大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
一、结果回顾
Gauss-Newton算法(高斯牛顿法)用来估计参数,Gauss-Newton算法学习对Gauss-newton算法做了详细的解释,并且使用C++实现,写得很不错。
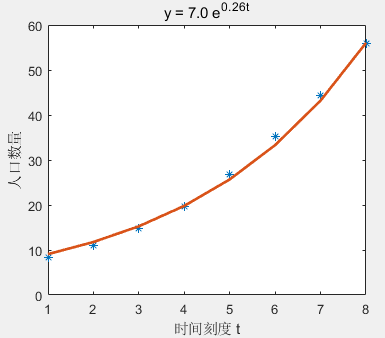
但是程序其实有微小错误,实际的坐标并不是年代1815-1885,而是1~8,否则 p = A e B t p = Ae^{Bt} p=AeBt拟合时将会迅速增大,也得不到 A = 0.7 A=0.7 A=0.7, B = 0.26 B=0.26 B=0.26 这一结果。 个人觉得原文对程序实现的解释也稍有不足,本文将使用 MATLAB,给出详细实现步骤。
A = 0.7 , B = 0.26 ; t = 1 − 8 , y = A e B t A = 0.7,B=0.26;t = 1-8,y = Ae^{Bt} A=0.7,B=0.26;t=1−8,y=AeBt绘图如下(星号为原始数据点,实现为拟合点)

二、Gauss-Newton算法
以下详细说明各个矩阵如何获取,逐步给出计算结果。
2.1 原始数据
| 时间刻度 t t t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 人口数 y y y | 8.3 | 11.0 | 14.7 | 19.7 | 26.7 | 35.2 | 44.4 | 55.9 |
2.2 数学模型
现需要使用指数模型拟合人口数 p 关于时间刻度 t 的变化。
数学模型为:
y ^ = x 1 e x 2 t (2.1) \hat {y} = x_1 e^{x_2 t} \tag{2.1} y^=x1ex2t(2.1)
现在需要求解合适的参数 x = [ x 1 , x 2 ] x=[x_1, x_2] x=[x1,x2],使得有:
min f ( x ) = 1 2 ∑ i = 1 8 r i 2 ( x ) (2.2) \min f(x)=\frac{1}{2} \sum_{i=1}^8 r_i^2(x) \tag{2.2} minf(x)=21i=1∑8ri2(x)(2.2)
r i ( x ) = y i ^ − y i (2.3) r_i(x) = \hat {y_i} – y_i \tag{2.3} ri(x)=yi^−yi(2.3)
2.3 算法流程
接下来给出 x = [ x 1 , x 2 ] T x=[x_1, x_2]^T x=[x1,x2]T 的迭代过程,也即Gauss-Newton算法流程:
1)给定初始点 x 0 x_0 x0,允许误差 ϵ > 0 \epsilon>0 ϵ>0,置 k = 0 k=0 k=0;
2) f ′ ( x ( k ) ) < ϵ f'(x^{(k)}) < \epsilon f′(x(k))<ϵ,导数接近0即在极小点附近,得到 x x x,算法结束,否则继续;
3)计算 x ( k + 1 ) x^{(k+1)} x(k+1), x ( k + 1 ) = x k − H − 1 x^{(k+1)}=x^{k}-H^{-1} x(k+1)=xk−H−1 ▽ \bigtriangledown ▽ f f f
2.4 梯度和黑森矩阵
根据定义,可得梯度和黑森矩阵如下:
原函数:
f ( x 1 , x 2 ) = 1 2 ∑ i = 1 8 r i 2 ( x 1 , x 2 ) (2.4) f(x_1, x_2) = \frac{1}{2} \sum_{i=1}^8 r_i^2(x_1, x_2) \tag{2.4} f(x1,x2)=21i=1∑8ri2(x1,x2)(2.4)
梯度:
▽ f = [ ∂ f ∂ x 1 ∂ f ∂ x 2 ] T = ∑ i = 1 8 [ r i ∂ r i ∂ x 1 r i ∂ r i ∂ x 2 ] T (2.5) \bigtriangledown f= \left [ \frac {\partial f} {\partial x_1}\quad \frac {\partial f} {\partial x_2} \right ]^T = \sum_{i=1}^8 \left [ r_i \frac {\partial r_i} {\partial x_1} \quad r_i \frac {\partial r_i} {\partial x_2} \right ]^T \tag{2.5} ▽f=[∂x1∂f∂x2∂f]T=i=1∑8[ri∂x1∂riri∂x2∂ri]T(2.5)
黑森矩阵:
H = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 x 2 ∂ 2 f ∂ x 2 x 1 ∂ 2 f ∂ x 2 2 ] ≈ ∑ i = 1 8 [ ∂ r i ∂ x 1 ∂ r i ∂ x 1 ∂ r i ∂ x 1 ∂ r i ∂ x 2 ∂ r i ∂ x 2 ∂ r i ∂ x 1 ∂ r i ∂ x 2 ∂ r i ∂ x 2 ] (2.6) H = \left [ \begin {array}{cc} \displaystyle \frac {\partial^2f} {\partial x_1^2} & \displaystyle \frac {\partial^2f} {\partial x_1x_2}\\ \displaystyle \frac {\partial ^2f} {\partial x_2x_1} & \displaystyle \frac {\partial ^2f} {\partial x_2^2} \end {array} \right ] \approx \sum_{i=1}^8 \left [ \begin{array}{cc} \displaystyle \frac {\partial r_i}{\partial x_1} \displaystyle \frac {\partial r_i}{\partial x_1} & \displaystyle \frac {\partial r_i}{\partial x_1} \displaystyle \frac {\partial r_i}{\partial x_2} \\ \displaystyle \frac {\partial r_i}{\partial x_2} \displaystyle \frac {\partial r_i}{\partial x_1} & \displaystyle \frac {\partial r_i}{\partial x_2} \displaystyle \frac {\partial r_i}{\partial x_2} \end {array} \right ] \tag{2.6} H=⎣⎢⎢⎡∂x12∂2f∂x2x1∂2f∂x1x2∂2f∂x22∂2f⎦⎥⎥⎤≈i=1∑8⎣⎢⎡∂x1∂ri∂x1∂ri∂x2∂ri∂x1∂ri∂x1∂ri∂x2∂ri∂x2∂ri∂x2∂ri⎦⎥⎤(2.6)

现在只剩下 r r r 关于 x 1 、 x 2 x_1、x_2 x1、x2 的偏导,由 r r r 的定义,容易直接根据求导法则得出 r r r 关于 x 1 、 x 2 x_1、 x_2 x1、x2 的偏导(也可使用数值微分,见第2.5小节),如下:
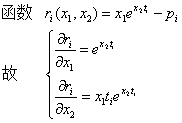
2.5 MATLAB 程序
进行运算时,C++程序需要逐个数据读取,而MATLAB擅长矩阵运算。矩阵运算一方面使得效率提高,运算简洁,但一定程度上也对运算表达能力有更高要求。
%原始数据
t = 1:8;
popu = [8.3 11.0 14.7 19.7 26.7 35.2 44.4 55.9];
%高斯牛顿法
A = 1.0; %待求变量1
B = 1.0; %待求变量2
k = 0; %迭代次数
eps = 1e-3; %允许误差
r = A*exp(B*t) - popu; %误差
r1 = zeros(size(r)); %记录上一次误差
while(1)
if (sum(abs(r1-r)) < eps) || (k >100)
A
B
k
break
else
pA = exp(B*t); %关于A的偏导数
pB = A*exp(B*t).*t; %关于B的偏导数
H = [2*sum(pA.*pA) 2*sum(pA.*pB)
2*sum(pA.*pB) 2*sum(pB.*pB)]; %黑森矩阵
df = [sum(r.*pA)
sum(r.*pB)]; %梯度
k = k + 1;
delta = inv(H) * df; %变化量
A = A - delta(1); %更新待求参数A
B = B - delta(2); %更新待求参数B
r1 = r; %记录上一次误差
r = A*exp(B*t) - popu; %更新误差
end
end
运行结果为
A = 7.0001
B = 0.2621
k = 25
因此迭代13次达到满足条件,也与文章最开始的结果一致。
2.6 微分的数值运算
在很多实际问题中,往往需要计算微分、偏微分等,本例就运用了偏微分。但是并不是所有的数学模型都像本例这样能够给出微分的解析式,很多时候需要数值运算。
回到第一次接触导数时,导数的定义为
f ′ ( x ) = lim Δ x → 0 f ( x + Δ x ) − f ( x − Δ x ) 2 Δ x f'(x)=\lim\limits_{\Delta x \to 0} \frac {f(x+\Delta x) – f(x-\Delta x)} {2 \Delta x} f′(x)=Δx→0lim2Δxf(x+Δx)−f(x−Δx)
这里两边都取 Δ \Delta Δ x x x,有助于提高精度,偏微分与之类似。
本例中
r i = x 1 e x 2 t i − y i r_i = x_1 e^{x_2 t_i} – y_i ri=x1ex2ti−yi
偏导即为:
∂ r i ∂ x 1 = r ( x 1 + Δ x 1 , x 2 ) − r ( x 1 − Δ x 1 , x 2 ) 2 Δ x 1 = ( x 1 + Δ x 1 ) e x 2 t i − ( x 1 − Δ x 1 ) e x 2 t i 2 Δ x 1 \frac {\partial r_i}{\partial x_1} = \frac {r(x_1+\Delta x_1, x_2) – r(x_1-\Delta x_1, x_2)} {2\Delta x_1} = \frac { (x_1+\Delta x_1)e^{x_2t_i} – (x_1-\Delta x_1) e^{x_2t_i}} {2\Delta x_1} ∂x1∂ri=2Δx1r(x1+Δx1,x2)−r(x1−Δx1,x2)=2Δx1(x1+Δx1)ex2ti−(x1−Δx1)ex2ti
∂ r i ∂ x 2 = r ( x 1 , x 2 + Δ x 2 ) − r ( x 1 , x 2 − Δ x 2 ) 2 Δ x 2 = x 1 e ( x 2 + Δ x 2 ) t i − x 1 e ( x 2 − Δ x 2 ) t i 2 Δ x 2 \frac {\partial r_i}{\partial x_2} = \frac {r(x_1, x_2 + \Delta x_2) – r(x_1, x_2-\Delta x_2)} {2\Delta x_2} = \frac {x_1 e^{(x_2 + \Delta x_2) t_i} – x_1 e^{(x_2 – \Delta x_2)t_i}} {2\Delta x_2} ∂x2∂ri=2Δx2r(x1,x2+Δx2)−r(x1,x2−Δx2)=2Δx2x1e(x2+Δx2)ti−x1e(x2−Δx2)ti
再取 Δ x 1 = Δ x 2 = 0.0001 \Delta x_1 = \Delta x_2 =0.0001 Δx1=Δx2=0.0001 例如,一个很小的值,我们就能够得出关于 x 1 、 x 2 x_1、x_2 x1、x2的偏导数。值得注意的是,我们其实也没必要过多地化简,因为很多时候是很复杂的,例如此时 x 2 x_2 x2 的偏导数就比较难化简,何不充分发挥计算机的计算能力呢?
修改程序如下,程序中使用 A A A 代替 x 1 x_1 x1, B B B 代替 x 2 x_2 x2:
%原始数据
t = 1:8;
popu = [8.3 11.0 14.7 19.7 26.7 35.2 44.4 55.9];
%高斯牛顿法
A = 1.0; %待求变量1
B = 1.0; %待求变量2
k = 0; %迭代次数
eps = 1e-3; %允许误差
r = A*exp(B*t) - popu; %误差
r1 = zeros(size(r)); %记录上一次误差
dA = 1e-4; %求导时变化率
dB = 1e-4; %求导时变化率
while(1)
if (sum(abs(r1-r)) < eps) || (k >100)
A
B
k
break
else
pA = (((A+dA)*exp(B*t)) - (A-dA)*exp(B*t)) / (2*dA);%关于A的偏导数
pB = (A*exp((B+dB)*t) - A*exp((B-dB)*t)) / (2*dB) ; %关于B的偏导数
H = [2*sum(pA.*pA) 2*sum(pA.*pB)
2*sum(pA.*pB) 2*sum(pB.*pB)]; %黑森矩阵
df = [sum(r.*pA)
sum(r.*pB)]; %梯度
k = k + 1;
delta = inv(H) * df; %变化量
A = A - delta(1); %更新待求参数A
B = B - delta(2); %更新待求参数B
r1 = r; %记录上一次误差
r = A*exp(B*t) - popu; %更新误差
end
end
代码主要修改了pA,pB的计算方式,结果跟上面一致
A = 7.0001
B = 0.2621
k = 25
三、LM算法
3.1 算法原理
LM算法结合高斯牛顿法和梯度下降法,虽然听起来很复杂的样子,实际上很简单,就是在高斯牛顿法的基础上添加一个梯度下降因子,算法如下:
1)给定初始点 x 0 x_0 x0,允许误差 ϵ > 0 \epsilon>0 ϵ>0,置 k = 0 k=0 k=0;
2) f ′ ( x ( k ) ) < ϵ f'(x^{(k)}) < \epsilon f′(x(k))<ϵ,导数接近0即在极小点附近,得到 x x x,算法结束,否则继续;
3)计算 x ( k + 1 ) x^{(k+1)} x(k+1), x ( k + 1 ) = x k − ( H + x^{(k+1)}=x^{k}-(H+ x(k+1)=xk−(H+ α \alpha α I ) − 1 I)^{-1} I)−1 ▽ \bigtriangledown ▽ f f f (高斯牛顿法为 x ( k + 1 ) = x k − H − 1 x^{(k+1)}=x^{k}-H^{-1} x(k+1)=xk−H−1 ▽ \bigtriangledown ▽ f f f)
3.2 MATLAB程序
% 原始数据
t = 1:8;
popu = [8.3 11.0 14.7 19.7 26.7 35.2 44.4 55.9];
% LM法
A = 1.0; %待求变量1
B = 1.0; %待求变量2
k = 0; %迭代次数
eps = 1e-3; %允许误差
r = A*exp(B*t) - popu; %误差
r1 = zeros(size(r)); %记录上一次误差
dA = 1e-4; %求导时变化率
dB = 1e-4; %求导时变化率
alpha = 10; %LM法梯度下降因子 =====此行添加=====
while(1)
if (sum(abs(r1-r)) < eps) || (k >100)
A
B
k
break
else
pA = (((A+dA)*exp(B*t)) - (A-dA)*exp(B*t)) / (2*dA);%关于A的偏导数
pB = (A*exp((B+dB)*t) - A*exp((B-dB)*t)) / (2*dB) ; %关于B的偏导数
H = [2*sum(pA.*pA) 2*sum(pA.*pB)
2*sum(pA.*pB) 2*sum(pB.*pB)]; %黑森矩阵
df = [sum(r.*pA)
sum(r.*pB)]; %梯度
k = k + 1;
delta = (inv(H + alpha*eye(2))) * df; %变化量 =====此行修改=====
A = A - delta(1); %更新待求参数A
B = B - delta(2); %更新待求参数B
r1 = r; %记录上一次误差
r = A*exp(B*t) - popu; %更新误差
end
end
A = 6.9999
B = 0.2621
k = 33
结果基本一致,但比高斯牛顿法还多运行了几代。
四、多变量问题
先说明一下,多变量时结果并不如预期所想,存在一些问题!
由于其他博友问到多自变量时怎么办这个问题,思考后觉得可行,做此补充。方便起见,直接把上面的时间换成两个吧:
| 时间刻度 t 1 t_1 t1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 时间刻度 t 2 t_2 t2 | 1.1 | 1.2 | 1.3 | 1.4 | 1.5 | 1.6 | 1.7 | 1.8 |
| 人口数 y y y | 8.3 | 11.0 | 14.7 | 19.7 | 26.7 | 35.2 | 44.4 | 55.9 |
数学模型为:
y ^ = x 1 e x 2 t 1 + x 3 e x 4 t 2 \hat {y} = x_1 e^{x_2 t_1} + x_3e^{x_4 t_2} y^=x1ex2t1+x3ex4t2
现在需要求解合适的参数 x = [ x 1 , x 2 , x 3 , x 4 ] x=[x_1, x_2, x_3, x_4] x=[x1,x2,x3,x4],使得有:
min f ( x ) = 1 2 ∑ i = 1 8 r i 2 ( x ) r i ( x ) = y i ^ − y i \min f(x)=\frac{1}{2} \sum_{i=1}^8 r_i^2(x) \\ r_i(x) = \hat {y_i} – y_i minf(x)=21i=1∑8ri2(x)ri(x)=yi^−yi
由于梯度和雅可比矩阵都使用一阶偏导即可计算,因此需要分别计算: ∂ y ^ ∂ x 1 \displaystyle \frac {\partial \hat y}{\partial x_1} ∂x1∂y^, ∂ y ^ ∂ x 2 \displaystyle \frac {\partial \hat y}{\partial x_2} ∂x2∂y^, ∂ y ^ ∂ x 3 \displaystyle \frac {\partial \hat y}{\partial x_3} ∂x3∂y^, ∂ y ^ ∂ x 4 \displaystyle \frac {\partial \hat y}{\partial x_4} ∂x4∂y^ 。此处导数可以直接运用公式计算,也可利用数值方式计算,程序将采用数值方式计算。
类比式(2.5),梯度为:
▽ f = [ ∂ f ∂ x 1 ∂ f ∂ x 2 ∂ f ∂ x 3 ∂ f ∂ x 4 ] T = ∑ i = 1 8 [ r i ∂ r i ∂ x 1 r i ∂ r i ∂ x 2 r i ∂ r i ∂ x 3 r i ∂ r i ∂ x 4 ] T (4.1) \bigtriangledown f= \left [ \frac {\partial f} {\partial x_1}\quad \frac {\partial f} {\partial x_2} \quad \frac {\partial f} {\partial x_3} \quad \frac {\partial f} {\partial x_4} \right]^T = \sum_{i=1}^8 \left [ r_i \frac {\partial r_i} {\partial x_1} \quad r_i \frac {\partial r_i} {\partial x_2} \quad r_i \frac {\partial r_i} {\partial x_3} \quad r_i \frac {\partial r_i} {\partial x_4}\right ]^T \tag{4.1} ▽f=[∂x1∂f∂x2∂f∂x3∂f∂x4∂f]T=i=1∑8[ri∂x1∂riri∂x2∂riri∂x3∂riri∂x4∂ri]T(4.1)
类比式(2.6),黑森矩阵为:
H = [ ∂ 2 f x 1 2 ⋯ ∂ 2 f ∂ x 1 x 4 ⋮ ⋱ ⋮ ∂ 2 f x 4 x 1 ⋯ ∂ 2 f ∂ x 4 2 ] ≈ ∑ i = 1 8 [ ∂ r i ∂ x 1 ∂ r i ∂ x 1 ⋯ ∂ r i ∂ x 1 ∂ r i ∂ x 4 ⋮ ⋱ ⋮ ∂ r i ∂ x 4 ⋯ ∂ r i ∂ x 4 ∂ r i ∂ x 4 ] (2.6) H = \left [ \begin {array}{ccc} \displaystyle \frac {\partial^2f} {x_1^2}& \cdots &\displaystyle \frac {\partial^2f} {\partial x_1x_4}\\ \vdots & \ddots & \vdots \\ \displaystyle \frac {\partial^2f} {x_4x_1}& \cdots &\displaystyle \frac {\partial^2f} {\partial x_4^2} \end {array} \right ] \approx \sum_{i=1}^8 \left [ \begin{array}{ccc} \displaystyle \frac {\partial r_i}{\partial x_1} \frac {\partial r_i}{\partial x_1} & \cdots & \displaystyle \frac {\partial r_i}{\partial x_1} \frac {\partial r_i}{\partial x_4} \\ \vdots & \ddots & \vdots \\ \displaystyle \frac {\partial r_i}{\partial x_4} & \cdots & \displaystyle \frac {\partial r_i}{\partial x_4} \displaystyle \frac {\partial r_i}{\partial x_4} \end {array} \right ] \tag{2.6} H=⎣⎢⎢⎢⎢⎢⎡x12∂2f⋮x4x1∂2f⋯⋱⋯∂x1x4∂2f⋮∂x42∂2f⎦⎥⎥⎥⎥⎥⎤≈i=1∑8⎣⎢⎢⎢⎢⎡∂x1∂ri∂x1∂ri⋮∂x4∂ri⋯⋱⋯∂x1∂ri∂x4∂ri⋮∂x4∂ri∂x4∂ri⎦⎥⎥⎥⎥⎤(2.6)
公式有了,写程序,程序中使用 A , B , C , D A, B, C, D A,B,C,D 代替 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4 :
%原始数据
t1 = 1:8;
t2 = 1.1:0.1:1.8;
popu = [8.3 11.0 14.7 19.7 26.7 35.2 44.4 55.9];
%高斯牛顿法
A = 1.0; %待求变量1
B = 1.0; %待求变量2
C = 1.0;
D = 1.0;
k = 0; %迭代次数
eps = 1e-3; %允许误差(相比之前,降低了一个数量级精度)
r = A*exp(B*t1)+ C*exp(D*t2) - popu; %误差
r1 = zeros(size(r)); %记录上一次误差
dA = 1e-4; %求导时变化率
dB = 1e-4; %求导时变化率
dC = 1e-4;
dD = 1e-4;
alpha = 5; % 梯度下降因子
while(1)
if (sum(abs(r1-r)) < eps) || (k >50)
A
B
C
D
k
break
else
% 计算偏导
pA = (((A+dA)*exp(B*t1)) - (A-dA)*exp(B*t1)) / (2*dA);%关于A的偏导数
pB = (A*exp((B+dB)*t1) - A*exp((B-dB)*t1)) / (2*dB) ; %关于B的偏导数
pC = (((C+dC)*exp(D*t2)) - (C-dC)*exp(D*t2)) / (2*dC);%关于C的偏导数
pD = (C*exp((D+dD)*t2) - C*exp((D-dD)*t2)) / (2*dD) ; %关于D的偏导数
% 黑森矩阵
H = [2*sum(pA.*pA) 2*sum(pA.*pB) 2*sum(pA.*pC) 2*sum(pA.*pD)
2*sum(pB.*pA) 2*sum(pB.*pB) 2*sum(pB.*pC) 2*sum(pB.*pD)
2*sum(pC.*pA) 2*sum(pC.*pB) 2*sum(pC.*pC) 2*sum(pC.*pD)
2*sum(pD.*pA) 2*sum(pD.*pB) 2*sum(pD.*pC) 2*sum(pD.*pD)];
% 梯度
df = [sum(r.*pA)
sum(r.*pB)
sum(r.*pC)
sum(r.*pD)];
k = k + 1;
delta = (inv(H + alpha*eye(4))) * df; %变化量
A = A - delta(1); %更新待求参数A
B = B - delta(2); %更新待求参数B
C = C - delta(3);
D = D - delta(4);
r1 = r; %记录上一次误差
r = A*exp(B*t1)+ C*exp(D*t2) - popu; %更新误差
end
end
结果如下:
A = -0.2168
B = 0.5926
C = 0.2473
D = 3.2152
k = 51
注意,不使用LM算法只使用Gauss-Newton法会出现矩阵奇异的问题,难以继续。
总结
本文在Gauss-Newton算法学习的基础上给出具体公式及推导,使用 MATLAB 详细地实现Gauss-Newton算法和LM算法,并给出数值计算偏导数方法。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187174.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
