大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
编写一个词法分析程序
实验目的:理解词法分析在编译程序中的作用;
加深对有穷自动机模型的理解;
掌握词法分析程序的实现方法和技术。
实验内容:选择部分C语言的语法成分,设计其词法分析程序,要求能够识别关键字、运算符、分界符、标识符、常量(至少是整型常量,可以自己扩充识别其他常量)等,并能处理注释、部分复合运算符(如>=等)。
实验要求:
(1)待分析的简单的语法
关键字:begin if then while do end
运算符和界符::= + – * / < <= > >= <> = ; ( ) #
其他单词是标识符id和整型常数num,通过以下正规式定义:
id=l(l|d)*
num=dd*
空格、注释:在词法分析中要去掉。
(2)各种单词符号对应的种别编码
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
\0 |
1000 |
|
if |
2 |
( |
26 |
|
then |
3 |
) |
27 |
|
while |
4 |
[ |
28 |
|
do |
5 |
] |
29 |
|
end |
6 |
{ |
30 |
|
int |
7 |
} |
31 |
|
main |
8 |
, |
32 |
|
return |
12 |
: |
33 |
|
cout |
13 |
; |
34 |
|
l(l|d)* |
10 |
> |
35 |
|
:= |
18 |
< |
36 |
|
dd* |
20 |
>= |
37 |
|
== |
21 |
<= |
38 |
|
+ |
22 |
!= |
40 |
|
– |
23 |
“ |
41 |
|
* |
24 |
# |
0 |
|
/ |
25 |
! |
-1 |
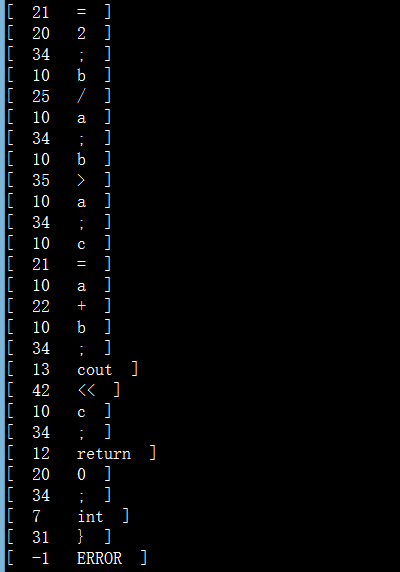
该程序实现词法分析,从文件data.txt中读取一段小程序(评论里贴了data.txt的代码哈),分解出一个个的单词,其中有关键词,有界符、运算符等等,代码还需实现去掉空格、回车、注释等等情况,最后的输出结果是以单词二元组(单词种别码,单词自身的值)的形式输出。
主要的函数有:
char m_getch() 从输入缓冲区读取一个字符到ch中
void getbc( ) 去掉空白字符
void concat( ) 拼接单词
int letter( ) 判断输入字符是否是字母
int digit( ) 判断输入字符是否是数字
int reserve( ) 检索关键字表格,判断单词是否为关键字
void retract( ) 回退一个字符
WORD * scanner( ) 词法扫描程序,返回值是二元组
在词法扫描程序中,扫描一个个字符,去掉空白,判断是否为注释等等。
程序代码如下:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#define _KEY_WORDEND "waiting for your expanding"
using namespace std;
typedef struct //词的结构,二元组形式(单词种别,单词自身的值)
{
int typenum; //单词种别
char * word;
}WORD;
char input[255];
char token[255] = "";
int p_input; //指针
int p_token;
char ch;
char * rwtab[] = { "begin","if","then","while","do","end","int","main",
"else","float","double","return","cout",_KEY_WORDEND };
WORD * scanner();//扫描
int main()
{
int over = 1;
WORD* oneword = new WORD;
//实现从文件读取代码段
cout << "read something from data.txt" << endl;
FILE *fp;
if((fp=freopen("data.txt","r",stdin))==NULL)
{
printf("Not found file!\n");
return 0;
}
else
{
while ((scanf("%[^#]s", &input)) != EOF)
{
p_input = 0;
printf("your words:\n%s\n", input);
while (over < 1000 && over != -1)
{
oneword = scanner();
if (oneword->typenum < 1000)
{
if(oneword->typenum != 999)
cout << "[ "<< oneword->typenum <<"\t"<< oneword->word <<" ]"<< endl;
}
over = oneword->typenum;
}
scanf("%[^#]s", input);
}
}
return 0;
}
//从输入缓冲区读取一个字符到ch中
char m_getch()
{
ch = input[p_input];
p_input++;
return ch;
}
//去掉空白符号
void getbc()
{
while (ch == ' ' || ch == 10)
{
ch = input[p_input];
p_input++;
}
}
//拼接单词
void concat()
{
token[p_token] = ch;
p_token++;
token[p_token] = '\0';
}
//判断是否字母
int letter()
{
if (ch >= 'a'&&ch <= 'z' || ch >= 'A'&&ch <= 'Z')
return 1;
else
return 0;
}
//判断是否数字
int digit()
{
if (ch >= '0'&&ch <= '9')
return 1;
else
return 0;
}
//检索关键字表格
int reserve()
{
int i = 0;
while(strcmp(rwtab[i], _KEY_WORDEND))
{
if (!strcmp(rwtab[i], token))
return i + 1;
i++;
}
return 10;//如果不是关键字,则返回种别码10
}
//回退一个字符
void retract()
{
p_input--;
}
//词法扫描程序
WORD * scanner()
{
WORD * myword = new WORD;
myword->typenum = 10; //初始值
myword->word = "";
p_token = 0; //单词缓冲区指针
m_getch();
getbc();//去掉空白
if (letter())//判断读取到的首字母是字母
{
//如int
while (letter() || digit())
{
concat(); //连接
m_getch();
}
retract(); //回退一个字符
myword->typenum = reserve();//判断是否为关键字,返回种别码
myword->word = token;
return myword;
}
else if (digit()) //判断读取到的单词首字符是数字
{
while (digit()) //所有数字连接起来
{
concat();
m_getch();
}
retract();
//数字单词种别码统一为20,单词自身的值为数字本身
myword->typenum = 20;
myword->word = token;
return(myword);
}
else switch (ch)
{
case '=':
m_getch();//首字符为=,再读取下一个字符判断
if (ch == '=')
{
myword->typenum = 39;
myword->word = "==";
return(myword);
}
retract();//读取到的下个字符不是=,则要回退,直接输出=
myword->typenum = 21;
myword->word = "=";
return(myword);
break;
case '+':
myword->typenum = 22;
myword->word = "+";
return(myword);
break;
case '-':
myword->typenum = 23;
myword->word = "-";
return(myword);
break;
case '/'://读取到该符号之后,要判断下一个字符是什么符号,判断是否为注释
m_getch();//首字符为/,再读取下一个字符判断
if (ch == '*') // 说明读取到的是注释
{
m_getch();
while(ch != '*')
{
m_getch();//注释没结束之前一直读取注释,但不输出
if(ch == '*')
{
m_getch();
if(ch == '/')//注释结束
{
myword->typenum = 999;
myword->word = "注释";
return (myword);
break;
}
}
}
}
else
{
retract();//读取到的下个字符不是*,即不是注释,则要回退,直接输出/
myword->typenum = 25;
myword->word = "/";
return (myword);
break;
}
case '*':
myword->typenum = 24;
myword->word = "*";
return(myword);
break;
case '(':
myword->typenum = 26;
myword->word = "(";
return(myword);
break;
case ')':
myword->typenum = 27;
myword->word = ")";
return(myword);
break;
case '[':
myword->typenum = 28;
myword->word = "[";
return(myword);
break;
case ']':
myword->typenum = 29;
myword->word = "]";
return(myword);
break;
case '{':
myword->typenum = 30;
myword->word = "{";
return(myword);
break;
case '}':
myword->typenum = 31;
myword->word = "}";
return(myword);
break;
case ',':
myword->typenum = 32;
myword->word = ",";
return(myword);
break;
case ':':
m_getch();
if (ch == '=')
{
myword->typenum = 18;
myword->word = ":=";
return(myword);
break;
}
else
{
retract();
myword->typenum = 33;
myword->word = ":";
return(myword);
break;
}
case ';':
myword->typenum = 34;
myword->word = ";";
return(myword);
break;
case '>':
m_getch();
if (ch == '=')
{
myword->typenum = 37;
myword->word = ">=";
return(myword);
break;
}
retract();
myword->typenum = 35;
myword->word = ">";
return(myword);
break;
case '<':
m_getch();
if (ch == '=')
{
myword->typenum = 38;
myword->word = "<=";
return(myword);
break;
}
else if(ch == '<')
{
myword->typenum = 42;
myword->word = "<<";
return(myword);
break;
}
else
{
retract();
myword->typenum = 36;
myword->word = "<";
return (myword);
}
case '!':
m_getch();
if (ch == '=')
{
myword->typenum = 40;
myword->word = "!=";
return(myword);
break;
}
retract();
myword->typenum = -1;
myword->word = "ERROR";
return(myword);
break;
case ' " ':
myword->typenum = 41;
myword->word = " \" ";
return(myword);
break;
case '\0':
myword->typenum = 1000;
myword->word = "OVER";
return(myword);
break;
case '#':
myword->typenum = 0;
myword->word = "#";
return (myword);
break;
default:
myword->typenum = -1;
myword->word = "ERROR";
return(myword);
break;
}
}
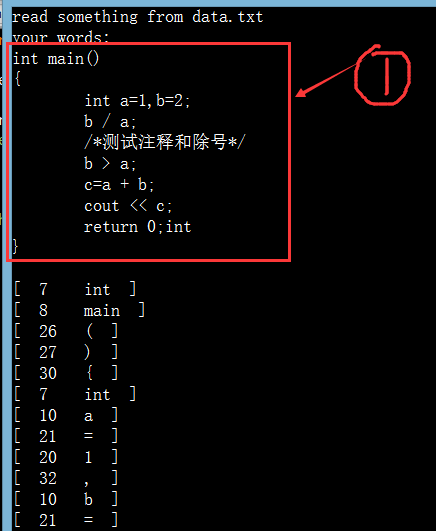
附上data.txt内容:
int main()
{
int a=1,b=2;
b / a;
/*测试注释和除号*/
b > a;
c=a + b;
cout << c;
return 0;int
}代码运行结果如下:
其中标注为1的部分是从data.txt中读取到的小程序,程序输出在小程序下方:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188347.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
