大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
经典网络DenseNet(Dense Convolutional Network)由Gao Huang等人于2017年提出,论文名为:《Densely Connected Convolutional Networks》,论文见:https://arxiv.org/pdf/1608.06993.pdf
DenseNet以前馈的方式(feed-forward fashion)将每个层与其它层连接起来。在传统卷积神经网络中,对于L层的网络具有L个连接,而在DenseNet中,会有L(L+1)/2个连接。每一层的输入来自前面所有层的输出。
DenseNet网络:
(1).减轻梯度消失(vanishing-gradient)。
(2).加强feature传递。
(3).鼓励特征重用(encourage feature reuse)。
(4).较少的参数数量。
Dense Block:像GoogLeNet网络由Inception模块组成、ResNet网络由残差块(Residual Building Block)组成一样,DenseNet网络由Dense Block组成,论文截图如下所示:每个层从前面的所有层获得额外的输入,并将自己的特征映射传递到后续的所有层,使用级联(Concatenation)方式,每一层都在接受来自前几层的”集体知识(collective knowledge)”。增长率(growth rate) 是每个层的额外通道数。
是每个层的额外通道数。

Growth rate:如果每个函数产生个feature-maps,那么第层产生个feature-maps。是输入层的通道数。将超参数称为网络的增长率。
DenseNet Basic Composition Layer:BatchNorm(BN)-ReLu-3*3 Conv
DenseNet-B(Bottleneck Layers):在BN-ReLu-3*3 Conv之前进行BN-ReLU-1*1 Conv操作,减少feature maps size。
Transition Layer(过渡层):采用1*1 Conv和2*2平均池化作为相邻Dense Block之间的转换层,减少feature map数和缩小feature map size,size指width*height。在相邻Dense Block中输出的feature map size是相同的,以便它们能够很容易的连接在一起。
DenseNet-BC:如果Dense Block包含个feature-maps,则Transition Layer生成输出feature maps,其中称为压缩因子。当时,通过Transition Layers的feature-maps数保持不变。当时,称为DenseNet-C,在实验中。当同时使用Bottleneck和的Transition Layers时,称为DenseNet-BC。
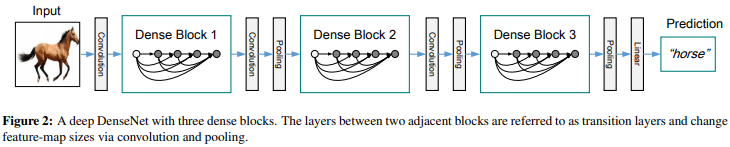
下图是一个DenseNet结构图,来自于论文:使用了3个Dense Blocks。DenseNet由多个Desne Block组成。每个Dense Block中的feature-map size相同。两个相邻Dense Block之间的层称为Transition Layers。通过卷积和池化来更改feature-map size。
论文中给出了4种层数的DenseNet,论文截图如下所示:所有网络的增长率是32,表示每个Dense Block中每层输出的feature map个数。
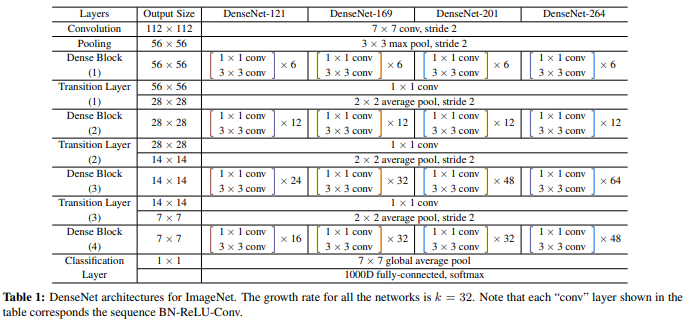
DenseNet-121、DenseNet-169等中的数字121、169是如何计算出来的:以121为例,1个卷积(Convolution)+6个Dense Block*2个卷积(1*1、3*3)+1个Transition Layer(1*1 conv)+12个Dense Block*2个卷积(1*1、3*3)+ 1个Transition Layer(1*1 conv)+24个Dense Block*2个卷积(1*1、3*3)+ 1个Transition Layer(1*1 conv)+ 16个Dense Block*2个卷积(1*1、3*3)+最后的1个全连接层=121。这里的层仅指卷积层和全连接层,其它类型的层并没有计算在内
公式表示:其中表示非线性转换函数
(1).传统的网络在层的输出为:
(2).ResNet在l层的输出为:
(3).DenseNet在l层的输出为:
假如输入图像大小为n*n,过滤器(filter)为f*f,padding为p,步长(stride)为s,则输出大小为:计算卷积层大小,如果商不是整数,向下取整,即floor函数;计算池化层大小,如果商不是整数,向上取整,即ceil函数。参考:https://blog.csdn.net/fengbingchun/article/details/80262495
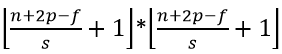
在https://github.com/fengbingchun/Caffe_Test/tree/master/test_data/Net/DenseNet 上整理了DenseNet prototxt文件。
这里描述下DenseNet-121架构:k=32,与上表中”DenseNet-121″有所差异
(1).输入层(Input):图像大小为224*224*3。
(2).卷积层Convolution+BatchNorm+Scale+ReLU:使用64个7*7的filter,stride为2,padding为3,输出为112*112*64,64个feature maps。
(3).Pooling:最大池化,filter为3*3,stride为2,padding为1,输出为57*57*64,64个feature maps。
(4).Dense Block1:输出为57*57*(64+32*6)=57*57*256,256个feature maps。
连续6个Dense Block,每个Dense Block包含2层卷积,卷积kernel大小依次为1*1、3*3,在卷积前进行BatchNorm+Scale+ReLU操作,第1、2个卷积输出feature maps分别为128、32。因为k=32,所以每个Dense Block输出feature maps数会比上一个Dense Block多32。每个Dense Block后做Concat操作。
(5).Transition Layer1:输出为29*29*128,128个feature maps。
A.BatchNorm+Scale+ReLU+1*1 conv,输出57*57*128。
B.平均池化,filter为2*2,stride为2,输出29*29*128。
(6).Dense Block2:输出为29*29*(128+32*12)=29*29*512,512个feature maps。
连续12个Dense Block,每个Dense Block包含2层卷积,卷积kernel大小依次为1*1、3*3,在卷积前进行BatchNorm+Scale+ReLU操作,第1、2个卷积输出feature maps分别为128、32。因为k=32,所以每个Dense Block输出feature maps数会比上一个Dense Block多32。每个Dense Block后做Concat操作。
(7).Transition Layer2:输出为15*15*256,256个feature maps。
A.BatchNorm+Scale+ReLU+1*1 conv,输出29*29*256。
B.平均池化,filter为2*2,stride为2,输出15*15*256。
(8).Dense Block3:输出为15*15*(256+32*24)=15*15*1024,1024个feature maps。
连续24个Dense Block,每个Dense Block包含2层卷积,卷积kernel大小依次为1*1、3*3,在卷积前进行BatchNorm+Scale+ReLU操作,第1、2个卷积输出feature maps分别为128、32。因为k=32,所以每个Dense Block输出feature maps数会比上一个Dense Block多32。每个Dense Block后做Concat操作。
(9).Transition Layer3:输出为8*8*512,512个feature maps。
A.BatchNorm+Scale+ReLU+1*1 conv,输出15*15*512。
B.平均池化,filter为2*2,stride为2,输出8*8*512。
(10).Dense Block4:输出为8*8*(512+32*16)=8*8*1024,1024个feature maps。
连续16个Dense Block,每个Dense Block包含2层卷积,卷积kernel大小依次为1*1、3*3,在卷积前进行BatchNorm+Scale+ReLU操作,第1、2个卷积输出feature maps分别为128、32。因为k=32,所以每个Dense Block输出feature maps数会比上一个Dense Block多32。每个Dense Block后做Concat操作。
(11).Classification Layer:
A.平均池化:filter为8*8,stride为1,padding为0,输出为1*1*1024,1024个feature maps。
B.卷积:kernel大小为1*1,输出1000个feature maps。
C.输出层(Softmax):输出分类结果,看它究竟是1000个可能类别中的哪一个。
可视化结果如下图所示:

GitHub:https://github.com/fengbingchun/NN_Test
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187810.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
