大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
7.4 SiamFC
学习目标
-
目标
-
知道SiamFC的网络结构特点
-
掌握SiamFC的网络训练方式
-
-
应用
-
无
-
任意对象跟踪的问题是通过仅仅在线地学习对象外观的模型来解决,使用视频本身作为唯一的训练数据。 尽管这些方法取得了成功,但他们的在线方法本质上限制了他们可以学习的模型的丰富性。需要跟踪的目标是通过起始帧的选择框给出的。框中可能是任意物体,甚至只是物体的某个部分。由于给定跟踪目标的不确定性,我们无法做到提前准备好数据,并且训练出一个具体的(specific)detector。过去几年出现了TLD,Struck和KCF等优秀的算法,但由于上述原因,用于跟踪的模型往往是一个简单模型,通过在线训练,来进行下一帧的更新。
-
SiamFC可以使用ILSVRC目标检测数据集来进行相似度学习的训练,验证了该数据集训练得到的模型在ALOV/OTB/VOT等跟踪数据集中拥有较好泛化能力。
7.4.1 SiamFC介绍
论文提出了一种全连接孪生网络,实现了端到端的训练。基于相似度学习(similarity learning)的跟踪器SiamFC,通过进行离线训练,线上的跟踪过程只需预测即可。证明这种方法在速度远远超过帧速率要求的情况下在现代跟踪基准测试中实现了非常有竞争力的性能。达到了超过实时的帧率(86 fps 在VOT-15上)
7.4.1.1 架构


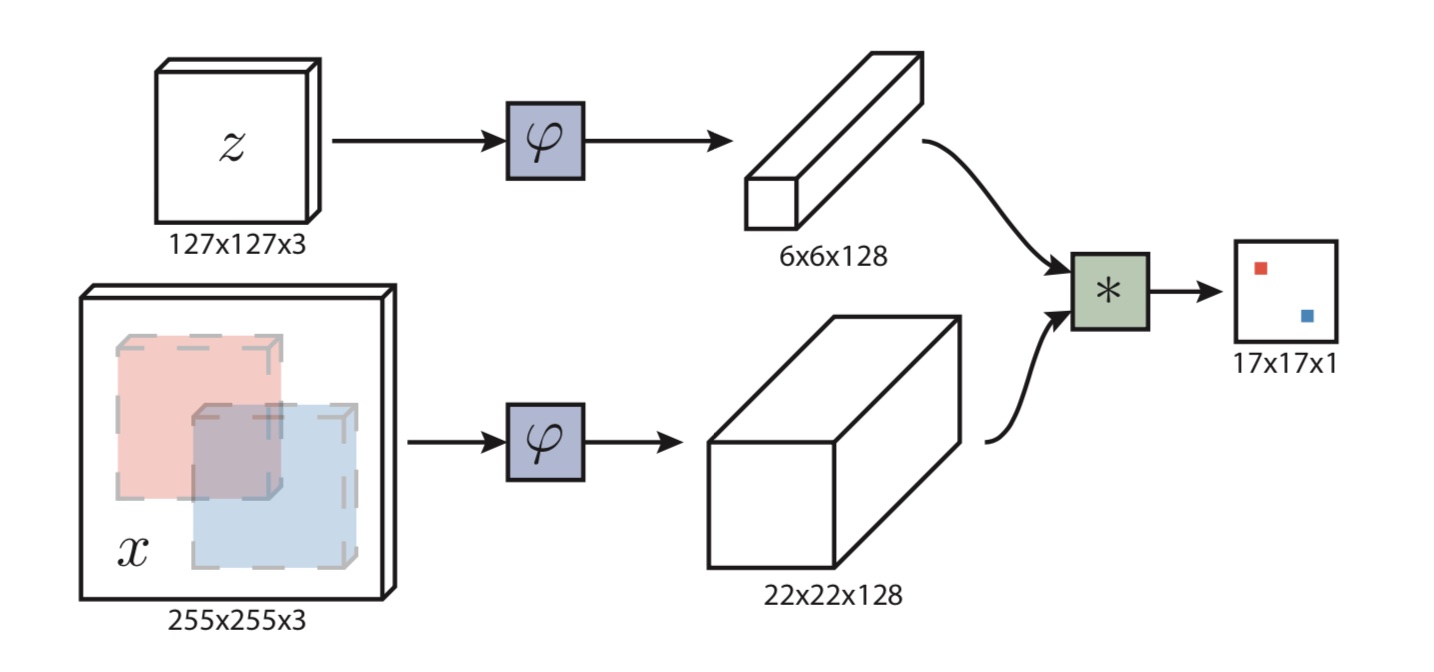

7.4.1.2 网络结构与训练过程
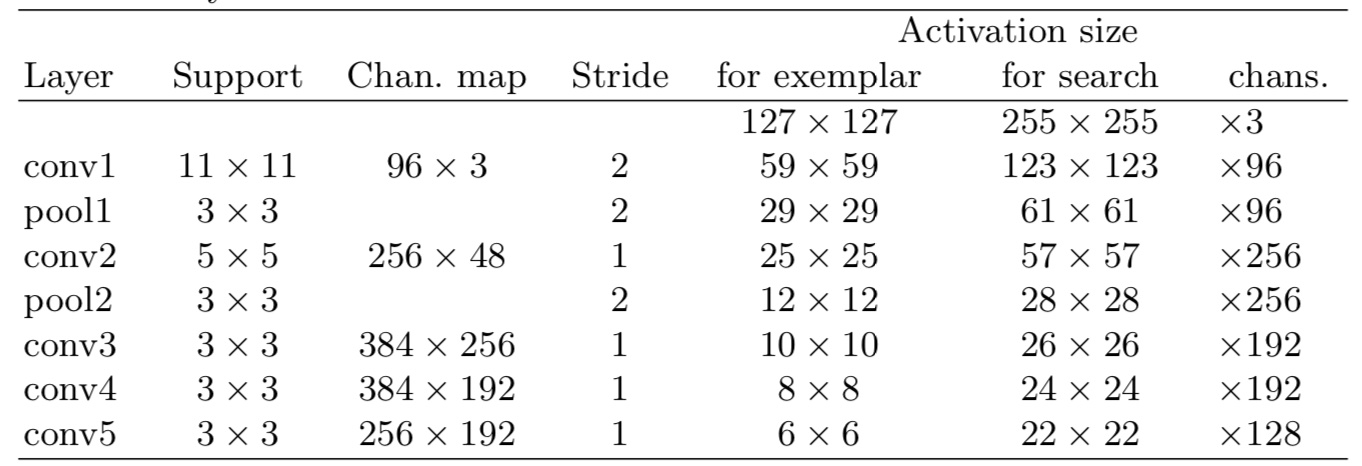
SiamFC设计的网络结构将原始图像缩小了8倍,即?=8,并且,该网络没有padding。
-
1、SiameseFC的卷积神经层是基于AlexNet架构的,其中的padding和全连接层被移去,加入batch normalization层,head改为全卷积网络层。
-
2、在经过卷积神经层提取特征后,SiameseFC使用cross-correlation(交叉相关)作为相似度的度量,计算两个feature map各个位置(区域)上的相似度,得到一个score map(或者说heat map)
-
相似度度量是cross-correlation交叉相关,计算每个位置的相似度得到score map,相当于拿输入特征6x6x128x1作为卷积核,对22x22x128的feature map进行卷积操作,(22-6)/1+1 = 17,得到17x17x1的输出
-
注:在数学上,相关操作可以用于计算两个数据之间的相似度。而在卷积神经网络中, 对卷积操作的定义事实上就是相关操作,因此可以通过卷积操作来计算模板图像和检测图像各个区域之间的相似度。
-
模型训练过程
由于论文提出的Siamese结构是全卷积网络结构,这样的好处是能够输入输出任意大小的结构。不用受限制于要输入相同大小的图片尺寸,可以在跟踪的时候使用全图作为输入去比较,找到目标的位置,保证目标不丢失。并且可以使用ImageNet数据集中的图片,把标注的目标位置作为模板样本,把整张图片作为搜索样本对网络进行训练,得到最终的参数。从标注的 video 数据集上,通过提取 exemplar 和 search images 得到的 Pairs,是在 target 中心的。从一个 video 的两帧上得到的 images 包括物体。在训练的过程中,不考虑物体的类别。


labels:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]

7.4.1.2 测试过程

1、确定预测的目标框的中心
-
1、找到一号最大响应点
-
(1)确定尺度:三个17×17的responses响应图分别经过16倍双三次插值上采样变成三个272×272大小的responses。
-
原因:插值到 272 是为了增大响应图的分辨率:只要 272 响应图和 255 输入的位置对应关系计算正确是可以跟踪的。
-
-
(2)对于第一个和第三个非正常尺度的responses乘以一个惩罚值(这里是 0.9745 )。第二个是正常尺度可以将惩罚值看做 1.0 。
-
对于三个尺度上的最大值,分别乘上 [0.9745, 1, 0.9745] 作为惩罚,然后再比较三者中的最大值,作为最终尺度。0.9745这个超参数的由来并没有特别说明
-
-
(3)选取惩罚后的三个responses 中最大值所在的那一个responses 对应的尺度作为目标的最佳尺度best scale ,将这个 response 称为 best responses (272×272)。
-
-
2、找到二号最大响应点 :将此最大相应点对应到输入的 search 区域,确定目标框的中心:
-
(1)对 best response (272×272) 进行归一化处理,然后用一个对应大小的余弦窗(hanning window)进行惩罚(余弦窗中心位置的值最大,往四周方向的值逐渐减小。因为目标物体靠近区域中心,这样做可以看做是对预测时出现较大位移的惩罚)。
-
(2)找到处理后的 best response (272×272) 中最大值的坐标,将这个坐标对应到输入的 search 区域上的一个点(通过和中心的距离来对应),作为下一帧搜索图区域中预测的目标物体中心位置。
-
-

2、确定目标框的大小:
-
由best scale和初始帧中的目标框大小确定当前预测框的大小,宽高比保持不变 。
这样由中心位置和框的大小,就可以画出输入的这这一帧搜索图的中心被跟踪物体了。
如此链接所示:SiamFC跟踪示例
7.4.1.2 算法特点
1、多尺度检测:多尺度检测通常是将目标先进行不同尺度的采样(如生成图像金字塔),再对不同尺度的图像分别进行检测。在SiameseFC中,对图像先进行不同尺度的采样、再resize到固定的分辨率,可以合并为一个步骤,因此可以并行地生成多张分辨率相同但尺度不同的目标图像(将尺度不同的目标图像resize到同一分辨率即可),集合成一个mini-batch,送进网络进行多尺度检测,从而实现SiameseFC的尺度适应性。
2、在线不更新:SiamFC是非常优秀的long-term跟踪算法。SiameseFC在预测的时候,不在线更新模板图像。这使得SiameseFC的计算速度很快,以便在后续帧中能够应对各种变换。而在另一方面,不在线更新模板图像的策略,可以确保跟踪目标的不变性和纯净性,在long-term跟踪算法上具有天然的优势。
7.4.1.3 算法细节

7.4.1.5 实验
实验设备是NVIDIA GeForce GTX Titan X显卡和Intel Core i7-4790K 4.0GHz处理器。共做了两种不同的算法版本,一种是5种尺度SiamFC,另一种是3种尺度SiamFC-3s,分别在OTB2013和VOT数据集上进行了测试。
1、OTB2013
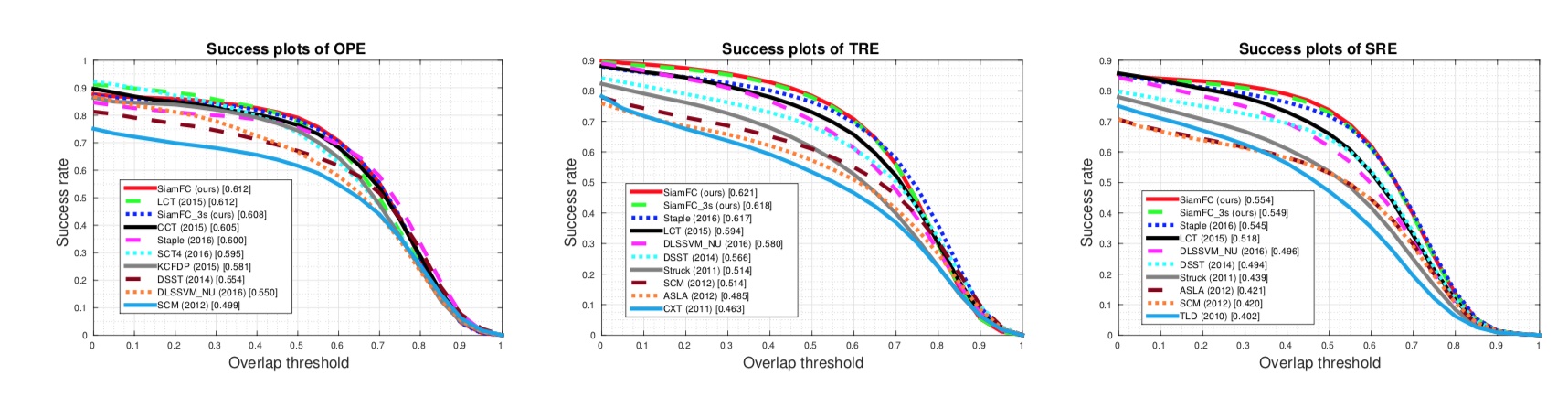
在测试过程中,作者将25%对图像样本转化为灰度图像,其余不变,效果如下。可以看到SiamFC和SiamFC-3s的效果都居于前两名。其中单次成功率OPE可达0.62,时间鲁棒性TRE(将不同帧打乱)可达0.612,而空间鲁棒性SRE(从帧内不同框位置开始)可达0.564。
2、VOT
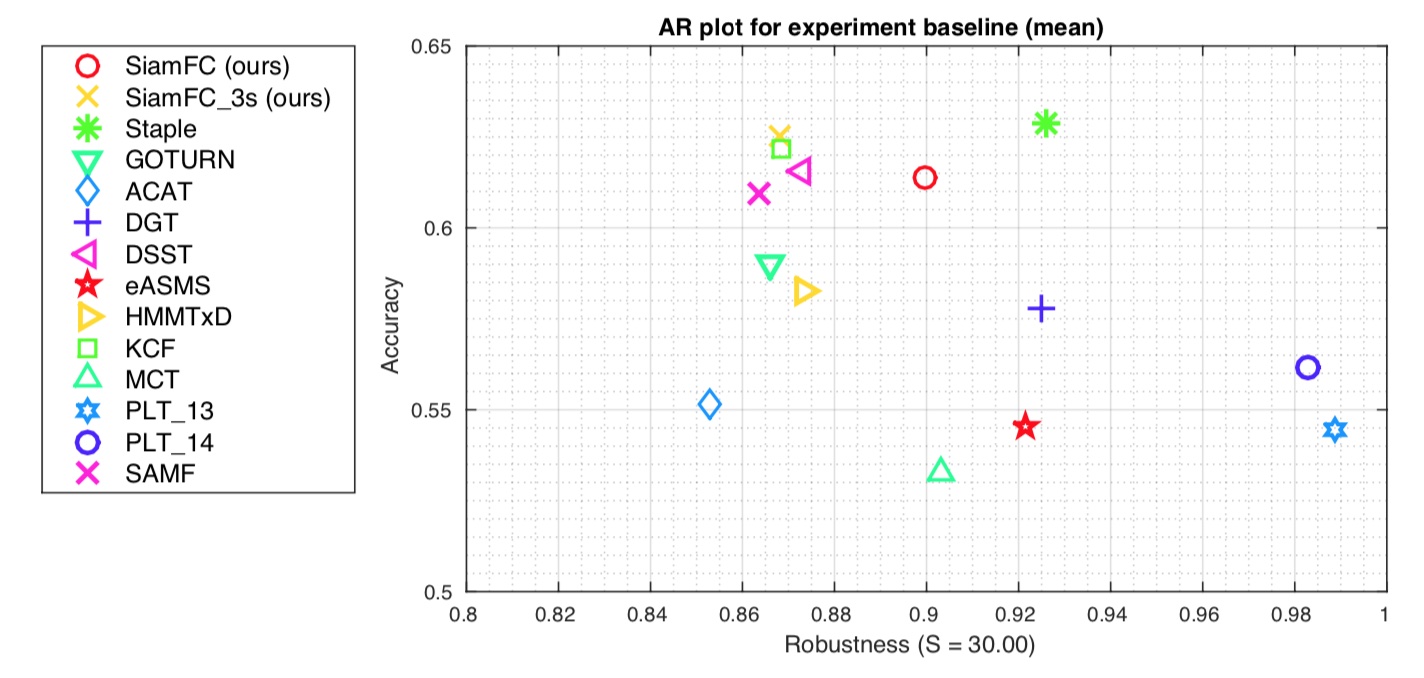
VOT-2014结果:除了和VOT2014的前十名的跟踪算法相比,还另外加入了Staple和GOTURN。算法主要两个评价指标:accuracy和robustness,前者是计算平均IOU,后者是计算总是失败帧数。下图显示了Accuracy-Robustness plot(按照accuracy和robustness分别进行排名,再进行平均)。
VOT-2015结果:下图显示了VOT-2015排名前41名的跟踪算法,另外还用表格显示出了排名前15的跟踪算法的更加细节的比较(包括速度)
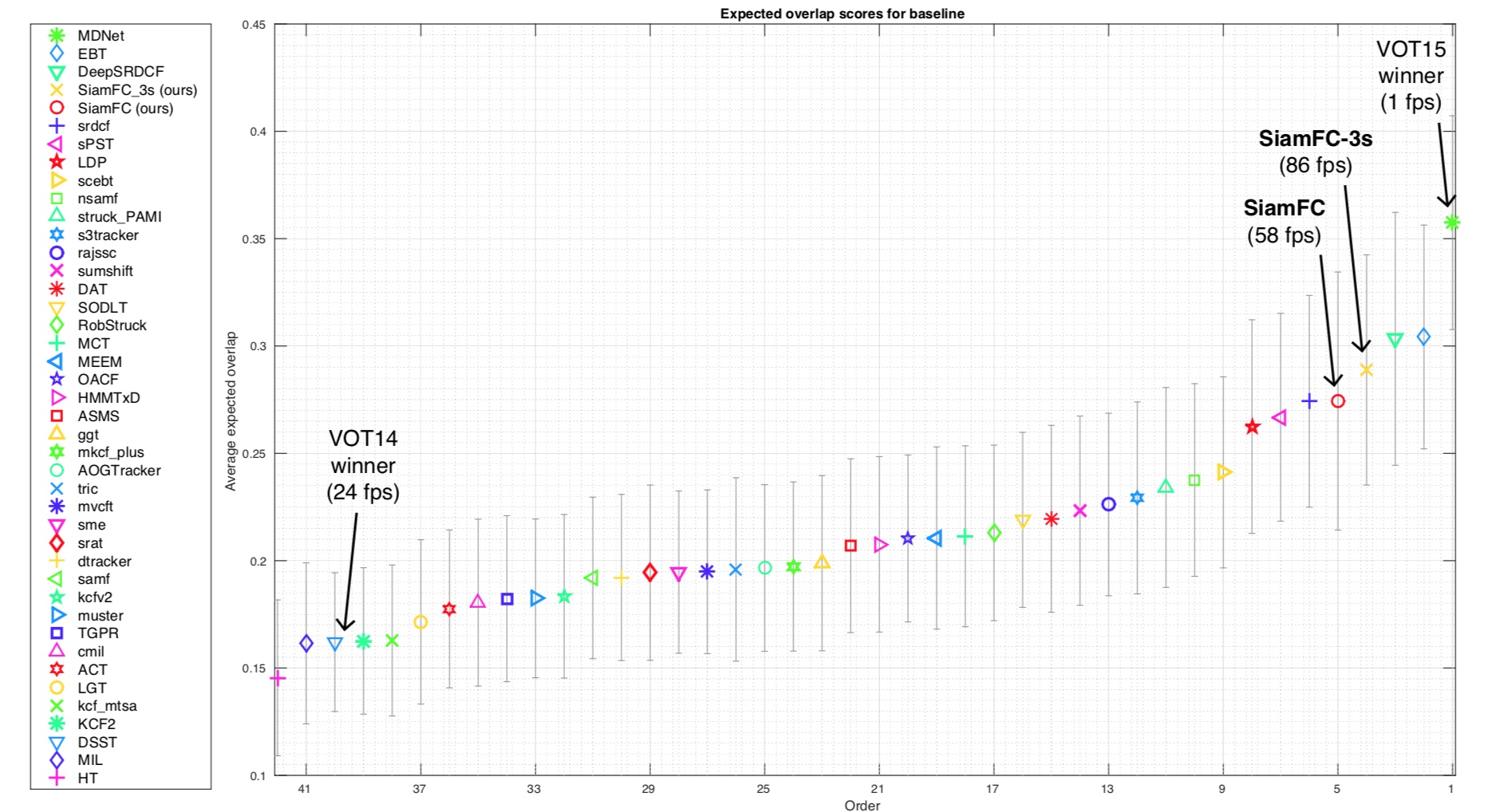
7.4.1.5.6 SiamFC的发展
SiamFC短短一年就有很多跟进paper,可以说开创了目标跟踪的另一个方向。从VOT2017的结果来看,SiamFC系列位数不多的end2end离线训练tracker,是可以得益于大数据和深度学习的最具发展潜力的方向。
注:有兴趣可以看看相关论文
7.4.2 SiamRPN
商汤科技智能视频团队首次开源其目标跟踪研究平台 PySOT。PySOT 包含了商汤科技 SiamRPN 系列算法,以及刚被 CVPR2019 收录为 Oral 的 SiamRPN++。
由于存在遮挡、光照变化、尺度变化等一些列问题,单目标跟踪的实际落地应用一直都存在较大的挑战。过去两年中,商汤智能视频团队在孪生网络上做了一系列工作,包括将检测引入跟踪后实现第一个高性能孪生网络跟踪算法的 SiamRPN(CVPR 18),以及最新的解决跟踪无法利用到深网络问题的 SiamRPN++(CVPR 19)。其中 SiamRPN++ 在多个数据集上都完成了 10% 以上的超越,并且达到了 SOTA 水平,是当之无愧的目标跟踪最强算法。
-
主要贡献
-
1、提出了孪生区域建议网络,能够利用ILSVRC和Youtube-BB大量的数据进行离线端到端训练。
-
2、在线跟踪时,将proposed framwork视为单目标的检测任务,这使得可以不用高耗时的多尺度测试就能精确的候选区域。
-
3、在VOT2015, VOT2016 and VOT2017的实时比赛中达到了最优性能,并且可达到160FPS,同时具有精度的效率的优势。
-
7.4.2.1 结构
由Siamese子网络和区域生成的候选区域子网络组成
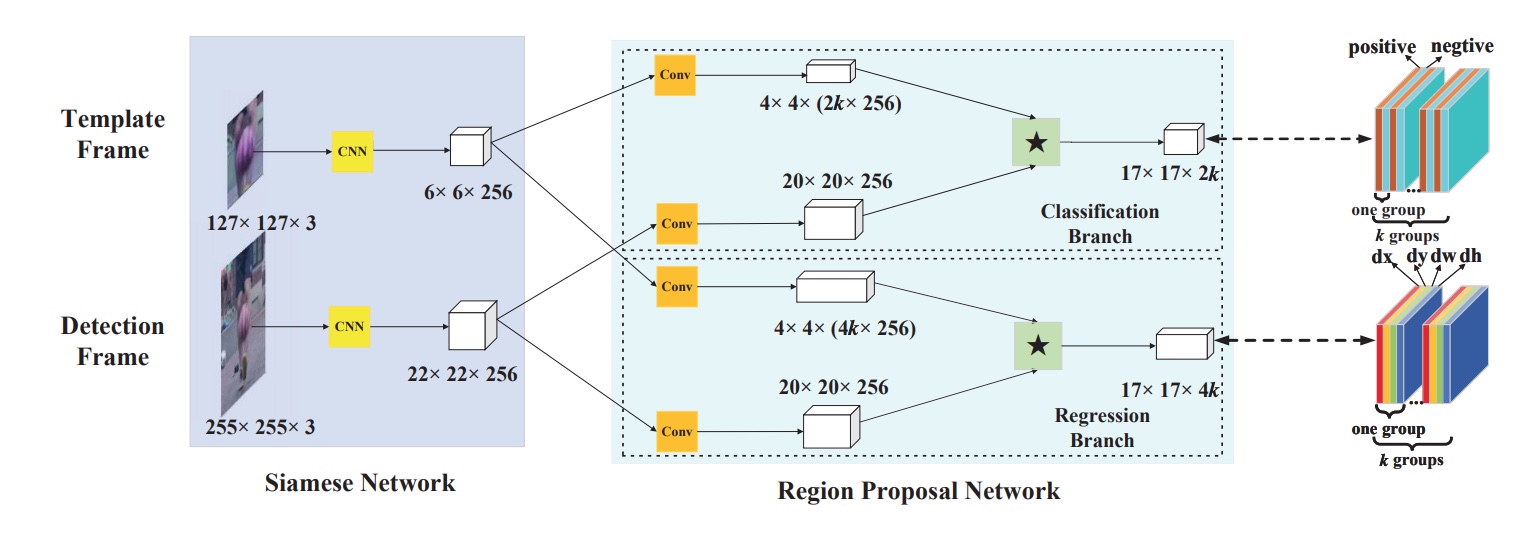
相比于SiameseFC的改进:
-
1、引进了Region Proposal Network。并将模板图像和检测图像经卷积神经层输出的feature map都复制双份,一份送到RPN中的分类分支,另一份送到RPN中的回归分支。
-
2、在RPN的分类分支中
-
模板图像和检测图像的feature map,都将首先通过一个卷积层,该卷积层主要是对模板图像的feature map进行channel上的升维
-
维度变为检测图像的feature map的维度的2k倍(k为RPN中设定的anchor数)。将模板图像的feature map在channel上按序等分为2k份,作为2k个卷积核,在检测图像的feature map完成卷积操作,得到一个维度为2k的score map。该score map同样在channel上按序等分为k份,得到对应k个anchor的k个维度为2的score map,两个维度分别对应anchor中前景(目标)和后景(背景)的分类分数,是关于目标的置信度。
-
-
3、在RPN的回归分支中
-
其维度变为检测图像的feature map的维度的4k倍(k为RPN中设定的anchor数)。此后,将模板图像的feature map在channel上按序等分为4k份,作为4k个卷积核,在检测图像的feature map完成卷积操作,得到一个维度为4k的score map。该score map同样在channel上按序等分为k份,得到对应k个anchor的k个维度为4的score map,四个维度分别对应anchor的(x,y,w,h),是关于目标的坐标及尺寸。
-
RPN的引入,使得Siamese网络自然拥有了多尺度检测的能力(通过anchor机制cover各种size),并且可以准确地回归出目标的位置及大小。
Siamese feature extraction subnetwork
该子网络由模板分支和检测分支组成:模板分支将历史帧的目标块作为输入,用 z 表示;检测分支用当前帧的目标块作为输入,用 x表示。两个网络共享CNN参数,用 φ(z) 和 φ(x)表示网络输出。
Region proposal subnetwork
该子网络由分类分支和回归分支组成,分类分支输出有 2k个channels(前景和背景),回归分支有 4k个channels(x,y,w,h),其中 k表示anchors,即每个位置预测框的个数。分类分支使用cross-entropy损失,回归分支使用Faster R-CNN中的smooth L1损失。
7.4.2.2 训练
-
1、Siamese子网络首先在ImageNet上进行预训练,然后用SGD对Siamese-RPN进行端到端训练
-
2、由于在跟踪任务中相邻帧间的变化不会太大,所以选用的anchors个数比检测任务要少。只选用了一个尺度的5种不同宽高比[0.33,0.5,1,2,3]
-
3、正样本:IOU >0.6,负样本:IOU < 0.3。对每个样本对限制最多16个正样本和总共64个样本
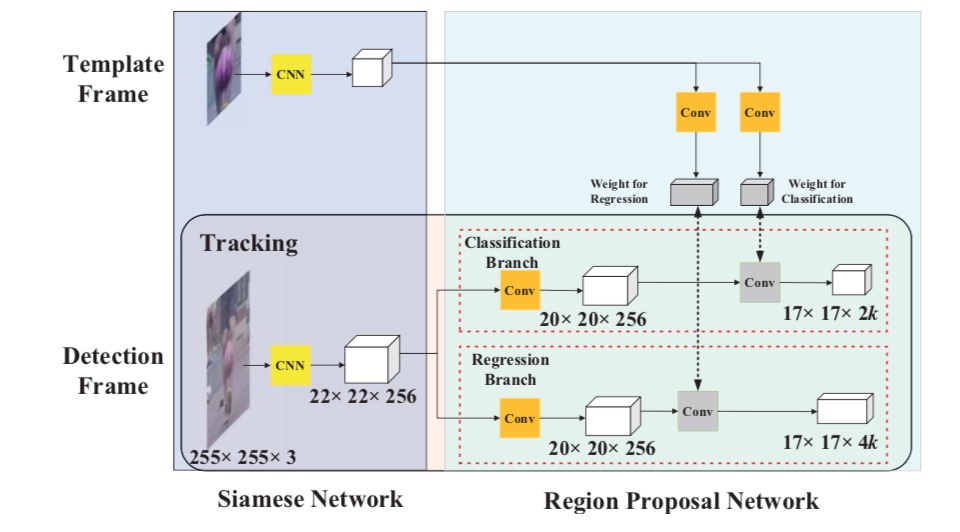
预测过程
模板分支在初始帧得到的输出作为检测分支的卷积核,然后在整个跟踪过程中固定不变。
7.4.2.3 实验效果
在基线算法 SiamFC 的基础上,让tracker可以回归位置、形状,可以省掉多尺度测试,进一步提高性能并加速。SiamRPN 实现了五个点以上的提升(OTB100,VOT15/16/17 数据集);同时还达到了更快的速度(160fps)、也更好地实现了精度与速度的平衡。
VOT2015效果
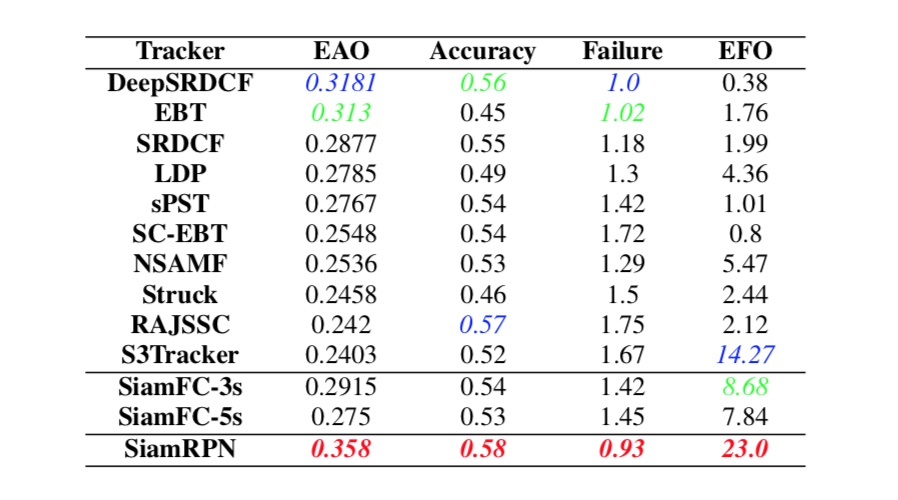
VOT2016效果
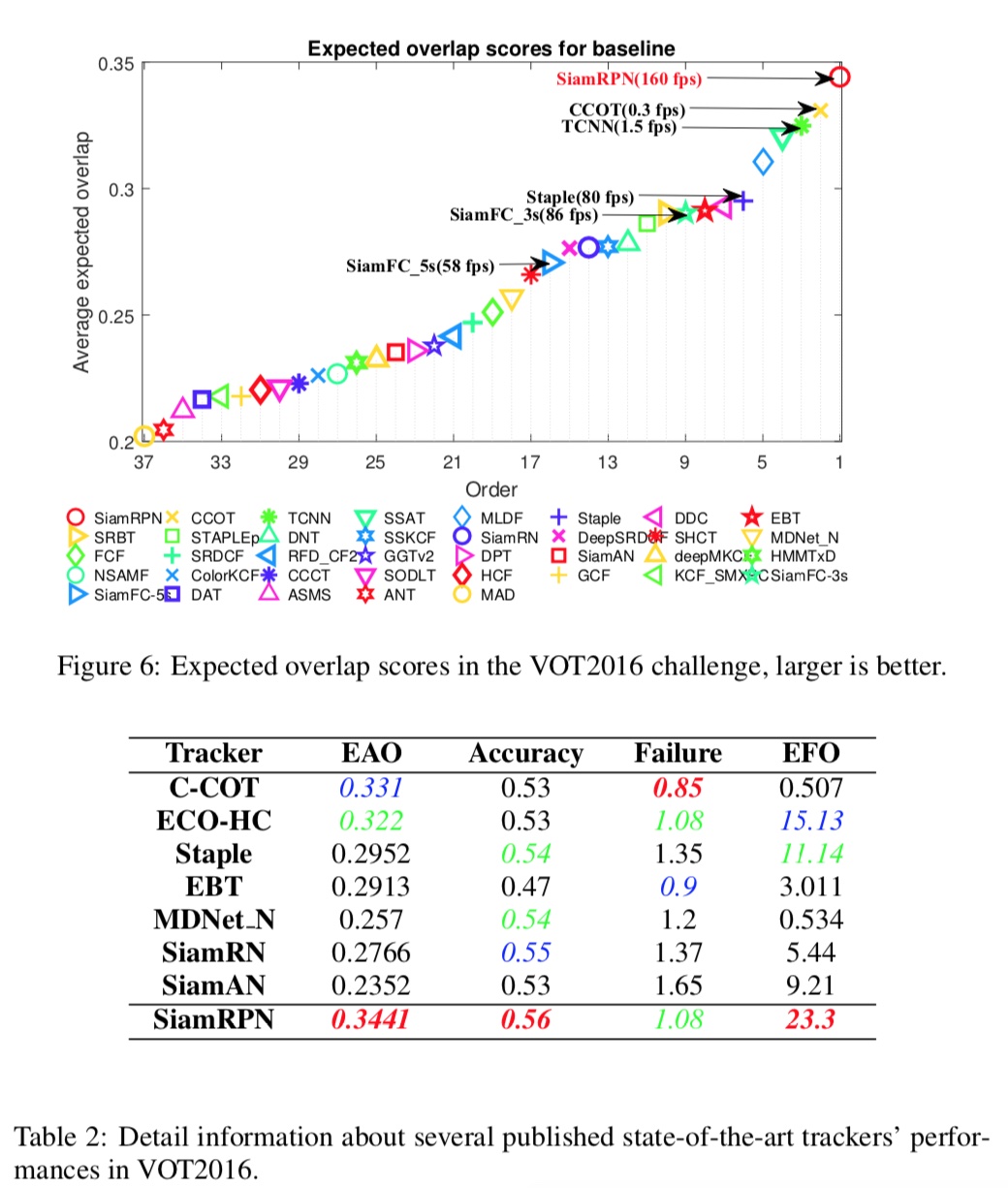
7.4.2.4 总结
与SiamFC对比
-
视觉跟踪领域主流的实时跟踪方法是以SiameseFC为代表的孪生网络结构,Siamese FC网络非常简单,通过相同的网络提取出图像的特征,通过类似卷积的相关操作方法,可以快速的实现模板与搜索区域中的17×17个小图像进行比对,输出的17×17的响应图,相当于每个位置和模板帧的相似度。
-
但SiameseFC有以下缺陷:1、首先由于没有回归,网络无法预测尺度上的变化,所以只能通过多尺度测试来预测尺度的变化,这里会降低速度。其次,2、输出的相应图的分辨率比较低,为了得到更高精度的位置,Siamese FC采用插值的方法,把分辨率放大16倍,达到与输入尺寸相近的大小。
-
-
SiameseRPN通过引入物体检测领域的区域推荐网络(RPN),通过网络回归避免多尺度测试,一方面提升了速度,另一方面可以得到更为精准的目标框,更进一步,通过RPN的回归可以直接得到更精确地目标位置,不需要通过插值得到最终的结果。在训练过程中,由于引入了大规模的视频数据集Youtube-BB进行训练,相比较SiameseFC使用的VID数据集,Youtube-BB在视频数量上有大约50倍的提升,这保证了网络能够得到更为充分的训练。
7.4.3 SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks (SiamRPN++)
之前的孪生网络,都是基于比较浅的卷积网络 (比如AlexNet) 。但如果直接引入深度网络,性能反而会大幅下降。
现存很多基于SiamNet算法的网络深度基本与Alext相似,作者多次尝试使用ResNet等深层网络,但性能并没有什么提升。经分析知,由于paddingpadding导致特征图失去了严格的裁剪不变性,不能很好的根据响应图位置反推目标的位置。为了能够使用深层网络来提取更加鲁棒的特征,作者提出一种有效的采样方式来打破空间不变的限制。
7.4.3.1 架构
使用ResNet-50作为特征提取的网络构架,提出depthwise和layerwise操作针对特征进行优化,提升SiamRPN网络的性能。下图为该算法框架图
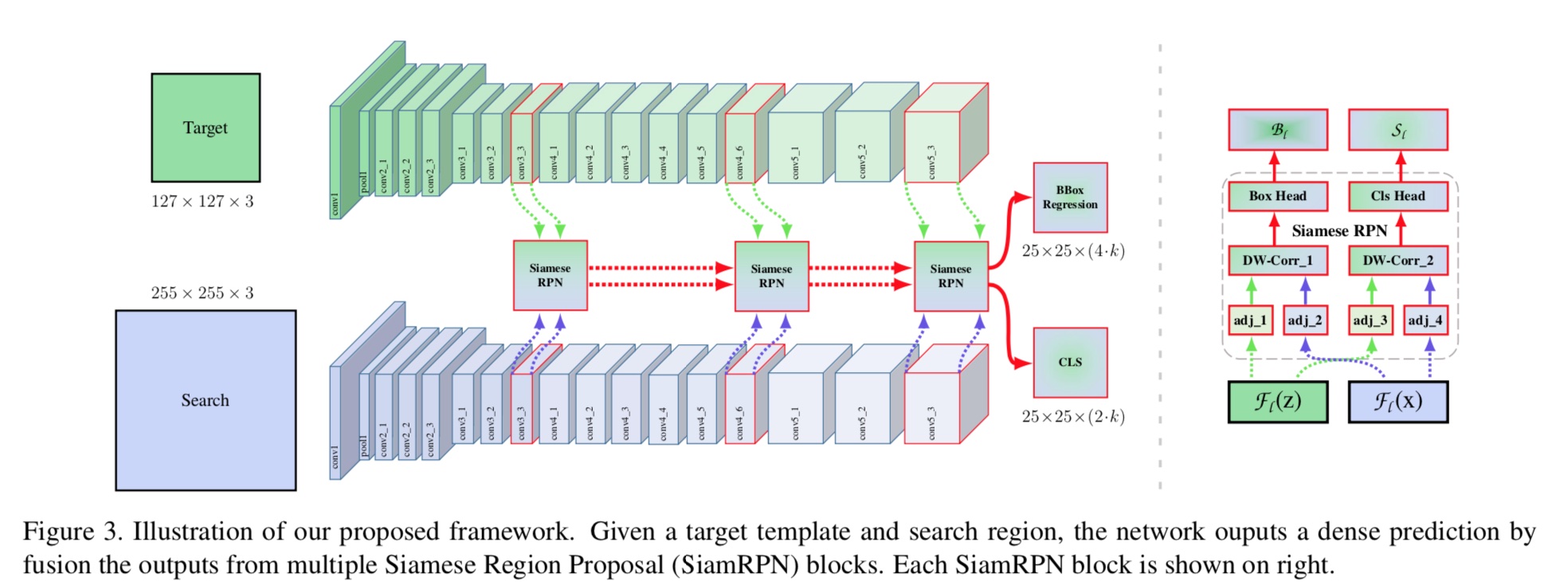
1、不同层特征应用
使用深层网络作为特征提取结构,网络的输出是目标的深层语义特征,而那些用于定位目标的浅层特征则未被利用。为了合理的结合深-浅层特征,作者提出channel-wise模块用于结合不同层特征,最大化提升网络的跟踪性能。
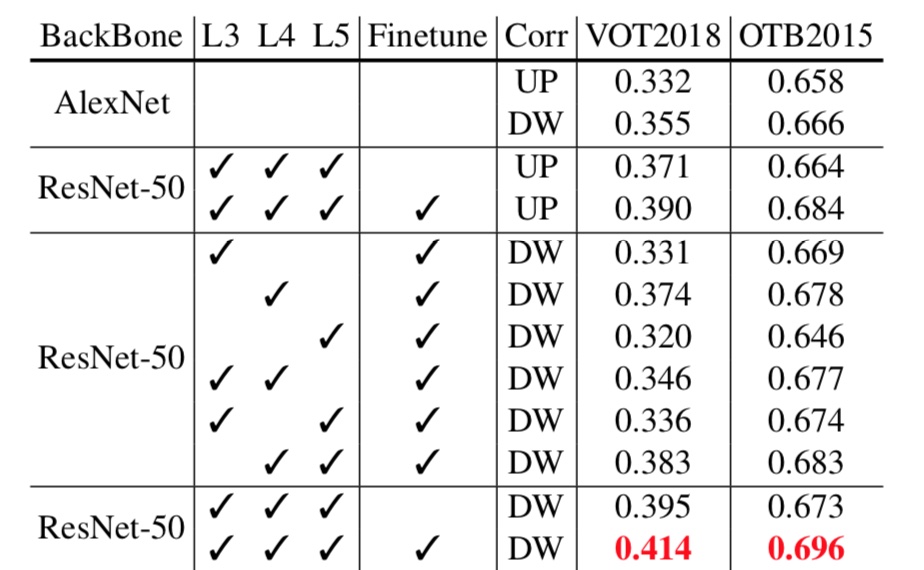
上图红框框出了不同层间跟踪性能,其中多层结合对极大地提升算法的跟踪性能,大概3%左右
2、减少参数数量
针对SiamRPN网络中UP-Channel操作带来的巨大网络参数量以及训练时难以拟合,作者提出一种Channel-wise操作,针对通道间进行卷积,有效的减少了网络参数量,同时加快了网络的拟合。 普通卷积、UP-Channel卷积、Channel-wise卷积如下图所示:
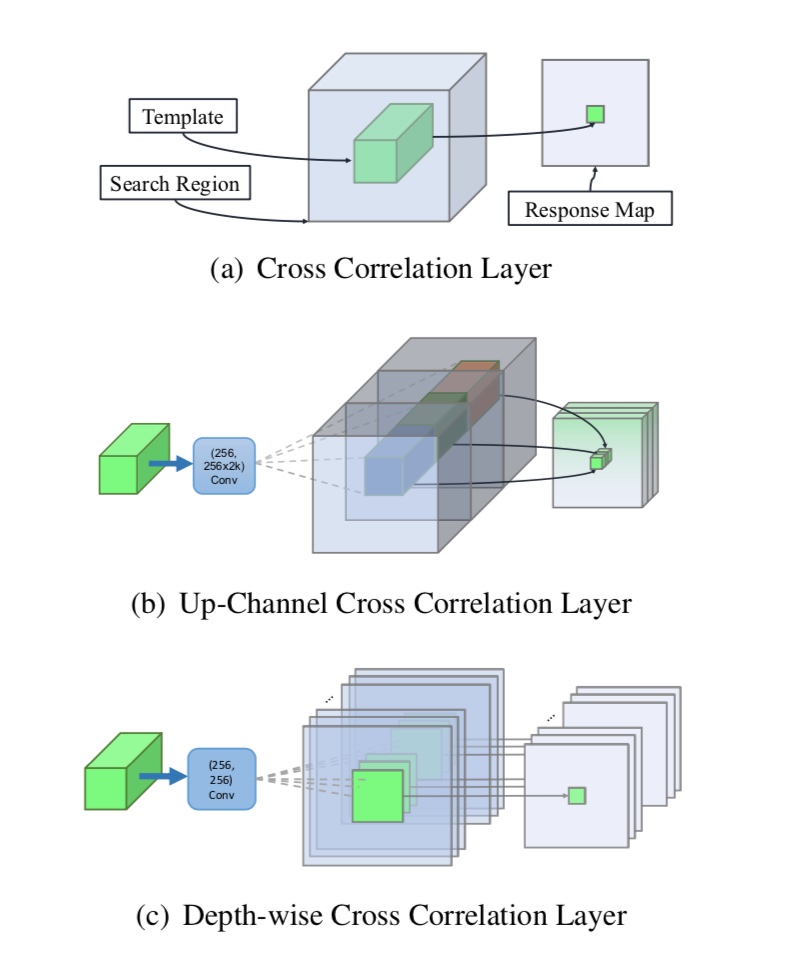
上图(b)中,可以明显的看出网络的通道数增加了2k倍,不仅带来了巨大的内存消耗,同时还难以拟合优化;图(c)采用了Channel-wise则有效的减少了网络的内存开销以及网络的优化参数。
3、添加Shift
针对padding带来的裁剪不变性丢失的问题,作者引入了一种新的有效的采样策略。深层网络中使用padding会导致网络习得隐藏的规律,目标所在的位置就在中心,从而导致响应图的最大值在中心附近。为了打破这种规律,作者在训练时将样本对中标签样本分布添加一个shift,从而保证样本中心的一种近似随机分布。
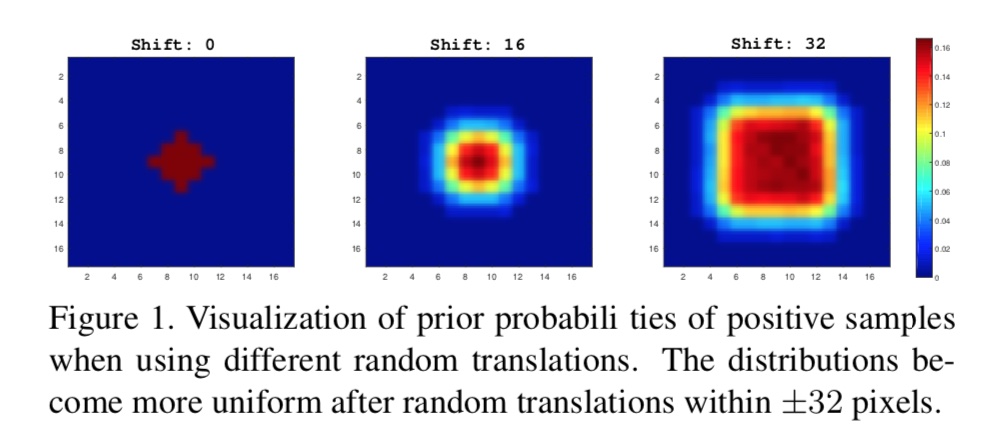
上图中从左往右显示了不同shift的响应图可视化。可以看出添加shift后,响应图的最大值分布会往四周扩散,有效地减轻了网络习得的中心化响应。
7.4.3.2 实验
-
性能比较
在VOT2018数据集上,Siam-RPN++在EAO、accuracy、AO指标上获得最佳成绩。

在OTB2015数据集上,性能也优于采用KCF方法的ECO算法,在成功率指标上获得最佳性能。
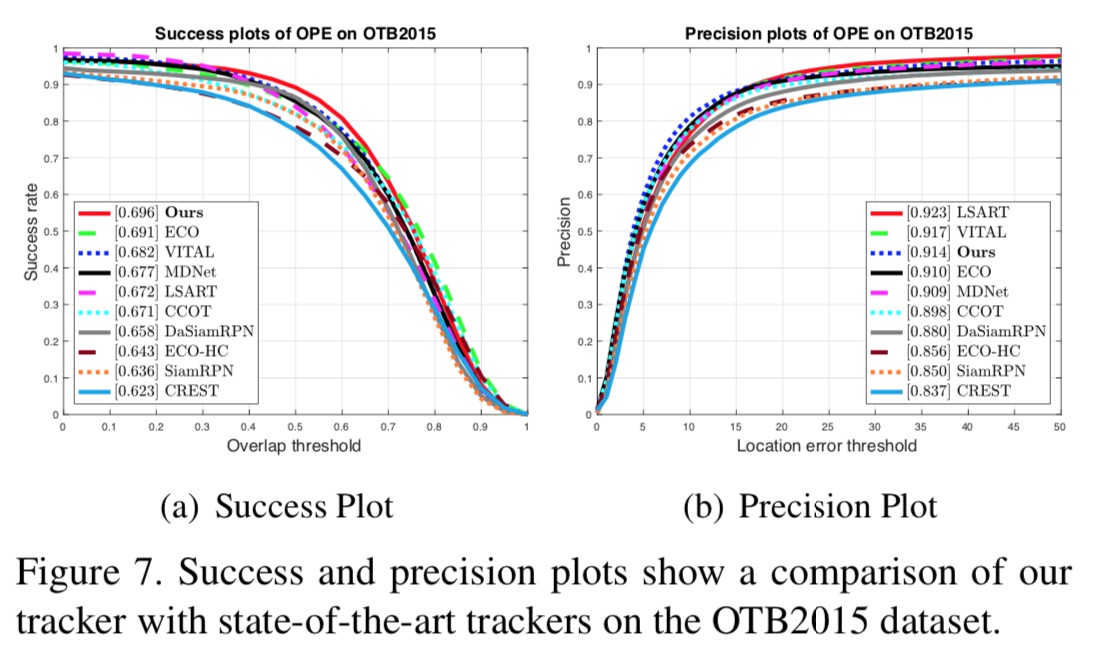
7.4.3.3 总结
-
Siam-RPN++从另一个角度解决深层网络带来的性能退化问题–标签样本的shift。
-
利用Channel-wise和layer-wise来提升目标特征的选择,提升跟踪性能。深浅层特征结合在KCF相关论文里早已提及,说明以后使用深层网络时需注意不同层特征之间的结合,以最大化利用浅层信息与深层信息。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187018.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
