大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
为什么需要Source Map
首先根据谷歌开发者文档的介绍,Source Map一般与下列类型的预处理器搭配使用:
- 转译器(Babel)
- 编译器(TypeScript)
- Minifiers(UglifyJS)
为什么呢?因为通常我们运行在浏览器中的代码是经过处理的,处理后的代码可能与开发时代码相差很远,这就导致开发调试和线上排错变得困难。这时Source Map就登场了,有了它浏览器就可以从转换后的代码直接定位到转换前的代码。在webpack中,可以通过devtool选项来配置Source Map。
配置项
了解了为什么需要Source Map,我们来了了解下webpack能生成哪些类型的Source Map。
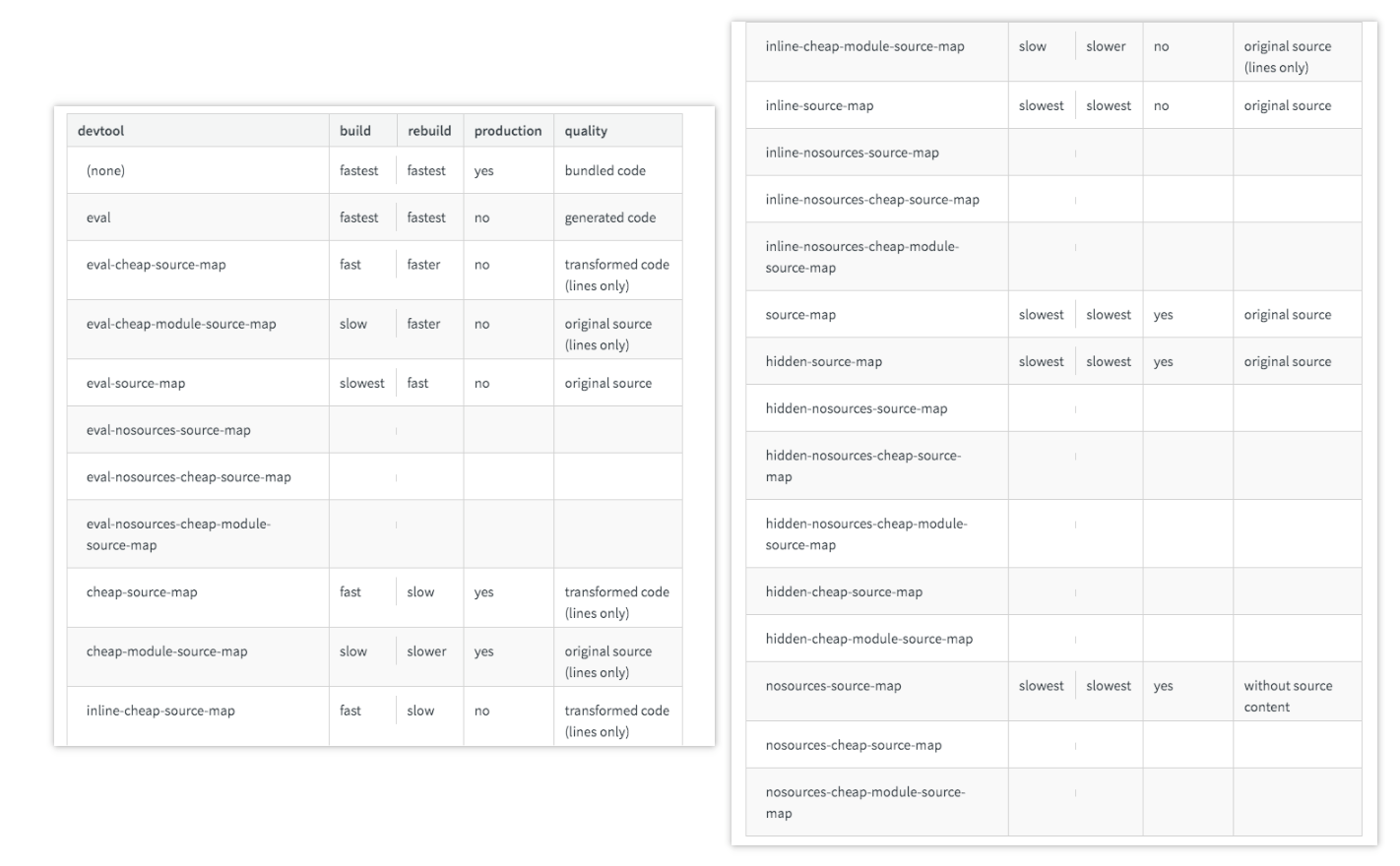
从webpack官网上了解到,devtool的值有20+种。
听起来很吓人,不过幸好它有固定的模式。
[inline-|hidden-|eval-][nosources-][cheap-[module-]]source-map
通过关键词的组合,就可以生成用于各种场景的Source Map。

理解quality
在学习各种值之前,我们需要先来了解一下表格中的quality列。配置某个属性值,我们是为了达到某个目的,而quality就是目的之一。
那么它是什么呢?它描述了我们在调试时能看到的源码内容。
下面来看看它的取值以及含义
| quality | 含义 |
|---|---|
| bundled code | 模块未分离 |
| generated code | 模块分离,未经loader处理的代码 |
| transformed code | 模块分离,经loader处理过的代码 |
| original source | 你自己所写的代码 |
| without source content | 生成的Source Map中不包含sourcesContent |
| (lines only) | 包含行信息,不包含列信息 |
理解devtool
quality就决定了我们调试时能看到的源码内容,所以选取devtool的值时,需要根据项目实际情况配合quality来选择。而devtool有20+个可选值,我们需要进一步来理解其组成原则。
特别提醒:指定devtool时,要与mode配合使用。
复制代码首先,上述模式中有三类关键词:
- inline、hidden、eval
- nosources
- cheap[module]
俗话说,实践是检验真理的唯一标准学懂一样东西的最好方式,下面有一个?来实践一下。
这里是一个简单的demo,里面有连个文件,其中主文件main.js引入了一个a.js。为了更好的模拟实际场景,还使用了webpack中还使用了babel-loader来处理js文件。
具体如下图: 
下面就来实操一波~
inline、hidden、eval
这几个模式是互斥的,描述的是Source Map的引入方式。
inline
Source Map内容通过base64放在js文件中引入。
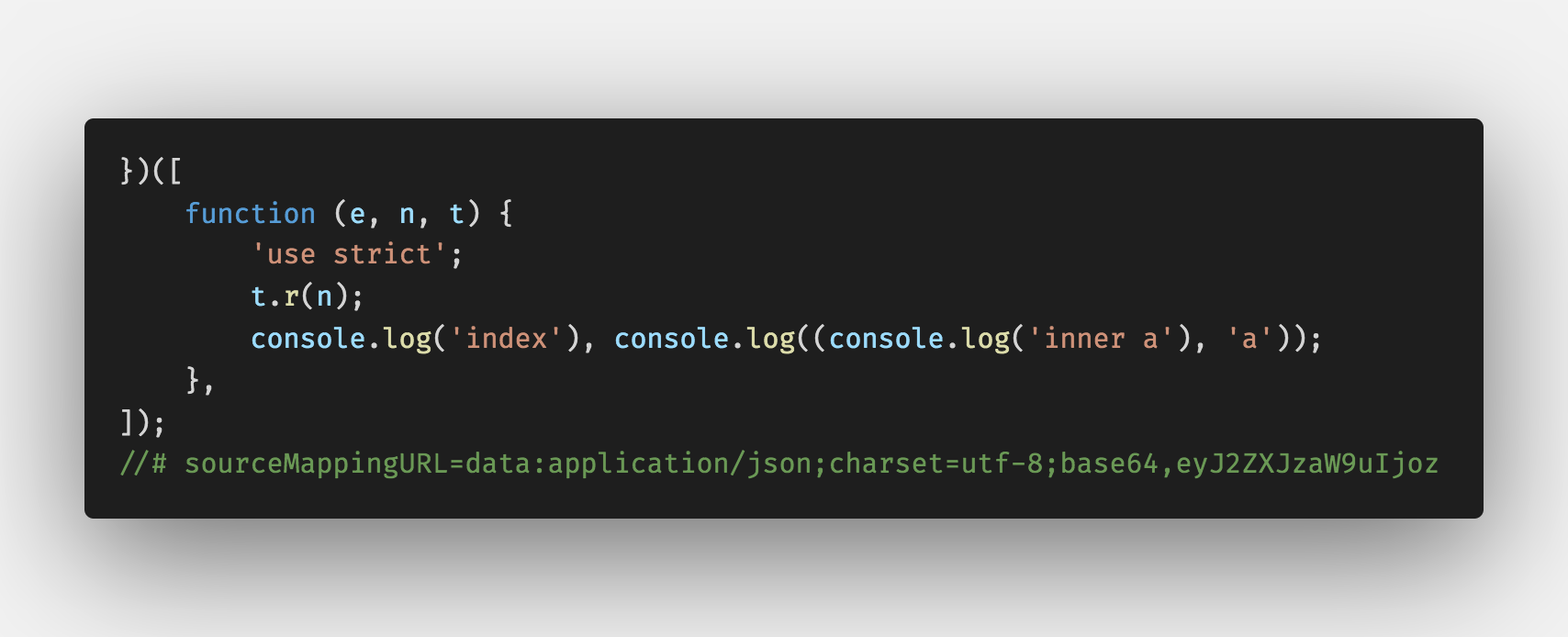
hidden
代码中没有sourceMappingURL,浏览器不自动引入Source Map。
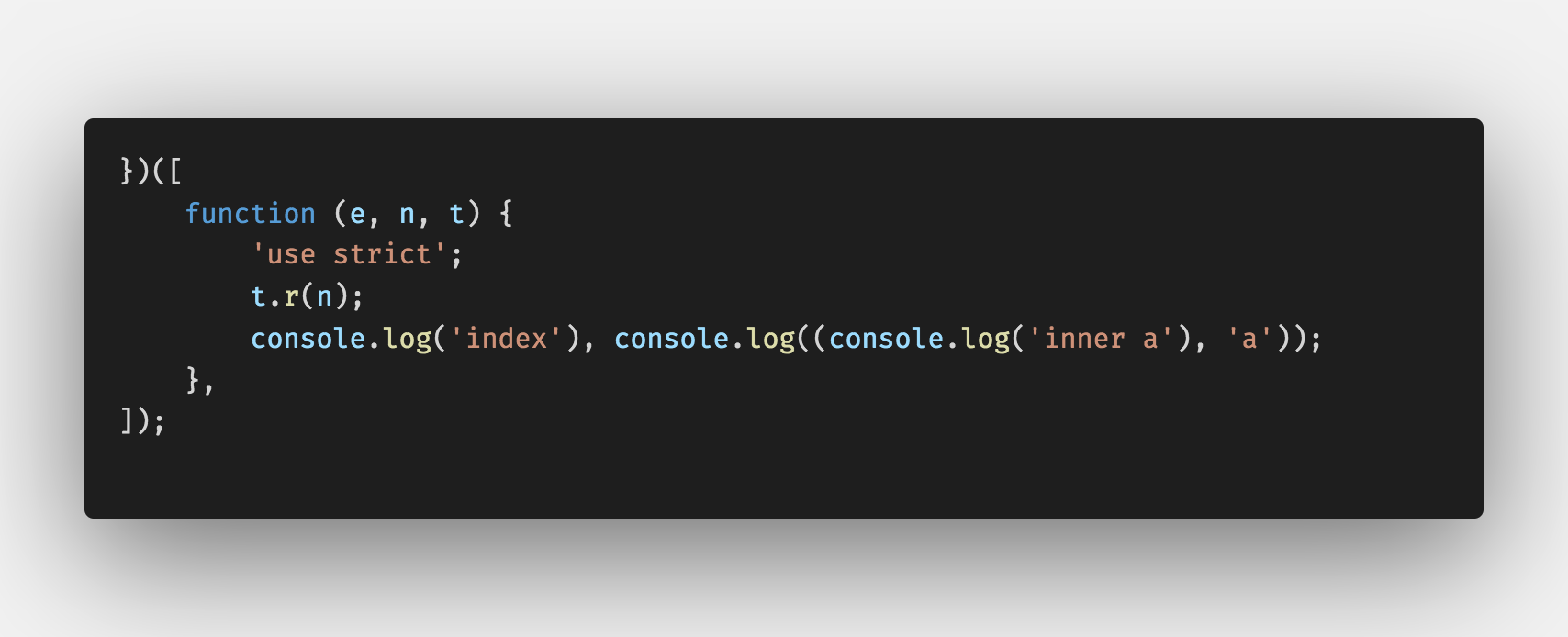
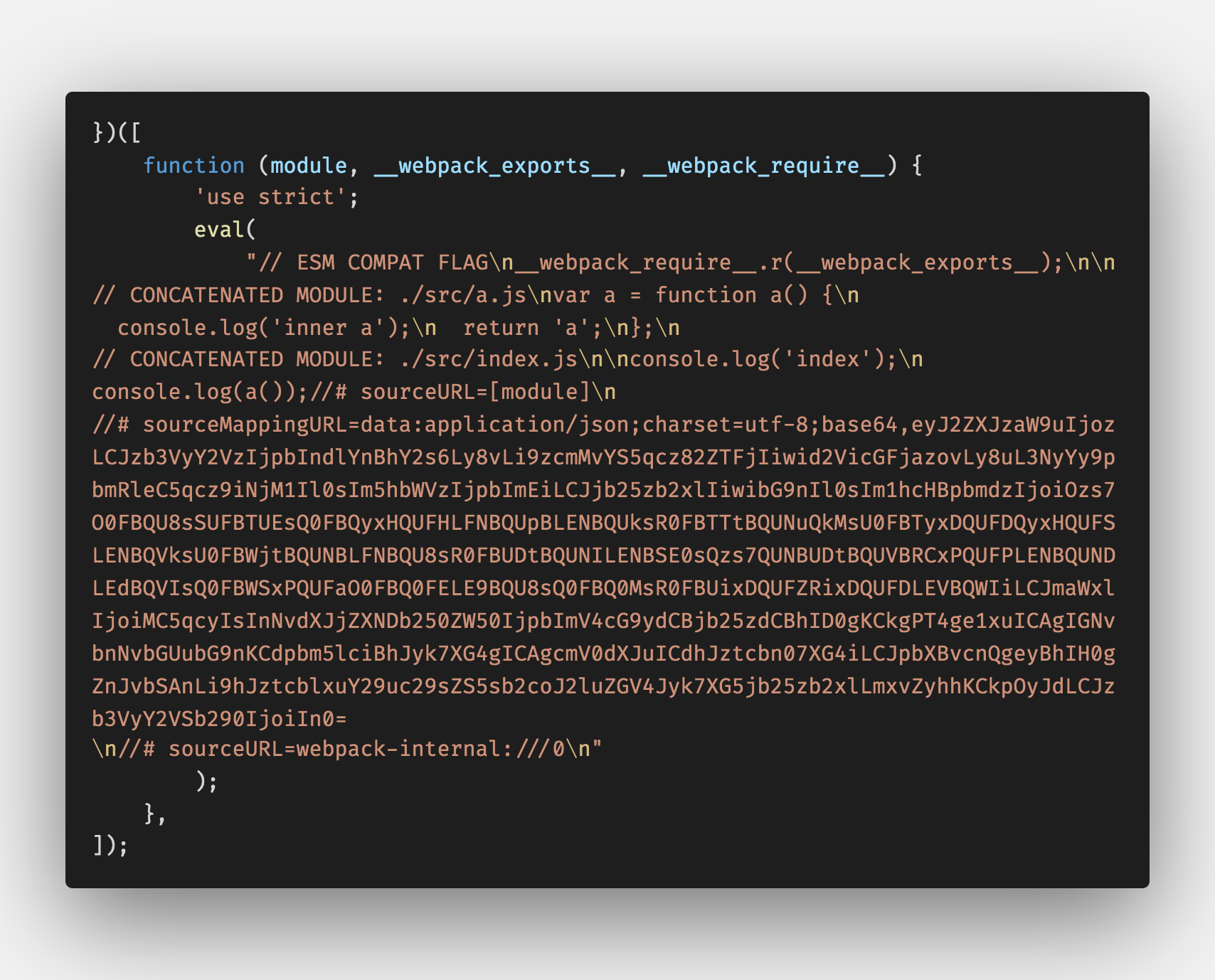
eval
生成代码和Source Map内容混淆在一起,通过eval输出。
nosources
使用这个关键字的Source Map不包含sourcesContent,调试时只能看到文件信息和行信息,无法看到源码。

cheap[module]
这个关键字用于指定调试信息的完整性
cheap
不包含列信息,并且源码是进过loader处理过的
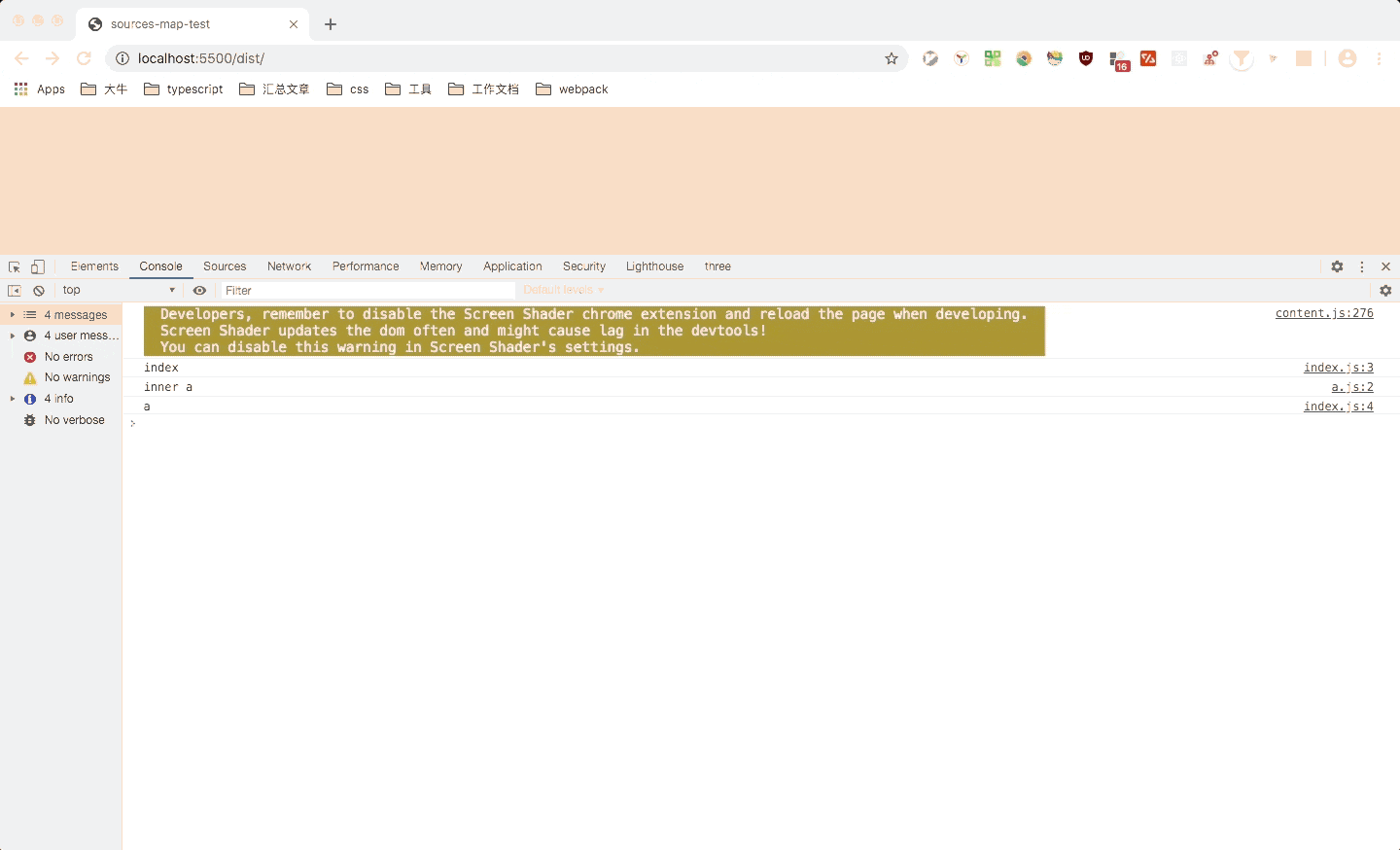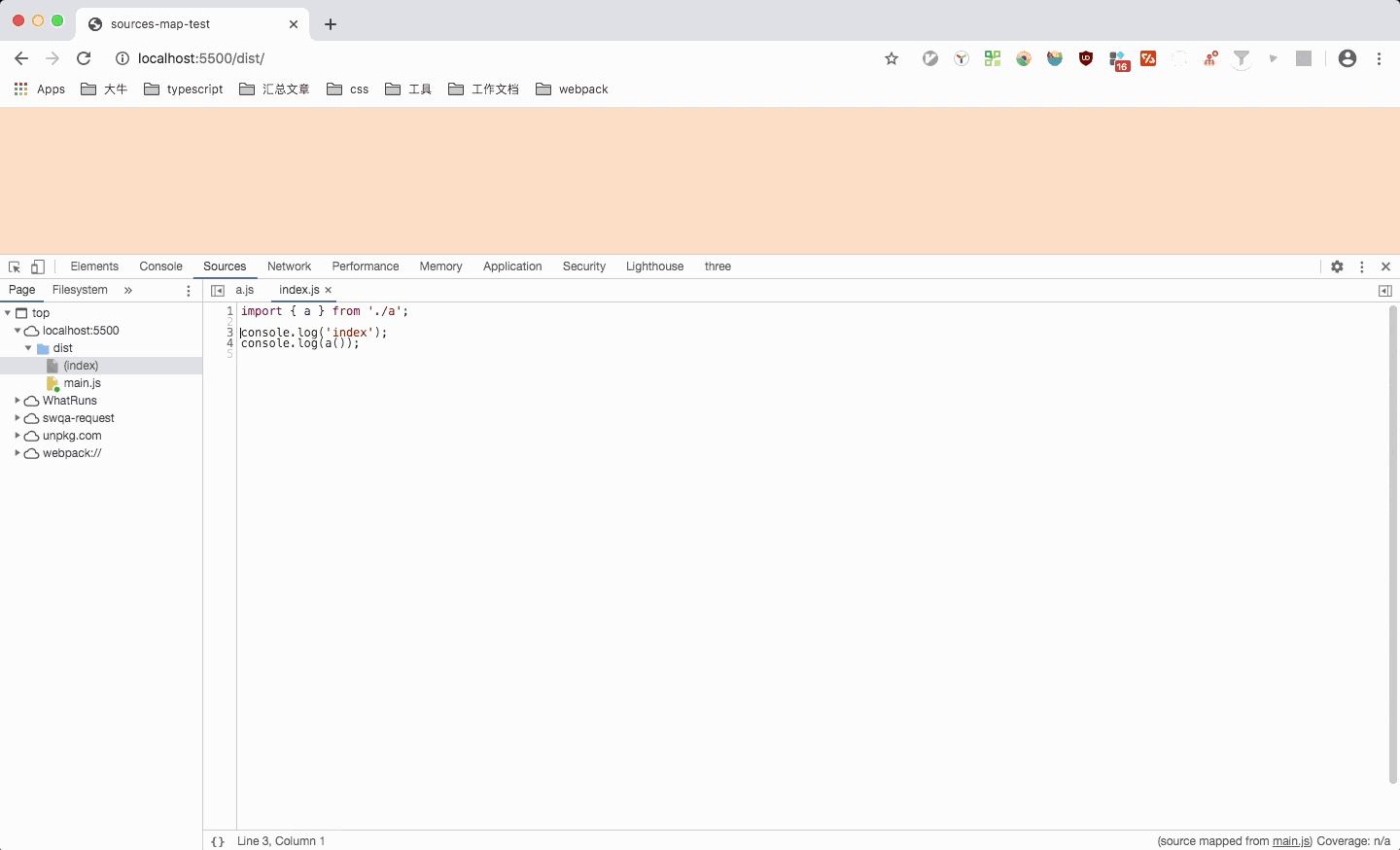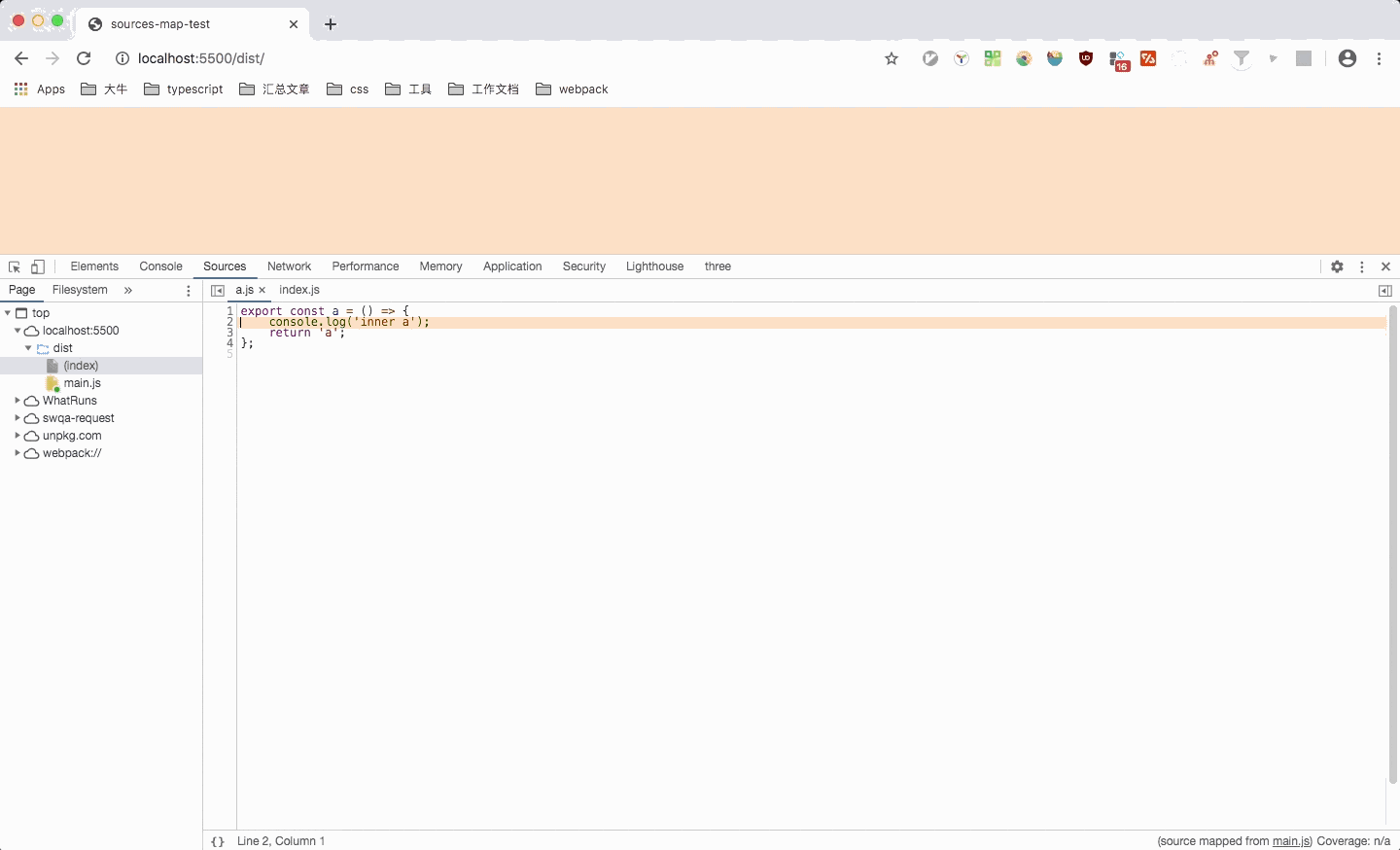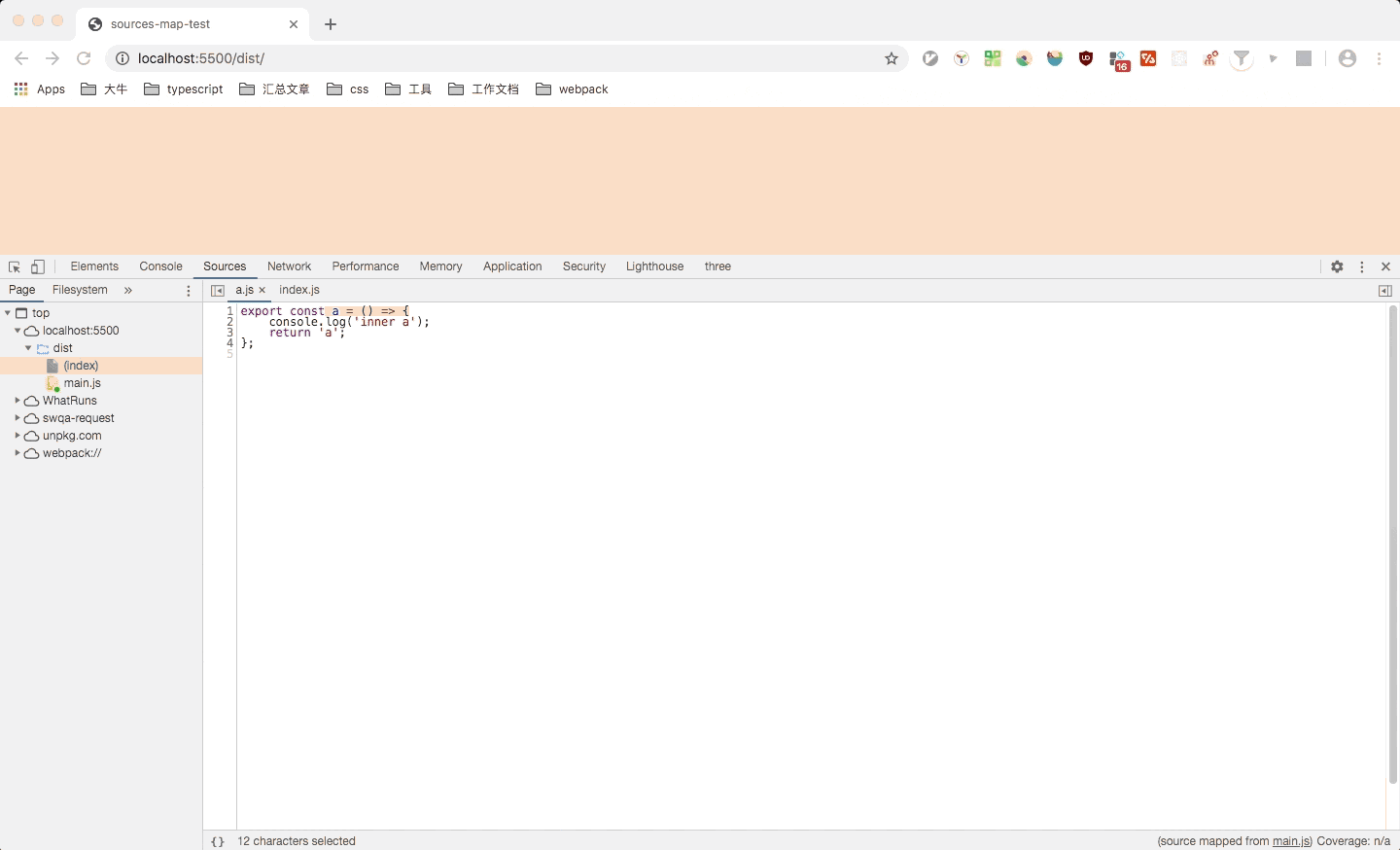
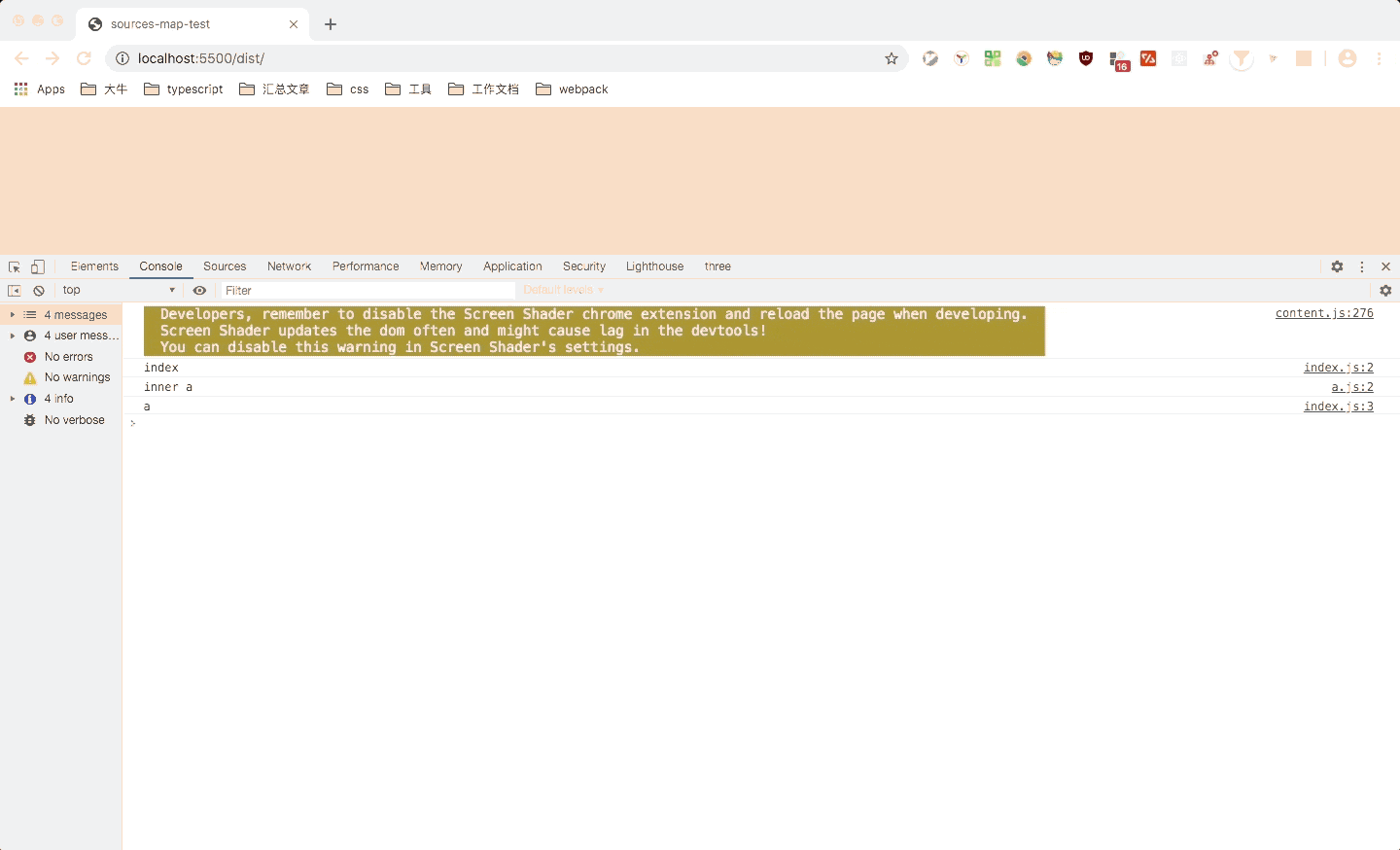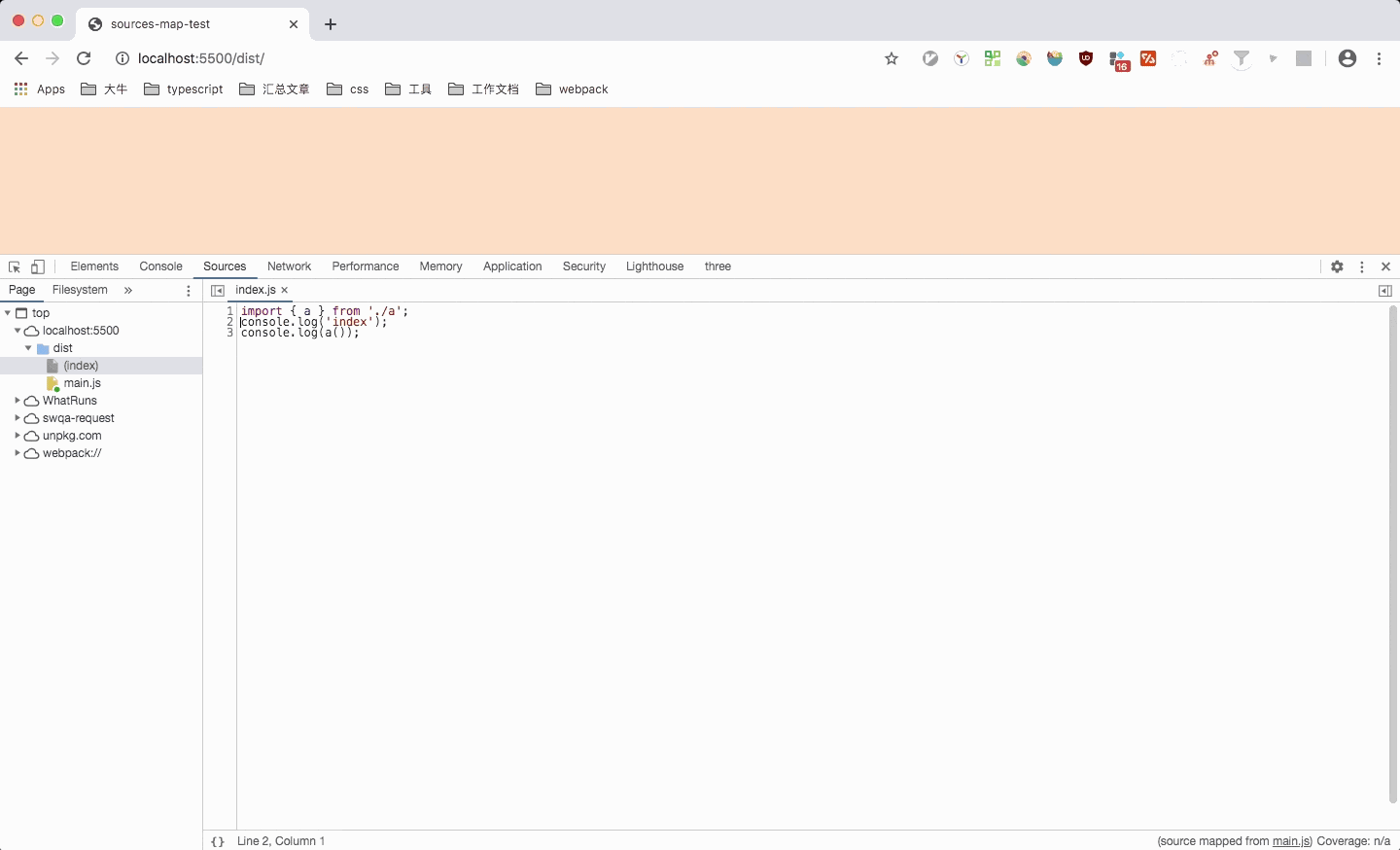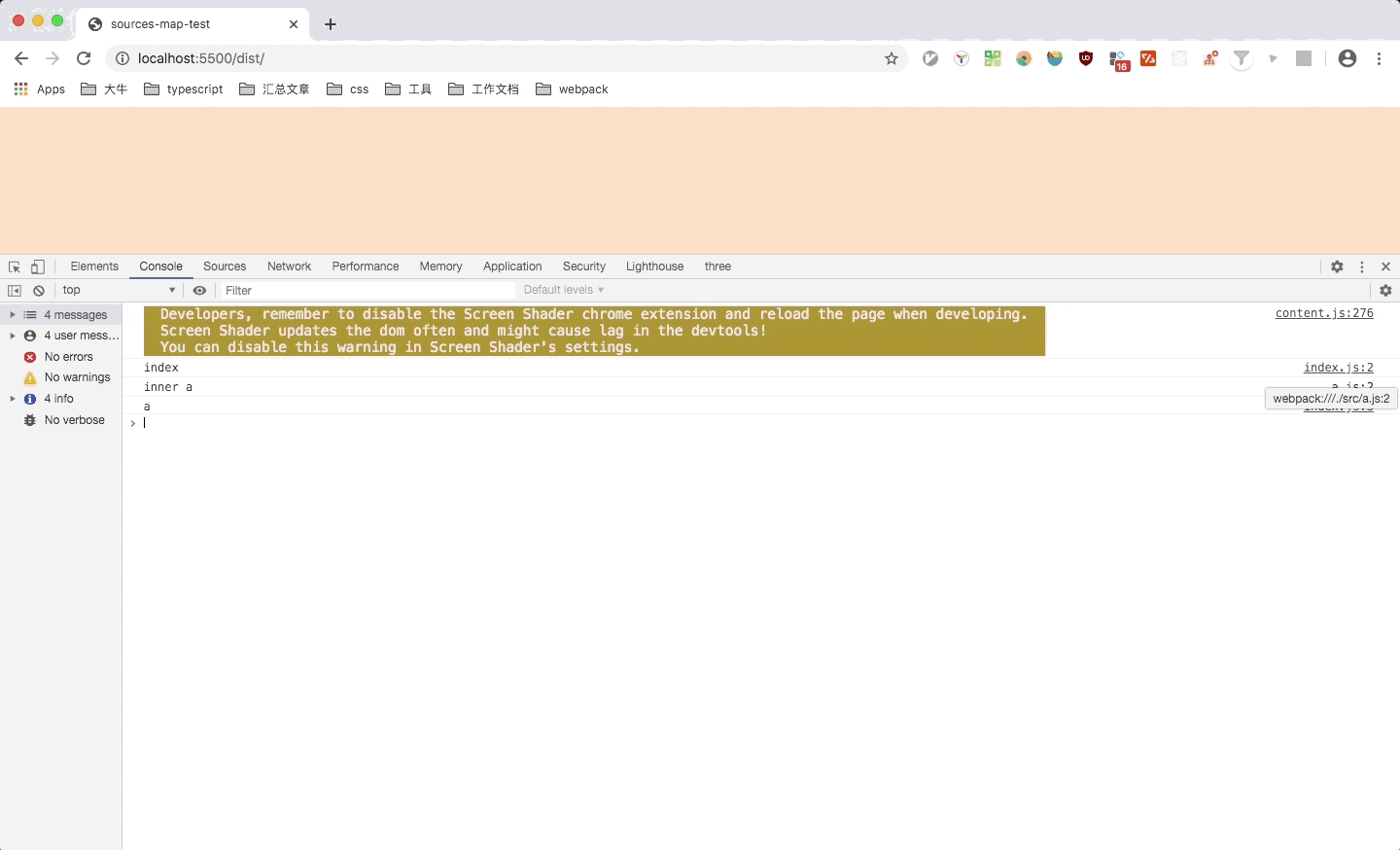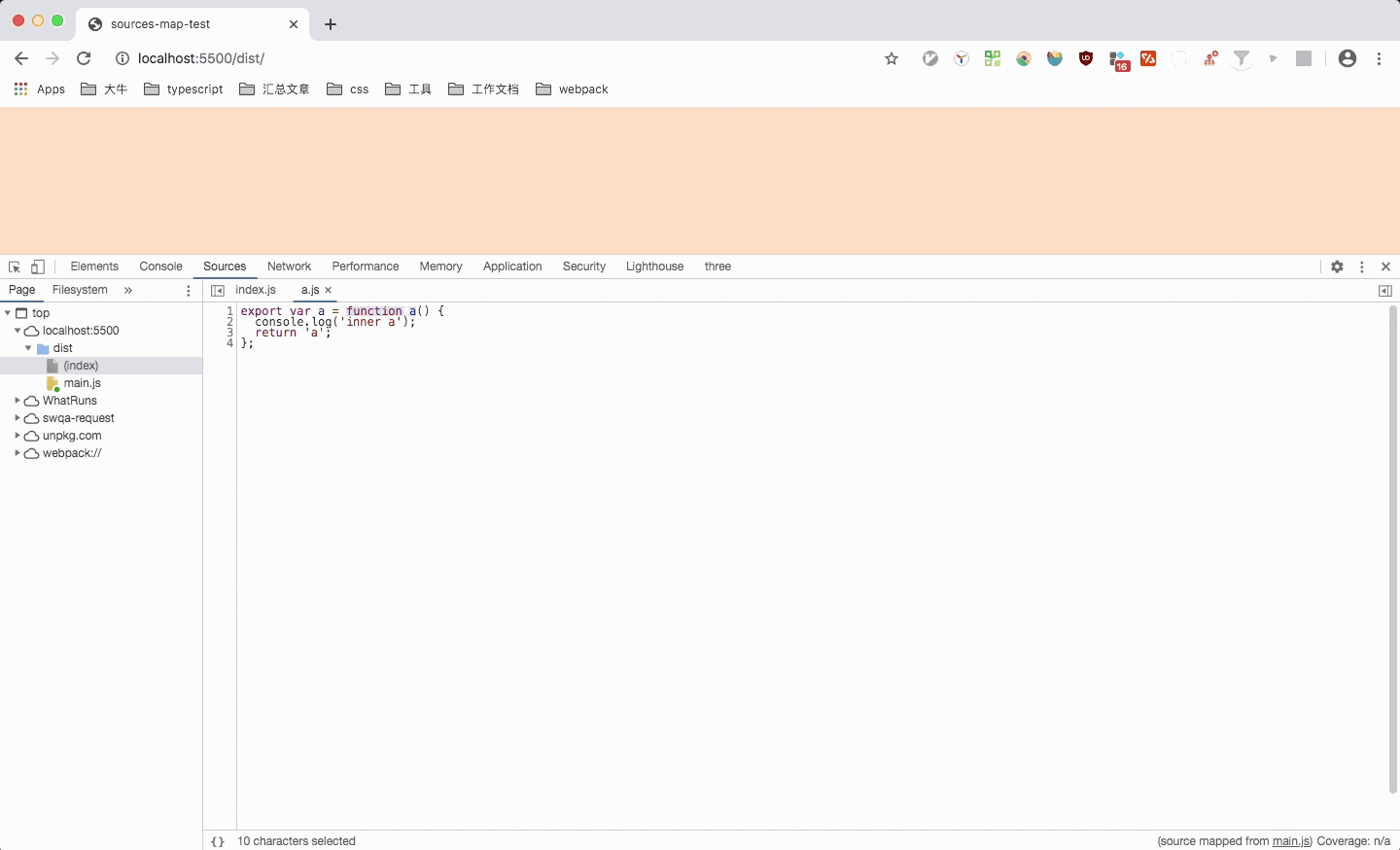 这里可以看到,点击对应文件时,会跳转到对应文件,但是光标是在第一列(缺少列信息则只定位到第一列),并且箭头函数也被转换成了function。
这里可以看到,点击对应文件时,会跳转到对应文件,但是光标是在第一列(缺少列信息则只定位到第一列),并且箭头函数也被转换成了function。
cheap-module
不包含列信息,源码是开发时的代码
 也是只能看到列信息,不过代码是原汁原味的开发时所写的代码。
也是只能看到列信息,不过代码是原汁原味的开发时所写的代码。
Source Map是如何工作的
Source Map规范
根据Source Map v3规范,推荐的格式是:
{
"version" : 3,
"file": "out.js",
"sourceRoot": "",
"sources": ["foo.js", "bar.js"],
"sourcesContent": [null, null],
"names": ["src", "maps", "are", "fun"],
"mappings": "A,AAAB;;ABCDE;"
}
复制代码下面来解释一下每个属性代表的含义。
| 属性 | 掘力值下限 |
|---|---|
| version | Source Map文件版本 |
| file | 该Source Map对应文件的名称 |
| sourceRoot | 源文件根目录,这个值会加在每个源文件之前 |
| sources | 源文件列表,用于mappings |
| sourcesContent | 源代码字符串列表,用于调试时展示源文件,列表每一项对应于sources |
| names | 源文件变量名和属性名,用于mappdings |
| mappings | 位置信息 |
浏览器与source-map
这里以chrome浏览器为例(其他浏览器应该也是类似的喔~)。
加载source-map
浏览器加载source-map是通过js文件中的sourceMappingRUL来加载的,而且sourceMapping支持两种形式:文件路径或base64格式。
加载source-map之后,在浏览器dev tool中的Sources tab就能看到对应的信息了。
这里重点讲解一下map文件中的sources字段和sourcesContent字段。
sources字段对应的是文件信息,会在浏览器的Sources中生成对应目录结构。之后再将sourcesContent中的内容对应填入上述生成的文件中。我们在调试时为啥能看到文件信息和源码内容,就是sources和sourcesContent共同作用的结果。
这里通过一个栗子来看看,我在sources中添加了一个文件hello.js,并且在sourcesContent中对应添加了内容hello~。下面是浏览器加载map文件后的结果。 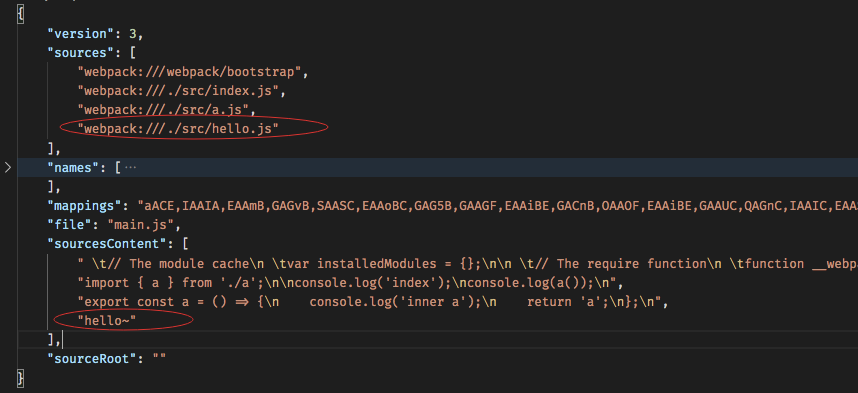
mappdings详解
直接举个栗子?:
源码:input.js
i am handsome
you are ugly
复制代码转换后代码:output.js
i am handsome you are
ugly
复制代码我们要如何记录这位置对应信息呢?这里可以参考这篇文章[1]。
位置信息必须包含的有:输出位置(Output location)、源文件(Input)、源码位置(Input location)、源码。
所以根据上面的栗子,我们可以得出如下表格。
| Output location | Input | Input location | Character |
|---|---|---|---|
| L1,C0 | index.js | L1, C0 | i |
| L1,C2 | index.js | L1, C2 | a |
| L1,C3 | index.js | L1, C3 | m |
| L1,C5 | index.js | L1, C5 | h |
| L1,C6 | index.js | L1, C6 | a |
| L1,C7 | index.js | L1, C7 | n |
| L1,C8 | index.js | L1, C8 | d |
| L1,C9 | index.js | L1, C9 | s |
| L1,C10 | index.js | L1, C10 | o |
| L1,C11 | index.js | L1, C11 | m |
| L1,C12 | index.js | L1, C12 | e |
| L1,C14 | index.js | L2, C0 | y |
| L1,C15 | index.js | L2, C1 | o |
| L1,C16 | index.js | L2, C2 | u |
| L1,C18 | index.js | L2, C4 | a |
| L1,C19 | index.js | L2, C5 | r |
| L1,C20 | index.js | L2, C6 | e |
| L2,C0 | index.js | L2, C8 | u |
| L2,C1 | index.js | L2, C9 | g |
| L2,C2 | index.js | L2, C10 | l |
| L2,C3 | index.js | L2, C11 | y |
这个表格描述了每个字符的处理前后的对应位置信息,有了这个表格就可以做位置的映射了。
可以看到对于几个字符来说,需要存储的信息就已经很庞大了,所以这种记录方式还需要进行优化。
优化点如下:
- 可以把输入文件放入一个列表中,这样在位置信息中就可以使用列表索引来表示了。
- 对于源码,没有必要记录每个字符的对应信息,我们只需要记录变量、属性名就可以了(单词),可以使用一个列表来保存单词,位置信息只记录单词首个字符位置即可。
- 输出文件的行信息是相对重复的,所以可以使用
;来分割每行输出代码,使用,来分割每个输出代码的位置信息。 - 源码的每个单词可以使用对于上一个单词的相对位置,这些位置信息(数字)可以更小些。
优化后如下表:
sources: [index.js]
names: [i, am, handsome, you, are, ugly]
复制代码| Output location | Input index | Input location | Name index |
|---|---|---|---|
| L1,C0 | 0 | L1, C0 | 0 |
| L1,C+2 | +0 | L1, C+2 | +1 |
| L1,C+3 | +0 | L1, C+3 | +1 |
| L1,C+9 | +0 | L2, C-5 | +1 |
| L1,C+4 | +0 | L2, C+4 | +1 |
| L2,C-18 | +0 | L2, C+4 | +1 |
此时位置信息可以记录成
mappings: "0|0|1|0|0,2|0|1|2|1,3|0|1|3|1,9|0|2|-5|1,4|0|2|4|1;-18|0|2|4|1"
备注:
1. 数字使用分隔符“|”分割
2. 0|0|1|0|0代表 -> 0(输出单词列), 0(输入文件sources索引),10(输入单词行列),0(单词names索引)
复制代码使用VLQ进行优化
在上述mappings中,因为每一个位置不一定是一个数字的,所以必须使用|分隔符来分割数字。如果能省略分隔符,mappings的大小可以得到很大的优化。这时就需要引入VLQ(Variable Length Quantities)了。
VLQ的特点就是可以非常精简地表示很大的数值。其原理是使用6个二进制位来表示字符,其中最高位表示是否连续(0:不连续,1:连续),最低位表示是正还是负(0:正数,1:负数)。
举两个栗子??:数字1与-23。
数字:1
二进制:1
VLQ编码:000010
Base64 VLQ: C
复制代码数字:-23
绝对值:23
二进制:10111
VLQ编码:101111 000001
Base64 VLQ: vB
复制代码这里拿-23来分解一下生成过程。
第一步:去23的二进制码 -> 10111
第二步:将10111分成两部分,第一部分是后四位,后面部分是五位为一部分 -> 1、0111 -> 00001、0111
第三步:按VLQ格式拼接 -> 101111 000001
其中,101111是 1【连续标识位】 + 0111 + 1【正负标识位】
000001是 0【连续标识位】+ 00001
第四步:对照Base64索引表(下表)
复制代码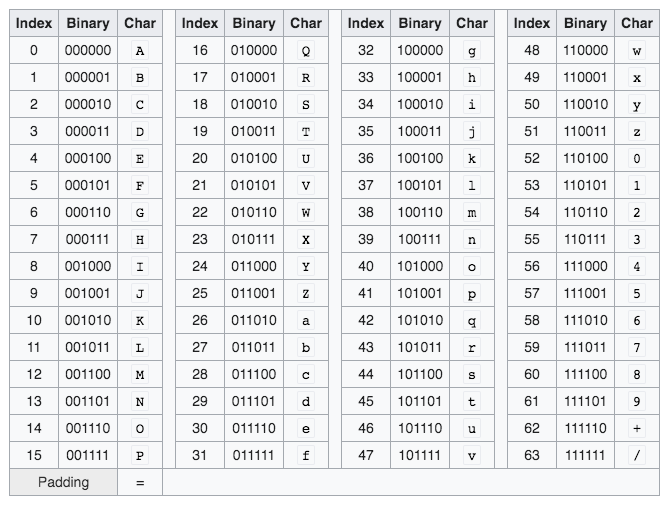
最后来看一下上述mappings优化之后长啥样吧。
优化前:
mappings: "0|0|1|0|0,2|0|1|2|1,3|0|1|3|1,9|0|2|-5|1,4|0|2|4|1;-18|0|2|4|1"
优化后
mappings: "AACAA,EACEC,GACGC,SAELC,IAEIC,lBAEIC"
复制代码项目中如何使用
通过上面的理论。我们对source-map以及webpack中devtool配置项已经有一些了解了,下面从实际出发,看看在项目不同环境中应该如何配置webpack。
webpack是如何推荐的
先直接来看看webpack官网的devtool[2]推荐:
Development
推荐使用:
- eval
- eval-source-map
- eval-cheap-source-map
- eval-cheap-module-source-map
在开发环境,我们比较在意的是开发体验,所以下面从源码级别、构建速度和列信息来对比。
| devtool | 源码级别 | 构建速度 | 列信息 |
|---|---|---|---|
| eval | webpack + loader处理后的代码 | 快 | + |
| eval-source-map | 源码 | 慢 | + |
| eval-cheap-source-map | loader处理后的代码 | 中 | – |
| eval-cheap-module-source-map | 源码 | 中 | – |
Production
推荐使用:
- none
- source-map
- hidden-source-map
- nosources-source-map
在生产环境,我们比较在意的是安全性,所以下面从源码级别、安全性和列信息来对比。
| devtool | 源码级别 | 安全性 | 列信息 |
|---|---|---|---|
| none | – | – | – |
| source-map | 源码 | 浏览器会加载source-map,调试时会暴露源码 | + |
| hidden-source-map | 源码 | 会生成map文件,但浏览器不会加载source-map。可以将map文件与错误上报工具结合使用 | + |
| nosources-source-map | 源码堆栈 | 没有sourcesContent,调试只能看到模块信息和行信息,不能看到源码 | – |
实际项目是如何配置
翻了一下项目组中的项目,开发环境使用的是eval-cheap-module-source-map,而生产环境这边多大数只需要知道报错的模块和行号就可以了,所以使用的是nosources-source-map。
原文链接:https://juejin.cn/post/6844904201311485966
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188904.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
