大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
个人公众号,欢迎关注
YouChouNoBB
1.首先对深度学习做一个简单的回顾
2.介绍DenseNet
3.参考文献
1.1 DNN回顾
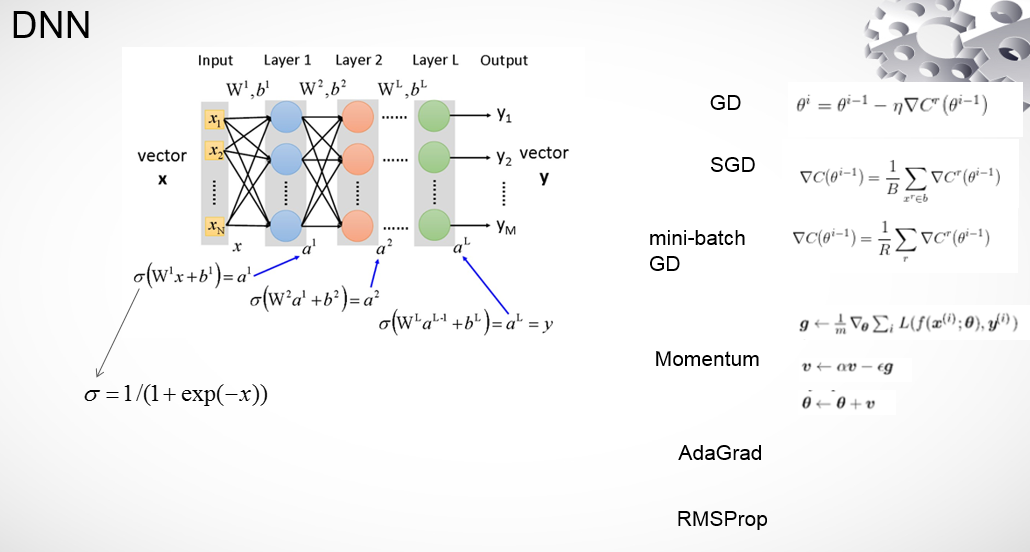
如下图所示是一个基本DNN结构,通过forward传播和backword传播来训练一个模型。包含input层,L个隐藏层和一个output,隐层使用的sigmoid激活函数,一般的优化方法有如下几种:
GD:对所有样本计算完一次梯度然后更新权重
SGD:每个样本计算一次梯度就更新权重
mini-batch-GD:对小部分样本计算梯度,然后更新权重
Momentum:加速度和速度在相同方向的时候,参数的更新得到加速,可以加快收敛速度

1.2 发展
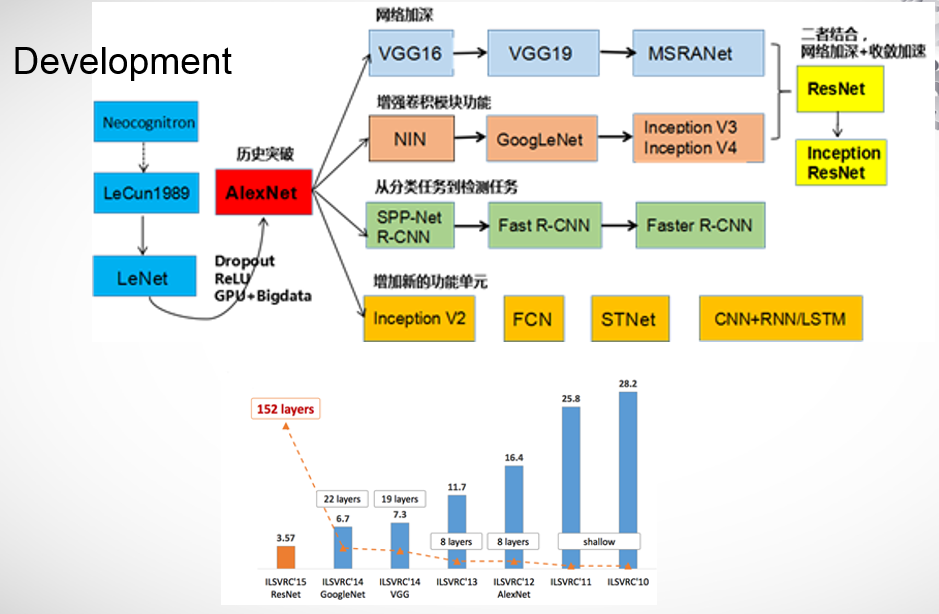
在2012年AlexNet的出现让深度学习重新成为研究热点,在AlexNet中,使用了一些新的优化方法:dropout,relu,gpu+bigdata。之后的发展主要有增加网络深度,增强卷积模块功能,检测任务,新的功能单元等
在ImageNet上,随着误差的降低,网络的深度呈现加深的趋势,在ResNet之前,很少超过20层的网络
1.3 卷积层 convolution
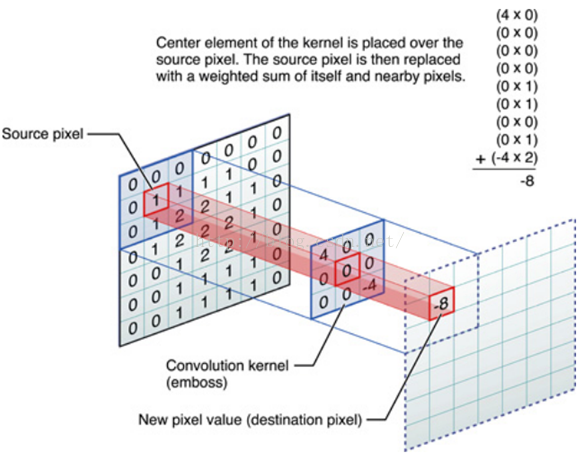
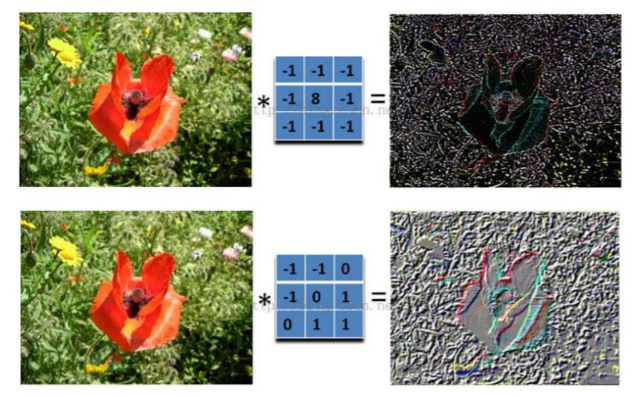
通过使用卷积核对图片提取特征,操作非常简单,对应位置相乘然后求和,然后卷积核根据步长滑动提取整个图片特征。不同的卷积核能提取不同的特征。
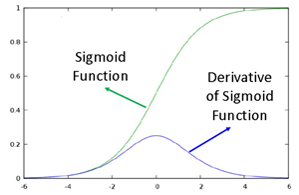
1.4 ReLU激活函数
sigmoid有一个非常致命的缺点,当输入非常大或者非常小的时候,这些神经元的梯度是接近于0的.
如果你的初始值很大的话,大部分神经元可能都会处在饱和的状态而把gradientkill掉,这会导致网络变的很难学习。
Sigmoid的output不是0均值. 这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。产生的一个结果就是:如果数据进入神经元的时候是正的,那么w计算出的梯度也会始终都是正的。
使用 ReLU得到的SGD的收敛速度会比sigmoid/tanh快很多,相比于sigmoid/tanh,ReLU只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的运算。Relu能加速训练,导数好求,在反向传播时速度快,激活部分梯度是1,梯度不容易消失,而Sigmoid和tanh在两端梯度消失严重。
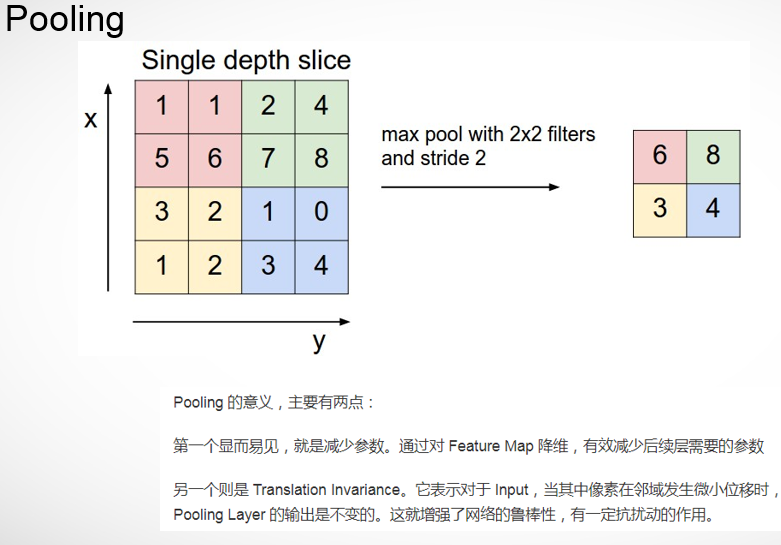
1.5 pooling
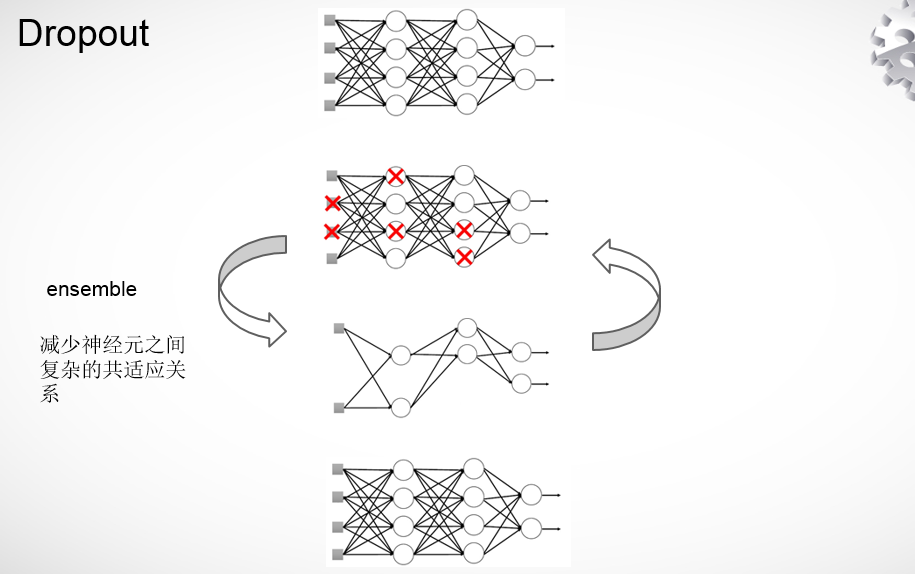
1.6 dropout
具体过程是,在某个mini-batch的训练中,随机隐藏部分神经元,这样就只能更新其他节点的参数,隐藏的这些没有更新,在下次迭代的时候再随机隐藏部分神经元,只更新剩下的节点参数。训练完成之后,在预测的时候还是使用所有节点来预测。
ensemble的作用: 先回到正常的模型(没有dropout),我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。(例如 3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果)。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络(随机删掉一半隐藏神经元导致网络结构已经不同),整个dropout过程就相当于 对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。(这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况)。 迫使网络去学习更加鲁棒的特征 (这些特征在其它的神经元的随机子集中也存在)。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的模式(鲁棒性)。这个角度看 dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高,隐藏部分节点之后,强迫剩下的节点学习更重要的特征。
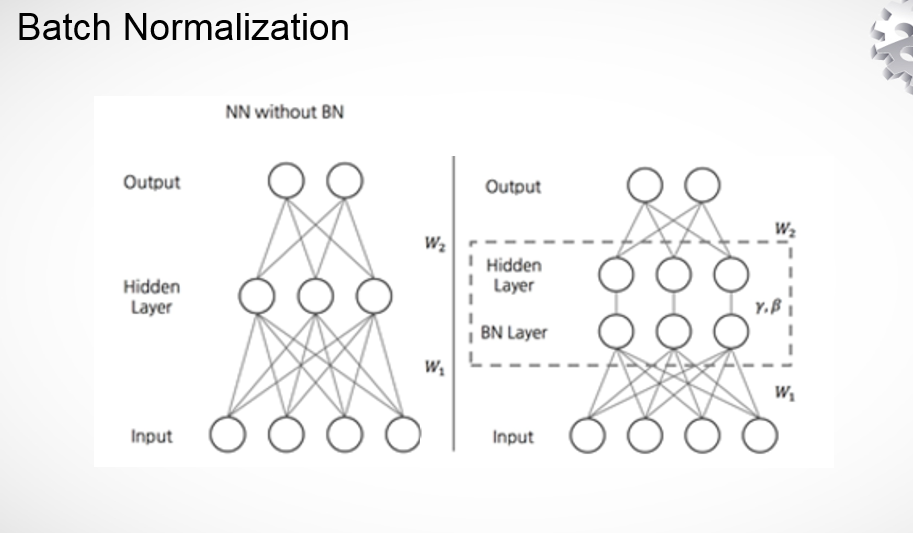
1.7 Batch Normalization
大家都知道在统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如,transfer learning/domain adaptation(迁移学习,领域适应)等。
如果分布改变,网络越深,分布变化越明显,不能学习到很好的参数。在其他资料上有指出Batch Normalization的本质是防止梯度弥散。
1.8 Gradient Vanish
我们知道在反向传播的时候,根据链式求导来计算梯度,并更新参数。反向传播时经过该层的梯度是要乘以该层的参数的,从l层传到k层的连乘就是问题所在,同样BN也是为了解决这个问题。

2.1 ResNet
ResNet的出现很好的解决了梯度弥散的问题,使得更深的网络得以更好的训练。第L层的网络是由L-1层的网络经过H(包括conv,BN,ReLU,Pooling)变换得到,在此基础上直接连接到上一层的网络。使得梯度能够得到更好的传播。
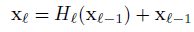
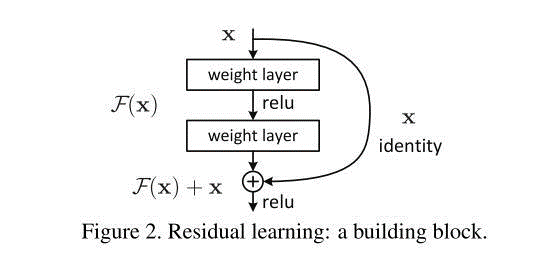
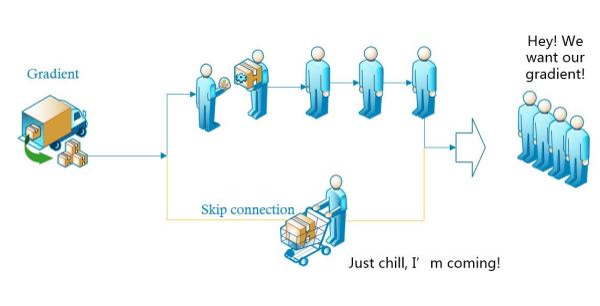
举个例子,后面的网络需要排队来领取梯度信息,但是排到越后面的网络领到的梯度很少甚至没有,这个时候直接开辟一条新的道路(skip connection),将梯度信息传递到后面的网络。
其实最先超过100层的网络是Highway Networks,非常形象的把这种结构比喻成高速公路。后来通过随机删掉一些层可以训练到1202层的ResNet。
2.2 DenseNet
DenseNet和ResNet的一个明显区别是,ResNet是求和,而DenseNet是做一个拼接,每一层网络的输入包括前面所有层网络的输出。第L层的输入等于K x (L-1) + k0,其中k是生长率,表示每一层的通道数,比如下图网络的通道数为4。
DenseNet提升了信息和梯度在网络中的传输效率,每层都能直接从损失函数拿到梯度,并且直接得到输入信号,这样就能训练更深的网络,这种网络结构还有正则化的效果。其他网络致力于从深度和宽度来提升网络性能,
DenseNet致力于从特征重用的角度来提升网络性能

上面图中的结构是一个dense block,下图的结构是一个完整的dense net,包括3个dense block。可以发现在block之间没有dense连接,因为在pooling操作之后,改变了feature maps的大小,这时候就没法做dense 连接了。在两个block之间的是transition layer ,包括了conv ,pool,在实验中使用的是BN,(1×1 conv),(2×2 avg pool)。
这种结构的好处是可以缓解梯度消失,省参数省计算,特征重用可以起到抗过拟合的作用。达到相同的精度,dense net只需要res net一半的参数和一半的计算量。
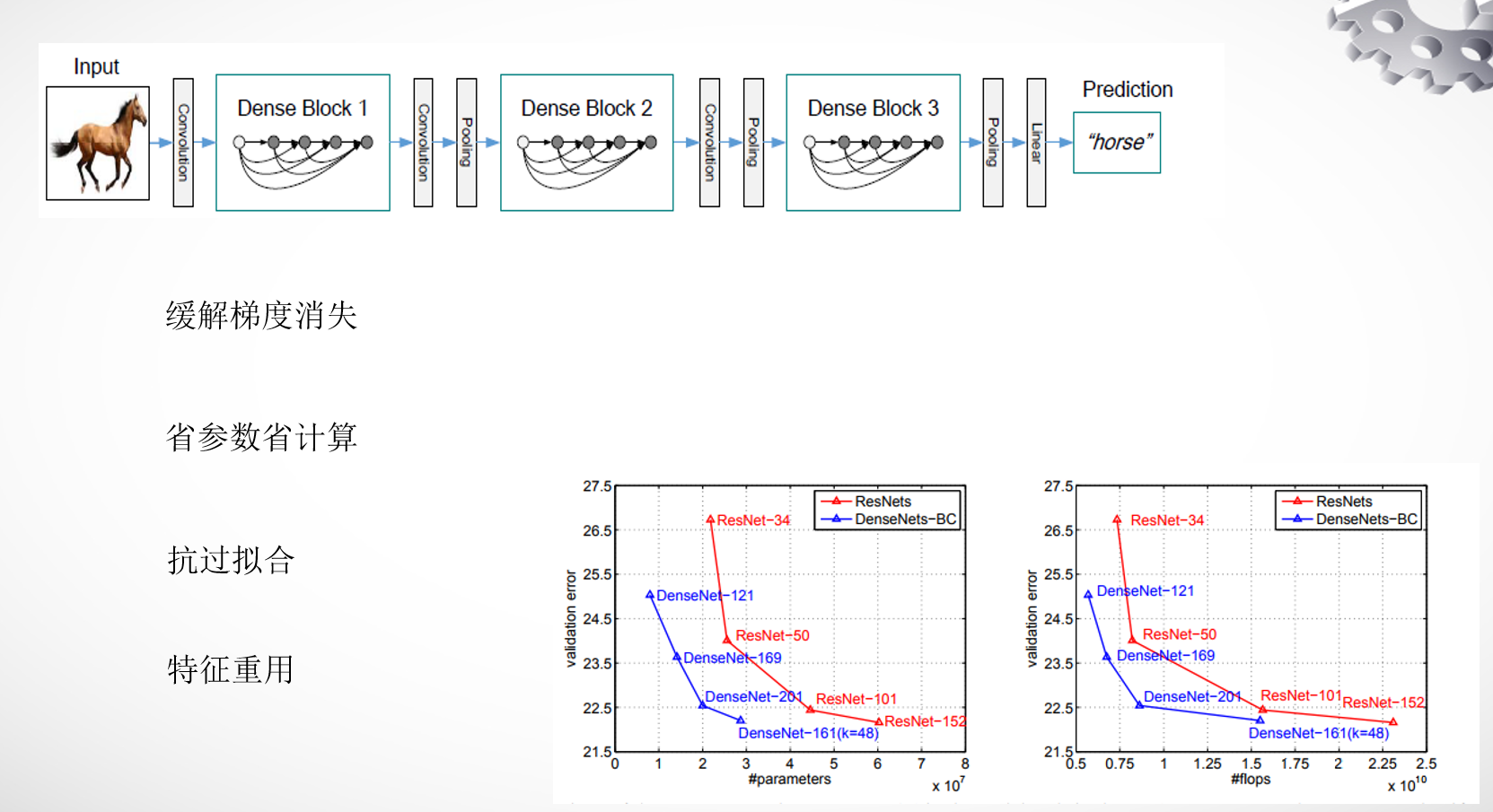
2.3 冗余
在使用密集连接时候的网络显得比较冗余,这样会不会增大参数量呢,DenseNet很好的处理了这个问题。它将每一层都设计的特别窄,在Dense Block中的每一个单元实际上都是一个 bottleneck layer,其中包括一个 1×1 conv和一个3×3 conv。在block之间还有个transition layer,包括一个BN,一个1×1的conv和一个pooling,同样起到了降低冗余的作用,一个block中有m个feature maps,通过一个0-1之间的参数来限制输出的feature maps数量。
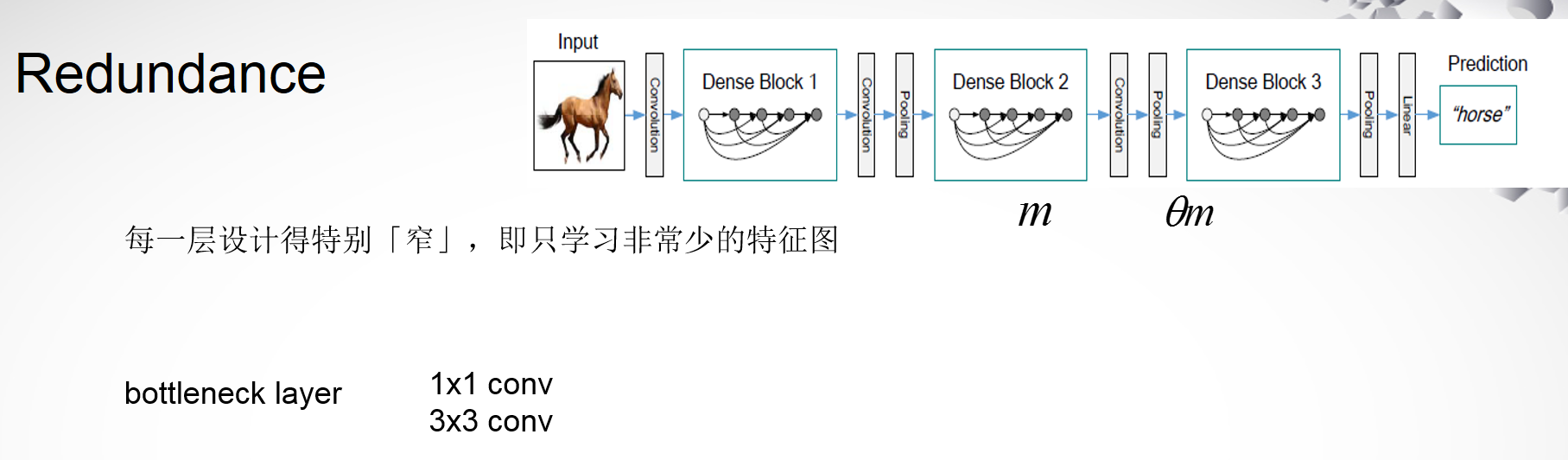
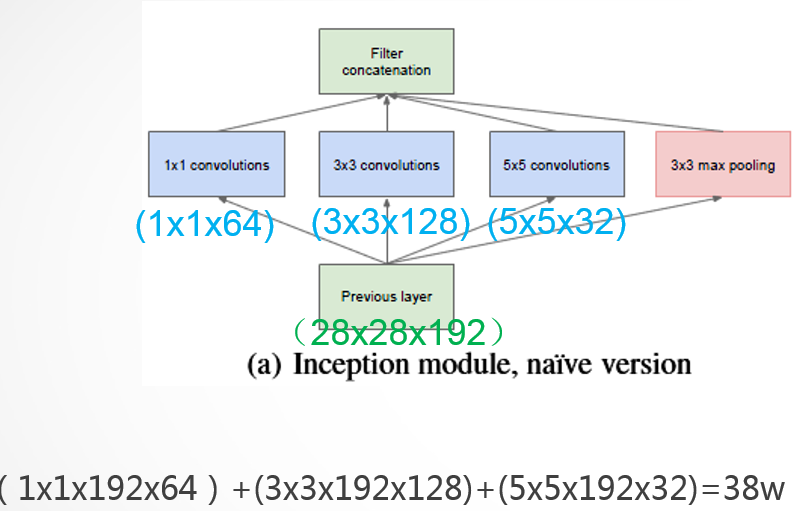
这种设计可以很好的降低参数量,GoogleNet也是用这种方式来降低参数的,下图是GoogleNet的一个功能模块,由1×1 64通道(通道可以理解为就是卷积核的数量),3×3 128通道,5×5 32通道的convolution和一个3×3 max pooling构成,输入的是28×28的图片192通道。那么可以分别计算出这3个卷积层的参数数量,为上一个通道数乘上当前卷积核的大小和通道数。可以算出来一个功能模块有38w个参数。
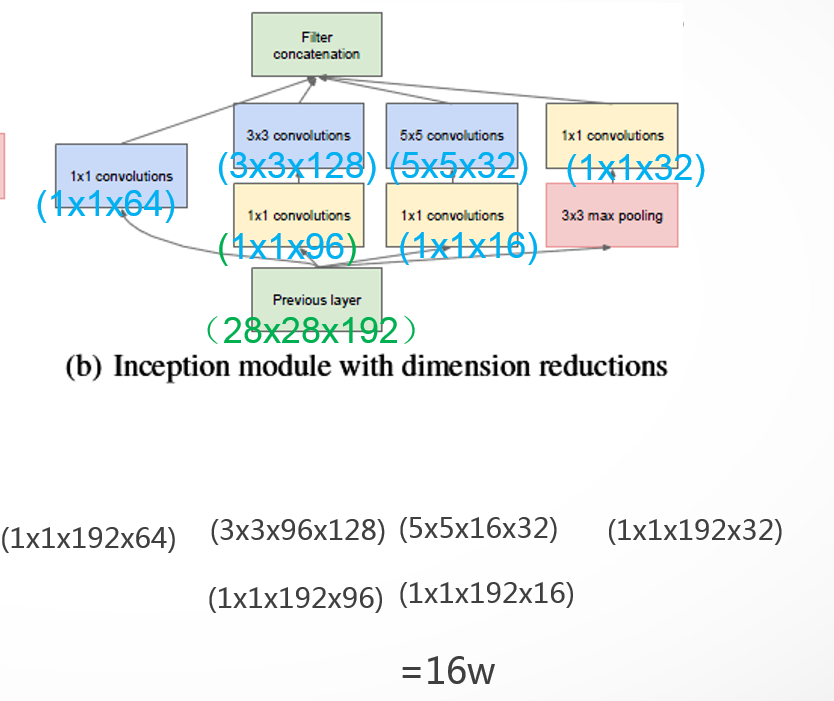
功能模块使用1×1的卷积核来实现降低参数量,方式为在3×3,5×5的卷积核之前分别添加1x1x96,1x1x16的卷积核,在pooling之后添加1x1x32的卷积核。用同样的方式来计算参数量,上一个通道数乘上当前卷积核的大小和通道数。得到当前功能模块的参数量为16w,所以可以使用1×1的卷积核,通过改变通道大小来进行参数降低。
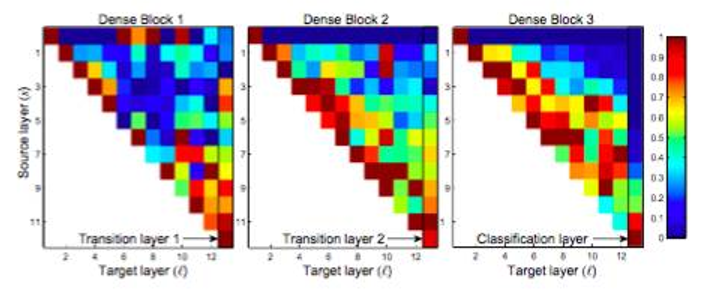
下面的图表示3个block中特征的热力图,颜色越深表示特征越重要,可以看到浅层特征同样会被利用到
下面是DenseNet的主要代码,就不作过多介绍了

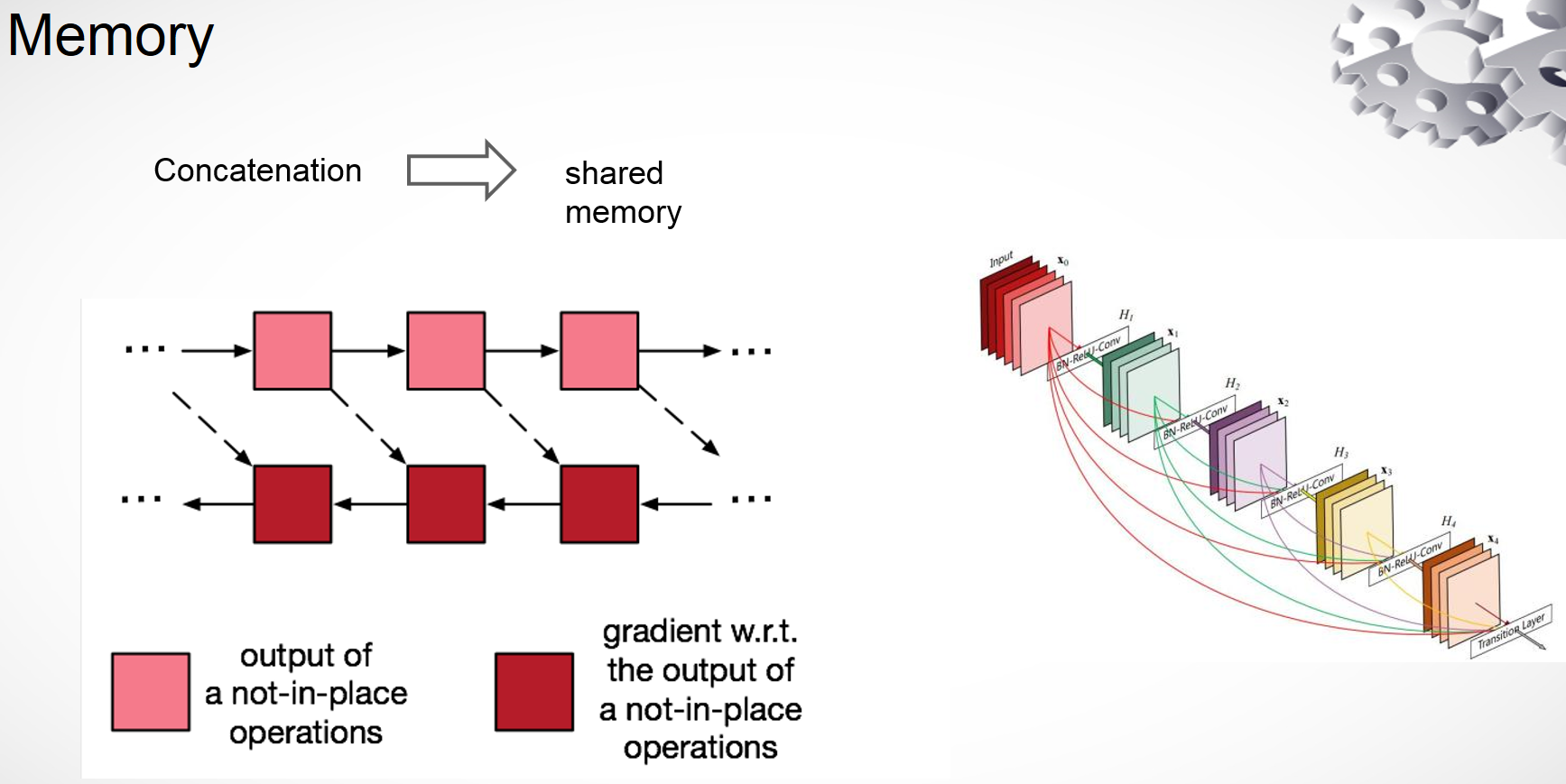
2.4内存优化
DenseNet的内存主要耗费在拼接过程,每次拼接都会开辟新的内存空间。那么可以使用共享内存来解决这个问题,另一个是forward和backward的内存依赖,粉红色是forward,深红色是backward。Forward的时候内存不能释放,backward的时候可以,计算完一块红色的就能直接释放,深红依赖粉红,粉红的也可以释放,在计算深红的时候重新计算粉红,这样会多耗费15%的时间,但是能节省70%的空间。
2.5 DPN
DPN获得了最后一届ImageNet的冠军,主要思想是融合了ResNet和DenseNet,这里就不作过多介绍了。
3 参考文献
DPN
个人公众号,欢迎关注
YouChouNoBB
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187773.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
