大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
首先谈一下应用场景——在拟合的时候进行应用
什么是拟合?你有一堆数据点,我有一个函数,但是这个函数的很多参数是未知的,我只知道你的这些数据点都在我的函数上,因此我可以用你的数据点来求我的函数的未知参数。例如:matlab中的fit函数
最小二乘法天生就是用来求拟合的,看函数和数据点的逼近关系。它通过最小化误差的平方和寻找数据的最佳函数匹配进行求解。

拟合我们可以认为是一种试探性的方法,这种方法在计算机出来以前很多情况下是不可能实现的,为什么,因为公式涉及了大量的迭代过程,也就是我想要通过数据点求函数的参数,没有解析解能够直接代入数据求得参数,而是通过一点一点的摸索尝试,最终得到最小误差也就是最好拟合。最具有代表性的就是暴风法,把所有可能的结果都带进去,找到最好的拟合。然后聪明的人类不想这么鲁莽,并且这么无目的地寻找,于是人们开始研究参数向什么方向迭代是最好的,于是便出现了梯度方向等一系列方法。

有最速下降法、Newton 法、GaussNewton(GN)法、Levenberg-Marquardt(LM)算法等。
| 方法 | 介绍 |
|---|---|
| 最速下降法 | 负梯度方向,收敛速度慢 |
| Newton 法 | 保留泰勒级数一阶和二阶项,二次收敛速度,但每步都计算Hessian矩阵,复杂 |
| GN法 | 目标函数的Jacobian 矩阵近似H矩阵,提高算法效率,但H矩阵不满秩则无法迭代 |
| LM法 | 信赖域算法,解决H矩阵不满秩或非正定, |
通过对比的形式想必大家已经记住了这一堆优化的方法,很多情况下使用中都是优化方法的改进方法,因此掌握了这些方法,改进方法也不是太难了。
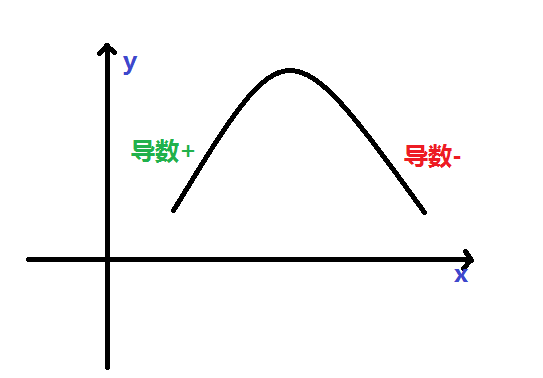
这里还想说明一点上面的最速下降法,很多人都在问的一个问题,为什么最速下降方向取的负梯度方向???为什么?这个可以看我们求导数的时候(梯度和导数的关系完美解析在我之前的博文中),
其实我们从图中不难看出,左侧,y随着x增加时,导数为正,因此导数的方向我们可以定义为指向x正方向,x与导数同向也就是x也逐渐增加时,函数是增大的。右侧,y随x增加而较小,导数为负,我们这里还定义导数的方向此时指向x负半轴,因此x沿负方向减小时,函数值是逐渐增大的,这里需要记住和注意,沿着导数方向,我们的函数值是逐渐增大的。
解释清了上面一点,我们就可以再升几维,在一维时我们的方向只能谈论左右,而上升到二维时,我们的方向就成了平面的360度了,此时就引出了梯度,下图是二维梯度
其实我们还是可以看出,梯度就是由导数组成的,完全可以说成是多维导数,而在一维导数存在的性质,上升了维度,我们的本质是不变的,因此我们只需要沿着每个维度的导数方向变化,我们的函数值就会增加。这里有个证明,沿梯度是增加最快的,我们可以引入方向导数,方向导数定义的在点P,沿某一方向的变化率。
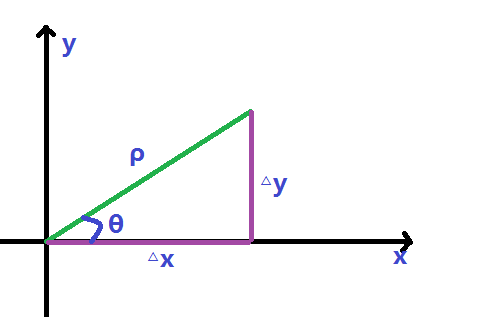
求变化率我们就需要公平一点,各方向变化的尺寸是相同的,可以写一个圆,
半径为
ρ = ( Δ x ) 2 + ( Δ y ) 2 \rho =\sqrt{
{
{\left( \Delta x \right)}^{2}}+{
{\left( \Delta y \right)}^{2}}} ρ=(Δx)2+(Δy)2
变化为
f ( x + Δ x , y + Δ y ) − f ( x , y ) ρ \frac{f\left( x+\Delta x,y+\Delta y \right)-f\left( x,y \right)}{\rho } ρf(x+Δx,y+Δy)−f(x,y)
变化率为(率这里需要加极限的概念,为什么?因为我们无法容忍一个我们没有明确定义数值的量 ρ \rho ρ)
lim ρ → 0   f ( x + Δ x , y + Δ y ) − f ( x , y ) ρ \underset{\rho \to 0}{\mathop{\lim }}\,\frac{f\left( x+\Delta x,y+\Delta y \right)-f\left( x,y \right)}{\rho } ρ→0limρf(x+Δx,y+Δy)−f(x,y)
其中
f ( x + Δ x , y + Δ y ) − f ( x , y ) = ∂ f ∂ x ⋅ Δ x + ∂ f ∂ y ⋅ Δ y + ∘ ( ρ ) f\left( x+\Delta x,y+\Delta y \right)-f\left( x,y \right)=\frac{\partial f}{\partial x}\centerdot \Delta x+\frac{\partial f}{\partial y}\centerdot \Delta y+\circ \left( \rho \right) f(x+Δx,y+Δy)−f(x,y)=∂x∂f⋅Δx+∂y∂f⋅Δy+∘(ρ)
两边同时除以 ρ \rho ρ
f ( x + Δ x , y + Δ y ) − f ( x , y ) ρ = ∂ f ∂ x ⋅ Δ x ρ + ∂ f ∂ y ⋅ Δ y ρ + ∘ ( ρ ) ρ = ∂ f ∂ x ⋅ cos θ + ∂ f ∂ y ⋅ sin θ + ∘ ( ρ ) ρ \begin{aligned} & \frac{f\left( x+\Delta x,y+\Delta y \right)-f\left( x,y \right)}{\rho }=\frac{\partial f}{\partial x}\centerdot \frac{\Delta x}{\rho }+\frac{\partial f}{\partial y}\centerdot \frac{\Delta y}{\rho }+\frac{\circ \left( \rho \right)}{\rho } \\ & =\frac{\partial f}{\partial x}\centerdot \cos \theta +\frac{\partial f}{\partial y}\centerdot \sin \theta +\frac{\circ \left( \rho \right)}{\rho } \end{aligned} ρf(x+Δx,y+Δy)−f(x,y)=∂x∂f⋅ρΔx+∂y∂f⋅ρΔy+ρ∘(ρ)=∂x∂f⋅cosθ+∂y∂f⋅sinθ+ρ∘(ρ)
lim ρ → 0   f ( x + Δ x , y + Δ y ) − f ( x , y ) ρ = ∂ f ∂ x ⋅ cos θ + ∂ f ∂ y ⋅ sin θ \underset{\rho \to 0}{\mathop{\lim }}\,\frac{f\left( x+\Delta x,y+\Delta y \right)-f\left( x,y \right)}{\rho }=\frac{\partial f}{\partial x}\centerdot \cos \theta +\frac{\partial f}{\partial y}\centerdot \sin \theta ρ→0limρf(x+Δx,y+Δy)−f(x,y)=∂x∂f⋅cosθ+∂y∂f⋅sinθ
上式可以进一步改写为
lim ρ → 0   f ( x + Δ x , y + Δ y ) − f ( x , y ) ρ = ∂ f ∂ x ⋅ cos θ + ∂ f ∂ y ⋅ sin θ = { ∂ f ∂ x , ∂ f ∂ y } ⋅ ( cos θ , sin θ ) = ∣ g r a d f ( x , y ) ∣ cos ( g r a d f ( x , y ) , ( cos θ , sin θ ) ) \begin{aligned} & \underset{\rho \to 0}{\mathop{\lim }}\,\frac{f\left( x+\Delta x,y+\Delta y \right)-f\left( x,y \right)}{\rho }=\frac{\partial f}{\partial x}\centerdot \cos \theta +\frac{\partial f}{\partial y}\centerdot \sin \theta \\ & =\left\{ \frac{\partial f}{\partial x},\frac{\partial f}{\partial y} \right\}\centerdot \left( \cos \theta ,\sin \theta \right) \\ & =\left| gradf\left( x,y \right) \right|\cos \left( gradf\left( x,y \right),\left( \cos \theta ,\sin \theta \right) \right) \end{aligned} ρ→0limρf(x+Δx,y+Δy)−f(x,y)=∂x∂f⋅cosθ+∂y∂f⋅sinθ={
∂x∂f,∂y∂f}⋅(cosθ,sinθ)=∣gradf(x,y)∣cos(gradf(x,y),(cosθ,sinθ))
可以看出要想cos值最大,gradf(x,y)和(cosθ,sinθ)需要同方向,而(cosθ,sinθ)就是我们下一步将要行进的方向。
到此便可以说,我们行进的方向和我们的梯度方向一致时,函数增长最快,方向相反时,函数下降最快。




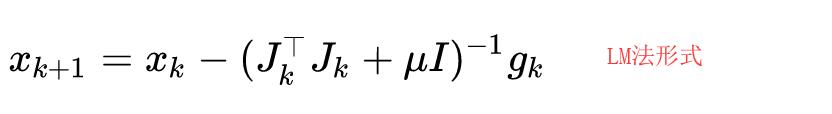
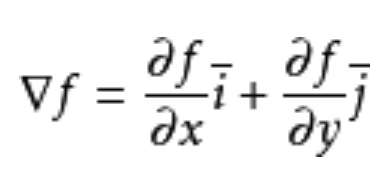
有一个文献写的不错,推荐一下,不过说明,本文并没有进行参考
Wilamowski, B. M., & Yu, H. (2010). Improved computation for Levenberg–Marquardt training. IEEE transactions on neural networks, 21(6), 930-937.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187060.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
