大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
电商网站商品价格获取
本文以苏宁易购,京东,两个电商网站,模仿说明电商网站商品价格的两种获取方法。
json形式存放,京东商品的价格以json形式存放,以以下页面为例

https://item.jd.com/100000287133.html
明显价格数据并非放在前端页面里,搜索找到以下数据
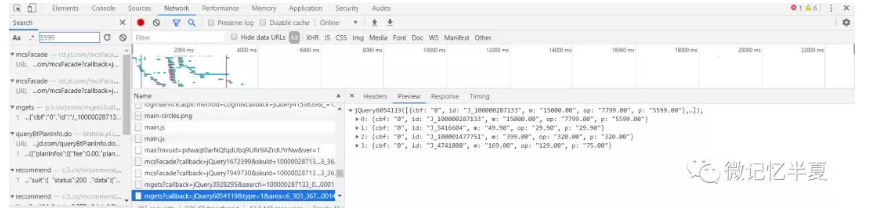
查看当前的url

在浏览器中请求
https://p.3.cn/prices/mgets?callback=jQuery6054119&type=1&area=6_303_36780_0&pdtk=&pduid=1588655612&pdpin=&pin=null&pdbp=0&skuIds=J_100000287133%2CJ_5416604%2CJ_100001477751%2CJ_4741808&ext=11100000&source=item-pc
通常来说call_back包含的内容可以直接去除,将链接处理后得到
https://p.3.cn/prices/mgets?skuIds=J_100000287133
skuIds=J_100000287133
#分析即可发现j_后的字符串为商品ID,对应商品详情页的链接
请求结果如下:

接下来,填充主程序。仅作为示例代码,详情数据重新处理
import scrapy
import json
class JgSpider(scrapy.Spider):
name = 'jg'
allowed_domains = ['shouji.jd.com','p.3.cn'] #需说明的是在价格详情内域名发生了变化
start_urls = ['https://item.jd.com/100000287133.html']
def parse(self, response):
item = {
}
contain= response.xpath("//div[@class='product-intro clearfix']")
item["title"] = contain.xpath("./div[@class='itemInfo-wrap']/div[@class='sku-name']/text()").extract_first().strip()
item["sku_num"] = contain.xpath(".//a[@class='notice J-notify-sale']/@data-sku").extract_first()
item["price_href"]='https://p.3.cn/prices/mgets?&skuIds=J_{}'.format(item["sku_num"])
yield scrapy.Request(
item["price_href"],
callback=self.price_detail, #获取价格
meta={
"item":item}
)
def price_detail(self ,response):
item = response.meta["item"]
item["price"] =json.loads(response.body.decode())[0]["p"] #json数据遍历方法
print(item)
需要说明的几点:
allowed_domains = ['shouji.jd.com','p.3.cn'] #需说明的是在价格详情内域名发生了变化
item["price_href"]='https://p.3.cn/prices/mgets?&skuIds=J_{}'.format(item["sku_num"]) #也可直接拼接
代码运行结果如下:

苏宁易购商品价格获取,与淘宝的逻辑相似存放在主页面但需要正则匹配获取。

同样以具体的某些页面为例:
https://product.suning.com/0070091633/10717510914.html?safp=d488778a.10038.resultsRblock.12&safc=prd.3.ssdln_502687_pro_pic01-1_0_0_10717510914_0070091633
用同样的方法找到价格
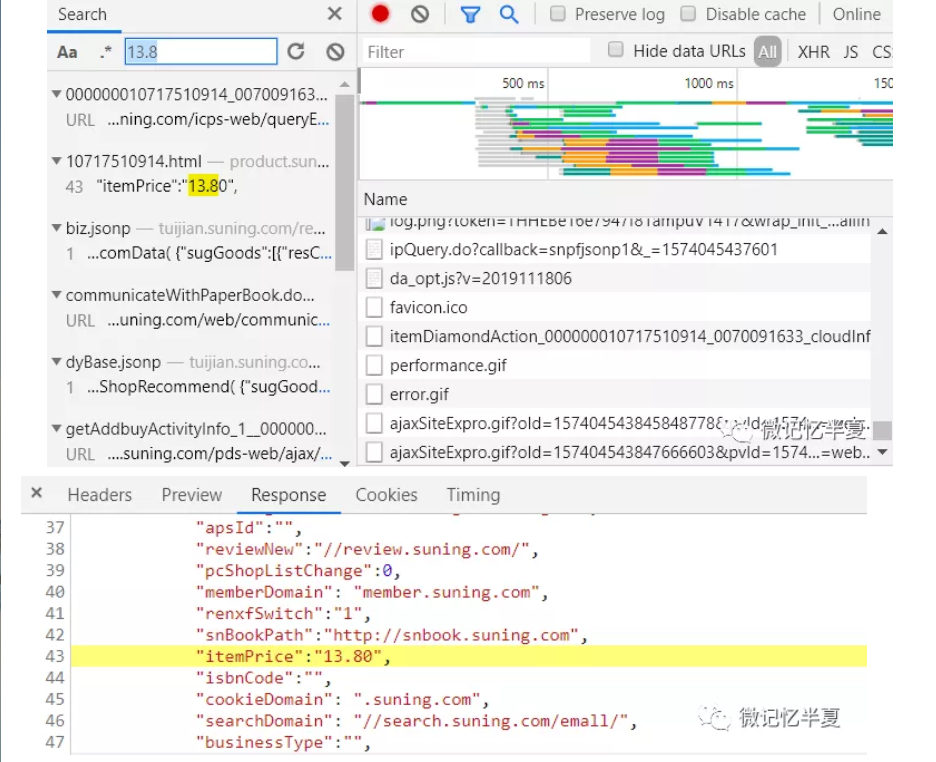
填充主程序代码:
import scrapy
import re
class SnSpider(scrapy.Spider):
name = 'sn'
allowed_domains = ['suning.com']
start_urls=['https://product.suning.com/0070091633/10717510914.html?safp=d488778a.10038.resultsRblock.12&safc=prd.3.ssdln_502687_pro_pic01-1_0_0_10717510914_0070091633']
def parse(self, response):
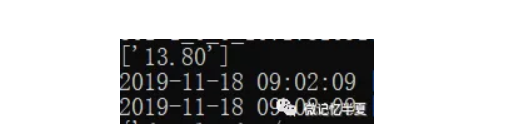
pr=re.findall('"itemPrice":"(.*?)",',response.body.decode())
print(pr)
运行结果如下
以上就是主流电商网站的商品价格获取方法,希望对大家的学习工作有所帮助。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/187017.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
