大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
【课程安利】人工智能课程请往下戳
如果想了解和系统学习更多人工智能、机器学习理论和项目实践,CSDN学院中有一系列精品AI课,分为大课和小课,包含数学基础、Python基础、算法和企业级项目 等,适合并不同类型的人群,值得拥有!
CSDN学院⼤课链接:
https://edu.csdn.net/topic/ai30?utm_source=lqy


CSDN学院⼩课链接:
https://edu.csdn.net/course/detail/6601?utm_source=lqy

正文如下
一个文本分类任务的典型操作流程如下:
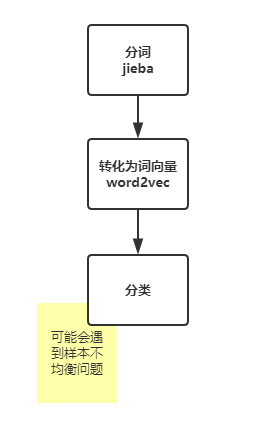
即拿到数据后先分词,然后转化为词向量(数值化过程),最后对数值化后的数据进行分类。
一、jieba分词原理
jieba自带了一个叫做dict.txt的词典, 里面有2万多条词, 包含了词条出现的次数(这个次数是于作者自己基于人民日报语料等资源训练得出来的)和词性. 这个第一条的trie树结构的词图扫描, 说的就是把这2万多条词语, 放到一个trie树(词典树)中, 而trie树是有名的前缀树, 也就是说一个词语的前面几个字一样, 就表示他们具有相同的前缀, 就可以使用trie树来存储, 具有查找速度快的优势。
用到的算法:
1.1 基于Trie树(字典树)结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)。
1.2 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
1.3 对于未登录词,采用了基于汉字成词能力的HMM(隐马尔可夫模型)模型,使用了Viterbi算法(维特比算法是一种动态规划算法)
分词过程:
生成切分词图:根据trie树对句子进行全切分,并且生成一个邻接链表表示的词图(DAG)。
计算最佳切分路径:在这个词图的基础上,运用动态规划算法生成切分最佳路径。
使用了HMM模型(隐马尔可夫模型)对未登录词进行识别:如进行中国人名、外国人名、地名、机构名等未登录名词的识别。
重新计算最佳切分路径。
继续深入学习:
字典树继续深入学习:https://www.cnblogs.com/TheRoadToTheGold/p/6290732.html
隐马尔科夫模型继续深入学习:https://www.cnblogs.com/skyme/p/4651331.html
维特比算法继续深入学习:https://blog.csdn.net/gzmfxy/article/details/78712878
二、word2vec生成词向量
word2vec是Google在2013年开源的一款将词表示为实数值向量的高效工具,是将单词嵌入到向量空间的一种词嵌入方法(word embedding)。word2vec采用的模型包含了连续词袋模型(CBOW)和Skip-Gram模型。通过它可以在大数据量上进行高效训练从而得到词向量。
将词数值化的方法包括
-
n-gram语言模型:一种统计语言模型,计算每个单词的概率,然后再进而计算一句话的整体概率。缺陷:当n大于3时,即考虑多于前三个单词的情况下,会因参数太多而无法计算。
-
one-hot形式的词向量
采用稀疏向量表示,某个单词出现则该位置为1,其余为0。此方法没有充分利用向量空间。 -
分布式编码:该编码将词语映射为固定长度的向量, 即N维向量空间中的一点。
理想状况下,两个对象越相似,它们词向量的相似度也越高,空间中两点的距离越近。
word2vec采用了CBOW和Skip-Gram两种模型
内部结构
CBOW连续词袋模型(Continuous Bag-of-Word Model, CBOW)是一个三层神经网络, 输入已知上下文输出对下个单词的预测.CBOW模型的第一层是输入层, 输入已知上下文的词向量. 中间一层称为线性隐含层, 它将所有输入的词向量累加.第三层是一棵哈夫曼树, 树的的叶节点与语料库中的单词一一对应。
Skip-gram模型同样是一个三层神经网络. skip-gram模型的结构与CBOW模型正好相反,skip-gram模型输入某个单词输出对它上下文词向量的预测。Skip-gram的核心同样是一个哈夫曼树, 每一个单词从树根开始到达叶节点可以预测出它上下文中的一个单词
对比
cbow方法中,是用周围词预测中心词,从而利用中心词的预测结果情况,不断的去调整周围词的向量。cbow预测行为的次数跟整个文本的词数几乎是相等的,**复杂度大概是O(V);**适用于数据量比较多的情况。
skip-gram是用中心词来预测周围的词。在skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV)。当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。
继续学习:
word2vec模型cbow与skip-gram的比较:https://www.cnblogs.com/june0507/p/9412989.html
分类——样本不均衡问题
应对样本不均衡问题的常用策略如下:
-
去除样本多的:欠采样方法
-
增加样本少的:过采样方法
代表性算法——SMOTE,即合成少数类的过采样技术。基本思想是在少数类中选两个样本,在其连线上随机选择一个点作为新和成的少数类样本 -
代价敏感学习
利用代价矩阵,若出现“第一类错误”和“第二类错误”,损失程度会更大。 -
集成学习方法
如Adaboost算法,每一轮迭代学习到一个分类器,并根据当前分类器的表现更新样本的权重,更新策略为正确分类样本权重降低,错误分类样本权重增大,最终的模型是多次迭代模型的一个加权线性组合。
AdaCost算法修改了Adaboost算法的权重更新策略,使得分类代价高的样本权重增加得大,降低的慢。
不平衡学习不能单纯的用准确率来描述模型的性能,通常使用F1值来描述模型性能。
更多模型性能度量: https://blog.csdn.net/qq_33414271/article/details/78198840
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187541.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
