大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
这篇文章是Densely Connected Convolutional Networks的解读,在精简部分内容的同时补充了相关的概念。如有错误,敬请指正。
论文地址:https://arxiv.org/abs/1608.06993
代码地址:https://github.com/liuzhuang13/DenseNet
Abstract
最近在卷及网络方面的进展显示,如果在深层网络中的输入和输出层中加入shortcut连接,会提高正确率和训练效率。根据这一发现,我们提出了一种新的网络结构:DenseNet,以前馈的方式来将每一层和其他所有层连接起来。对于每一层来说,之前所有层的feature maps都将作为输入;同时这一层的feature map将会作为之后所有层的输入。DenseNet有如下优点:减轻了梯度消失的现象;强化了特征传播;高效地重复使用特征;减少了参数的数量。
1. Introduction
当CNN网络深度剧增时,梯度消失的问题凸显出来。ResNet和Highway Networks通过恒等映射将信号传递到更深层的网络。有许多方法对ResNet进行了改进,这些方法虽然在网络拓扑结构,训练方法上有所差异,但实质上有一个重要的共性:在层间进行shortcut连接。
本文将这种思想作了进一步升华:在层间保证最大的信息流动,即将所有层直接连接起来。Figure 1. 展示了这种结构。
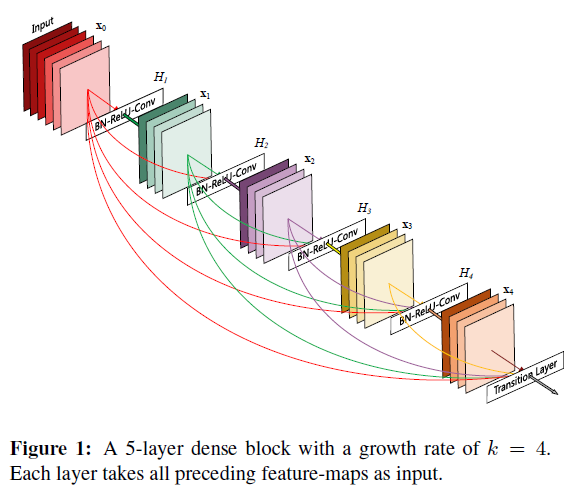

和ResNet不同的是,DenseNet在features流向下一层之前,不做叠加,而是通过层间的连接将特征融合。因此,第
ℓ
层将会有
ℓ
个输入,由之前的所有层的卷积模块的特征图组成。而这一层的特征图将会输入到之后的
L−ℓ
层。因此,对于一个
L
层的网络,将会产生
L(L+1)/2
个连接,而不是像传统的网络架构那样,只有
L
条连接。
这种连接貌似会产生更多的参数,但实际上DenseNet所需的参数要比传统的神经网络少。因为网络不需要学习冗余的特征图。在传统的前馈网络中,每一层网络都需要从前一层中获得输入,经过变换后再传入下一层。ResNet将需要保留的信息显式地通过恒等变换传入之后的层。但是因为ResNet每一层都有自己的权重参数,所以参数总数更多。DenseNet对输入网络中的信息和需要保留的信息作出了显示的区分。DenseNet的层非常窄,比如只有每层只有12个filter。并且只对网络中共有信息增添了一小部分feature map,其余的特征图保持不变。最后的分类器基于网络中所有的特征图来进行最终的判别。
DenseNet的另一个优势是优化的信息和梯度流动。因为每一层都和损失函数的梯度有直接的连接。更重要的是,密集连接具有正则化的作用,可以减小在较小数据集上的过拟合。
2. Related Work
与深层网络优化相关的工作有:
- Highway Networks:可训练达100层的网络 ResNet stochastic
- depth训练方法:证明了深层网络实际上存在大量的参数冗余
- Network in Network(NIN):在网络中加入了多层微网络结构,以提取更加复杂的特征
- Deeply Supervised Network(DSN):由额外的分类器来监督内层网络的学习过程,可以增强靠前的多层网络接收到的梯度。
- Ladder Networks:在自编码器中引入了侧向连接,在半监督学习中产生了很好的效果。
- Deeply-Fused Nets (DFNs) :不同分支的网络在中间层进行融合(加和或拼接等方式),能够(1)产生很多潜在的共享参数的基础网络,(2)同时优化信息的流动,(3)从而帮助深层网络的训练过程。
DenseNet的创新在于,不是简单地通过加深网络层数或者拓展单层的宽度来获得新的网络架构,而是通过特征重用(feature reuse)来获得很高的参数利用率。
3. DenseNets
假设图像输入为
x0
Hℓ(⋅)
ResNets.
ResNet在原始网络的基础上增加了一个恒等映射:
xℓ=Hℓ(xℓ−1)+xℓ−1
ResNet的优点是,在反向传播的时候,靠后层的梯度可以通过恒等映射直接传导到之前的层。但是注意恒等映射 xℓ−1 和 Hℓ 是直接相加的,这可能导致对信息传递的阻碍。
Dense connectivity.
为了提高信息在层间的传递,我们将每一层和其他的层直接连接起来。此时,第 ℓ 层接收到之前所有层的特征图作为输入:
xℓ=Hℓ([x0,x1,...,xℓ−1])
为方便实现,将多重输入 [x0,x1,...,xℓ−1] 连接成一个张量。
Composite function.
将 Hℓ 定义成一个复函数,包含BN,ReLU和一个 3×3 卷积。
Pooling layers.
以上公式中使用的连接操作在特征图大小改变的时候将变得不可行。而卷积中的down-sampling操作又正好会改变特征图的大小。为了解决这个问题,将网络变成多个密集连接的dense blocks,如下图:
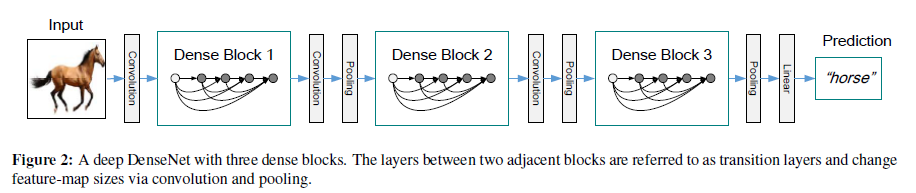
将相邻两个dense blocks之间的层称作transition layers,进行卷积和池化操作。在实验中使用的transition layers包含一个BN,一个
1×1
卷积层和一个
2×2
池化层。
Growth rate
如果每一个 Hℓ 产生 k 个特征图,那么第
ℓ
Bottleneck layers
1∗1
Compression
为了使模型更加紧凑,可以减少transition layers中的特征图数量。如果一个dense block中有 m 个特征图,可以令紧接着的transition layer生成
[θm]
Implementation Details
除开ImageNet,在实验中使用的DenseNet都有三个dense block,每一个都有相同数量的layer。在输入数据进入第一个dense block之前,会首先经过一个有16(对于DenseNet-BC,数量是增长率的两倍)个输出通道的卷积层。卷积核的大小为 3×3 ,使用zero-padded来保持特征图大小固定。在最后一个dense block,使用global average pooling,紧接着使用一个softmax分类器。对于三个不同的dense block,分别使用 32×32 、 16×16 、 8×8 的特征图大小。实验中使用如下几种配置:
{
L=40,k=12} 、 {
L=100,k=12} 、 {
L=100,k=24} 。对于DenseNet-BC,以下配置:
{
L=100,k=12} 、 {
L=250,k=24} 、 {
L=190,k=40} 也进行了实验。
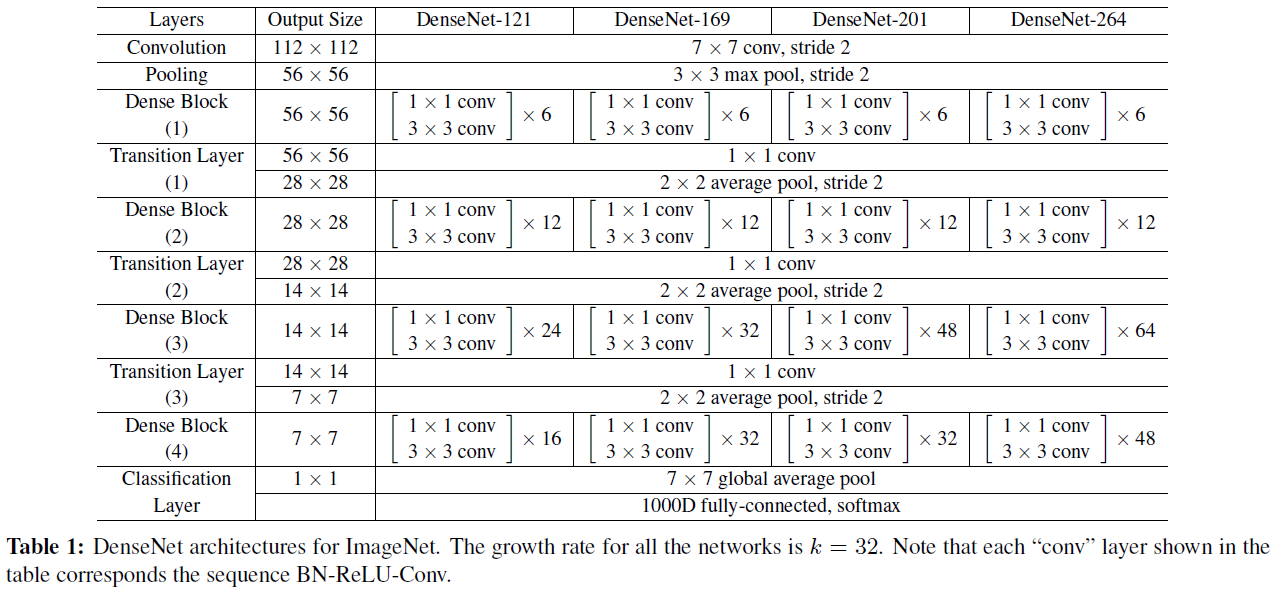
在ImageNet上,使用了如下的DenseNet-BC结构:
4个dense block, 224×224 个输入图像。初始的卷积层由 2×k 个卷积组成,大小为 7×7 ,步长为2。其他所有层的特征图数量为 k 。具体细节详见Table1。
4. Experiments
在CIFAR和SVHN数据集上的实验结果如下:
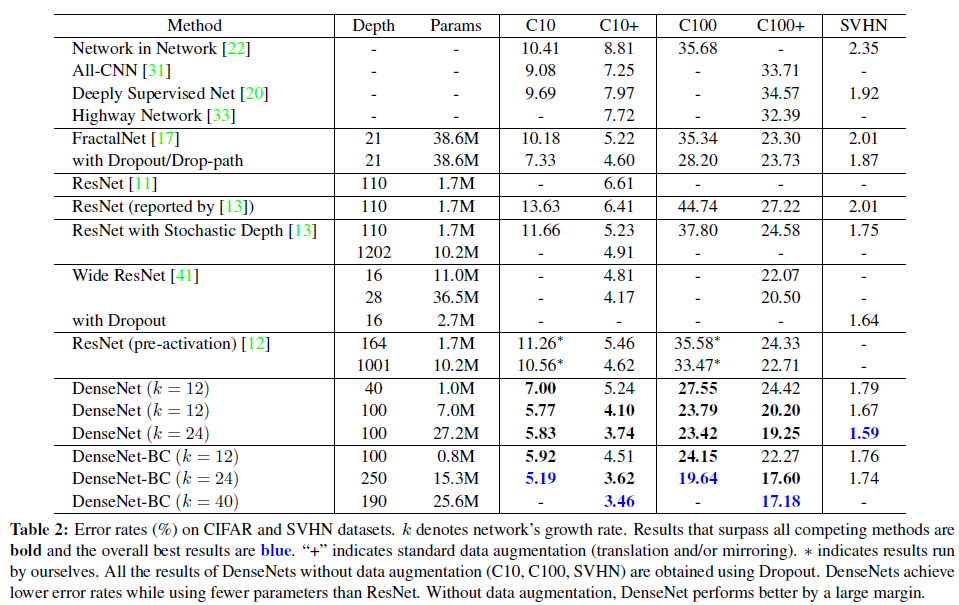
Classification Results on CIFAR and SVHN
Accuracy.
使用不同的深度
L
L=190
Parameter Efficiency.
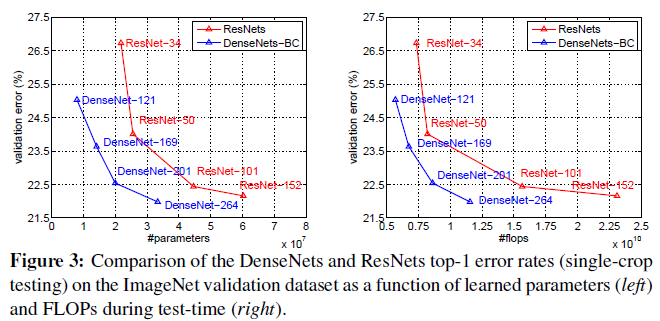
250层的DenseNet模型仅仅有15M参数,正确率高于有30M参数的FractalNet和Wide ResNets。Figure 3给出了ResNet和DenseNet-BC的比较。
4.4. Classification Results on ImageNet
FIgure 4给出了在ImageNet上的详细测试结果:

5. Discussion
Model compactness
因为DenseNet中使用了密集连接的方式,特征图能被所有层共享,提高了特征重用的效率,也使得模型更加紧凑。从FIgure 4中可以发现,对于6%左右的测试误差,DenseNet的参数为ResNet的三分之一。对于性能相似的ResNet-1001和DenseNet-100,前者参数数量为10M,后者仅为0.8M。
Implicit Deep Supervision
DenseNet正确率提高的一种解释是,每一层通过shortcut收到了来自损失函数的额外监督(additional supervision)。关于deeply-supervised nets(DSN)的解释可见1,DSN在每一个隐层中都使用了分类器,使中间层学习分类特征。
DenseNet使用一种隐式的deep supervision策略,即只在网络终端使用一个单独的分类器来直接监督所有的层。但是相对DSN来说,DenseNet的损失函数和梯度要相对简单一些,因为所有的层都共享一个损失函数。
Feature Reuse
DenseNet的网络结构允许每一层利用之前层的特征。可以设计实验来验证这一点,在C10+数据集上使用 L=40 、 k=12 的DenseNet,对于每一个block中的卷积层 ℓ ,计算被分配给 s 层的平均权重。Figure 5 给出了3个Dense block的图示。 平均绝对权重代表了卷积层对之前层的依赖性。位置
(ℓ,s)
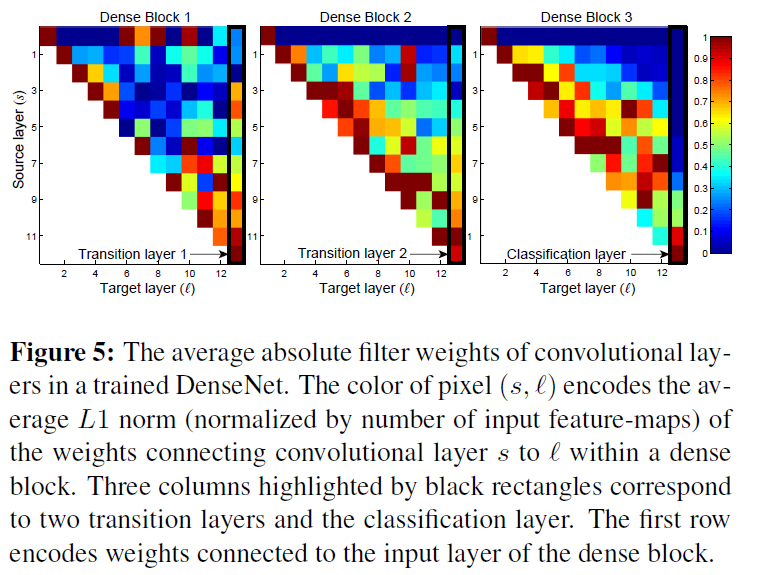
从图中可以发现如下规律:
- 所有的层将权重传播到同一个block,这表明靠后层通过同一个dense block使用了靠前层的特征
- Transtions layer在它之前的所有层传播了权重,表明信息通过间接的方式从前向后流动
- 第二和第三个dense block 中的层没有想transition layer 的输出层(三角形最上边的一行)分配权重,说明transition layer输出了许多冗余的特征(平均权重很低)
- 虽然最终的分类层(最右边的一层)使用了整个dense block的权重,但是从图上能发现最后的特征图权重的集中,这暗示了在网络的最后几层可能产生了高阶特征。
- C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu. Deeplysupervised
nets. In AISTATS, 2015. ↩
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187882.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
