大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
作为一个计算机底层小白,在了解一个知识点的时候时常需要恶补很多基础知识。
本文记录在了解LMDB过程中接触的知识点。
LMDB基本架构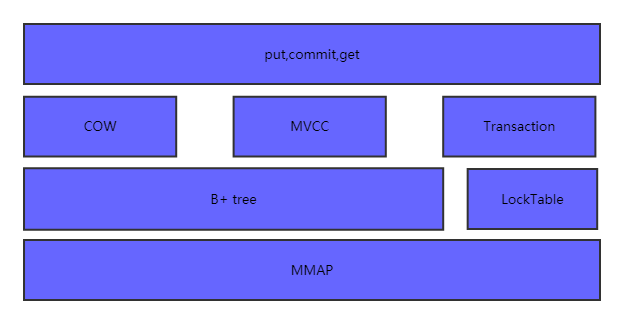

一个比较官方的解释:lmdb的基本做法是使用mmap文件映射,不管这个文件存储实在内存上还是在持久存储上。lmdb的所有读取操作都是通过mmap将要访问的文件只读的映射到虚拟内存中,直接访问相应的地址.因为使用了read-only的mmap,同样避免了程序错误将存储结构写坏的风险。并且IO的调度由操作系统的页调度机制完成。而写操作,则是通过write系统调用进行的,这主要是为了利用操作系统的文件系统一致性,避免在被访问的地址上进行同步。
lmdb把整个虚拟存储组织成B+Tree存储,索引和值读存储在B+Tree的页面上.对外提供了关于B+Tree的操作方式,利用cursor游标进行。可以进行增删改查。
解读
慢慢解读上面这段话。
1. mmap
Memory map: 一种内存映射文件的方法。mmap将一个文件或者其他对象映射进内存。 文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap在用户空间映射调用系统中作用很大。
2. 内存映射文件原理
映射:建立一种一 一对应关系。
在这里主要是指 硬盘上文件 的位置与进程 逻辑地址空间 中一块大小相同的区域之间的一 一对应,如图1中过程1所示。这种对应关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在的。在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space),这个过程由系统调用mmap()实现,所以建立内存映射的效率很高。
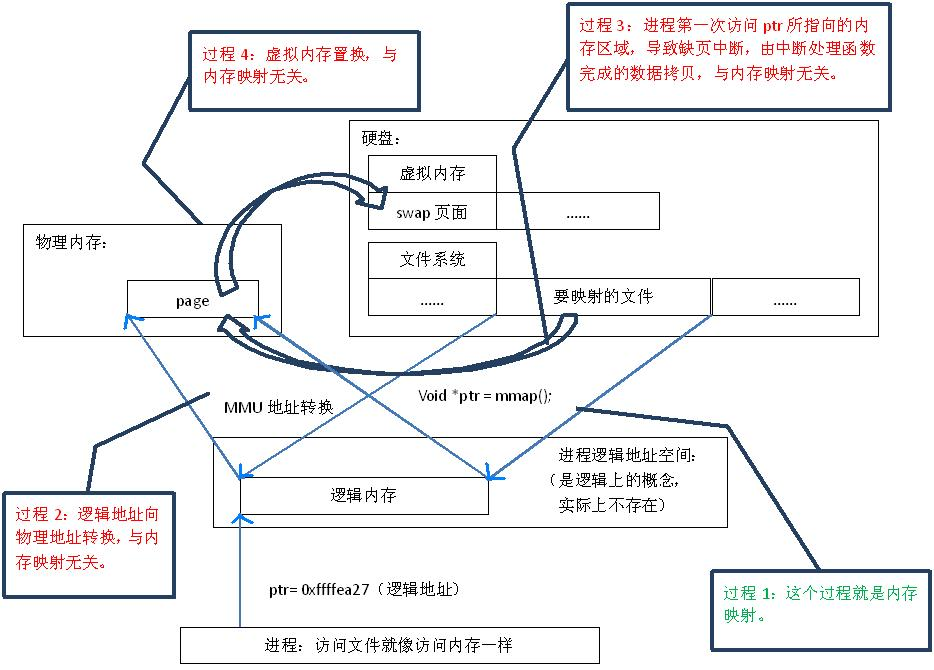 图1.内存映射原理
图1.内存映射原理
既然建立内存映射没有进行实际的数据拷贝,那么进程又怎么能最终直接通过内存操作访问到硬盘上的文件呢?那就要看内存映射之后的几个相关的过程了。
- mmap()会返回一个指针ptr,它指向进程逻辑地址空间中的一个地址,这样以后,进程无需再调用read或write对文件进行读写,而只需要通过ptr就能够操作文件。但是ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,如图1中过程2所示。这个过程与内存映射无关。
- 前面讲过,建立内存映射并没有实际拷贝数据,这时,MMU(Memory Management Unit,内存管理单元)在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬盘上将文件读取到物理内存中,如图1中过程3所示。这个过程与内存映射无关。
- 如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘上,如图1中过程4所示。这个过程也与内存映射无关。
文件系统:硬盘上组织、存储和命名文件的结构。在所有的计算机系统中,都存在一个相应的文件系统,它规定了计算机对文件和文件夹进行操作处理的各种标准和机制。
进程 逻辑地址空间:
虚拟内存:虚拟内存别称虚拟存储器(Virtual Memory)。电脑中所运行的程序均需经由内存执行,若执行的程序占用内存很大或很多,则会导致内存消耗殆尽。为解决该问题,Windows中运用了虚拟内存技术,即匀出一部分硬盘空间来充当内存使用。当内存耗尽时,电脑就会自动调用硬盘来充当内存,以缓解内存的紧张。若计算机运行程序或操作所需的随机存储器(RAM)不足时,则 Windows 会用虚拟存储器进行补偿。它将计算机的RAM和硬盘上的临时空间组合。当RAM运行速率缓慢时,它便将数据从RAM移动到称为“分页文件”的空间中。将数据移入分页文件可释放RAM,以便完成工作。 一般而言,计算机的RAM容量越大,程序运行得越快。若计算机的速率由于RAM可用空间匮乏而减缓,则可尝试通过增加虚拟内存来进行补偿。但是,计算机从RAM读取数据的速率要比从硬盘读取数据的速率快,因而扩增RAM容量(可加内存条)是最佳选择。
虚拟内存是Windows 为作为内存使用的一部分硬盘空间。虚拟内存在硬盘上其实就是为一个硕大无比的文件,文件名是PageFile.Sys,通常状态下是看不到的。必须关闭资源管理器对系统文件的保护功能才能看到这个文件。虚拟内存有时候也被称为是“页面文件”就是从这个文件的文件名中来的。
总结:内存在计算机中的作用很大,电脑中所有运行的程序都需要经过内存来执行,如果执行的程序很大或很多,就会导致内存消耗殆尽。为了解决这个问题,WINDOWS运用了虚拟内存技术,即拿出一部分硬盘空间来充当内存使用,这部分空间即称为虚拟内存,虚拟内存在硬盘上的存在形式就是 PAGEFILE.SYS这个页面文件。
效率对比
从代码层面上看,从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一样的。但是通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高,这是为什么呢?原因是read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,如图2中过程1,然后再将这些数据拷贝到用户空间,如图2中过程2,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比read/write效率高。
Q:read系统调用为什么不直接把磁盘上的数据读到用户空间,而是先读到内核空间再读到用户空间啊?
A: read和write都是内核指令,所以内核中有对应的缓冲区。
补充:
#linux下的缓存机制及清理buffer/cache/swap的方法梳理
缓存机制介绍
写的很好:https://www.cnblogs.com/kevingrace/p/5991604.html
在Linux系统中,为了提高文件系统性能,内核利用一部分物理内存分配出缓冲区,用于缓存系统操作和数据文件,当内核收到读写的请求时,内核先去缓存区找是否有请求的数据,有就直接返回,如果没有则通过驱动程序直接操作磁盘。
缓存机制优点:减少系统调用次数,降低CPU上下文切换和磁盘访问频率。
cache是高速缓存,用于CPU和内存之间的缓冲;
buffer是I/O缓存,用于内存和硬盘的缓冲;
CPU上下文切换:CPU给每个进程一定的服务时间,当时间片用完后,内核从正在运行的进程中收回处理器,同时把进程当前运行状态保存下来,然后加载下一个任务,这个过程叫做上下文切换。实质上就是被终止运行进程与待运行进程的进程切换。
Swap用途:Swap意思是交换分区,对应通常我们说的虚拟内存,是从硬盘中划分出的一个分区。当物理内存不够用的时候,内核就会释放缓存区(buffers/cache)里一些长时间不用的程序,然后将这些程序临时放到Swap中,也就是说如果物理内存和缓存区内存不够用的时候,才会用到Swap。
swap清理:swapoff -a && swapon -a
注意:这样清理有个前提条件,空闲的内存必须比已经使用的swap空间大。
虚拟内存和swap分区的关系
首先,这两个概念分别对应windows和linux,即:
windows:虚拟内存
linux:swap分区
windows即使物理内存没有用完也会去用到虚拟内存,而Linux不一样 Linux只有当物理内存用完的时候才会去动用虚拟内存(即swap分区)
swap类似于windows的虚拟内存,不同之处在于,Windows可以设置在windows的任何盘符下面,默认是在C盘,可以和系统文件放在一个分区里。而linux则是独立占用一个分区,方便由于内存需求不够的情况下,把一部分内容放在swap分区里,待内存有空余的情况下再继续执行,也称之为交换分区,交换空间是其中的部分
windows的虚拟内存是电脑自动设置的
Linux的swap分区是你装系统的时候分好的。
参考:http://wiki.dreamrunner.org/public_html/C-C++/Library-Notes/LMDB.html
https://www.cnblogs.com/kevingrace/p/5991604.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187850.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
