大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
?论文下载地址
SiamFC论文地址
SiamFC论文百度网盘下载地址 ❗提取码:7309❗
SiamFC论文翻译(水印)百度网盘下载地址 ❗提取码:4ysm❗
SiamFC论文翻译(无水印PDF+Word)下载地址
?代码下载地址
??论文作者
Luca Bertinetto、Jack Valmadre、Joao F. Henriques、Andrea Vedaldi、Philip H. S. Torr
Department of Engineering Science, University of Oxford
?模型讲解
[模型结构]
一说到孪生,大家或许会想到两个一样的东西。在SiamFC的网络结构中,如下图所示,具有两个权值共享的分支。下图中,z为127×127的模板图像相当于我们要追踪的目标,x为256×256的搜索图像,我们所要完成的就是在x中找到z的位置。
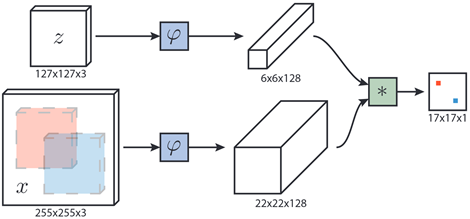

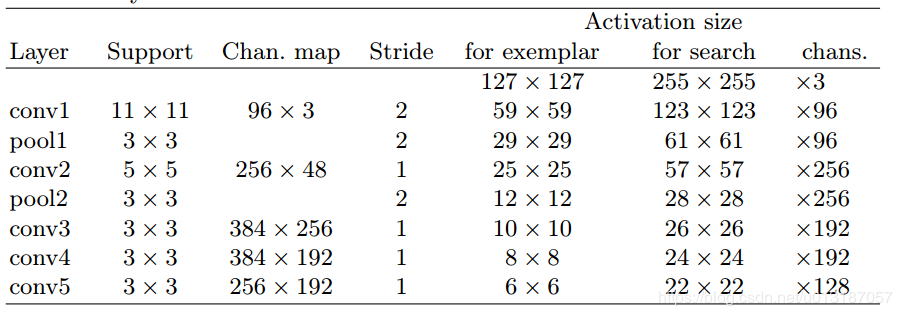
SiamFC有两个分支对应两个输入为z和x,将他们同时输入进行φ的计算,这里的作用就是进行特征提取,分别生成6×6×128和22×22×128的featuremap。φ所对应的特征提取网络采用的是AlexNet,其结构如下:
之后会将生成的featuremap输入互相关层生成heatmap,也叫做相应图,实际上会进行如下的计算:
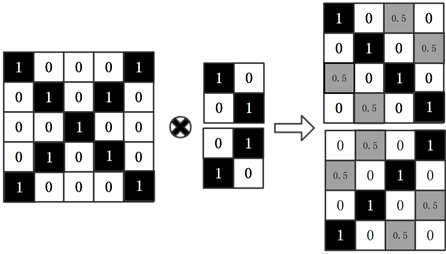
f ( z , x ) = φ ( z ) ∗ φ ( x ) + b I f(z,x) =φ(z)* φ(x)+b\mathbb{I} f(z,x)=φ(z)∗φ(x)+bI 其中 b I b\mathbb{I} bI为每个位置对应的值,’ ∗ * ∗’是进行的卷积运算,通过卷积运算提取在x中与z最相似的部分。如下图所示,卷积的左边就相当于x的featuremap,卷积的右边就是两种不同的z所对应的featuremap,将两者互相卷积生成相应图,响应值最高的位置就对应着z可能的位置。在SiamFC结构图中,输入的搜索图像中有红蓝两个区域在经过网络后与heatmap中的红蓝响应值相对应。
在这会出现一个问题,网络生成的是17×17 的heatmap,而输入x是255×255的搜索图像,怎样将两者的位置进行映射呢。这里,作者将17×17的heatmap进行双三次插值生成272×272的图像,来确定物体的位置。但是为什么不生成255×255的图像呢,作者在论文中说,这样做是由于原始图像相对比较粗糙,为了使定位更加准确。
[模型输入]
孪生网络有两个分支对应两个输入,z与x的大小并不是任意输入的,如下图所示

上面的三张图是网络输入的模板图像z,下面对应的是网络输入的搜索图像x,红色为当前的所在帧的bounding-box。对于模板图像来说,根据第一帧的groundtruth会得到目标的(x_min,y_min,w,h)四个值,会通过以下公式生成模板图像的大小:
s ( w + 2 p ) × s ( h + 2 p ) = A s(w+2p)×s(h+2p) = A s(w+2p)×s(h+2p)=A p = w + h 4 p=\frac{w+h}{4} p=4w+h其中 A = 12 7 2 A=127^2 A=1272,s是对图像进行的一种变换,先将包含上下文信息的 ( w + 2 p ) × ( h + 2 p ) (w+2p)×(h+2p) (w+2p)×(h+2p)的图片扩展,然后进行resize,生成127×127的模板图像(代码中有一个resize的过程)。
对于搜索图像x来说,会从整张图片中裁剪出255×255的图片,裁剪的中心为上一帧预测的bounding-box的中心。作者为了提高跟踪性能,选取了多种尺度进行预测。最初的SiamFC为5种尺度 1.02 5 { − 2 , − 1 , 0 , 1 , 2 } 1.025^{\{-2,-1,0,1,2\}} 1.025{
−2,−1,0,1,2},其中255×255对应尺度为1。后来,为了提升网络的FPS,作者又提出了存在3种尺度的SiamFC-3s。
当模板图像和搜索图像不够裁剪时,会对不足的像素按照RGB通道的均值进行填充。
[损失函数]
首先作者采用了Logistic损失函数:
ℓ ( y , v ) = l o g ( 1 + e x p ( − y v ) ) \ell(y,v)=log(1+exp(-yv)) ℓ(y,v)=log(1+exp(−yv)) L ( y , v ) = 1 ∣ D ∣ ∑ u ∈ D ℓ ( y [ u ] , v [ u ] ) L(y,v)=\frac{1}{|D|}\sum_{u\in D}\ell(y[u],v[u]) L(y,v)=∣D∣1u∈D∑ℓ(y[u],v[u])其中 v v v是网络输出的单个响应值, y y y为实际值,且 y ∈ { − 1 , + 1 } y \in \{-1,+1\} y∈{
−1,+1}, D D D是生成的heatmap, u u u为 D D D中的某一个值, ∣ D ∣ |D| ∣D∣为heatmap的大小。而heatmap的groundtruth按照以下公式进行标记: y [ u ] = { + 1 i f k ∣ ∣ u − c ∣ ∣ ≤ R − 1 otherwise y[u]=\begin{cases}+1& \text if\ \ \ k||u-c||\le R\\-1& \text{otherwise}\end{cases} y[u]={
+1−1if k∣∣u−c∣∣≤Rotherwise其中 c c c为物体在heatmap的中心, u u u为heatmap中任意一点, ∣ ∣ u − c ∣ ∣ ||u-c|| ∣∣u−c∣∣是 u u u与 c c c的欧氏距离, R R R为距离的阈值, k k k为heatmap经过网络之后缩小的倍数,从网络结构可以看出,有三层的卷积或者池化是以2为步长,所以包含物体信息的像素的变化会缩小 2 3 = 8 2^3=8 23=8倍,而以1为步长的操作是不会对包含物体信息的像素产生影响。
[训练过程]
训练过程中,作者通过MatConvNet使用随机梯度下降法(SGD)进行以下公式: arg min θ E ( z , x , y ) L ( y , f ( z , x : θ ) ) \arg \min _{\theta} \underset{(z, x, y)}{\mathbf{E}} L(y, f(z, x : \theta)) argθmin(z,x,y)EL(y,f(z,x:θ))其中 θ \theta θ代表着网络参数。
| 训练属性 | 参数取值 |
|---|---|
| 梯度下降 | SGD |
| 初始化参数 | 高斯分布 |
| 迭代次数 | 50 |
| 每次迭代样本数 | 50000 |
| 批量大小 | 8 |
| 学习率 | 1 0 − 2 − 1 0 − 5 10^{-2}-{10^{-5}} 10−2−10−5 |
[结果分析]
[OTB-13]
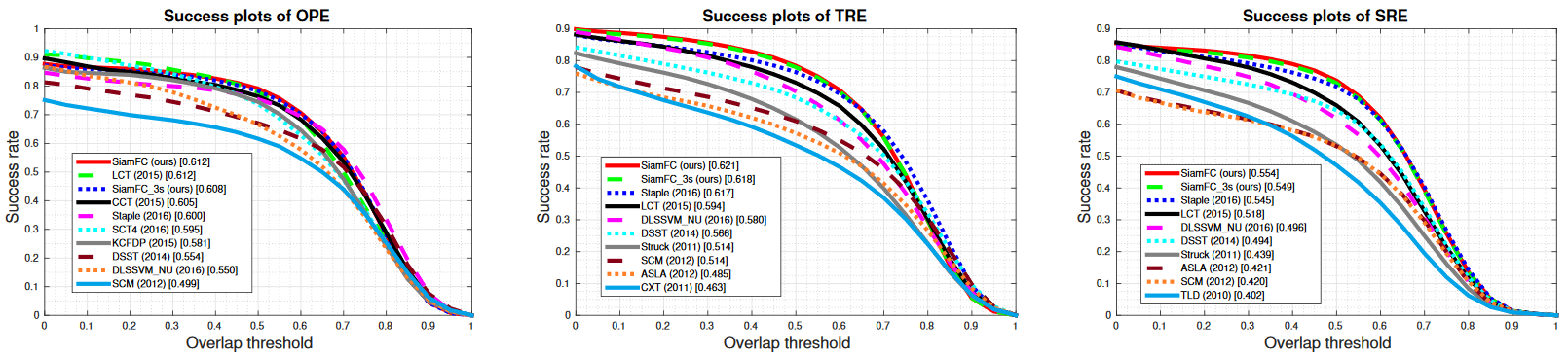
OTB-13基准考虑了不同阈值下的平均每帧的成功率:如果一个跟踪器的估计值和真值之间的联合(IOU)交并比高于某个阈值,则该跟踪器在给定帧中是成功的。OPE(一次性评估)、TRE(时间鲁棒性评估)和SRE(空间鲁棒性评估)。如下图所示,SiamFC的OPE为0.612,TRE为0.621,SRE为0.554。而SiamFC-3s的OPE为0.608,TRE为0.618,SRE为0.549。
[VOT]
在VOT基准测试中,追踪器在故障后5帧自动重新初始化,当估计的边界框和真值之间的IOU为零时,就认为发生了这种情况。
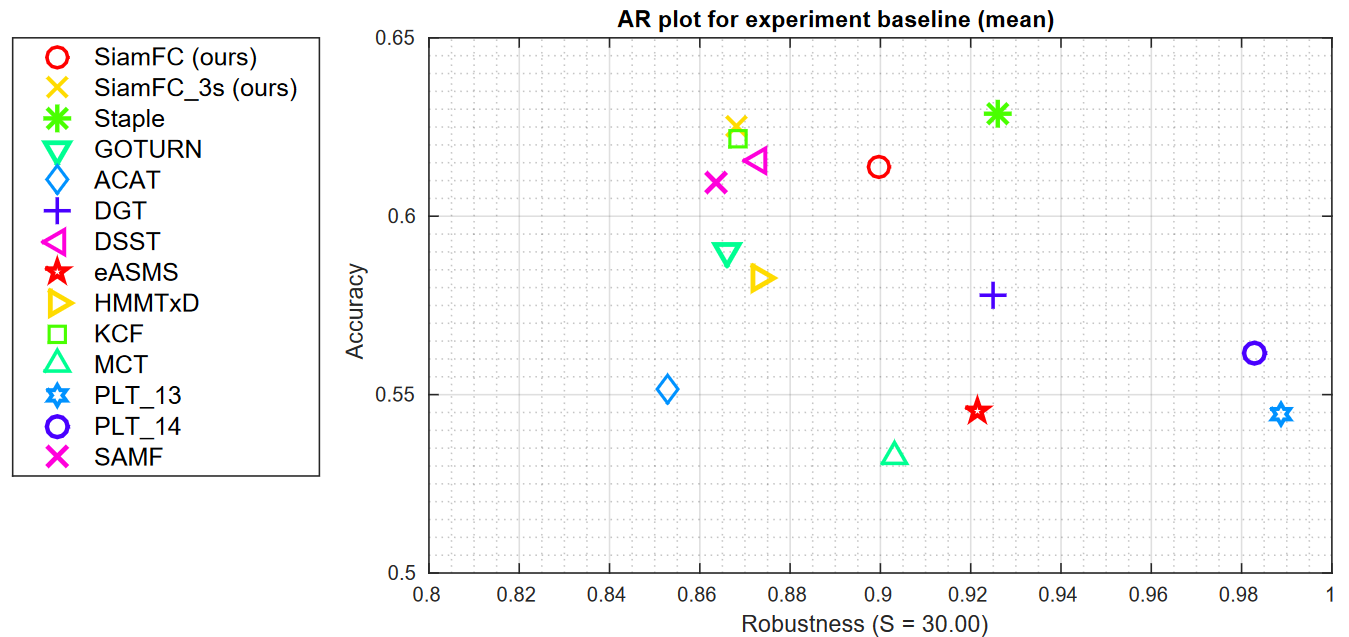
对于VOT-14,跟踪器根据两个性能指标进行评估:精确度和鲁棒性。前者按平均IOU计算,后者按失败总数表示。下图在VOT-14上与其他方法的比较:
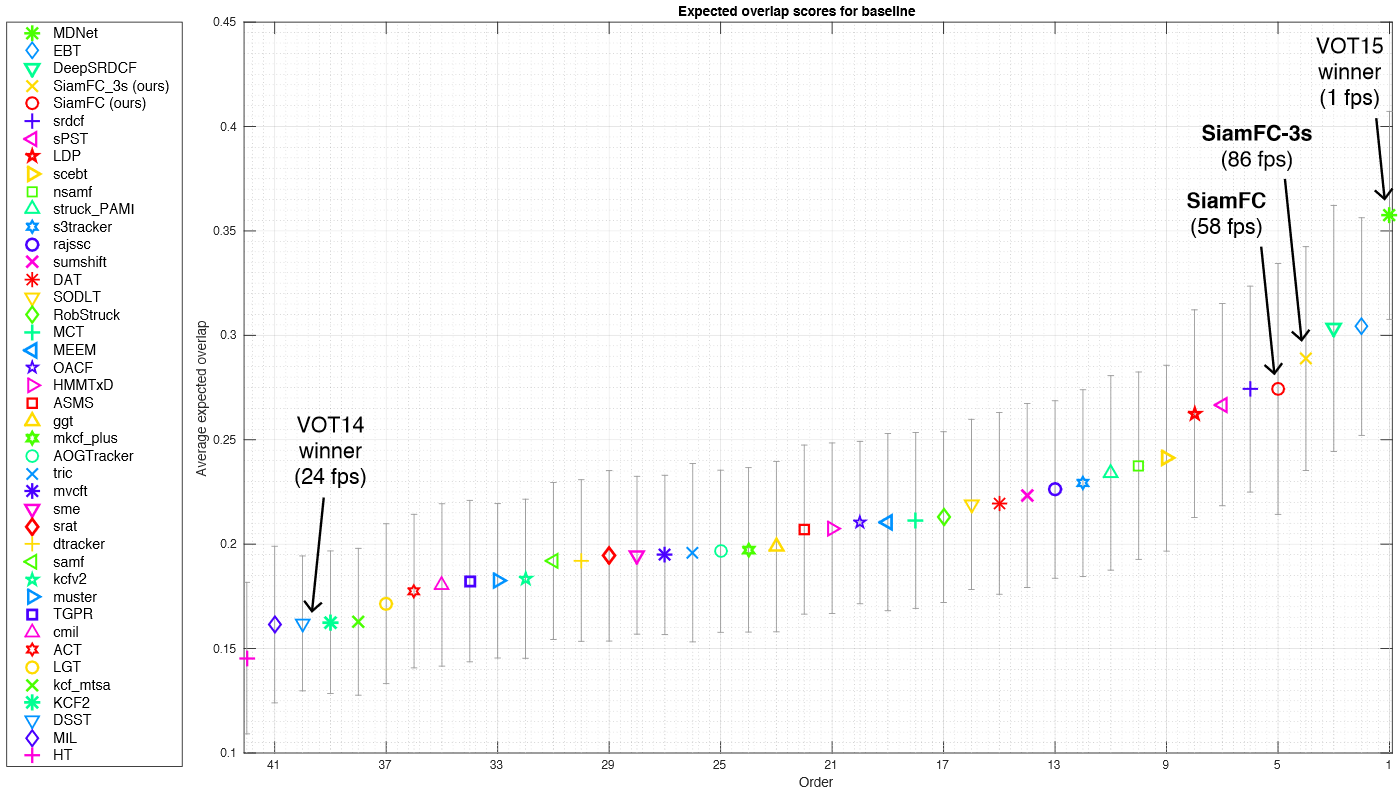
对于VOT-15,计算平均重叠率,它表示失败后没有重新初始化的平均IOU。下图为40多种方法在VOT-15上的对比:
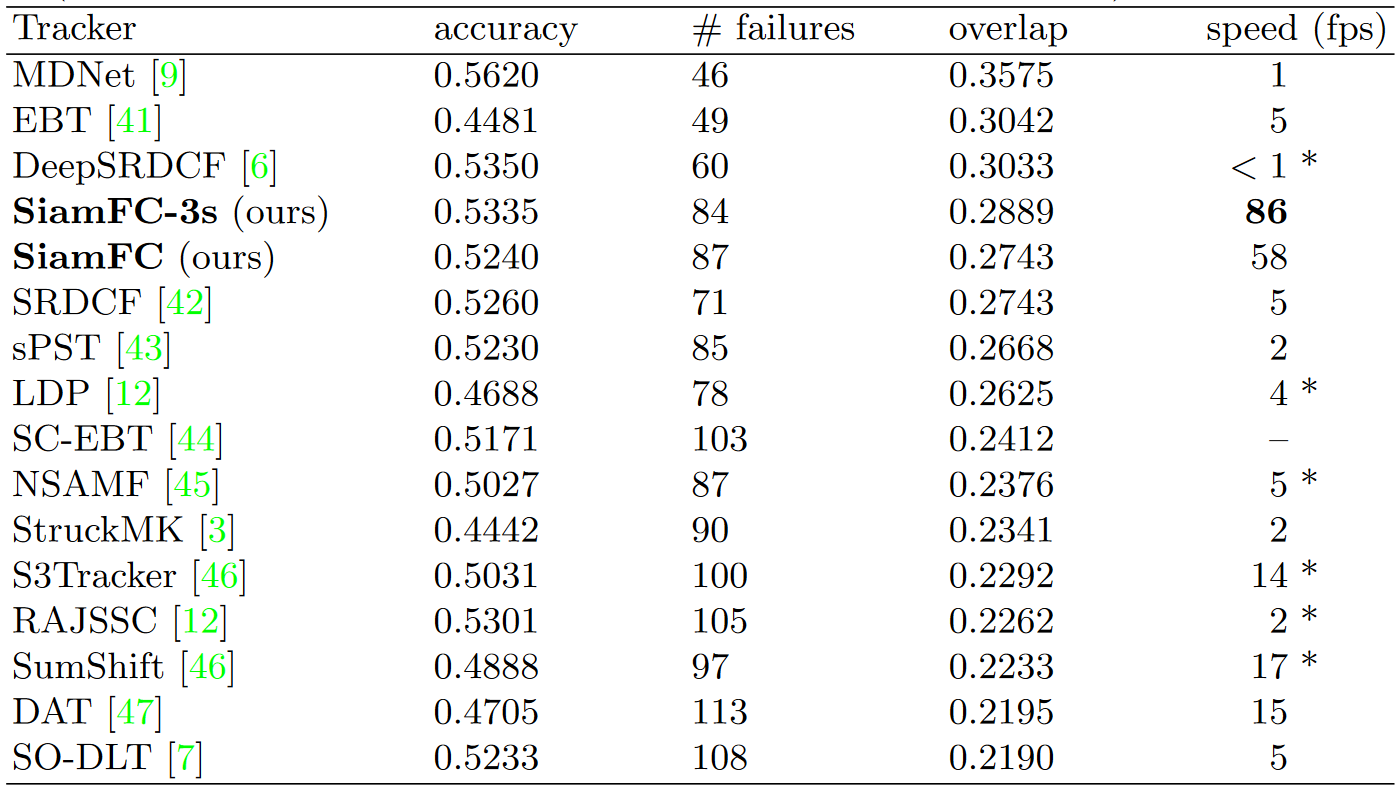
对于VOT-16,SiamFC和SiamFC-3s,分别获得了0.3876和0.4051的总体重叠率。
[ImageNet]
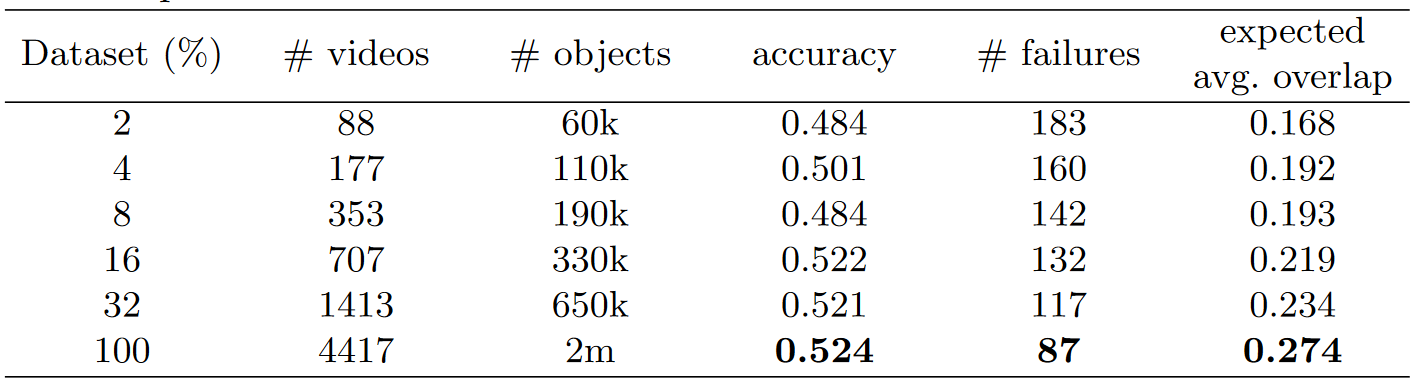
另外,作者还进行了数据集大小对网络性能影响的研究,当ImageNet数据集的大小从5%增加到100%时,平均重叠率(在VOT-15上测量)从0.168提高到0.274。
下图作者展示了SiamFC的优秀的鲁棒性,如运动模糊(第2行)、外观的剧烈变化(第1、3和4行)、照明效果差(第6行)和比例变化(第6行)。

?传送门
[视频跟踪]
[视频跟踪数据集指标分析]
[SiamFC:利用全卷积孪生网络进行视频跟踪]
[SiamRPN:利用区域建议孪生网络进行视频跟踪]
[DaSiamRPN:用于视觉跟踪的干扰意识的孪生网络]
[SiamRPN++: 基于深度网络的孪生视觉跟踪的进化]
[SiamMask: 快速在线目标跟踪与分割的统一方法]
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187124.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
