大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
1. 简介
DenseNet 见于论文《Densely Connected Convolutional Networks》,是 CVPR2017 的 oral。一般而言,为提升网络效果,研究者多从增加网络深/宽度方向着力。但 DenseNet 另辟蹊径,聚焦于特征图的极致利用。延续借助跳层连接解决梯度消失 (如 ResNet) 的思路,论文提出的 Dense Block 将所有层直接相连 (密集连接),保证特征信息最大程度的传输利用,大幅提升网络性能。
2. DenseNet 浅析
2.1 网络结构
DenseNet主要由 Dense Block 和 Transition Layer 两部分组成,Fig.1 中展示了一个含有 3 个 Dense Block 的 DenseNet。Dense Block是网络的关键模块,由多个Bottleneck Layer叠加而成。Dense Block 中各层间采用密集连接,每层输出的大小保证相同。Dense Block 中 Bottleneck Layer 的个数并不固定,这构成了不同的 DenseNet。Fig.2 中给出了 DenseNet-121、DenseNet-169、DenseNet-201 和 DenseNet-264 四种 DenseNet 的详细参数。Transition Layer位于两个 Dense Block 之间,使用 1×1 卷积减少通道数 (减半),通过最大池化降低特征图大小。
密集连接是 DenseNet 的灵魂,其通过建立不同层之间的连接关系,充分利用特征信息,缓解梯度消失现象,提升网络训练效果。此外,DenseNet 使用 Bottleneck Layer,Translation Layer 和 growth rate (即 Dense Block 中各层的输出通道数) 控制通道数量,在减少参数和抑制过拟合的同时,大幅减少计算量。
  |
| Fig.1 DenseNet 网络结构 |
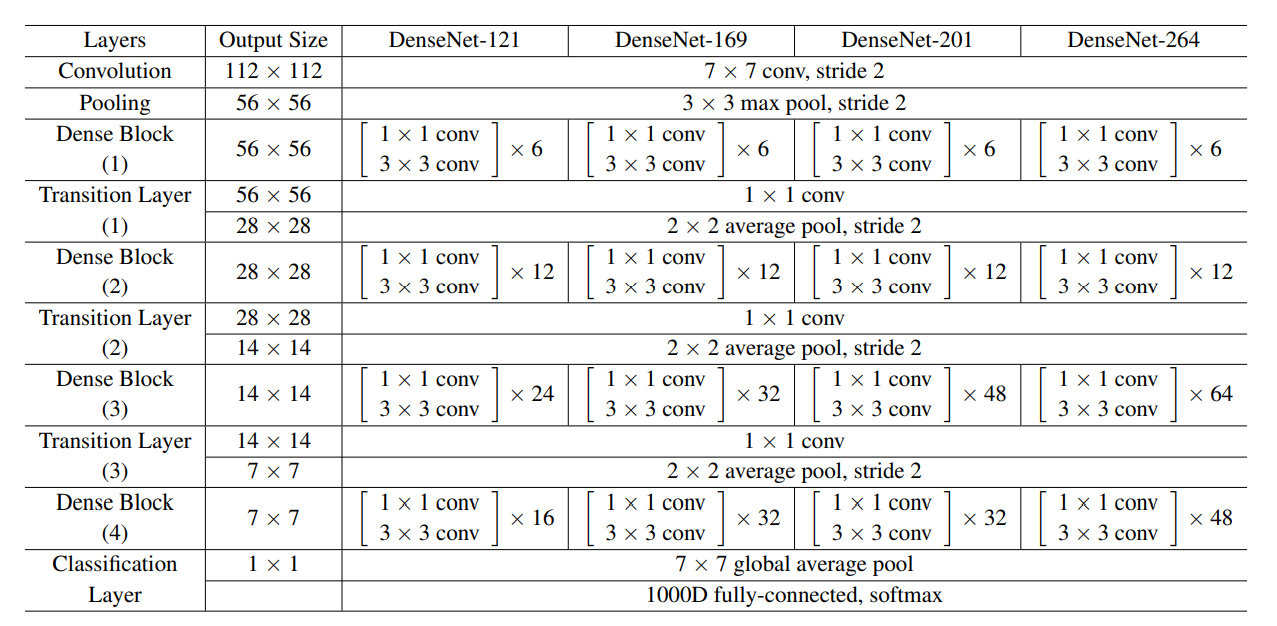 |
| Fig.2 DenseNet 网络参数 |
2.2 Dense Block
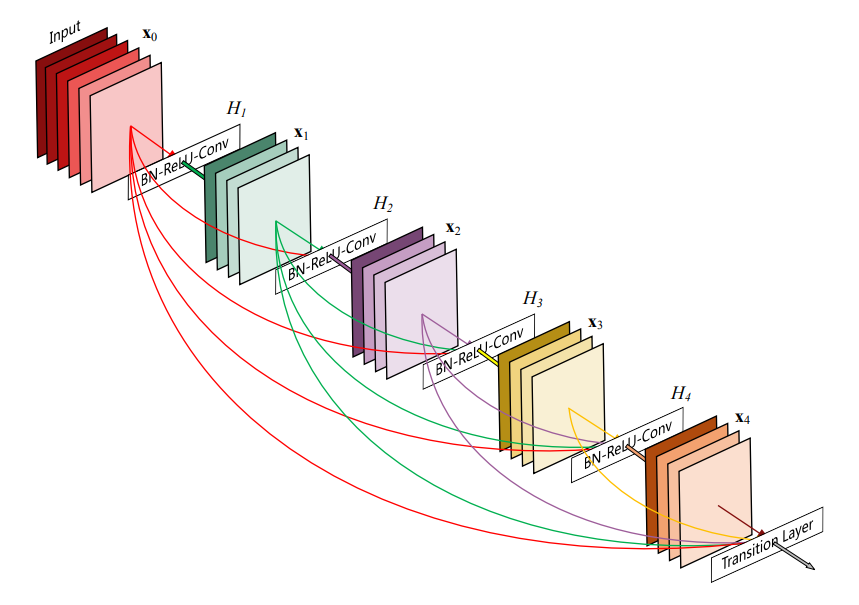 |
| Fig.3 Dense Block 结构 |
Dense Block 详细结构如 Fig.3 所示,从图中可以直观地看出以下几点:
- Dense Block 中各层间是密集连接的;
- 各层输出特征图的大小是相同的;
- 各层的输出通道数是相同的。
在连接数量方面, L L L 层的传统卷积神经网络对应 L L L 个连接,Residual Block 则会增加一个从输入到输出的连接。但在 Dense Block 中, L L L 层的网络将会有 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1) 个连接,每一层的输入来自前面所有层的输出。对于网络输出而言,传统卷积神经网络的第 t t t 层输出为:
x t = h ( x t − 1 ) x_t = h(x_{t-1}) xt=h(xt−1)
ResNet 的第 t t t 层输出为:
x t = h ( x t − 1 ) + x t − 1 x_t = h(x_{t-1}) + x_{t-1} xt=h(xt−1)+xt−1
Dense Block 中的第 t t t 层输出为:
x t = h ( [ x 0 , ⋯ , x t − 1 ] ) x_t = h([x_0, \cdots, x_{t-1}]) xt=h([x0,⋯,xt−1])
借助以上公式,更清晰地显示出 Dense Block 的独特
Dense Block 中各层的特征图大小一致,因此可以在通道维度上进行拼接。假定输入特征图的通道数为 k 0 k_0 k0,Dense Block 中各层均输出 k k k 个特征图 ( k k k 为 growth rate),则第 l l l 层输入的通道数为 k 0 + ( l − 1 ) k k_0+(l−1)k k0+(l−1)k。Dense Block 采用了pre-activation方式,即 BN-ReLU-Conv 的顺序,激活函数在前、卷积层在后。一般模型通常使用post-activation方式,即 Conv-BN-ReLU 的顺序,激活函数在卷积层之后,但作者证明采用这种方式会导致性能变差。根据 Dense Block 的设计,后面的层可以得到前面所有层的输入,因此在拼接后的通道数量较多。为此,在每个 DenseBlock 中的 3×3 卷积前都有一个 1×1 的卷积,降低输入特征图的数量,减少计算量。此外,为进一步压缩参数,在 Dense Block 之间也使用了 1×1 卷积 (Translation Layer)。在论文的实验对比中,DenseNet-C 网络表示使用了 Translation Layer,将输出的通道数减半。DenseNet-BC 网络表示既有 Bottleneck Layer,又有 Translation Layer。再网络训练过程中,还使用 Dropout 来随机减少分支,避免过拟合。
总而言之,Dense Block 使得网络结构更加紧凑,参数更少。密集连接使得特征图和梯度的传递更加有效,网络训练更加容易。
2.3 Bottleneck Layer
密集连接使得 Dense Block 中后面层的输入剧增,因此 Dense Block 中使用了 Bottleneck Layer,借助 Bottleneck 结构控制通道数,减少计算量。 一个 Bottleneck Layer 的网络结构如 Fig.4 所示,各层的顺序为 B N + R e L U + 1 × 1 ⋅ C o n v + B N + R e L U + 3 × 3 ⋅ C o n v \rm\small BN + ReLU + 1 \times 1 \cdot Conv + BN + ReLU + 3 \times 3 \cdot Conv BN+ReLU+1×1⋅Conv+BN+ReLU+3×3⋅Conv。 Bottleneck 结构主要聚焦于降低 Dense Block 内部的通道数量。
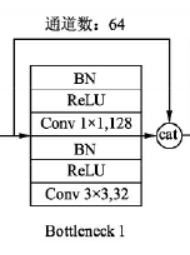 |
| Fig.4 Bottleneck Layer 结构 |
2.4 Trainsition Layer
与 Bottleneck 结构不同,Trainsition Layer 主要聚焦于控制 Dense Block 之间的通道数量。Trainsition Layer 连接两个相邻的 Dense Block,使用一个1×1 的卷积降低通道数,使用一个 2×2 的 AvgPooling 调整特征图大小,起到压缩模型的作用。一个 Trainsition Laye 中各层的顺序为 B N + R e L U + 1 × 1 ⋅ C o n v + 2 × 2 ⋅ A v g P o o l i n g \small BN + ReLU + 1 \times 1 \cdot Conv + 2 \times 2 \cdot AvgPooling BN+ReLU+1×1⋅Conv+2×2⋅AvgPooling。
3. 个人理解
-
DenseNet = Dense Block + Trainsition Layer。其中,Dense Block 由多个 Bottleneck Layer 构成,Trainsition Layer 和 Bottleneck Layer 都对通道数量进行控制。 -
ResNet 通过建立 “短路连接” 助力梯度的反向传播,从而训练出更深的网络。DenseNet 则更进一步,互相连接所有的层 (密集连接),更大程度上复用特征,提升网络性能。
-
DenseNet 的优势
- 密集连接改进网络的信息流和梯度,更有效地利用特征,加强梯度传播,缓解了梯度消失现象。
- 使用 Bottleneck Layer 和 Transition Layer 减少参数量,加速网络训练。
- 密集连接具有正则化效应 ,缓解了训练集规模较小任务中的过拟合现象。
- DenseNet 并未从极深 (如 ResNet) 或极宽 (如 GoogLeNet) 的架构中获取表征能力,而是通过特征重用来挖掘网络潜力,产生易于训练和高参数效率的压缩模型。
- 标准卷积网络只利用最高层次的特征,但 DenseNet 使用了不同层次的特征 (包括低维度特征)。DenseNet 倾向于给出更平滑的决策边界,这也是 DenseNet 在训练数据不足时表现依旧良好的原因。
- DenseNet 的劣势
- DenseNet 需要进行多次拼接操作,数据需要被复制多次,显存增加得很快,需要一定的显存优化技术。
- 与 ResNet 相比,DenseNet 是一种更为特殊的网络,因此 ResNet 的应用范围更广。
4. DenseNet-121 的 PyTorch 实现
import torch
import torch.nn as nn
from torchinfo import summary
from collections import OrderedDict
import torch.nn.functional as F
class Bottleneck(nn.Module):
def __init__(self, in_features, growth_rate, bn_size, drop_rate):
super(Bottleneck, self).__init__()
out_features = bn_size * growth_rate
# 1x1卷积
self.norm1: nn.BatchNorm2d
self.add_module('norm1', nn.BatchNorm2d(in_features))
self.relu1: nn.ReLU
self.add_module('relu1', nn.ReLU(inplace=True))
self.conv1: nn.Conv2d
self.add_module('conv1', nn.Conv2d(in_features, out_features, kernel_size=1, stride=1, bias=False))
# 3x3卷积
self.norm2: nn.BatchNorm2d
self.add_module('norm2', nn.BatchNorm2d(out_features))
self.relu2: nn.ReLU
self.add_module('relu2', nn.ReLU(inplace=True))
self.conv2: nn.Conv2d
self.add_module('conv2', nn.Conv2d(out_features, growth_rate, kernel_size=3, stride=1, padding=1, bias=False))
# Dropout
self.drop_rate = float(drop_rate)
def forward(self, x):
new_features = self.conv1(self.relu1(self.norm1(x)))
new_features = self.conv2(self.relu2(self.norm2(new_features)))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
new_features = torch.cat([x, new_features], 1) # Bottleneck
return new_features
class TransitionLayer(nn.Sequential):
def __init__(self, in_features, out_features):
super(TransitionLayer, self).__init__()
self.add_module('norm', nn.BatchNorm2d(in_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(in_features, out_features, kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class DenseBlock(nn.Sequential):
def __init__(self, in_features, growth_rate, num_layers, bn_size, drop_rate):
super(DenseBlock, self).__init__()
for i in range(num_layers):
layer = Bottleneck(in_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module("dense_layer%d" % (i + 1), layer)
class DenseNet121(nn.Module):
def __init__(self, block_config, growth_rate, num_init_features, bn_size=4, drop_rate=0, num_classes=100):
super(DenseNet121, self).__init__()
# First Conv
# 特征图大小:224 -> 卷积 -> 112 -> 最大池化 -> 56
# 通道数变化:3 -> 卷积 -> num_init_features=64
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
# Each DenseBlock - 4 个DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
Block = DenseBlock(num_features, growth_rate, num_layers, bn_size, drop_rate)
self.features.add_module('dense_block%d' % (i + 1), Block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1: # 非最后一个DenseBlock
trans = TransitionLayer(num_features, num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2 # 通道数减半
# Final BN
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# Classification Layer
self.avg = nn.AvgPool2d(kernel_size=7, stride=1)
self.classifier = nn.Linear(num_features, num_classes)
def forward(self, x):
x = self.features(x)
x = F.relu(x, inplace=True)
x = self.avg(x)
x = torch.flatten(x, 1)
out = self.classifier(x)
return out
if __name__ == "__main__":
growth_rate = 8
num_init_features = 64
block_config = [6, 12, 24, 16] # 各DenseBlock中Bottle Layer的个数
x = torch.randn(1, 3, 224, 224)
net = DenseNet121(block_config, growth_rate, num_init_features)
y = net(x)
summary(net, (1, 3, 224, 224), depth=4)
【参考】
- DenseNet算法详解;
- [ 图像分类 ] 经典网络模型5——DenseNet 详解与复现;
- DenseNet论文详解及PyTorch复现;
- [网络结构]DenseNet网络结构;
- DenseNet网络结构的讲解与代码实现;
- DenseNet详解;
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187822.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
