大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Abstract
- 本论文提出一种新的全卷积孪生网络作为基本的跟踪算法,这个网络在ILSVRC15的目标跟踪视频数据集上进行端到端的训练。我们的跟踪器在帧率上超过了实时性要求,尽管它非常简单,但在多个benchmark上达到最优的性能。
1. Introduction
- 最近很多研究通过使用预训练模型来解决上述问题。这些方法中,要么使用网络内部某一层作为特征的
shallow方法(如相关滤波);要么是使用SGD方法来对多层网络进行微调。然而shallow的方法没有充分利用端到端学习的益处,而使用SGD微调虽然能到达时最优结果,但却难以达到实时性的要求。 - 我们提出另一种替代性的方法。这个方法在初始离线阶段把深度卷积网络看成一个更通用的相似性学习问题,然后在跟踪时对这个问题进行在线的简单估计。这篇论文的关键贡献就在于证明这个方法在benchmark上可以达到非常有竞争性的性能,并且运行时的帧率远超实时性的要求。具体点讲,我们训练了一个孪生网络在一个较大的搜索区域搜索样本图片。本文另一个贡献在于,新的孪生网络结构是一个关于搜索区域的全卷积网络:密集高效的滑动窗口估计可通过计算两个输入的互相关性并插值得到。
2. Deep similarity learning for tracking
- 跟踪任意目标的学习可看成是相似性问题的学习。我们提出学习一个函数 f ( x , z ) f(x,z) f(x,z) 来比较样本图像 z z z 和搜索图像 x x x 的相似性。如果两个图像描述的是同一个目标,则返回高分,否则返回低分。
- 我们用深度神经网络来模拟函数 f f f,而深度卷积网络中相似性学习最典型的就是孪生结构。孪生网络对两个输入 z z z 和 x x x 进行相同的变换 φ \varphi φ ,然后将得到的输出送入函数 g g g,最后得到相似性度量函数为: (1) f ( z , x ) = g ( φ ( z ) , φ ( x ) ) f(z,x)=g(\varphi(z),\varphi(x)) \tag{1} f(z,x)=g(φ(z),φ(x))(1) 1.函数 g g g 是一个简单的距离或相似性度量
2. φ \varphi φ 相当于特征提取器
2.1 Fully-convolutional Siamese architecture
- 网络结构如下图所示
1. z z z 表示样本图像(即目标)
2. x x x 表示待搜索图像
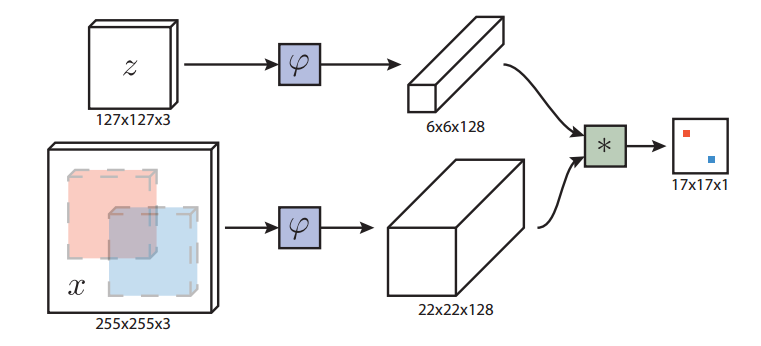

- 全卷积网络的优点是待搜索图像不需要与样本图像具有相同尺寸,可以为网络提供更大的搜索图像作为输入,然后在密集网格上计算所有平移窗口的相似度。本文的相似度函数使用互相关,公式如下 (2) f ( z , x ) = φ ( z ) ∗ φ ( x ) + b 1 f(z,x)=\varphi(z) * \varphi(x) + b\mathcal 1 \tag{2} f(z,x)=φ(z)∗φ(x)+b1(2) 1. b 1 b\mathcal 1 b1 表示在得分图中每个位置的取值
2.上式可将 φ ( z ) \varphi(z) φ(z) 看成卷积核,在 φ ( x ) \varphi(x) φ(x) 上进行卷积 - 跟踪时以上一帧目标位置为中心的搜索图像来计算响应得分图,将得分最大的位置乘以步长即可得到当前目标的位置。
2.2 Training with large search images
- 我们用判别方法来对正、负样本对进行训练,其逻辑损失定义如下: (3) l ( y , v ) = l o g ( 1 + e x p ( − y v ) ) \mathcal l(y,v)=log(1+exp(-yv))\tag{3} l(y,v)=log(1+exp(−yv))(3) 1. y ∈ ( + 1 , − 1 ) y\in(+1,-1) y∈(+1,−1) 表示真值
2. v v v 表示样本–搜索图像的实际得分
3.上式表示的正样本的概率为 1 1 + e − v \frac{1}{1+e^{-v}} 1+e−v1(sigmoid函数),负样本的概率为 1 − 1 1 + e − v 1-\frac{1}{1+e^{-v}} 1−1+e−v1,则按交叉熵的公式很容易得到式 ( 3 ) (3) (3) 的loss - 训练时采用所有候选位置的平均loss来表示,公式如下: (4) L ( y , v ) = 1 D ∑ u ∈ D l ( y [ u ] , v [ u ] ) L(y,v)=\frac{1}{\mathcal D}\sum_{u\in \mathcal D}\mathcal l(y[u],v[u])\tag{4} L(y,v)=D1u∈D∑l(y[u],v[u])(4) 1. D \mathcal D D 表示最后得到的 score map
2. u u u 表示 score map 中的所有位置 - 训练的卷积参数 θ \theta θ 通过SGD来最小化如下问题得到: (5) a r g m i n θ = E ( z , x , y ) L ( y , f ( z , x ; θ ) ) arg\ \underset {\theta}{min}=\underset {(z,x,y)}{E}\ L(y,f(z,x;\theta))\tag{5} arg θmin=(z,x,y)E L(y,f(z,x;θ))(5)
- 训练样本对 ( z , x ) (z,x) (z,x) 从标注的视频数据集得到,如下图所示
1.搜索区域 x x x 以目标区域 z z z 为中心
2.如果超出图像则用像素平均值填充,保持目标宽高比不变
3.训练时不考虑目标类别
4.网络的输入尺寸统一

- 网络输出正负样本的确定:在输入搜索图像上(如 255 ∗ 255 255*255 255∗255),只要和目标的距离不超过R,那就算正样本,否则就是负样本,用公式表示如下: (6) y [ u ] = { + 1 i f k ∣ ∣ u − c ∣ ∣ ≤ R − 1 o t h e r w i s e . y[u]=\left\{\begin{matrix} & +1\quad if\ k||u-c||\leq R\\ &-1\qquad otherwise\quad . \end{matrix}\right.\tag{6} y[u]={
+1if k∣∣u−c∣∣≤R−1otherwise.(6) 1. k k k 为网络的总步长
2. c c c 为目标的中心
3. u u u 为score map的所有位置
4. R R R 为定义的半径
2.3 Practical considerations
- Dataset curation
1.样本图像大小 127 × 127 127\times 127 127×127,搜索图像大小 255 × 255 255\times255 255×255
2.图像的缩放与填充如式所示: s ( w + 2 p ) × s ( h + 2 p ) = A s(w+2p)\times s(h+2p)=A s(w+2p)×s(h+2p)=A
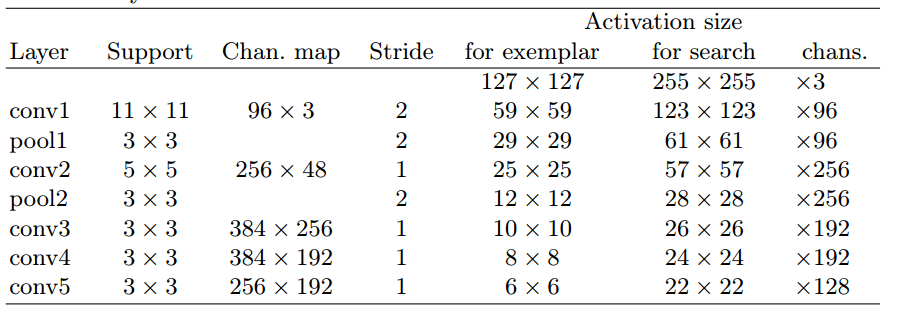
3.从ILSVRC15的4500个视频中选出4417个视频,超过2,000,000个标注的跟踪框作为训练集 - Network architecture
1.前两个卷积层后有池化层;
2.每个卷积层后都有ReLU层(conv5除外);
3.每个线性层后都加上BN;
4.卷积层没有加padding;
3. Experiments
3.1 Implementation details
- Training
1.梯度下降采用SGD
2.用高斯分布初始化参数
3.训练50个epoch,每个epoch有50,000个样本对
4.mini-batch等于8
5.学习率从 1 0 − 2 10^{-2} 10−2 衰减到 1 0 − 8 10^{-8} 10−8 - Tracking
1.初始目标的特征提取 φ ( z ) \varphi(z) φ(z) 只计算一次
2.用双三次插值将score map从 17 × 17 17 \times 17 17×17 上采样到 272 × 272 272 \times 272 272×272
3.对目标进行5种尺度来搜索( 1.02 5 { − 2 , − 1 , 0 , 1 , 2 } 1.025^{\left\{-2,-1,0,1,2\right\}} 1.025{
−2,−1,0,1,2})
4.目标图像在线不更新,因为对于CNN提取的是高层语义特征,不会像HOG或CN这些浅层特征苛求纹理相似度。(如跟踪目标是人,不论躺着或站着,CNN都能“认出来”这是人,而纹理特征如HOG或conv1可能完全无法匹配)
5.跟踪效率:3尺度86fps,5尺度58fps (NVIDIA GeForce GTX Titan X and an Intel Core i7-4790K at 4.0GHz)
3.2 Evalution
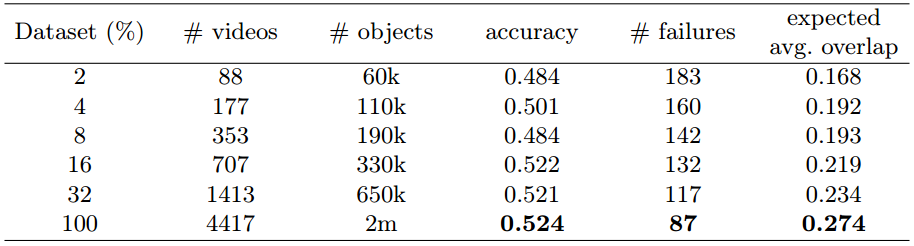
- Dataset size
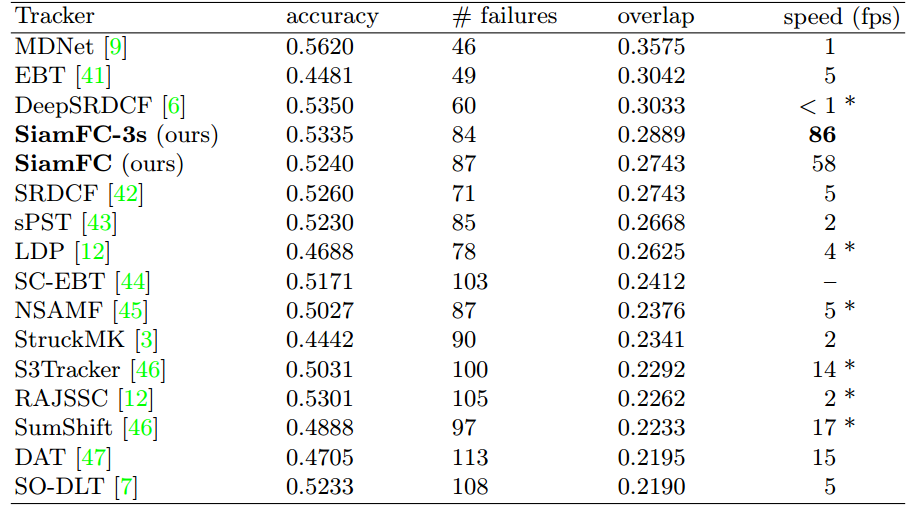
- VOT 2015
为什么5尺度比3尺度效果要差???
- Snapshots
1.motion blur—robust(row 2)
2.drastic change of appearance—robust(row 1,3,4)
3.poor illumination and scale change—robust(row 6)
4.occlusion—sensitive(row 5):because the model is never updated

4. Cross-correlation与Correlation Filter
- Cross-correlation:适合特征分辨率较小的高层CNN,典型AlexNet的conv5,CNN特征提取部分更大更慢,滑窗检测计算量较大但没有边界效应,检测范围不受限,目标模型在线不更新,定位精度较低但更鲁棒。
- Correlation Filter:适合特征分辨率较大的低层CNN,典型AlexNet的conv2,CNN特征提取部分更小更快,模板更新和检测都可以在频域高效解决,CF速度快,但边界效应难以处理,目标模型在线更新,定位精度更高但容易被污染。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188708.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
