大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
0x01 海量数据文本相似度解决方式SimHash+分词方法+基于内容推荐算法
0x01 海量数据文本相似度解决方式SimHash+分词方法+基于内容推荐算法
原文链接:海量数据文本相似度解决方式SimHash+分词方法+基于内容推荐算法 – 约翰史密斯 – CSDN博客
问题:海量文本相似度怎么解决?
最简单的方式是SimHash,通过对分好的词进行hash并加权(乘以他们的重要程度)进行相加,再进行二值化,最后通过度量二值化后的数字之间的相似度来度量文本句子的相似度。唯一比较麻烦的是最后需要取阈值来界定相似与否。
问题:分词?
一是基于字符串匹配,加入一些启发式的方法将其匹配,时间复杂度为O(n)
二是基于机器学习的分词
问题:如何应用文本相似的度量–常见的是推荐算法
推荐算法分为两种:基于内容,协同过滤
基于内容的推荐容易理解,即通过相似内容来推荐相同的东西,比如你看西游记,我给你推荐悟空传,弊端是会推送雷同的东西
协同过滤包括基于用户的方式和基于item的方式,基于用户大抵是我和你的以前看过的东西或兴趣很相似,那我喜欢的你没有看过的就推荐给你;基于item即给item贴一些标签特征(比如打分等等等等),推送类似标签的的item,再把相同的item安利给你(这样还是会雷同吧?)
0x02 海量simhash查询
原文链接:文档相似度算法 Simhash
造成网页近重复的可能原因主要包括:
镜像网站、内容复制、嵌入广告、计数改变、少量修改
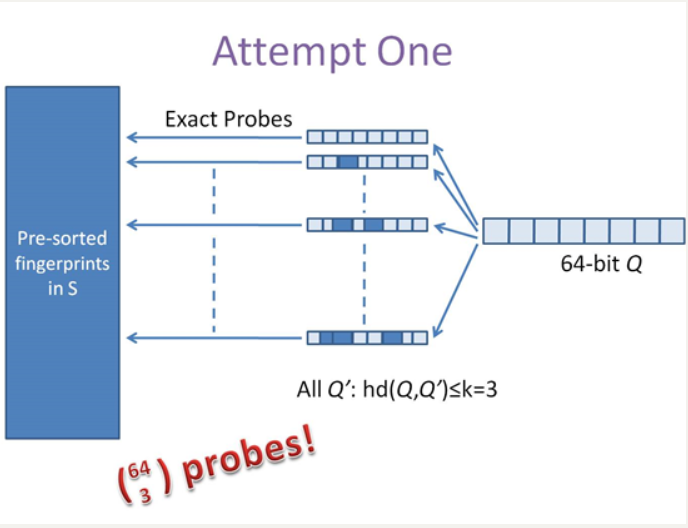
在引入simhash的索引结构之前,先提供两种常规的思路。第一种是方案是查找待查询文本的64位simhash code的所有3位以内变化的组合,大约需要四万多次的查询,参考下图:

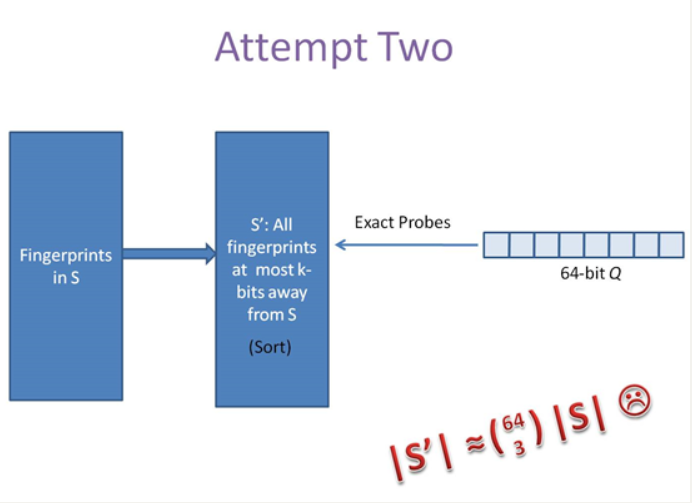
另一种方案是预生成库中所有样本simhash code的3位变化以内的组合,大约需要占据4万多倍的原始空间,参考下图:
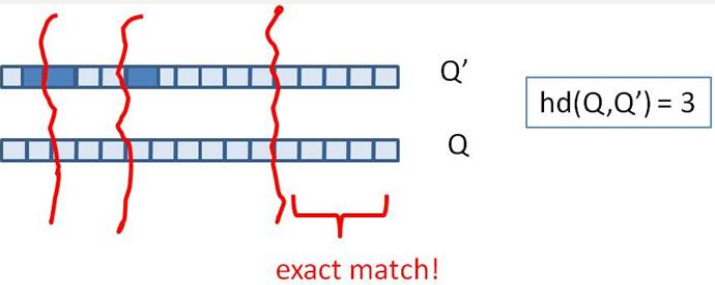
显然,上述两种方法,或者时间复杂度,或者空间复杂度,其一无法满足实际的需求。我们需要一种方法,其时间复杂度优于前者,空间复杂度优于后者。 假设我们要寻找海明距离3以内的数值,根据抽屉原理,只要我们将整个64位的二进制串划分为4块,无论如何,匹配的两个simhash code之间至少有一块区域是完全相同的,如下图所示:
由于我们无法事先得知完全相同的是哪一块区域,因此我们必须采用存储多份table的方式。在本例的情况下,我们需要存储4份table,并将64位的simhash code等分成4份;对于每一个输入的code,我们通过精确匹配的方式,查找前16位相同的记录作为候选记录,如下图所示:
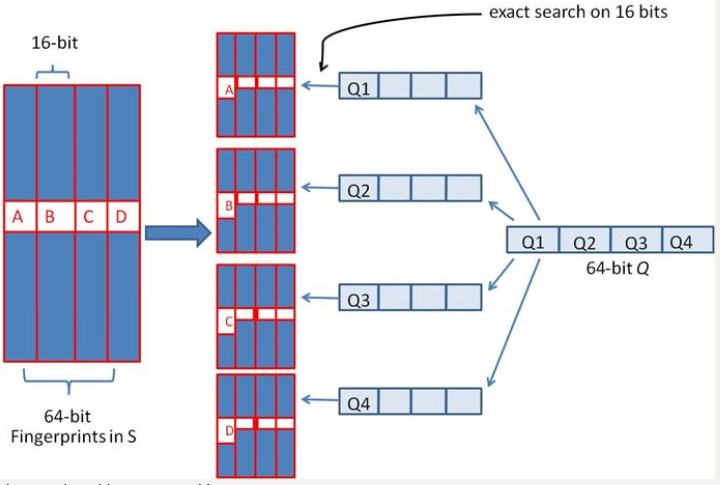
让我们来总结一下上述算法的实质: 1、将64位的二进制串等分成四块 2、调整上述64位二进制,将任意一块作为前16位,总共有四种组合,生成四份table 3、采用精确匹配的方式查找前16位 4、如果样本库中存有2^34(差不多10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果,大大减少了海明距离的计算成本 我们可以将这种方法拓展成多种配置,不过,请记住,table的数量与每个table返回的结果呈此消彼长的关系,也就是说,时间效率与空间效率不可兼得,参看下图:
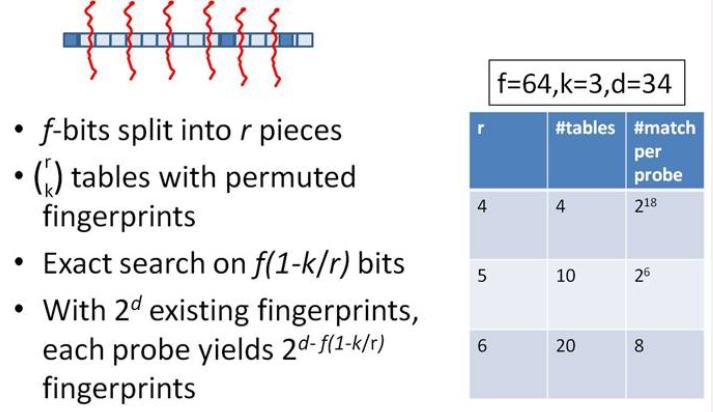
事实上,这就是Google每天所做的,用来识别获取的网页是否与它庞大的、数以十亿计的网页库是否重复。另外,simhash还可以用于信息聚类、文件压缩等。
原文链接:面试|海量文本去重~simhash – Spark高级玩法 – CSDN博客
(1)抽屉原理
一般来讲,判定2篇文章相似的规则,即为2个simhash的汉明距离<=3。
查询的复杂性在于:已有海量(如100亿个)文章的simhash,给定一个新的simhash,希望判断是否与已有的simhash相似。我们只能遍历100亿个simhash,分别做异或运算,看看汉明距离是否<=3,这个性能是没法接受的。
优化的方法就是”抽屉原理“,因为2个simhash相似的标准是<=3比特的差异,所以如果我们把64比特的simhash切成4段,每一段16比特,那么不同的3比特最多散落在3段中,至少有1段是完全相同的。
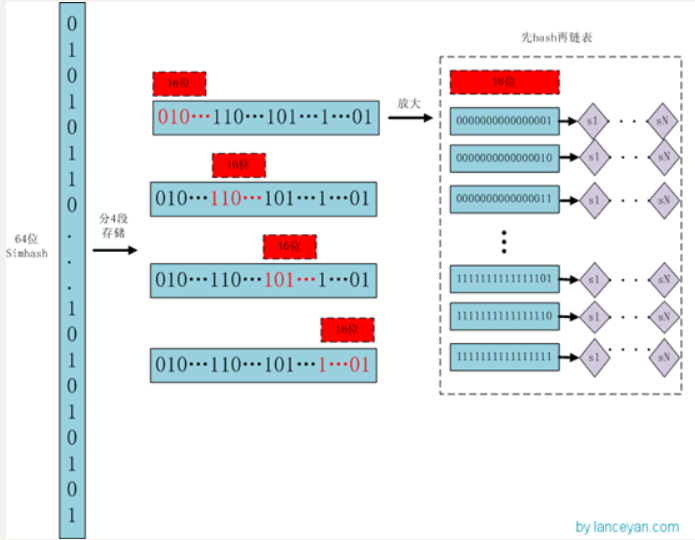
同理,如果我们把simhash切成5段,分别长度 13bit、13bit、13bit、13bit、12bit,因为2个simhash最多有3比特的差异,那么2个simhash至少有2段是完全相同的。
(2)建立索引
对于一个simhash,我们暂时决定将其切成4段,称为a.b.c.d,每一段16比特,分别是:
a=0000000000000000,
b=0000000011111111,
c=1111111100000000,
d=111111111111111。
因为抽屉原理的存在,所以我们可以将simhash的每一段作为key,将simhash自身作为value追加索引到key下。
假设用redis做为存储,那么上述simhash在redis里会存成这样:
key:a=0000000000000000 value(set结构):
{000000000000000000000000111111111111111100000000111111111111111}
key:b=0000000011111111 value(set结构):
{000000000000000000000000111111111111111100000000111111111111111}
key:c=1111111100000000 value(set结构):
{000000000000000000000000111111111111111100000000111111111111111}
key:d=111111111111111 value(set结构):
{000000000000000000000000111111111111111100000000111111111111111}
也就是一个simhash会按不同的段分别索引4次。
(3)判重
假设有一个新的simhash希望判重,它的simhash值是:
a=0000000000000000,b=000000001111110,c=1111111100000001,d=111111111111110
它和此前索引的simhash在3段中一共有3比特的差异,符合重复的条件。
那么在查询时,我们对上述simhash做4段切割,然后做先后4次查询:
用a=0000000000000000 找到了set集合,遍历集合里的每个simhash做异或运算,发现了汉明距离<=3的重复simhash。
用b=000000001111110 没找到set集合。
用c=1111111100000001 没找到set集合。
用d=d=111111111111110 没找到set集合。
(4)优化效果
经过上述索引与查询方式,其实可以估算出优化后的查询计算量。
假设索引库中有100亿个simhash(也就是2^34个simhash),并且simhash本身是均匀离散的。
一次判重需要遍历4个redis集合,每个集合大概有 2^32 / 2^16个元素,也就是26万个simhash,比遍历100亿次要高效多了。
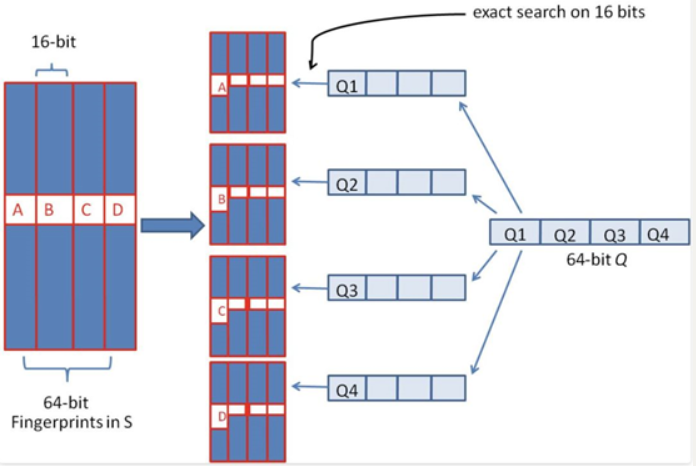
图片左侧表示了一个simhash索引了4份,右侧表示查询时的分段4次查找。
(5)权衡时间、空间
假设分成5段索引,分别命名为:a.b.c.d.e。
根据抽屉原理,至多3比特的差异会导致至少有2段是相同的,所以一共有这些组合需要索引:
a,b a,c a,d a,e b,c b,d b,e c,d c,e d,e
一个simhash需要索引10份,一个集合的大小是2^34 / 2^(26)=256个。
一次查询需要访问10次集合,每个集合256个元素,一共只需要异或计算2560次,基本上查询性能已不再是瓶颈。
但是也可以知道,因为冗余的索引份数从4份变成了10份,所以其实是在牺牲空间换取时间。对应的,这么大量的存储空间,再继续使用redis也是不可能的事情,需要换一个依靠廉价磁盘的分布式存储。
(6)存储选型
毫无疑问选择hbase,特别适合SCAN遍历集合。
rowkey设计:4字节的segment+1字节的段标识flag+8字节的simhash。
切4段,索引一段需要16比特;切5段,索引2段需要13+13比特;所以用4字节的segments来存段落。
1字节的抽屉标识,比如是切4段则标识是1,2,3,4;切5段则可以是1,2,3,4,5,6,7,8,9,10,分别代表(a,b),(a,c),(a,d),(a,e),(b,c) …
然后最后追加上simhash自身作为区分值,这样在查询时只需要指定segment+flag做4/10次SCAN操作,进行异或运算即可。
0x03 比较相似度
海明距离:两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。一个有效编码集中, 任意两个码字的海明距离的最小值称为该编码集的海明距离。
举例如下: 100111和 101010从第一位开始依次有第三位、第四、第六位不同,则海明距离为 3.
举例如下:
A = 100111; B = 101010; hamming_distance(A, B) = count_1(A xor B) = count_1(001101) = 3
异或: 只有在两个比较的位不同时其结果是1 ,否则结果为 0
对每篇文档根据SimHash 算出签名后,再计算两个签名的海明距离(两个二进制异或后 1 的个数)即可。根据经验值,对 64 位的 SimHash ,海明距离在 3 以内的可以认为相似度比较高。 假设对64 位的 SimHash ,我们要找海明距离在3 以内的所有签名。我们可以把 64 位的二进制签名均分成 4 块,每块 16 位。根据鸽巢原理(也成抽屉原理,见组合数学),如果两个签名的海明距离在 3 以内,它们必有一块完全相同。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187080.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
