大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用

发现一篇讲解LMDB不错的文章,记录一下,原文在这里。
Overview
- homepage: http://symas.com/mdb/
- https://github.com/LMDB/lmdb
- source codes doc: http://symas.com/mdb/doc/starting.html
- official repo on openldap.org: http://www.openldap.org/software/repo.html
LMDB(Lightning Memory-Mapped Database) is a tiny database with some great capabilities:
- Ordered-map interface (keys are always sorted, supports range lookups)
- Fully transactional, full ACID (Atomicity, Consistency, Isolation, Durability) semantics with MVCC(Multiversion concurrency control).
- Reader/writer transactions: readers don’t block writers and writers don’t block readers. Writers are fully serialized, so writes are always deadlock-free.
- Read transactions are extremely cheap, and can be performed using no mallocs or any other blocking calls.
- Supports multi-thread and multi-process concurrency, environments may be opened by multiple processes on the same host.
- Multiple sub-databases may be created with transactions covering all sub-databases.
- Memory-mapped, allowing for zero-copy lookup and iteration.
- Maintenance-free, no external process or background cleanup/compaction required.
- Crash-proof, no logs or crash recovery procedures required.
- No application-level caching. LMDB fully exploits the operating system’s buffer cache.
- 32KB of object code and 6KLOC of C.
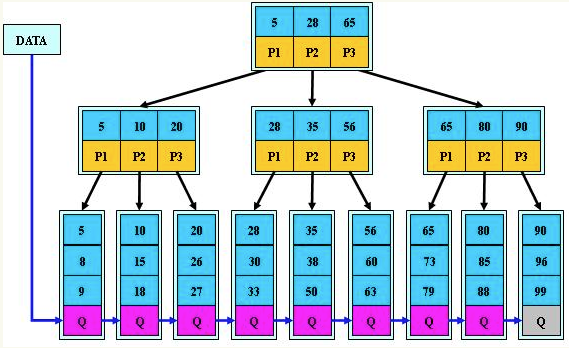
LMDB基本架构
lmdb的基本架构如下:
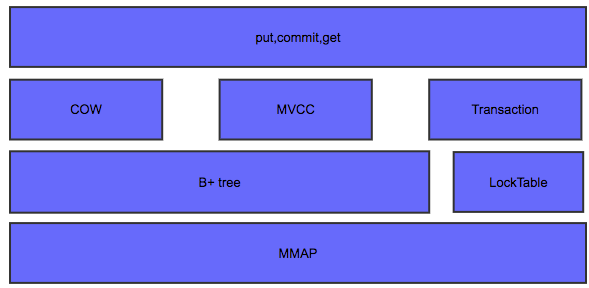

lmdb的基本做法是使用mmap文件映射,不管这个文件存储实在内存上还是在持久存储上。lmdb的所有读取操作都是通过mmap将要访问的文件只读的映射到虚拟内存中,直接访问相应的地址.因为使用了read-only的mmap,同样避免了程序错误将存储结构写坏的风险。并且IO的调度由操作系统的页调度机制完成。而写操作,则是通过write系统调用进行的,这主要是为了利用操作系统的文件系统一致性,避免在被访问的地址上进行同步。
lmdb把整个虚拟存储组织成B+Tree存储,索引和值读存储在B+Tree的页面上.对外提供了关于B+Tree的操作方式,利用cursor游标进行。可以进行增删改查。
使用Memory Map
Memory Map原理
内存映射就是把物理内存映射到进程的地址空间之内,这些应用程序就可以直接使用输入输出的地址空间.由此可以看出,使用内存映射文件处理存储于磁盘上的文件时,将不需要由应用程序对文件执行I/O操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
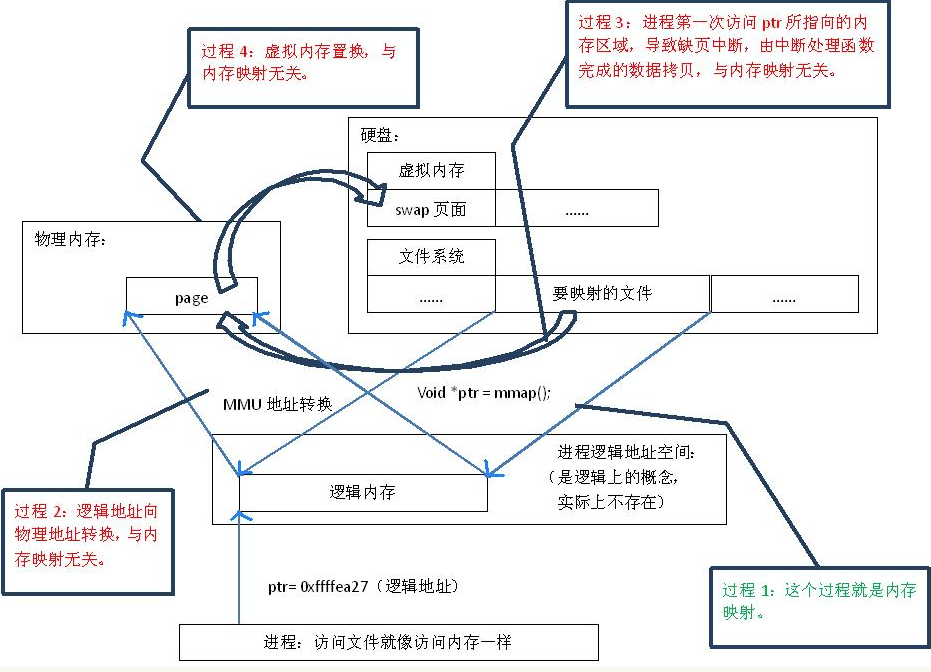
Linux下mmap的实现过程与普通文件io操作
mmap映射原理与过程:
一般文件io操作方式:
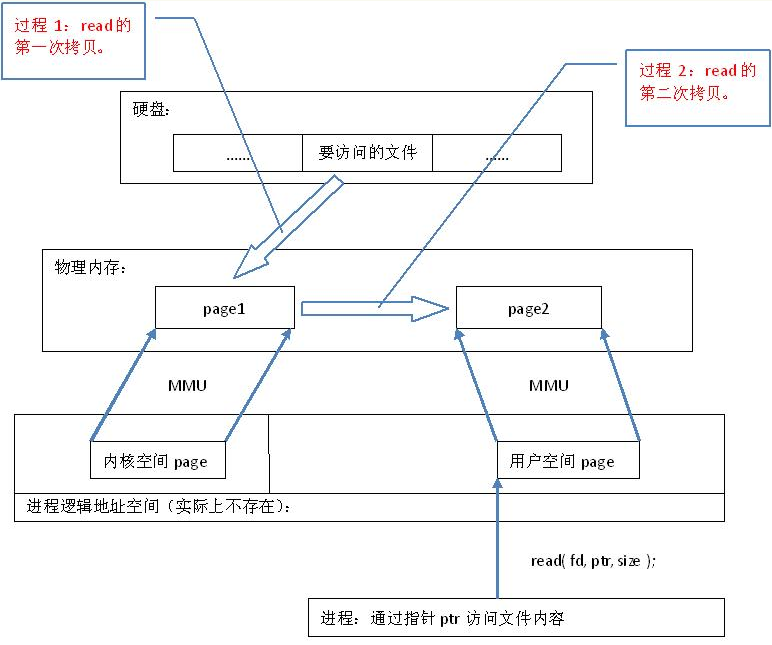
通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高, read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,然后再将这些数据拷贝到用户空间,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比 read/write效率高。
lmdb使用mmap过程
lmdb创建完env对象,打开时,会做data file和lock file的mmap映射:
env->me_lfd = open(lpath, O_RDWR|O_CREAT|MDB_CLOEXEC, mode);
void *m = mmap(NULL, rsize, PROT_READ|PROT_WRITE, MAP_SHARED,
env->me_lfd, 0);
env->me_txns = m;
env->me_fd = open(dpath, oflags, mode);
env->me_map = mmap(addr, env->me_mapsize, prot, MAP_SHARED,
env->me_fd, 0); 其他时刻都直接使用内存指针,通过系统级别的缺页异常获取对应的数据。页面内数据的获取和使用MDB_CURSOR_GET进行。页面的获取和key查询通过 mdb_page_get/mdb_page_search 完成.
页面头部大小及内容是固定的,具体的含义代表根据flags决定,在头部之后紧接的是node,真正的key-value值对所在位置的索引,因此访问这些node时通过指针计算即可得到对应的位置。
lmdb 之后是如何将页面给映射进进程地址空间呢.lmdb通过 mdb_page_get 函数以 pgno 为主要参数获得页面并返回页面指针。若仅仅是只读事务且环境对象是以只读方式打开的,page的获取很简单,根据
page= (MDB_page *)(env->me_map + env->me_psize * pgno); 获得。
在lmdb中B+Tree的是基于append-only B+Tree改造的。对于数据增加、修改、删除导致页面增加时,pageno也增加,当旧页面(数据旧版本)被重用时,pageno 保持不变,因此pageno保持了在数据文件中的顺序性,从而在获取页面时,只需要进行简单计算即可以。同时在创建env对象时,数据库已经被整个映射进整个进程空间,因此系统在映射时,会给数据库文件保留全部地址空间,从而在根据上述算法获取真实数据库,系统触发缺页错误,进而从数据文件中获取整个页面内容。此为最简单有效方式,否则不将全部数据映射进地址空间,对于未映射部分还需要在访问页面时判断是否已经被映射,未被映射时进行映射。
在需要时在通过文件方式写入。lmdb保证任意时刻只有一个写操作在进行,从而避免了并发时数据被破坏。
B-tree/B+tree/B*tree
B-tree
B-tree又叫平衡多路查找树。一棵m阶的B-tree (m叉树)的特性如下:
- 树中每个结点至多有m个孩子;
- 除根结点和叶子结点外,其它每个结点至少有有ceil(m / 2)个孩子;
- 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
- 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,实际上这些结点不存在,指向这些结点的指针都为null);
- 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2, P2,……,Kn,Pn)。其中:
- Ki (i=1…n)为关键字,且关键字按顺序排序K(i-1)< Ki。
- Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
- 关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1。
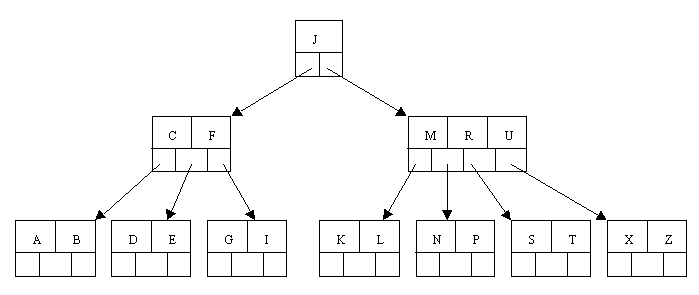
B+tree
B+ tree:是应文件系统所需而产生的一种B-tree的变形树。一棵m阶的B+-tree和m阶的B-tree的差异在于:
- 有n棵子树的结点中含有n个关键字; (B-tree是n棵子树有n-1个关键字)
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (B-tree的叶子节点并没有包括全部需要查找的信息)
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (B-tree的非终节点也包含需要查找的有效信息)
B*tree
B* tree是B+ tree的变体,在B+-tree的非根和非叶子结点再增加指向兄弟的指针;B*-tree定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为 2/3(代替B+树的1/2)。如下图所示
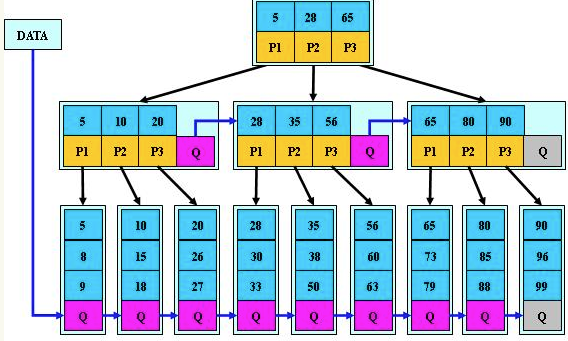
More
lmdb中的使用
lmdb代码主要分为page管理和cursor操作两块实现b-tree结构.
- page管理
mdb_page_malloc: 为新页面分配内存,从操作系统中申请1个或者n个页面,一般为一个页面,n个页面为overflow页面mdb_page_alloc: 分配页面分配一个或n个页面,若分配n个,则n个页面是连续页面。若事务中可用脏空间没有了,则分配失败,可用脏空间是指存储脏页ID的数组大小. LMDB中所有可用的脏页同样被维护成一颗B-Tree,FREE_DBI中记录了最后一次放入页面的事务ID,每次分配时都从freedb中寻找足够大重用空间,一般分配一个页面能满足,连续页面,可能需要尝试多次,因此多个页面一般是overflow 页面,必须是连续页面才能满足要求。mdb_page_new: 新建页面首先调用mdb_page_alloc分配页面,然后初始化页面,新建一个页面时,认为这个页面是一个全新的页面,因此需要其整个空间可用,初始化设置将体现这点。mdb_page_free: 释放单个页面,将它放入可重用页面列表。mdb_page_copy: 复制页面将页面内容从一个页面复制到另外一个页面,此功能主要用于COW.mdb_page_split: 页面分裂实现了B-Tree的操作过程,考虑了仅有一个节点时、append模式、 braches/leaf/leaf2等不同页面的处理过程,基本流程就是根据一定的算法确定分裂点,根据B-Tree的定义,在分裂时,不一定需要保证平分,只需要保证页面节点保持半满即可。分裂点确定之后,就进行数据的移动并插入导致分裂的数据以及修改指针以维持B-Tree结构,同时再决定是否会导致上层分裂以及 root分裂,若会则进行递归处理。mdb_page_merge: 页面合并同样是实现了上述因为节点删除导致的merge过程。基本过程是,将合并的目标页面置为脏页,然后根据上述理论情况进行节点的一个个复制,或者对于内部节点而言进行页面指针调整以及进行上下节点的移动,对于本页完成之后进行平衡操作,其中平衡操作可能会又导致merge操作,直到B-Tree重新满足定义为止。mdb_page_spill: 将脏页写回磁盘,这是为了嵌套长事务进行的设计,有些嵌套长事务会使用大量的页,为了避免耗光内存,可以将脏页写回磁盘,写回磁盘如同commit一样,因为多个进程、线程之间将只会存在一个写事务,因此在未提交之间前写回磁盘没有任何问题。而且只要能有空间,页面就不会刷入磁盘。在执行时,先计算是否空间足够,不够的将id存入idl数组,然后刷入磁盘,再根据环境变量决定是否保留pdirty标记。mdb_page_unspill: 将spill的页面重新读回, 这就不需要进行touch,直接设置dirty标志就可以了。lmdb支持嵌套事务,因此在查找页面是否属于已经被spilled的页面需要查找整个嵌套路径,从叶子到跟,找到之后确认midl列表(脏空间)是否有足够空间,没有的提示事务空间已满,否则加载页面并设置脏页标记。mdb_page_dirty: 设置脏页标记,并将脏页加入到事务中的脏页列表当中。mdb_page_flush: 用在事务提交时,当清除页面脏页标记后,将数据更新到磁盘(通过写文件方式).mdb_page_touch: 实现COW的技术,复制一个页面,并将更新过B-Tree指针关系的页面插入到B-Tree当中,这样意味着在修改时是在复制的页面上进行修改,别的事务在本事务没有提交之前看到还是以前的数据,提交之后的新事物看到的才是修改之后的数据。mdb_page_search_root: 从B-Tree根节点检索,根据key的值,从根节点开始遍历子树获取每一层对应的page,在page之内检索key,再根据B-Tree查找方法确定下一层子节点的page,层层遍历,从而最终确定key的位置或者判断 B-Tree中没有对应的key。同时将页面存放到cursor页堆栈中。这样cursor将可以重用对应的页面,为后续进行更新等操作提供便利。mdb_page_search/mdb_page_search_lowest都将调用mdb_page_search_root以完成检索mdb_page_search,除了完成检索为的附加工作是确保所使用的B-Tree在本事务可见范围内是最新版本,同时在需要时将页面置为脏页。mdb_page_search_lowest: 从当前分支页开始,检索第一个符合条件的值。
mdb_page_get获取页面,本来根据MMAP原则,读取对应的页面非常简单,计算下地址即可,但lmdb中,考虑到事务可能使用大量的页面,事务可用空间满时,将一部分页面spill/flush到磁盘中,因此需要在get时判断是否在 spill列表中,在的话从中获取,否则直接计算获取。mdb_page_list显示页面中的所有key,是个工具方法。
- cursor操作
cursor操作实现了B-Tree节点操作,cursor指向当前需要进行操作的B-Tree节点,然后依据提供的操作方式(insert、del)进行数据操作,然后进行一系列复杂的操作流程以维持B-Tree结构。
- 游标遍历(
mdb_cursor_sibling,mdb_cursor_next,mdb_cursor_prev,mdb_cursor_first ,mdb_cursor_last)mdb_cursor_first: 将游标定位至B-Tree的最小叶子节点(第一个),而非根据key查询时得到第一个结果位置。若支持重复数据,还要特殊处理,移动到重复数据第一个。mdb_cursor_last:与first类似,只不过定位至最大叶子节点(最后一个)mdb_cursor_next: 游标移动至下一个节点mdb_cursor_prev: 游标移动至前一个节点mdb_cursor_sibling: 将游标移动至兄弟节点,可以是前一个页面或者下一个页面。若当前页有key,则行为与next、prev类似,否则移动到下一个页面的对应key位置。
- 增删改查(
mdb_cursor_get ,mdb_cursor_set ,mdb_cursor_del ,mdb_cursor_del0 ,mdb_cursor_put ,mdb_cursor_count)mdb_cursor_get:根据游标位置和条件获取值,最常用:MDBGETCURRENT, 获取游标所指节点的值,基本思路是看页面中索引是否已经大于key个数,大于则说明游标已经需要指向下一页,对于取当前值的不重复key来说,这不可能,因此获取失败。mdb_cursor_set:将游标设置(定位)到指定key位置,假如已经在正确页面,只需要判断key是否在页面key的范围之内,判断最大、最小值可以确定。然后根据相应标志,如同get中所说,进行判断以及读取或设置某些变量。否则话进行页面查找先定位key所在页面(mdb_page_search),然后定位页面中位置(mdb_node_search),然后再设置相关变量。mdb_cursor_count:返回游标代表的结果数,唯一key返回一,重复key 返回重复个数。mdb_cursor_put:将key、value对存放到数据库中,默认是新增加,若key已经存在则是更新,基本流程是:判断前提cursor、key非空,确认各种标志是否合法,比如多个value,但是数据库不支持重复key这种情形就不合法,标志合适之后,判断是否为空树,非空时将cursor指向正确的位置,比如 append模式指向数据库最大节点之后,正常指向应该插入的位置。然后 touch所有页面使所有页面可写。若为leaf2类型页面,说明key、value完全重复,增加key就OK了,然后再判断value值是否太大,太大则转换为子树进行存储。转化为subdb/subpage时,首先根据各种标志设置各种变量,包括申请新页等,然后其余的就是根据各种标志完成上述理论描述的节点插入动作,将值放置对应位置、进行分页等,需要时进行unspill,放置到 overflow页面等,若一次插入多条数据还需要多次重复进行一次一条的插入。mdb_cursor_del,mdb_cursor_del0:删除指定key、value。首先是根据各种标志设置各种变量,其次设置页面为脏页,其次若删除之后, subdb/subpage,overflowpage 等受到影响,则需要将对应页面回收到 free-list,比如subdb删除最后一个节点时,需要删除整棵子树。真正的 key删除在del0中,它从页面中删除对应的key,删除完成后对整个B-Tree进行rebalance,然后修正所有指向当前删除页的同一事务内的其他cursor,通知其他cursor此页面已经被删除。
- 打开、关闭、重用、初始化
mdb_cursor_touch:将数据库以及在cursor堆栈中的所有页面设置为脏页。这样可能会有少量页面实际不需要设置为脏页实际设置为脏页的情形,但这样为实现COW提供最大的便利,只需要修改root页面指针即可,否则需要跟踪很多页面。mdb_cursor_open:打开游标,首先判断标志是否合法,合法就申请内存并调用init初始化mdb_cursor_renew:重用游标,当本游标已经不再使用,可以renew重用。mdb_cursor_close:关闭游标,从事务的cursor列表中删除,释放内存。mdb_cursor_copy:复制游标,将所有内容从一个复制到新游标。mdb_cursor_shadow:备份cursor对应事务的游标mdb_cursor_init:设置各种变量,若数据库状态为DB_STALE,则需获取最新的root节点。
- 页面操作
mdb_cursor_pop:从cursor堆栈中弹出一个页面mdb_cursor_push: 将一个页面压入堆栈,一般会将整个search路径上的所有页面压入堆栈。
- 状态
mdb_cursor_chk:检查cursor是否正确mdb_cursor_txn: 获取cursor对应事务mdb_cursor_dbi:获取cursor对应数据库
- 游标遍历(
COW and MVCC
COW(Copy-on-write)
写入时复制(Copy-on-write,COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。4
MVCC(Multiversion concurrency control)
Multiversion concurrency control (MCC or MVCC), is a concurrency control method commonly used by database management systems to provide concurrent access to the database and in programming languages to implement transactional memory.
If someone is reading from a database at the same time as someone else is writing to it, it is possible that the reader will see a half-written or inconsistent piece of data. There are several ways of solving this problem, known as concurrency control methods. The simplest way is to make all readers wait until the writer is done, which is known as a lock. This can be very slow, so MVCC takes a different approach: each user connected to the database sees a snapshot of the database at a particular instant in time. Any changes made by a writer will not be seen by other users of the database until the changes have been completed (or, in database terms: until the transaction has been committed.)
When an MVCC database needs to update an item of data, it will not overwrite the old data with new data, but instead mark the old data as obsolete and add the newer version elsewhere. Thus there are multiple versions stored, but only one is the latest. This allows readers to access the data that was there when they began reading, even if it was modified or deleted part way through by someone else. It also allows the database to avoid the overhead of filling in holes in memory or disk structures but requires (generally) the system to periodically sweep through and delete the old, obsolete data objects. For a document-oriented database it also allows the system to optimize documents by writing entire documents onto contiguous sections of disk—when updated, the entire document can be re-written rather than bits and pieces cut out or maintained in a linked, non-contiguous database structure.
MVCC provides point in time consistent views. Read transactions under MVCC typically use a timestamp or transaction ID to determine what state of the DB to read, and read these versions of the data. Read and write transactions are thus isolated from each other without any need for locking. Writes create a newer version, while concurrent reads access the older version.5
MVCC/COW在LMDB中的实现
LMDB对MVCC加了一个限制,即只允许一个写线程存在,从根源上避免了写写冲突,当然代价就是写入的并发性能下降。因为只有一个写线程,所以不会不需要wal 日志、读写依赖队列、锁队列等一系列控制并发、事务回滚、数据恢复的基础工具。
MVCC的基础就是COW,对于不同的用户来说,若其在整个操作过程中不进行任何的数据改变,其就使用同一份数据即可,若需要进行改变,比如增加、删除、修改等,就需要在私有数据版本上进行,修改完成提交之后才给其他事务可见。
LMDB中,数据操作的基本单元是页,因此COW也是以页为单位,对应函数是 mdb_page_touch, mdb_page_copy ,copy真正实现页面复制,touch调用copy完成复制,然后修改pgno后插入到B+Tree当中,这样对于此次事务,后续的操作访问的数据页就是最新的数据页面,而非事务启动时对应的数据页面,且此页面与其他页面的关联关系仅在本事务页面列表中可见,对其他事务不可见。
实际上通过以上两个函数实现了MVCC的核心,对于读写的控制,通过 mdb_txn_begin 控制,在其中,事务启动时会检查读写锁的情况,若事务需要更新数据,则会被阻止,若只是读数据,则不管是否有写事务存在,读锁都可以获得。
MVCC的一个副作用就是对于存在大量写的应用,其数据版本很多,因此旧数据会占用大量空间,LMDB中通过freedb解决,即将不再使用的旧的数据页面空间插入到一棵B+Tree当中,这样旧空间在所有事务不再访问之后就可以被LMDB使用,从而避免了需要定期执行清理操作。当然其副作用是数据只能保持最新不能恢复到任意时刻,
事务控制
事务的基本特征
事务是恢复和并发控制的基本单位。它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
- 原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability)。持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
LMDB 中的实现基本思路
- Atom(A): LMDB中通过txn数据结构和cursor数据结构的控制,通过将脏页列表放入 dirtylist中,当txn进行提交时再一次性统一刷新到磁盘中或者abort时都不提交保证事务要不全成功、要不全失败。对于长事务,若页面spill到磁盘,因为COW技术,这些页面未与整棵B-Tree的rootpage产生关联,因此后续的事务还是不能访问到这些页面,同样保证了事务的原子性。
- Consistency(C): 有如上的操作,保证其数据就是一致的,不存在因为多线程同时写数据导致数据产生错误的情况。
- Isolation(I):事务隔离通过锁控制(MUTEX),LMDB支持的锁互斥是进程级别/线程级别,支持的隔离方式为锁表支持,读读之间不锁,写等待读完成之后开始,读等待写完成后开始.
- Duration(D):LMDB中,没有使用WAL、undo/redo log等技术来保证系统崩溃时数据库的可用性,其保证数据持续可用的技术是COW技术和只有一线程写技术。假如LMDB或者系统崩溃时,只有读操作,那么数据本来就没有发生变化,因此数据将不可能遭到破坏。假如崩溃时,有一个线程在进行写操作,则只需要判断最后的页面号与成功提交到数据库中的页面号是否一致,若不一致则说明写操作没有完成,则最后一个事务写失败,数据在最后一个成功的页面前的是正确的,后续的属于崩溃事务的,不能用,这样就保证了数据只要序列化到磁盘则一定可用,要不其就是还没有遵循ACI原则序列化到磁盘
Example
#include <stdio.h>
#include "lmdb.h"
int main(int argc,char * argv[])
{
int rc;
MDB_env *env;
MDB_dbi dbi;
MDB_val key, data;
MDB_txn *txn;
MDB_cursor *cursor;
char sval[32];
/* Note: Most error checking omitted for simplicity */
rc = mdb_env_create(&env);
rc = mdb_env_open(env, "./testdb", 0, 0664);
rc = mdb_txn_begin(env, NULL, 0, &txn);
rc = mdb_dbi_open(txn, NULL, 0, &dbi);
key.mv_size = sizeof(int);
key.mv_data = sval;
data.mv_size = sizeof(sval);
data.mv_data = sval;
sprintf(sval, "%03x %d foo bar", 32, 3141592);
rc = mdb_put(txn, dbi, &key, &data, 0);
rc = mdb_txn_commit(txn);
if (rc) {
fprintf(stderr, "mdb_txn_commit: (%d) %s\n", rc, mdb_strerror(rc));
goto leave;
}
rc = mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
rc = mdb_cursor_open(txn, dbi, &cursor);
while ((rc = mdb_cursor_get(cursor, &key, &data, MDB_NEXT)) == 0) {
printf("key: %p %.*s, data: %p %.*s\n",
key.mv_data, (int) key.mv_size, (char *) key.mv_data,
data.mv_data, (int) data.mv_size, (char *) data.mv_data);
}
mdb_cursor_close(cursor);
mdb_txn_abort(txn);
leave:
mdb_dbi_close(env, dbi);
mdb_env_close(env);
return 0;
}Run the example:
mkdir testdb
./sample
key: 0x7f1435f678a4 020 , data: 0x7f1435f678a8 020 3141592 foo bar
key: 0x7f1435f67fdc 1bd , data: 0x7f1435f67fe0 1bd 445 foo bar
key: 0x7f1435f67fb0 1dc , data: 0x7f1435f67fb4 1dc 476 foo bar
key: 0x7f1435f67f84 1e2 , data: 0x7f1435f67f88 1e2 482 foo bar
key: 0x7f1435f67f58 1f9 , data: 0x7f1435f67f5c 1f9 505 foo bar
key: 0x7f1435f67f2c 1ff , data: 0x7f1435f67f30 1ff 511 foo bar
LMDB 核心数据结构
1、MDB_env
struct MDB_env {
HANDLE me_fd; /**< The main data file */
HANDLE me_lfd; /**< The lock file */
HANDLE me_mfd; /**< just for writing the meta pages */
uint32_t me_flags; /**< @ref mdb_env */
unsigned int me_psize; /**< DB page size, inited from me_os_psize */
unsigned int me_os_psize; /**< OS page size, from #GET_PAGESIZE */
unsigned int me_maxreaders; /**< size of the reader table */
/** Max #MDB_txninfo.%mti_numreaders of interest to #mdb_env_close() */
volatile int me_close_readers;
MDB_dbi me_numdbs; /**< number of DBs opened */
MDB_dbi me_maxdbs; /**< size of the DB table */
MDB_PID_T me_pid; /**< process ID of this env */
char *me_path; /**< path to the DB files */
char *me_map; /**< the memory map of the data file */
MDB_txninfo *me_txns; /**< the memory map of the lock file or NULL */
MDB_meta *me_metas[NUM_METAS]; /**< pointers to the two meta pages */
void *me_pbuf; /**< scratch area for DUPSORT put() */
MDB_txn *me_txn; /**< current write transaction */
MDB_txn *me_txn0; /**< prealloc'd write transaction */
mdb_size_t me_mapsize; /**< size of the data memory map */
off_t me_size; /**< current file size */
pgno_t me_maxpg; /**< me_mapsize / me_psize */
MDB_dbx *me_dbxs; /**< array of static DB info */
uint16_t *me_dbflags; /**< array of flags from MDB_db.md_flags */
unsigned int *me_dbiseqs; /**< array of dbi sequence numbers */
pthread_key_t me_txkey; /**< thread-key for readers */
txnid_t me_pgoldest; /**< ID of oldest reader last time we looked */
MDB_pgstate me_pgstate; /**< state of old pages from freeDB */
# define me_pglast me_pgstate.mf_pglast
# define me_pghead me_pgstate.mf_pghead
MDB_page *me_dpages; /**< list of malloc'd blocks for re-use */
/** IDL of pages that became unused in a write txn */
MDB_IDL me_free_pgs;
/** ID2L of pages written during a write txn. Length MDB_IDL_UM_SIZE. */
MDB_ID2L me_dirty_list;
/** Max number of freelist items that can fit in a single overflow page */
int me_maxfree_1pg;
/** Max size of a node on a page */
unsigned int me_nodemax;
#if !(MDB_MAXKEYSIZE)
unsigned int me_maxkey; /**< max size of a key */
#endif
int me_live_reader; /**< have liveness lock in reader table */
# define me_rmutex me_txns->mti_rmutex /**< Shared reader lock */
# define me_wmutex me_txns->mti_wmutex /**< Shared writer lock */
void *me_userctx; /**< User-settable context */
MDB_assert_func *me_assert_func; /**< Callback for assertion failures */
};me_rmutext,me_wmutex: 锁表互斥所,lmdb可以支持多线程、多进程。多进程之间的同步访问通过系统级的互斥来达到。其mutex本身存在于系统的共享内存当中而非进程本身的内存,因此在进行读写页面时,首先访问锁表看看对应的资源是否有别的进程、线程在进行,有的话需要根据事务规则要求进行排队等待。me_txn,me_txns: 目前环境中使用的事务列表,一个env对象归属于一个进程,一个进程可能有多个线程使用同一个env,每个线程可以开启一个事务,因此在一个进程级的env对象需要维护txn列表以了解目前多少个线程及事务在进行工作。- meflags: 标志,标志控制的数据库的许多行为,每次使用env之前必须设置,应用程序应该用一致的方式使用flags,否则数据库可能会出现不可预知的错误。
- medbxs: 数据库对象
2.MDB_envinfo
typedef struct MDB_envinfo {
void *me_mapaddr; /**< Address of map, if fixed */
mdb_size_t me_mapsize; /**< Size of the data memory map */
mdb_size_t me_last_pgno; /**< ID of the last used page */
mdb_size_t me_last_txnid; /**< ID of the last committed transaction */
unsigned int me_maxreaders; /**< max reader slots in the environment */
unsigned int me_numreaders; /**< max reader slots used in the environment */
} MDB_envinfo;3、MDB_meta
/** Meta page content.
* A meta page is the start point for accessing a database snapshot.
* Pages 0-1 are meta pages. Transaction N writes meta page #(N % 2).
*/
typedef struct MDB_meta {
/** Stamp identifying this as an LMDB file. It must be set
* to #MDB_MAGIC. */
uint32_t mm_magic;
/** Version number of this file. Must be set to #MDB_DATA_VERSION. */
uint32_t mm_version;
void *mm_address; /**< address for fixed mapping */
pgno_t mm_mapsize; /**< size of mmap region */
MDB_db mm_dbs[CORE_DBS]; /**< first is free space, 2nd is main db */
/** The size of pages used in this DB */
#define mm_psize mm_dbs[FREE_DBI].md_pad
/** Any persistent environment flags. @ref mdb_env */
#define mm_flags mm_dbs[FREE_DBI].md_flags
pgno_t mm_last_pg; /**< last used page in file */
volatile txnid_t mm_txnid; /**< txnid that committed this page */
} MDB_meta;- meta页面循环使用,即id为1,修改页面1,id为2,修改页面0.
mm_dbs[CORE_DBS]数据库B+Tree根,同时保存两个:FREE_DBI和MAIN_DBI.
4、MDB_page
typedef struct MDB_page {
#define mp_pgno mp_p.p_pgno
#define mp_next mp_p.p_next
union {
pgno_t p_pgno; /**< page number */
struct MDB_page *p_next; /**< for in-memory list of freed pages */
} mp_p;
uint16_t mp_pad;
uint16_t mp_flags; /**< @ref mdb_page */
#define mp_lower mp_pb.pb.pb_lower
#define mp_upper mp_pb.pb.pb_upper
#define mp_pages mp_pb.pb_pages
union {
struct {
indx_t pb_lower; /**< lower bound of free space */
indx_t pb_upper; /**< upper bound of free space */
} pb;
uint32_t pb_pages; /**< number of overflow pages */
} mp_pb;
indx_t mp_ptrs[1]; /**< dynamic size */
} MDB_page;- page描述了不同页面的头。不管是树中的root、还是branch、leaf页面,都是用它描述。
- 对于overflow页面来说,只有第一页使用头进行描述,其后的连续页面不使用,仅仅使用指针将页面关联起来.
mp_flags: 代表是什么类型的页面mp_pb: overflow页数或者当前页的可用空间
5、MDB_node
typedef struct MDB_node {
/** lo and hi are used for data size on leaf nodes and for
* child pgno on branch nodes. On 64 bit platforms, flags
* is also used for pgno. (Branch nodes have no flags).
* They are in host byte order in case that lets some
* accesses be optimized into a 32-bit word access.
*/
unsigned short mn_lo, mn_hi; /**< part of data size or pgno */
unsigned short mn_flags; /**< @ref mdb_node */
unsigned short mn_ksize; /**< key size */
char mn_data[1]; /**< key and data are appended here */
} MDB_node;- node代表key/value对的描述,是对branch、leaf页中的数据的描述
mn_flags: 标志:是否重复、子数据库、overflow等mn_hi.lo: 数据大小或者页码mn_data: 数据指针
6、MDB_db
/** Information about a single database in the environment. */
typedef struct MDB_db {
uint32_t md_pad; /**< also ksize for LEAF2 pages */
uint16_t md_flags; /**< @ref mdb_dbi_open */
uint16_t md_depth; /**< depth of this tree */
pgno_t md_branch_pages; /**< number of internal pages */
pgno_t md_leaf_pages; /**< number of leaf pages */
pgno_t md_overflow_pages; /**< number of overflow pages */
mdb_size_t md_entries; /**< number of data items */
pgno_t md_root; /**< the root page of this tree */
} MDB_db;- mdbdb描述了一颗单独的b+tree树,主要包含了一些相关的信息和根节点页码
7、MDB_txn
struct MDB_txn {
MDB_txn *mt_parent; /**< parent of a nested txn */
/** Nested txn under this txn, set together with flag #MDB_TXN_HAS_CHILD */
MDB_txn *mt_child;
pgno_t mt_next_pgno; /**< next unallocated page */
txnid_t mt_txnid;
MDB_env *mt_env; /**< the DB environment */
/** The list of pages that became unused during this transaction.
*/
MDB_IDL mt_free_pgs;
/** The list of loose pages that became unused and may be reused
* in this transaction, linked through #NEXT_LOOSE_PAGE(page).
*/
MDB_page *mt_loose_pgs;
/* #Number of loose pages (#mt_loose_pgs) */
int mt_loose_count;
/** The sorted list of dirty pages we temporarily wrote to disk
* because the dirty list was full. page numbers in here are
* shifted left by 1, deleted slots have the LSB set.
*/
MDB_IDL mt_spill_pgs;
union {
/** For write txns: Modified pages. Sorted when not MDB_WRITEMAP. */
MDB_ID2L dirty_list;
/** For read txns: This thread/txn's reader table slot, or NULL. */
MDB_reader *reader;
} mt_u;
/** Array of records for each DB known in the environment. */
MDB_dbx *mt_dbxs;
/** Array of MDB_db records for each known DB */
MDB_db *mt_dbs;
/** Array of sequence numbers for each DB handle */
unsigned int *mt_dbiseqs;
/** In write txns, array of cursors for each DB */
MDB_cursor **mt_cursors;
/** Array of flags for each DB */
unsigned char *mt_dbflags;
/** Number of DB records in use, or 0 when the txn is finished.
* This number only ever increments until the txn finishes; we
* don't decrement it when individual DB handles are closed.
*/
MDB_dbi mt_numdbs;
unsigned int mt_flags; /**< @ref mdb_txn */
/** #dirty_list room: Array size - \#dirty pages visible to this txn.
* Includes ancestor txns' dirty pages not hidden by other txns'
* dirty/spilled pages. Thus commit(nested txn) has room to merge
* dirty_list into mt_parent after freeing hidden mt_parent pages.
*/
unsigned int mt_dirty_room;
};mdb_txn描述了数据库的事务结构,mdb中的事务支持嵌套事务。支持完全ACID 属性,但是只支持serializable事务隔离级别,通过同一个env对应的数据库只允许一个事务写来控制。mt_child,parent:事务嵌套父子关系mt_cursor: 写事务中每个数据库中已经打开的游标。
8、MDB_cursor
struct MDB_cursor {
/** Next cursor on this DB in this txn */
MDB_cursor *mc_next;
/** Backup of the original cursor if this cursor is a shadow */
MDB_cursor *mc_backup;
/** Context used for databases with #MDB_DUPSORT, otherwise NULL */
struct MDB_xcursor *mc_xcursor;
/** The transaction that owns this cursor */
MDB_txn *mc_txn;
/** The database handle this cursor operates on */
MDB_dbi mc_dbi;
/** The database record for this cursor */
MDB_db *mc_db;
/** The database auxiliary record for this cursor */
MDB_dbx *mc_dbx;
/** The @ref mt_dbflag for this database */
unsigned char *mc_dbflag;
unsigned short mc_snum; /**< number of pushed pages */
unsigned short mc_top; /**< index of top page, normally mc_snum-1 */
unsigned int mc_flags; /**< @ref mdb_cursor */
MDB_page *mc_pg[CURSOR_STACK]; /**< stack of pushed pages */
indx_t mc_ki[CURSOR_STACK]; /**< stack of page indices */
};
- 游标对象是进行所有数据库操作的对象,读写都是基于游标进行。进行读写操作时,首先需要根据条件确定页面位置,从而获得一个游标,应用程序根据游标对象操作数据库。
mc_next: 同一个事务中关于同一个db的游标组成一个列表。next指向下一个游标mc_top: 最上层页面idmc_xcursor: 用于key可重复b+tree。mc_pg: cursor打开的页面组成一个堆栈mc_ki: 打开页面的索引的堆栈
转载于:https://my.oschina.net/fileoptions/blog/1828660
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187808.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
