大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
写前bb
最早是看了matlab的代码,搭了环境,demo也跑了,就再也没碰过了。之后想自己把测试和训练部分全部跑通,找了个用pytorch写的代码,看的过程中发现自己还是很多细节部分不是很清楚。虽然文章写的很一笔带过,但是看着代码会发现还是很多疑问的。
代码地址: gayhub
代码的requirements:
Ubuntu
Python 2.7 (use Anaconda 2.* here)
Python-opencv
PyTorch 0.40
我用的是:
Win10
Python 3.6 (use Anaconda 3.*here)
Python-opencv
PyTorch 1.0
Part one —— ILSVRC15-curation
第一部分,ILSVRC15数据集的处理,里面有两个python file,gen_image_crops_VID.py和gen_imdb_VID.py。
- gen_image_crops_VID.py
从名字上就可以很清楚,这个代码是进行图像crop操作的。
examplar_size = 127.0 #模板的尺寸
instance_size = 255.0 #实例的尺寸
context_amount = 0.5 #填充的参数
我们所crop图像需要的数据。
def get_subwindow_avg(im, pos, model_sz, original_sz):
get_subwindow_avg函数是具体进行crop subwindow窗的操作,im指输入的图片,pos指中心点的位置,model_sz指需要得到的尺寸,original_sz指图像输入前的原始尺寸。
context_xmin = round(pos[1] - c) # floor(pos(2) - sz(2) / 2);
context_xmax = context_xmin + sz - 1
context_ymin = round(pos[0] - c) # floor(pos(1) - sz(1) / 2);
context_ymax = context_ymin + sz - 1
其中在计算尺寸大小的时候,作者考虑到python的原始坐标的起点是(0,0),从而会做相应加减1的操作。详情见 #issue15
left_pad = max(0, 1 - context_xmin) # in python, index starts from 0
top_pad = max(0, 1 - context_ymin)
right_pad = max(0, context_xmax - im_sz[1])
bottom_pad = max(0, context_ymax - im_sz[0])
context_xmin = context_xmin + left_pad
context_xmax = context_xmax + left_pad
context_ymin = context_ymin + top_pad
context_ymax = context_ymax + top_pad
后面这些部分的计算,是判断当我根据给定的position和size来进行crop是否会出现超出图片边缘的情况,如果超出的话计算要padding多少。更详细的解释可以参考:SiamFC代码解读 (可以直接看get_subwindow_tracking部分的解释)
if (top_pad != 0) | (bottom_pad != 0) | (left_pad != 0) | (right_pad != 0):
im_R = np.pad(im_R, ((int(top_pad), int(bottom_pad)), (int(left_pad), int(right_pad))), 'constant',
constant_values=avg_chans[0])
im_G = np.pad(im_G, ((int(top_pad), int(bottom_pad)), (int(left_pad), int(right_pad))), 'constant',
constant_values=avg_chans[1])
im_B = np.pad(im_B, ((int(top_pad), int(bottom_pad)), (int(left_pad), int(right_pad))), 'constant',
constant_values=avg_chans[2])
这部分对应论文所提到的,若我们crop出的图片超过了图片边缘的话,则用RGB的均值进行填充。
def get_crops(img, bbox, size_z, size_x, context_amount):
这个函数是根据给的img,x和z的size然后调用上面的get_subwindow_avg函数从而进行crops的。
# for examplar
wc_z = w + context_amount * (w + h)
hc_z = h + context_amount * (w + h)
s_z = np.sqrt(wc_z * hc_z)
scale_z = size_z / s_z
im_crop_z = get_subwindow_avg(img, np.array([cy, cx]), size_z, round(s_z))
这个部分就是对应论文中所提到的,

代码中没有出现p是因为直接用 w + h w+h w+h替换掉了,同时用context_amount = 0.5 代替掉了公式里的二分之一。同时s_z是将原本长宽w,h的图像转换为正方形的边长,scale_z对应论文中公式的s,size_z等于127。这段代码也就是计算出s_z的大小,然后通过get_subwindow_avg函数来先得到基于[cy,cx]为中心,边长为s_z的正方形框再resize到size_z大小,最后返回该图像。
# for search region
d_search = (size_x - size_z) / 2
pad = d_search / scale_z
s_x = s_z + 2 * pad
scale_x = size_x / s_x
im_crop_x = get_subwindow_avg(img, np.array([cy, cx]), size_x, round(s_x))
这部分便是对search region进行操作了,思路是直接在我们计算到的s_z上再加上一圈pad就得到我们所需要的s_x尺寸,不过pad也要进行相应的转换得到的。
def generate_image_crops(vid_root_path, vid_curated_path):
这个函数就是最后的大头部分了~ 输入你存放lLSVRC的地址和你想处理后的图片保存的地址就大功告成了。
- gen_imdb_VID.py
这个代码是用来生成imdb文件的。
for ki in range(len(tmp_keys)):
if len(video_ids[tmp_keys[ki]]) < 2:
del video_ids[tmp_keys[ki]]
105-107行的源代码我运行会出错,原因在于当if条件为真时,删除了相对应的ids之后,最初的for循环里面的len(tmp_keys)是不会有对应的变动的,所以我对着三行代码进行了改写。(感觉是python版本的原因导致的)
while ki<len(tmp_keys):
#if len(video_ids[tmp_keys[ki]]) < 2:
if len(video_ids[list(tmp_keys)[ki]]) < 2:
del video_ids[list(tmp_keys)[ki]]
ki -= 1
ki += 1
使用了while循环,度娘告诉我while循环里面的条件是会实时改变的,改完之后debug了一下,确实能成功跑下去了~这个代码运行完之后,会产生两个imdb文件,imdb_video_train和imdb_video_val,它们被安静存放在你代码文件夹里的ILSVRC15-curation这个文件里,我真的在我存放处理完的图像那个文件里找了很久,导致我以为运行失败又跑了一次!!!!!!
Part two —— Train
Train文件夹里有六个python文件,分别是:Config.py,SiamNet.py,Utils.py,DataAugmentation.py,VIDDataset.py,run_Train_SiamFC.py。
- Config.py
这个文件就是写好了我们需要的参数数值,就稍微提一下两个参数,论文中给出了5个scale时的参数,代码里有给出3s的参数。
self.num_scale = 3
self.scale_step = 1.0375 - SiamNet.py
就是搭SiamNet的网络框架,还是比较好理解的,我贴上打印出来的框架结构。
SiamNet(
(feat_extraction): Sequential(
(0): Conv2d(3, 96, kernel_size=(11, 11), stride=(2, 2))
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), groups=2)
(5): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace)
(7): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1))
(9): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU(inplace)
(11): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), groups=2)
(12): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(13): ReLU(inplace)
(14): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), groups=2)
)
(adjust): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
)
可以留意一下,做卷积的时候是用了group=2的操作,之前没有接触过group convolution,就专门查了一下,就是输入分为group份,同样卷积核也分为group份,然后做完卷积操作之后把每个group的结果contact在一起,这样算下来参数量就减少到1/group倍,当group的大小等于in_channel的时候,就是在进行深度卷积depthwise操作了。
其中有行代码我不是很理解 xcorr_out = torch.reshape(out, (channel_out, batch_size_out, w_out, h_out)) 我知道这步是将out的大小resize成为(C×B×W×H),我不能理解的点是这么操作会不会对out原本的信息做出改变,因为之前的shape是(B×C×W×H),进行resize操作先把out展开然后按顺序排成所需要的shape,这样的话是不是对包含的信息结构有所改变?
- Utils.py
create_logisticloss_label:
输入:label_size, rPos, rNeg
输出:logloss_label
create_label:
输入:fixed_label_size, config, use_gpu
输出:fixed_label, instance_weight
这个部分主要是在写怎么创建标签,create_logisticloss_label这个函数就是通过计算 score map上每个点与中心点的距离大小来判断点的logloss_label是否为1,否则为0。(这里好像和论文有些出入,因为论文的标签给的是1/-1,这里是1或0)。在函数def create_label(fixed_label_size, config, use_gpu),我对label_weight这个参数不是很明白。
instance_weight[tmp_idx_P] = 0.5 * instance_weight[tmp_idx_P] / sumP
instance_weight[tmp_idx_N] = 0.5 * instance_weight[tmp_idx_N] / sumN
对label计算权重是一个什么操作,为什么要做这一步?论文里没有提到过,但是感觉好像是必须要做的一件事(哭泣,自己基础知识真的是太薄弱了,希望有大神可以指点一下)。
- DataAugmentation.py
class RandomStretch
class CenterCrop
class RandomCrop
class Normalize
class ToTensor
都是data augmentation的一些操作,像randomstretch,randomcrop,normalize,totensor这些操作都有见过(但不知道为什么使用这些操作能达到一个什么样的效果,姑且认为是默认操作好了),唯独对center crop这个操作不是很明白,代码作者给的注释是 center crop for examplar z。我的内心是?????为什么还有个对examplar z centercrop ,这一步不是在gen_image_crops_VID.py文件里就做完了吗? - VIDDataset.py
这个python文件就是通过输入Imdb的地址和我们处理过的图像地址,从而读取数据。在运行的过程中,有过报错。
rand_x = np.random.choice(possible_x_pos[max(rand_z - self.config.pos_pair_range, 0):rand_z] + possible_x_pos[(rand_z + 1):min(rand_z + self.config.pos_pair_range, len(video_id_z))])
rand_x = np.random.choice(list(possible_x_pos[max(rand_z - self.config.pos_pair_range, 0):rand_z]) + list(possible_x_pos[(rand_z + 1):min(rand_z + self.config.pos_pair_range, len(video_id_z))]))
错误出现在代码54行,将上述语句替换成第二句语句之后就可以顺利运行了。
- run_Train_SiamFC.py
def train(data_dir, train_imdb, val_imdb, model_save_path="./model/", use_gpu=True):这个函数里,首先做一些data augmentation的操作:
center_crop_size = config.instance_size - config.stride
random_crop_size = config.instance_size - 2 * config.stride
上面两行计算的size我不是很明白,是根据什么来写的?做完这些操作后,load数据然后创建dataloader(pytorch里面需要的操作,将数据放入到data loader里面),接着就是常规操作,定义训练策略。最后,进行training和validation操作,保存两个阶段的loss,每一个epoch结束,就print对应的loss。全部跑完之后,会在model文件里看到有50个model.pth文件。至此,train部分就全部结束了。
我跑的结果 :
Part three —— Tracking
Tracking文件夹里有四个文件,Config.py,SiamNet.py,Tracking_Utils.py,run_SiamFC.py。
- Config.py
和Train文件夹里的没有区别,就是一些要用到的参数。 - SiamNet.py
和之前Train里面是一样的,也就不过多解释了。 - Tracking_Utils.py
又出现了熟悉的身影:def get_subwindow_tracking(im, pos, model_sz, original_sz, avg_chans):,这个函数和我们在gen_image_crops_VID.py用的很像,只不过它的avg_chans是输入量了。
接下来这个函数我觉得是代码里比较难理解的之一:def make_scale_pyramid(im, target_position, in_side_scaled, out_side, avg_chans, p):因为在论文中没怎么提怎么构造scale_pyramid,也没说怎么用的。其实这部分代码是构造三个不同的尺度,然后根据后面不同尺度框选出来的信息好与坏来选择表现更好的尺度,从而达到对尺度的学习。(其实细节方面还是有些小迷糊)
in_side_scaled = np.round(in_side_scaled)
pyramid = np.zeros((out_side, out_side, 3, p.num_scale), dtype=np.double)
max_target_side = in_side_scaled[in_side_scaled.size - 1]
min_target_side = in_side_scaled[0]
beta = out_side / min_target_side
上面这代码中的beta我就很confuse,不是很清楚这个参数是起到一个什么作用,255和最小的边长的比值有什么物理意义?为什么是拿最小的边长进行计算?
for s in range(p.num_scale):
target_side = round(beta * in_side_scaled[s])
search_target_position = np.array([1 + search_side / 2, 1 + search_side / 2], dtype=np.double)
pyramid[:, :, :, s] = get_subwindow_tracking(search_region, search_target_position, out_side,
target_side, avg_chans)
然后通过get_subwindow_tracking来得到不同尺寸下的crop 图片,再把这些图片堆放在pyramid变量里。
def tracker_eval这个函数是做测试部分用到的,也就是跟踪检测阶段的最后一个部分,得到score-map之后来找最大响应的点,然后再把该点返回到原图的位置。其中,代码有几个地方我不是很明白:
if p.num_scale > 1:
current_scale_id =np.ceil(p.num_scale/2) #why?
best_scale = current_scale_id
best_peak = float("-inf")
上面的第二行为什么current_scale_id是选取右边那个值?(不知道依据是什么)。如果if s != current_scale_id:s不是最好的scale的话,该s的scale要乘一个惩罚系数,这个操作就是所谓的尺度惩罚吗,不是很清楚依据是什么,为什么会有效果。然后num_scale次都操作一遍,最后得到经过尺度惩罚之后的score-map。之后对response map进行处理,归一化(这一步操作的原因有大佬知道的话请告诉我,困惑很久了),接着加上余弦窗的影响。In the end,就是把这个最大的点返回到原图的位置了,同时返回最佳的尺度和点的位置。(具体怎么转换的就自己看代码吧,之前一直没看懂这部分,今天恍然之间理解到了~✿✿ヽ(°▽°)ノ✿tracking部分结束了)
- run_SiamFC.py
最后一个代码文件,就是直接运行开跑啦~在此之前我们再来仔细看下代码到底是在干什么,加载模型,加载序列,之后就是之前出现过的操作啦。其中有个操作我不是很明白,# arbitrary scale saturation这个是什么操作?(有大神知道的话求告知一下)
min_s_x = p.scale_min * s_x
max_s_x = p.scale_max * s_x
之后就没有什么了,fps就是一秒处理多少帧的物理意义~ 然后在main函数中,有两种方法评估,单个视频\视频集 ~最后就木有了,就安静等数据跑完就可以了(我下的OTB10数据集有很多问题,如果你跑的时候报错,你可以看下是不是你的视频里有两个groundtruth或者groundtruth里的位置信息不是用逗号分隔的,如果有这些问题需要你手动修改 ~)
Part four ——Evaluation
暑假的时候跑过otb所以知道它对结果的要求是mat文件,这个代码跑出来的是txt文件,所以我百度搜python怎么用otb,找到说pysot-toolkit是可以用的。我就下载下来,然后根据百度教我的操作来做一遍,发现我的结果和他给的有些出入,比如涉及到视频中有两个物体,分成两个视频的话会有groundtruth的对应问题。(不是什么大问题,手动修改就好了~)然后我把结果的后缀名’_SiamFC’手动删除了,最后运行的话就OK了。

可以看出我们跑的结果没有Pysot_toolkit自带的结果好,但是我发现一个很严重的问题!就是我自己跑的视频和它的一些视频的帧数是对不上的,git上issue里有人也提过这个问题,git主说他是按照原otb工具箱来的(emmmm我不是很清楚,我otb数据也是官网下载的啊)最后我发现我用这个工具的话,plot图我是画不出来的!!!!很难受,各种报错。


反正就是画不出自带fig里面好看的图,我也各种度娘找问题,也重新装了glob,opencv-python的版本就是不行。(最后放弃了)由于以上这些问题,心里很不爽,而且感觉结果还是不太可信,所以我就准备转OTB官方工具箱了。
首先就是要把txt文件转换成mat文件,这个度娘就可以解决了~然后就是在otb工具箱添加tracker和我们转换好的结果。具体操作可以看这个:STRCF算法跑OTB调试全过程,在导入数据的时候我有担心就是结果文件名的大小写会不会有影响,结果抛出来的时候就打消了我的疑虑,是没有问题的。最后附上我弄了一下午的成果 ~
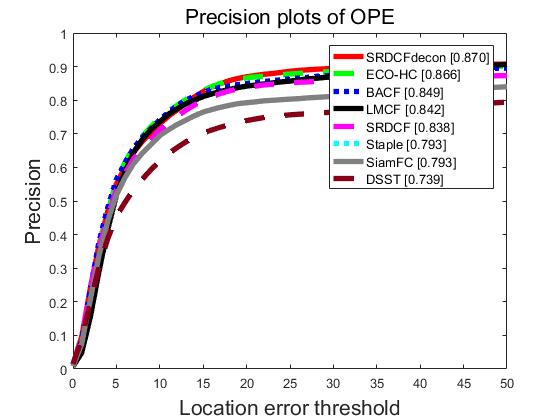
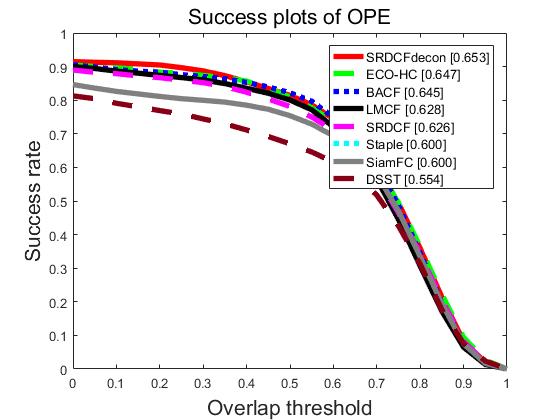
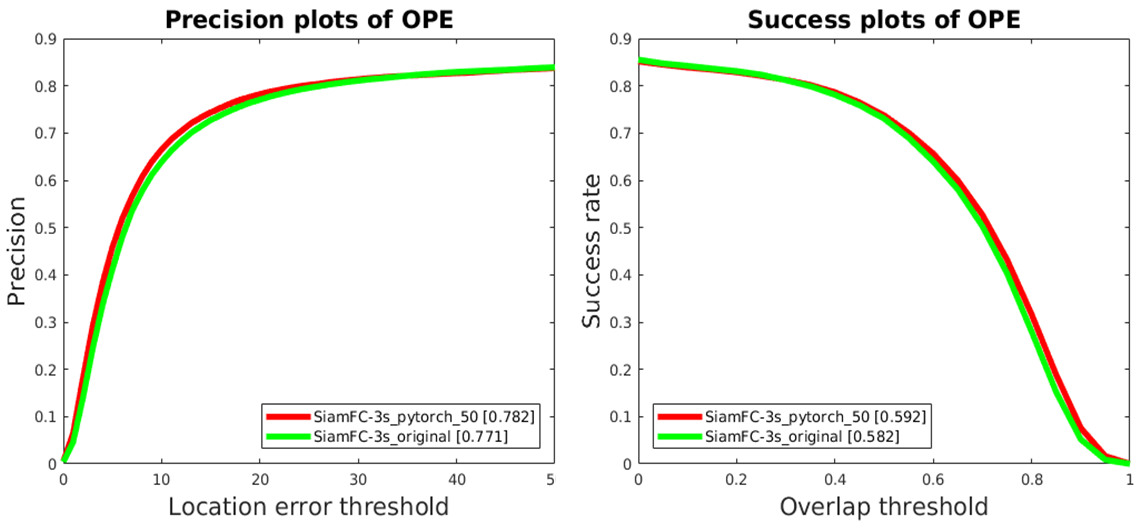
第一张和第二张是我自己跑的结果,第三张是gayhub 上code作者跑出来的结果,可以看出来,结果很近而且感觉我的值还会比他的要高一些。(有点不可思议,因为code作者说python2和3下运行的结果会有些差异,python2运行的结果会好一些emmm我反而是相反的)其实我对这个结果也是有一些疑问的,我觉得工具箱跑的是53个序列的因为anno文件夹只有53个视频的groundtruth,虽然我们放的是100个视频的测试结果。如果真的是跑OTB100应该要有100个视频的标注和属性标注(属性标注应该到哪里下载?),而且我们的数据转换成mat的话还要加上属性信息吧?(我是直接转换成mat操作,所以感觉生成的按类别的图是不是可信度会低一点?)
Siamfc应该可以说是告一段落了,之后准备跑下Updatenet和siamrpn(进度好慢啊呜呜呜),要开始看vot的toolkit了~最后感谢下大尧哥,多亏他们实验室的电脑我才能跑完这个程序,也希望我实验室的设备赶快到吧。最后的最后,感谢我家猪,是我的精神支持和动力哈 ~
希望之后自己有一些新想法吧
2019.11.7
华丽分界线
我又来了,之前对用tracker_benchmark_v1.0画出的图有疑问,今天多靠网友的帮忙终于画出了正确的图!!!!!
我之前的疑问是对的,如果要正确画出OTB100数据集下的图的话,要把benchmark里面的anno文件和ConfigSeqs文件作相应修改,把那100个视频手动加进去~
最后画出的OPE的success图的值确实比之前下降了一些,比源代码的coder结果少一个多点。
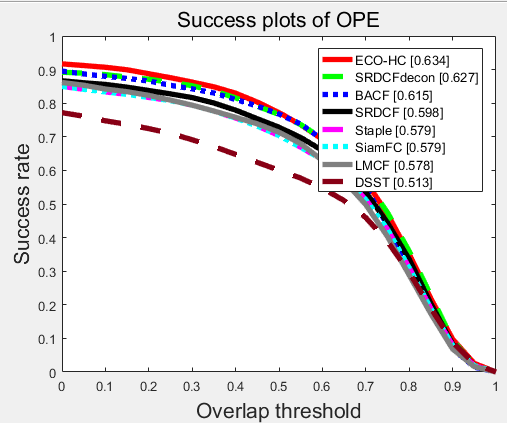
希望之后能把pysot-toolkit的问题解决了~
2019.12.4
华丽分界线
今天把之前挖的坑给填了,之前用pysot-toolkit工具画不出plot图,看别的博客,有好心的博主告诉我是因为没装latex导致会缺少一些字体从而画不出图,我今天把miktex给装好了,然后就可以把图画出来了。刚刚把之前写过的看了一下,发现用otb的benchmark跑和用pysot-toolkit跑出来的success和precision值差很大,找下原因在哪里。
2019.12.20 希望12.30赶快到吧,想见对象了
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/188264.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
