路追踪:还原分布式服务调用过程的链路
● 日志管理:针对海量日志使用流处理,涉及Flink、kafka等大数据框架
● 任务调度:求解多任务多站点下执行时间最小化问题
以上是我自己对这些概念的简单解释,若想深度理解分布式系统可参考博客: 分布式系统概念详解及学习方法
2.4 云原生-构建
正是由于分布式应用系统使结构复杂化,才会面临以上诸多问题,解决方案也相应的较为繁琐,因此衍生了服务上云的需求。而Spring也提出了相应的框架来响应这一需求,即SpringBoot + SpringCloud。说白了,就是分布式系统服务上云,以便更加便捷的构建和管理结构复杂的高性能服务器应用。
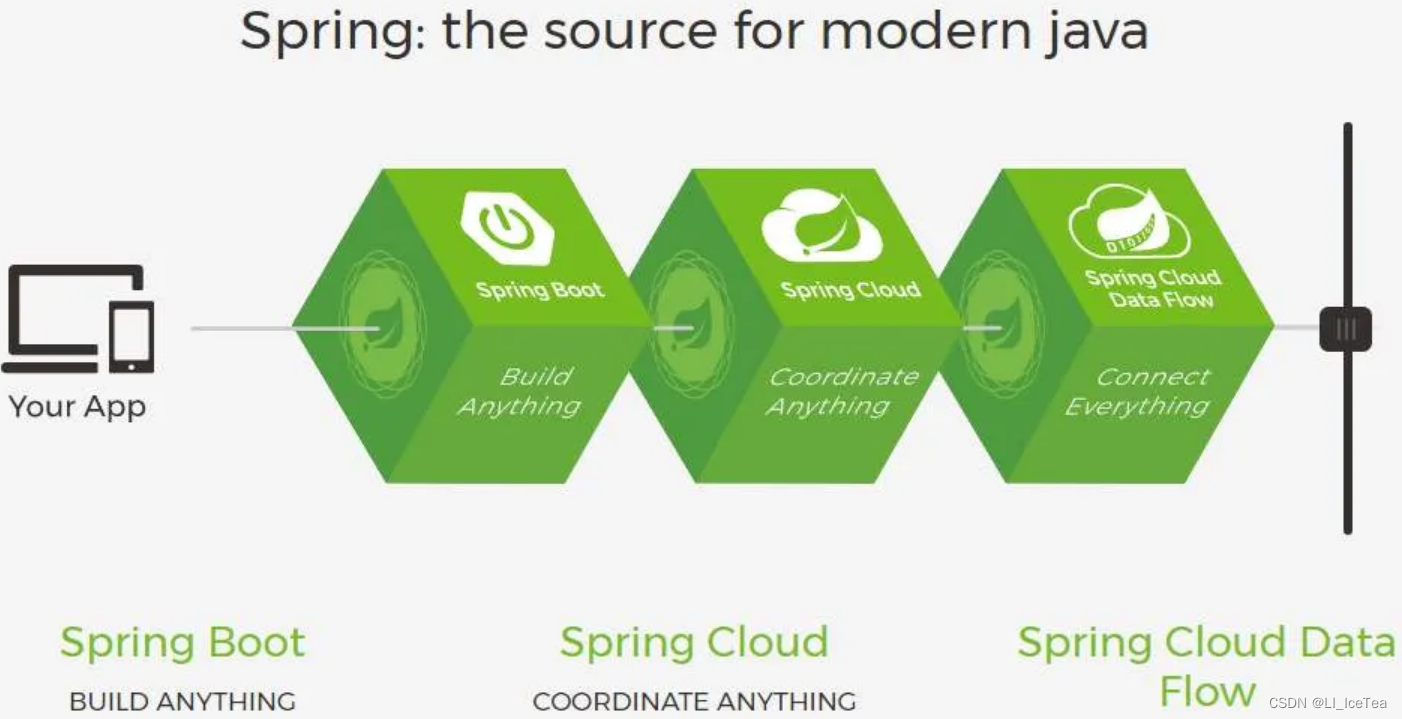
Spring云原生方案
云原生是一种构建和运行应用程序的方法,是一套技术体系和方法论。云原生(CloudNative)是一个组合词,Cloud+Native。Cloud表示应用程序位于云中,而不是传统的数据中心;Native表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性+分布式优势。

云原生概念图
3.技术升级
2018 年 3 月 1 号 Spring Boot 2.0.0.RELEASE 正式发布。众所周知,SpringBoot号称“版本帝”,小版本更新时都会不断更新新功能和底层源码实现,这次2.0大版本究竟更新了什么呢?
3.1 基础环境升级
- JDK版本升级
最低 JDK 8,支持 JDK 9,不再支持 Java 6 和 7。
这是因为SpringBoot2内部源码设计是基于JDK8的很多新特性的,包括:接口方法的默认实现、函数回调以及一些新的 API(如 javax.time)等。 - 第三方依赖组件升级
主要包括以下组件版本:Jetty 9.4、Tomcat 8.5、Hibernate 5.2、Gradle 3.4、Thymeleaf 3.0、Flyway 5等
3.2 默认软件替换和优化
-
数据库连接池
默认连接池已从 Tomcat 切换到 HikariCP。
HikariCP 是一个高性能的 JDBC 连接池,号称是 Java 业界最快的数据库连接池,官网提供了 c3p0、dbcp2、tomcat、vibur 和 Hikari 等数据连接池的性能对比。 -
Spring Security
作为原生的Security推荐组件,SpringBoot2中对其进行了更好的集成优化。在Spring Boot 2.0中极大地简化了默认的安全配置,并使添加定制安全变得简单。 -
OAuth 2.0
OAuth 2.0 是 OAuth 协议的延续版本,但不向后兼容 OAuth 1.0,它可以使第三方应用程序或客户端获得对 HTTP 服务上(如 Google、GitHub )用户帐户信息的有限访问权限。
Spring Boot 2.0 将 Spring Security OAuth 项目迁移到 Spring Security。不再提供单独的依赖包,Spring Boot 2.0 通过Spring Security 5提供OAuth 2.0客户端支持。 -
Micrometer
Micrometer 是一款监控指标的度量类库,可以让你在没有供应商锁定的情况下对 JVM 的应用程序代码进行调整。
Spring Boot 2.0 增强了对 Micrometer 的集成,不再提供自己的指标API。依靠 micrometer.io 来满足所有应用程序监视需求。 -
Redis默认使用Lettuce
替代了前的 Jedis 作为底层的 Redis 连接方式。Lettuce 是一个可伸缩的线程安全的 Redis 客户端,用于同步、异步和反应使用。多个线程可以共享同一个 RedisConnection,它利用优秀 Netty NIO框架来高效地管理多个连接,支持先进的 Redis 功能,如 Sentinel、集群、流水线、自动重新连接和 Redis 数据模型。 -
配置属性绑定
修复了部分绑定规则的错误漏洞,并提供了YMAL格式的配置文件绑定。
在Spring Boot 2.0中,使用 @ConfigurationProperties 的绑定机制被重新设计,限制了绑定规则,并修复了 Spring Boot 1.x 中的许多不一致的地方。 -
转换器支持
转换器实现类的源码改进。
Binding使用了一个新的 ApplicationConversionService 类,它提供了一些额外有用的转化。包括转换器的Duration类型和分隔字符串等。
该 Duration转换器允许在任一 ISO-8601 格式的持续时间,或是一个简单的字符串(如 10m,10 分钟)。现有的属性已更改为默认使用 Duration,@DurationUnit 注释通过设置如果没有指定所使用的单元确保向后兼容性。 -
Actuator 改进
在 Spring Boot 2.0 中 Actuator endpoints 有很大的改进,所有 HTTP Actuator endpoints 现在都在该 /actuator 路径下公开,并且生成的 JSON 有效负载得到了改进。
3.3 新技术的引入
- 支持HTTP/2
HTTP2.0版本相比1.x版本引入了很多新特性,包括:新的二进制格式(Binary Format)、多路复用(MultiPlexing)、header压缩、服务端推送(server push)、优先级数据流响应等。 - Kotlin 的支持
Spring Boot 2.0 现在包含对 Kotlin 1.2.x 的支持,并提供了runApplication,一个使用 Kotlin 运行 Spring Boot 应用程序的方法。我们还公开和利用了Kotlin对其他 Spring项目(如Spring Framework,Spring Data和Reactor)已添加到其最近版本中的支持。 - 响应式编程WebFlux
响应式编程是一种面向数据流和变化传播的编程范式,可以更方便地表达静态或动态的数据流,而相关的计算模型会自动将变化的值通过数据流进行传播。
WebFlux 模块的名称是 spring-webflux,名称中的 Flux 来源于 Reactor 中的类 Flux。Spring WebFlux 有一个全新的非堵塞的函数式 Reactive Web 框架,可以用来构建异步的、非堵塞的、事件驱动的服务,在伸缩性方面表现非常好。
Summary:本章是SpringBoot核心功能的源码解析和原理讲解
三、SpringBoot功能源码&原理图解
可能有些朋友会有疑问,为什么SpringBoot的源码解析会分为SpringBoot功能的源码和SpringMVC的功能源码呢?实际上,在前言章节中我们说了SpringBoot是框架的框架,其本身的功能只是解决“框架整合”的问题,至于其他开发中的核心业务流程依然是SpringMVC来实现的,因此我们分为两章介绍。
1.依赖管理原理
SpringBoot和Spring都是依赖于Maven使用依赖管理的,在Maven中使用groupId,artifactId,version组成的Coordination(坐标)唯一标识一个依赖,通过配置文件中的远程仓库地址下载(只需下载一次后就保存到本地仓库)。SpringBoot在Maven的依赖管理基础上又做了进一步优化,主要包括:通过版本仲裁机制自动控制依赖版本、通过场景启动器批量引入依赖jar包。
1.1版本仲裁机制
我们先来看看什么是版本仲裁机制。如果大家仔细观察过SpringBoot的POM.xml文件,会发现里面的很多依赖是没有写版本号的!
<!-- SpringBoot POM.xml中的依赖 -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
根据Maven规则,坐标必须由groupId,artifactId,version才能唯一确定,那为什么SpringBoot中可以省略版本呢?省略后我们又怎么知道项目中引入的redis、mybatis和lombok版本的呢?这就是Springboot中的版本仲裁机制。
原理解析:
为什么Spring Boot导入dependency时不需要指定版本?首先,在POM.xml文件的顶层声明了一个父容器,该项目下的所有模块默认继承父容器中的依赖配置。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.7</version>
</parent>
tip: 按Ctrl+左键单击查看源文件/源码
这个父容器中添加的spring-boot-starter-parent依赖是什么呢?我们可以查看其底层源文件,发现该依赖又有一个顶层父容器依赖:spring-boot-dependencies
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.6.7</version>
</parent>
这就是版本自动控制的根源所在了,查看spring-boot-dependencies的源文件如下:
<!-- 以property属性标签的方式写死了常用组件的版本 -->
<properties>
<activemq.version>5.16.4</activemq.version>
<antlr2.version>2.7.7</antlr2.version>
<appengine-sdk.version>1.9.96</appengine-sdk.version>
<artemis.version>2.19.1</artemis.version>
……
<spring-amqp.version>2.4.4</spring-amqp.version>
<spring-batch.version>4.3.5</spring-batch.version>
<spring-framework.version>5.3.19</spring-framework.version>
<spring-kafka.version>2.8.5</spring-kafka.version>
……
</properties>
<!-- 在依赖坐标的version中引入了属性标签 -->
<dependencies>
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-amqp</artifactId>
<version>${activemq.version}</version>
</dependency>
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-blueprint</artifactId>
<version>${activemq.version}</version>
</dependency>
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-broker</artifactId>
<version>${activemq.version}</version>
</dependency>
……
</dependencies>
其配置文件中,通过properties属性的方式写死了所有常用组件的版本号,而其底层依赖dependency中的在坐标的version中引入了上面写死的properties属性标签,从而唯一控制了所有常用组件的版本号。这就是版本仲裁的根本原理。
假设对版本仲裁的结果不满意如何修改呢?只需要在POM.xml中通过标签指定对应的依赖版本即可,原理就是根据Maven依赖的就近原则,加载时会优先使用我们声明的属性标签决定依赖版本。例如修改mysql的版本:
<properties>
<mysql.version>5.1.43</mysql.version>
</properties>
原理图:

版本仲裁机制原理图解
1.2场景启动器(Starter)
概念:
Starter被称为场景启动器,它能将模块/项目所需的依赖整合起来并对模块内的Bean根据环境进行自动配置。开发者只需要引入相应开发场景的Starter,其内就会包含该场景所需的依赖及配置,Spring Boot也会自动扫描并加载Starter下的所有依赖。因此其实际功能总结如下:
①整合引入对应场景需要的依赖库;
②提供对模块的配置项给使用者、提供配置项的默认值(类似版本仲裁机制),使用者不指定配置时使用默认值,也可根据需要指定配置项的值(xxxProperties);
③提供自动配置类(xxxAutoConfiguration)对模块内的Bean进行自动装配
命名:
| 官方启动器 | 第三方启动器 | |
|---|---|---|
| 前/后缀 | spring-boot-starter- | -spring-boot-starter |
| 模式 | spring-boot-starter-模块名 | 模块名-spring-boot-starter |
| 举例 | spring-boot-starter-web、spring-boot-starter-jdbc | mybatis-spring-boot-starter |
原理解析:
我们以spring-boot-starter-web为例,即通过web开发场景启动器讲解一下场景启动器的基本原理。首先还是打开spring-boot-starter-web源文件:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>2.6.7</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-json</artifactId>
<version>2.6.7</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<version>2.6.7</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>5.3.19</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.3.19</version>
<scope>compile</scope>
</dependency>
</dependencies>
可以看到Web场景启动器中引入了很多新的启动器,这些启动器底层就是响应的依赖,包括json、tomcat、Spring-web和webmvc等,即包含几乎所有Web开发场景下所需的依赖,并管理了其版本和作用范围。因此,我们只需在POM.xml中引入对应场景的启动器,就可以轻松进行该场景下的开发工作,而不用关心其底层依赖。
值得关注的是,当你点开任意一个Starter(官方发布的原生starter)会发现其内都依赖spring-boot-starter,即部分场景启动器依赖于底层启动器,如spring-boot-starter,我们可以称其为“底层场景启动器”,如果我们查看Spring-boot-starter源文件:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot</artifactId>
<version>2.6.7</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
<version>2.6.7</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
<version>2.6.7</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>jakarta.annotation</groupId>
<artifactId>jakarta.annotation-api</artifactId>
<version>1.3.5</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.3.19</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.29</version>
<scope>compile</scope>
</dependency>
</dependencies>
原来,web场景启动器的底层依赖spring-boot-starter中声明了开发所需的必要依赖,包括spring-core核心代码、yaml支持、注解API、自动配置等。那么具体哪些启动器依赖于更底层的启动器呢?我们可以通过Maven打印依赖树的方式查看,如图所示:
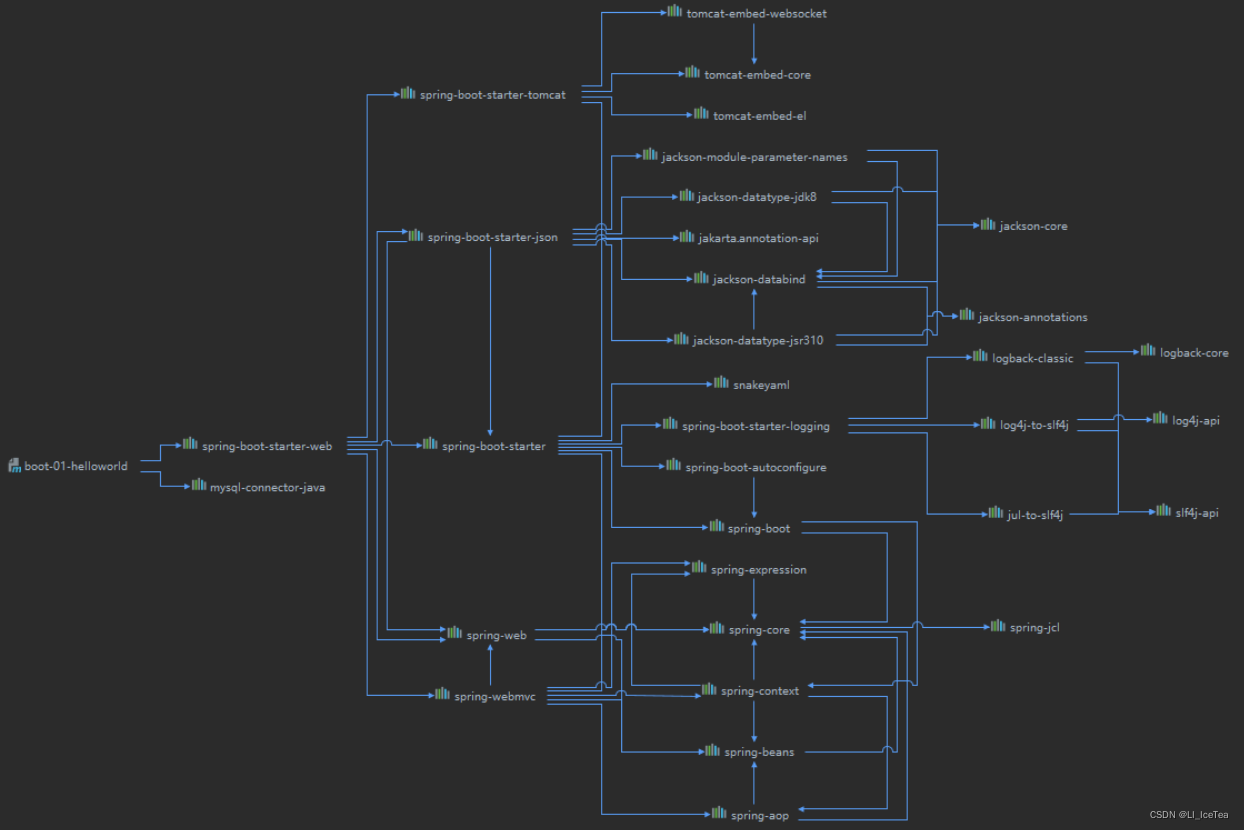
原理图:

场景启动器原理图
更多可用的场景启动器,请参考: 官方文档:所有支持的场景启动器
2.自动配置原理
任何一个组件或依赖想要生效都分为两步:首先引入jar包,之后需要对引入的组件进行配置。上文介绍的依赖管理实现的其实就是引入并管理jar包,这一小结我们讲一讲SpringBoot为我们提供的自动配置功能。
2.1 默认扫描包结构
首先要介绍的是默认扫描的包结构。在以往的SSM框架中我们需要在web.xml中配置DispatcherServlet等组件,同时在SpringMVC.xml中配置组件扫描的包结构。而在SpringBoot中,会默认扫描主程序所在的包及其下面的所有子包中的组件,官方文档中的默认扫描包结构示意图如下图所示

官方提供的默认包结构示意图
主程序即配置了 @SpringBootApplication注解的类,如果想要修改默认扫描的包结构,有两种方式:
①@SpringBootApplication(scanBasePackages=“指定包路径”)
②@ComponentScan (“指定包路径”)
需要注意的是@SpringBootApplication是一个合成注解,其内包含三个注解:@SpringBootConfiguration@EnableAutoConfiguration@ComponentScan(“默认包路径”)因为@ComponentScan是一个不可重复的注解,因此无法在主程序类上注释@ComponentScan。
原理解析:
默认扫描包结构的原理涉及到合成注解中的@EnableAutoConfiguration注解的底层注解 @AutoConfigurationPackage,其内指定了对MainApplication主程序所在包及其子包下的所有组件进行扫描并注册到容器中,具体源码可查看2.2小结中的详细解释。
2.2 自动配置类
可以想到,SpringBoot之所以能实现自动配置常用组件的功能,一定是在容器启动前就自动加载了常用组件,如DispatcherServlet、viewResolver、characterEncodingFilter等,具体加载了哪些组件可以通过如下代码查看:
//返回IOC容器
ConfigurableApplicationContext run = SpringApplication.run(Boot01Helloworld2Application.class, args);
//查看IOC容器内所有组件
String[] names = run.getBeanDefinitionNames();
for (String name : names) {
System.out.println(name);
}
下面我们来解析一下,SpringBoot是如何在容器启动时自动将这些组件加载到IOC容器中的。
原理解析:
在SpringBoot的启动类上有一个@SpringBootApplication注解,上文说过这是一个合成注解@SpringBootConfiguration@EnableAutoConfiguration@ComponentScan,我们依次查看每一个注解。
- @SpringBootConfiguration
首先依次点击查看@SpringBootApplication注解的源码,再查看其内的@SpringBootConfiguration源码如下:
@Target({
ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration //代表这是一个配置类!
@Indexed
public @interface SpringBootConfiguration {
@AliasFor(
annotation = Configuration.class
)
boolean proxyBeanMethods() default true;
}
可以看到该注解上标注了一个@Configuration注解,代表这是一个配置类。说明主程序也是一个配置类,并且是SpringBoot核心配置类。
-
@ComponentScan
简单说明一下@ComponentScan,该注解的作用就是指定包扫描路径,其底层是通过TypeExcludeFilter和AutoConfigurationExcludeFilter两个过滤器实现具体包扫描规则的。 -
@EnableAutoConfiguration
主程序既然是核心配置类,具体配置了什么内容呢?查看第二个注解,见名知意,该注解是指激活自动配置,查看源代码发现它也是两个注解的合成注解:
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
}
① @AutoConfigurationPackage
见名知意,自动配置包,即指定了默认的包规则。查看该注解源码:
@Import(AutoConfigurationPackages.Registrar.class) //给容器中导入一个组件
public @interface AutoConfigurationPackage {
}
//利用Registrar给容器中导入一系列组件
//哪一系列组件?其实是将指定的一个包下的所有组件导入进来,哪个包?MainApplication
//(即@SpringbootApplication组件标注的类)所在包下。
首先通过@Import注解,利用Registrar类给容器中批量导入一系列组件,哪一系列组件?其实是将指定的一个包下的所有组件导入进来,哪个包?MainApplication所在包及其子包。为什么说Rigistra类的作用是导入组件以及导入组件的具体路径为什么是主程序包及子包,参考Rigistra.class源码如下:
static class Registrar implements ImportBeanDefinitionRegistrar, DeterminableImports {
Registrar() {
}
public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) {
AutoConfigurationPackages.register(registry, (String[])(new AutoConfigurationPackages.PackageImports(metadata)).getPackageNames().toArray(new String[0]));
}
public Set<Object> determineImports(AnnotationMetadata metadata) {
return Collections.singleton(new AutoConfigurationPackages.PackageImports(metadata));
}
}
② @Import(AutoConfigurationImportSelector.class)
该注解导入AutoConfigurationImportSelector.class,该类源码较长我就不复制粘贴过来了,其功能就是使用指定路径的自动配置类向IOC容器中加载组件。简述该类的主要方法从而解析原理,该类中逐级调用方法如下:
(a)该类里核心方法是String[] selectImports(),该方法内通过调用getAutoConfigurationEntry(annotationMetadata)给容器中批量导入一些组件
(b)所有要加载到容器中的组件的全类名是通过调用如下方法获取:
List configurations = getCandidateConfigurations(annotationMetadata, attributes)获取到所有需要导入到容器中的配置类全类名List
(c)获取到要加载的全类名后,通过Spring工厂加载器去加载这些组件SpringFactoriesLoader.loadFactoryNames(…)
设计模式:工厂模式; 原理:反射
(d)具体是利用工厂加载器中的加载方法 Map<String, List> loadSpringFactories(@Nullable ClassLoader classLoader);,该方法会去获取一个指定位置的资源文件:META-INF/spring.factories
(e)加载每一个jar包的META-INF/spring.factories文件(如果存在)
默认扫描我们当前系统里面所有META-INF/spring.factories位置的文件
如spring-boot-autoconfigure-2.6.7.jar包里面也有META-INF/spring.factories
打开改文件就会发现,里面写死了所有IOC容器初始化时加载的所有组件的自动配置类如下图所示: 其中xxxAutoConfiguration即相应xxx组件的自动配置类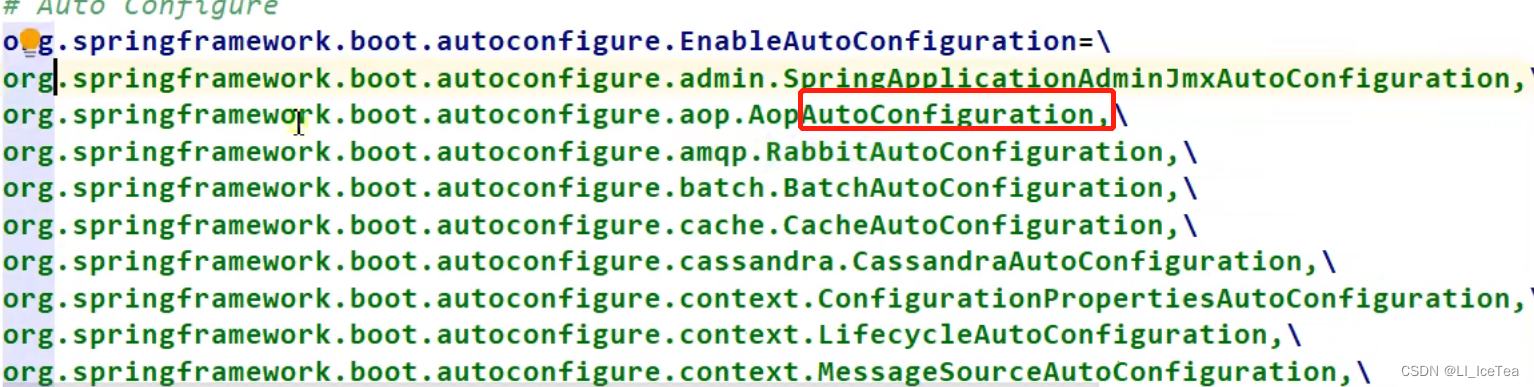 注意,这些只是组件的自动配置类,自动配置类有些生效有些不生效,生效的自动配置类才会向容器中添加相应组件,不生效的自动配置类则不添加该组件。具体哪些自动配置类生效呢?实际上每一个自动配置类上面的@Conditional注解决定了其是否生效,这就是按需加载。常见的@Conditinal注解如下:
注意,这些只是组件的自动配置类,自动配置类有些生效有些不生效,生效的自动配置类才会向容器中添加相应组件,不生效的自动配置类则不添加该组件。具体哪些自动配置类生效呢?实际上每一个自动配置类上面的@Conditional注解决定了其是否生效,这就是按需加载。常见的@Conditinal注解如下:
@ConditionalOnBean:当容器里有指定的bean的条件下。
@ConditionalOnMissingBean:当容器里不存在指定bean的条件下。
@ConditionalOnClass:当类路径下有指定类的条件下。
@ConditionalOnMissingClass:当类路径下不存在指定类的条件下。
@ConditionalOnProperty:指定的属性是否有指定的值,比如:@ConditionalOnProperties(prefix=”xxx.xxx”, value=”enable”, matchIfMissing=true),代表当xxx.xxx为enable时条件的布尔值为true,如果没有设置的情况下也为true。
按需加载:
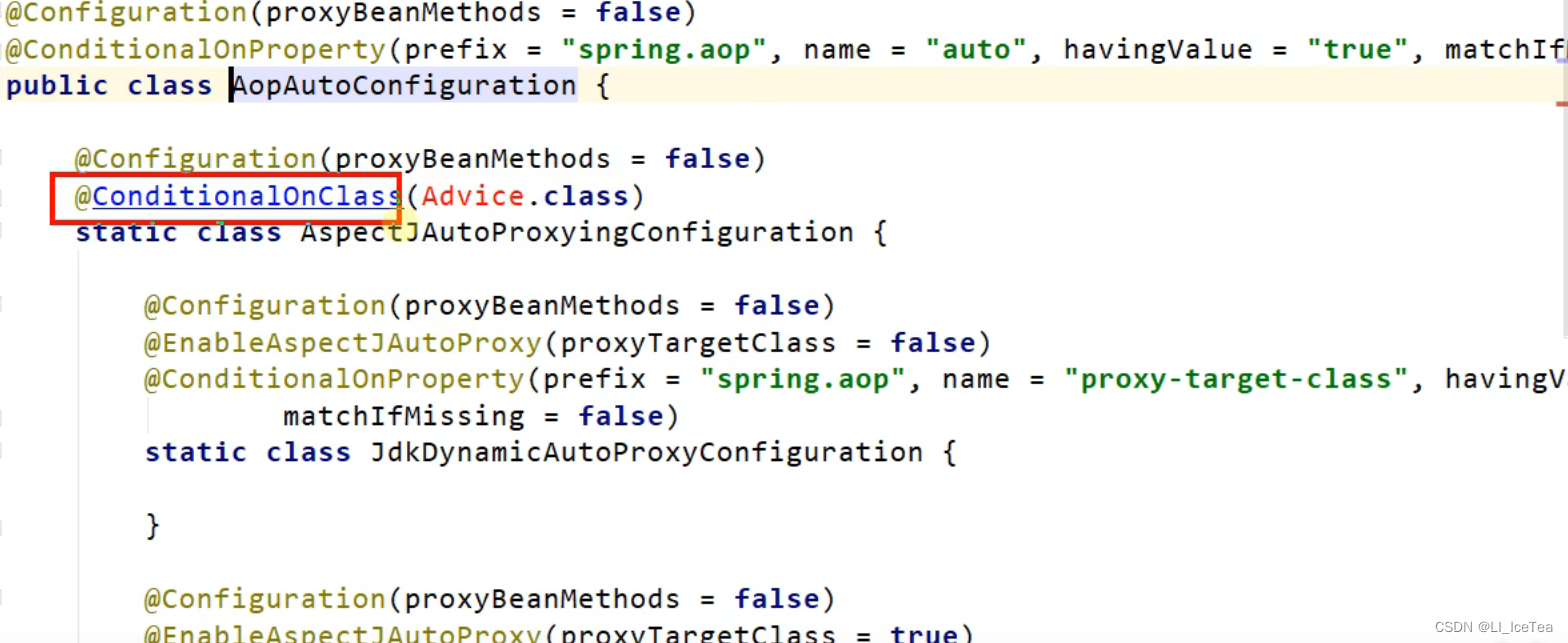
我们以切面的自动配置类AopAutoConfiguration类来讲解一下按需加载的原理。首先看到该类上面注解了@ConditionalProperty,代表了配置文件中有给定值的时候才生效;如果要看容器中是否添加切面组件,则要看其内的方法,例如红框标注的注解标示只有当前工程的上下文路径中存在Advice类时才会生效,而默认情况下我们当前路径中没有配置该类,因此Aop组件不会加载到IOC容器中。
那么何时生效呢?当我们写代码时用到了切面,必然会通过import导入aspectj这个包,此时我们当前类路径下就必然出现Advice类,从而AOP自动配置类就会生效,在IOC容器初始化时加载IOC组件,这就是按需加载。
配置绑定:
如果某一个自动配置类按需加载时,根据@Conditinal判断生效,则就会对该自动配置类对应的组件进行配置绑定。以批处理为例,当我们代码中用到了批处理,就会import相关的jar包或在容器中创建相应的bean组件,从而按需加载BatchAutoConfiguration这一自动配置类。
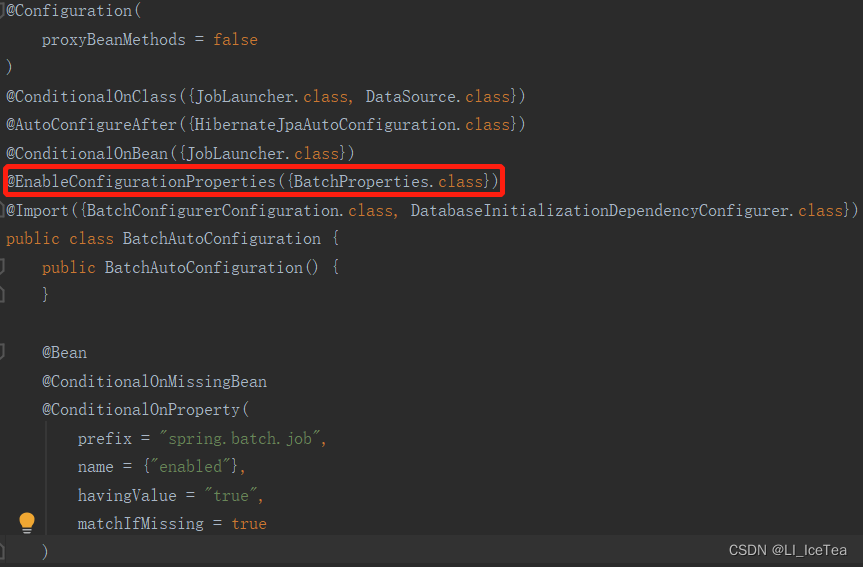
该自动配置类中有一个@EnableConfigurationProperties注解(如下图所示),该注解有两个作用:①是开启指定xxxProperties类的配置绑定功能②是将该xxxProperties类注册到容器中,相当于在该类上面加了@Component,我们进入对应BatchProperties中查看源码:
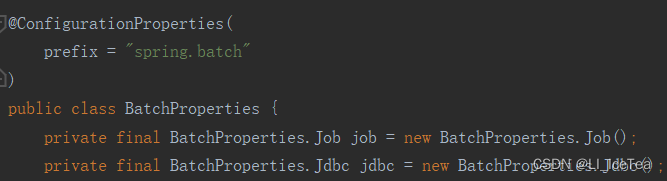
可以看到该类中通过@ConfigurationProperties注解,该注解的作用就是将批处理组件的属性与核心配置文件中的字段进行了绑定,从而实现了配置绑定。上面说的比较详细,如果做一个粗略的总结。
自动配置流程总结:
- 主程序入口:Spring Boot启动的时候会先找到主程序上的@SpringBootApplication注解,该注解三个注解的合成注解
- 加载指定路径的配置文件(其内写死了所有组件的自动配置类):其底层是通过@EnableAutoConfiguration注解找到所有jar包的META-INF/spring.factories配置文件中的所有自动配置类(主要是找到spring-boot-autoconfigure jar包内的该文件),并对其进行加载
- 按需加载:而这些自动配置类都是以xxxAutoConfiguration结尾来命名的,它们实际上就是一个个JavaConfig形式的容器组件的自动配置类,这些自动配置类是否生效取决于它们上面的@Conditinal注解(这叫按需加载)
- 配置绑定:针对按需加载中生效的自动配置类,才进行属性绑定。自动配置类上使用@EnableConfigurationProperties注解,激活对应的以Properties结尾命名的类,这些Properties类会通过@ConfigurationProperties注解获得在全局配置文件中配置的属性如:server.port等
- IOC容器初始化,根据上面绑定好的配置,按需加载所有自动配置类生效的组件,从而完成了自动配置。
原理图:
这里我在学习过程中看到了王福强老师的博客,他绘制了一张SpringBoot自动配置的详细流程图,我认为画的比我详细比我好,我放在开头供大家学习参考:
 图片出处与博客原文:王富强老师博客:Spring Boot Rock’n’Roll!
图片出处与博客原文:王富强老师博客:Spring Boot Rock’n’Roll!
既然王老师的上图非常详细的从Spring类的角度绘制了自动配置底层原理图,那我就换个角度,并且简略一些,从加载顺序的角度绘制一张自动配置过程原理图吧!

自动配置过程原理图
Summary:本章是SpringMVC核心功能的源码解析和原理讲解
四、SpringMVC功能源码&原理图解
除了自动配置与依赖管理外,SpringBoot作为“框架的框架”,其在开发中实现的具体功能大多是通过SpringMVC实现的,因此本章我们来看一下SpringMVC功能原码。
1.静态资源配置原理
1.1静态资源访问路径
在SpringBoot中,允许直接访问静态资源,但这些静态资源必须放在指定包下:
①classpath:/META-INF/resources/
②classpath:/resources/
③classpath:/static/
④classpath:/public/
这个功能是如何实现?能否禁用?为什么是指定这些包?下面我们来看一下原理。
首先,SpringMVC相关功能是通过WebMvcAutoConfiguration自动配置类来配置的,其加载原理在上文自动配置中已经详述。我们看一下该类上的多个@Conditional注解,依次要求:Servlet类型、DispatcherServlet相关类文件、无用户定制的WebMvcConfigurationSupport类(用来全面接管SpringMVC),满足以上要求则自动配置类生效。
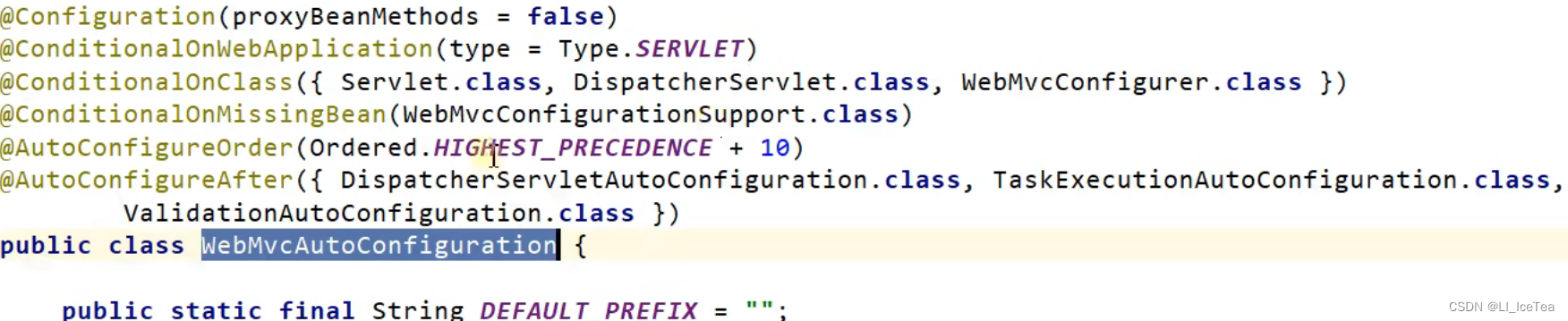
WebMvc自动配置类生效后,我们关注其源码,WebMvcAutoConfiguration自动配置类中有一个静态内部类WebMvcAutoConfigurationAdapter:
@Configuration(
proxyBeanMethods = false
)
@Import({
WebMvcAutoConfiguration.EnableWebMvcConfiguration.class})
@EnableConfigurationProperties({
WebMvcProperties.class, ResourceProperties.class}))
@Order(0)
public static class WebMvcAutoConfigurationAdapter implements WebMvcConfigurer, ServletContextAware {
private static final Log logger = LogFactory.getLog(WebMvcConfigurer.class);
private final Resources resourceProperties;
private final WebMvcProperties mvcProperties;
private final ListableBeanFactory beanFactory;
private final ObjectProvider<HttpMessageConverters> messageConvertersProvider;
private final ObjectProvider<DispatcherServletPath> dispatcherServletPath;
private final ObjectProvider<ServletRegistrationBean<?>> servletRegistrations;
private final WebMvcAutoConfiguration.ResourceHandlerRegistrationCustomizer resourceHandlerRegistrationCustomizer;
private ServletContext servletContext;
这里先介绍一下xxxAdapter,在源码中多处应用到了xxxAdapter,这是典型的 设计模式:适配器模式,SpringBoot源码中多用它来兼容多个实现不同接口的类。比如这里就是实现了接口WebMvcConfigurer, ServletContextAware。适配器模式基本介绍如下:
适配器模式
● 背景:已有Target接口,和待适配对象Adaptee,需要使用Adaptee提供的功能,但是无法通过Target接口去调用
● 定义一个适配器类Adapter,实现Target接口,继承Adaptee类(或者令Adaptee成为它的成员变量)
● 实现Target接口提供的方法,实际上调用Adaptee中的方法
● 使用时创建Adapter对象即可通过Target接口调用Adaptee种的方法了
回到WebMvcAutoConfigurationAdapter源码中,可以看到该类也是一个配置类,且其上注解声明了激活两个属性类的属性绑定:WebMvcProperties.class、ResourceProperties,因此我们查看这两个类源码
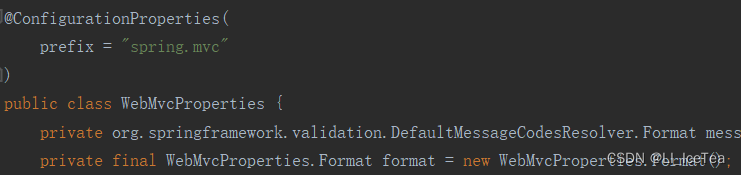
WebMvcProperties类与核心配置文件的spring.mvc属性进行了绑定
ResourceProperties类与核心配置文件的spring.resources属性进行了绑定(新版中改为了WebPropertie绑定spring.web)

原理解析:
静态资源配置的具体原理是WebMvcAutoConfigurationAdapter内的核心方法:addResourceHandlers(),其源码如下:
public void addResourceHandlers(ResourceHandlerRegistry registry) {
if (!this.resourceProperties.isAddMappings()) {
logger.debug("Default resource handling disabled");
} else {
this.addResourceHandler(registry, "/webjars/**", "classpath:/META-INF/resources/webjars/");
this.addResourceHandler(registry, this.mvcProperties.getStaticPathPattern(), (registration) -> {
registration.addResourceLocations(this.resourceProperties.getStaticLocations());
if (this.servletContext != null) {
ServletContextResource resource = new ServletContextResource(this.servletContext, "/");
registration.addResourceLocations(new Resource[]{
resource});
}
});
}
}
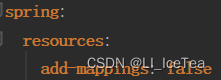
首先通过resourceProperties.isAddMappings()属性判断是否启用静态资源配置,而resourceProperties是ResourceProperties类对象,其属性值与核心配置文件绑定,即可以通过核心配置文件中的spring:resources:add-mappings属性设置为false禁用掉静态资源配置。
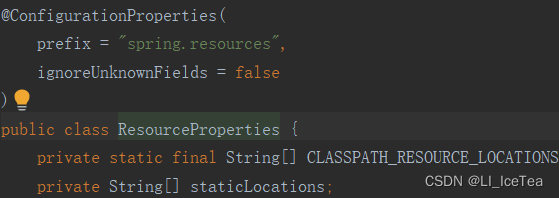
ResourceProperties类中,除了add-mappings属性设置可以设置是否启用静态资源配置外,还有哪些属性可以配置呢?具体参考该类源码:
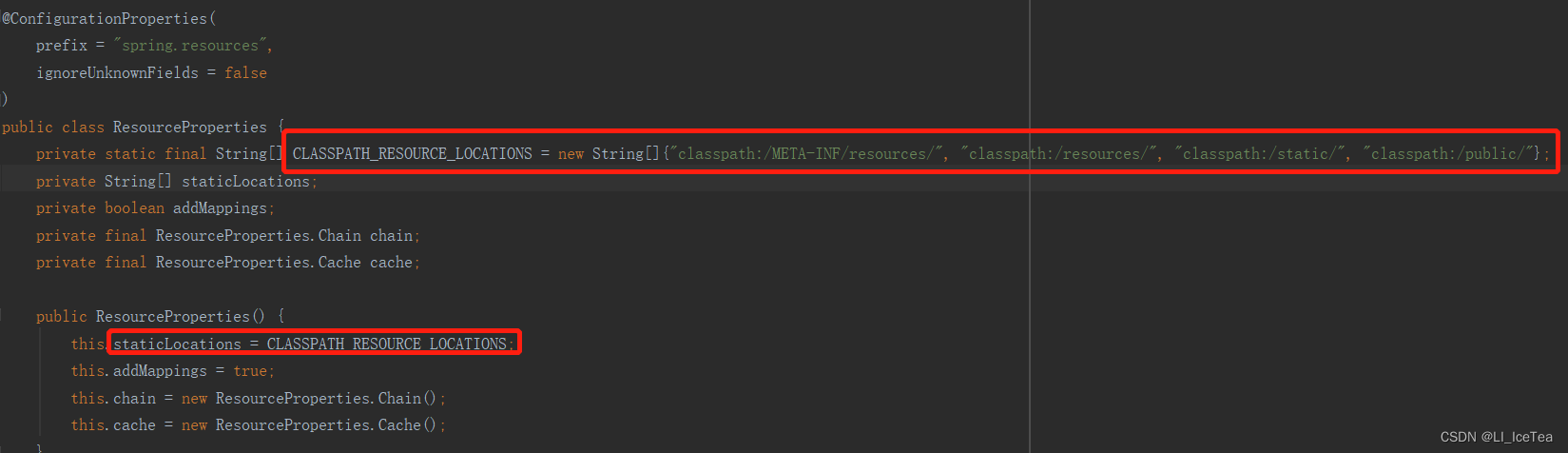
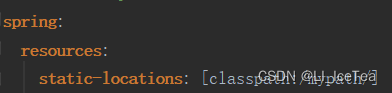
该类的构造器方法中,将默认值CLASSPATH_RESOURCE_LOCATIONS属性赋给了staticLocations,因此SpringBoot中默认的静态资源访问路径支持上面四个,原因就在这里。同理,也可以通过核心配置文件中修改staticLocations修改静态资源访问路径:(注意,修改后原默认静态资源路径会失效,只支持配置的路径)
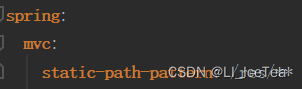
此外,也可以通过修改WebMvcProperties类中的static-path-pattern属性(对应于核心配置文件中的spring.mvc.static-path-pattern)配置浏览器访问静态资源的前缀名,如下图所示配置,则浏览器访问静态资源时路径为:localhost:8080/res/静态资源名
静态资源访问默认底层是使用了缓存策略的,访问过以后短期内再次访问直接走缓存,提高响应速度。
1.2欢迎页配置
在SpringMVC中默认支持欢迎页的功能,只需要将index.html的欢迎页放在静态资源路径下。下面我们来解析一下原理:
首先,依然是在WebMvcAutoConfiguration类中创建了一个welcomePageHandlerMapping,源码中的多处xxxHandlerMapping代表的是xxx处理器映射,它的作用就是为xxxHandler提供映射规则,说的直白点就是将处理器和请求进行匹配。此处的welcomePageHandlerMapping就是配置了欢迎页请求和其处理器的映射。
//WebMvcAutoConfiguration类中创建了一个welcomePageHandlerMapping
@Bean
public WelcomePageHandlerMapping welcomePageHandlerMapping(ApplicationContext applicationContext,
FormattingConversionService mvcConversionService, ResourceUrlProvider mvcResourceUrlProvider) {
WelcomePageHandlerMapping welcomePageHandlerMapping = new WelcomePageHandlerMapping(
new TemplateAvailabilityProviders(applicationContext), applicationContext, getWelcomePage(),
this.mvcProperties.getStaticPathPattern());
welcomePageHandlerMapping.setInterceptors(getInterceptors(mvcConversionService, mvcResourceUrlProvider)); welcomePageHandlerMapping.setCorsConfigurations(getCorsConfigurations());
return welcomePageHandlerMapping;
}
进入该类的源码,可以看到如果存在欢迎页并且静态资源请求路径是”/**”才可以返回欢迎页。反之,如果没有放入欢迎页或通过spring.mvc.static-path-pattern修改了静态资源请求路径,则不再支持默认的欢迎页功能。如果默认的欢迎页规则不匹配,那么就会进入Controller以请求映射的方式寻找是否有方法能处理该请求,这部分原理我们在请求映射一节中详解。
//
WelcomePageHandlerMapping(TemplateAvailabilityProviders templateAvailabilityProviders,
ApplicationContext applicationContext, Optional<Resource> welcomePage, String staticPathPattern) {
if (welcomePage.isPresent() && "/**".equals(staticPathPattern)) {
//要用欢迎页功能,必须是/**
logger.info("Adding welcome page: " + welcomePage.get());
setRootViewName("forward:index.html");
}
else if (welcomeTemplateExists(templateAvailabilityProviders, applicationContext)) {
// 调用Controller /index
logger.info("Adding welcome page template: index");
setRootViewName("index");
}
}
上面说的比较详细,如果做一个粗略的总结
静态资源配置总结:
- 加载WebMvcAutoConfiguration自动配置类:Spring Boot启动时会根据自动配置原理,加载所有自动配置类,包括WebMvc自动配置类。
- 按需加载静态内部类WebMvcAutoConfigurationAdapter:在Web开发场景下,该类的所有@Conditinal全部生效,从而加载该类内的所有方法和属性,其内有一个静态内部类WebMvcAutoConfigurationAdapter。
- 激活WebMvcProperties、ResourcesProperties属性绑定:
WebMvcAutoConfigurationAdapter是一个配置类,且激活了WebMvcProperties和ResourcesProperties的属性与核心配置文件绑定 - 执行addResourceHandlers()方法:该方法为ResourcesProperties属性的变量staticLocations设置了默认值,若核心配置文件有修改则按mvc.resources.static-locations配置的静态资源包路径生效
- 执行WelcomePageHandlerMapping()方法:该方法会判断,如果欢迎页存在且静态资源请求路径是/**则会跳转到index.html;否则,会进行请求参数映射寻找Controller中是否有方法可以处理“/index”请求
原理图:

静态资源访问原理图
2.请求处理
我们回顾一下原生的Web开发中,我们如何进行请求处理的?当时我们使用的是HttpServlet(即原生servlet),我们会继承该类并重写其doGet()和doPost()方法来实现自己的处理逻辑。SpringBoot要实现请求处理的功能,自然也要如此,我们来看一下它的继承树:
tip:光标在类上按Ctrl + H即可快速查看继承树
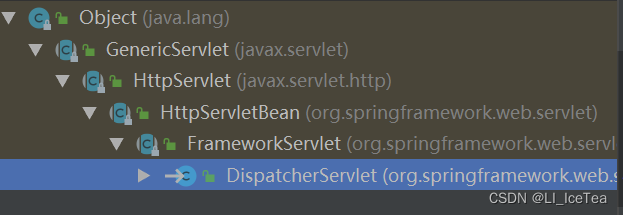
这里简单给大家介绍一下各继承类的关系和作用,有兴趣的同学可以自己逐一查看源码验证。首先HttpServletBean直接继承了原生的HttpServlet,但它是一个抽象类,其内没有实现doGet()和doPost()方法,主要作用是做一些初始化配置,FrameworkServlet类实现了doGet()和doPost()方法:
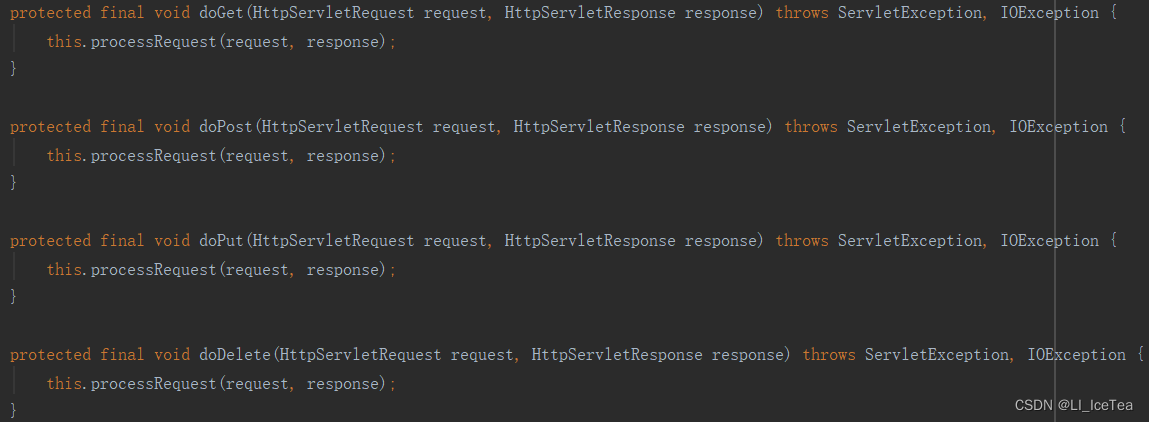
虽然FrameworkServlet实现了doGet和doPost方法(以及Restful风格的doPut和doDelete),但其内都是通过调用processRequest方法实现,进入该方法:
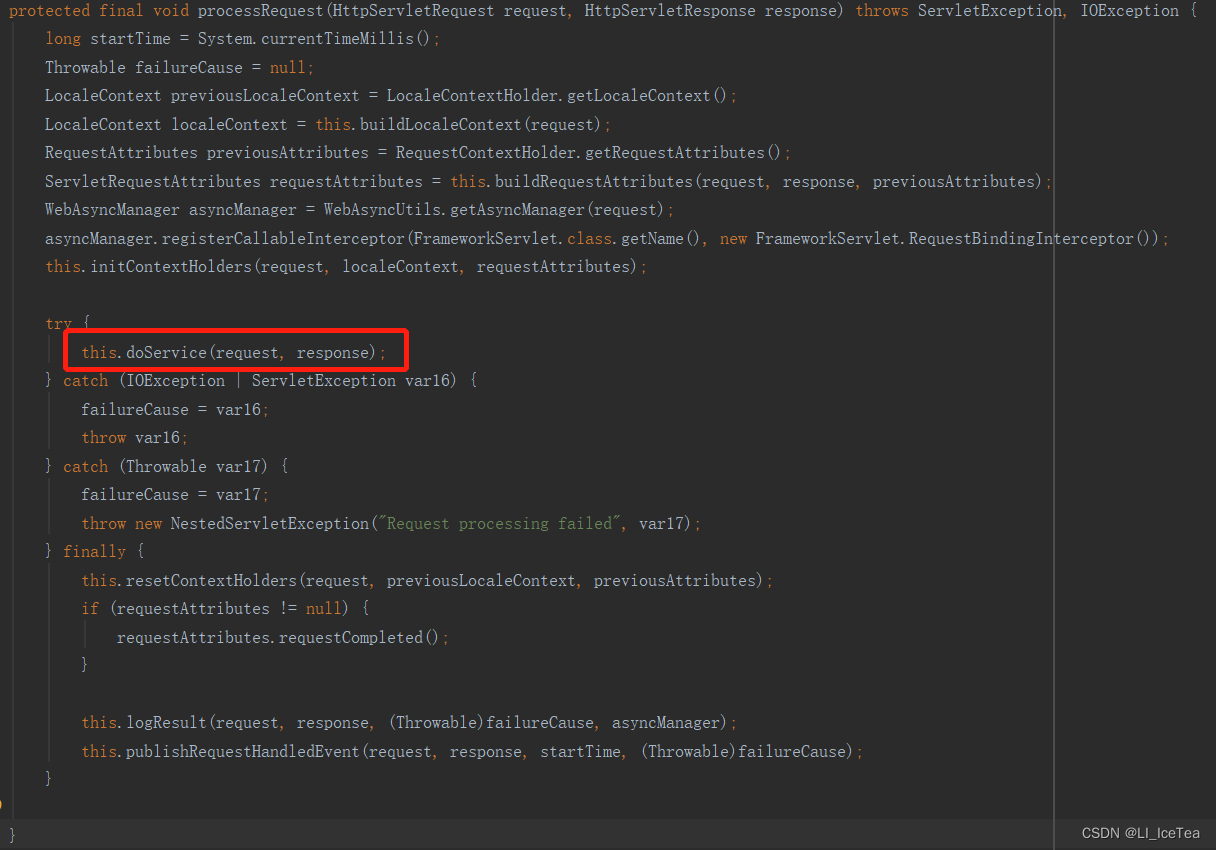
processReuqest()中实际是通过调用doService()方法来实现功能的,查看doService()方法:

该方法是抽象方法,因此FramworkServlet也没有实现该方法,是其子类DispatcherServlet实现了doService方法,而其内又通过调用本类的doDispatch方法实现功能:
protected void doService(HttpServletRequest request, HttpServletResponse response) throws Exception {
this.logRequest(request);
Map<String, Object> attributesSnapshot = null;
if (WebUtils.isIncludeRequest(request)) {
attributesSnapshot = new HashMap();
Enumeration attrNames = request.getAttributeNames();
…………(省略部分源码)…………
try {
//真正实现功能的方法调用
this.doDispatch(request, response);
} finally {
if (!WebAsyncUtils.getAsyncManager(request).isConcurrentHandlingStarted() && attributesSnapshot != null) {
this.restoreAttributesAfterInclude(request, attributesSnapshot);
}
if (this.parseRequestPath) {
ServletRequestPathUtils.setParsedRequestPath(previousRequestPath, request);
}
}
}
综上所述,SpringBoot中实现请求处理也是和传统Web开发一样,继承原生HttpServlet并重写其doXXX()方法,只不过在继承树中,其子类HttpServletBean只实现了初始化,FrameworkServlet实现了doXXX()方法,但方法内是通过调用doService()抽象方法实现功能,因此最终是DispatcherServlet类通过实现doService()方法,其内调用doDispatch()真正继承并实现了doXXX()方法来完成请求处理功能。请求处理的源码起点就是DispatcherServlet类的doDispatch()方法。这里放一张雷神视频中的继承图,表示继承树各子类方法之间的关系。

2.1请求映射
当前端页面发起一个请求时,SpringBoot是如何为我们匹配到处理该请求的Controller方法呢?这是SpringMVC中的dispatcherServlet的功能,其内通过doDispatch()方法处理请求,部分源码如下:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false;
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
try {
try {
ModelAndView mv = null;
Object dispatchException = null;
try {
processedRequest = this.checkMultipart(request);
multipartRequestParsed = processedRequest != request;
//该方法决定了使用哪个Handler处理当前请求
mappedHandler = this.getHandler(processedRequest);
…………(省略部分源码)…………
doDispatch方法中传入了原生的request和response,其底层实现还是通过操作请求与响应来完成各种功能的。
原理解析:
请求映射的核心源码就是getHandler()方法,该方法通过当前请求(processedRequest即封装后的请求request)决定了使用哪一个Handler处理器处理该请求:
protected HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception {
if (this.handlerMappings != null) {
Iterator var2 = this.handlerMappings.iterator();
while(var2.hasNext()) {
HandlerMapping mapping = (HandlerMapping)var2.next();
HandlerExecutionChain handler = mapping.getHandler(request);
if (handler != null) {
return handler;
}
}
}
return null;
}
首先可以看到,该方法内是通过遍历handlerMapping来寻找能接收当前请求的HandlerMapping。HandlerMapping实际上是处理器映射,其内保存了/xxx请求与xxx()方法的映射关系。这里默认有五个HandlerMapping,如下图所示:
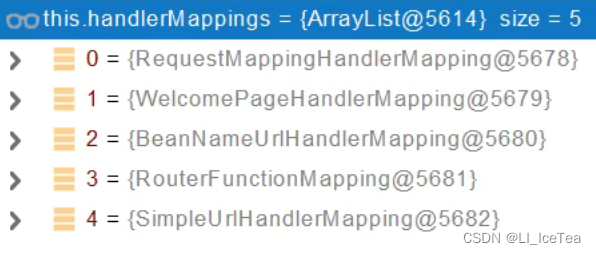
其中有一个我们很眼熟的WelcomePageHandlerMapping,就是欢迎页实现的原理。这里我们重点关注第一个 RequestMappingHandlerMapping,它对应于我们在Controller方法上常使用的注解@RequestMapping,因此见名知意它其实是@RequestMapping注解的处理器映射,里面保存了每一个@RequestMapping注解和对应handler的映射规则。这里我们看一下RequestMappingHandlerMapping内部的属性和结构,其中我们重点关注一个 mappingRegistry注册中心,它会在主程序启动时保存好所有Controller方法和请求路径的映射关系,
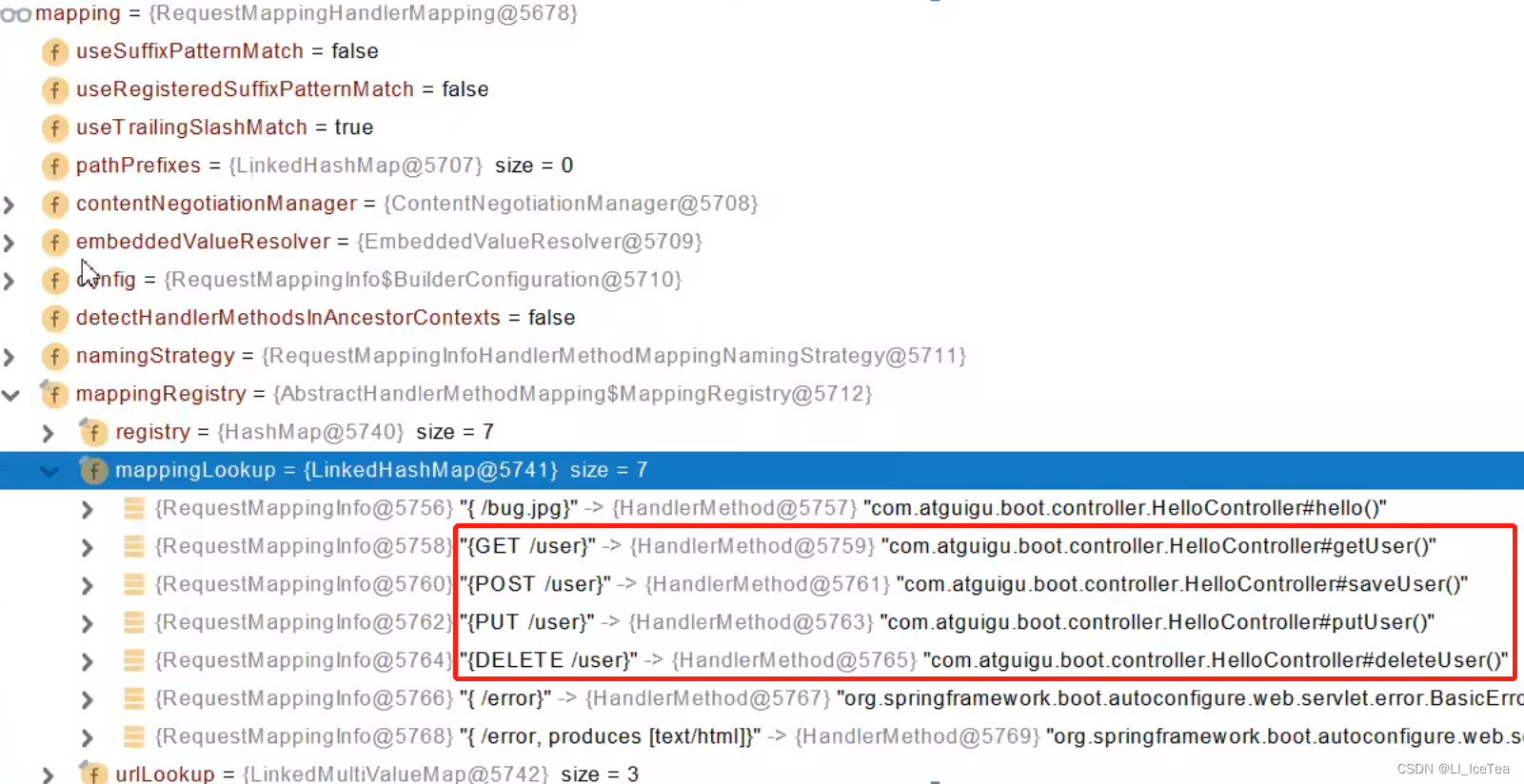
在getHandler源码中我们可以看到,实际是通过mapping.getHandler(request)获取到返回的Handler处理器的,进入该方法会发现实际调用的是getHandlerInternal(request)方法,进行处理后获得url又调用了lookupHandlerMethod我们查看这个方法,这个方法最后找到handler返回:
public class AbstractHandlerMapping{
protected HandlerMethod lookupHandlerMethod(String lookupPath, HttpServletRequest request) throws Exception {
List<Match> matches = new ArrayList<>();
//首先在注册中心中通过当前请求路径url匹配所有的RequestMapping放入List
//(同一url可能请求方式不同,匹配多个不同的Handler)
List<T> directPathMatches = this.mappingRegistry.getMappingsByUrl(lookupPath);
//获取“完全匹配”的matches,内部判断了请求头,请求方式等信息
if (directPathMatches != null) {
addMatchingMappings(directPathMatches, matches, request);
}
//没有“完全匹配”的RequestMapping则全部添加
if (matches.isEmpty()) {
// No choice but to go through all mappings...
addMatchingMappings(this.mappingRegistry.getMappings().keySet(), matches, request);
}
//正常情况固定请求方式固定url应当只有一个完全匹配的RequestMapping
if (!matches.isEmpty()) {
Comparator<Match> comparator = new MatchComparator(getMappingComparator(request));
matches.sort(comparator);
Match bestMatch = matches.get(0);
//确保匹配的RequestMapping只有一个,否则报错
if (matches.size() > 1) {
if (logger.isTraceEnabled()) {
logger.trace(matches.size() + " matching mappings: " + matches);
}
if (CorsUtils.isPreFlightRequest(request)) {
return PREFLIGHT_AMBIGUOUS_MATCH;
}
Match secondBestMatch = matches.get(1);
if (comparator.compare(bestMatch, secondBestMatch) == 0) {
Method m1 = bestMatch.handlerMethod.getMethod();
Method m2 = secondBestMatch.handlerMethod.getMethod();
String uri = request.getRequestURI();
throw new IllegalStateException(
"Ambiguous handler methods mapped for '" + uri + "': {" + m1 + ", " + m2 + "}");
}
}
request.setAttribute(BEST_MATCHING_HANDLER_ATTRIBUTE, bestMatch.handlerMethod);
handleMatch(bestMatch.mapping, lookupPath, request);
return bestMatch.handlerMethod;
}
else {
return handleNoMatch(this.mappingRegistry.getMappings().keySet(), lookupPath, request);
}
}
}
简单阐述一下这段源码的基本逻辑:
1.首先调用注册中心mappingRegistry的getMappingsByUrl()方法,即通过当前请求路径url匹配所有的RequestMapping放入ArrayList。
2.但由于同一url可能因为请求方式的不同存在多个处理器方法。例如上图中的多个RequestMappingInfo属于同一url但请求方式包括get post put delete(如restful风格),对应了不同的RequestMapping处理器映射。
3.因此还需要进一步获取除url外的其余请求信息(包括请求头、请求方法等)来获取一个“完全匹配”的RequestMapping,从而找到唯一的处理器方法HandlerMethod。如何获取完全匹配呢?我们下一段详细介绍。
4.将获取到完全匹配的RequestMapping放入到matches(也是一个ArrayList)中,正常情况下,一个RequestMappingInfo完全匹配的RequestMapping应该只有一个,当matches.size()大于1时就说明1个请求匹配到了多个方法,此时就会抛出异常。
5.若只完全匹配到一个,则根据唯一的ReqeustMapping找到对应的HandlerMethod,在完成参数注入等工作后,执行该处理器方法。
再说一下如何由匹配路径获取到“完全匹配”的matches的,通过多个方法逐级调用addMatchingMappings()——>getMatchingMapping()——>getMatchingCondition(),因此最终是调用RequestMappingInfo类的getMatchingCondition()根据条件获取完全匹配方法来确定matches:
public RequestMappingInfo getMatchingCondition(HttpServletRequest request) {
RequestMethodsRequestCondition methods = this.methodsCondition.getMatchingCondition(request);
if (methods == null) {
return null;
} else {
ParamsRequestCondition params = this.paramsCondition.getMatchingCondition(request);
if (params == null) {
return null;
} else {
HeadersRequestCondition headers = this.headersCondition.getMatchingCondition(request);
if (headers == null) {
return null;
} else {
ConsumesRequestCondition consumes = this.consumesCondition.getMatchingCondition(request);
if (consumes == null) {
return null;
} else {
ProducesRequestCondition produces = this.producesCondition.getMatchingCondition(request);
if (produces == null) {
return null;
} else {
PathPatternsRequestCondition pathPatterns = null;
if (this.pathPatternsCondition != null) {
pathPatterns = this.pathPatternsCondition.getMatchingCondition(request);
if (pathPatterns == null) {
return null;
}
}
PatternsRequestCondition patterns = null;
if (this.patternsCondition != null) {
patterns = this.patternsCondition.getMatchingCondition(request);
if (patterns == null) {
return null;
}
}
RequestConditionHolder custom = this.customConditionHolder.getMatchingCondition(request);
return custom == null ? null : new RequestMappingInfo(this.name, pathPatterns, patterns, methods, params, headers, consumes, produces, custom, this.options);
}
}
}
}
}
}
这段源码是不是有种我们自己写的代码的感觉?(笑) 原来SpringBoot源码也会用一堆if else呀…不过人家用的有理有据,依次判断请求方式、携带参数、请求头等信息,任意一项不匹配则返回空,最终获取到每一项都完全匹配的RequestMappingInfo放入matches中。
原理图:

请求映射原理图
2.2原生参数&注解注入
在请求处理的过程中,完成了请求映射找到对应Controller方法后,就要完成参数注入了,参数注入包括注解类型的参数、Servlet原生API参数,以及我们自定义类型的POJO参数。本节我们讲解一下注解参数注入和原生参数注入的原理。我们先回顾一下原生参数:
原生参数
实现方式:
1.HttpServletRequest :原生Servlet请求
2. HttpServletResponse :原生Servlet响应
3. HttpSession:原生Session域
4. java.security.Principal :可表示任何实体,通常用来做安全认证和授权
5. Locale :表示地区信息
6. InputStream:字节输入流
7. OutputStream:字节输出流
8. Reader:字符输入流
9. Writer:字符输出流
注解参数
实现方式:
1.@PathVariable:路径传参,如someUrl/{paramId}绑定@Pathvariable paramId
2.@RequestHeader:请求头信息,可获取Map类型的全部请求头信息或String类型的单一信息,如 @RequestHeader(“User-Agent”) String userAgent
3.@CookieValue:Cookie的值信息,可以获取Cookie或String类型的值信息,如@CookieValue(“_ck”) Cookie cookie
4.@RequestParam:请求参数,可以灵活选取参数类型如@RequestParam(“age”) Integer age
5.@RequestBody:请求体参数,通常用来获取前端传递给后端的json字符串,如@RequestBody String jsonValue
原理解析:
前文中说过,所有请求处理的源码都点就是DispatcherServlet类的doDispatch()方法,参数注入的原理我们也从这里开始~如下图所示,首先经过请求映射过程获取到mappedHandler(如蓝框所示),之后为该Handler寻找一个适配器HandlerAdapter(如红框所示):
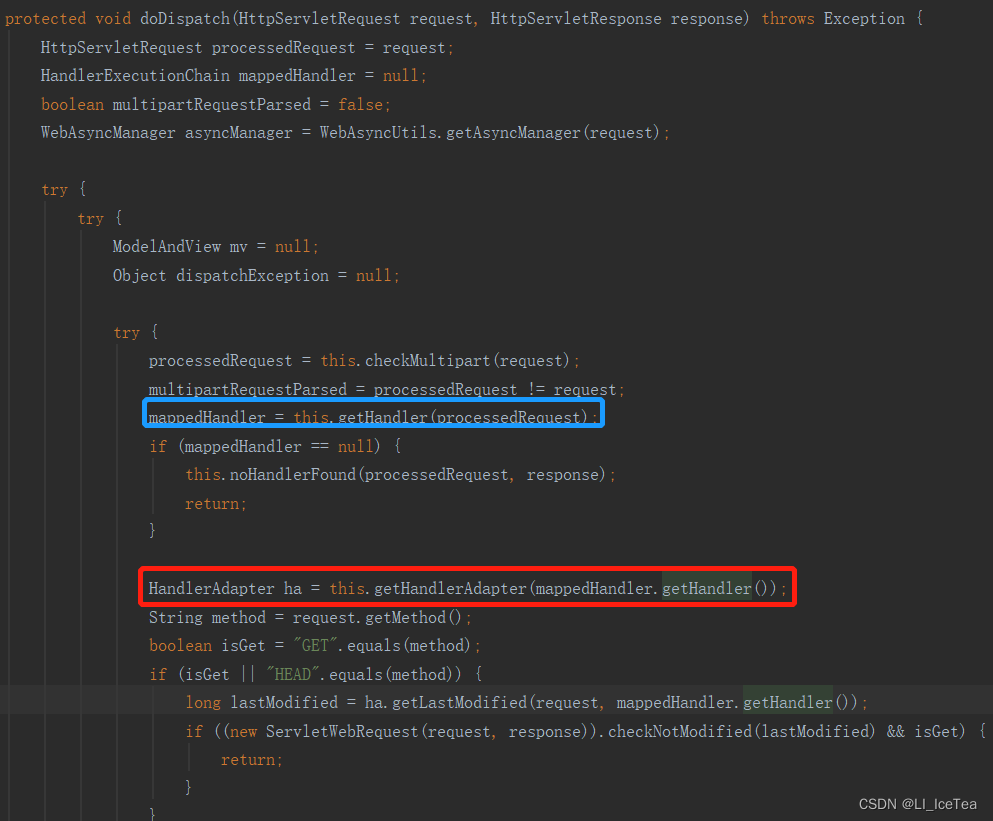
HandlerAdapter是处理器适配器(接口),它是请求处理部分的关键,其 设计模式是适配器模式(上文已有介绍),在处理器这里应用适配器模式的原因我们可以大胆猜测一下,就是因为处理器为了处理请求,需要调用各类的接口方法,而部分类和接口方法不兼容,因此通过适配器模式协调。
为请求映射获取到的Handler寻找一个HandlerAdapter,在本项目中HandlerAdapter有四个,如下图所示:
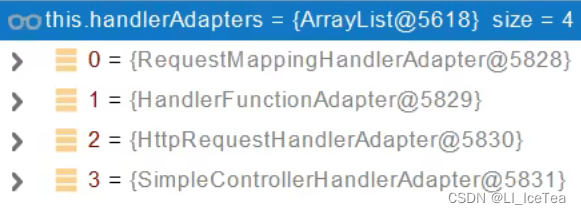
这四个适配器见名知意即可知道大概的意思,如第一个适配器是@RequestMapping 方法所使用的,第二个适配器是支持函数式编程的。寻找处理器适配器时依然是按顺序遍历每一个适配器,我们来看一下遍历过程:
protected HandlerAdapter getHandlerAdapter(Object handler) throws ServletException {
if (this.handlerAdapters != null) {
Iterator var2 = this.handlerAdapters.iterator();
while(var2.hasNext()) {
HandlerAdapter adapter = (HandlerAdapter)var2.next();
//判断adapter适配器是否支持当前handler
if (adapter.supports(handler)) {
return adapter;
}
}
}
throw new ServletException("No adapter for handler [" + handler + "]: The DispatcherServlet configuration needs to include a HandlerAdapter that supports this handler");
}
如何判断一个adapter适配器是否支持handler方法?我们查看supports方法源码:
public final boolean supports(Object handler) {
return handler instanceof HandlerMethod && this.supportsInternal((HandlerMethod)handler);
}
判断是否支持的逻辑为当前handler是HandlerMethod类型,如请求映射后我们获得了RequestMappingHandlerMapping,该处理器映射最终得到的handler就会封装成RequestMappingHandler,也就是RequestMappingHandlerAdapter支持的类型。
找到xxxHandlerAdapter后,就会调用适配器的.handle()方法,其内又是多级的方法调用,我们引用雷神的笔记(加一些我的注解)描述这一过程:
适配器处理方法逐级调用:
//DispatcherServlet——doDispatch()——handle():
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
//RequestMappingHandlerAdapter——handleInternal()
//handleInternal()方法内调用——invokeHandlerMethod()
mav = invokeHandlerMethod(request, response, handlerMethod); //其内封装了参数解析器和返回值处理器
//ServletInvocableHandlerMethod ——>invokeForRequest() 执行目标方法
Object returnValue = invokeForRequest(webRequest, mavContainer, providedArgs);
//invokeForRequest中首先要获取方法的参数值——>getMethodArgumentValues()
Object[] args = getMethodArgumentValues(request, mavContainer, providedArgs);
我们看一下本项目中的参数解析器argumentResolvers,即参数注入的核心:
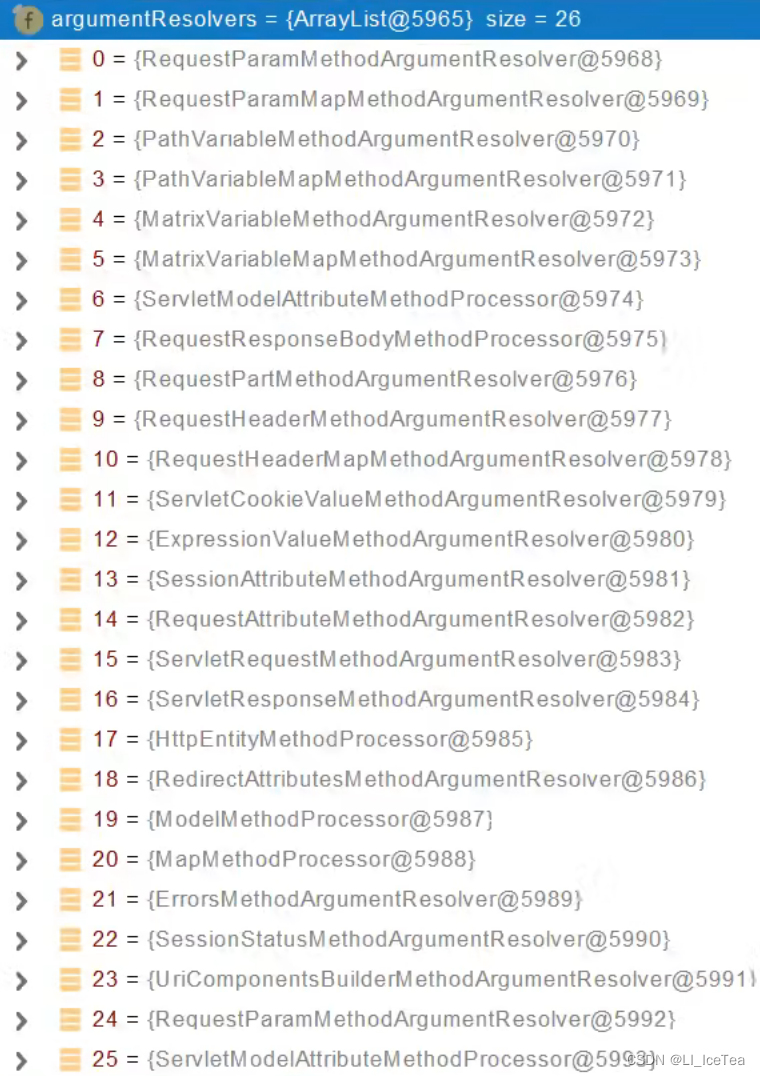
每一个argumentResolvers对应一个注解,看到这里大家应该明白了,其实注解参数和Servlet原生API参数的解析原理是一样的,都是通过对应不同的参数解析器来调用其resolve()方法解析的。这里我们以表格形式列出一些常用的参数解析器功能:
| 类型 | 名称 | 功能 |
|---|---|---|
| 获取request对象 | ServletRequestMethodArgumentResolver | 直接获取Request,HttpSession, PushBuilder,HttpMethod等对象 |
| 获取response对象 | ServletResponseMethodArgumentResolver | 直接获取ServletResponse, OutputStream, Writer对象 |
| 获取requestHeader参数 | RequestHeaderMethodArgumentResolver | @RequestHeader标注的参数(非Map类型) |
| 获取requestHeader参数 | RequestHeaderMapMethodArgumentResolver | 1.@RequestHeader标注的Map参数(同参数取第一个值) 2.@RequestHeader标注的MultiValueMap参数(同参数取所有值) |
| 获取requestParamter参数 | RequestParamMethodArgumentResolver | 1.@RequestParam标注的普通参数(非Map类型) 2.@RequestParam标注的MultipartFile参数 3.没用@RequestParam标注的简单类型(int/long) 4.@RequestParam标注的Map类型参数(需在注解中指定参数名) |
| 获取requestParamter参数 | RequestParamMapMethodArgumentResolver | 1.@RequestParam标注的Map类型参数(没有指定参数名。同参数取第一个值,文件则取所有文件) 2.@RequestParam标注MultiValueMap参数(没有指定参数名。同参数取所有值) |
| 获取requestParamter参数 | ModelAttributeMethodProcessor (从model中获取值) | 1.@ModelAttribute标注的参数 2.@ModelAttribute标注的方法 |
| 获取requestParamter参数 | ServletModelAttributeMethodProcessor (依次从url/requestParameter/model中获取值) | 1.@ModelAttribute标注的参数 2.@ModelAttribute标注的方法 3.所有非简单类型/简单类型数组(annotationNotRequired=true) |
| 获取requestParamter参数 | ExpressionValueMethodArgumentResolver | @Value标注的参数(支持${…}表#{…}表达式) |
| 获取requestAttribute参数 | RequestAttributeMethodArgumentResolver | @RequestAttribute标注的参数 |
| 获取serssionAttribute参数 | SessionAttributeMethodArgumentResolver | @SessionAttribute标注的参数 |
| 获取url参数 | PathVariableMethodArgumentResolver | 1.@PathVariable标注的普通参数(非Map类型) 2.@PathVariable标注的Map类型参数(需在注解中指定参数名) |
| 获取url参数 | PathVariableMapMethodArgumentResolver | @PathVariable标注的Map类型参数(没有指定参数名) |
| 获取url参数 | MatrixVariableMethodArgumentResolver | 1.@MatrixVariable标注的普通参数(非Map类型) 2.@MatrixVariable标注的Map类型参数(需在注解中指定参数名) |
| 获取url参数 | MatrixVariableMapMethodArgumentResolver | @MatrixVariable标注的Map类型参数(没有指定参数名) |
| 获取requestBody参数 | ExpressionValueMethodArgumentResolver | 1.@RequestPart注解标注的参数 2.MultipartFile类型参数 3.Servlet3.0的javax.servlet.http.Part类型参数 |
| 获取requestBody参数 | RequestResponseBodyMethodProcessor | 1.@RequestBody标注的参数 2.@ResponseBody标注的方法 |
| 获取requestBody参数 | HttpEntityMethodProcessor | 1.HttpEntity和RequestEntity类型的参数 2.返回HttpEntity和ResponseEntity类型的方法 |
参数解析器的实质是一个接口HandlerMethodArgumentResolver,里面包含两个接口方法首先通过supportsParameter判断是否支持这种参数,如果支持的话调用resolveArgument来解析。

回到源码中适配器方法的逐级调用,最终是通过invokeForRequest()真正调用目标方法:
@Nullable
public Object invokeForRequest(NativeWebRequest request, @Nullable ModelAndViewContainer mavContainer, Object... providedArgs) throws Exception {
//通过该方法封装参数
Object[] args = this.getMethodArgumentValues(request, mavContainer, providedArgs);
if (this.logger.isTraceEnabled()) {
this.logger.trace("Arguments: " + Arrays.toString(args));
}
return this.doInvoke(args);
}
其中,通过调用getMethodArugumentValues()封装方法的参数,之后就将参数传入目标方法,通过反射doInvoke调用了。我们继续进入方法源码:
protected Object[] getMethodArgumentValues(NativeWebRequest request, @Nullable ModelAndViewContainer mavContainer,
Object... providedArgs) throws Exception {
MethodParameter[] parameters = getMethodParameters();
if (ObjectUtils.isEmpty(parameters)) {
return EMPTY_ARGS;
}
Object[] args = new Object[parameters.length];
for (int i = 0; i < parameters.length; i++) {
MethodParameter parameter = parameters[i];
parameter.initParameterNameDiscovery(this.parameterNameDiscoverer);
args[i] = findProvidedArgument(parameter, providedArgs);
if (args[i] != null) {
continue;
}
//遍历所有参数解析器判断是否支持解析该方法参数
if (!this.resolvers.supportsParameter(parameter)) {
throw new IllegalStateException(formatArgumentError(parameter, "No suitable resolver"));
}
try {
//若支持则调用对应参数解析器的解析方法,解析参数值
args[i] = this.resolvers.resolveArgument(parameter, mavContainer, request, this.dataBinderFactory);
}
catch (Exception ex) {
// Leave stack trace for later, exception may actually be resolved and handled...
if (logger.isDebugEnabled()) {
String exMsg = ex.getMessage();
if (exMsg != null && !exMsg.contains(parameter.getExecutable().toGenericString())) {
logger.debug(formatArgumentError(parameter, exMsg));
}
}
throw ex;
}
}
return args;
}
上述方法中首先通过==getMethodParameters()==获取到Controller方法的方法参数数组parameters,其内包含每一个参数的索引位置、类型、标注的注解等;然后创建了一个Object数组,遍历parameters进行初始化、使用名称发现器确定参数名,关键步骤是 通过supportsParameter()遍历所有参数解析器,挨个调用supportsParameter()方法,判断是否存在支持解析该方法参数的参数解析器。若存在则找到对应参数解析器并调用其resolveArgument()方法解析参数(并放入缓存)。 supportsParameter()遍历参数解析器的源码:
private HandlerMethodArgumentResolver getArgumentResolver(MethodParameter parameter) {
HandlerMethodArgumentResolver result = (HandlerMethodArgumentResolver)this.argumentResolverCache.get(parameter);
if (result == null) {
Iterator var3 = this.argumentResolvers.iterator();
while(var3.hasNext()) {
HandlerMethodArgumentResolver resolver = (HandlerMethodArgumentResolver)var3.next();
//确认支持该参数后,会把参数和对应参数解析器放入缓存
if (resolver.supportsParameter(parameter)) {
result = resolver;
this.argumentResolverCache.put(parameter, resolver);
break;
}
}
}
return result;
}
确认支持该方法参数的参数解析器后,调用其解析方法,解析过程比较繁琐,依次解析参数名和参数的值,解析参数值时又用到底层的BeanExpressionResolver等,我们不做深究。只需知道,最终解析是调用确定的HandlerMethodArgumentResolver的resolveArgument方法即可。
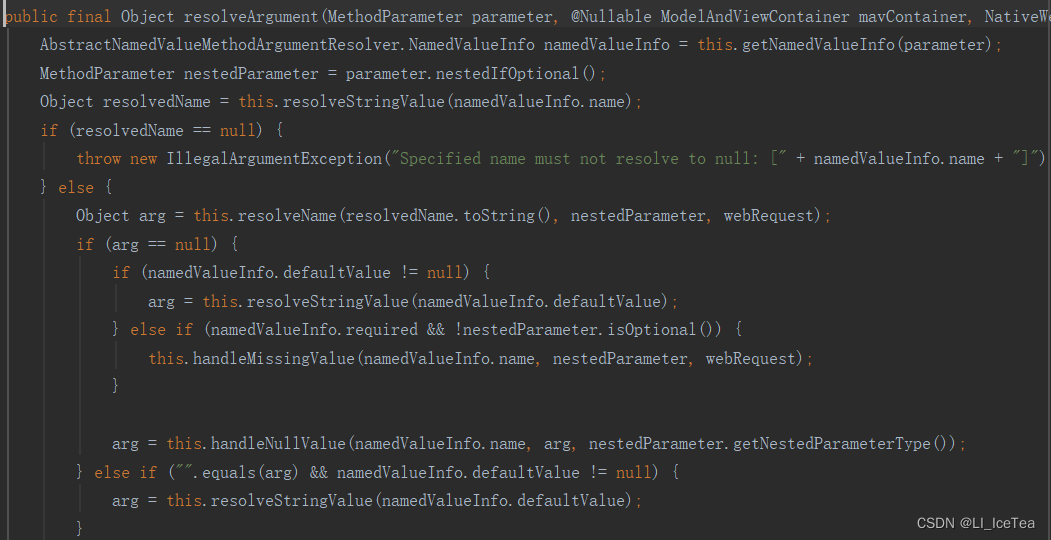
需要补充一点的是,当我们给方法中注入复杂参数时(如Model和Map),map、model里面的数据会被放在request的请求域,相当于request.setAttribute。我们再讲解一下SpringBoot中是如何将他们放入到请求域中的呢?其具体实现原理在后文响应处理中讲解,这里做一下简单说明。其实也是通过参数解析器实现的,只不过Model和Map使用的是Model/MapMethodProcessor解析器,他们的resolveArgument()方法比较特殊,我们来看一下:

处理时会返回mavContainer.geModel(),即ModelAndMapContainer,查看该类的getModel()发现最终返回的是BindingAwareModelMap(),该类既是Model也是Map
private final ModelMap defaultModel = new BindingAwareModelMap();
将携带数据的BindingAwareModelMap封装到目标方法中,并doInvoke()执行目标方法。特殊的地方在于,执行完目标方法后,BindingAwareModelMap的值会保存在ModelAndMapContainer(mavContainer)中,并在处理返回结果时将mavContainer传入,具体方法是通过processDispatchResult()
简单总结:复杂参数使用xxxMethodProcessor解析,其resolveArgument()较为特殊,会返回一个mavContainer.getModel()方法,Map/Model方法会封装在Model中,ModelAndViewContainer封装成ModelAndView又层层包装为mergedModel(本质是Map<String,Object>),在响应处理中有一步渲染视图,渲染视图时会将mergedModel中的每一个(k,v)数据放在Request请求域中。
参数解析过程总结:
SpringMVC功能的起点都是doDispatch()方法
- 请求映射:获取匹配当前请求的Handler处理器(mappedHandler)
- 寻找匹配的适配器:遍历所有适配器HandlerAdapter(适配器设计模式),并调用其support()方法看是否支持处理当前handler()方法(support源码中判断当前handler是否为HandlerMethod类型)
- 调用适配器的handle方法:找到支持的适配器HandlerAdapter并调用其ha.handle()方法
- 方法逐级调用:handle()——>handleInternal()——>invokeHandlerMethod()*
(该方法封装了默认的参数解析器和返回值处理器)——>invokeForRequest()(获取方法参数值后通过反射调用目标方法)
——>getMethodArgumentValues()(参数解析核心方法) - 获取目标方法参数数组:getMethodParameters()获取到Controller方法的方法参数数组parameters,包含每一个参数的索引位置、类型、标注的注解
- 遍历参数解析器判断是否支持解析当前参数:针对每个参数遍历所有参数解析器,挨个调用HandlerMethodArgumentResolver的supportsParameter()方法,判断是否存在支持解析该参数的参数解析器。
- 调用支持的参数解析器的解析方法:若存在则找到对应参数解析器并调用其resolveArgument()方法解析参数(并放入缓存)
原理图:

参数解析原理图
2.3自定义类型参数处理
首先我们来看一下应用场景,如果我们希望前端提交的信息直接与我们自定义的Bean对象绑定,并自动完成属性注入,SpringBoot能否自动实现呢?如下图所示:
/** * 姓名: <input name="userName"/> <br/> * 年龄: <input name="age"/> <br/> * 生日: <input name="birth"/> <br/> * 宠物姓名:<input name="pet.name"/><br/> * 宠物年龄:<input name="pet.age"/> */
@Data
public class Person {
private String userName;
private Integer age;
private Date birth;
private Pet pet;
}
@Data
public class Pet {
private String name;
private String age;
}
在正式解析原理之前,我们要明确一点,自定义类型参数封装注入的前期流程和一般参数是一样的,只是采用的参数解析器不同。
原理解析:
自定义类型参数所使用的参数解析器是ServletModelAttributeMethodProcessor,我们依然关注该参数解析器的两个接口方法,首先看一下它的supportsParameter()方法,查看它支持处理哪种类型的参数:
public boolean supportsParameter(MethodParameter parameter) {
//关注最后一个判断是否是简单属性,非简单属性则返回true代表能处理
return parameter.hasParameterAnnotation(ModelAttribute.class) || this.annotationNotRequired && !BeanUtils.isSimpleProperty(parameter.getParameterType());
}
该方法的逻辑为,首先判断是否标注了==@ModelAttribute==注解,如果没标注并且注解不是必须的,则判断是否是简单属性,非简单属性则返回true代表能处理。因此,其supportsParameter()表示该参数解析器(实际上包括ModelAttributeMethodProcessor父类下的所有子类)可以处理自定义类型参数。具体简单类型包括哪些,我们也可以查看源码确认:
public static boolean isSimpleValueType(Class<?> type) {
return (Void.class != type && void.class != type &&
(ClassUtils.isPrimitiveOrWrapper(type) ||
Enum.class.isAssignableFrom(type) ||
CharSequence.class.isAssignableFrom(type) ||
Number.class.isAssignableFrom(type) ||
Date.class.isAssignableFrom(type) ||
Temporal.class.isAssignableFrom(type) ||
URI.class == type ||
URL.class == type ||
Locale.class == type ||
Class.class == type));
}
显然我们自定义类型不属于上述简单类型,因此判断可解析。接下来我们关注它的另一个接口方法resolveArgument()是如何进行解析的:
public final Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
Assert.state(mavContainer != null, "ModelAttributeMethodProcessor requires ModelAndViewContainer");
Assert.state(binderFactory != null, "ModelAttributeMethodProcessor requires WebDataBinderFactory");
String name = ModelFactory.getNameForParameter(parameter);
ModelAttribute ann = parameter.getParameterAnnotation(ModelAttribute.class);
if (ann != null) {
mavContainer.setBinding(name, ann.binding());
}
Object attribute = null;
BindingResult bindingResult = null;
if (mavContainer.containsAttribute(name)) {
attribute = mavContainer.getModel().get(name);
}
else {
// Create attribute instance(核心逻辑在这开始!)
//这里创建了一个初始为空的自定义类型的实例(空Person)
try {
attribute = createAttribute(name, parameter, binderFactory, webRequest);
}
catch (BindException ex) {
if (isBindExceptionRequired(parameter)) {
// No BindingResult parameter -> fail with BindException
throw ex;
}
// Otherwise, expose null/empty value and associated BindingResult
if (parameter.getParameterType() == Optional.class) {
attribute = Optional.empty();
}
bindingResult = ex.getBindingResult();
}
}
if (bindingResult == null) {
// Bean property binding and validation;
// skipped in case of binding failure on construction.
//创建数据绑定器,将请求中传入的自定义类型对象参数传入到创建的空attribute中
WebDataBinder binder = binderFactory.createBinder(webRequest, attribute, name);
if (binder.getTarget() != null) {
if (!mavContainer.isBindingDisabled(name)) {
bindRequestParameters(binder, webRequest);
}
validateIfApplicable(binder, parameter);
if (binder.getBindingResult().hasErrors() && isBindExceptionRequired(binder, parameter)) {
throw new BindException(binder.getBindingResult());
}
}
// Value type adaptation, also covering java.util.Optional
if (!parameter.getParameterType().isInstance(attribute)) {
attribute = binder.convertIfNecessary(binder.getTarget(), parameter.getParameterType(), parameter);
}
bindingResult = binder.getBindingResult();
}
// Add resolved attribute and BindingResult at the end of the model
Map<String, Object> bindingResultModel = bindingResult.getModel();
mavContainer.removeAttributes(bindingResultModel);
mavContainer.addAllAttributes(bindingResultModel);
return attribute;
}
首先尝试获取@ModelAttribute注解,若存在则将注解内容绑定到mavContainer中。若不存在,则会通过createAttribute创建一个空的自定义类型对象(如创建一个空Person对象)attribute = createAttribute(name, parameter, binderFactory, webRequest)。之后,创建了一个数据绑定器WebDataBinder,它的作用就是将请求参数的值绑定到attribute中,进而绑定到JavaBean内。
我们Debug看一下WebDataBinder的结构如下图所示:
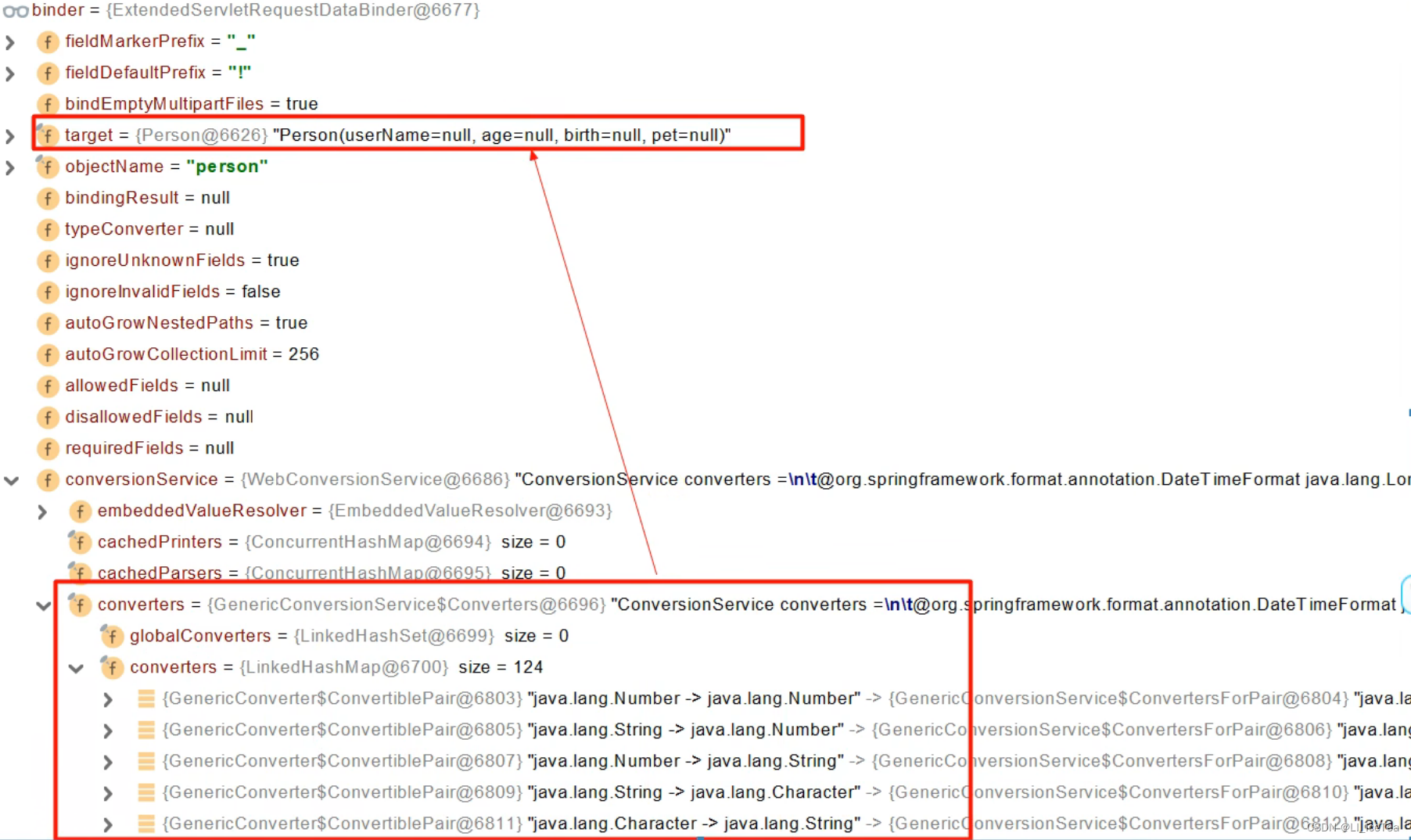
WebDataBinder工作原理:WebDataBinder实际上是通过其转换服务conversionService中的诸多转换器converters将请求数据转换成指定类型的。为什么有这么多转换器呢?这是因为,传输中我们默认使用的是HTTP协议,传输的数据默认是字符串类型,需要通过调用ConversionService里的某一个converter方法将协议中的id之类的数据转成Integer等类型。因此GenericConversionService就是在设置每一个值的时候调用canService()方法,该方法遍历所有converter哪个可以将当前数据类型(如请求携带的字符串类型参数ID,值为“10”)转换到指定的类型(如JavaBean中的Integer类型id,值为10),转换后经过复杂的层层封装和反射工具,最终调用自定义bean对象的set方法为对应属性赋值。
设计模式:策略模式:
我们在ArgumentsResolver、WebDataBinder以及ReturnValueHandler(下一章讲)中都见到了遍历所有底层组件(分别遍历了解析器、转换器、处理器)看谁能执行当前处理(处理参数、处理类型转换、处理返回值),就调用对应类的处理方法。这其实是典型的策略模式。此外,接口的设计也是典型的策略模式,不同应用对象实现同一行为可采用不同方式。其基本概念如下:
策略模式
● 背景:在不同场景下使用不同的方法解决同一问题。
● 概念:属于对象的行为模式。其用意是针对一组算法,将每一个算法封装到具有共同>接口的独立的类中,从而使得它们可以相互替换。简单的说,策略模式定义一系列的算法,把每一个算法封装起来, 并且使它们可相互替换
● 实现:策略模式把对象本身和运算规则区分开来,因此我们整个模式也分为三个部分:
1.环境类(Context):用来操作策略的上下文环境。
2.抽象策略类(Strategy):一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
3.具体策略类(ConcreteStrategy):具体的策略实现。
原理图:

自定义类型参数解析原理图
3.响应处理
上文我们介绍了请求映射的过程原理,当浏览器发送一个请求给后端,该请求首先映射匹配到一个处理器方法,又将请求中的参数与处理器方法的传入参数进行了绑定,之后通过反射调用目标方法,最后应当将方法执行结果返还给前端页面,这个过程就是响应处理。
响应处理的处理内容包括两部分:数据和视图,也就是ModelAndView,其中数据响应过程中需要依据客户端(浏览器)接收能力不同和服务端(后端程序)可产生的数据格式进行内容协商,决定数据传输的格式。因此,我们本章分为以下三个小结来介绍。
在正式开始讲解数据相应原理之前,我们先提一下前后端分离的问题,因为在这个问题直接影响到我们响应处理的内容。传统开发中,前端使用html、css、js等技术来显示后台数据,或者使用视图模板如JSP、thymeleaf等,需要我们同时返还数据和视图,或者说返回包含数据的视图;但是在前后端分离的开发模式中,往往前端可能使用Vue、React,甚至可能部署在安卓APP或H5中,此时后端往往只需要返回json格式的数据,前后端约定好接口规范,分别开发。
3.1数据响应
数据相应指的是调用目标方法后得到返回值如何处理的过程。具体来讲,如果后端只需返回json数据,我们往往可以使用@ResponseBody注解,但其本质也是通过返回值处理器来处理的,如果要返回json格式数据,只需要引入jackson或fastjson的jar包即可。具体代码应用举例,如下图所示:

原理解析:
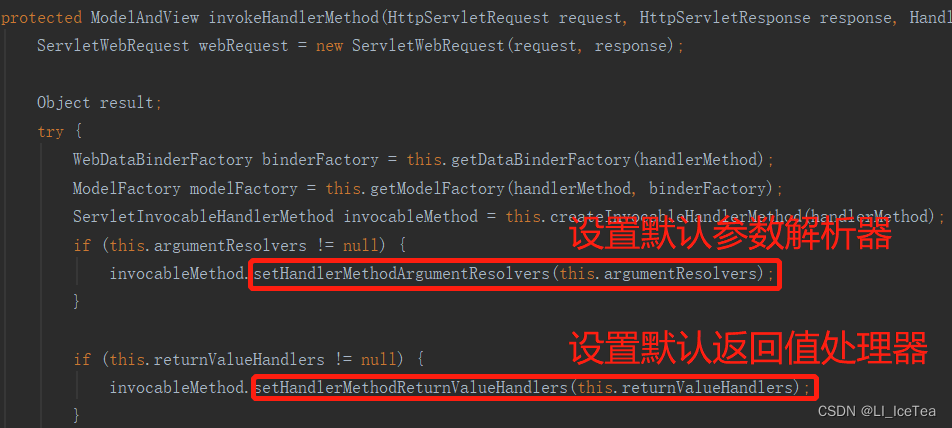
涉及原理,我们前文说到SpringMVC相关功能的起点都是DispatcherServlet类的doDispatch()方法,其内依次调用handle()、handleInternal()、invokeHandlerMethod() 方法(同请求处理部分),在invokeHandlerMethod()方法中封装了默认的参数解析器和返回值处理器:
我们通过Debug查看一下当前项目中的返回值处理器有哪些:
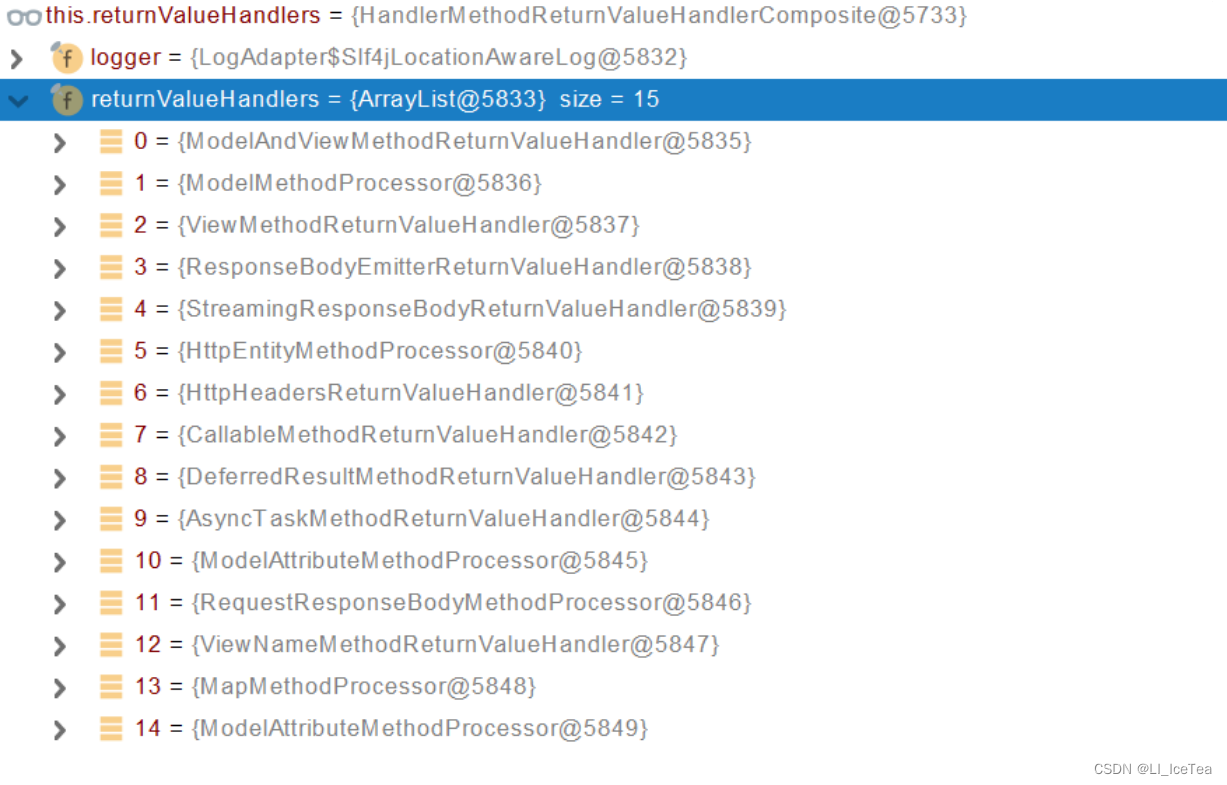
我们讲解一下常见返回值处理器的功能:
| 类型 | 名称&功能 | 支持的返回值类型 |
|---|---|---|
| 组合模式 | HandlerMethodReturnValueHandlerComposite 组合模式,调用其它返回值处理器 | 内部引用的返回值处理器支持的返回类型 |
| 写入httpHeader | HttpHeadersReturnValueHandler 写入到response的header | HttpHeaders返回类型 |
| 写入httpBody | RequestResponseBodyMethodProcessor 写入到response的body | 1.@RequestBody标注的参数 2.@ResponseBody标注方法 |
| 写入httpBody | HttpEntityMethodProcessor 写入到response的body | 1.HttpEntity和RequestEntity类型的参数 2.HttpEntity和ResponseEntity返回类型 |
| 写入springModel | ModelAttributeMethodProcessor 写入model | 1.@ModelAttribute标注的参数 2.@ModelAttribute标注的方法 3.所有非简单类型/简单类型数组(annotationNotRequired=true) |
| 写入springModel | ModelMethodProcessor 写入model | 1.Model类型参数(没有注解)2.Model返回类型 |
| 写入springModel | MapMethodProcessor 写入model | 1.Map类型参数(没有注解) 2.Map返回类型 |
| 处理异步结果 | AsyncHandlerMethodReturnValueHandler 自定义异步返回值处理器接口 | 支持自定义的异步返回类型 |
| 处理异步结果 | ResponseBodyEmitterReturnValueHandler 封装成DeferredResult,处理异步结果 | 支持自定义的异步返回类型 |
| 处理异步结果 | AsyncHandlerMethodReturnValueHandler 自定义异步返回值处理器接口 | 1.ResponseBodyEmitter/SseEmitter(异步)返回类型 2.Reactive返回类型(Spring5引入的响应式编程) 3.ResponseEntity返回类型(泛型是以上2种类型) |
| 处理异步结果 | DeferredResultMethodReturnValueHandler 封装成DeferredResult,处理异步结果 | 1.DeferredResult返回类型 2.ListenableFuture返回类型 3.CompletionStage返回类型 |
| 处理异步结果 | AsyncTaskMethodReturnValueHandler 执行WebAsyncTask中的Callable异步任务,处理异步结果 | WebAsyncTask返回类型 |
| 处理异步结果 | StreamingResponseBodyReturnValueHandler 把StreamingResponseBody封装成Callable,然后执行Callable异步任务,处理异步结果 | 1.StreamingResponseBody返回类型 2.ResponseEntity返回类型(泛型是StreamingResponseBody) |
| 处理异步结果 | CallableMethodReturnValueHandler 执行Callable异步任务,处理异步结果 | Callable返回类型 |
需要注意的是,上述返回值处理器中,除了处理异步结果的返回值处理器和写入HttpHeader的处理器外,其他的写入Model和写入HttpBody的返回值处理器都是符合类型,同时属于返回值处理器和参数解析器。例如RequestResponseBodyMethodProcessor这个处理器,该类(Processor结尾的类)比较特殊,既实现了返回值处理器顶层接口,也实现了参数解析器顶层接口;因此在参数解析器中也有该类,用来处理@RequestBody注解的参数,可直接获取POST请求中封装在请求体内的json数据(字符串);而返回值处理器中也有该类,用来处理@ResponseBody注解的方法,直接将返回值封装到响应体中。
tip:大多数以Processor结尾的同属于参数解析器和返回值处理器
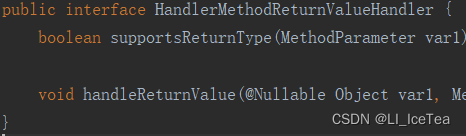
同样我们还是关注一下返回值处理器的顶层接口,其内和参数解析器的结构一模一样,两个接口方法,分别用来判断可接收的返回值类型和具体的处理返回值方法:
设置好默认的参数解析器和返回值处理器后,调用invokeForRequest()方法进行参数注入并执行目标方法,得到方法返回值,如下图所示:
public void invokeAndHandle(ServletWebRequest webRequest, ModelAndViewContainer mavContainer, Object... providedArgs) throws Exception {
//参数处理、执行目标方法,得到返回值returnValue
Object returnValue = this.invokeForRequest(webRequest, mavContainer, providedArgs);
//参数处理、执行目标方法,设置响应状态
this.setResponseStatus(webRequest);
if (returnValue == null) {
if (this.isRequestNotModified(webRequest) || this.getResponseStatus() != null || mavContainer.isRequestHandled()) {
this.disableContentCachingIfNecessary(webRequest);
mavContainer.setRequestHandled(true);
return;
}
} else if (StringUtils.hasText(this.getResponseStatusReason())) {
mavContainer.setRequestHandled(true);
return;
}
mavContainer.setRequestHandled(false);
Assert.state(this.returnValueHandlers != null, "No return value handlers");
try {
//数据响应的核心方法!
this.returnValueHandlers.handleReturnValue(returnValue, this.getReturnValueType(returnValue), mavContainer, webRequest);
} catch (Exception var6) {
if (this.logger.isTraceEnabled()) {
this.logger.trace(this.formatErrorForReturnValue(returnValue), var6);
}
throw var6;
}
}
其核心方法是handleReturnValue(),我们查看方法源码:
public void handleReturnValue(@Nullable Object returnValue, MethodParameter returnType, ModelAndViewContainer mavContainer, NativeWebRequest webRequest) throws Exception {
//策略模板:遍历所有返回值处理器调用supports方法查找支持处理当前返回值类型的处理器
HandlerMethodReturnValueHandler handler = this.selectHandler(returnValue, returnType);
if (handler == null) {
throw new IllegalArgumentException("Unknown return value type: " + returnType.getParameterType().getName());
} else {
//调用支持的返回值处理器的处理方法
handler.handleReturnValue(returnValue, returnType, mavContainer, webRequest);
}
}
首先通过selectHandler()方法判断哪个返回值处理器能处理当前返回值类型,查看源码:
private HandlerMethodReturnValueHandler selectHandler(@Nullable Object value, MethodParameter returnType) {
boolean isAsyncValue = this.isAsyncReturnValue(value, returnType);
Iterator var4 = this.returnValueHandlers.iterator();
HandlerMethodReturnValueHandler handler;
do {
do {
if (!var4.hasNext()) {
return null;
}
handler = (HandlerMethodReturnValueHandler)var4.next();
} while(isAsyncValue && !(handler instanceof AsyncHandlerMethodReturnValueHandler));
} while(!handler.supportsReturnType(returnType));
return handler;
}
果不其然,又是典型的策略模式,首先判断一下是不是异步的返回值,如果是则调用异步返回值处理器;然后通过循环遍历所有其余的返回值处理器调用supportsReturnType()方法查看哪一个返回值处理器能处理当前类型的返回值。找到支持的返回值处理器后返回,调用其处理方法:
@Override
public void handleReturnValue(@Nullable Object returnValue, MethodParameter returnType,
ModelAndViewContainer mavContainer, NativeWebRequest webRequest)
throws IOException, HttpMediaTypeNotAcceptableException, HttpMessageNotWritableException {
mavContainer.setRequestHandled(true);
ServletServerHttpRequest inputMessage = createInputMessage(webRequest);
ServletServerHttpResponse outputMessage = createOutputMessage(webRequest);
// Try even with null return value. ResponseBodyAdvice could get involved.
//核心方法调用Converter转换为最佳媒体类型
writeWithMessageConverters(returnValue, returnType, inputMessage, outputMessage);
}
该方法的核心是通过调用MessageConverters实现返回值类型转换为最佳媒体类型。所谓媒体类型就是写入到HTTP协议数据域中的数据类型,如json或xml等。这个方法的源码非常长,而且不同返回值处理器的实现也有所差异,因此这里我给大家详细叙述一下其代码逻辑:
- 调用writeWithMessageConverter:
该方法首先会判断响应头中是否有ContentType字段(即标注了响应应该以什么形式返回),如果要实现这一功能会利用拦截器做,若有则直接使用字段指定的媒体类型返回。默认这里响应头为空,为空的话则需要进行内容协商(即寻找最佳媒体类型) - 内容协商:(大致原理,详解在第二小节)
①确定浏览器可接收的媒体类型:getAcceptableMediaType().浏览器会以请求头或携带参数的方式告诉服务器他能接受什么样的内容类型,具体是请求头中的Accept字段,其中q=0.9/0.8代表权重,权重越大则代表优先接受该类型;*/*代表能接受所有类型,但权重较低。这一步的目的找出所有浏览器能接收的媒体类型,并将其放入到一个List中。
②确定服务器可产生的媒体类型:getProducibleMediaType().遍历所有messageConverter消息转换器,逐个调用canWriter()方法获取服务器端能产生的(当前方法返回值可转换的)所有内容类型List
③遍历匹配:首先从请求头中获取到所有浏览器能接收的类型List,同时服务器根据自己自身的返回值处理器获取服务器能产生的所有内容类型List;之后双重for循环遍历两个list进行匹配,某一项同时存在两个list当中即匹配成功(如json类型),代表该媒体类型是服务器可生产浏览器可接收的类型。
④最优排序:上一步可能会有多项匹配的媒体类型,如浏览器请求头支持多种媒体类型,而服务器也有多种返回值处理器可返回多种媒体类型,需要进行排序!排序的依据可以是请求头header Accpet中的q值(即quality权重)也可以是参数指定,取决于是用什么排序策略。 - 最佳媒体类型封装进响应头ContentType中
内容协商后决定了最佳媒体类型,将其放入响应头的ContentType中。 - 遍历MessageConverters寻找可转换最佳媒体类型的转换器
此时,SpringMVC会遍历所有容器底层的HttpMessageConverters,看谁能进行“最佳转换”即将当前方法返回值类型(如POJO或基本类型)转换成最佳媒体类型(如JSON或XML)。这里遍历MessageConverter寻找的原理实际上去调用的是每一个Converter的canWrite方法,看谁能将当前返回值类型转为“最佳匹配媒体类型”。 - 调用匹配转换器的Write方法
找到可以输出“最佳匹配媒体类型”的转后期后,调用其Write()方法进行转化 。
上述流程对应的部分代码如下:
HttpServletRequest request = inputMessage.getServletRequest();
//确定浏览器可接收的媒体类型
List<MediaType> acceptableTypes = this.getAcceptableMediaTypes(request);
//确定服务器可产生的媒体类型
List<MediaType> producibleTypes = this.getProducibleMediaTypes(request, valueType, (Type)targetType);
if (body != null && producibleTypes.isEmpty()) {
throw new HttpMessageNotWritableException("No converter found for return value of type: " + valueType);
}
List<MediaType> mediaTypesToUse = new ArrayList();
Iterator var15 = acceptableTypes.iterator();
MediaType mediaType;
//双重循环遍历匹配
while(var15.hasNext()) {
mediaType = (MediaType)var15.next();
Iterator var17 = producibleTypes.iterator();
while(var17.hasNext()) {
MediaType producibleType = (MediaType)var17.next();
if (mediaType.isCompatibleWith(producibleType)) {
mediaTypesToUse.add(this.getMostSpecificMediaType(mediaType, producibleType));
}
}
}
看完上述原理后你可能有些懵…对很多名词不了解…这很正常,我们一一讲解一下。关于内容协商的部分我们会在下一小节详细解析,现在我们先来解析一下MessageConverter。它被称为消息转换器,其主要功能就是实现服务端数据类型和浏览器数据类型的转换,通常使用HTTP协议进行传输,浏览器要接收的HTTP数据域中的数据类型我们称为媒体类型,来源于源码中的MediaType一词。最常用的就是HttpMesageConverters即将方法返回值类型封装成HTTP协议数据域的媒体类型。它是一个接口,其结构如下:
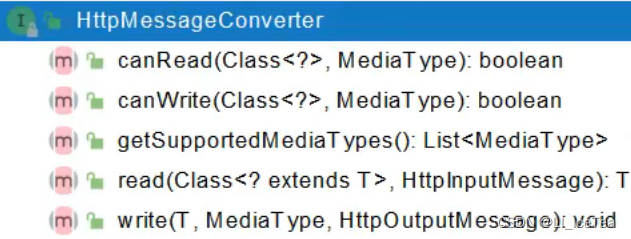
为了简化开发,HttpMessageConverter接口有两个抽象类AbstractHttpMesageConverter和AbstractHttpMessageConverter类和AbstractGenericHttpMessageConverter,它简化了开发难度。其中AbstractHttpMessageConverter抽象了用于简化对HttpMessageConverter接口的实现;经过简化后,开发人员只需要重写以下三个方法就可以了:
- supports(Class<?>):将要被转化的目标类型,是否是本转换器所支持的类型。而mediaType不需要再单独被关注,只需要它从属于AbstractHttpMessageConverter具体示例化时由构造函数传入的supportedMediaTypes范围即可
- T readInternal(Class<? extends T> , HttpInputMessage):如果supports(Class<?>)方法返回为true,则该方法才可能被触发。开发人员重写该方法,以便从HTTP请求的Body部分提取数据进行真正的数据对象转换。
- writeInternal(T , HttpOutputMessage):该方法负责将controller层方法返回的结果(或者报错结果),转换为既定的数据格式返回给本次HTTP请求的调用者。
HttpMessageCovnerters接口主要包含可读可写方法,即判断转换器是否可读入和可写出某类型(读入时表示是否支持将媒体类型作为class类型读入,写出时表示是否支持将class类型写出成媒体类型),以及对应的读写方法执行实际的数据输入与输出。还包含一个getSupportedMediaTypes(),它的作用是表示当前转换器可以输出哪种媒体类型(如xml/html等)。它也含有诸多实现类,我们来看一下本项目中包含哪些HttpMessageCovnerters实现类:
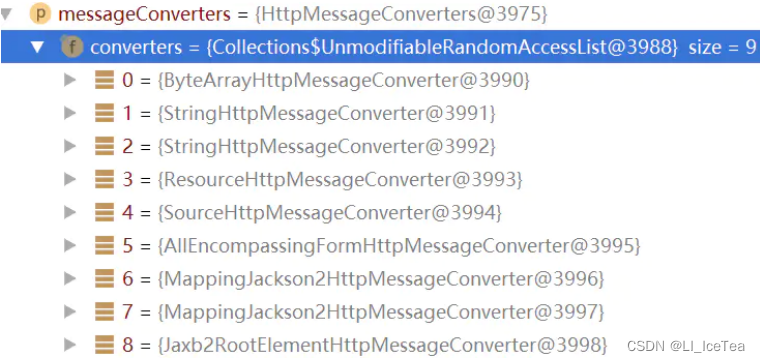
可以看到,上述converters可以输入各类数据,包括字节数组、String、刘类型、Source文件(DOMSource.class、StreamSource.class、Source.class等)、还有将java类转换为json字符串的MappingJacson2HttpMessageConverter等。
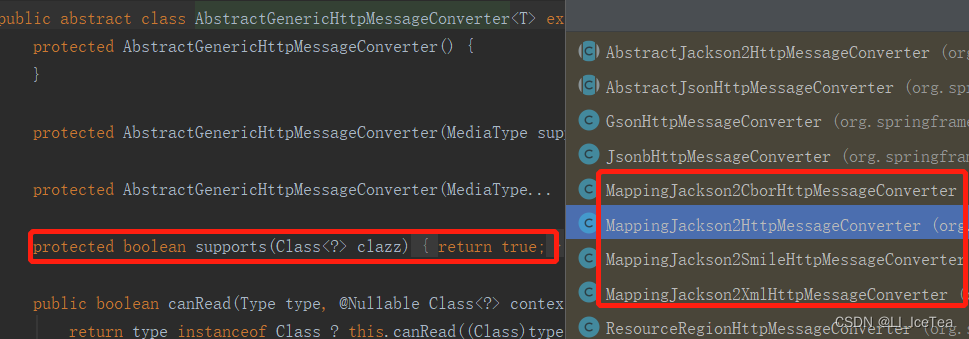
需要注意一下的是,MappingJacson2HttpMessageConverter这个类的supports方法较为特殊,它继承自AbstractGenericHttpMessageConverter抽象类,其内的supports()方法直接返回true,而它的实现类中有各种MappingJcson2xxx。可以这样理解:由于任何返回值类型(非空)都可以转为json类型。
由于内容协商还没有详细介绍,因此这里我们先做一个简略的过程总结,详细原理图放在3.2小结讲解后来详细绘制。
数据响应过程总结(简):
- 加载默认的返回值处理器
请求处理的invokeHandlerMethod()方法中,加载了默认的参数解析器和返回值处理器。 - 目标方法执行获取返回值
Object returnValue = invokeForRequest() - 遍历寻找支持的返回值处理器
执行selectHandler()方法:首先判断一下是不是异步的返回值,如果是则调用异步返回值处理器;否则循环遍历所有其余的返回值处理器逐个调用supportsReturnType()方法查看哪一个返回值处理器能处理当前类型的返回值。 - 调用支持的返回值处理器的处理方法
handler.handleReturnValue()该方法的核心是通过调用MessageConverters消息转换器实现返回值类型转换为最佳媒体类型。 - 内容协商确定最佳媒体类型:
①确定浏览器可接收的媒体类型:基于请求头/请求参数策略获取放入一个
List <MediaType>中
②确定服务器可产生的媒体类型:遍历所有messageConverter调用canWrite()方法获取服务器端能产生的所有内容类型List <MediaType>
③遍历匹配:双重循环遍历两个list进行匹配,某一项同时存在两个list当中即匹配成功(如json类型),代表该媒体类型是服务器可生产浏览器可接收的匹配类型。
④最优排序:上一步可能会有多项匹配的媒体类型,需要进行最优排序,排序策略有多种,如请求头Accpet中的q值(quality权重)等。 - 最佳媒体类型封装进响应头ContentType
- 遍历MessageConverters寻找可转换最佳媒体类型的转换器
遍历所有HttpMessageConverters逐个调用canWrite方法,看谁能将当前返回值类型转为“最佳匹配媒体类型”。 - 调用匹配转换器的Write方法
找到可以输出“最佳匹配媒体类型”的转后期后,调用其Write()方法进行转化 。
3.2内容协商
经过3.1小结的学习,相信大家也发现,内容协商是数据响应过程中的核心环节,它直接决定了数据响应的结果使用何种格式(媒体类型)。下面我们来详细解析一下其原理:
首先需要明确,如果在进行内容协商前响应头中已经有指定的媒体类型则不会进行内容协商。这类应用场景在于需要使用自定义数据格式收发数据的前后端项目,如前端为APP客户端,后端发送的数据需要首先经过加密压缩后再以特殊的自定义格式封装进响应体中,则会通过拦截器提前指定好响应头中的媒体类型,不经过内容协商。
原理解析:
内容协商的第一步就是获取浏览器可接收的媒体类型。如何获取?具体方法是getAcceptableMediaType(),我们看一下该方法的具体实现:
private List<MediaType> getAcceptableMediaTypes(HttpServletRequest request) throws HttpMediaTypeNotAcceptableException {
return this.contentNegotiationManager.resolveMediaTypes(new ServletWebRequest(request));
}
该方法实际调用的是ContentNegotiationManager类的resolveMediaTypes方法,即内容协商管理器类的解析方法:
public List<MediaType> resolveMediaTypes(NativeWebRequest request) throws HttpMediaTypeNotAcceptableException {
Iterator var2 = this.strategies.iterator();
List mediaTypes;
do {
if (!var2.hasNext()) {
return MEDIA_TYPE_ALL_LIST;
}
ContentNegotiationStrategy strategy = (ContentNegotiationStrategy)var2.next();
mediaTypes = strategy.resolveMediaTypes(request);
} while(mediaTypes.equals(MEDIA_TYPE_ALL_LIST));
return mediaTypes;
}
该方法遍历了所有的ContentNegotiationStrategy内容协商策略,其解析方法依据具体实现类的不同而有所差异,其实现类总体结构如下图所示: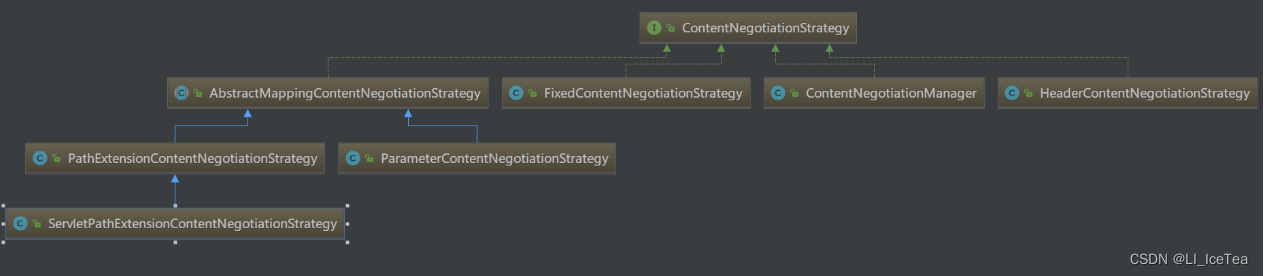
其具体实现的解析策略类及功能如下:
| 名称 | 功能 |
|---|---|
| HeaderContentNegotiationStrategy | Header-accpet请求头解析 : 负责解析request头中的accept字段 |
| FixedContentNegotiationStrategy | 固定类型解析 : 返回固定的MediaType,每个类都有一个defaultContentType,在构造函数时需要传入默认的MediaType类型 |
| ParameterContentNegotiationStrategy | parameter解析 : 根据request中的参数来判断mediaType的类型,默认的参数名为format,在其构造函数中需要传递一个mediaType的Map,在解析format时,format对应的值就会在这个map里寻找匹配MediaType。其参数名可以使用setParameterName方法注入修改。 |
| PathExtensionContentNegotiationStrategy | 路径名解析 : 根据请求路径的后缀名来判断用哪种MediaType,默认忽略未知的路径扩展名,比如说我们常见的 xx.html,xx.json ,里的.html,.json都是已知的路径扩展名,对于程序来说,只要没有匹配上就属于未知的扩展名。 |
| ServletPathExtensionContentNegotiationStrategy | 属于4的扩展,作为4的一种备用机制使用ServletContext.getMIMEType来匹配MediaType,备用机制的实现是在handlerNoMatch方法里,如果是application/octet-stream类型(比如上传文件),则不采用该备用机制。 |
例如在本项目中,其具体内容协商策略的实现类有以下三个: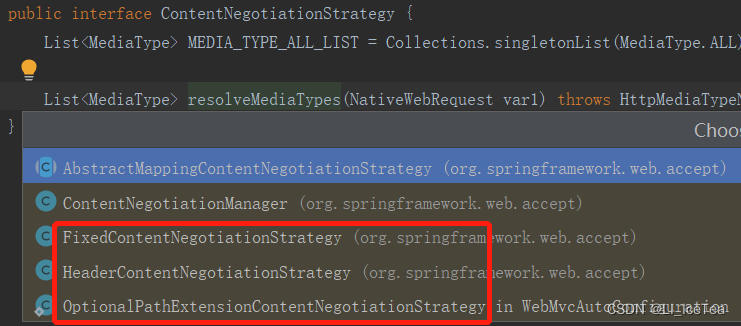
我们详解两个最常用的内容协商策略,即默认的HeaderContentNegotiationStrategy请求头策略和需配置开启的ParameterContentNegotiationStrategy基于请求参数策略。
首先是基于请求头策略,它是内容协商管理器默认使用的策略。浏览器的请求头中有一个Accpet字段,代表的是该浏览器能接收什么类型的数据,如下图所示:

图片中显示浏览器针对文本可接收html、xml格式以及图片可接收png、webp格式,最后有一个*/*代表的是任意格式数据(包括json)。虽然可接收格式有很多,但其中会有一个q值,它代表的是quality被称为品质因数,实际上也就是权重,该值越高代表浏览器更希望接收此类型。例如上图中显示,针对一个方法返回值是自定义类型pojo对象,则在服务器能产生xml和json两种媒体类型的情况下,会优先转换成xml发送。
再来介绍一下基于参数的策略。 由于默认使用的基于请求头策略是由浏览器q值决定浏览器期望媒体类型的,而在实际项目开发中,为了方便内容协商,我们可以使用请求参数来决定客户端优先接收的内容类型,需要开启基于请求参数的内容协商功能。
#application.yml中添加:
spring:
contentnegotiation:
favor-parameter: true #开启请求参数内容协商模式
并且在发送请求时携带上format字段(默认是format字段,也可自定义更改)如下所示:
http://localhost:8080/test/person?format=json
http://localhost:8080/test/person?format=xml
基于参数策略的原理是通过原生request.getParameter() 方法,参数名默认是format,获取该参数后进行解析确认浏览器可接收类型。如果想要修改,可以通过重写ContentNegotiationManager中的策略来实现自定义,或通过setParametersName更改。
经过以上步骤,内容协商管理器ContentNegotiationManager通过某一种内容协商策略ContentNegotiationStrategy确定了浏览器可接收的媒体类型,下一步就是确认服务器可产生的媒体类型,具体方法为getProducibleMediaType():
protected List<MediaType> getProducibleMediaTypes(HttpServletRequest request, Class<?> valueClass, @Nullable Type targetType) {
Set<MediaType> mediaTypes = (Set)request.getAttribute(HandlerMapping.PRODUCIBLE_MEDIA_TYPES_ATTRIBUTE);
if (!CollectionUtils.isEmpty(mediaTypes)) {
return new ArrayList(mediaTypes);
} else if (this.allSupportedMediaTypes.isEmpty()) {
return Collections.singletonList(MediaType.ALL);
} else {
List<MediaType> result = new ArrayList();
Iterator var6 = this.messageConverters.iterator();
//遍历messageConverters调用canWriter()方法
while(true) {
while(var6.hasNext()) {
HttpMessageConverter<?> converter = (HttpMessageConverter)var6.next();
if (converter instanceof GenericHttpMessageConverter && targetType != null) {
//canWriter()方法返回true则添加到List中
if (((GenericHttpMessageConverter)converter).canWrite(targetType, valueClass, (MediaType)null)) {
result.addAll(converter.getSupportedMediaTypes());
}
} else if (converter.canWrite(valueClass, (MediaType)null)) {
result.addAll(converter.getSupportedMediaTypes());
}
}
return result;
}
}
}
该方法中遍历了所有messageConverter消息转换器,逐个调用canWriter()方法获取服务器端能产生的所有媒体类型,所谓“能产生”指的其实就是当前方法返回值可转换的,并将其放入一个List中。
接下来,根据获取到的浏览器媒体类型和服务器媒体类型进行双重循环遍历,寻找所有匹配的媒体类型,匹配指的是既属于浏览器可接收同时又属于服务器可产生的媒体类型,具体判断逻辑是当某一项同时存在两个list当中即匹配成功(如json类型既属于*/*,又属于服务器MappingJackson2HttpMessageConverter可输出类型),则将其加入到匹配列表中
最后,由于匹配列表中很可能存在多项匹配的媒体类型,如浏览器请求头支持多种媒体类型,而服务器也有多种返回值处理器可返回多种媒体类型,匹配类型就有多个,需要对匹配列表进行排序!排序的依据取决于内容协商时使用的协商策略。如使用的是基于请求头的策略,则排序策略是请求头header-Accpet字段中的q值(即quality权重),若使用基于请求参数的策略,则直接选择参数指定的媒体类型。至此,获得了最佳媒体类型,内容协商过程结束。
原理图:

参数解析原理图
3.3视图解析
上文我们说过,在前后端分离的项目中,通常后端只需要返回指定格式的数据,前端使用相关技术进行页面渲染和处理。但是在传统开发或非大型项目中,我们会将数据和视图一起返回或直接跳转到指定页面,此时都需要使用到视图解析技术。
先来看一下视图解析的概念,视图解析其实就是SpringBoot某一个controller的方法执行完成之后,执行页面跳转的操作。需要注意的是,SpringBoot默认打包方式是jar包,jsp不支持在压缩包内编译的方式,因此默认不支持,需要引入第三方模板引擎才可以处理(常用的有模板引起包括:Thymeleaf、FreeMarker、Velocity、JSP等)。
原理解析:
再次明确一点,SpringMVC的所有功能都是从doDispatch()方法开始的,依次经过请求映射、参数处理、目标方法执行,之后会得到返回值(这一步同数据处理),只不过视图解析中,我们得到的返回值是一个字符串。通常该字符串的值表示我们要跳转的页面,可能只包含页面名称(如”index”),这种方式一般是配置了视图解析器前后缀,并且以转发形式进行跳转;除此以外,还可以重定向方式来跳转(如“redirect:/index.html”)。得到方法返回之后,依然是去遍历寻找支持的返回值处理器,这里返回值类型是字符串最终找到了ViewNameMethodReturnValueHandler,我们来看一下原因:
//ViewNameMethodReturnValueHandler返回值处理器的supportsReturnType方法如下:
public boolean supportsReturnType(MethodParameter returnType) {
Class<?> paramType = returnType.getParameterType();
return (void.class == paramType || CharSequence.class.isAssignableFrom(paramType));
}
因为该返回值处理器的supportsReturnType方法中判断,只要是字符串类型都支持解析,因此视图解析中会返回该处理器。之后还是调用该处理器的handleReturnValue()方法,这段源码和数据响应一致:
public void handleReturnValue(@Nullable Object returnValue, MethodParameter returnType, ModelAndViewContainer mavContainer, NativeWebRequest webRequest) throws Exception {
HandlerMethodReturnValueHandler handler = this.selectHandler(returnValue, returnType);
if (handler == null) {
throw new IllegalArgumentException("Unknown return value type: " + returnType.getParameterType().getName());
} else {
handler.handleReturnValue(returnValue, returnType, mavContainer, webRequest);
}
}
我们重点关注该处理器的的handleReturnValue()方法源码:
public void handleReturnValue(@Nullable Object returnValue, MethodParameter returnType, ModelAndViewContainer mavContainer, NativeWebRequest webRequest) throws Exception {
if (returnValue instanceof CharSequence) {
//返回值转String
String viewName = returnValue.toString();
//返回值存入ModeAndViewContainer中
mavContainer.setViewName(viewName);
if (this.isRedirectViewName(viewName)) {
mavContainer.setRedirectModelScenario(true);
}
} else if (returnValue != null) {
throw new UnsupportedOperationException("Unexpected return type: " + returnType.getParameterType().getName() + " in method: " + returnType.getMethod());
}
}
首先,将方法返回值转成String,它代表的是目标视图地址,之后将数据和视图地址全部放入ModeAndViewContainer中,视图地址存入其View属性中,数据存入Model属性中。之后会判断当前视图地址是否是重定向地址,查看其判断方法的源码:
protected boolean isRedirectViewName(String viewName) {
return PatternMatchUtils.simpleMatch(this.redirectPatterns, viewName) || viewName.startsWith("redirect:");
}
实际就是解析判断路径是否以redirect起始;如果是的话则设置RedirectModelScenario(直译为转发模型传感器)为true(个人理解相当于一个标志位,看到该标志位后底层调用原生重定向方法response.sendRedirect())。
至此返回值处理器的工作结束,返回到invokeHandlerMethod()方法中,该方法最终会获取ViewNameMethodReturnValueHandler(或其他返回值处理器)封装的ModelAndView对象,如下图所示:

我们查看一下ModelAndView对象的结构: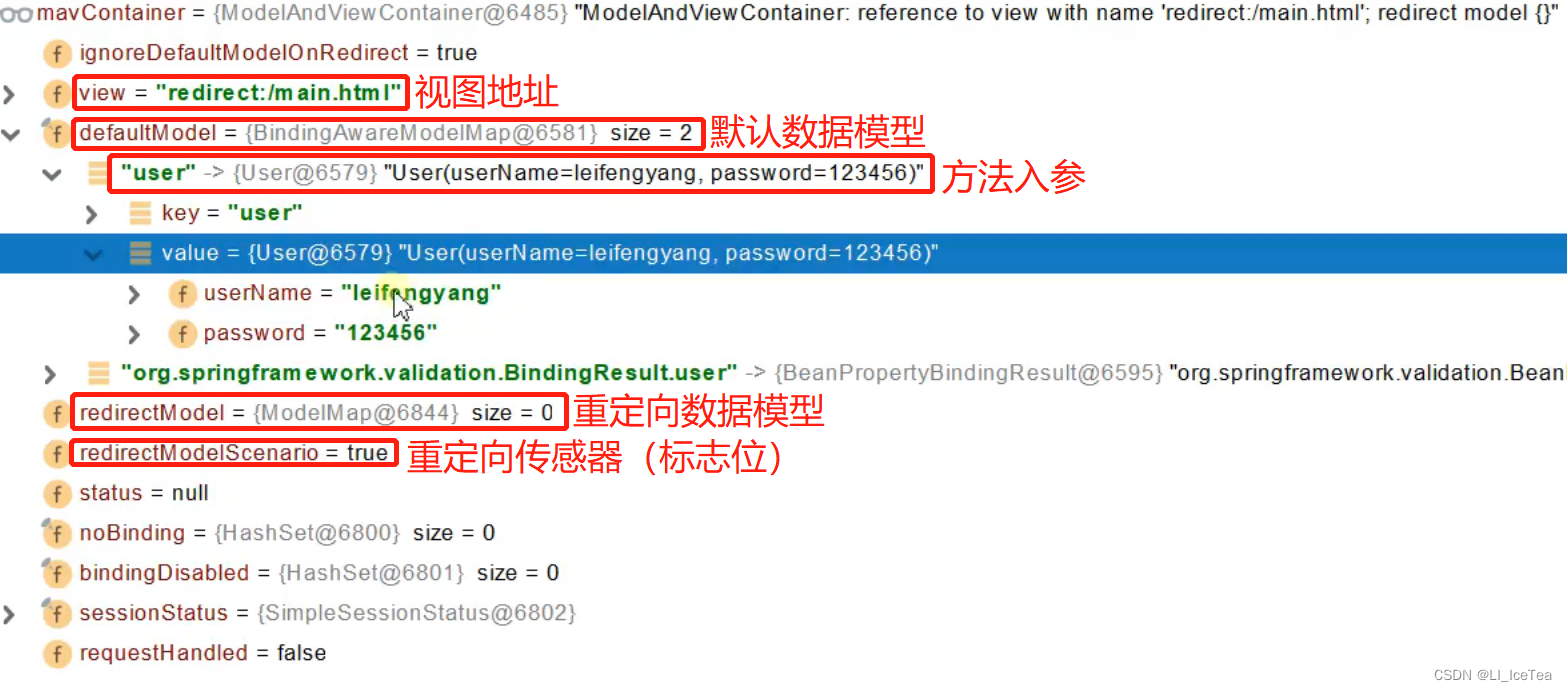
可以看到,返回值处理器操作的数据和视图地址都放进了mav对象中,如果方法的传入参数包含自定义类型对象pojo(从请求参数中确定的),则会将pojo也放在 ModelAndViewContainer中(封装在model内)。
因此,在invokeHandlerMethod()方法中显示:任何目标方法执行完成以后都会返回ModelAndView,就算目标方法没有返回值底层也会设置默认的数据和视图,默认跳转的视图地址是通过原生request请求中拿到的请求路径。(即跳转回原路径)
至此,doDisptach()方法中ha.handle()方法执行完成,之后进行处理派发结果processDispatchResult(),它决定了页面该如何响应
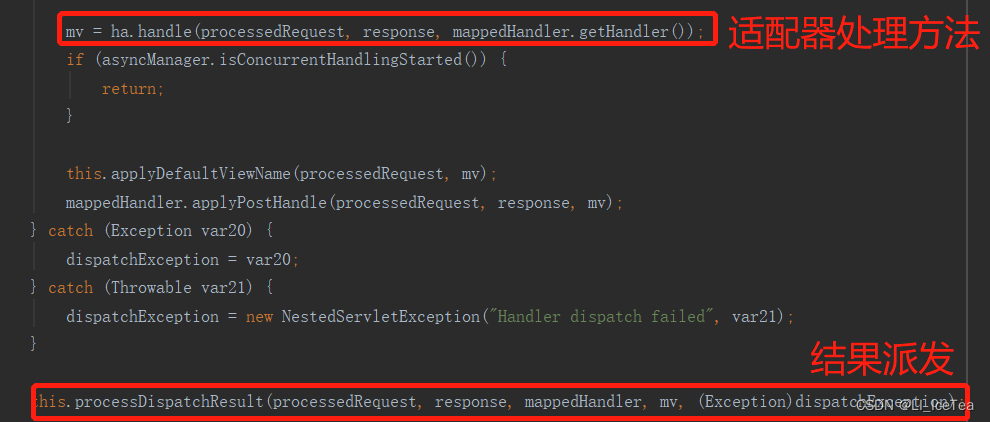
我们来查看一下处理派发结果的源码:
private void processDispatchResult(HttpServletRequest request, HttpServletResponse response, @Nullable HandlerExecutionChain mappedHandler, @Nullable ModelAndView mv, @Nullable Exception exception) throws Exception {
//判断是否处理过程存在失败步骤
boolean errorView = false;
if (exception != null) {
if (exception instanceof ModelAndViewDefiningException) {
this.logger.debug("ModelAndViewDefiningException encountered", exception);
mv = ((ModelAndViewDefiningException)exception).getModelAndView();
} else {
Object handler = mappedHandler != null ? mappedHandler.getHandler() : null;
mv = this.processHandlerException(request, response, handler, exception);
errorView = mv != null;
}
}
//ModelAndView不为空,即有实际返回值
if (mv != null && !mv.wasCleared()) {
//视图渲染:核心方法
this.render(mv, request, response);
if (errorView) {
WebUtils.clearErrorRequestAttributes(request);
}
} else if (this.logger.isTraceEnabled()) {
this.logger.trace("No view rendering, null ModelAndView returned.");
}
if (!WebAsyncUtils.getAsyncManager(request).isConcurrentHandlingStarted()) {
if (mappedHandler != null) {
mappedHandler.triggerAfterCompletion(request, response, (Exception)null);
}
}
}
该方法首先判断整个处理过程是否存在异常和错误,之后当ModelAndView不为空时进行处理,核心方法为render(),我们查看源码:
protected void render(ModelAndView mv, HttpServletRequest request, HttpServletResponse response) throws Exception {
//国际化相关参数
Locale locale = this.localeResolver != null ? this.localeResolver.resolveLocale(request) : request.getLocale();
response.setLocale(locale);
//获取之前存入mv对象的View属性即视图名
String viewName = mv.getViewName();
View view;
if (viewName != null) {
//解析得到视图对象:核心方法
view = this.resolveViewName(viewName, mv.getModelInternal(), locale, request);
if (view == null) {
throw new ServletException("Could not resolve view with name '" + mv.getViewName() + "' in servlet with name '" + this.getServletName() + "'");
}
} else {
view = mv.getView();
if (view == null) {
throw new ServletException("ModelAndView [" + mv + "] neither contains a view name nor a View object in servlet with name '" + this.getServletName() + "'");
}
}
if (this.logger.isTraceEnabled()) {
this.logger.trace("Rendering view [" + view + "] ");
}
try {
if (mv.getStatus() != null) {
response.setStatus(mv.getStatus().value());
}
view.render(mv.getModelInternal(), request, response);
} catch (Exception var8) {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Error rendering view [" + view + "]", var8);
}
throw var8;
}
}
源码中首先获取到之前存入ModeAndView中的View即视图名,之后由resolveViewName()方法获取到视图对象,查看该方法源码:
protected View resolveViewName(String viewName, @Nullable Map<String, Object> model, Locale locale, HttpServletRequest request) throws Exception {
if (this.viewResolvers != null) {
Iterator var5 = this.viewResolvers.iterator();
//遍历所有的视图解析器尝试是否有能根据当前返回值得到View对象的视图解析器
while(var5.hasNext()) {
ViewResolver viewResolver = (ViewResolver)var5.next();
View view = viewResolver.resolveViewName(viewName, locale);
if (view != null) {
return view;
}
}
}
return null;
}
又是熟悉的遍历过程,这里是遍历所有的视图解析器寻找是否有能解析当前返回值的视图解析器,即根据当前返回值得到View对象的视图解析器。
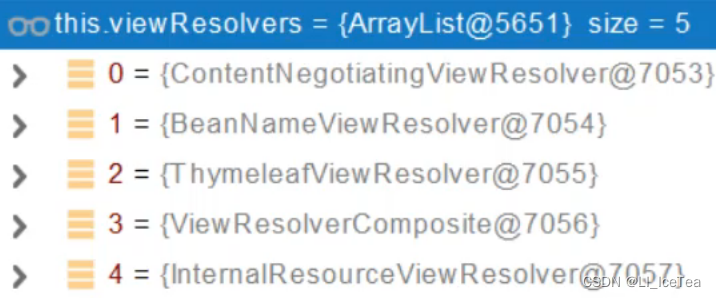
本项目中有五个视图解析器,如遍历找到了第一个ContentNegotiationViewResolver。它比较特殊,里面包含了下面四个视图解析器,内部还是遍历下面所有视图解析器判断哪个可解析。我们查看下每个视图解析器
| 分类 | 名称 | 功能 |
|---|---|---|
| 内容协商视图解析器 | ContentNegotiationViewResolver | 用于进行内容协商,其内保存了浏览器可接收的媒体类型,之后遍历其他视图解析器寻找最佳视图 |
| 自定义视图解析器 | BeanNameViewResolver | 用于查找IOC容器中是否存在返回值名称的组件,并返回自定义的视图。通过配置后,控制器返回自定义的视图的bean名,即可返回自定义的视图。 |
| 模板引擎视图解析器 | ThymeleafViewResolver | 配置后用于解析并返回Thymeleaf视图 |
| 内部资源视图解析器 | InternalResourceViewResolver | 把返回的视图名称都解析为InternalResourceView对象,InternalResourceView会把Controller处理器方法返回的模型属性都存放到对应的request属性中,然后通过RequestDispatcher在服务器端把请求forword到目标URL。一般会用来解析JSP视图。 |
我们查看一下遍历部分的源码:
if (requestedMediaTypes != null) {
List<View> candidateViews = this.getCandidateViews(viewName, locale, requestedMediaTypes);
View bestView = this.getBestView(candidateViews, requestedMediaTypes, attrs);
if (bestView != null) {
return bestView;
}
}
依次获取候选视图candidateViews和最佳视图bestView,我们依次查看源码:
private List<View> getCandidateViews(String viewName, Locale locale, List<MediaType> requestedMediaTypes)
throws Exception {
List<View> candidateViews = new ArrayList<>();
if (this.viewResolvers != null) {
Assert.state(this.contentNegotiationManager != null, "No ContentNegotiationManager set");
// 遍历视图解析器,上面有张图显示,在第1个视图解析器里面包含另外的4个视图解析器
for (ViewResolver viewResolver : this.viewResolvers) {
// 视图解析器处理视图
View view = viewResolver.resolveViewName(viewName, locale);
if (view != null) {
// 处理结果不为空则存入候选的视图
candidateViews.add(view);
}
// 内容协商MediaType提取扩展名加载View
for (MediaType requestedMediaType : requestedMediaTypes) {
List<String> extensions = this.contentNegotiationManager.resolveFileExtensions(requestedMediaType);
for (String extension : extensions) {
String viewNameWithExtension = viewName + '.' + extension;
view = viewResolver.resolveViewName(viewNameWithExtension, locale);
if (view != null) {
candidateViews.add(view);
}
}
}
}
}
// 判断是否添加默认视图
if (!CollectionUtils.isEmpty(this.defaultViews)) {
candidateViews.addAll(this.defaultViews);
}
return candidateViews;
}
源码显示获取候选视图getCandidateViews() 分为两个步骤:
- 调用各个ViewResolver中的resolveViewName()方法解析获得View对象。
- 根据MediaType提取出扩展名,再根据扩展名去加载View对象
在实际应用中,第二步我们都很少去配置,所以基本上是加载不出来View对象的,主要靠第一步。第一步去加载View对象,其实就是根据viewName,再结合ViewResolver中配置的prefix、suffix、templateLocation等属性,找到对应的 View,方法执行流程依次是 resolveViewName()->createView()->loadView()(返回值是普通字符串)。接下来调用模板引擎解析器的resolveViewName(),其内调用createView(),我们查看一下该方法的源码:
protected View createView(String viewName, Locale locale) throws Exception {
if (!this.alwaysProcessRedirectAndForward && !this.canHandle(viewName, locale)) {
vrlogger.trace("[THYMELEAF] View \"{}\" cannot be handled by ThymeleafViewResolver. Passing on to the next resolver in the chain.", viewName);
return null;
} else {
String forwardUrl;
//视图名以redirect开头,则创建RedirectView重定向视图
if (viewName.startsWith("redirect:")) {
vrlogger.trace("[THYMELEAF] View \"{}\" is a redirect, and will not be handled directly by ThymeleafViewResolver.", viewName);
forwardUrl = viewName.substring("redirect:".length(), viewName.length());
RedirectView view = new RedirectView(forwardUrl, this.isRedirectContextRelative(), this.isRedirectHttp10Compatible());
return (View)this.getApplicationContext().getAutowireCapableBeanFactory().initializeBean(view, viewName);
//视图名以forwad开头,则创建InternalResourceView视图
} else if (viewName.startsWith("forward:")) {
vrlogger.trace("[THYMELEAF] View \"{}\" is a forward, and will not be handled directly by ThymeleafViewResolver.", viewName);
forwardUrl = viewName.substring("forward:".length(), viewName.length());
return new InternalResourceView(forwardUrl);
} else if (this.alwaysProcessRedirectAndForward && !this.canHandle(viewName, locale)) {
vrlogger.trace("[THYMELEAF] View \"{}\" cannot be handled by ThymeleafViewResolver. Passing on to the next resolver in the chain.", viewName);
return null;
} else {
vrlogger.trace("[THYMELEAF] View {} will be handled by ThymeleafViewResolver and a {} instance will be created for it", viewName, this.getViewClass().getSimpleName());
return this.loadView(viewName, locale);
}
}
}
可以看到createView()方法中针对redirect:/开头和forward开头的字符串都创建了对应的视图并返回,针对都不包含的普通字符串则进一步调用loadView() 方法:
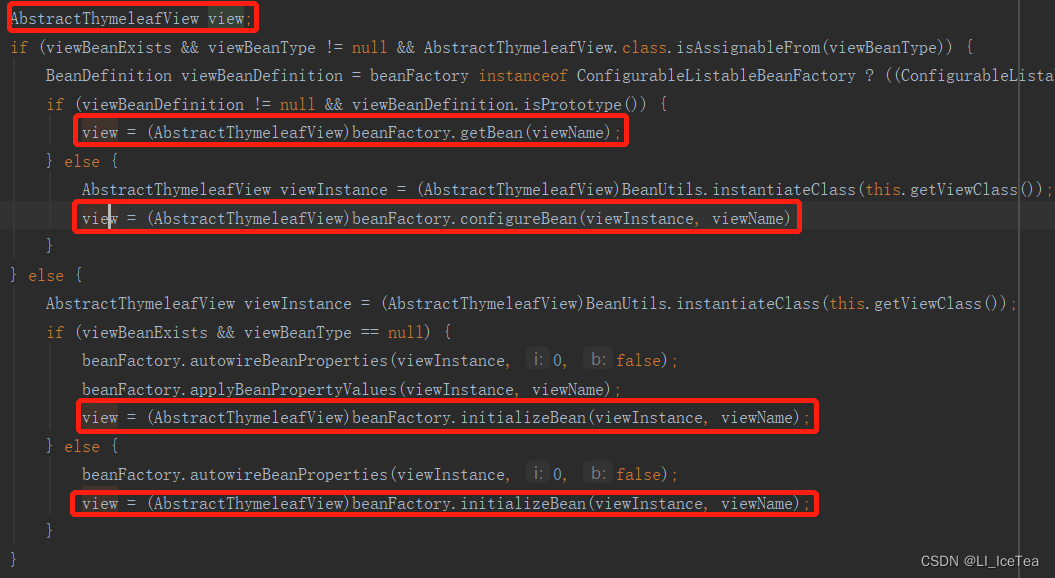
redirect:/开头——>new RedirectView() ;
forward:/开头——>new InternalResourceView()
普通字符串——> loadView()——>new TheameleafView()
当返回值结果是普通字符串时会继续调用loadView()方法,我们来看下这个方法:
protected View loadView(String viewName, Locale locale) throws Exception {
AbstractUrlBasedView view = buildView(viewName);
View result = applyLifecycleMethods(viewName, view);
return (view.checkResource(locale) ? result : null);
}
在这个方法中,View加载出来后,会调用checkResource方法判断View是否存在,如果存在就返回View,不存在就返回null。
小结一下候选视图的获取依据:遍历视图解析器依次调用resolveViewName()。解析视图名、创建视图、加载视图,并检查视图资源存在,即最后解析结果不为空时才将当前视图解析器解析的视图加入到候选列表中。
再来看一下最佳视图getBestView() 方法,从所有的候选View中找到最佳的 View。getBestView方法的逻辑比较简单,就是查找看所有View的MediaType,然后和请求的MediaType数组进行匹配,第一个匹配上的就是最佳 View,这个过程它不会检查视图是否真的存在,所以就有可能选出来一个压根没有的视图,最终导致 404。
private View getBestView(List<View> candidateViews, List<MediaType> requestedMediaTypes, RequestAttributes attrs) {
Iterator var4 = candidateViews.iterator();
while(var4.hasNext()) {
View candidateView = (View)var4.next();
if (candidateView instanceof SmartView) {
SmartView smartView = (SmartView)candidateView;
if (smartView.isRedirectView()) {
return candidateView;
}
}
}
var4 = requestedMediaTypes.iterator();
while(var4.hasNext()) {
MediaType mediaType = (MediaType)var4.next();
Iterator var10 = candidateViews.iterator();
while(var10.hasNext()) {
View candidateView = (View)var10.next();
if (StringUtils.hasText(candidateView.getContentType())) {
MediaType candidateContentType = MediaType.parseMediaType(candidateView.getContentType());
if (mediaType.isCompatibleWith(candidateContentType)) {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Selected '" + mediaType + "' given " + requestedMediaTypes);
}
attrs.setAttribute(View.SELECTED_CONTENT_TYPE, mediaType, 0);
return candidateView;
}
}
}
}
return null;
}
}
起初,我不太理解View视图中为什么会有MediaType,查阅了官方文档和其他博客后初步理解了。其在ContentNegotiatingViewResolver类中配置了一个mediaTypes这个属性,它代表的其实就是和媒体类型对应的View类型!匹配时,根据请求的后缀名和请求头类型来决定返回什么样的View。而mediaTypes这个属性存储了 请求后缀名或者参数所对应的媒体类型。(如要想返回JSON数据所代表的MappingJacksonJsonView ,我们要么在请求头中设置contentType为application/json,要么使用 **.json 或者 **?format=json )
小结一下最佳视图的获取依据:遍历候选视图的MediaType(视图支持的媒体类型)和请求中的MediaType数组,最先匹配上(出现在MediaType数组中)的候选视图即为最佳视图。
(这部分参考了知乎某文介绍候选视图与最佳视图获取
和CSDN某文《解析mediaTypes+viewResolvers+view》)
经过以上两步,我们获取到了最佳视图,之后调取最佳视图view.render()方法,这一步也是因视图不同会有所差异的,我们以ThymeleafView为例看一下视图渲染的大致逻辑。首先会创建一个HashMap用来存放Model中的数据:
//创建HashMap存放Model中的数据;创建Map存放静态变量
Map<String, Object> mergedModel = new HashMap(30);
Map<String, Object> templateStaticVariables = this.getStaticVariables();
if (templateStaticVariables != null) {
mergedModel.putAll(templateStaticVariables);
}
if (pathVariablesSelector != null) {
Map<String, Object> pathVars = (Map)request.getAttribute(pathVariablesSelector);
if (pathVars != null) {
mergedModel.putAll(pathVars);
}
}
if (model != null) {
//存入所有model数据
mergedModel.putAll(model);
}
之后设置响应头内容类型ContentType和编码CharacterEncoding;再调用模板引擎的process()方法,其内通过writer.flush() 使用字节流将页面的内容刷到缓冲区中,进而在浏览器上显示。
那么其他视图如何渲染呢?其实redirect开头和forward开头就是分别调用RedirectView和InternalResourceView的解析方法,其内还是调用原生sendRedirect()和forward() 进行视图跳转的。
视图解析流程总结:
(由于视图渲染设计方法逐级调用太多,所以流程逻辑间有些交错,使用多级列表显示)
-
方法返回值为字符串类型
通常该字符串的值表示我们要跳转的页面,可能包含forward:或redirect:或只包含页面名称 -
遍历寻找支持的返回值处理器
依然是逐个处理器调用supportsReturnType,字符串类型最终找到ViewNameMethodReturnValueHandler -
调用对应处理器的handleReturnValue()方法
将方法返回值转成String,它代表的是目标视图地址放入View属性中,数据存入Model属性中,及存入ModeAndViewContainer中- ModeAndViewContainer处理时判断是否为重定向?
实质是判断路径是否以redirect起始。如果是的话则设置RedirectModelScenario为true(个人理解相当于一个标志位)
- ModeAndViewContainer处理时判断是否为重定向?
-
得到ModelAndView
如果方法的传入参数包含自定义类型对象pojo(从请求参数中确定的),则会将pojo也放在 ModelAndViewContainer中(封装在model内)。任何目标方法执行完成以后都会返回ModelAndView,就算目标方法没有返回值底层也会设置默认的数据和视图,默认跳转的视图地址是通过原生request请求中拿到的请求路径。 -
处理派发结果
执行processDispatchResult()方法,该方法决定了页面如何响应- 方法逐级调用:
processDispatchResult()
—>DispatcherServlet.render()
——>获取mv中的View调用resolveViewName() - 遍历寻找可解析的视图解析器
遍历视图解析器尝试是否有能根据当前返回值得到View对象的视图解析器- 优先遍历ContentNegotiationViewResolver
getCandidateViews获取候选视图+getBestView获取最佳视图 - 先获取候选视图
方法内遍历其余视图解析器调用resolveViewName解析方法,若返回view不为空则加入候选视图 - 候选原理:创建视图并返回
其余视图解析器createView()。判断:以redirect开头,则创建RedirectView、以forwad开头,则创建InternalResourceView、普通字符串则进一步调用loadView()——>创建TheameleafView(模板引擎视图) - 再获取最佳视图:
getBestView()从所有的候选View中找到最佳的View:查找看所有View的MediaType,然后和请求的MediaType数组进行匹配,第一个匹配上的就是最佳 View,这个过程它不会检查视图是否真的存在,所以就有可能选出来一个压根没有的视图,最终导致 404
- 优先遍历ContentNegotiationViewResolver
- bestview.render()
调取最佳视图渲染方法- 获取Model中的数据
(如果有需要返回的数据可以通过url地址后?拼接参数的形式返回) - 获取View中目标url地址
- 底层调用页面跳转
方法返回值字符串判断:
①redircet开头:调用response.sendRedirect(encodedURL);
②forward开头:调用request.getRequestDispatcher(encodedURL).forward();
③普通字符串:通过writer.flush()方法将包含model数据的最终页面html代码写入到缓冲区中,发送到浏览器并显示
- 获取Model中的数据
- 方法逐级调用:
原理图:

视图解析原理图
4.异常处理(待更新)
首先让我们来看一下官方对于异常处理的定义:
1、默认规则
● 默认情况下,Spring Boot提供/error处理所有错误的映射
● 对于机器客户端,它将生成JSON响应,其中包含错误,HTTP状态和异常消息的详细信息。对于浏览器客户端,响应一个“ whitelabel”错误视图,以HTML格式呈现相同的数据
● 要对其进行自定义,添加View解析为error
● 要完全替换默认行为,可以实现 ErrorController 并注册该类型的Bean定义,或添加ErrorAttributes类型的组件以使用现有机制但替换其内容。
2、定制错误处理逻辑
● 自定义错误页
○ error/404.html error/5xx.html;
● @ControllerAdvice+@ExceptionHandler处理全局异常;
● 自定义实现 HandlerExceptionResolver 处理异常
翻译自:官方文档Doc——异常处理
官方文档中说明,默认情况下SpringBoot使用/error来处理所有错误的映射,该映射会根据客户端的不同响应JSON或whitelabe错误视图,其内包含错误信息。若想替换相应的错误页面,则可以将4xx.html或5xx.html页面放在/error文件夹下,SpringBoot会自动进行替换。此外,也支持自定义错误处理机制。
原理解析:
4.1自动配置原理
经过第三章第二小节的学习可以知道,所有自动配置原理都是以xxxAutoConfiguration配置类的形式生效,异常处理自动配置的配置类为ErrorMvcAutoConfiguration,它的生效条件为容器中存在DispatcherServlet,同时它激活了两个配置属性绑定ServerProperties和WebMvcProperties,如下图所示:

自动配置类中放入了一个组件(在容器中没有ErrorAttributes组件时生效)DefaultErroAttributes:

该类实现了ErrorAttributes和HandlerExceptionResolver接口

ErrorAttributes接口用来获取错误属性:
当用户业务请求出现异常,并且该异常未被Spring MVC处理,或者调用了response.sendError,Servlet容器就会构造并触发(forward)一个对错误处理页面的请求,并将如下信息添加为错误页面处理请求的属性 :
1.javax.servlet.error.request_uri – String,错误发生时所请求的URI路径
2.javax.servlet.error.exception – Throwable,所发生的错误/异常
3.javax.servlet.error.message – String,所发生的错误/异常信息 4.javax.servlet.error.status_code – Integer ,HTTP协议的状态代码
public interface ErrorAttributes {
/** @deprecated */
@Deprecated
default Map<String, Object> getErrorAttributes(WebRequest webRequest, boolean includeStackTrace) {
return Collections.emptyMap();
}
default Map<String, Object> getErrorAttributes(WebRequest webRequest, ErrorAttributeOptions options) {
return this.getErrorAttributes(webRequest, options.isIncluded(Include.STACK_TRACE));
}
Throwable getError(WebRequest webRequest);
}
HandlerExceptionResolver接口用以处理程序映射或执行期间抛出的异常。
public interface HandlerExceptionResolver {
@Nullable
ModelAndView resolveException(HttpServletRequest var1, HttpServletResponse var2, @Nullable Object var3, Exception var4);
}
从它实现的这两个接口我们就可以推测出,该组件的作用实际上就是定义错误页面中可以包含哪些数据,并添加相应的数据。具体来讲,该类中通过getErrorAttributes方法定义了最终输出的错误页面上包含哪些内容(如时间戳、状态码、异常信息、message、trace等),又通过相应的addXXX()方法添加了这些信息,源码如下:
public Map<String, Object> getErrorAttributes(WebRequest webRequest, ErrorAttributeOptions options) {
Map<String, Object> errorAttributes = this.getErrorAttributes(webRequest, options.isIncluded(Include.STACK_TRACE));
if (Boolean.TRUE.equals(this.includeException)) {
options = options.including(new Include[]{
Include.EXCEPTION});
}
if (!options.isIncluded(Include.EXCEPTION)) {
errorAttributes.remove("exception");
}
if (!options.isIncluded(Include.STACK_TRACE)) {
errorAttributes.remove("trace");
}
if (!options.isIncluded(Include.MESSAGE) && errorAttributes.get("message") != null) {
errorAttributes.put("message", "");
}
if (!options.isIncluded(Include.BINDING_ERRORS)) {
errorAttributes.remove("errors");
}
return errorAttributes;
}
ErrorMvcAutoConfiguration类中还放入了另一个组件,BasicErrorController:

查看该组件源码可发现,它是用来处理请求的,它匹配的请求路径为:配置文件中的server.rror.path或默认路径/error,这就解释了为什么默认异常处理的请求路径为/error:

该Controller中配置了一系列的处理/error请求的方法,首先如果produces属性指定返回值的编码媒体类型,也就是当请求中content-type可以接收text/html类型时将执行该方法并返回该媒体类型。这也解释了为什么浏览器错误处理时返回html页面,是由于浏览器请求的content-type中包含text/html;机器客户端发起请求则执行下面的方法直接返回ResponseEntity即编码成json字符串。 具体源码如下:
@RequestMapping(
produces = {
"text/html"}
)
public ModelAndView errorHtml(HttpServletRequest request, HttpServletResponse response) {
HttpStatus status = this.getStatus(request);
Map<String, Object> model = Collections.unmodifiableMap(this.getErrorAttributes(request, this.getErrorAttributeOptions(request, MediaType.TEXT_HTML)));
response.setStatus(status.value());
ModelAndView modelAndView = this.resolveErrorView(request, response, status, model);
return modelAndView != null ? modelAndView : new ModelAndView("error", model);
}
@RequestMapping
public ResponseEntity<Map<String, Object>> error(HttpServletRequest request) {
HttpStatus status = this.getStatus(request);
if (status == HttpStatus.NO_CONTENT) {
return new ResponseEntity(status);
} else {
Map<String, Object> body = this.getErrorAttributes(request, this.getErrorAttributeOptions(request, MediaType.ALL));
return new ResponseEntity(body, status);
}
}
@ExceptionHandler({
HttpMediaTypeNotAcceptableException.class})
public ResponseEntity<String> mediaTypeNotAcceptable(HttpServletRequest request) {
HttpStatus status = this.getStatus(request);
return ResponseEntity.status(status).build();
}
源码中可以看到,errorhtml()方法返回的是一个ModelAndView对象,其中的View名称为’error’,该View又是在哪里来的呢?同样是自动配置类注入的,且为了解析该View,还注入了视图名称解析器(按照返回的视图名作为组件的id去容器中找View对象。):
我们看一下其返回的默认Error视图,即defaultErrorView:
public void render(Map<String, ?> model, HttpServletRequest request, HttpServletResponse response) throws Exception {
if (response.isCommitted()) {
String message = this.getMessage(model);
logger.error(message);
} else {
response.setContentType(TEXT_HTML_UTF8.toString());
StringBuilder builder = new StringBuilder();
Object timestamp = model.get("timestamp");
Object message = model.get("message");
Object trace = model.get("trace");
if (response.getContentType() == null) {
response.setContentType(this.getContentType());
}
builder.append("<html><body><h1>Whitelabel Error Page</h1>").append("<p>This application has no explicit mapping for /error, so you are seeing this as a fallback.</p>").append("<div id='created'>").append(timestamp).append("</div>").append("<div>There was an unexpected error (type=").append(this.htmlEscape(model.get("error"))).append(", status=").append(this.htmlEscape(model.get("status"))).append(").</div>");
if (message != null) {
builder.append("<div>").append(this.htmlEscape(message)).append("</div>");
}
if (trace != null) {
builder.append("<div style='white-space:pre-wrap;'>").append(this.htmlEscape(trace)).append("</div>");
}
builder.append("</body></html>");
response.getWriter().append(builder.toString());
}
}
源码中通过builder.append追加写入了html文本,其内包含了页面标题“Whitelabel Error Page”、message、trace信息。
最后,自动配置类中还配置了一个DefaultErrorViewResolver:
它的作用是配置了id为error的异常页面View内的具体地址,方法源码中显示它会以“error/”拼接HTTP的状态码作为视图页地址(即View中的viewName属性),如”error/404″,因此我们可以将自定义视图放到/error路径下即可响应生效。而实际上我们可以放入“4xx”或“5xx”页面是因为底层查找时会遍历匹配所有4或5开头页面均使用此视图地址。
4.2异常处理原理
在自动配置中ErrorMvcAutoConfiguration自动配置类向容器中添加了一系列异常处理相关的组件,那么这些组件具体是如何按顺序工作的呢?我们来详解一下:
首先,我们看一下异常处理的总体逻辑。还是先关注方法执行的起点DispatcherServlet类的doDispatch()方法,其内通过doInvoke()反射调用执行目标方法,该方法中进行了异常的捕获,之后使用requestCompleted()方法标志当前请求结束;最后在外层将异常封装为dispatchException,然后执行processDispatchResult()处理派发结果,外层再捕获处理派发结果过程中的异常。源码如下:
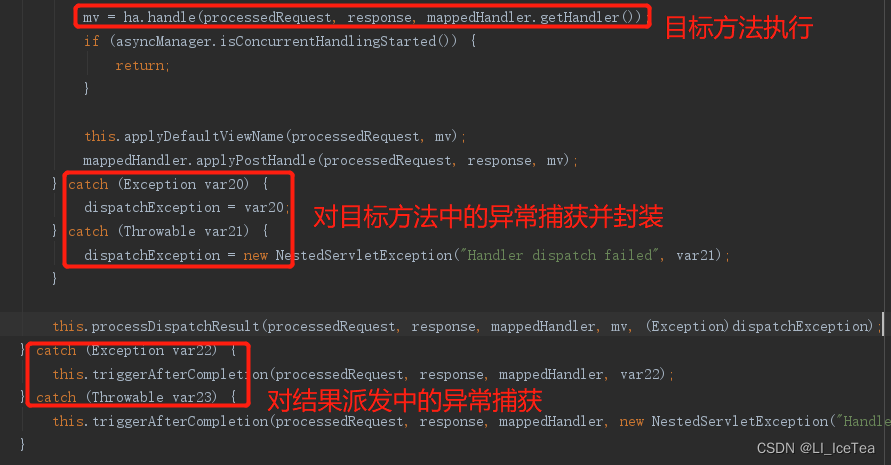
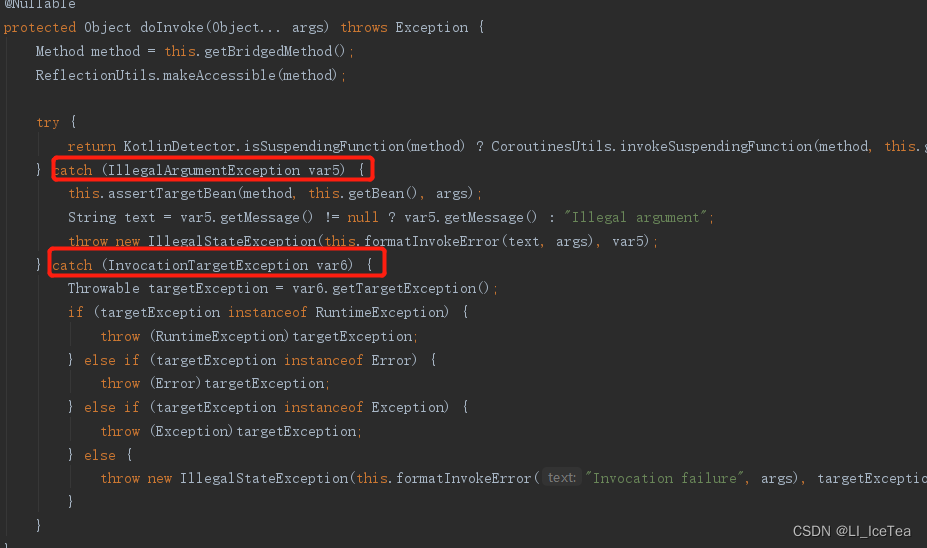
在处理派发结果的源码中,对传入的dispatchException进行了处理,源码如下:
private void processDispatchResult(HttpServletRequest request, HttpServletResponse response, @Nullable HandlerExecutionChain mappedHandler, @Nullable ModelAndView mv, @Nullable Exception exception) throws Exception {
boolean errorView = false;
if (exception != null) {
if (exception instanceof ModelAndViewDefiningException) {
this.logger.debug("ModelAndViewDefiningException encountered", exception);
mv = ((ModelAndViewDefiningException)exception).getModelAndView();
} else {
Object handler = mappedHandler != null ? mappedHandler.getHandler() : null;
//通过该方法处理异常并返回ModelAndView对象
mv = this.processHandlerException(request, response, handler, exception);
errorView = mv != null;
}
}
源码中可以看到,本质是通过调用processHandlerException()方法处理异常并返回了一个ModelAndView对象,我们查看该方法源码:
protected ModelAndView processHandlerException(HttpServletRequest request, HttpServletResponse response, @Nullable Object handler, Exception ex) throws Exception {
request.removeAttribute(HandlerMapping.PRODUCIBLE_MEDIA_TYPES_ATTRIBUTE);
ModelAndView exMv = null;
if (this.handlerExceptionResolvers != null) {
Iterator var6 = this.handlerExceptionResolvers.iterator();
while(var6.hasNext()) {
HandlerExceptionResolver resolver = (HandlerExceptionResolver)var6.next();
exMv = resolver.resolveException(request, response, handler, ex);
if (exMv != null) {
break;
}
}
}
…………
该方法中运用了我们熟悉的适配器模式,遍历所有的HandlerExceptionResolver异常处理解析器,逐个调用resolveException()方法,任一方法返回的exMv不为空则返回该mv。我们来看一下有哪些异常处理解析器:
包含默认的DefaultErrorAttributes和三个组合的HandlerExceptionResolverComposite,我们关注一下默认的异常处理器的处理方法,源码如下:
public ModelAndView resolveException(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {
this.storeErrorAttributes(request, ex);
return null;
}
private void storeErrorAttributes(HttpServletRequest request, Exception ex) {
//本质是调用原生方法向request域存放异常信息
request.setAttribute(ERROR_ATTRIBUTE, ex);
}
这里可以看到,默认的异常处理解析器中本质是实通过原生方法向request域存放了异常信息,但返回的mv对象为空,因此会继续向下遍历其他HandlerExceptionResolver,我们来看一下后面几个异常处理解析器。ExceptionHandlerExceptionResolver是用于处理 Handler中用 @ExceptionHandler 注解所修饰的方法,默认不使用。ResponseStatusExceptionResolver则用来处理Handler中用 @ResponseStatus注解所修饰的方法,当出现异常后响应对应的状态码,默认不使用。最后一个DefaultHandlerExceptionResolver则是框架用来处理一些常见的默认异常,如NoSuchRequestHandlingMethodException、
HttpRequestMethodNotSupportedException、
HttpMediaTypeNotSupportedException、
HttpMediaTypeNotAcceptableException等。
注意,这里如果没有任何一个异常处理解析器可以处理异常(返回mv不为空)则异常会被抛出,由DispatcherServlet类中的triggerAfterCompletion()方法处理,该方法实际是拦截器方法,并不是默认的异常处理。
那么如果没有任何一个异常处理解析器可以处理异常,则默认异常处理机制是怎样的的呢?实际上,当前发生异常的请求会直接结束,然后底层发起了一个地址为“/error”的请求转发(可通过debug模式查看),自动配置中注入的BasicErrorController组件专门负责处理”/error”请求,该类的处理方法源码如下:
//浏览器客户端发起请求,可支持编码类型html,返回mv
@RequestMapping(
produces = {
"text/html"}
)
public ModelAndView errorHtml(HttpServletRequest request, HttpServletResponse response) {
HttpStatus status = this.getStatus(request);
Map<String, Object> model = Collections.unmodifiableMap(this.getErrorAttributes(request, this.getErrorAttributeOptions(request, MediaType.TEXT_HTML)));
response.setStatus(status.value());
ModelAndView modelAndView = this.resolveErrorView(request, response, status, model);
return modelAndView != null ? modelAndView : new ModelAndView("error", model);
}
//非浏览器客户端发起请求,返回json字符串
@RequestMapping
public ResponseEntity<Map<String, Object>> error(HttpServletRequest request) {
HttpStatus status = this.getStatus(request);
if (status == HttpStatus.NO_CONTENT) {
return new ResponseEntity(status);
} else {
Map<String, Object> body = this.getErrorAttributes(request, this.getErrorAttributeOptions(request, MediaType.ALL));
return new ResponseEntity(body, status);
}
}
@ExceptionHandler({
HttpMediaTypeNotAcceptableException.class})
public ResponseEntity<String> mediaTypeNotAcceptable(HttpServletRequest request) {
HttpStatus status = this.getStatus(request);
return ResponseEntity.status(status).build();
}
该Controller中提供了不同方法根据发起请求的客户端支持的编码类型(媒体类型)不同,返回mv或json字符串。当发起请求的是浏览器时,支持html的文本编码类型,方法内会首先调用getErrorAttributes()方法从请求域中获取数据封装为Model,之后调用resolveErrorView()方法(传入Model)解析错误视图,该方法中遍历所有的ErrorViewResolver逐个调用resolveErrorView() 若返回的mv不为空则成功解析并将该mv作为结果显示。
protected ModelAndView resolveErrorView(HttpServletRequest request, HttpServletResponse response, HttpStatus status, Map<String, Object> model) {
Iterator var5 = this.errorViewResolvers.iterator();
ModelAndView modelAndView;
do {
if (!var5.hasNext()) {
return null;
}
ErrorViewResolver resolver = (ErrorViewResolver)var5.next();
modelAndView = resolver.resolveErrorView(request, status, model);
} while(modelAndView == null);
return modelAndView;
}
默认是用的错误视图解析器为自动装配时向容器中注入的DefaultErrorViewResolver,该解析器的解析方法为:
private ModelAndView resolve(String viewName, Map<String, Object> model) {
//错误视图的视图地址(ViewName)为"error/状态码"
String errorViewName = "error/" + viewName;
TemplateAvailabilityProvider provider = this.templateAvailabilityProviders.getProvider(errorViewName, this.applicationContext);
return provider != null ? new ModelAndView(errorViewName, model) : this.resolveResource(errorViewName, model);
}
private ModelAndView resolveResource(String viewName, Map<String, Object> model) {
String[] var3 = this.resources.getStaticLocations();
int var4 = var3.length;
for(int var5 = 0; var5 < var4; ++var5) {
String location = var3[var5];
try {
Resource resource = this.applicationContext.getResource(location);
resource = resource.createRelative(viewName + ".html");
//在资源中找到对应视图名称的视图显示
if (resource.exists()) {
return new ModelAndView(new DefaultErrorViewResolver.HtmlResourceView(resource), model);
}
} catch (Exception var8) {
}
}
return null;
}
上文所叙述的过程比较详细,而且逻辑复杂,我们以总结的形式简略概括下默认异常处理的全流程
默认异常处理流程总结:
- 自动配置加载:自动配置类ErrorMvcAutoConfiguration主要实现了两项功能:
①激活配置文件属性绑定:ServerProperties、WebMvcProperties
②向IOC容器中加载组件:DefaultErrorAttributes(存放异常信息)、BasicErrorController(处理转发的”/error”请求)、DefaultErrorViewResolver(默认错误视图解析器)、defaultErrorView(默认的错误视图) - 方法调用发生异常:DispatcherServlet.doDispatch()方法中通过doInvoke()调用目标方法,而目标方法执行过程中发生异常
- 请求结束并封装异常:requestCompleted()方法标志请求结束,并在外层将原生异常Excepton封装为dispatchException
- 处理派发结果:processDispatchResult()中传入了封装后的dispatchException,然后进行多级方法调用
- 遍历处理器异常解析器解析:处理派发结果中调用了processHandlerException(),该方法内遍历了所有HandlerExceptionResolver,逐个调用其resolverException()方法,任一返回值exMv不位空则将该ModelAndView返回
①request域存放异常信息:首先遍历到DefaultErrorAttributes,它的解析方法本质是通过调用原生的request.setAttribute()来存放异常信息,但返回null
② 自定义异常处理:HandlerExceptionResolverComposite中存放了多个处理器异常解析器,用来实现通过注解或其他方式自定义异常处理机制,包括@ExceptionHandler和@ResponseStatus等,未配置的默认情况下也都返回null - 若返回mv为空则结束当前请求:当遍历所有处理器异常解析器调用解析方法后,依然返回的mv均为空,则会直接结束当前请求
- 发起地址为“/error”的请求转发:当前请求结束后底层会进行请求转发,转发地址为“/error”
- 依据媒体类型分类处理“/error”请求:BasicErrorController专门处理“/error”请求,其内有两类Controller方法:
①如果发起请求的客户端是浏览器,即支持“text/html”的媒体类型则使用第一类方法会返回mv最终显示html页面。
(a)获取请求域中的异常数据封装为Model:第一类方法处理时,首先会通过getErrorAttributes()方法获得存放在第一次请求的请求域中的异常数据,并将其封装为Model返回
(b)遍历错误视图解析器返回ModelAndView:遍历ErrorViewResolver调用resolveErrorView()方法,默认解析器为DefaultErrorViewResolver,它解析视图地址为“error/状态码”,之后在资源中找到对应视图名称的视图,合并异常数据Model返回ModelAndView
②如果发起请求的客户端为机器或postman等不支持“text/html”媒体类型,则使用第二类方法返回ResponseEntity最终显示json字符串
- 遍历处理器异常解析器解析:处理派发结果中调用了processHandlerException(),该方法内遍历了所有HandlerExceptionResolver,逐个调用其resolverException()方法,任一返回值exMv不位空则将该ModelAndView返回
- 返回值处理:返回值处理器将mv转换为html,将ResponseEntity转换为json并传输至客户端显示
4.3自定义异常处理原理
最后说一下异常处理中的自定义实现,可自定义定制以下内容:
1.自定义错误页 :error/4xx.html或error/5xx.html;有精确的错误状态码页面就匹配精确,没有精确匹配到就启用4/5xx.html;都没有就触发白页
2.@ControllerAdvice+@ExceptionHandler:自定义全局指定类型的异常处理
3.@ResponseStatus:处理自定义类型异常
4.HandlerExceptionResolver自定义处理器异常解析器:实现自定义异常处理逻辑
5.ErrorViewResolver自定义错误视图解析器:实现自定义错误视图匹配的处理逻辑
1.自定义错误页原理:
自定义错误页的具体操作是将需显示的错误页面放在/error或template/error(启用了模板引擎时为此路径)下,命名为具体状态码如“404” “500”或宽泛命名“4xx”(客户端错误)“5xx”(服务器端错误)即可。其原理也较为简单,在4.2小结中已经提到,只有当处理器异常解析器返回mv为空时,才会发起“/error”的请求转发,由BasicErrorController中遍历得到DefaultErrorViewResolver处理,它的视图处理逻辑才是拼接“/error”+状态码,才能实现自定义错误页。因此,要实现自定义错误页,需要保证未自定义处理器异常解析器HandlerExceptionResolver和错误视图解析器ErrorViewResolver,否则不会走默认的错误视图解析器也就不会生效自定义错误页
2.@ControllerAdvice+@ExceptionHandler原理:
首先,ControllerAdvice是一个合成注解,它本质上是一个@Component,会作为组件被IOC容器扫描
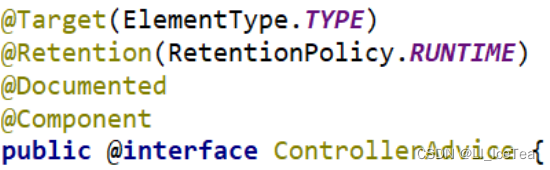 该注解本质上是aop思想的一种实现,你配置好拦截规则,我帮你把他们拦下来,具体需要通过@ExceptionHandler、@InitBinder 或 @ModelAttribute这三个注解结合使用配置以实现自定义。@ExceptionHandler用来标注处理哪些异常(如ArithmeticException.class,NullPointerException.class等)。
该注解本质上是aop思想的一种实现,你配置好拦截规则,我帮你把他们拦下来,具体需要通过@ExceptionHandler、@InitBinder 或 @ModelAttribute这三个注解结合使用配置以实现自定义。@ExceptionHandler用来标注处理哪些异常(如ArithmeticException.class,NullPointerException.class等)。
该方法的原理也比较简单,4.2小结中我们说过处理结果派发中调用方法processHandlerException(),该方法内遍历了所有HandlerExceptionResolver,首先遍历的DefaultErrorAttributes只向request域存放了异常数据并未返回mv,因此继续遍历到 ExceptionHandlerExceptionResolver它就是用来处理注解了@ExceptionHandler的异常处理方法,其内的解析方法会调用注解方法处理指定类型异常,调用结束后将结果封装为mv对象返回。 因此两个注解结合使用可实现自定义全局指定类型的异常处理的本质是通过ExceptionHandlerExceptionResolver实现的。
3.@ResponseStatus处理自定义类型异常原理
使用@ResponseStatus可以用来处理自定义异常,如在Controller方法中满足触发条件时抛出一个自定义异常,再声明该自定义异常类标注@ResponseStatus注解处理该异常,使用方式如下:
//Controller方法中抛出自定义异常
@GetMapping(value = {
"/","/login"})
public String loginPage(User user){
if(user.name="LI_IceTea"){
throw CustomException
}
return "login";
}
//声明自定义异常类并标注@ResponseStatus,可标注状态和原因等信息
@ResponseStatus(value= HttpStatus.FORBIDDEN,reason = "登录用户错误")
public class CustomException extends RuntimeException {
}
其原理基本同2,只不过 @ResponseStatus实现处理自定义类型异常本质是通过ResponseStatusExceptionResolver实现的,其解析方法把@Responsestatus注解的信息传入原生方法中,底层调用response.sendError(statusCode, resolvedReason)发送“/error”请求,由默认的BasicErrorController处理。
4.HandlerExceptionResolver自定义处理器异常解析器原理
上面讲到的2和3实际上都是使用了SpringBoot中默认装配的处理器异常解析器来实现自定义异常处理的,实际上我们也可以通过自定义类实现HandlerExceptionResolver接口,向容器中注入后生效,从而实现更灵活的自定义异常处理机制,其使用方法如下:
@Order(value= Ordered.HIGHEST_PRECEDENCE) //优先级数字越小优先级越高,用来指定resolver启用顺序
@Component
public class CustomerHandlerExceptionResolver implements HandlerExceptionResolver {
@Override
public ModelAndView resolveException(HttpServletRequest request,
HttpServletResponse response,
Object handler, Exception ex) {
try {
response.sendError(511,"自定义错误");
} catch (IOException e) {
e.printStackTrace();
}
return new ModelAndView();
}
}
自定义异常解析器工作原理也和4.2小结解析的过程一致,processHandlerException()方法内遍历了所有HandlerExceptionResolver,其中也包含我们自定义的CustomerHandlerExceptionResolver,其内通过resolveException()方法执行自定义异常处理逻辑,这里我们的处理逻辑是调用原生response.sendError()方法发送/error请求,由默认的BasicErrorController处理。
5.ErrorViewResolver 实现自定义错误视图解析器:
根据4.2小结的流程可知,如果所有处理器异常解析器均返回空的mv对象,或自定义的处理器异常解析器中调用了sendError()方法,最终都会通过发送”/error”请求进入到BasicErrorController类中处理,其内的处理方法遍历了ErrorViewResolver,默认的错误视图解析器规则是设置视图名称为“error/”+”状态码”并寻找资源。如果不想使用依据error/状态码(视图名称)寻找资源的规则,则可以自定义ErrorViewResolver 实现其他的错误页面匹配规则。
原理图:

异常处理原理图
五、参考资料
文中小段引用的文字与图片已在原文引用处注明链接,此处为学习与写作过程中的参考资料:
- 视频资料:雷神SpringBoot2视频(尚硅谷) 雷神SpringBoot2视频(b站)
- 官方文档:SpringBoot官方网站
- 中文文档: 个人翻译版官方文档
- 学习源码:雷神教程配套源码
- 文档笔记:尚硅谷语雀文档-SpringBoot
- 书籍:《深入浅出SpringBoot2.x》
- 实战系列教程:CSDN——《SpringBoot从入门到精通教程》
- 其他博客:
①王老师详解SpringBoot:王富强老师个人博客——《Spring Boot Rock’n’Roll!》
①详解前后端分离:CSDN——《前后端分离架构概述》
②SpringBoot启动过程原理:CSDN——《SpringBoot启动原理及相关流程》
③SpringMVC使用与案例:CSDN——《实例详解Spring MVC入门使用》
④SpringMVC深度探险系列文章:ITeye——《SpringMVC深度探险1-5》
联系作者指正或交流,可点击作者头像私信,或评论留言~
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189339.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
