大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines
摘要。视觉跟踪问题要同时对一个给定目标进行高效的鲁棒分类和精确的状态预测。以往的方法提出了多种目标状态预测方法,但很少有方法考虑到视觉跟踪问题本身的特殊性。在仔细分析的基础上,为高性能通用目标跟踪器的设计提供了一套实用的目标状态预测指导原则。遵循这些指导原则,我们通过引入分类和目标状态预测分支(G1)、无模糊性分类评分(G2)、无先验知识跟踪(G3)和预测质量评分(G4),设计了完全卷积Siamese跟踪器++ (SiamFC++)。大量的分析和消融研究证明了我们提出的准则的有效性。没有花哨的功能,我们的SiamFC++跟踪器在五个具有挑战性的基准测试(OTB2015, VOT2018, LaSOT,GOT-10k,TrackingNet)上实现了最先进的性能,这证明了跟踪器的跟踪和泛化能力。特别是,在大规模的TrackingNet数据集上,SiamFC++实现了75.4的AUC较高 得分,同时帧率超过90 FPS,这远远超过了实时要求。代码和模型可在:https://github.com/MegviiDetection/videoanalyst.
1 Introduction
通用视觉跟踪的目的是在给定非常有限的信息的情况下,连续地定位视频中的移动物体,通常只有第一帧的标注信息。作为计算机视觉各个领域的基本构建块,该任务伴随着各种应用,如基于无人机的监控(Mueller, Smith, and Ghanem 2016)和监视系统(Kokkeby et al. 2015)。通用物体追踪的一个独特特点是,不允许有 关于物体以及其周围环境的先验知识(如物体类别)(Huang, Zhao, and Huang 2018)。
跟踪问题可以被视为分类任务和评估任务的组合(Danelljan et al. 2019)第一个任务是通过分类提供一个鲁棒的目标粗略位置。第二项任务是估计一个准确的目标状态,通常用一个边界框表示。虽然现代跟踪器已经取得了很大的进步,但令人惊讶的是,它们的第二项任务(即目标状态估计)的方法却有很大的不同。根据这一点,以前的方法大致可以分为三类。第一类,包括判别性的相关滤波器(DCF) (Henriques et al. 2014;Bolme等人2010年)和SiamFC (Bertinetto等人2016年),采用野蛮的多尺度测试,这是不准确的(Danelljan等人2019年)和低效的(Li等人2018a)。此外,之前的假设是在相邻帧中目标比例/比率以固定速率变化,这种假设在现实中往往不成立。对于第二类,ATOM (Danelljan et al. 2019)通过梯度上升法迭代细化多个初始边界框,以估计目标边界框,这在精度上有显著提高。然而,这种目标估计方法不仅带来了沉重的计算负担,而且还带来了许多额外的超参数(如初始框的数量、初始框的分布),需要微调。第三类是SiamRPN跟踪器家族(Li et al. 2018a;Zhu et al. 2018;Li et al. 2019),通过引入区域建议网络(Region Proposal Network, RPN)来实现准确高效的目标状态估计(Ren et al. 2015)。然而,预定义的锚点设置不仅引入了严重阻碍鲁棒性的模糊的相似度评分(见第4节),而且还需要获取数据分布的先验信息,这显然违背了通用物体追踪的精神。(Huang, Zhao, and Huang 2018)。
在上述分析的推动下,我们提出了一套高性能通用目标跟踪器设计准则:
•G1:分类和状态估计的分解 跟踪器应该执行两个子任务:分类和状态估计。如果没有强大的分类器,跟踪器就无法从背景或干扰物中区分目标,这严重阻碍了其鲁棒性(Zhu et al. 2018)。没有准确的估计结果,跟踪器的准确性从根本上受到限制(Danelljan et al. 2019)。那些野蛮的多尺度测试方法很大程度上忽略了后一项任务,存在效率低、准确性低等问题。
•G2:non-ambiguous 评分 分类分数应该直接代表目标存在的置信度评分,在“视域”中,即对应像素的子窗口,而不是锚盒等预定义设置。作为一个负面的例子,目标与anchor(例如基于anchor的RPN分支)之间的匹配很容易产生一个假阳性的结果,从而导致跟踪失败(参见第4节了解更多细节)。
•G3:无先验知识 根据一般的目标跟踪精神,跟踪方法不需要尺度/比例分布等先验知识(Huang, Zhao, and Huang 2018)。现有方法普遍存在对数据分布先验知识的依赖,影响了算法的泛化能力。
•G4:评估质量评估 如先前研究所示(Jiang et al. 2018;Tian et al. 2019),直接使用分类置信度来选择边界框会导致性能下降。应该使用独立于分类的估计质量评分,就像之前许多关于目标检测和跟踪的研究一样(Jiang et al. 2018;Tian et al. 2019;Danelljan等人2019年)。第二分支(例如ATOM和DiMP)惊人的准确性很大程度上来自于这条准则。而其他人仍然忽略了它,为进一步提高估计精度留下了空间。
根据上述指导原则,我们设计了基于全卷积Siamese跟踪器的SiamFC++方法,由于其全卷积特性,特征图的每个像素都直接对应搜索图像上的每个平移子窗口。我们在分类head(G1)的基础上,增加了一个回归head来准确估计目标。由于取消了预定义的anchor设置,因此也移除了匹配模糊度(G2)和目标尺度/比率分布的先验知识(G3)。最后,在G4之后,在高质量的特权边界框增加了一个估计质量评估分支。
我们的贡献可以概括为三个方面:
- 通过识别跟踪的独特特性,为现代跟踪器设计提供了一套目标状态估计的实用的准则。
- 我们用提出的准则设计了一个简单但功能强大的SiamFC++跟踪器。大量的实验和全面的分析证明了我们提出的准则的有效性。
- 我们的方法在五个具有挑战性的基准上取得了最先进的结果。据我们所知,我们的SiamFC++跟踪器是第一个在大规模数据集TrackingNet(Muller等人,2018年)上以超过90 FPS的速度运行时,实现AUC 75.4的跟踪器。


图1:我们的方法(遵循准则)与最先进的siamrpn++跟踪器(违反了一些指导方针)的比较。分数地图由红色可视化(即红色部分代表高分区域,反之亦然)。在目标外观发生显著变化的情况下,siamrpn++由于锚对象不匹配而失败,而我们的siamfc++通过直接匹配对象而成功。详细分析请参见第4节。
2 Related Works
Tracking Framework
现代跟踪器通过对目标状态的预测大致可以分为三个分支。
其中包括DCF (Henriques et al. 2014;Bolme et al. 2010)和SiamFC (Bertinetto et al. 2016),使用多尺度测试来估计目标尺度。具体来说,算法通过将搜索patch缩放成多个尺度,并将一小批缩放后的图像组合在一起,选取当前帧中分类得分最高的对应尺度作为预测目标尺度。这种策略从根本上来说是有限的,因为边界框预测本身就是一项具有挑战性的任务,需要对物体的姿态有较高的理解(Danelljan等人,2019年)。
在DCF和IoU-Net (Jiang et al. 2018)的启发下,ATOM (Danelljan et al. 2019)通过顺序分类和估计来跟踪目标。通过对分类获得的目标的粗略初始位置的迭代细化,以实现精确的边界框估计。在每帧中对边界框进行多次随机初始化,并在迭代细化中进行多次反向传播,大大降低了ATOM的速度。这种方法在提高精度的同时也带来了沉重的计算负担。更重要的是,ATOM引入了许多额外的超参数,需要进行微调。
另一个分支,名为SiamRPN及其后续作品(Li et al. 2018a;Zhu et al. 2018;Li等人2019年)在Siamese网络之后附加一个区域建议网络,实现了以前未见过的准确性。RPN将预先定义的anchor和目标位置之间的位置移位和大小差异进行回归。然而,RPN结构更适合于需要高召回率的目标检测,而在视觉跟踪中只需要跟踪一个目标。anchor框与目标的模糊匹配严重影响了跟踪器的鲁棒性(见第4节)。最后,anchor的设置不符合一般目标跟踪的精神,需要预先定义超参数来描述其形状。
Detection Framework
视觉跟踪任务虽然具有许多独特的特性,但与目标检测任务仍有许多共同之处,这使得每一项任务都有可能相互受益。例如,在fast – rcnn (Ren et al. 2015)中首次设计的RPN结构在SiamRPN (Li et al. 2018a)中实现了惊人的准确性。继承了fast – rcnn (Ren et al. 2015),最先进的现代探测器,即anchor-based检测器,采用了RPN结构和anchor框设置(Ren et al. 2015;Liu et al. 2016;Li等,2018b)。基于anchor的检测器将预定义的proposal分为正的或负的patch,使用一个额外的偏移量回归来细化对边界框位置的预测。然而,anchor框引入的超参数(如anchor框的比例/比率)对最终的准确性有很大影响,需要尝试性的调整(Cai和Vasconcelos 2018;Tian et al. 2019)。研究人员已经尝试了各种方法来设计无anchor检测器,比如预测物体中心附近点的边界框(Redmon et al. 2016;Huang et al. 2015),或检测并分组一个边界框的一对角(Law and Deng 2018)。在本文中,我们展示了一个基于精心设计的准则的简单传输对目标状态估计的启发,可以实现最先进的跟踪性能。
3 SiamFC++: Fully Convolutional Siamese Tracker for Object Tracking
在本节中,我们将详细描述我们的全卷积Siamese tracker++框架。我们的SiamFC++基于SiamFC,并根据建议的准则逐步改进。如图2所示,SiamFC++框架由一个用于特征提取的Siamese子网络和一个用于分类和回归的区域建议子网络组成。

图2:我们的siamfc++框架(AlexNet版本)。方框表示特征地图。为了清晰起见,公共特征提取器中的中间层被省略了。在分数可视化中,深绿色代表分数地图输入图像上对应的区域,红色的亮度代表分数的大小(min-max归一化)。彩色放大效果更好。
Siamese-based Feature Extraction and Matching
目标跟踪任务可以看作是相似学习问题(Li et al. 2018a)。具体来说,Siamese网络是离线训练和在线评估,以在更大的搜索图像中定位模板图像。Siamese网络由两个分支组成。模板分支将第一帧中的目标patch作为输入(记作z),而搜索分支将当前帧作为输入(记作x)。Siamese骨干网络在两个分支之间共享参数,的对输入的x和z执行相同的变换换,以将它们嵌入到共同的特征空间中,以供后续任务使用。模板patch和搜索patch在嵌入空间 ϕ \phi ϕ进行互相关:
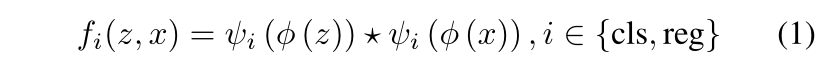
其中★表示互相关操作, ϕ ( . ) \phi(.) ϕ(.)表示共同特征提取的Siamese骨干网络, ψ ( . ) \psi(.) ψ(.)表示特定任务层,并且 i 表示子任务类型(“cls”用于分类,“reg”用于回归)。在我们的实现中,在共同特征提取后,我们对 ψ c l s \psi_{cls} ψcls和 ψ r e g \psi_{reg} ψreg都使用了两个卷积层,将共同特征调整到特定任务的特征空间。需要注意的是, ψ c l s \psi_{cls} ψcls和 ψ r e g \psi_{reg} ψreg的特征是相同大小的。
Application of Design Guidelines in Head Network
基于SiamFC,我们按照提出的准则逐步改进跟踪器的每个部分。
跟随G1,我们在嵌入空间的互相关层后设计了分类head和回归head。对于特征图中的每一个像素,分类head将 ψ c l s \psi_{cls} ψcls作为输入,并将对应的图像patch分为正patch或负patch,而回归head将 ψ r e g \psi_{reg} ψreg作为输入,并且输出一个额外的偏置回归,以细化边界框位置的预测。head的结构在图2的互相关操作后呈现。
特别地,在分类时,如果输入图像上的相应位置 ( [ s / 2 ] + x s , [ s / 2 ] + y s ) ([s/2]+xs,[s/2]+ys) ([s/2]+xs,[s/2]+ys)落入ground-truth边界框,则特征图 ψ c l s \psi_{cls} ψcls上的位置(x, y)被视为正样本。否则,它是一个负样本。这里s是指backbone的总步距(在本文s=8)。对于特征图 ψ r e g \psi_{reg} ψreg上每个正样本位置(x, y)的回归目标,最后一层预测从相对应位置 ( [ s / 2 ] + x s , [ s / 2 ] + y s ) ([s/2]+xs,[s/2]+ys) ([s/2]+xs,[s/2]+ys)到ground-truth边界框四边的距离,表示为一个4D向量 t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) t^*= (l^*, t^*, r^*, b^*) t∗=(l∗,t∗,r∗,b∗)。因此,位置(x, y)的回归目标可以表示为:
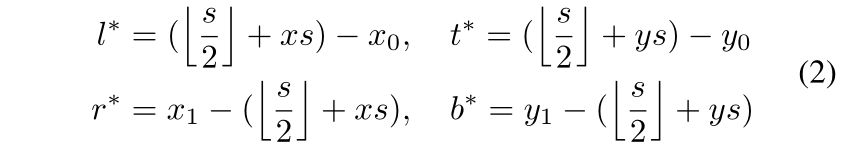
其中(x0, y0)和(x1, y1)表示与点(x,y)相关的ground-truth边界框 B ∗ B^* B∗的left-top和right-bottom。
分类head和回归head特征图上的每个位置(x, y),都对应于输入图像上以位置 ( [ s / 2 ] + x s , [ s / 2 ] + y s ) ([s/2]+xs,[s/2]+ys) ([s/2]+xs,[s/2]+ys)为中心的一个图像patch。跟随G2,我们直接对相应的图像patch进行分类,并在该位置回归目标边界框,就像在许多先前的跟踪器中一样(Henriques et al. 2014;Bolme et al. 2010;Bertinetto等人,2016)。换句话说,我们的SiamFC++直接将位置视为训练样本。而基于anchor的对应方法,将输入图像上的位置视为多个anchor框的中心,在同一位置输出多个分类分数,并将目标边框相对于这些anchor框进行回归,导致anchor和目标之间的模糊匹配。尽管(Li et al. 2018a;Zhu et al. 2018;Li et al. 2019)在各种指标上的表现优于(Henriques et al. 2014;Bolme et al. 2010;Bertinetto et al. 2016),我们的经验表明,模糊匹配可能导致严重的问题(详见第4节)。在我们的逐像素预测方式中,在最终特征图的每个像素上只做一个预测。因此,很明显,每个分类分数直接给出了目标在相应像素子窗口中的置信度,而我们的设计在这种程度上是没有歧义的。
由于SiamFC++对位置进行分类和回归w.r.t.,它没有预定义的anchor框,因此没有关于目标数据分布(例如比例/比例)的先验知识,这符合G3。
在上述章节中,我们还没有考虑目标状态估计质量,直接使用分类评分来选择最终的方框。这可能会导致定位精度的下降,因为(Jiang et al. 2018)表明分类置信度与定位精度没有很好的相关性。根据(Luo et al. 2016)的分析,子窗口中心周围的输入像素对相应的输出特征像素的重要性要大于其他像素。因此,我们假设目标中心周围的特征像素比其他位置特征像素具有更好的估计质量。跟随G4,我们增加了一个简单而有效的质量评估分支,类似于通过在1×1卷积分类head的基础上添加1×1卷积层,如图2右侧所示。输出应该是估计 先验空间得分(Prior Spatial Score, PSS),其定义如下:
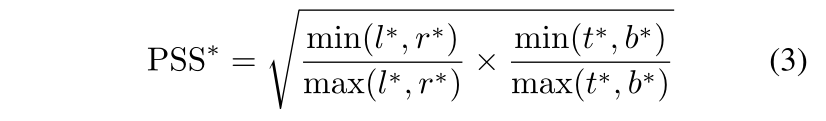
注意,PSS并不是质量评估的唯一选择。作为一个变量,我们还可以计算预测框和ground-truth框之间的IOU得分,类似于(Jiang et al. 2018):

其中B是预测框和 B ∗ B^* B∗是它相对应的ground-truth边界框。
在推理过程中,通过将PSS与相应的预测分类分数相乘来计算用于最终框选择的分数。这样,那些远离物体中心的边界框将会严重的惩罚。从而提高了跟踪精度。
Training Objective
我们优化训练目标如下:
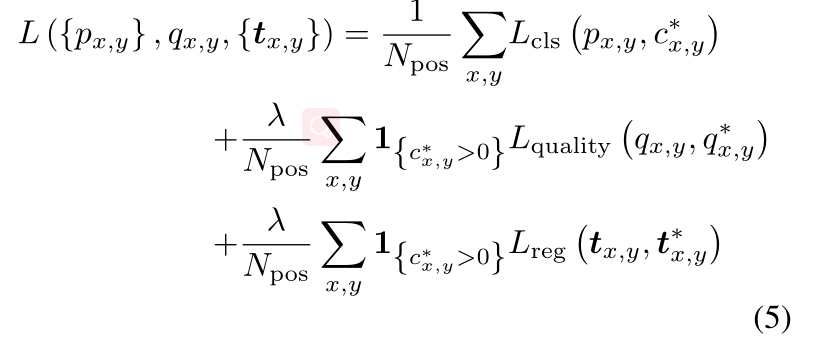
其中1{·}是指标函数,如果{}中的条件成立则取1,不成立则取0; L c l s L_{cls} Lcls表示分类结果的焦点损失。 L q u a l i t y L_{quality} Lquality表示质量评估的二值交叉熵(BCE)损失, L r e g L_reg Lreg表示边界框结果的。如果(x, y)被认为是正样本,我们给 c x , y ∗ c_{x,y}^∗ cx,y∗赋1,如果是负样本,则给 c x , y ∗ c_{x,y}^∗ cx,y∗赋0。
4 Experiments
Implementation Details 实验细节
**模型设置 ** 在这项工作,我们使用不同的骨干网络架构,实现两个版本的追踪器:一种采用以前文献中修改版本的AlexNet (Bertinettoetal.2016) ,记为SiamFC ++ _AlexNet,另一个使用GoogLeNet (Szegedy et al . 2015),记为SiamFC ++_GoogLeNet。与之前使用ResNet-50的方法相比(He et al. 2016),前者在跟踪基准上的性能与前者相同甚至更好,计算成本更低(见第4节)。两个网络都在ImageNet (Krizhevsky, Sutskever,和Hinton 2012)上进行了预训练,这已被证明适用于跟踪任务(Li et al. 2018a;Zhu et al. 2018)。我们将发布代码,以方便进一步研究。
训练数据 我们采用ILSVRC-VID/DET 、COCO 、YoutubeBB 、LaSOT 和GOT -10k作为我们的基本训练集。特定基准测试的例外w.r.t.在以下小节中详细介绍。对于视频数据集,我们从VID、LaSOT和get -10k中提取图像对,间隔小于100帧(Youtube-BB为5帧)。对于图像数据集(COCO/ImagenetDET),我们通过包含负样本对(Zhu et al. 2018)作为训练样本的一部分来生成训练样本,以增强识别模型干扰物的能力。作为数据增强技术,我们在搜索图像上按照均匀分布进行随机移动和缩放。
训练阶段 对于AlexNet版本,我们将参数从conv1冻结到conv3,并微调conv4和conv5。对于那些没有经过预处理的层,我们采用零中心高斯分布进行初始化,标准差为0.01。我们首先用5个预热epoch训练模型,学习速率从 1 0 − 7 10^{−7} 10−7至 2 × 1 0 − 3 2×10^{−3} 2×10−3线性增加,然后对其余45个epoch使用余弦退火学习速率计划,每个时段使用600k图像对。我们选择momentum为0.9的随机梯度下降(SGD)作为优化器。
对于GoogLeNet版本,我们冻结阶段1和阶段2,微调阶段3和阶段4,将基础学习率提高到 2 × 1 0 − 2 2×10_{−2} 2×10−2,并将骨干网络参数的学习率乘以0.1,即全局学习率。我们还将每个epoch的图像对数量减少到300k,将总epoch数减少到20(热身5,训练15个),并在第10历元解冻骨干网络中的参数,以避免过拟合。在LaSOT基准实验(Fan et al. 2019)(协议II)中,我们冻结骨干中的参数,进一步将每个epoch的图像对数量减少到150k,以稳定训练数据量相对较少的训练。
在VOT2018短期基准测试中,AlexNet骨干网络的跟踪器运行速度为160帧/秒,而在VOT2018短期基准测试中,GoogleNet骨干网络的跟踪器运行速度为90帧/秒,两者都在NVIDIA RTX 2080Ti GPU上进行评估。
测试阶段 我们的模型的输出是一组带有相应置信度得分的边界框。根据相应方框的比例变化和离上一帧预测的目标位置的距离,对分数进行惩罚。然后选则惩罚后分数最高的方框,并用于更新目标状态。
From SiamFC towards SiamFC++ 从SiamFC到SiamFC++
虽然两者都采用逐像素预测方式,但SiamFC和我们的SiamFC++之间存在显著的性能差距。在本小节中,我们对VOT2018数据集进行了消融研究,以SiamFC为基线,旨在确定改善跟踪性能的关键组件.
结果如表1所示。具体来说,在SiamFC基线中,跟踪器只在其网络中执行分类任务,目标状态估计是通过多尺度测试来完成的。我们逐渐更新SiamFC跟踪器通过使用额外的训练数据(2/4),申请一个更好的head结构(第3行),并添加回归分支以进行准确的估计,从而产生我们提出SiamFC + +跟踪器(第5行),我们进一步用GoogLeNet取代AlexNet主干,GoogLeNet在提取视觉特征方面更强大(第6行)。

表1:消融研究:从SiamFC到SiamFC++。在VOT-2018 (A/R/EAO)上进行了实验。∆EAO表示EAO w.r.t.的增量,即基线(线1)
跟踪性能的关键组件可以按降序排列如下:回归分支(0.094)、数据源多样性(0.063/0.010)、更强的主干网络(0.026)和更好的head结构(0.020),其中括号中注明每个部分带来的∆EAO。请注意,这些是Siamrpn++在SiamFC之上的额外组件。在将所有额外的组件添加到SiamFC后,我们的SiamFC++以更少的计算预算实现了优异的性能。此外,有两件事值得一提:1)。Line 2的鲁棒性®超过了SiamRPN跟踪器(0.46(Li et al. 2018a));2). Line 3的鲁棒性与DaSiamRPN(0.337(Zhu et al. 2018))处于同一水平,而使用的数据(没有COCO和DET)比后者少。这些结果表明,引入RPN模块和anchor框设置无疑会提高精度,但其鲁棒性并未得到提高,甚至受到阻碍。我们应该把这归功于它违反了我们提出的指导方针。
Quality Assessment Choice 在GOT -10k val子集上,我们获得了跟踪器预测PSS的AO值为77.8,跟踪器预测IoU的AO值为78.0。通过SiamFC+±GoogLeNet进行了实验。最后,我们在本文中选择PSS作为我们方法的一个实现,因为在我们的实验中,我们在数据集上观察到它的稳定性。
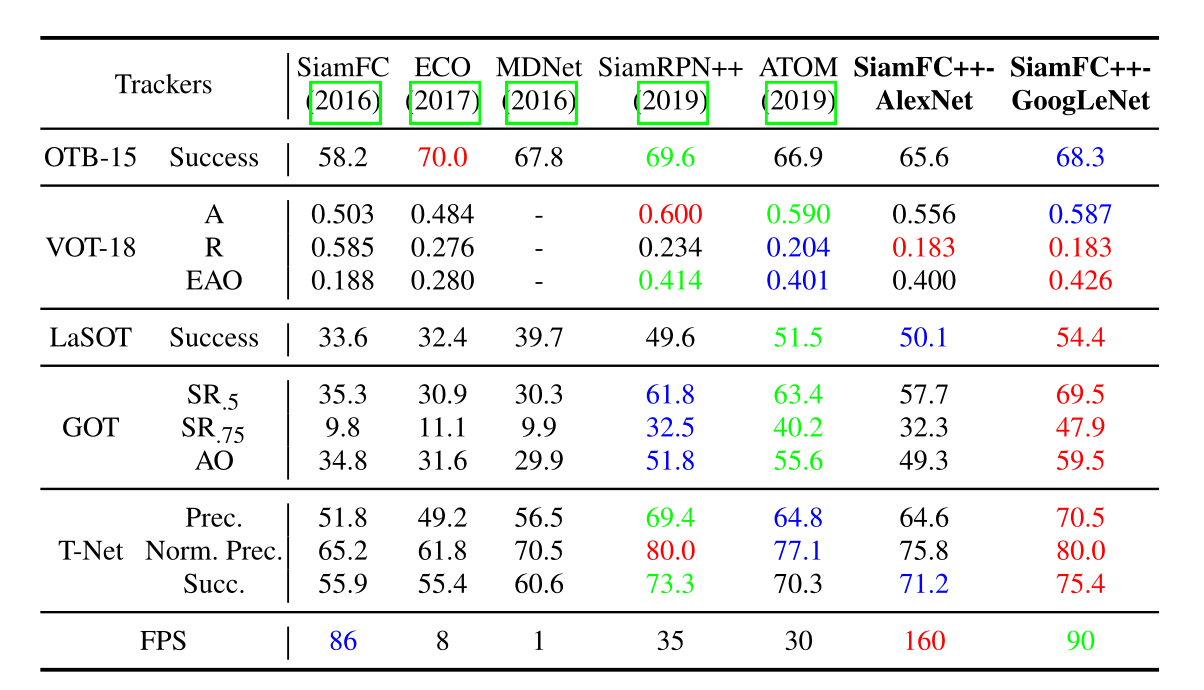
表2:几个基准测试的结果。T-Net 表示TrackingNet。每个维度(row)的前3个结果分别用红色、绿色和蓝色表示。
5 Conclusion
本文通过分析视觉跟踪任务的特点和以往跟踪器的缺陷,提出了一套跟踪器设计中目标状态估计的准则。遵循这些准则,我们提出了我们的方法,为分类和目标状态估计(G1)提供有效的方法,给出无模糊性的分类评分(G2),没有先验知识的跟踪(G3),并提出估计质量(G4)。我们通过广泛的消融研究来验证所提出的准则的有效性。我们的跟踪器基于这些指导原则,在5个具有挑战性的基准测试中达到了最先进的性能,同时仍然以90 FPS运行。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187184.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
