大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
参考代码:video_analyst
1. 概述
导读:这篇文章指出之前的一些跟踪算法没有深入讨论针对跟踪任务的实质,很多时候只是在某些点上进行突破,因而最后方法的性能总是有局限性的。对此文章深入分析了跟踪网络的特性,因而对跟踪网络的设计提出了4点建议:G1(目标位置估计和目标判别需要接耦,分别具有各自的分支)/G2(目标判别置信度不能与实际相模糊)/G3(不能依赖数据分布等先验知识,否则导致泛化性鲁棒性不强)/G4(目标位置的估计应该准确)。正是基于上的4点设计指导,文章设计了SiamFC++网络,在5个VOT数据集(OTB2015/VOT2018/LaSOT/GOT-10k)上表现为state-of-art,并且在TrackingNet大型数据集上达到75.4的AUC,在2080Ti GPU上帧率为90FPS。
对于之前的一些跟踪算法文章进行分析,大致上可以将其划分为3个大类:
- 1)以DCF(Discriminative Correlation Filter)和SiamFC为代表暴力使用多尺度测试,并且假设相邻帧上目标的尺度和比例变化比例是固定,但是这在实际中却不能成立;
- 2)以ATOM为代表使用多个bounding box进行初始化,之后迭代进行最终目标box,虽然极大提升了目标定位的准确度,但是却带来了计算量和额外的超参数(initial box的数量和分布等);
- 3)以SiamRPN++为代表使用RPN网络进行目标位置估计,但RPN网络是需要预先设置anchor超参数的,这就带来了目标辨别的不确定性以及目标尺度的先验知识(用于设计anchor的超参数);
就目前较好的跟踪网络SiamRPN文章将其与SiamFC++进行对比,见下图所示:


可以看到SiamRPN中目标的判别分数和实际的anchor是并不匹配的这就导致了其性能的缺陷。通过探究跟踪网络的性质,文章对于跟踪网络的设计给出了下面的几点指引:
- 1)G1:将目标位置估计和目标判别解耦,分别使用不同的分支进行预测;
- 2)G2:目标的置信度应该直接反应是否存在目标,而不是与预先定义的anchor之类的产生关联;
- 3)G3:不应该使用尺度/比例等数据集上的先验分布特性,从而导致其在其它数据集上泛化性能下降;
- 4)G4:直接使用ATOM类似的目标位置估计度量,而不是使用目标判别置信度,从而更加直观体现目标位置估计的准确性;
对此文章在章节“Comparison with Trackers that Do not Apply Our Guidelines”对其进行了讨论。其具体表现在SiamRPN++中主要由三点与文章提出的跟踪网络设计思路不相匹配:
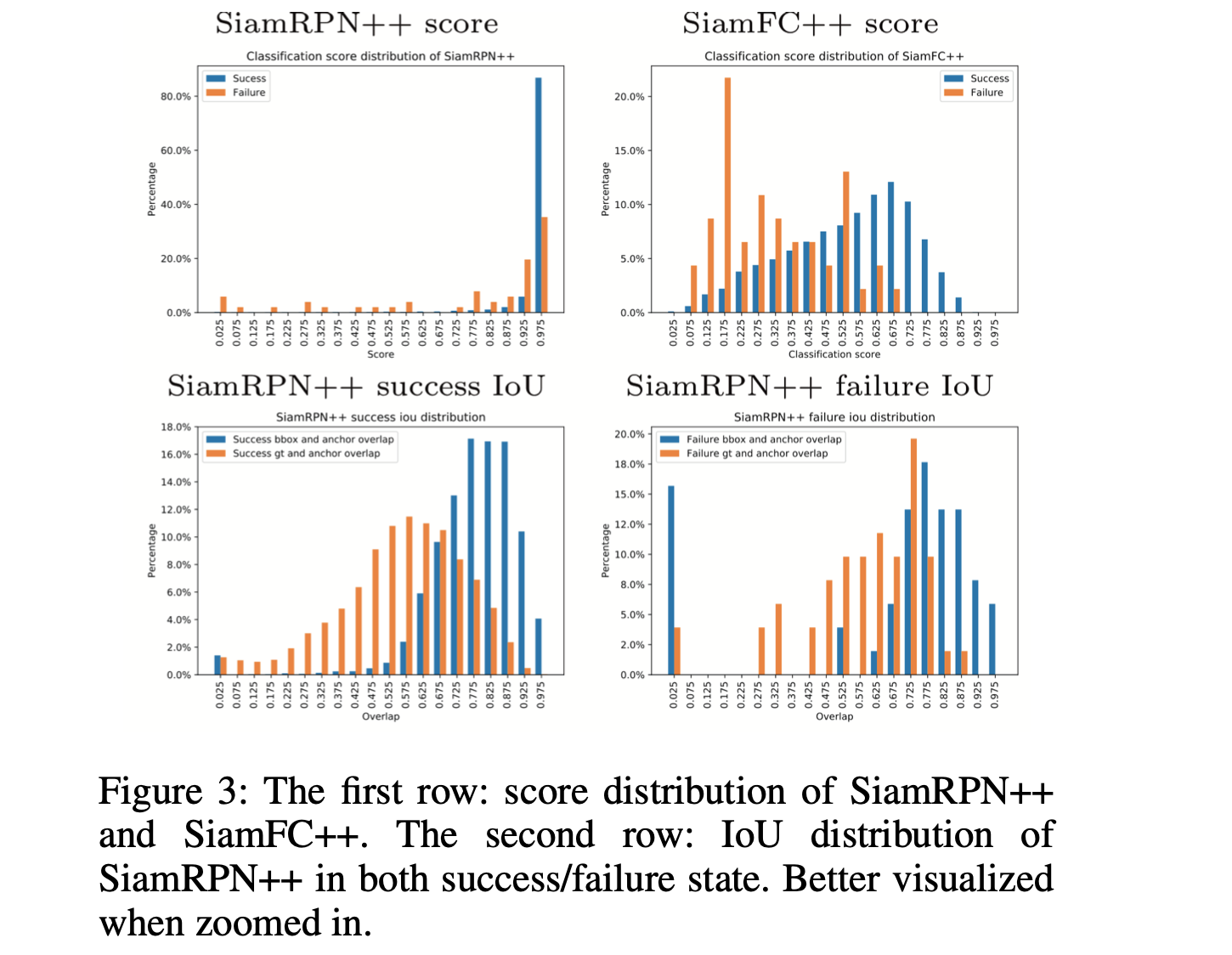
- 1)由于anchor的引入导致目标判别置信度表达的是anchor和目标的相似性,而不是目标template和实际目标的相似性。这是由于这一点SiamRPN++网络会带来一定的假阳性结果,特别是当目标的外表发生较大变化时(如旋转/形变)其在目标周围物体和背景上产生无法解释的高置信度预测结果,如图1。文章认为RPN机制匹配的是目标和anchor而不是目标和目标,因而匹配的结果就是次优的。文章统计了SiamRPN++和SiamFC++在跟踪正确与否(是否与GT有重合)的数量和目标判别置信度之间的分布关系,见图3的第一行。可以看到在SiamRPN++中错误和正确的数量分布是呈现近似的分布,而SiamFC++中则是两个较大差异的分布。此外,另一原因是特征进行匹配的时候使用的是固定的尺寸并且与之匹配的anchor也是设置好的超参数;
- 2)由于存在anchor超参数,这就导致了SiamRPN++是与anchor的设计存在关联的,进而与数据的分布存在关联。这就导致经过训练之后SiamRPN++的预测结果与anchor box有更佳高的重合度(见图3的第二行),这就导致了新能的下降;
- 3)没有直接使用目标定位的置信度而是使用目标判别的置信度,这样的方式在IoU-Net中就已经指出了其弊端,因而SiamFC++采用了预测IoU的形式;
2. 方法设计
2.1 跟踪方法pipline
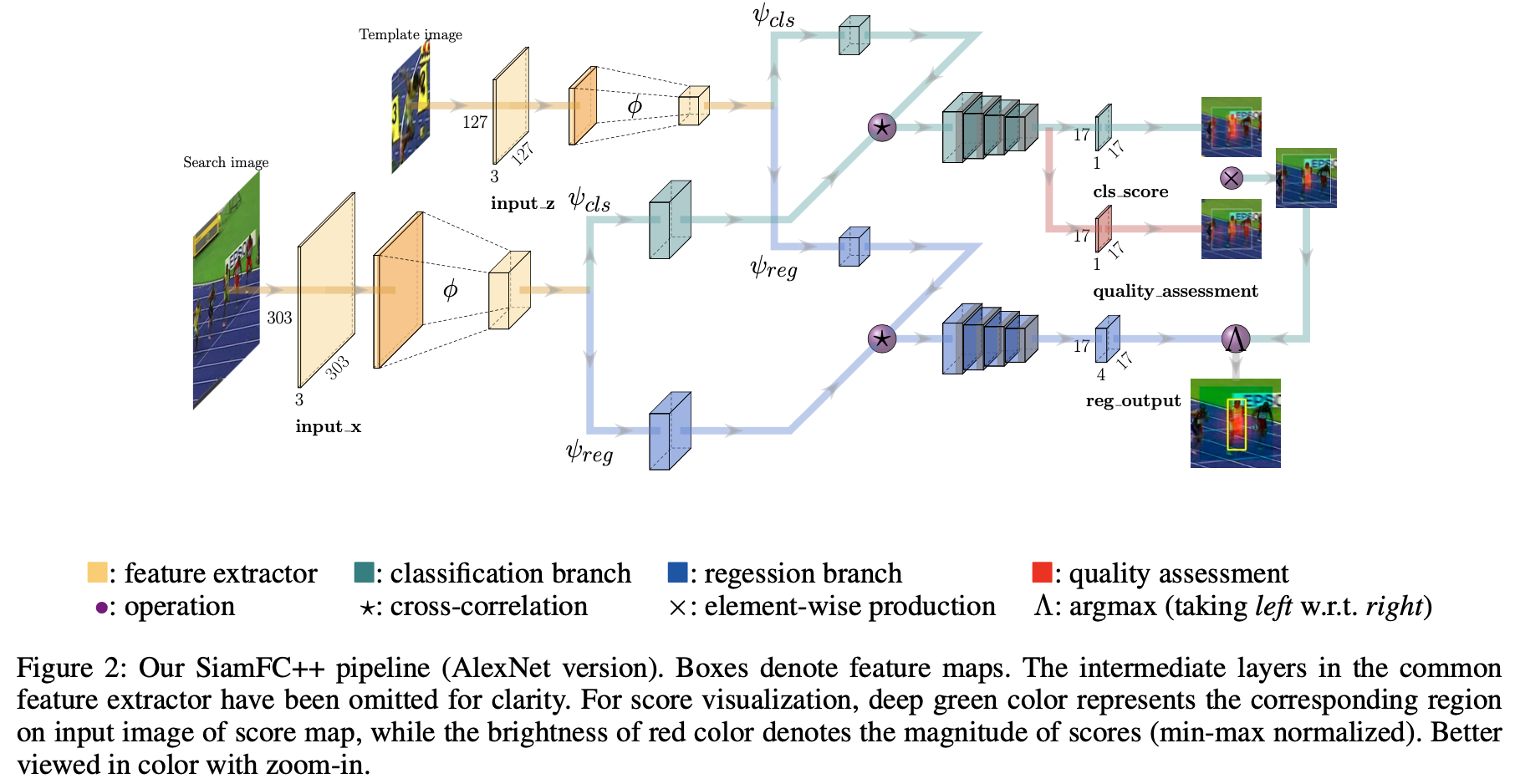
2.2 基于Siamese的特征抽取与匹配
文章的网络pipeline已经在图2中给出了,可以很明显的看到其将目标判别分支和目标位置估计分支做了隔离,则其特征抽取和匹配的过程可以描述为下式:
f i ( z , x ) = ψ i ( ϕ ( z ) ) ∗ ψ i ( ϕ ( x ) ) f_i(z,x)=\psi_i(\phi(z))*\psi_i(\phi(x)) fi(z,x)=ψi(ϕ(z))∗ψi(ϕ(x))
其中, ∗ * ∗代表cross-correlation操作, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)代表的siamese backbone输出的特征, ψ i ( ⋅ ) \psi_i(\cdot) ψi(⋅)代表对应的具体的任务分支,实现从普通的特征到特定任务空间特征的转变, i ∈ { c l s , r e g } i\in\{cls,reg\} i∈{
cls,reg}代表目标判别任务和目标位置估计任务。
2.3 依据指引设计的预测头
2.3.1 指引:G1
在图2中可以清楚看到文章已经将目标判别和目标位置估计使用不同的预测头进行区分。
目标判别分支:
对于判别分支输出特征图上的一点 ( x , y ) (x,y) (x,y),其在原图的位置经过映射为 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) (\lfloor\frac{s}{2}\rfloor+xs,\lfloor\frac{s}{2}\rfloor+ys) (⌊2s⌋+xs,⌊2s⌋+ys),要是这个点落在了GT框的内部,那么就算做是正样本,反之就是负样本了,其中 s = 8 s=8 s=8是网络的stride。
目标位置估计:
对于位置预测特征图上的一点 ( x , y ) (x,y) (x,y),其在原图上对应的点为 ( ⌊ s 2 ⌋ + x s , ⌊ s 2 ⌋ + y s ) (\lfloor\frac{s}{2}\rfloor+xs,\lfloor\frac{s}{2}\rfloor+ys) (⌊2s⌋+xs,⌊2s⌋+ys),而对应的该点出的位置GT预测值描述为 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) t^{*}=(l^{*},t^{*},r^{*},b^{*}) t∗=(l∗,t∗,r∗,b∗), ( x 0 , y 0 ) (x_0,y_0) (x0,y0)和 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)代表GT的左上角和右下角点的坐标,则对应各个GT分量的计算过程描述为:
l ∗ = ( ⌊ s 2 ⌋ + x s ) − x 0 , t ∗ = ( ⌊ s 2 ⌋ + y s ) − y 0 l^{*}=(\lfloor\frac{s}{2}\rfloor+xs)-x_0,\ t^{*}=(\lfloor\frac{s}{2}\rfloor+ys)-y_0 l∗=(⌊2s⌋+xs)−x0, t∗=(⌊2s⌋+ys)−y0
r ∗ = x 1 − ( ⌊ s 2 ⌋ + x s ) , b ∗ = y 1 − ( ⌊ s 2 ⌋ + y s ) r^{*}=x_1-(\lfloor\frac{s}{2}\rfloor+xs),\ b^{*}=y_1-(\lfloor\frac{s}{2}\rfloor+ys) r∗=x1−(⌊2s⌋+xs), b∗=y1−(⌊2s⌋+ys)
2.3.2 指引:G2/G3
对于G2文章的方法是采用密集预测的方式也就是整个特征图(每个坐标位置预测一个sample)参与,因而每个位置上是能够代表与目标位置的对应关系的,满足G2。而且正式这种不借用任何外部参数进行的预测(直接进行回归)避免了外部先验参数的引入,从而满足G3。
2.3.3 指引:G4
这里需要对目标位置估计的质量进行评估,不过这里不同于ATOM的方法(其采用IoU-Net的方法预测IoU值),这里是通过预测PSS值得到的(通过与目标判别分支的预测结果相乘使得那些背景区域的置信度更低,从而容易将其排除),这是通过在目标判别分支旁边平行加一个预测分支,其结构可以参考图2中的对应部分。其对应的标注生成过程可以描述为:
P S S ∗ = m i n ( l ∗ , r ∗ ) m a x ( l ∗ , r ∗ ) ∗ m i n ( t ∗ , b ∗ ) m a x ( t ∗ , b ∗ ) PSS^{*}=\sqrt{\frac{min(l^{*},r^{*})}{max(l^{*},r^{*})}*\frac{min(t^{*},b^{*})}{max(t^{*},b^{*})}} PSS∗=max(l∗,r∗)min(l∗,r∗)∗max(t∗,b∗)min(t∗,b∗)
2.4 训练和预测
文章采用的损失函数为:
L ( { p x , y } , q x , y , { t x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + λ N p o s 1 { c x , y ∗ > 0 } ∑ x , y L q u a l i t y ( q x , y , q x , y ∗ ) + λ N p o s 1 { c x , y ∗ > 0 } ∑ x , y L r e g ( t x , y , t x , y ∗ ) L(\{p_{x,y}\},q_{x,y},\{t_{x,y}\})=\frac{1}{N_{pos}}\sum_{x,y}L_{cls}(p_{x,y},c_{x,y}^{*})+\frac{\lambda}{N_{pos}}\mathcal{1}_{\{c_{x,y}^{*}\gt 0\}}\sum_{x,y}L_{quality}(q_{x,y},q_{x,y}^{*})+\frac{\lambda}{N_{pos}}\mathcal{1}_{\{c_{x,y}^{*}\gt 0\}}\sum_{x,y}L_{reg}(t_{x,y},t_{x,y}^{*}) L({
px,y},qx,y,{
tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλ1{
cx,y∗>0}x,y∑Lquality(qx,y,qx,y∗)+Nposλ1{
cx,y∗>0}x,y∑Lreg(tx,y,tx,y∗)
其中, 1 { ⋅ } \mathcal{1}_{\{\cdot\}} 1{
⋅}代表的是该点是否为正样本,也就是是不是在GT框内部, L c l s L_{cls} Lcls表示为focal loss, L q u a l i t y L_{quality} Lquality表示为BCE loss, L r e g L_{reg} Lreg表示为IoU loss。
在测试的过程中参考了SiamRPN类的infer优化方法,使得预测的结果更加鲁棒,可以参考文章附录章节“B Test Phase Behavior”
3. 实验结果
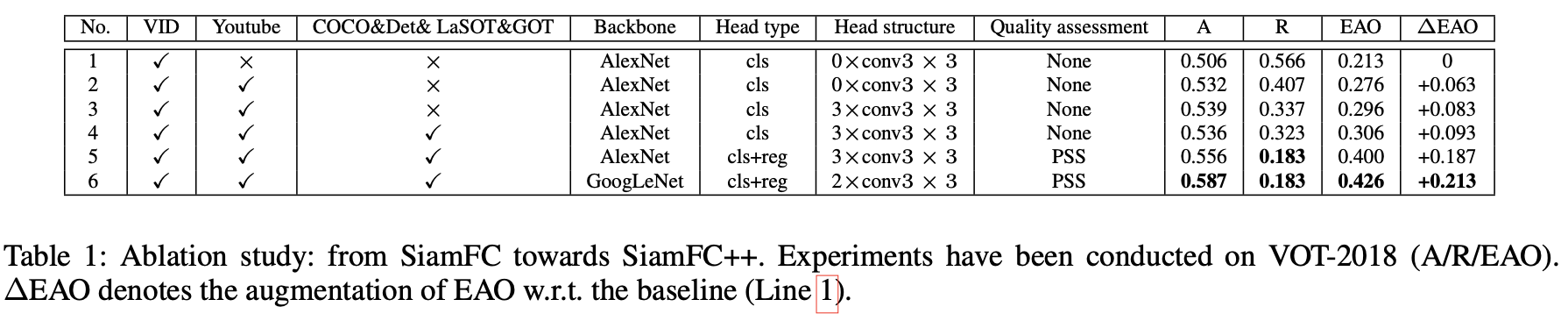
按照文章提出的网络设计指引,其各个分量对最后性能的贡献和影响:
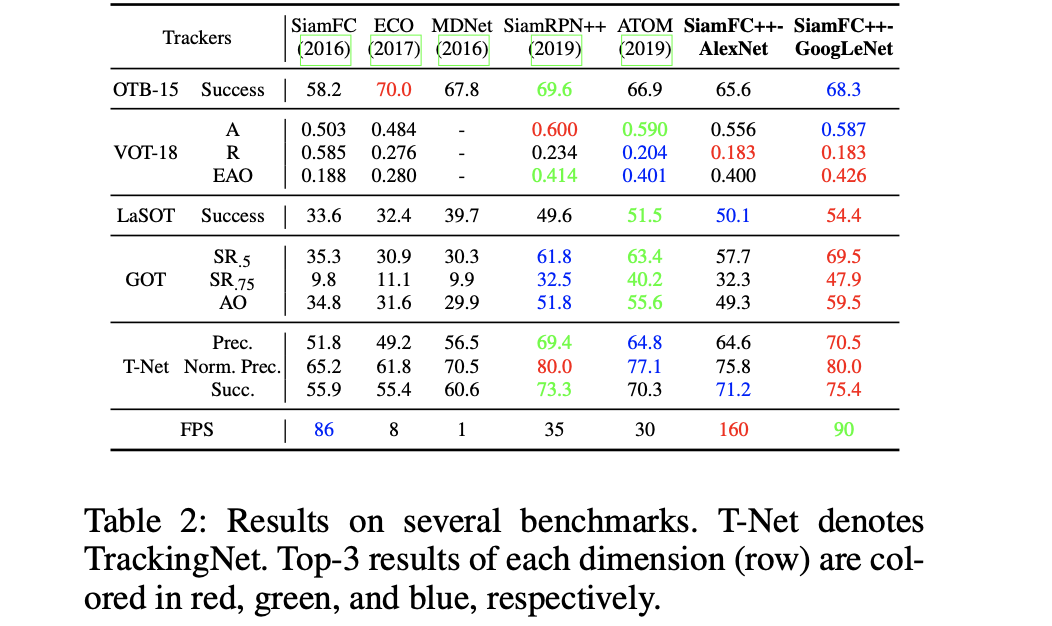
TrackingNet数据集上的性能表现与比较:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188926.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
