大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
MGN的核心思想是利用global feature+fine grain feature做特征融合然后分类,做part-based的branch取得很简单就是等分,但是为了让模型能收敛,用了多个patch的loss混合训练。看文章结果很不错,只用了给的数据集里面的trainset就能达到90+。github上只有pytorch版本,准备这段时间自己搞一个纯TF版本出来。
Motivation
1.基于区域的方法主要是通过定位预先设定好的特殊区域来学习局部特征。对于高方差的场景效率并不高而且不鲁棒。
常用的part-based方法分为三类:
(1)根据先验知识,例如对人体结构的知识划分结构
(2)利用RPN定位区域
(3)中层次的注意力机制定位区域
2.基于全局特征的方法容易在小数据集上忽略细节
3.许多方法并不能End2End
Spot light
1.构建了3个branch,Coarse to fine使用全局特征和局部特征融合
2.End2End
3.同时使用Triplet loss和softmax
Result
不额外使用数据集仅使用简单的数据增强就能达到非常好的mAP
使用re-rank后效果更好
Structure
这部分直接从我OneNote截取的,重要的部分我已经直接标在图中了
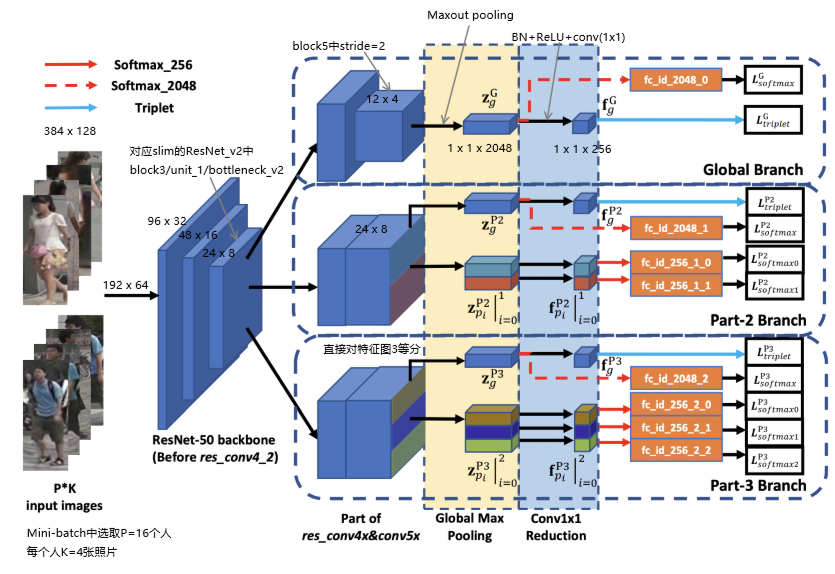

Loss设计
softmax: 使用normface的版本,不加bias
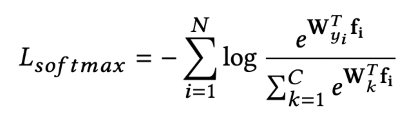
Triplet loss:使用batch hard triplet loss
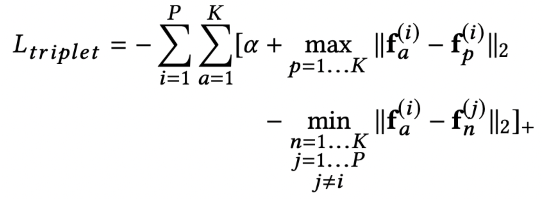
训练时的loss则是将图中所有同类loss相加等除之后再相加avg(triplet)+avg(softmax)
Hyper parameters
DataAugmentation:random horizontal flipping
Pretrain:全部加载Resnet50
Optimizer:momentum 0.9
L2_regularizer:5e-4
Learning rate:1e-2(40 epoch)1e-3(60 epoch)1e-4(80 epoch)
Evaluation
将所有256-dim的特征concat (8 x 256)=2048
测试的时候将原始特征和flipping后的特征求avg为最终结果
Discussion
1.使用Conv4_1的特征作为分支是实验出来的结果,前或后效果都不好
2.粒度多样性,Global学习全局但是粗糙特征,Branch学习局部但是精细特征
3.对于局部特征不应该使用triplet loss,因为切的时候就是等分,局部特征var很大
4.使用softmax有利于模型收敛,而triplet则是为了拉大inter-class var(度量学习了)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188884.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
