大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
前言
什么是分类算法
通俗地讲分类算法就是把大量已知特征及类别的样本对象输入计算机,让计算机根据这些已知的类别与特征归纳出类别与特征之间的规律(准确地说应该是分类模型),最终目的是运用得到的分类模型对新输入的对象(该对象已知特征,类别是不知道的)判断出该对象所属分类。
朴素贝叶斯分类算法
分类算法常用的有很多种,朴素贝叶斯算法是其中一个比较常用的,之所以称为朴素贝叶斯算法主要是因为该算法最基本的原理是基于贝叶斯定理的,称为朴素是因为该算法成立的前提是特征之间必须得是独立的。
朴素贝叶斯(Naive Bayes)算法理论基础是基于贝叶斯定理和条件独立性假设的一种分类方法。
一、简述贝叶斯定理
贝叶斯公式如下所示:
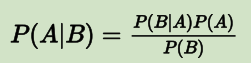

换个比较形象的形式也可如下
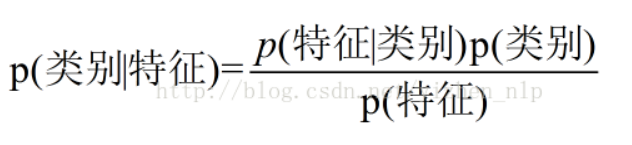
公式二很直白地说明的了贝叶斯模型的用途以及其原理。
通俗地说在 B 出现的前提下 A 出现的概率,等于 A 和 B 都出现的概率除以 B 出现的概率。
换句话说就是后验概率和先验概率的关系。
公式解说:
P(A)是先验概率,表示每种类别分布的概率;
P(B|A)是条件概率,表示在某种类别前提下,某事发生的概率;该条件概率可通过统计而得出,这里需要引入极大似然估计概念,详见后文。
P(A|B)是后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,便可对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,便越有理由把它归到这个类别下。
二、贝叶斯定理的推导
首先假设A和B为两个不相互独立的事件,做图如下:
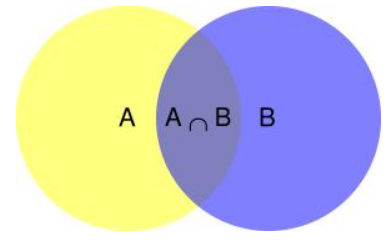
由上图可以看出,在事件B已经发生的情况下,事件A发生的概率为事件A和事件B的交集除以事件B:
同理,在事件A已经发生的情况下,事件B发生的概率为事件A和事件B的交集除以事件A:
公式解说:
通过上图图形面积可以比较形象地得出上面的公式。
由上面的公式可以得到:
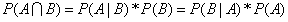
上式通过转换便可得到贝叶斯定理:
公式解说:
1、各个事件不相互独立,注意事件对应的特征是独立的。
P(AB) 表示 A,B 事件同时发生的概率,如果 A 和 B 是相互独立的两个事件,那么:
P(A|B) = P(A) 或 P(B|A) = P(B),因此要满足贝叶斯公式必需得各个事件不相互独立。
2、条件概率
条件概率是指事件A在另外一个事件B已经发生条件下的发生概率。
条件概率表示为:P(A|B),读作“在B的条件下A的概率”。若只有两个事件A,B,那么,
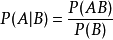
由上面的公式同样可得到如下公式,将如下公式进行转换则也可得出贝叶斯定理:
总的来说,对于贝叶斯定理可通过画图的形式直观地通过面积占比得出,也可通过严格的条件概率定理转换而来。
三、贝叶斯定理的例子说明
- 注:例子引自李烨老师机器学习极简入门第十二课,付费课程链接
例子1:
我们假设:目前的全集是一个小学的小学一年级学生。
这个小学一年级一共100人,其中有男生30人。
穿白袜子的人数一共有20个,这20个人里面,有5个是男生。
那么请问,男生里面穿白袜子的人的出现概率为多少?
这不是废话嘛,一共30个男生,5个穿白袜子,出现概率是5/30=1/6啊。用得着贝叶斯公式吗?
如果我已经把人数都告诉你了,当然没必要算什么先后验概率。
但是我先不告诉你人数,我只告诉你:
(下面用 A 指代“穿白袜子”,B 指代“是男生”)
这个小学一年级学生里面,男生的出现概率是 0.3 —— P(B);
穿白袜子的人的出现概率是0.2 —— P(A);
穿白袜子的人是男生这件事出现的概率是0.25 —— P(B|A)。
请问你,一个人是男生又穿白袜子的出现概率 —— P(A|B)是多少?
这个时候就该贝叶斯公式出场啦:
P(A|B)=P(B|A)P(A)/P(B) ==> P(A|B) = 0.25 * 0.2 / 0.3 = 1/6
另一个简单的例子
如果你问我,明明人数都知道了,为什么还要绕个弯算概率?那么再来看另一个例子。
例子2:
把场景从一个小学的一年级转换为某个大饭店的门口,我们根据以往数据,可以计算出:
所有来吃饭的所有客人中,会有10%的人喝酒 —— P(B),
所有客人中,会有20%的人驾车前来—— P(A),
开车来的客人中,会有5%喝酒 —— P(B|A)。
那么请问,在这个饭店喝过酒的人里,仍然会开车的比例—— P(A|B)是多少?
P(A|B)=P(B|A)P(A)/P(B) ==> P(A|B) = 5% * 20% / 10% = 10%
一般化的贝叶斯公式
更一般化的情况,假设事件 A 本身又包含多种可能性,即 A 是一个集合:,那么对于集合中任意的 ,贝叶斯定理可用下式表示:
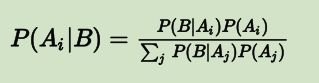
这和之前的简化版公式:
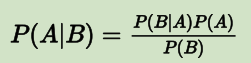
在使用上有什么区别呢?
我们还是来看一个例子
例子3:
某 AI 公司招聘工程师,来了8名应聘者,这8个人里,有5个人是985院校毕业的,另外3人不是。
面试官拿出一道算法题准备考察他们。根据以前的面试经验,面试官知道:985毕业生做对这道题的概率是80%,非985毕业生做对率只有30%。
现在,面试管从8个人里随手指了一个人——小甲,让 TA 出来做题。结果小甲做对了,那么请问,小甲是985院校毕业的概率是多大?
- 笔者解决该题的思路:首先理清该题求小甲所毕业院校实际上是根据输入的对象特征(题目做对或做错为对象特征),以及不同特征所对应的分类(对象类别:毕业于985,非毕业于985),还有目前已知的类别对应的特征概率(先验概率),求输入的对象所对应的类别。按上述思路将已知条件转换为具体数值,代入一般化的贝叶斯公式则可求出输入对象所对应类别的概率情况,求入的各个类别占比之和为1。
具体解决方法:
现在我们来看,这道题里面的小甲的毕业院校有两种可能,也就是 A={A1,A2},
A1 —— 被选中的人是985毕业的;
A2 —— 被选中的人不是985毕业的。
B —— 被选中的人做对了面试题
P(A1) = 5/8
P(A2) = 3/8
P(B|A1) = 80% = 0.8(985毕业生做对改道面试题的先验概率)
P(B|A2) = 30% = 0.3(非985毕业生做对改道面试题的先验概率)
因此:

所以,小甲是985毕业的概率是81.6%,非毕业于985为:1-0.8163
- 注意:上面的几个例子中,先验、后验事件的概率都是离散的。
- 事实上贝叶斯定理一样可以应用于连续概率的情况,假设上面的具体事件的概率不是一个确定值,而是一个分布函数,也是一样的。只不过 sum 部分变为了对应函数的积分而已。
- 连续概率的贝叶斯定理的形式为(下面所说的 A 和 B 对应之前贝叶斯公式中的的 A 与 B):
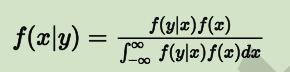
其中,f(x|y) 是给定 B=y 时,A 的后验分布;对应的 f(y|x) 是给定 A=x 时,B 的后验分布; f(x) 则是 A 的先验分布概率函数。
为了方便起见,这里的 f 在这些专有名词中代表不同的函数。
四、朴素贝叶斯分类器
“朴素贝叶斯”(Naïve Bayes)既可以是一种算法——朴素贝叶斯算法,也可以是一种模型——朴素贝叶斯分类模型(分类器)。
简洁版的贝叶斯定理:
- 在之前的几个例子中,为了便于理解,当 B 作为 A 的条件出现时,我们假定它总共只有一个特征。
- 但在实际应用中,很少有一件事只受一个特征影响的情况,往往影响一件事的因素有多个。假设,影响 B 的因素有 n 个,分别是 b1,b2,…,bn。
则 P(A|B) 可以写为:
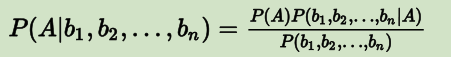
- A 的先验概率 P(A) 和多个因素的联合概率 P(b1,b2,…,bn) 都是可以单独计算的,与 A 和 bi 之间的关系无关,因此这两项都可以被看作常数。
- 对于求解 P(A|b1,b2,…,bn),最关键的是 P(b1,b2,…,bn|A)。根据链式法则,可得:
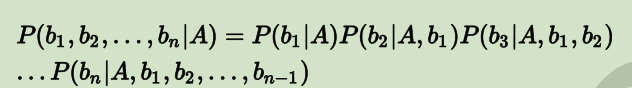
- 上面的求解过程,看起来好复杂,但是,如果从 b1 到 bn这些特征之间,在概率分布上是条件独立的,也就是说每个特征 bi与其他特征都不相关。如下图所示:
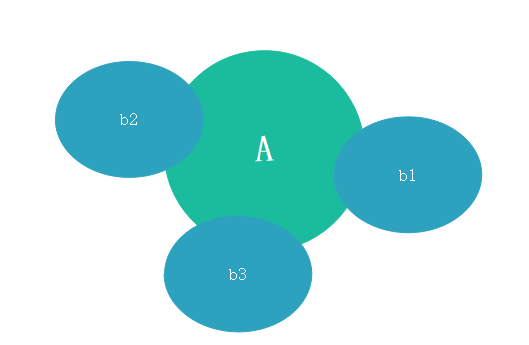
- 那么,当 i≠j 时,有 P(bi|A,bj)=P(bi|A) —— 无关条件被排除到条件概率之外,这一点由上图可以很直观地看出。因此,当 b1,b2,…,bn 中每个特征与其他 n-1 个特征都不相关时,就有:
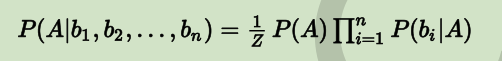
- 注:是希腊字母,即π的大写形式,在数学中表示求积运算或直积运算,形式上类似于。
- Z 对应 。
一款极简单的朴素贝叶斯分类器
上式中的 b1 到 bn 是特征(Feature),而 A 则是最终的类别(Class),所以,我们换一个写法:
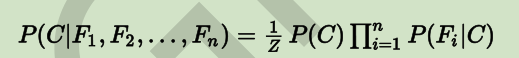
这个公式也就是我们的朴素贝叶斯分类器的模型函数!
- 注:由该公式可知,当所求的分类不同时,该式 Z 对应 P(b1,b2,…,bn)永远都是固定不变的,因此当计算对象所属类别时可直接省去该公式中的分母部分。
它用来做预测时是这样的:
-
有一个朴素贝叶斯分类模型(器),它能够区分出 k 个类 (c1,c2,…,ck), 用来分类的特征有 n 个:(F1,F2,…,Fn)。
-
现在有个样本 s,我们要用 NB 分类器对它做预测,则需要先提取出这个样本的所有特征值 F1到 Fn,将其带入到下式(因为对应不同分类的分母为固定值,所以公式可简化为如下所示)中进行 k 次运算:
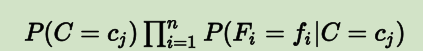
-
然后比较这 k 次的结果,选出使得运算结果达到最大值的那个 cj(j=1,2,…,k)—— 这个 cj 对应的类别就是预测值。求上式的最大值也可以用为如下公式表示:
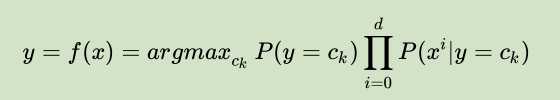 注:argmax是一种函数,函数y=f(x),x0= argmax(f(x)) 的意思就是参数x0满足f(x0)为f(x)的最大值;
注:argmax是一种函数,函数y=f(x),x0= argmax(f(x)) 的意思就是参数x0满足f(x0)为f(x)的最大值;
设我们当前有一个模型,总共只有两个类别:c1 和 c2;有三个 Feature:F1,F2和F3。F1 有两种可能性取值:f11 和 f12;F2 有三种可能性取值:f21,f22,f23;F3 也有两种可能性取值:f31,f32。
那么对于这个模型,我们要做得,就是通过训练过程,获得下面这些值:
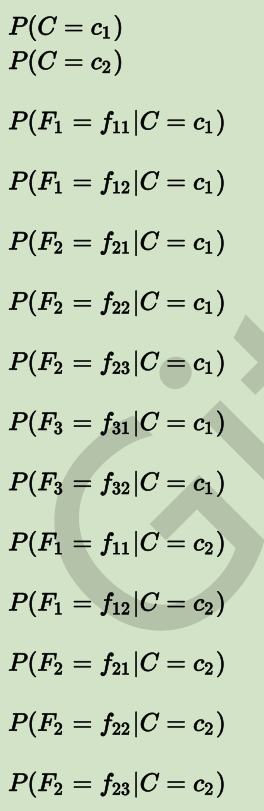
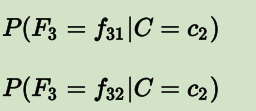
把这些概率值都算出来以后,就可以用来做预测了。

上面那些先验概率和条件概率如何得到呢?通过在训练样本中间做统计,就可以直接获得了!
现在让我们把上面那个抽象的例子具象化,来看一个新的例子,例子4:
假设有一家小公司招收机器学习工程师,为了在更广泛的范围内筛选人才,他们写了一些爬虫,去各个招聘平台、职场社交平台爬取简历,然后又写了一个简单的分类器,来筛选他们感兴趣的候选人。
这个筛选分类器是朴素贝叶斯分类器,训练数据是现在公司里的机器学习工程师和之前来面试过这一职位,没有被录取的人员的简历。
全部数据集如下图所示:

对应符号表达含义:


注:符号“∝”表示成正比例,值得注意的是P(C=c1|x)与P(C=c2|x)这两个值之和不为1是因为这里的计算并没有带入分母,这也是主里引入正比符号的原因,但是不引入分母对于实际分类的对比是没有影响的。
体现的思路是:
在训练样本的基础上做一系列概率运算,然后用这些算出来的概率按朴素贝叶斯公式“拼装”成分类模型——这就成了朴素贝叶斯分类器。
频率 VS 概率
这也太简单了吧。
朴素贝叶斯分类器这个模型的训练过程都不需要先从模型函数推导目标函数,再优化目标函数求 Cost 最小的解吗?朴素贝叶斯公式就是朴素贝叶斯分类器的训练算法啦??
上述例子之所以这样简单,是因为我们简单地将频率当成了概率。
但在现实应用中,这种方法往往不可行,因为这种方法实际上默认了“未被观测到”的就是“出现概率为0”的。这样做显然是不合理的。
比如:上面例子中,由于样本量太小,“博士”候选人只有两位,而且全部被录取,因此对于“未被录用”的情况而言,学历是博士的条件概率就变成了0。这种情况使得学历是否是博士成了唯一决定因素,显然不合理。
虽然我们可以靠做一些简单的变换——比如加一平滑法(就是把概率计算为:对应类别样本中该特征值出现次数 + 1 /对应类别样本总数)——来规避除以0的情况,但是这样做的“准确性”仍然非常不可靠。
总结
全文主要是简单描述了贝叶斯的基本思想以及推导出朴素贝叶斯分类器的基本公式如下。对于更加深入的部分详见下一篇博文。
注:本文主要是参考李烨老师的博客以及个人的理解整理出来的,目的是为了后期以便学习与回顾,参考文献如下
1、李烨老师的机器学习极简入门(付费)
2、贝叶斯定理推导(Bayes’ Theorem Induction)
5、概率论的链式法则
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/189050.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
